- The paper introduces a novel mask-guided region-aware vision-language pretraining approach that improves fetal ultrasound analysis by fusing global context with local anatomical details.
- It leverages a large-scale, curated dataset with 1.44M images and segmentation masks as visual prompts to boost zero-shot classification and segmentation performance.
- Extensive experiments show superior results with a Top-1 accuracy of 85.01% and a Dice score of 87.2%, underscoring its potential for clinical application.
Mask-Guided Region-Aware Vision-Language Pretraining for Fetal Ultrasound: An Analysis of SonoCLIP
Introduction and Motivation
The paper "SonoCLIP: Mask-Guided Region-Aware Vision-Language Pretraining for Fetal Ultrasound Analysis" (2606.29586) addresses fundamental limitations in vision-language foundation models (FMs) for fetal ultrasound. The domain is characterized by severe speckle noise, heterogeneous data acquisition, and ambiguous anatomical boundaries—all contributing to subjectivity and inter-operator variability in diagnostic interpretation. Although recent CLIP-inspired models have demonstrated transferability to medical imaging, their reliance on global image–text alignment restricts sensitivity to clinically crucial local anatomical details. SonoCLIP overcomes these constraints by integrating a region-controllable paradigm, leveraging segmentation masks as mask-channel visual prompts, and establishing a robust joint global–local contrastive representation learning framework.
Dataset Curation and Multimodal Data Pipeline
SonoCLIP’s performance is predicated on a highly curated, large-scale dataset comprising 1.44M fetal ultrasound images across 24 standard anatomical planes, with corresponding clinical records, segmentation masks, and structured captions. The data pipeline employs both manual annotation and AI-assisted segmentation to generate reliable anatomical masks, followed by quality control measures such as label-wise consolidation and geometric filtering to ensure high-quality supervision. Each image is enriched with region-level (mask-targeted) and global text descriptions to enable multi-level semantic alignment.
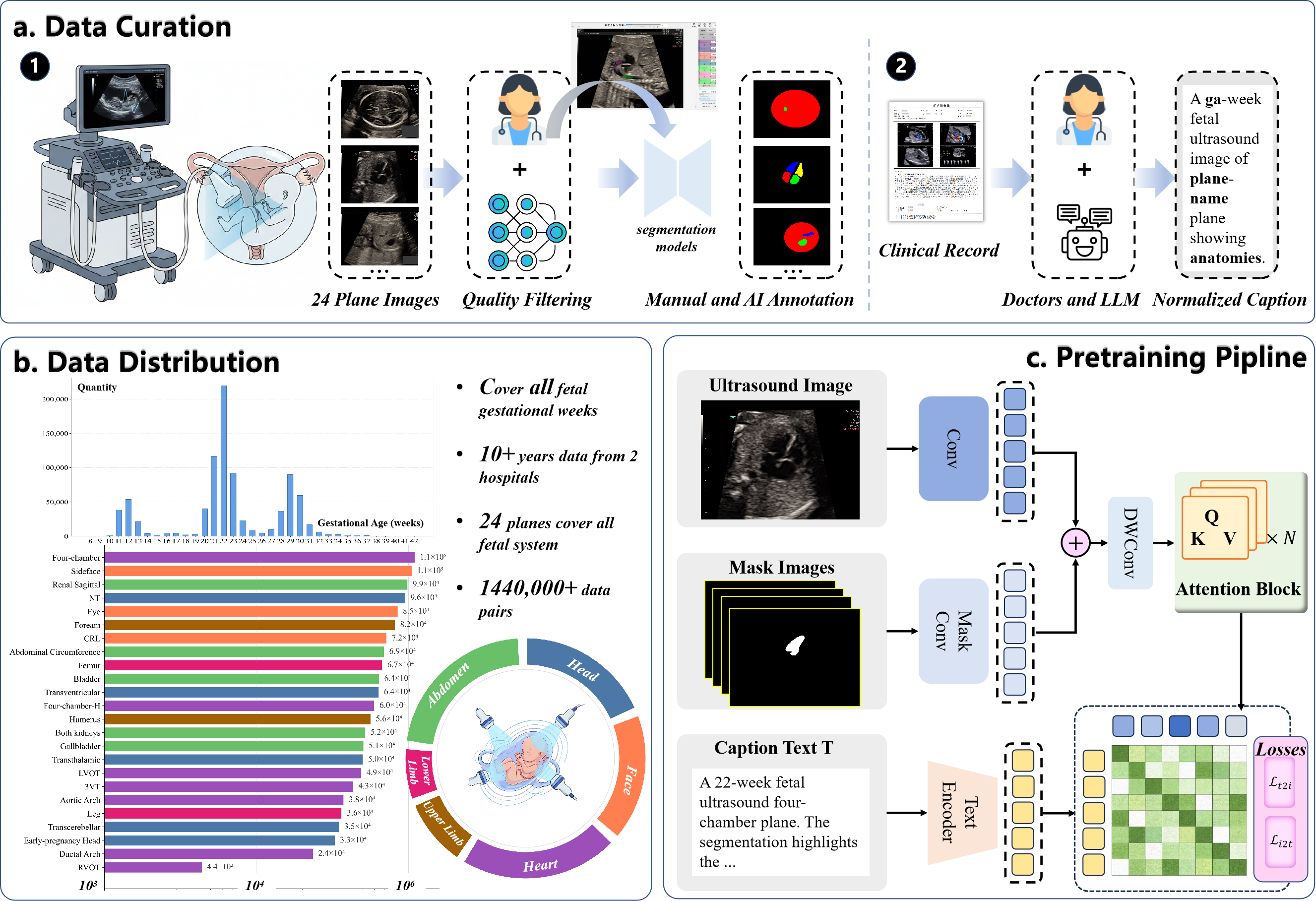
Figure 1: Overview of SonoCLIP including data curation, dataset stratification across gestation, and the multimodal mask-channel contrastive pretraining framework.
Model Architecture and Region-Controllable Pathway
The core innovation of SonoCLIP is the introduction of a mask-channel visual pathway within the CLIP architecture, enabling anatomical region prompts to be directly fused with ultrasound images at the feature embedding level. This dual-stem approach (image and mask) retains the pretrained global context while injecting salient region cues, initialized to preserve pretrained CLIP behavior but permitted to adaptively learn mask-informed representational biases during fine-tuning.
A second architectural contribution is the adoption of a sigmoid-based pairwise contrastive loss. By replacing softmax-normalized InfoNCE with a SigLIP-inspired independent image–text matching objective, SonoCLIP mitigates batch composition sensitivity and better accommodates large-scale, heterogeneous region–text supervision.
Experimental Results and Numerical Benchmarks
The extensive cross-center evaluations and ablations on FetalP24 (Center B), FetalP6, and FetalP5 demonstrate unequivocal numerical superiority for SonoCLIP.
- Zero-shot classification on FetalP24 (Center B): SonoCLIP (w/ mask) achieves a Top-1 accuracy of 85.01% and Top-5 of 99.01%, greatly outperforming FetalCLIP (39.78%/83.25%) and UniMed-CLIP (16.69%/50.34%).
- Ablation studies confirm that enabling both mask-channel guidance and the sigmoid objective yields substantial performance gains over either component in isolation, with observed synergistic improvements.
- Zero-shot and linear-probe evaluation on the FetalP6 dataset further corroborate these findings. SonoCLIP (w/ mask) achieves perfect or near-perfect accuracy in most classes, with an average accuracy/F1 of 99.3%/98.8%.
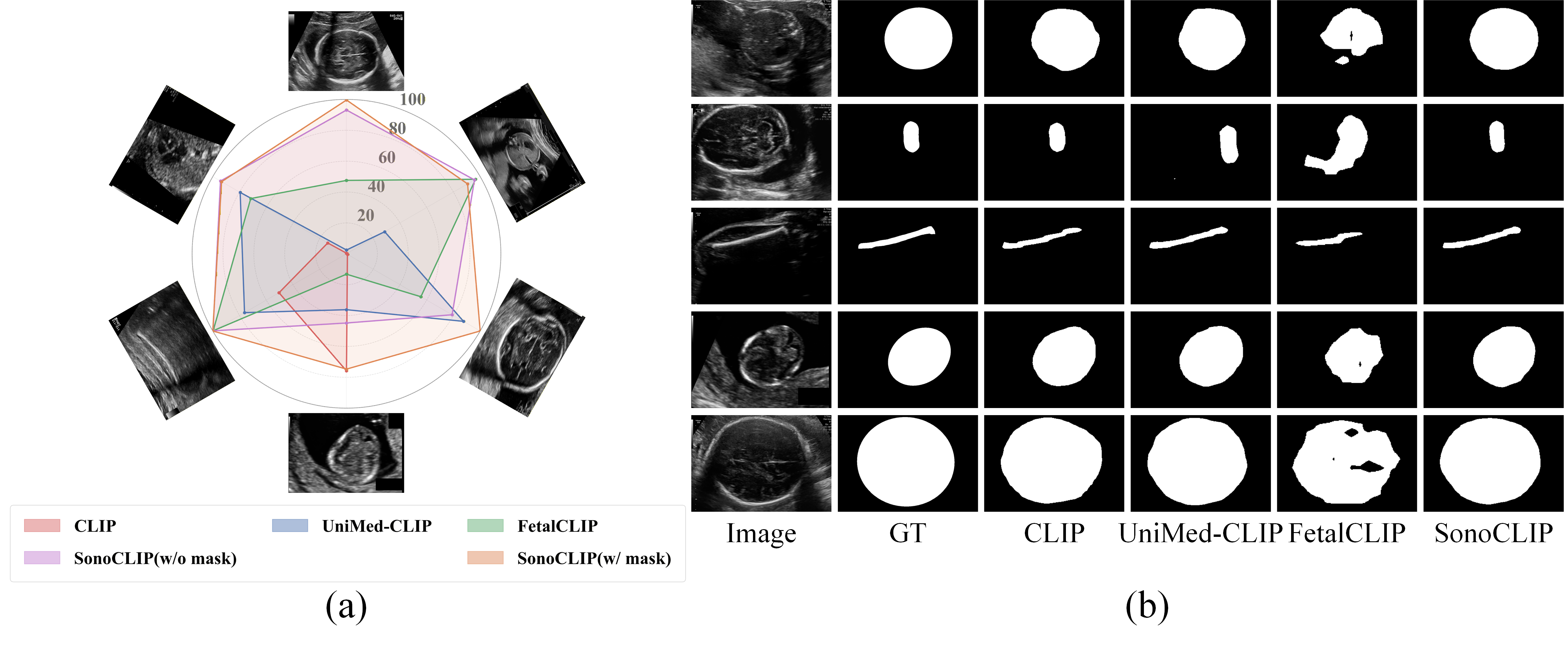
Figure 2: (a) Zero-shot classification accuracy on the FetalP6 benchmark, (b) Segmentation qualitative comparison on FetalP5, demonstrating the improved clarity and completeness of SonoCLIP's predictions.
- Segmentation on FetalP5: SonoCLIP delivers a Dice score of 87.2% and mIoU of 80.5%, with qualitative outputs showing more precise and contiguous regional predictions, confirming the efficacy of joint global–local representation learning.
Theoretical and Practical Implications
The inclusion of region-controllable pathways and mask-guided pretraining enables foundational representations that are both anatomically granular and robust to extrinsic sources of noise (e.g., equipment, acquisition site), thereby reducing inter-observer variability. The scalable sigmoid-based contrastive loss aligns with theoretical advances in contrastive learning for large batch sizes and heterogeneous supervision. Practically, the model supports zero-shot transfer, cross-domain generalizability, and efficient adaptation to new clinical centers or rare anatomical variants with minimal annotation overhead.
SonoCLIP's approach, by explicitly localizing learning to clinically decisive regions, contrasts with prevailing foundation model paradigms constrained to global semantics, and sets a precedent for future domain-customized foundation models in complex, high-variance imaging disciplines.
Limitations and Future Directions
While SonoCLIP's results are robust across multiple datasets and protocols, further research should explore:
- Extension of the mask-guided prompting mechanism to 3D or longitudinal fetal ultrasound sequences.
- Integration with real-time operator-in-the-loop systems for intra-procedural decision support.
- Application of the region-controllable philosophy to other ambiguous imaging modalities including echocardiography, elastography, or interventional navigation.
Future theoretical work should also investigate the compatibility of region-aware supervision with other multimodal fusion techniques (e.g., cross-attention transformers) and the downstream interpretability of learned representations.
Conclusion
SonoCLIP establishes a new benchmark for fetal ultrasound foundation models by harnessing mask-guided, region-aware contrastive pretraining at unprecedented scale. The demonstrated numerical gains in zero-shot transfer, segmentation, and cross-domain robustness highlight the transformative potential of region-controllable, multimodal learning paradigms for clinically reliable and anatomically sensitive foundation models in medical imaging (2606.29586).

