MJEPA: A Simple and Scalable Joint-Embedding Predictive Architecture for Audio-Visual Learning
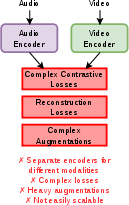
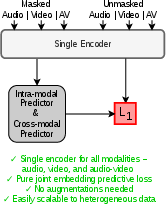
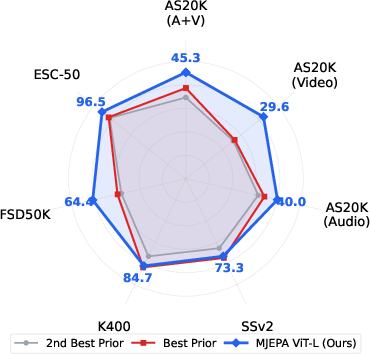
Abstract: Self-supervised learning from large-scale video data has emerged as a dominant paradigm for visual representation learning. Since audio and visual streams naturally co-occur in video data, extending this success to jointly learn from both modalities is a natural next step, yet it remains challenging. Existing audio-visual self-supervised methods rely on modality-specific encoders and complex combinations of contrastive or reconstruction objectives, limiting cross-modal synergy and scalability. Joint Embedding Predictive Architectures (JEPAs) offer a simple, modality-agnostic alternative, but have to date been applied primarily to individual modalities. We introduce MJEPA, a joint-embedding predictive architecture for audio-visual learning that uses a single, unified encoder for both modalities. Our approach uses only a single predictive objective, applied both within and across modalities. We show that cross-modal prediction is critical: without it, a shared encoder degrades below unimodal baselines; with it, each modality's representation benefits from the other. Our frozen ViT-g model outperforms the best prior frozen baseline by over 6.8 mAP on AudioSet-20K, surpasses fully finetuned models on ESC-50 and FSD50K, and is competitive on video benchmarks despite using 10x less video data.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
MJEPA: A simple explanation for teens
What is this paper about?
This paper introduces MJEPA, a new way for computers to learn from videos and their sounds at the same time without needing labels. The big idea is to use one shared “brain” (a single model) to understand both pictures (video) and sounds (audio) together, using a simple learning goal. This makes the model easier to train and scale, and it ends up learning better, more general skills.
What questions did the researchers ask?
- Can one shared model learn good features for both sound and video instead of using two separate models?
- Is it enough to learn within each type (audio with audio, video with video), or do we need to make the model also predict across types (audio ↔ video)?
- If we add more data or make the model bigger, does this simple approach keep getting better?
How does MJEPA work (in everyday language)?
Imagine a puzzle game:
- You take a full picture (the “target”), and a version with some pieces missing (the “context”).
- The model looks at the context and learns to predict what the hidden parts of the target should look like—but not at the pixel level. Instead, it guesses the “summary” of the hidden parts (their meaning or pattern), which helps it learn useful, high-level features.
MJEPA brings this puzzle game to both sound and video:
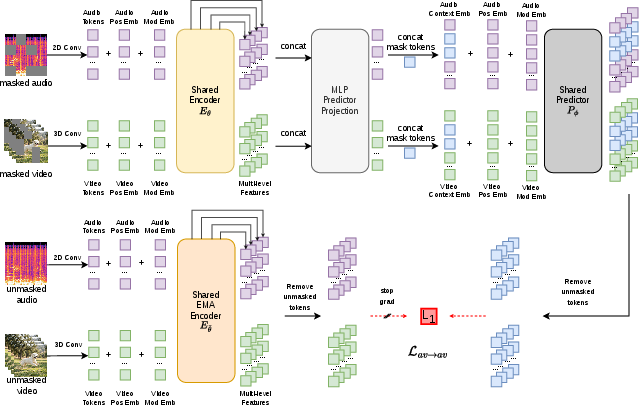
- The model turns short chunks of sound (audio spectrograms) and frames of video into tokens (think small tiles).
- It masks (hides) some tokens and learns to predict the missing pieces in a shared, abstract space (a space of “representations,” like summaries that capture meaning rather than raw details).
Here are the two kinds of predictions it learns:
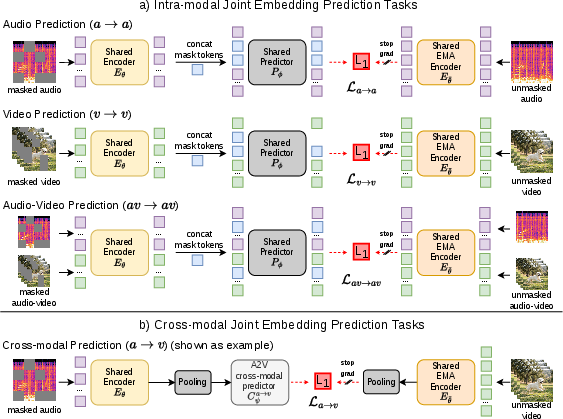
- Intra-modal prediction: predict missing audio from visible audio, and missing video from visible video (learning within the same type).
- Cross-modal prediction: predict a summary of the video from the audio, and predict a summary of the audio from the video (learning across types). This pushes the model to align what it “knows” about sound with what it “knows” about vision.
Two important design choices make this work:
- A single shared encoder: the same model processes audio, video, or both together, so everything lives in one common space.
- A simple training rule (JEPA): no contrastive tricks, no pixel-level reconstruction, no heavy data augmentations—just predicting representations of the missing parts.
Finally, the team “freezes” the learned model and evaluates it by training a tiny add-on (a light probe) for new tasks. This checks how generally useful the learned features are, not how well the whole model can be fine-tuned to one task.
Some helpful plain-language definitions
- Self-supervised learning: learning by making your own training tasks from the data (like predicting hidden parts), no human labels needed.
- Encoder: the part of the model that turns raw audio/video into compact summaries (representations).
- Representation: a learned summary that captures meaning (e.g., “dog barking” sound, “person running” video) rather than raw pixels or waveforms.
- Masking: hiding parts of the input so the model has to guess them.
- Cross-modal: connecting two different types of data, like sound and video.
- Frozen evaluation: keep the big model’s weights fixed; only train a small head on top to test how good the learned features are.
What did they actually do?
The researchers built up MJEPA step by step to see what matters:
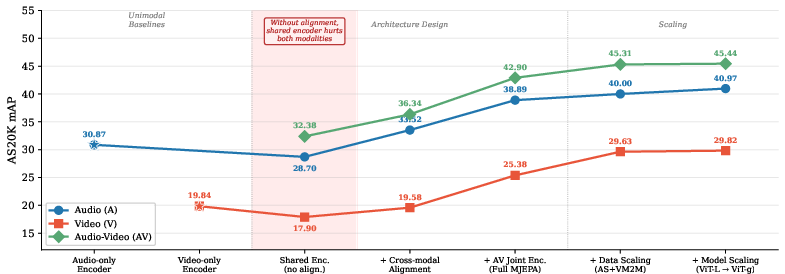
- Baseline: Train separate audio-only and video-only models. These work fine on their own.
- Shared encoder without cross-modal prediction: One model handles both audio and video, but only learns within each type. Result: both audio and video performance get worse—sharing alone causes conflicts.
- Add cross-modal prediction: Make the model predict audio from video and video from audio (high-level summaries). Result: both audio and video improve—cross-modal learning fixes the conflict.
- Joint audio+video inputs: Let the model sometimes see both at once. Result: another big boost.
- Scale up: Add more video-only data and use a bigger model (up to 1 billion parameters). Result: more gains across the board.
What were the main results and why do they matter?
- Cross-modal prediction is critical. Sharing one model without aligning audio and video hurts performance. Adding cross-modal prediction makes the two modalities help each other.
- Stronger than previous methods with a simpler recipe. With the model kept frozen:
- On AudioSet-20K (an audio-visual benchmark), MJEPA beat the best previous frozen features by over 6.8 mAP and did very well when using audio-only or video-only too.
- On audio benchmarks ESC-50 and FSD50K, MJEPA’s frozen features even surpassed some fully fine-tuned models.
- On video benchmarks (Kinetics-400 and Something-Something v2), MJEPA was competitive with top video-only methods despite using about 10× less video data, thanks to learning from audio+video together.
- Scaling helps. Adding extra video-only data improved not only video performance but also audio performance—evidence of positive transfer from one modality to the other. Making the model bigger helped too.
Why is this important?
- It’s simpler and more scalable. One unified model, one simple learning rule, and no complicated losses or augmentations. Easier to train and extend.
- It learns general skills. Because it performs well even when frozen, it’s a strong “feature extractor” you can reuse for many tasks.
- It saves data and compute for video. Audio helps teach the model about video and vice versa, letting you reach strong performance with less data.
- It points to a unified future. The same idea could extend beyond audio and video to other types of data—like text, sensors in robots, or medical images—so one model can understand many kinds of inputs and handle missing pieces gracefully.
In one sentence
MJEPA shows that teaching a single model to predict and align high-level summaries across sound and video—using a simple, label-free training game—creates powerful, reusable features that outperform more complicated methods and scale naturally with more data and bigger models.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The paper leaves the following concrete gaps and unresolved questions that future work could address:
- Cross-modal alignment design space:
- The cross-modal predictor is a simple MLP on global mean-pooled last-layer features; the paper does not explore alternative mechanisms (e.g., token-level alignment, cross-attention bridges, shared adapters, or contrastive/predictive hybrids) or quantify whether richer predictors improve alignment or transfer.
- Only last-layer alignment is used; the utility of multi-layer or hierarchical cross-modal alignment is untested.
- Loss formulation and weighting:
- All nine objectives are combined with equal weights; no ablation of loss weights, curriculum/scheduling, or adaptive weighting (e.g., uncertainty weighting) is provided to understand trade-offs between intra- and cross-modal terms.
- The necessity and marginal contribution of each cross-modal direction (a↔v, a↔av, v↔av) is not quantified.
- Temporal alignment and robustness:
- The method assumes paired, synchronous audio-video for cross-modal prediction; robustness to temporal misalignment, dubbing, or unrelated audio/video is not evaluated.
- No study of sensitivity to controlled desynchronization, noise corruption, or modality dropout during training and inference.
- Data mixture and scaling strategy:
- Only video-only data are added for scaling; the impact of adding large-scale audio-only data, or varying the ratio of paired vs. unpaired samples, is not explored.
- The optimal sampling/mixing policy across modalities and datasets (e.g., compute allocation, curriculum across sources) remains unspecified.
- Input tokenization and masking choices:
- Audio and video use separate projection layers and modality embeddings; the effect of these design choices (vs. fully shared tokenization, shared positional encodings, or alternative patch/tubelet sizes) on transfer and alignment is not ablated.
- Mask ratios/shapes per modality and their impact on cross-modal synergy are not studied.
- Fusion at inference:
- Audio-video fusion is implemented by token concatenation; alternative fusion strategies (e.g., learned cross-modal attention, gating, late fusion) and their impact on downstream tasks are not compared.
- Generalization beyond studied tasks:
- Evaluation focuses on classification; capabilities for localization, temporal detection, dense prediction (e.g., segmentation), source separation, audio-visual event localization, and synchronization are untested.
- Zero-shot or few-shot cross-modal retrieval and transfer are mentioned only in supplement; comprehensive, standardized cross-modal retrieval benchmarks are not reported in the main text.
- Domain and task breadth:
- Generalization to speech (ASR, speaker ID), music tagging, and other audio domains is not evaluated.
- Video generalization to long-form, egocentric, instructional, or non-Western content, and robustness under domain shift, are not assessed.
- Comparison breadth:
- No direct comparison to multimodal models trained with language supervision (e.g., ImageBind-/LanguageBind-like) to contextualize the benefit of purely self-supervised alignment.
- Finetuning performance of MJEPA itself is not reported, limiting understanding of headroom under adaptation vs. frozen features.
- Probing protocol sensitivity:
- Results rely on an attentive probe; sensitivity to probe architecture, capacity, and training regimen is not analyzed, nor is consistency across different probes to ensure representation quality, not probe strength, drives gains.
- Paired-data reliance:
- Cross-modal prediction requires paired samples; strategies to exploit large-scale unpaired audio and unpaired video for alignment (e.g., cycle consistency, pseudo-pairing, teacher-student alignment) are not investigated.
- Over-alignment vs. modality specificity:
- Potential trade-offs between enforcing strong alignment and preserving modality-specific features are not quantified; diagnostics for over-alignment or negative transfer are absent.
- Computational efficiency and practicality:
- Training cost, memory footprint when processing concatenated A+V tokens, and throughput vs. performance trade-offs are not reported; methods for efficient deployment (e.g., distillation to lighter models) are not discussed.
- Handling variable input rates and lengths:
- The approach does not examine varying frame rates, audio sampling rates, or different clip lengths, nor strategies for dynamic or streaming scenarios.
- Calibration and uncertainty:
- No analysis of predictive calibration, confidence under missing/contradictory modalities, or mechanisms to adaptively weight modalities at test time.
- Fairness and bias:
- Potential biases arising from web video pretraining (e.g., content, demographic, cultural biases) and their cross-modal amplification are not addressed; no bias or safety evaluations are provided.
- Statistical robustness:
- Variance across runs, statistical significance of improvements, and sensitivity to seeds/hyperparameters are not reported.
- Failure cases and qualitative analysis:
- The paper lacks qualitative diagnostics (e.g., attention maps, error typologies) to understand when cross-modal prediction helps or hurts and where the model fails.
- Extensibility to additional modalities:
- While the approach is claimed modality-agnostic, integration and empirical evaluation with other modalities (e.g., text, depth, IMU/proprioception, medical modalities) are not demonstrated; required changes to tokenization, masking, and alignment for such modalities are unspecified.
Practical Applications
Immediate Applications
Below are actionable, deployable-now use cases that exploit MJEPA’s single-encoder, cross-modal predictive learning and strong frozen features. Each item lists target sectors, potential tools/products/workflows, and feasibility notes.
- Smart multimedia tagging and recommendation
- Sectors: media/entertainment, software platforms
- Tools/products/workflows:
- Frozen “MJEPA embeddings” service for batch/on-the-fly auto-tagging of user videos (sound events, actions, scenes)
- Attentive-probe microservices trained per taxonomy (e.g., platform-specific content categories)
- Cross-modal retrieval (find videos by audio cues and vice versa) for search and content discovery
- Assumptions/dependencies: domain shift from web videos may require light probe retraining; privacy-compliant ingestion of user audio; GPU/TPU inference budget for ViT-L/g or need for model distillation
- Content moderation and brand safety
- Sectors: trust & safety, advertising
- Tools/products/workflows:
- Event/scene detectors for prohibited sounds (gunshots, screams) and corresponding visuals; ad adjacency filters
- AV-consistency checks to flag manipulated/deceptive content using cross-modal alignment scores
- Assumptions/dependencies: false positives require human-in-the-loop; jurisdiction-specific policy definitions; robust handling of low-SNR audio or poor lighting
- Cross-modal video/audio search and indexing
- Sectors: enterprise knowledge management, media archives, education
- Tools/products/workflows:
- Build a unified AV embedding index for retrieval (e.g., “find clips with barking sounds and running”)
- Lecture and training content indexing with joint audio–visual semantic search
- Assumptions/dependencies: storage and indexing at scale; alignment to institution-specific ontologies; de-duplication pipelines
- Industrial monitoring and anomaly alerts
- Sectors: manufacturing, energy, logistics
- Tools/products/workflows:
- Deploy smart camera–microphone nodes to detect machine faults via audio–visual anomalies
- Train task-specific lightweight probes on historical AV logs with minimal labels (frozen features)
- Assumptions/dependencies: domain adaptation to machinery sounds; ruggedized hardware and on-edge acceleration; worker privacy/consent for audio capturing
- Retail and venue analytics
- Sectors: retail, smart buildings
- Tools/products/workflows:
- Customer flow and event detection (spills, breakage sounds, crowd surges, queue anomalies)
- Safety alerting (e.g., alarms detected in audio and localized by video)
- Assumptions/dependencies: strict compliance with surveillance/audiorecording regulations; calibration to site acoustics
- Automotive in-cabin event detection and HMI
- Sectors: automotive, mobility
- Tools/products/workflows:
- Detect driver distraction, infant cry, glass break, sirens; improve voice-trigger reliability using visual context
- Robust to missing modalities (e.g., audio failure) thanks to shared-encoder training
- Assumptions/dependencies: automotive-grade hardware; noise/echo handling; data governance for continuous in-cabin sensing
- Smart home and consumer devices
- Sectors: IoT, consumer electronics
- Tools/products/workflows:
- On-device alerts for smoke alarms, baby cry + video confirmation; pet behavior and intrusion detection
- Camera–microphone synergy for fewer false positives; simple probes for personalization
- Assumptions/dependencies: model compression/distillation for edge; local processing for privacy; multi-vendor device integration
- Accessibility features
- Sectors: assistive tech, public services
- Tools/products/workflows:
- Real-time environmental sound recognition paired with visual cues for Deaf/HoH users
- Tactile/visual notifications when relevant audio events occur but visuals are occluded (or vice versa)
- Assumptions/dependencies: low-latency inference; UX tailored to user needs; on-device privacy
- Rapid prototyping for academic research
- Sectors: academia (vision/audio, HCI, robotics)
- Tools/products/workflows:
- Use frozen MJEPA features to establish strong baselines for new AV tasks with few labels
- Mixed-data pretraining workflows (paired + unimodal) to maximize use of lab-curated datasets
- Assumptions/dependencies: availability of pretrained checkpoints; reproducible attentive-probe code; fair-use of training data
- Data-efficient model development and cost savings
- Sectors: ML platform engineering across industries
- Tools/products/workflows:
- Replace separate audio and video encoders with a single backbone to reduce training/serving complexity
- Leverage mixed unimodal/multimodal corpora without redesigning pipelines
- Assumptions/dependencies: migration cost for legacy models; monitoring performance per-modality; governance around reuse of unlabeled data
- Policy and compliance analytics (non-content-specific)
- Sectors: compliance, governance
- Tools/products/workflows:
- Measurement of data labeling reductions due to self-supervised training; reporting of compute savings (less video needed for comparable performance)
- Dataset audits for audio capture consent and retention policies
- Assumptions/dependencies: organization-wide data inventory; legal review for audio collection; carbon accounting frameworks
Long-Term Applications
These opportunities are promising but need further research, additional modalities, domain-specific data, or productization work.
- Unified multimodal perception for robotics
- Sectors: robotics, smart factories, service robots
- Potential tools/products/workflows:
- Extend shared encoder to vision + audio + proprioception/IMU for robust manipulation and navigation
- Cross-modal prediction to learn tactile/force “proxies” from audio/visual cues during teleoperation
- Assumptions/dependencies: synchronized multi-sensor logs; safety validation; robustness under extreme acoustics and motion blur
- Healthcare AV sensing
- Sectors: healthcare, eldercare
- Potential tools/products/workflows:
- Hospital room monitoring for critical sound events (alarms, coughs) plus visual context (patient motion, falls)
- Respiratory/cardiac acoustic screening combined with facial/pose video for telemedicine triage
- Assumptions/dependencies: domain-specific, IRB-approved datasets; strict HIPAA/GDPR compliance; bias and safety audits; clinically validated probes
- AR/VR real-time scene understanding
- Sectors: XR, gaming, telepresence
- Potential tools/products/workflows:
- Audio–visual event awareness for mixed reality (e.g., identify behind-the-user sound sources with visual grounding)
- Enhanced spatial audio rendering guided by visual semantics via cross-modal alignment
- Assumptions/dependencies: low-latency streaming and on-device acceleration; robust AV synchronization; battery constraints
- Multimodal foundation services across additional sensors and languages
- Sectors: smart cities, defense, environmental monitoring
- Potential tools/products/workflows:
- Incorporate radar, thermal, or RF with audio/video in a single JEPA-style backbone for adverse conditions
- Low-resource language or locale adaptation for public-safety alerts derived from non-speech soundscapes
- Assumptions/dependencies: large-scale, synchronized, lawful datasets; model scaling and training compute; governance for public deployment
- Video understanding for scientific discovery and education at scale
- Sectors: science, open education
- Potential tools/products/workflows:
- Indexing and mining of lab videos (e.g., microscopy with instrument sounds) or field recordings (ecology, geology)
- Open educational resource platforms with multimodal search and auto-tagging across lectures and labs
- Assumptions/dependencies: domain shift handling; standardized metadata/ontologies; reproducibility and data-sharing agreements
- Privacy-preserving, on-device multimodal intelligence
- Sectors: mobile, IoT, automotive
- Potential tools/products/workflows:
- Distill/quantize MJEPA to small edge models; local feature extraction with server-side lightweight probes or federated fine-tuning
- Selective modality use to minimize data capture (e.g., operate video only when high-confidence audio event detected)
- Assumptions/dependencies: advances in compression without degrading cross-modal alignment; secure enclaves; federated analytics governance
- Enhanced generative and captioning systems via MJEPA features
- Sectors: media tools, accessibility
- Potential tools/products/workflows:
- Use MJEPA embeddings as conditioning inputs for captioning, dubbing alignment, or video B-roll retrieval for LLM-based editors
- Cross-modal retrieval to aid dataset curation for generative training (find representative clips by audio/visual semantics)
- Assumptions/dependencies: integration with generative pipelines; careful evaluation to prevent hallucinations; licensing for training data
- Regulation and standards for AV self-supervised systems
- Sectors: policy, standards bodies
- Potential tools/products/workflows:
- Guidelines for lawful AV data collection and transparent self-supervised training (annotation reduction benchmarks, privacy risk assessments)
- Standardized tests for cross-modal robustness and missing-modality behavior
- Assumptions/dependencies: multi-stakeholder engagement; alignment with regional privacy laws; open benchmarks and reporting templates
Cross-cutting Assumptions and Dependencies
- Data availability and governance: large-scale AV data (and in some domains, additional sensors) with lawful collection and consent.
- Compute and deployment: pretraining large ViT-g models is compute intensive; many deployments will require distillation/quantization or ViT-L-class backbones.
- Domain adaptation: although frozen features are strong, probe retraining or light fine-tuning may be necessary for specialized domains (healthcare, manufacturing).
- Synchronization and quality: cross-modal predictive benefits depend on reasonably aligned, non-corrupted audio and video; noisy capture reduces gains.
- Monitoring and evaluation: strong frozen performance reduces task-specific tuning but necessitates careful post-deployment monitoring for drift, bias, and failure cases.
Glossary
- A-JEPA: A JEPA variant tailored for audio-only pretraining. "This setup is equivalent to training separate A-JEPA~\cite{ajepa_2024} and V-JEPA models~\cite{vjepa_2024}"
- Attentive probe: A lightweight attention-based classifier used to evaluate frozen features. "A lightweight attentive probe is trained on top of frozen encoder features for each downstream task."
- Audio-Visual Self-Supervised Learning (AV-SSL): Learning representations from unlabeled paired audio-video data without explicit labels. "Approaches exploring audio-visual self-supervised learning (AV-SSL) tend to rely on complex, multi-component architectures"
- Contrastive losses: Objectives that pull matching pairs together and push non-matching pairs apart in embedding space. "Prior AV-SSL methods typically combine modality-specific encoders with a mixture of contrastive losses, reconstruction objectives, and heavy augmentations."
- Context encoder: The encoder that processes a corrupted or masked input view to produce context features. "The typical JEPA setup involves two main components: a context encoder, , which computes representations for the corrupted input"
- Cross-modal alignment: Enforcing that different modalities map to semantically compatible representations. "Cross-modal alignment, joint audio-video encoding, and scaling are each critical for learning high-quality, generalizable multimodal representations."
- Cross-modal distillation: Transferring knowledge across modalities using a teacher-student setup. "cross-modal distillation, or combinations thereof"
- Cross-modal prediction: Predicting the representation of one modality using the representation of another. "we introduce cross-modal prediction: predicting the representation of one modality from the other."
- Data augmentations: Transformations applied to inputs during training to improve robustness and generalization. "EquiAV~\cite{equiav_icml24} relies heavily on data augmentations"
- Equivariance: A property where transformations of inputs correspond predictably to transformations of representations. "using equivariance to encode augmentation-related information into the learned representations."
- Exponential moving average (EMA): A smoothed parameter update that tracks a running average of model weights. "an exponential moving average (EMA) of the encoder weights to produce stable targets"
- Frozen evaluation: Assessing representation quality by training a probe on top of fixed (non-updated) encoder features. "we follow the frozen evaluation protocol of~\cite{vjepa_2024, vjepa2_2025}"
- Frozen representations: Feature embeddings extracted from a pretrained encoder kept fixed during downstream evaluation. "MJEPA produces highly generalizable frozen representations from a single model"
- Heterogeneous data: Training data drawn from different modalities or dataset types. "This design scales naturally to heterogeneous data, including mixtures of unimodal and multimodal sources."
- Inductive bias: Architectural or training assumptions that guide learning towards certain solutions. "making parameter sharing an inductive bias toward a unified representation space."
- Intra-modal prediction: Predicting masked features within the same modality from visible context of that modality. "Intra-modal prediction: the encoder and a shared predictor are applied independently to three input modes"
- Joint-Embedding Predictive Architectures (JEPAs): Models that learn by predicting target embeddings from context embeddings without reconstructing raw inputs. "Joint-Embedding Predictive Architectures (JEPAs) offer a simple, modality-agnostic alternative"
- Latent space: The learned embedding space where representations are compared or predicted. "predicting masked features in a latent space without pixel-level reconstruction."
- Masked reconstruction: Rebuilding masked parts of the input, typically used in autoencoder-based SSL. "masked reconstruction~\cite{georgescu2023avmae}"
- Masked tokens: Representation slots corresponding to intentionally hidden input regions used for prediction. "$\mathcal{L}_{\text{predict}$ is only applied on masked tokens, and not on the context tokens."
- Mean Average Precision (mAP): A metric averaging precision across classes, commonly used in multi-label evaluation. "we report audio-only (A), video-only (V), and audio-video (A-V) mean Average Precision (mAP) on AudioSet-20K"
- Mean pooling: Aggregating token features by averaging them across positions. "denotes mean pooling over tokens."
- Modality-agnostic: Applicable across different input types (e.g., audio, video) without modality-specific changes. "an alternative that is explicitly designed to be modality-agnostic"
- Modality-specific encoders: Separate encoders specialized for each modality in a multimodal system. "Existing audio-visual self-supervised methods rely on modality-specific encoders"
- Multi-label: A setting where each example may belong to multiple classes simultaneously. "a multi-label audio event classification benchmark"
- Multi-level prediction: Predicting targets using features from multiple intermediate layers to encourage richer representations. "we use multi-level prediction for the intra-modal objective"
- Negative samples: Non-matching pairs used in contrastive learning to push apart representations. "requiring no data augmentations, negative samples or reconstruction"
- Out-of-distribution: Data that differ from the training distribution, used to test generalization. "generalizing to diverse out-of-distribution benchmarks without any fine-tuning."
- Representation collapse: A failure mode where the encoder outputs degenerate (constant) representations. "A key challenge is preventing 'representation collapse'"
- Self-supervised learning: Learning representations from unlabeled data by solving surrogate tasks. "Self-supervised learning has become the dominant paradigm for learning general-purpose representations"
- Shared encoder: A single encoder whose parameters are used across multiple modalities. "a single, shared encoder processes all modalities (audio, video, and audio-video)"
- Stop-gradient (sg): An operation that prevents gradients from flowing through a branch during backpropagation. "a stop-gradient (sg) operation on the target branch"
- Target encoder: The branch (often EMA-updated) that provides stable target representations during training. "a target encoder $E_{\bar{\theta}$ (an EMA of ) processes the complete, unmasked view ."
- Tokenized: Converted into discrete vector tokens for transformer-style processing. "Audio and video are tokenized by separate linear projection layers"
- Tubelets: Spatio-temporal video patches used as tokens in video transformers. "masking out large blocks of spatio-temporal tubelets."
- Unimodal: Involving a single modality (e.g., only audio or only video). "unimodal baselines"
Collections
Sign up for free to add this paper to one or more collections.

