Drax: Speech Recognition with Discrete Flow Matching
Published 5 Oct 2025 in eess.AS, cs.LG, and cs.SD | (2510.04162v1)
Abstract: Diffusion and flow-based non-autoregressive (NAR) models have shown strong promise in large language modeling, however, their potential for automatic speech recognition (ASR) remains largely unexplored. We propose Drax, a discrete flow matching framework for ASR that enables efficient parallel decoding. To better align training with inference, we construct an audio-conditioned probability path that guides the model through trajectories resembling likely intermediate inference errors, rather than direct random noise to target transitions. Our theoretical analysis links the generalization gap to divergences between training and inference occupancies, controlled by cumulative velocity errors, thereby motivating our design choice. Empirical evaluation demonstrates that our approach attains recognition accuracy on par with state-of-the-art speech models while offering improved accuracy-efficiency trade-offs, highlighting discrete flow matching as a promising direction for advancing NAR ASR.
The paper introduces Drax, a non-autoregressive ASR framework using a tri-mixture discrete flow matching path to bridge training and inference conditions.
The methodology leverages an audio-conditioned intermediate distribution with a frozen Whisper encoder and a DiT-based transformer decoder to improve efficiency.
Empirical results demonstrate competitive multilingual accuracy and superior runtime performance by enabling parallel token decoding and controlled accuracy-efficiency trade-offs.
Drax: Speech Recognition with Discrete Flow Matching
Overview
Drax introduces a non-autoregressive (NAR) automatic speech recognition (ASR) framework based on discrete flow matching (DFM), addressing the efficiency bottlenecks of autoregressive (AR) models while maintaining competitive recognition accuracy. The core innovation is a tri-mixture probability path that incorporates an audio-conditioned intermediate distribution, bridging the gap between noise-like source states and the ground-truth target during training. This design aligns the training and inference distributions, theoretically reducing the generalization gap and empirically improving both accuracy and efficiency. Drax demonstrates strong results across multilingual benchmarks, supports parallel decoding, and integrates naturally with candidate scoring and speculative decoding strategies.
Motivation and Background
AR ASR models, such as Whisper and Qwen2-Audio, achieve high accuracy but suffer from sequential decoding latency, which scales linearly with output sequence length. NAR models, particularly those based on diffusion and flow matching, enable parallel generation and offer explicit control over the accuracy-efficiency trade-off via the number of inference steps (NFE). However, prior DFM applications in ASR have relied on simple two-way mixture paths (noise-to-target), which fail to expose the model to plausible intermediate states encountered during inference, leading to a domain gap analogous to the train-sampling mismatch in AR models.
Drax addresses this by introducing an audio-conditioned middle distribution into the probability path, exposing the model to acoustically plausible but imperfect hypotheses during training. This tri-mixture path is theoretically motivated by an analysis linking the generalization gap to divergences between training and inference occupancies, which are controlled by cumulative velocity errors along the probability path.
Methodology
Discrete Flow Matching with Tri-Mixture Path
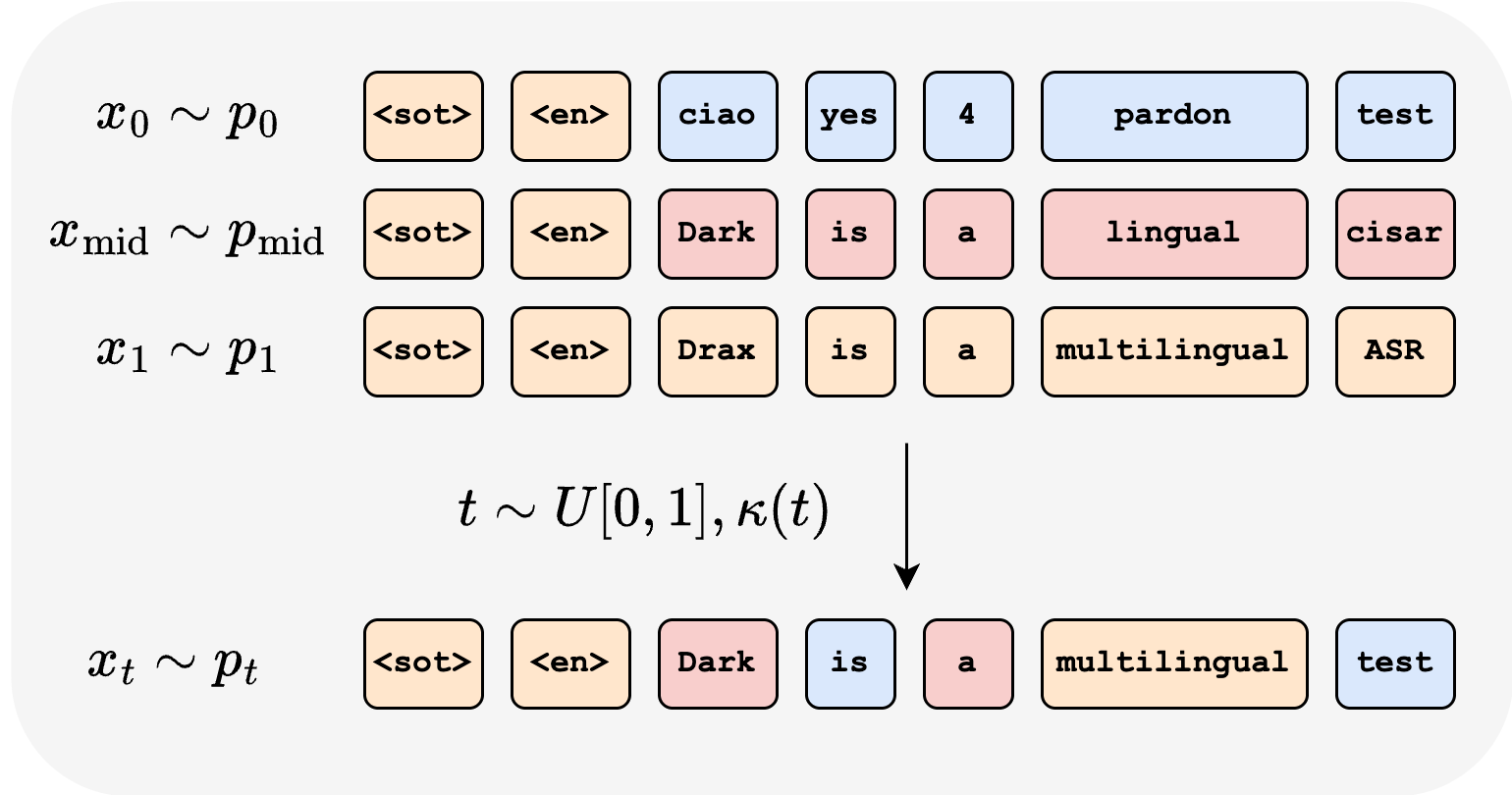
Let x∈VL denote a token sequence and a the input audio. Drax models the generative process as a flow from a source distribution p0 (uniform noise) to a target distribution q(x1) (ground-truth transcription), via a time-dependent probability path pt(x) parameterized as a convex combination of three components:
where κj(t) are smooth mixing schedules, and pmid(xi∣a) is an audio-conditioned categorical distribution parameterized by an auxiliary network.
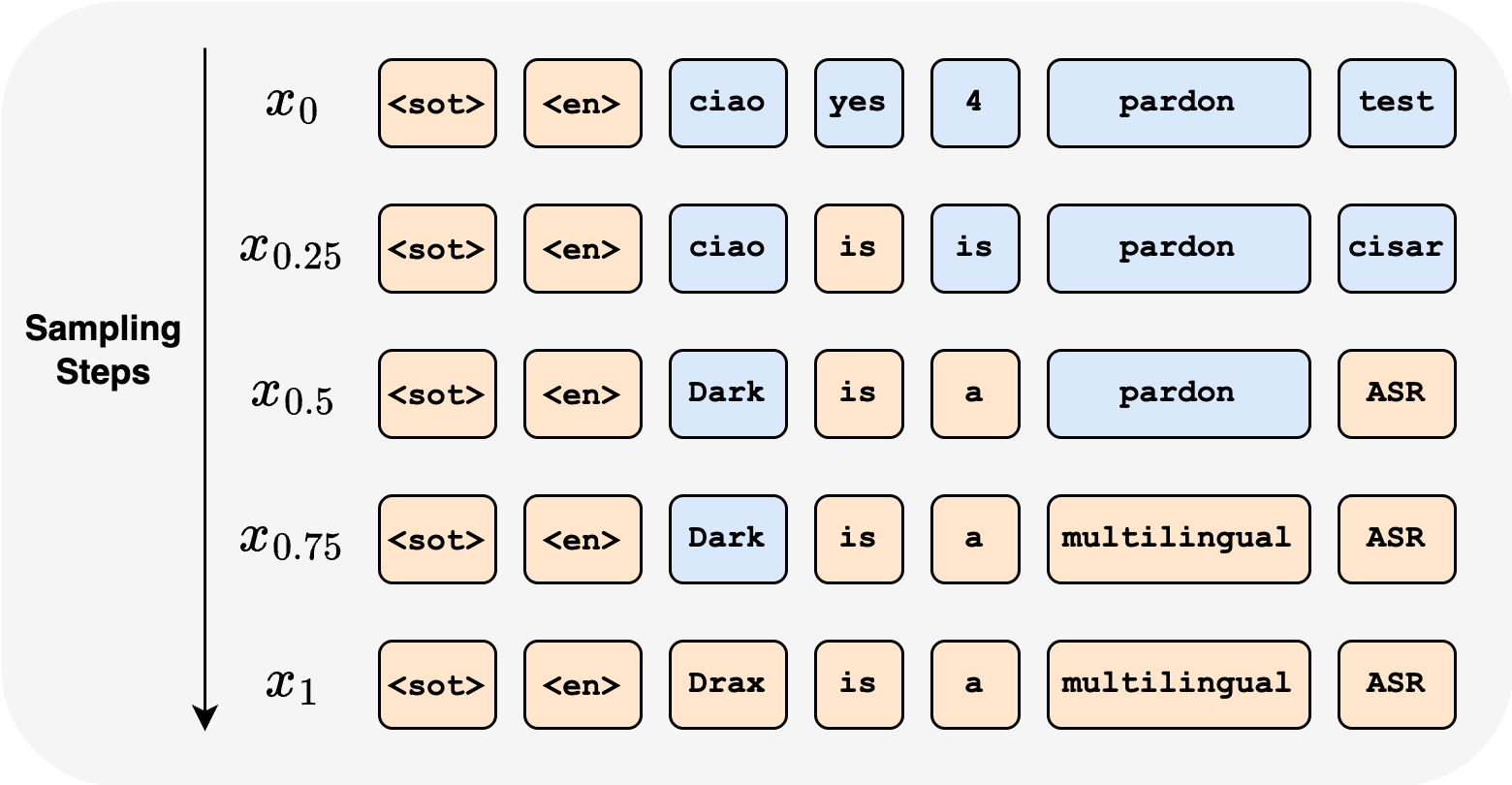
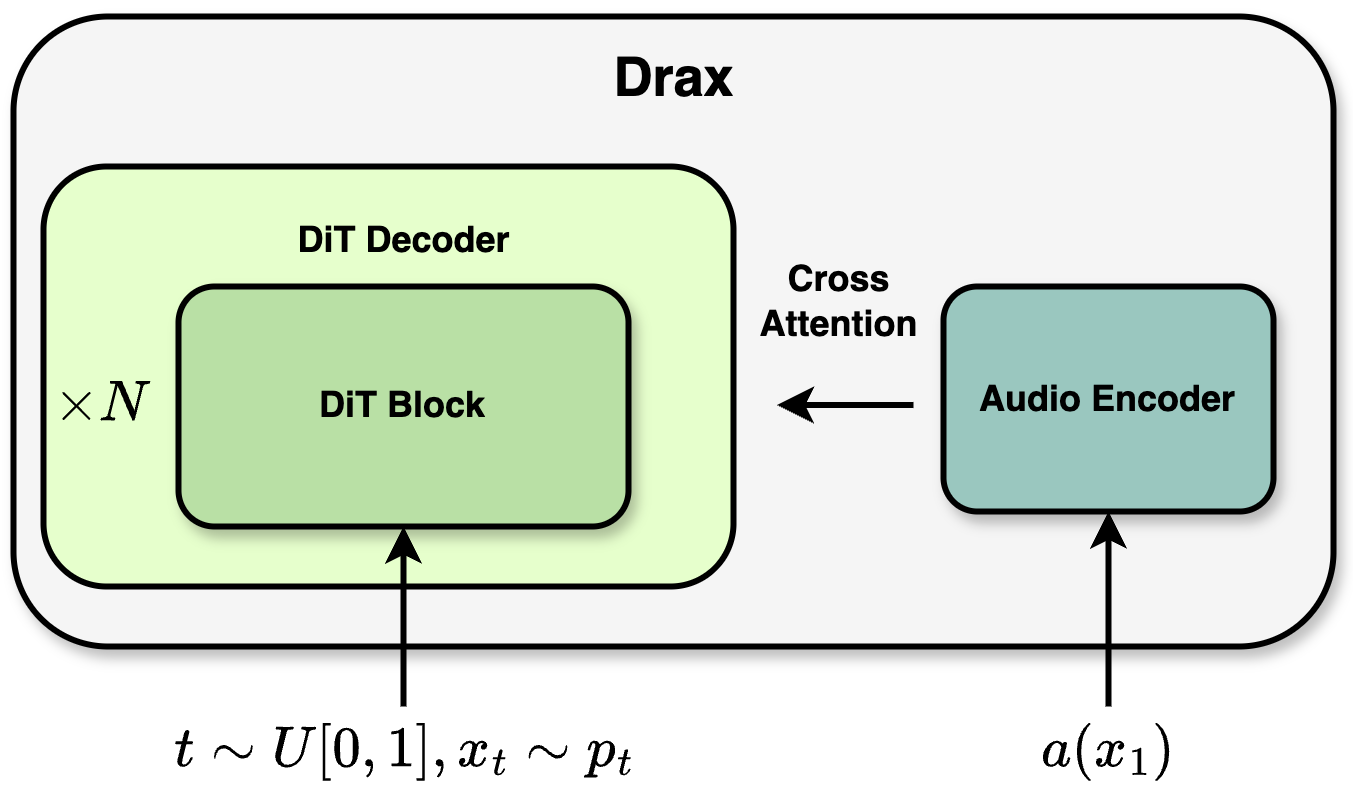
Figure 1: The Drax framework: (a) Training with a tri-mixture path (source, audio-conditioned middle, target); (b) Inference traverses plausible intermediate hypotheses; (c) Architecture combines a Whisper encoder with a DiT-based decoder.
Model Architecture
Encoder: Pre-trained Whisper (large-v3) encoder, frozen during Drax training.
Decoder: DiT-based transformer with cross-attention to audio representations at each block.
Main Loss: Cross-entropy over the conditional DFM path, using Gumbel-Softmax reparameterization for differentiable sampling.
Auxiliary Loss: Cross-entropy on the middle distribution logits.
Total Loss: L(θ,ψ)=LCDFM(θ,ψ)+Lmid(ψ)
Inference and Sampling
Sampling: Integrate the learned velocity field along the probability path, in parallel for each token position.
Candidate Scoring: Multiple candidate transcriptions can be generated and scored via mode, minimum Bayes risk (MBR), external model rescoring (e.g., Whisper), or ELBO-based internal scoring.
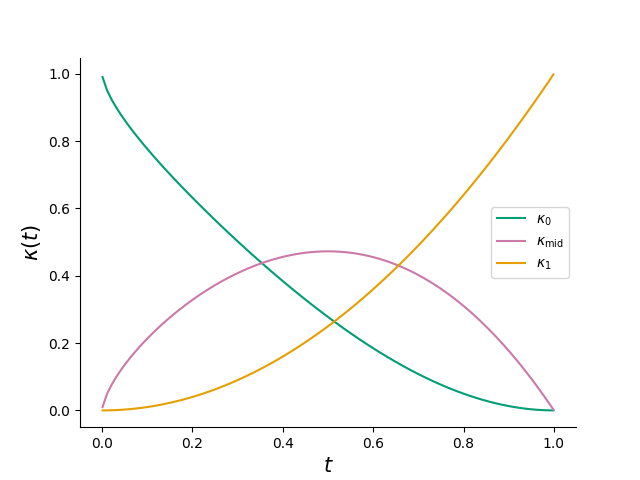
Figure 2: Tri-mixture sampling scheduler, showing the temporal dominance of the audio-conditioned middle distribution near the midpoint of the trajectory.
Theoretical Analysis
The generalization gap in DFM is bounded by the total variation (TV) distance between the training and inference occupancies, which is in turn controlled by the cumulative velocity error along the probability path:
∥qs−ps∥TV≤∫0sEx∼qtz=x∑∣Δt(x,z)∣dt
where Δt is the difference between the learned and target velocity fields. The tri-mixture path, by exposing the model to acoustically plausible intermediate states, reduces the divergence between training and inference distributions, tightening the generalization bound and improving robustness.
Empirical Results
Multilingual and English Benchmarks
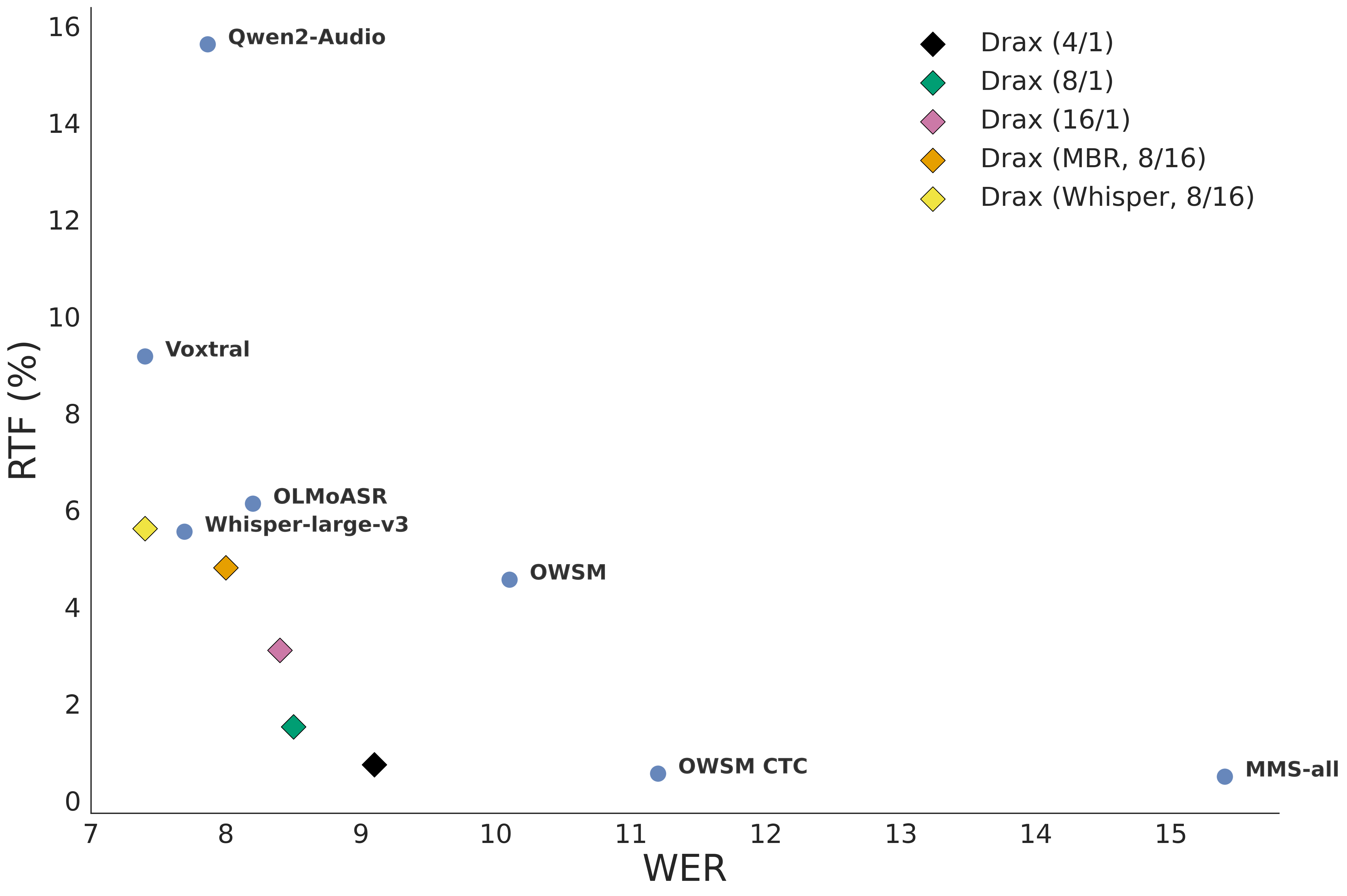
Drax is evaluated on a suite of public ASR benchmarks spanning multiple languages and domains. It achieves recognition accuracy on par with or surpassing strong AR and CTC baselines, including Whisper, Qwen2-Audio, and Voxtral, across both English and multilingual datasets.
Accuracy-Efficiency Trade-off
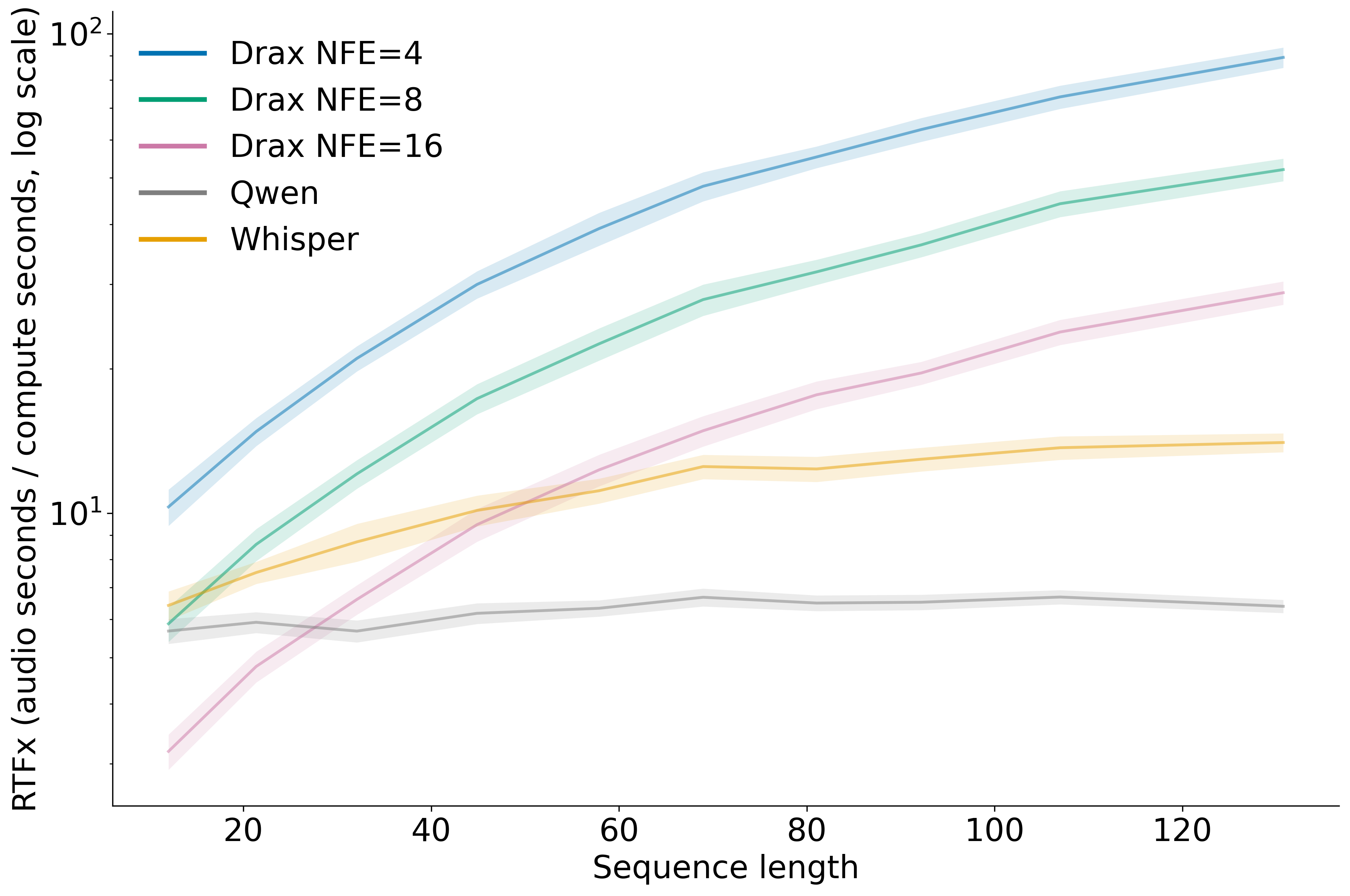
Drax enables explicit control over the accuracy-efficiency trade-off via the number of function evaluations (NFE) and candidate set size. Increasing NFE improves WER, while lower NFE yields faster decoding. Drax demonstrates favorable scaling with respect to sequence length, outperforming AR models in runtime efficiency.
Figure 3: RTFx (real-time factor inverse) as a function of sequence length, demonstrating Drax's superior scaling compared to AR baselines.
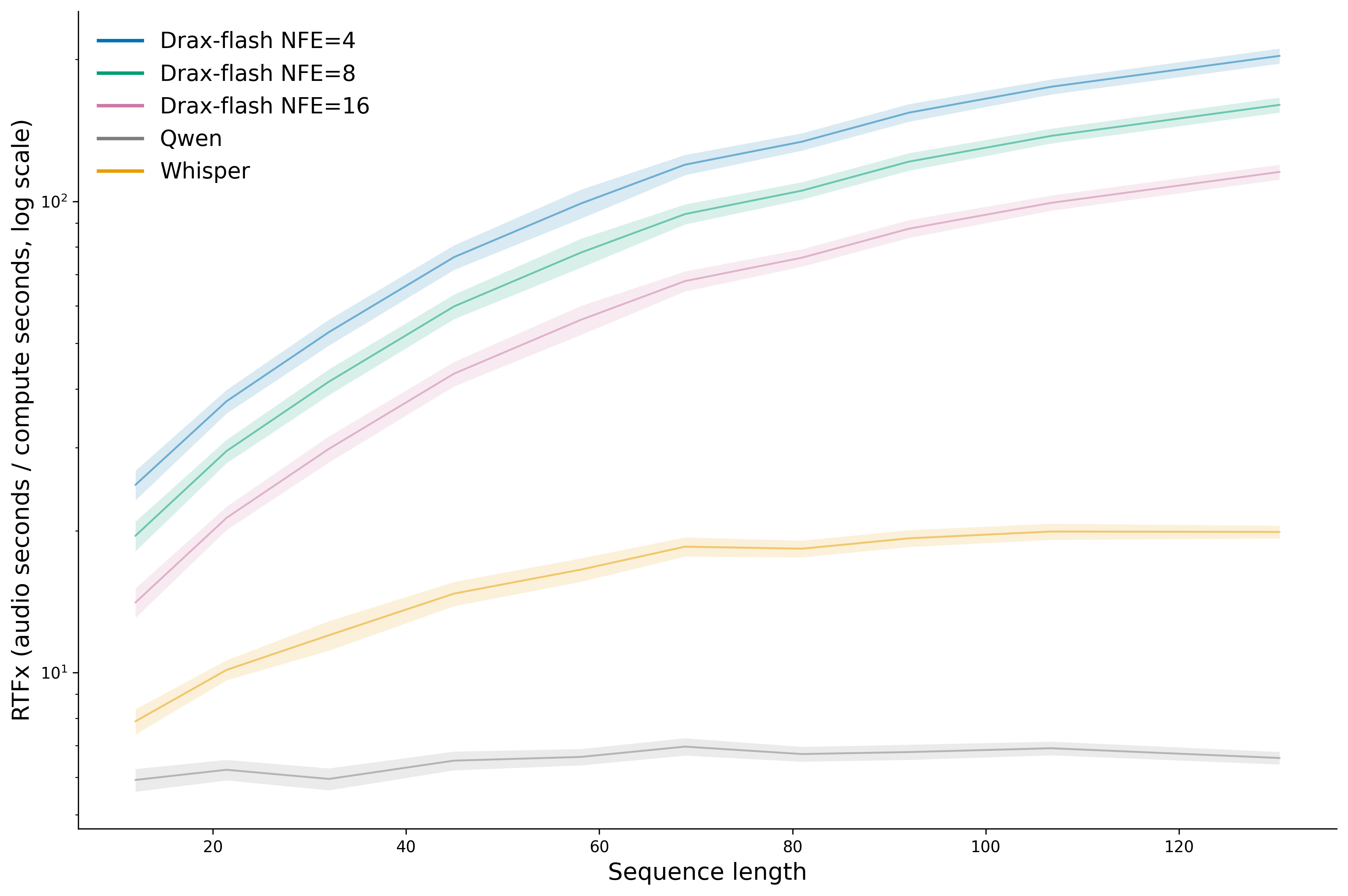
Figure 4: Runtime comparison for Drax-flash, highlighting substantial speedups over AR models.
Candidate Scoring and Speculative Decoding
Drax supports efficient candidate generation and scoring. MBR and Whisper-based rescoring yield further accuracy gains with minimal runtime overhead. In speculative decoding setups, Drax serves as a fast draft model, enabling blockwise parallel proposals and achieving higher throughput and more matched tokens than Whisper-Turbo.
Ablation and Path Design
Ablation studies confirm that the tri-mixture path with an audio-conditioned middle distribution yields the lowest WER and best generalization, compared to uniform or two-way mixture paths. Including the middle distribution only during training is critical; using it at inference degrades performance.
Implementation Considerations
Resource Requirements: Drax's main model (with a frozen Whisper encoder and DiT decoder) contains 1.2B parameters; the Drax-flash variant reduces decoder size for further efficiency.
Parallelism: All sampling steps are parallelizable across token positions, enabling high throughput on modern accelerators.
Scalability: Drax's efficiency advantage increases with sequence length, making it suitable for long-form transcription and low-latency applications.
Deployment: The model supports batch candidate generation and can be integrated into speculative decoding pipelines for further acceleration.
Limitations and Future Directions
Data Scale: Current experiments are on curated multilingual datasets; scaling to larger, more diverse corpora may reveal additional challenges.
Path Design: The tri-mixture path is one instantiation; adaptive or learned path constructions could further improve alignment between training and inference.
Candidate Selection: There remains a gap between the best scoring strategy and the oracle, indicating room for improved candidate selection mechanisms.
Conclusion
Drax demonstrates that discrete flow matching with a tri-mixture, audio-conditioned probability path is a viable and efficient alternative to AR ASR models. Theoretical analysis and empirical results validate the approach, showing competitive accuracy, superior runtime efficiency, and robust multilingual performance. Drax's design principles—exposing the model to plausible intermediate states and leveraging parallel decoding—provide a strong foundation for future research in non-autoregressive speech recognition.
“Emergent Mind helps me see which AI papers have caught fire online.”
Philip
Creator, AI Explained on YouTube
Sign up for free to explore the frontiers of research
Discover trending papers, chat with arXiv, and track the latest research shaping the future of science and technology.Discover trending papers, chat with arXiv, and more.