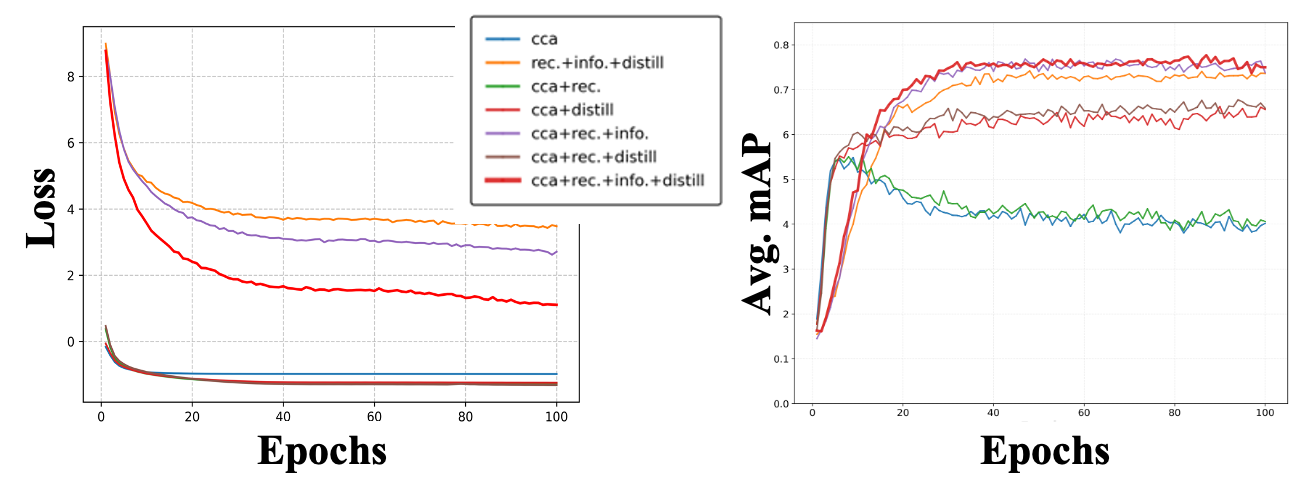
- The paper presents HSC-MAE, a dual-path teacher-student model that enforces hierarchical semantic consistency for robust cross-modal retrieval.
- It combines global DCCA alignment, local soft top-k InfoNCE loss, and sample-level masking to create modality-invariant embeddings.
- Experiments on AVE and VEGAS show up to 15.72% mAP improvement over baselines, confirming the effectiveness of the proposed framework.
Hierarchical Semantic Correlation-Aware Masked Autoencoder for Unsupervised Audio-Visual Representation Learning
Introduction and Motivation
Unsupervised learning of cross-modal representations remains a significant challenge due to the weak, noisy, and ambiguous association between modalities in real-world corpora. The "Hierarchical Semantic Correlation-Aware Masked Autoencoder (HSC-MAE)" addresses unsupervised audio-visual representation learning from pre-extracted, paired—but unlabeled—audio-visual features. It directly confronts major limitations of pre-existing approaches such as strict single-positive assumptions, confirmation bias, and lack of mechanisms for robust intra-modal decoding, thereby enabling more reliable multimodal semantic alignment under weak supervision.
Methodology
HSC-MAE introduces a dual-path teacher-student framework that enforces semantic consistency hierarchically at three levels: global (canonical-geometry), local (neighborhood-semantics), and instance (conditional-sufficiency).
- Global-level alignment: An EMA-updated teacher pathway operates in a clean (unmasked) regime and employs Deep Canonical Correlation Analysis (DCCA) to enforce that audio and visual embeddings share a modality-invariant low-dimensional subspace, providing a global geometric scaffold.
- Local-level structure: The student pathway is regularized via a soft top-k InfoNCE loss, where local semantic neighborhoods are mined and weighted with affinities provided by the stable teacher. This approach relaxes brittle single-positive matching in favor of more realistic multi-positive neighborhoods.
- Sample-level robustness: The student employs sample-level feature masking and autoencoding, aiming for robustness to incomplete or noisy descriptors and ensuring conditional sufficiency of representations.
- Multi-task optimization: All objectives are harmonized via learnable uncertainty-based multi-task weights, with an optional consistency loss distilling teacher geometry into the student.
This architecture enables decoupling of correlation and reconstruction objectives while strategically coupling them via cross-attention, a shared encoder, and soft-positive mining.
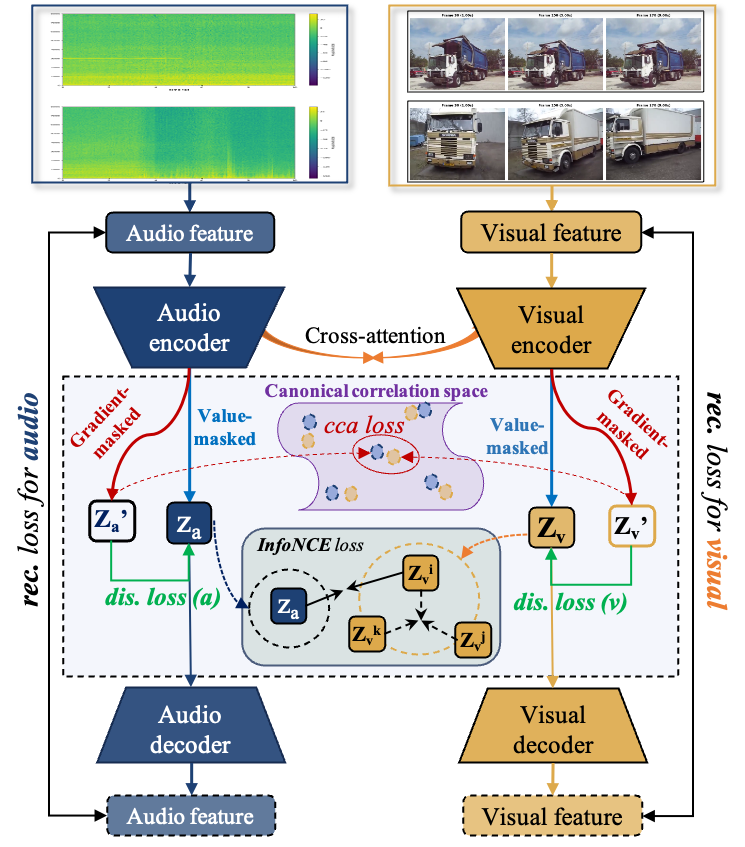
Figure 1: Schematic of HSC-MAE's dual-path architecture with shared encoders, cross-attention fusion, sample-level masking, EMA teacher, and hierarchical objective coordination.
Experimental Results
Datasets and Setup
HSC-MAE is evaluated on AVE and VEGAS datasets using pre-extracted audio (VGGish, 128-D) and visual (InceptionV3, 1024-D) descriptors. The model is trained entirely unsupervised, with cross-modal retrieval performance (UCMR: audio-to-visual, visual-to-audio) assessed via mean Average Precision (mAP).
Main Quantitative Results
HSC-MAE delivers significant improvements over all considered baselines:
- On AVE, averaged mAP increases from 0.6165 (CAV-MAE) to 0.7737 (+15.72%) and outperforms InfoNCE, triplet, and DUMCH by a clear margin.
- On VEGAS, it improves average mAP from 0.7535 to 0.8026 over CAV-MAE (+4.91%), and achieves higher scores than DCCA and contrastive learning variants.
The HSC-MAE model achieves the strongest reported unsupervised cross-modal retrieval results across both AVE and VEGAS.
Ablation Analysis
Ablation studies systematically demonstrate that:
Mask Ratio Sensitivity
Performance is contingent on an optimal feature mask ratio. Moderate masking (e.g., 0.2–0.3) yields maximal mAP; overly aggressive masking (≥0.5) impairs semantic alignment, while too little masking under-regularizes and weakens robustness.
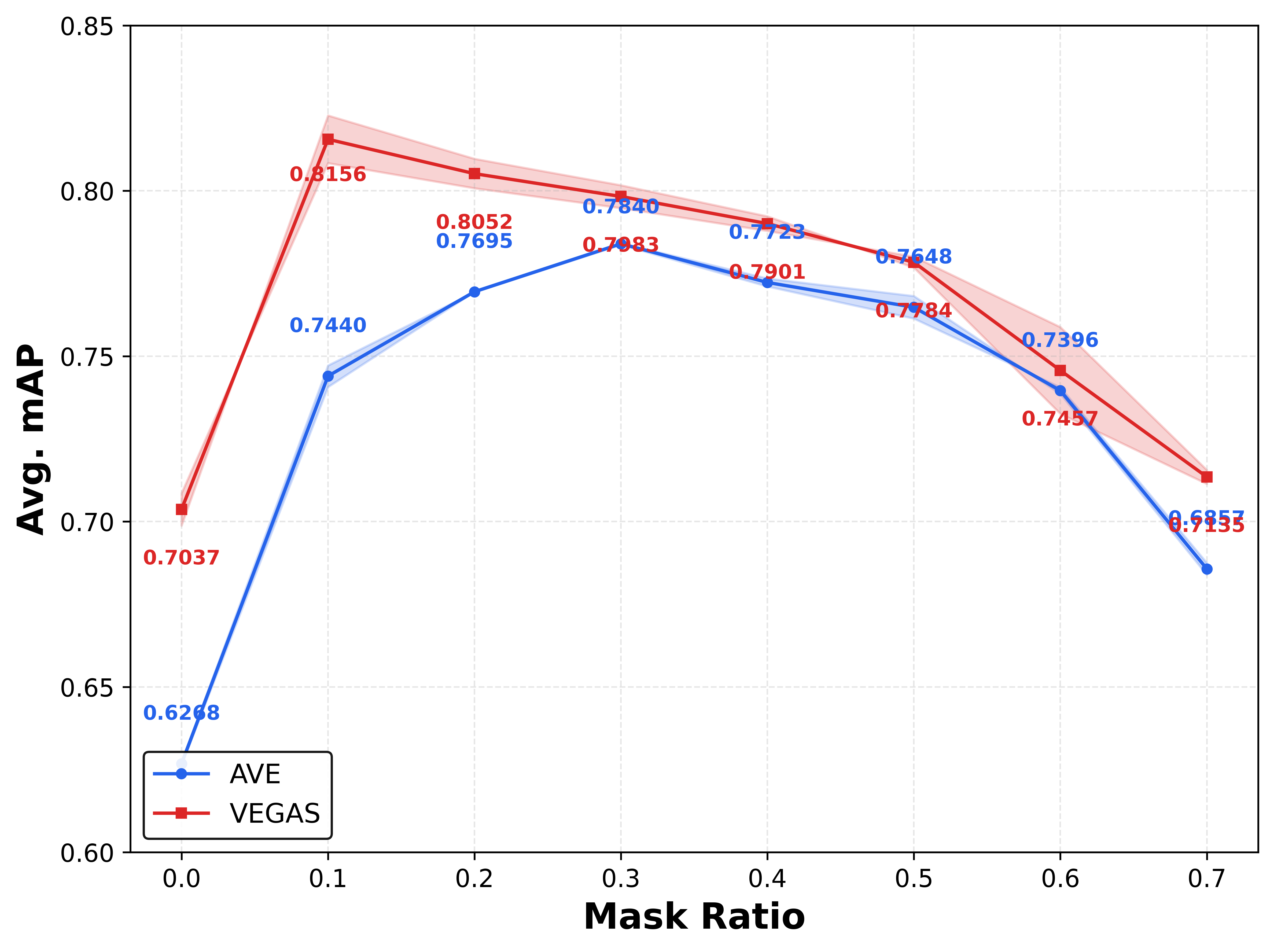
Figure 3: Effect of sample-level mask ratio on UCMR task for AVE and VEGAS; optimal retrieval at moderate masking, with dataset-dependent gaps between retrieval directions.
Qualitative Retrieval
HSC-MAE demonstrates retrieval alignment that is robust to subtle cross-modal ambiguities. Querying with audio or visual features of a "truck" consistently retrieves semantically congruent top results; mismatches primarily reflect inter-class confusion (e.g., truck vs. bus) rather than modality-level noise or misalignment.

Figure 4: Qualitative top-10 retrievals for audio and visual queries (AVE), showing robust cross-modal alignment despite ambiguous categories.
Implications and Future Directions
HSC-MAE provides a general algorithmic framework for scalable, label-efficient learning in multimodal settings where only compact feature descriptors are available and paired supervision is weak or ambiguous. The approach is immediately applicable to embodied agents and large-scale multimedia retrieval, with strong implications for:
- Robust multimodal embedding under partial observability and noise
- Reductions in confirmation bias and improved mining of positives in multi-event corpora
- Extension to arbitrary modalities and scalability to online/self-adaptive systems
Further directions include scaling to raw sensor data, causal discovery of multimodal structure, and integration with end-to-end video/sequence models.
Conclusion
HSC-MAE introduces hierarchical semantic correlation-aware constraints within a dual-path masked autoencoder, leveraging global DCCA alignment, local soft-neighborhood InfoNCE, sample-level masked autoencoding, and teacher-guided distillation. Strong empirical evidence attests to substantial mAP gains over diverse unsupervised baselines, with ablations confirming non-redundant contributions of each architectural innovation. The work consolidates effective solutions for unsupervised audio-visual representation, providing a robust template for future work in scalable multimodal learning.