- The paper introduces a CTC-seeded edit refinement technique that initiates decoding from a collapsed greedy CTC hypothesis to iteratively correct token-level errors.
- The methodology employs a bidirectional Transformer-based Edit Flow decoder that predicts insertion, deletion, and substitution operations via Levenshtein alignment for efficient token edits.
- Empirical results on LibriSpeech demonstrate significant WER reductions with only two refinements, leveraging classifier-free audio guidance and CTC confidence gating.
CTC-Seeded Edit Flow: Efficient Token-Level Refinement for Non-Autoregressive ASR
Motivation and Context
Automatic Speech Recognition (ASR) has advanced through autoregressive models such as RNN-T and AED, which leverage decoder-side context for token dependency modeling but suffer from inherent inference latency. In contrast, Connectionist Temporal Classification (CTC) enables efficient, parallel decoding but lacks the capacity for robust dependency reconstruction, typically resulting in higher residual error rates. Recent non-autoregressive (NAR) refinement-based ASR approaches attempt to mitigate this gap by iteratively reconstructing output sequences, often starting from uninformative or fully masked states. These methods, including diffusion-based NAR generation, require multiple rounds to reach the reference transcript, substantially increasing decoding cost.
This work proposes an alternative: seeding NAR speech recognition with a collapsed greedy CTC hypothesis and directly learning parallel token edit refinement via a discrete diffusion model. The Edit Flow decoder operates on variable-length sequences, predicts targeted insert, delete, and substitute operations, and is trained jointly with the CTC backbone under an acoustic-conditioned loss. The approach is informed by edit-distance alignment, minimizes unnecessary sequence reconstruction, and leverages novel inference strategies, including classifier-free audio guidance and CTC confidence gating.
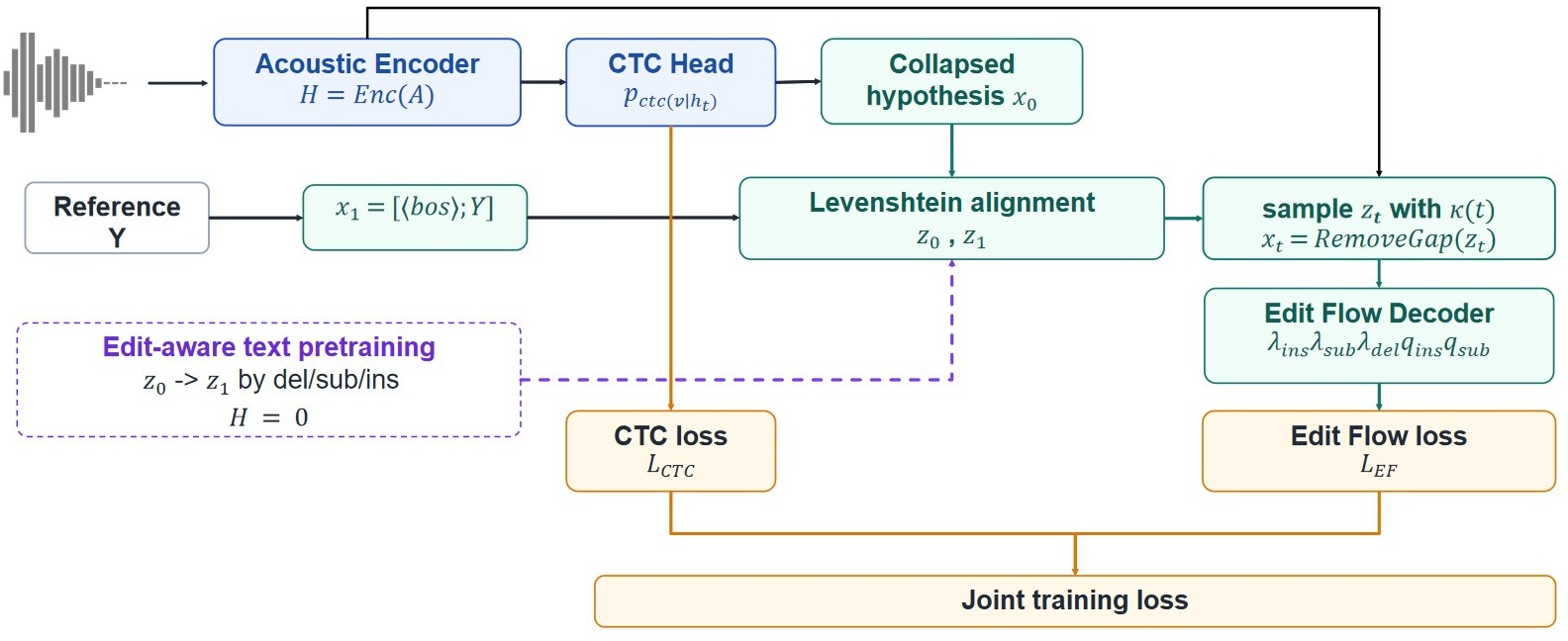
Figure 1: Overview of the proposed CTC-seeded Edit Flow training procedure, which initializes decoding from a collapsed CTC hypothesis and executes parallel token edits conditioned on acoustic evidence.
Methodology
CTC Hypothesis Seeding and Variable-Length Edit Flow
The model first obtains a greedy CTC hypothesis, collapses repeated and blank tokens, and uses this compact sequence as the initial decoding state. The Edit Flow decoder, a bidirectional Transformer, is then tasked to transform this hypothesis toward the ground truth transcript via a path defined by insertion, deletion, and substitution edit operations. Crucially, the model computes Levenshtein alignment in an auxiliary gap-augmented space, which allows for efficient edit tracking and avoids the overhead of padded or fixed-length latents.
At each refinement step t, the Edit Flow decoder receives the partially edited sequence, flow time, and acoustic memory, predicting edit rates and distributions in parallel across all positions. The continuous-time discrete diffusion loss encourages the decoder to focus correction intensity where residual errors remain, penalizing unnecessary edits and rewarding correct recovery of target operations.
Edit-Aware Pretraining
To enhance edit-correction robustness, an edit-aware text pretraining scheme corrupts transcripts with deletion, insertion, and substitution operations independently at each token, optimizing the decoder with the Edit Flow loss absent acoustic input. This initialization aligns the decoder's training distribution with typical ASR hypothesis error profiles, improving downstream performance.
Inference Strategies
Inference proceeds in a multi-step iterative process, using a tau-leaping approximation for Poisson edit event probabilities. Deterministic decoding applies edits exceeding operation thresholds, selecting highest-scoring tokens. Empirical analysis demonstrates efficacy with only two edit rounds.
Classifier-Free Audio Guidance
Classifier-free guidance (CFG) is employed on the acoustic condition. During training, acoustic memory is randomly dropped to enable guidance scale–weighted combination of conditioned and unconditioned edit fields. This prioritizes acoustic signal fidelity during decoding, reducing hallucinations.
CTC Confidence-Guided Editing
Residual CTC error regions correlate with low token-level confidence scores. Edit proposals are gated to only those positions and boundaries below a tunable confidence threshold, focusing refinement on acoustically ambiguous regions and suppressing unnecessary re-editing of high-confidence tokens.
Empirical Results
Extensive LibriSpeech evaluation shows consistent WER reductions across ESPnet and frozen Whisper encoder backbones. With two-step edit flow refinement, the method achieves 2.6%/5.8% WER on test-clean/other using ESPnet encoder and 2.0%/4.7% with Whisper Medium, representing relative reductions of ~25% versus CTC-only baselines. Edit-aware pretraining and optimal CTC confidence gating further enhance performance. Only two parallel edit rounds are needed to reach these results, outperforming many prior NAR and diffusion-based systems even those leveraging stronger supervised initialization or larger external corpora.
The procedure offers strong accuracy–efficiency tradeoffs without the need for lengthy diffusion sampling or recovery from fully masked/noisy initializations. Analysis demonstrates that the variable-length refinement is effective, as each edit operation directly corrects errors in the CTC path rather than performing full-sequence reconstruction. Final hypotheses after two rounds typically match reference transcripts, as illustrated in example cases.
Theoretical and Practical Implications
By reframing NAR ASR as structured edit refinement seeded by CTC, the approach provides a modular, extensible methodology for speech recognition that elegantly balances efficiency with correction power. The acoustic-conditioned Edit Flow bridges the divide between conditional independence in CTC and context-sensitive decoding in autoregressive models. This also enables straightforward integration with pretrained speech encoders, scaling readily with model capacity.
Classifier-free and confidence-guided strategies suggest generalizable mechanisms for balancing generative flexibility with acoustic grounding, relevant for broader NAR text and speech processing tasks. Edit-aware pretraining aligns the decoder's inductive bias with empirical ASR error distributions, hinting at future directions for synthetic hypothesis generation and semi-supervised correction.
Future Directions
Expanding multilingual coverage within this framework is a natural progression, capitalizing on the modularity of CTC-backed edit refinement. Combining the Edit Flow with self-supervised or weakly supervised pretraining, perhaps leveraging larger speech-text corpora, could further improve robustness in noisy or low-resource settings. The approach may also generalize to other sequence correction and translation tasks, especially where compact initial hypotheses can be reliably obtained.
Conclusion
CTC-seeded token edit refinement via acoustic-conditioned Edit Flow offers an efficient and accurate NAR ASR methodology. With variable-length, targeted correction and only two parallel refinement rounds, strong empirical performance is achieved, exceeding CTC baselines and competing with state-of-the-art NAR and diffusion-based systems. The framework's combination of structural edit tracking, acoustic confidence guidance, and edit-aware pretraining lays foundation for practical speech recognition deployments and motivates new directions in structured NAR decoding (2606.28732).

