On-Policy Self-Distillation with Sampled Demonstrations Reduces Output Diversity
Abstract: On-policy self-distillation achieves strong pass@1 accuracy by using a single model as both teacher and student, with the teacher conditioned on a correct demonstration to provide dense token-level feedback. We show that this could come at a hidden cost: rollout diversity decreases and pass@k curves flatten (i.e., generating more rollouts fails to improve accuracy). We trace this to compounding biases in the design of self-distillation with sampled demonstrations. The teacher scores each student rollout while conditioned on a sampled correct rollout, channeling its feedback through the model's own biases. We theoretically analyze the optimal self-distillation policy and show that it tilts the base distribution by a pointwise conditional mutual information score between the student's rollout and the correct rollout used as context. Unlike the ideal optimal on-policy reinforcement learning (RL), which preserves probability ratios among equally correct rollouts, self-distillation can amplify existing probability gaps, concentrating mass on already-dominant modes. On a controlled graph path-finding task and science question-answering benchmarks, self-distilled models match or exceed RL on average performance but exhibit substantially lower functional and semantic diversity, failing on out-of-distribution settings that require diverse strategies.





Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper looks at a popular way to train LLMs called self-distillation with sampled demonstrations (SDSD). In simple terms, the model teaches itself: it shows itself one correct example and then learns to make its own answers more like what it would say if it had that example in front of it. The authors found a hidden downside: while this often boosts first-try accuracy (pass@1), it makes the model less varied in how it answers. So, if you ask the model to try multiple times (pass@k), extra attempts don’t help much—the curve flattens. They explain why this happens, prove it mathematically, and show it in experiments.
What the paper is asking
- Does self-distillation with demonstrations reduce the variety of solutions a model produces?
- Why does this happen? Can we explain it with a simple theory?
- How does this affect real tasks (like science questions) and special tests that need different strategies?
- Are common diversity measures (like token entropy) good enough to judge diversity?
- If we give the model more diverse examples to learn from, does that fix the problem?
How the methods work (in everyday terms)
Think of training like a student learning to solve problems:
- Reinforcement Learning (RL): A “verifier” checks each answer and gives a simple score (right or wrong). If the student gets an answer right—no matter how they arrived there—they get the same credit. This tends to support many different correct ways equally.
- Self-Distillation with Sampled Demonstrations (SDSD): The same model acts as the teacher and the student. Before training on a problem, the teacher is shown one correct example (a “demonstration”). The teacher then gives detailed hints for each word/token to guide the student’s answer to be more like what the teacher would say with that example in mind. This is like a student learning from one worked-out solution and then writing answers that look similar in style or structure.
Key idea: SDSD involves “double sampling.” For each problem, you sample:
- a student attempt, and
- one demonstration to show the teacher. If a student’s attempt looks more like the demonstration, the teacher reinforces it more. Over time, solutions that match common demonstrations get stronger, and unusual-but-correct solutions get weaker.
The theory in plain language
The authors show that the “best” policy for SDSD doesn’t just reward correct answers equally. Instead, it boosts answers that align well with the demonstration. They measure this alignment with something called pointwise conditional mutual information (PCMI). You can think of PCMI as an “alignment score” that says: “Given the example in the teacher’s context, how much more does the teacher like this answer than it normally would?” Answers that align more get pushed up more. This creates a “rich get richer” effect: already popular ways of answering become even more popular.
By contrast, in standard RL with a binary reward (right/wrong), two correct answers are treated equally. That helps keep multiple good strategies alive.
What they tested and how
The authors ran several experiments:
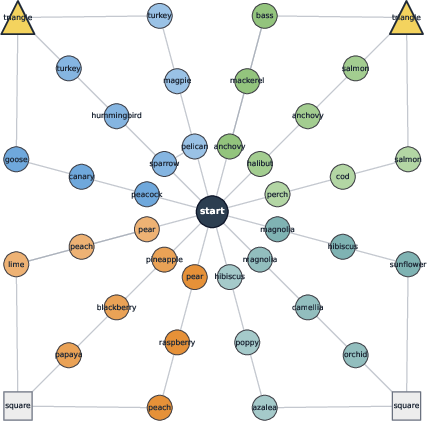
- A controlled “graph path-finding” task:
- Imagine a hub with multiple chains (paths) going out, each chain representing a concept (like birds, fruits, etc.). Two endpoints are the true target; others are distractors.
- There are multiple valid paths to the target, some shorter (easier) and some longer (harder).
- During training, it’s tempting for a model to rely on the easy path and ignore the others.
- They measured:
- Functional diversity: Does taking more samples (pass@k) solve more new problems? Steeper pass@k = more diverse and useful variety.
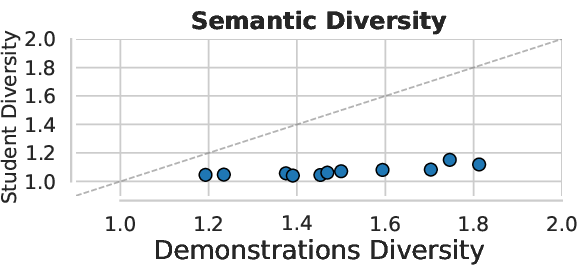
- Semantic diversity: Do answers use different high-level strategies (e.g., different concept chains), not just different wording?
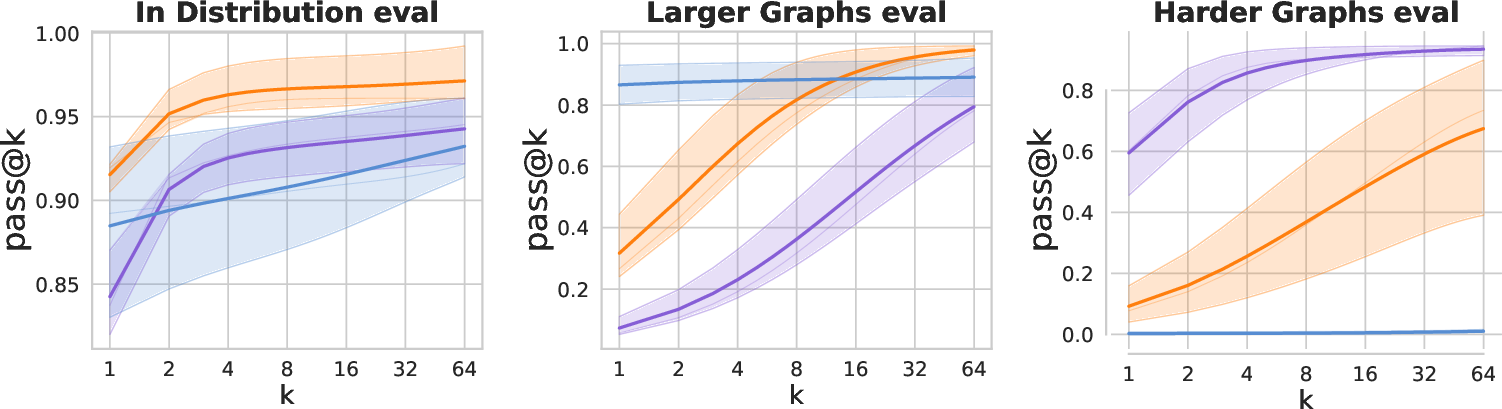
- They also tested out-of-distribution (OOD) cases: bigger graphs and a “harder” version where easy paths get blocked. These require having learned multiple strategies.
- Science question answering (from the SciKnowEval benchmark):
- Four subjects: Biology, Chemistry, Materials, Physics.
- They compared SDSD and RL (GRPO) on pass@1 and pass@k.
- They also tried a version of SDSD with multiple demonstrations () to see if more demos help.
- External demonstrations:
- They gave the teacher demonstrations from other models (some very diverse) to see if that would fix the diversity problem.
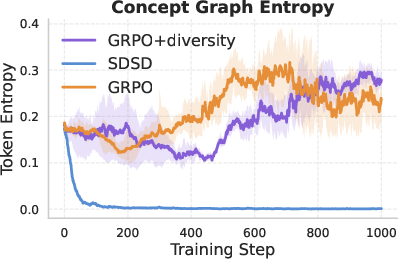
- Token-level entropy:
- This is a common “diversity” metric that measures how spread out the model’s next-word choices are. They checked whether this matches the more meaningful notions of functional or semantic diversity.
Main findings
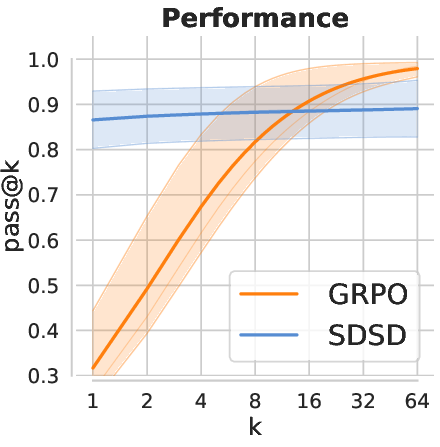
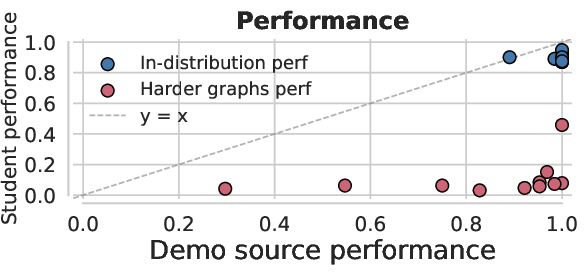
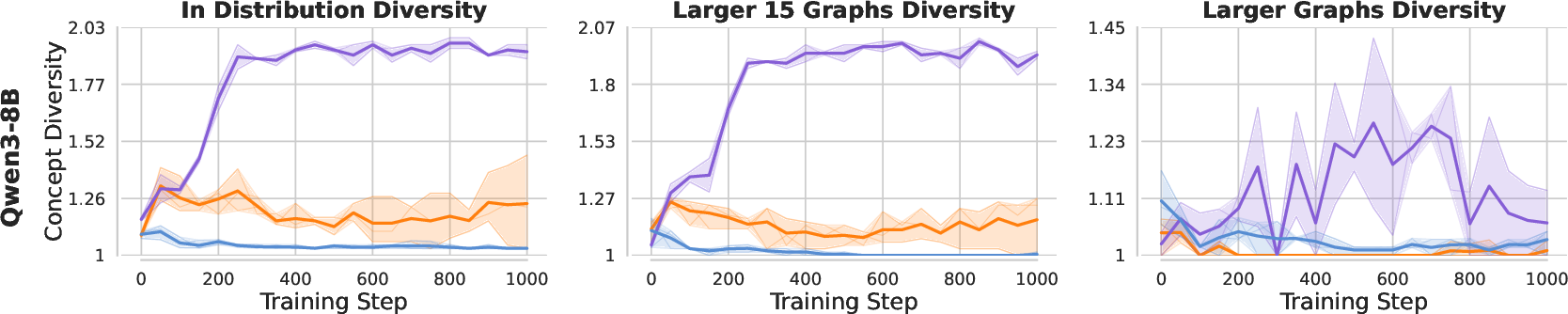
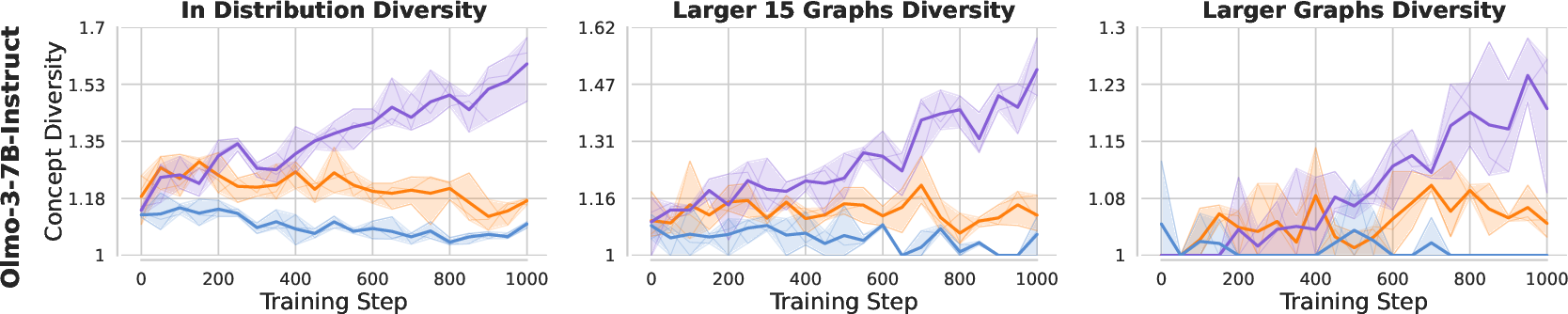
- High first-try accuracy, low variety:
- SDSD often gets strong pass@1.
- But its pass@k curves flatten quickly: extra samples don’t solve many new problems. That means low functional diversity.
- RL gives more coverage:
- RL (GRPO) usually has steeper pass@k curves. More samples = more different solutions = better chance to solve more problems.
- Fewer strategies learned:
- On the graph task, SDSD mainly learns the easy path and ignores alternative paths. It performs well in normal tests but fails on OOD and “harder” cases where a different strategy is needed. Its semantic diversity (number of distinct high-level strategies) is lowest.
- Theory matches practice:
- The math predicts that SDSD amplifies already-likely solutions that align with the demonstration. That’s exactly what the experiments show: a “rich-get-richer” sharpening and reduced variety.
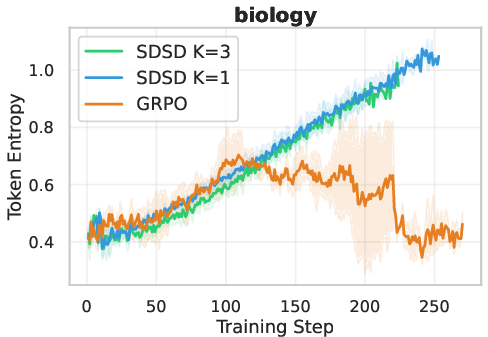
- Token entropy is not enough:
- Token-level entropy didn’t reliably reflect useful diversity. In some settings SDSD had lower entropy (as expected with fewer varied outputs), but in others it had higher entropy while still producing less diverse, less useful solutions. So entropy can be misleading.
- Diverse demos don’t fix it:
- Even when the teacher saw diverse external demonstrations, students trained with SDSD still collapsed to low diversity. The bias toward aligning with a sampled demonstration remained.
Why this matters
- If you rely on sampling multiple answers and picking the best (common in practice), you want variety. SDSD can reduce that variety, making extra samples less helpful and harming robustness on new or tougher problems.
- Training goals should include diversity:
- Don’t just track pass@1; also watch pass@k and measures of strategy-level variety (semantic diversity). Token entropy alone isn’t enough.
- Design choices matter:
- RL with simple right/wrong rewards tends to preserve multiple correct solutions better than SDSD with demonstrations.
- If you use self-distillation, consider ways to encourage diverse strategies (e.g., diversity-aware rewards or objectives that directly improve pass@k), or use feedback that is tied closely to the student’s specific attempt rather than a single demonstration.
- Big picture:
- The paper highlights a trade-off: methods like SDSD can quickly boost accuracy but risk narrowing the model’s thinking. For tasks that benefit from exploring different approaches—math, science, planning, coding—keeping solution diversity healthy is important for better generalization and reliability.
Knowledge Gaps
Unresolved gaps, limitations, and open questions
The paper surfaces important findings about diversity collapse under self-distillation with sampled demonstrations (SDSD), but several aspects remain uncertain or unexplored. Below is a concise list of concrete gaps that future work can address:
- Theory–practice mismatch: The optimal-policy analysis assumes a frozen teacher at the base policy and demonstrations drawn from a fixed reference distribution, while practical SDSD uses an EMA teacher and self-generated demonstrations. A formal analysis covering EMA dynamics and self-generated context distributions is missing.
- No formal treatment without explicit KL: The theoretical results assume explicit KL regularization to the base; many practical setups omit or implicitly rely on limited training. The sharpening behavior without explicit KL needs formal characterization.
- Token-level dynamics not fully characterized: Although an appendix claims analogous token-level results, there is no rigorous treatment of how the PCMI tilt compounds across long horizons with sampling, truncation, and temperature, especially under autoregressive decoding.
- Lack of empirical PCMI measurement: The theory hinges on expected pointwise conditional mutual information (PCMI), but PCMI is not estimated empirically to diagnose or predict diversity collapse across tasks or training phases.
- Hyperparameter sensitivity uncharted: Systematic ablations are absent for key knobs (KL strength, teacher and student temperatures, sampling strategies like top-k/top-p, number of rollouts N, and teacher-ensemble size K), leaving it unclear which regimes mitigate or worsen collapse.
- Limited teacher-ensemble exploration: Only K=3 context teachers are tested; scaling K, mixing teachers of different styles/strengths, or per-token mixtures are not explored to test whether broader teachers reduce PCMI-driven sharpening.
- Demonstration selection policy is underexplored: Demonstrations are sampled uniformly from correct rollouts; alternatives (e.g., inverse-probability or anti-alignment reweighting, stratified/orthogonal coverage sampling, curriculum-based selection) are not evaluated for diversity preservation.
- External demonstration diversity effects are only surface-level: While diverse external demonstrations still yield low student diversity, the causal mechanisms (e.g., PCMI alignment to dominant modes, teacher–student bias coupling) are not empirically dissected or controlled.
- Mitigation strategies within SDSD are not developed: Beyond teacher ensembling, there is no principled modification to the SDSD loss to counteract sharpening (e.g., PCMI balancing/penalties, diversity-aware weighting, pass@k-aware objectives, orthogonalization constraints, anti-collapse regularizers).
- Interaction with RL-style diversity interventions is unclear: The study compares to GRPO and GRPO+diversity, but does not test hybrid training (interleaving RL and SDSD), or SDSD augmented with explicit diversity rewards or coverage constraints.
- Inference-time sampling vs training-time bias: It remains unclear how pass@k flattening depends on inference sampling methods (temperature, top-k/p, diverse beam search). Controlled evaluations disentangling training-induced collapse from decoding choices are missing.
- Generalization breadth is narrow: Evidence for OOD harms is shown on a specific graph variant; broader tests (math with multiple proof styles, code with alternative algorithmic strategies, tool-use/agents, multimodal tasks) are needed to validate generality.
- Scale and compute effects are unknown: Experiments use 1.7B–8B models with modest training budgets; whether diversity collapse persists, attenuates, or worsens at larger scales, longer training, or larger rollout groups is not established.
- Verifier noise and imperfect correctness: All analyses assume perfectly correct demonstrations. The impact of noisy verifiers, partially-correct demonstrations, or conflicting signals on SDSD diversity and stability is untested.
- Safety, bias, and style concentration: Sharpening toward canonical modes may entrench stylistic or sociocultural biases and reduce stylistic diversity; these downstream risks are not measured.
- Diversity metrics beyond toy settings: Semantic diversity is precisely defined only in the graph domain. For naturalistic QA and reasoning, operational and scalable semantic diversity metrics (beyond pass@k and token entropy) are not provided.
- Causal link between semantic diversity and OOD performance: While shown in the graph task, the causal relationship is not tested in QA or other domains using controlled interventions on strategy coverage.
- Mode-forgetting dynamics unmeasured: The time course of minority-mode suppression (e.g., when during training collapse occurs, and whether it is reversible) is not quantified.
- Convergence and stability analysis: Conditions under which SDSD admits unique/non-unique fixed points, and when mode collapse is inevitable vs avoidable, are not established.
- Decomposition of alignment: The paper posits alignment on “structural or stylistic features,” but does not disentangle whether PCMI favors semantics (strategy) or surface style; controlled experiments to separate these components are absent.
- Role of privileged signals aligned per rollout: SDSD variants using rollout-specific privileged information (e.g., runtime error traces) might reduce misalignment; whether these signals preserve diversity is not evaluated.
- Comparative baselines are incomplete: Methods intended to alleviate self-distillation gaps (e.g., RLSD-style gradient-direction fixes, HDPO, DPO/RLHF variants, best-of-N-aware training) are cited but not empirically compared as potential diversity-preserving alternatives.
- Demonstration content and length effects: The impact of demonstration length, formatting, rationale detail, and locality of relevance on PCMI and diversity collapse is not studied.
- Constraints and coverage objectives: Maintaining probability ratios among equally correct rollouts (as in RL optimum) via constrained optimization or maximum-entropy regularization is not explored.
- Compute/performance trade-offs: SDSD’s dense token-level loss is compute-efficient early on but may induce long-term diversity costs; a quantitative analysis of compute vs diversity/accuracy trade-offs is not provided.
- Cross-task interference in multi-task training: Whether SDSD-induced sharpening on one task suppresses alternative strategies needed for others (negative transfer) is not investigated.
- Horizon effects: The hypothesized compounding loss of diversity with trajectory length is not quantified across tasks with different reasoning horizons.
Practical Applications
Immediate Applications
Below are practical, deployable uses that leverage the paper’s findings on how self-distillation with sampled demonstrations (SDSD) flattens pass@k and reduces semantic/functional diversity compared to on-policy RL (e.g., GRPO). Each item notes likely sectors, tools/workflows that might emerge, and key assumptions.
- Deploy diversity-aware evaluation in LLM MLOps
- Add pass@k curves (functional diversity) and domain-level “semantic diversity” dashboards to model evaluation; treat token entropy as insufficient.
- Tools/workflows: sampling pipelines that generate N outputs per prompt, compute pass@k, cluster strategies (e.g., embedding-based clustering for code/math, concept taxonomies).
- Assumptions/dependencies: ability to sample multiple outputs per query; availability of domain-specific diversity proxies. (Sectors: software/ML platforms, QA/benchmarking, safety)
- Choose training method to match deployment (single-shot vs best-of-N)
- If the product will rely on multiple attempts or reranking (best-of-N), prefer RL (e.g., GRPO) over SDSD due to stronger pass@k scaling; if strictly single-shot and latency-sensitive, SDSD can be viable for higher pass@1.
- Tools/workflows: policy for “training–deployment alignment” decided at project start.
- Assumptions/dependencies: existence of verifiable rewards for RL; compute budget for on-policy sampling. (Sectors: code assistants, planning agents, search, customer support)
- Hybrid post-training: warm-start with SDSD, then switch to RL (with diversity bonus)
- Use SDSD briefly to lift pass@1 quickly, then fine-tune with GRPO (or similar) augmented with a group-wise diversity reward to recover coverage.
- Tools/workflows: two-phase schedule; early stopping on flattening pass@k.
- Assumptions/dependencies: infrastructure to run both SDSD and RL; verifiers for RL. (Sectors: general-purpose LLMs, enterprise AI platforms)
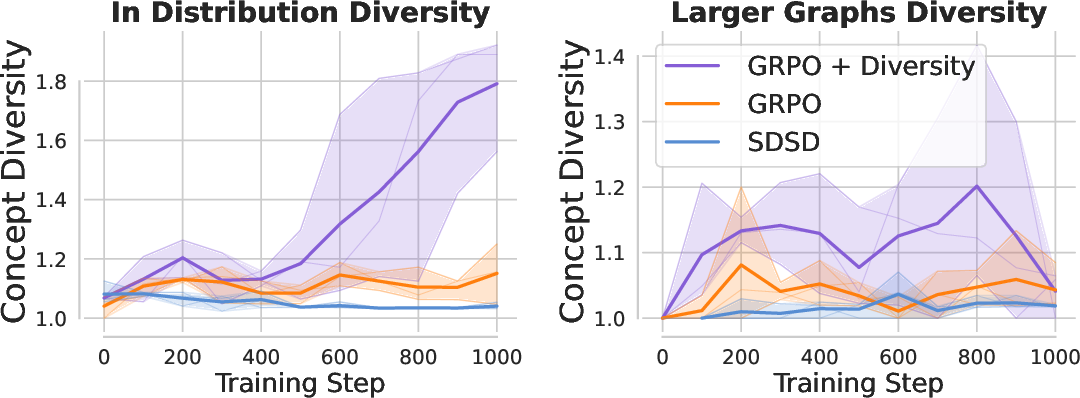
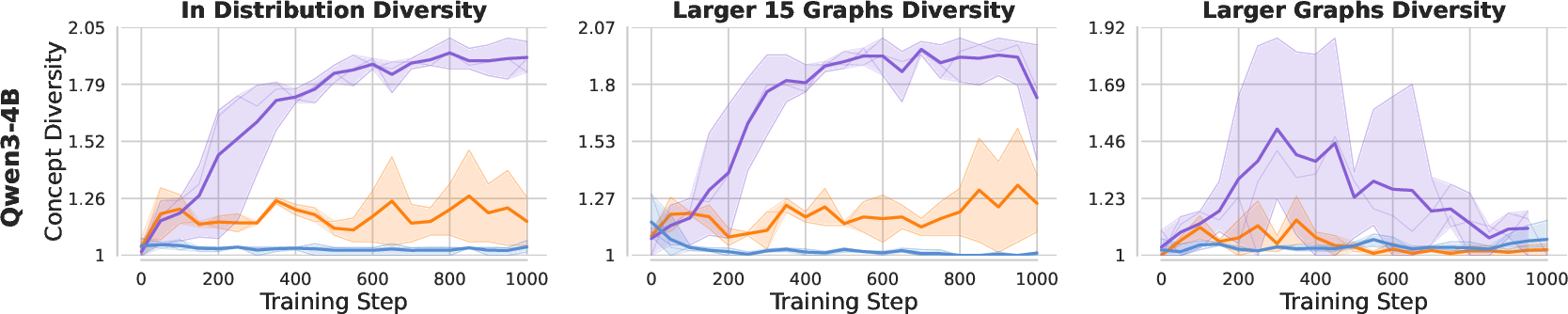
- Add diversity bonuses during RL
- Incorporate group-level dissimilarity bonuses (e.g., embedding or concept-based diversity) into advantage calculations, as shown to increase semantic diversity and OOD performance in the paper’s graph task.
- Tools/workflows: rollout clustering within a prompt, reward shaping, DARLING-style clustering multipliers.
- Assumptions/dependencies: domain-appropriate diversity metric; careful balance to avoid harming correctness. (Sectors: education/tutoring, math/science QA, creative writing)
- Cautious use of SDSD teacher ensembles and multiple demonstrations
- If using SDSD, condition teachers on multiple distinct correct demonstrations (K>1) per example to moderate—but not eliminate—the alignment bias; expect only partial mitigation of pass@k flattening.
- Tools/workflows: multi-teacher averaging, deduping teacher contexts, context selection.
- Assumptions/dependencies: extra compute for multiple teacher passes; sufficient correct demonstrations. (Sectors: model training frameworks)
- Demonstration curation policies that avoid canonical-only bias
- Ensure demonstrations cover diverse solution strategies during curation to avoid over-reinforcing “canonical” approaches, while recognizing (per paper) that diverse external demos alone do not fix SDSD’s diversity collapse.
- Tools/workflows: demo coverage audits, strategy taxonomy labels, stratified sampling.
- Assumptions/dependencies: human-in-the-loop tagging of strategies; domain expertise. (Sectors: data engineering, education, software)
- Inference-time coverage for SDSD-trained models
- For SDSD-trained models in multi-sample products, force diversity at inference: diverse beam search, repetition/embedding penalties, temperature/Top-p sampling, dissimilarity constraints across N, followed by verifier/reranker selection.
- Tools/workflows: “generate–diversify–rerank” pipelines; ROC curves for coverage.
- Assumptions/dependencies: access to a verifier or heuristic scorer; compute for multiple samples. (Sectors: coding agents, scientific QA, content generation)
- OOD challenge suites for robustness gating
- Include OOD tests that require alternate strategies (e.g., modified constraints, longer plans) in CI to catch diversity collapse before deployment.
- Tools/workflows: curated “hard mode” test sets; automated regression checks on pass@k slopes.
- Assumptions/dependencies: domain-tailored OOD tasks; monitoring infrastructure. (Sectors: robotics/planning, finance risk, healthcare CDS)
- Procurement and model-card requirements for diversity
- Require pass@k reporting, semantic diversity analyses, and OOD performance disclosures alongside pass@1 in model evaluations and vendor SLAs.
- Tools/workflows: standardized reporting templates; acceptance thresholds for coverage.
- Assumptions/dependencies: organizational policy adoption. (Sectors: public sector, regulated industries)
- Practical user guidance for multi-try tasks
- For assistants used by end-users in creativity or problem-solving, expose a “generate diverse alternatives” button and instruct users to prefer multi-try modes for tasks that benefit from exploration.
- Tools/workflows: UI affordances for parallel candidates and reranking.
- Assumptions/dependencies: product UI capacity to present multiple options. (Sectors: productivity apps, education, marketing)
Long-Term Applications
These items require further research, scaling, or productization to realize the benefits implied by the paper’s PCMI-based analysis and empirical findings.
- PCMI-aware objective redesign to counter sharpening
- Develop self-distillation variants that explicitly penalize reliance on demonstration similarity (PCMI tilt), preserving probability ratios among equally correct rollouts (an RL property).
- Tools/workflows: anti-tilt regularizers, contrastive losses that upweight less-aligned but correct rollouts, importance reweighting for underrepresented modes.
- Assumptions/dependencies: theoretical guarantees and stable training recipes. (Sectors: core LLM training, foundation model labs)
- Pass@k-aware and coverage-optimized training objectives
- Train models to maximize coverage across N samples—e.g., best-of-N–aware losses, coverage sets, or submodular selection objectives—so that pass@k improves steeply.
- Tools/workflows: inference-aware training; curriculum over N; mixture-of-experts selecting complementary rollouts.
- Assumptions/dependencies: differentiable or estimable coverage proxies; compute. (Sectors: code/genAI platforms, planning agents)
- Teacher design beyond single sampled demonstrations
- Replace single-demo conditioning with learned mixtures, marginalization over demo sets, or adversarially diverse teachers that encourage multiple valid strategies.
- Tools/workflows: multi-context conditioning, learned demo selectors, self-play between teacher and student modes.
- Assumptions/dependencies: scalable teacher architectures; robust optimization. (Sectors: LLM research)
- Rare-mode amplification via data and sampling policies
- Rebalance training by oversampling rare-but-correct strategies; adaptive demo sampling that prioritizes underrepresented solution families.
- Tools/workflows: strategy taxonomy mining; active data selection; replay buffers indexed by strategy.
- Assumptions/dependencies: high-quality labels for strategy families; data engineering overhead. (Sectors: education, legal, healthcare)
- Domain-specific semantic diversity estimators
- Build reliable, automatable measures of “strategy-level” diversity (e.g., proof types in math, architectural patterns in code, path classes in robotics) to guide training and evaluation.
- Tools/workflows: template/graph extractors, code AST analyzers, theorem/technique taggers.
- Assumptions/dependencies: domain ontologies; gold annotations for calibration. (Sectors: education, software, robotics)
- Benchmarks and standards for diversity and OOD robustness
- Establish cross-sector benchmarks akin to the paper’s concept-graph tasks, emphasizing multiple valid strategies and OOD shifts; integrate into model certifications.
- Tools/workflows: public datasets with controlled structure; test harnesses.
- Assumptions/dependencies: community adoption; governance. (Sectors: standards bodies, regulators)
- Multi-agent and ensemble orchestration for coverage
- Run ensembles of differently trained models (e.g., RL vs SDSD, or varying diversity penalties) with orchestrators that enforce dissimilarity and select best candidates via verifiers.
- Tools/workflows: ensemble schedulers, deduplication, cross-model rerankers.
- Assumptions/dependencies: inference cost budgets; reliable verifiers. (Sectors: finance risk analysis, legal argument generation, scientific discovery)
- Sector-specific workflows that depend on diversity
- Healthcare: multiple differential diagnoses and treatment plans, with verification and clinician-in-the-loop selection; training to favor coverage over single-shot confidence.
- Finance: scenario generation across regimes for stress testing; diversity metrics ensure non-canonical strategies are represented.
- Robotics/planning: maintaining alternative path topologies and contingency plans to improve mission robustness.
- Education: tutors that present distinct solution pathways to foster understanding and transfer.
- Tools/workflows: best-of-N pipelines, adjudication/verifier integration, audit trails.
- Assumptions/dependencies: strong verifiers/humans-in-the-loop; risk and compliance processes.
- Diversity-aware early stopping and training governance
- Monitor pass@k slopes and semantic diversity during training; stop or switch objectives when diversity collapses despite rising pass@1.
- Tools/workflows: training governance dashboards, auto-switch policies to RL/diversity-boost phases.
- Assumptions/dependencies: reliable on-the-fly metrics; organizational practices.
- Theoretical extensions to practical SDSD variants
- Extend PCMI analysis to EMA teachers and token-level dynamics to derive sufficiency conditions that prevent sharpening; formalize guarantees for hybrid methods.
- Tools/workflows: open-source reference implementations and proofs.
- Assumptions/dependencies: community validation; reproducibility.
- Policy and compliance frameworks for diversity-sensitive deployments
- For domains where missing alternative strategies is risky, require evidence of output diversity and OOD robustness during model approval and periodic audits.
- Tools/workflows: compliance checklists, third-party audits, incident reporting tied to diversity failures.
- Assumptions/dependencies: regulatory alignment; sector-specific risk thresholds. (Sectors: healthcare, finance, public sector)
These applications flow directly from the paper’s core findings: SDSD improves pass@1 but can collapse output diversity via a PCMI-driven “sharpening” of already-dominant modes; RL yields steeper pass@k; token entropy alone is not a reliable diversity signal; and external demonstrations do not, by themselves, fix SDSD’s diversity collapse.
Glossary
- advantage: In policy-gradient RL, a baseline-adjusted measure of how much better a sampled trajectory is than expected. "Within each group of N rollouts, a scalar reward is used to compute a scalar advantage for the whole sequence."
- autoregressively: A generation process that produces each token conditioned on all previous tokens. "causing the effect to compound autoregressively along a trajectory"
- base policy: The initial reference policy distribution from which training starts and to which regularization often constrains updates. "The optimal RL policy consists of the base policy modulated by the reward."
- best-of-N fine-tuning: A training strategy that selects the best sample among multiple candidates per input and fine-tunes accordingly. "and best-of-N fine-tuning~\citep{chow2025_best_n_inferenceaware} that directly optimize for output coverage."
- diversity reward: An auxiliary reward added to encourage different strategies or outputs across samples. "GRPO+diversity adds a diversity reward to the score reward to encourage the model to explore different concept chains across its rollouts."
- exponential moving average (EMA): A parameter-averaging technique that maintains a smoothed teacher by exponentially weighting recent student parameters more. "The teacher is an exponential moving average (EMA) of the student"
- functional diversity: The extent to which additional samples solve new instances, typically reflected in the slope of pass@k curves. "Functional diversity is the rate at which additional samples solve new problems, reflected in the slope of pass@k curves."
- GRPO: An on-policy reinforcement learning algorithm used for LLM post-training that serves as a baseline in the paper. "models trained with on-policy RL (e.g., GRPO) show steep pass@k improvement"
- KL divergence: A measure of dissimilarity between probability distributions, used here for token-level distillation. "The training objective minimizes the token-level KL divergence between the student and this context-conditioned teacher:"
- KL regularization: A penalty that keeps the learned policy close to a reference (base) policy by adding a KL term to the loss. "All models add to the main loss a KL regularization to the reference model."
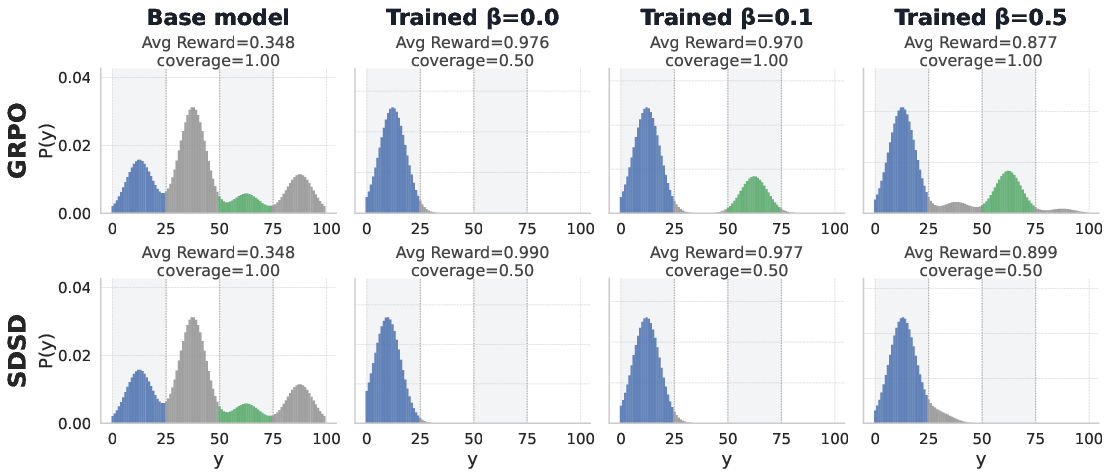
- mode collapse: A failure mode where a model concentrates probability mass on a small number of modes, reducing diversity. "Illustrative Example: Mode Collapse Under Self-Distillation"
- mode-seeking: A tendency of objectives like reverse KL to focus on high-probability modes, often reducing diversity. "Any on-policy method exhibits mode-seeking behavior concentrating its rollouts into a smaller subset"
- on-policy: A training regime where data is generated by the current policy being optimized. "Any on-policy method exhibits mode-seeking behavior"
- out-of-distribution (OOD): Inputs that differ from the training distribution, used to test generalization. "failing on out-of-distribution settings that require diverse strategies."
- pass@k: The probability (or accuracy) that at least one of k generated samples solves the task. "pass@k curves flatten (i.e., generating more rollouts fails to improve accuracy)."
- pointwise conditional mutual information (PCMI): A log-ratio score quantifying how much a demonstration increases the model’s preference for a rollout. "pointwise conditional mutual information (PCMI) between a student rollout and the sampled demonstration."
- privileged information: Additional context (e.g., a correct solution) available to the teacher during training but not at inference for the student. "the same model, conditioned on privileged information, such as a correct solution or environmental feedback"
- reverse KL: The Kullback–Leibler divergence in the direction KL(student || teacher), known to be mode-seeking. "SDSD as a reverse KL objective~\citep{bishop2006pattern} has the same behavior"
- rich-get-richer: A feedback loop in which already likely outputs are reinforced to become even more likely. "This leads to a rich-get-richer (likely-get-likelier)"
- rollout: A full generated sequence sampled from a policy, often used for evaluation and training signals. "rollout diversity decreases and pass@k curves flatten"
- SDSD (Self-Distillation with Sampled Demonstrations): A self-distillation setup where the teacher is conditioned on sampled correct demonstrations to guide the student. "Self-Distillation with Sampled Demonstrations (SDSD) where student rollouts are guided by a teacher with demonstrations in its context."
- SDPO: A specific self-distillation method that conditions the teacher on privileged signals or student demonstrations. "SDPO-style self-distillation \citep{sdpo} where the teacher is the base model conditioned on one correct student rollout."
- semantic diversity: Diversity in high-level strategies or concepts across solutions, beyond superficial token variation. "Semantic diversity measures whether rollouts differ in their high-level strategy (e.g., different paths through a graph, different proof approaches in math) rather than just surface-level wording."
- stop-gradient: An operation that prevents gradients from flowing through a tensor during backpropagation. "where denotes stop-gradient."
- tilted distribution: A reweighted version of a base distribution using an exponential factor determined by a score (e.g., reward or PCMI). "The resulting policy is a tilted version of the base distribution"
- token-level entropy: The entropy of next-token distributions, often used as a proxy for uncertainty or diversity. "token-level entropy fails to capture either notion (\S\ref{sec:entropy})."
- verifier: An automatic checker that provides correctness feedback (e.g., binary reward) for generated outputs. "A binary verifier gives equal reward to all correct rollouts"
Collections
Sign up for free to add this paper to one or more collections.