- The paper introduces a novel two-stage framework that uses latent LLM representations to guide online RL, significantly enhancing policy generalization.
- It decouples the explicit action generation from the LLM by projecting environment states into a latent space and applying a KL-regularized prior.
- Empirical results on CLEVR-Robot and Meta-World benchmarks show remarkable improvements in reward and success rate over Vanilla PPO.
Latent Action Guidance for Online Reinforcement Learning: An Expert Perspective on LaGO
Context and Motivation
The intersection of LLMs and RL has seen rapid developments, with researchers exploring LLMs as direct controllers, high-level planners, and world model simulators. Prior methodologies often require LLMs to generate explicit actions, plans, or simulated trajectories with high fidelity, which is not always reliable, especially in tasks involving complex, non-linguistic state spaces or continuous control. "LaGO: Latent Action Guidance for Online Reinforcement Learning" (2606.24669) reframes the role of LLMs in sequential decision-making by leveraging their pretrained latent representations as soft behavioral priors, facilitating a more robust and practical integration into online RL pipelines.
Methodological Framework
LaGO is a two-stage protocol that decouples the role of the LLM from explicit action generation. In the first stage, a pretrained LLM is fine-tuned on expert demonstrations, with non-textual environment states projected into the LLM latent space via learned projection layers. An additional action prediction head is trained to map these latent features to action distributions, constructing the latent policy prior.
During the second stage, this prior is frozen and serves as a regularization target for an RL policy, which is optimized online via environmental interaction using algorithms such as PPO. The action distributions produced by the RL policy are softly regularized toward those generated by the LLM prior, implemented as a KL or cross-entropy term (depending on action space discreteness) weighted by a configurable coefficient β. This allows the RL policy to adaptively balance reward optimization with inductive guidance derived from LLM knowledge.
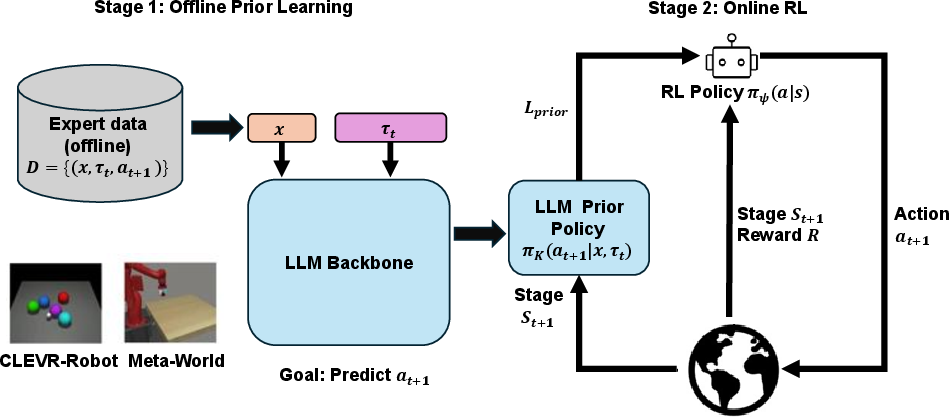
Figure 1: Overview of the LaGO framework; numeric environment states are projected into the frozen LLM latent space and the resulting action distribution serves as a KL-regularized prior for online RL.
Notably, the framework's design eliminates the requirement that the LLM produce precise actions or plans. Instead, it suffices that the LLM prior encodes coarse behavioral heuristics reflecting structural environment knowledge, which can facilitate efficient and directed exploration in RL.
Empirical Evaluation
LaGO is evaluated in both discrete (CLEVR-Robot) and continuous (Meta-World) control benchmarks. CLEVR-Robot presents a manipulation scenario with a 10-dimensional state and 40 discrete actions; Meta-World involves 91-dimensional robot states with 4-dimensional continuous actions across a diverse set of manipulation tasks. Four task categories are considered: Real (covered in offline data), Rephrase (paraphrased instructions), Easy (unseen, low-novelty), and Hard (unseen, high-complexity).
Results demonstrate substantial improvements over Vanilla PPO in both reward and success rate:
- On CLEVR-Robot, average success rate improves from 15.1% to 27.2% (~80% increase).
- On Meta-World, average success rate increases from 2.7% to 15.2% (~463% increase).
These gains are most pronounced in in-distribution tasks (Real, Rephrase), but LaGO also generalizes to unseen task variants, indicating that the LLM prior does not merely encode memorized actions but embeds transferable structural knowledge.
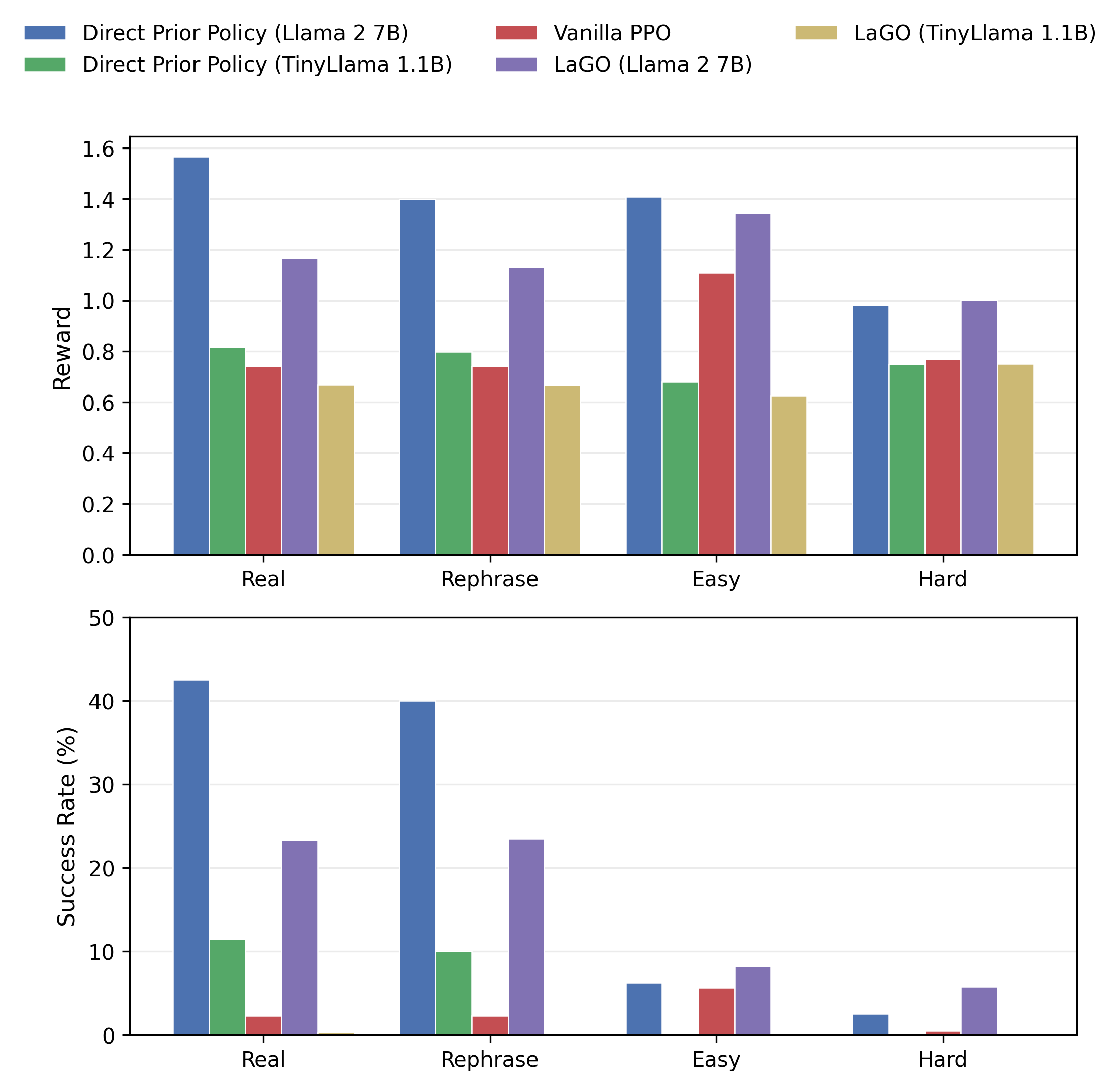
Figure 2: Impact of LLM prior quality on Meta-World; reward and success rate across task categories for direct prior policy, Vanilla PPO, and LaGO—highlighting the superiority of LaGO with stronger LLM backbones.
Ablation studies further reveal that the quality of the pretrained LLM substantially affects the efficacy of the latent prior. Using Llama 2 7B as the backbone results in markedly better performance compared to TinyLlama 1.1B, both in direct prior execution and RL policy regularization. This underscores the importance of LLM backbone selection and suggests the framework's scalability with advances in foundation model architectures.
Analysis and Implications
LaGO provides a pragmatic architectural solution for leveraging the structural and conceptual knowledge encoded in LLMs without relying on their explicit control capacities. The KL-regularized prior acts as a soft bias, effectively guiding policy learning, especially in settings where reward signals are sparse and exploration is challenging. The empirical findings suggest the following implications:
- Policy Generalization: LaGO's latent prior supports substantial policy generalization beyond memorized demonstrations, even to compositional, out-of-distribution tasks.
- Continuous Control: The framework generalizes to continuous action spaces, expanding applicability well beyond text-based or discrete domains.
- Model Scalability: Improvements in LLM backbone quality are directly translatable to stronger latent guidance, making the approach robust to ongoing advances in foundation models.
Theoretically, this approach aligns with Bayesian RL perspectives, treating the LLM prior as an information-rich behavioral prior that guides—rather than constrains—policy search. Practically, LaGO circumvents the need for expensive explicit rollout generation or plan synthesis during online training, while remaining compatible with conventional reward-based optimization.
Future Directions
Several avenues emerge:
- Progressive weakening of prior regularization as RL policy attains competence, enabling more adaptive exploration-exploitation tradeoffs.
- Deployment of state-of-the-art foundation models to further enhance generalization and task transfer.
- Evaluation in longer-horizon, multi-modal, or nonstationary environments.
- Integration with hierarchical RL architectures, where latent priors can inform high-level decision bottlenecks.
Conclusion
LaGO establishes a principled framework for harnessing the latent structural knowledge embedded in LLMs to guide online RL policy learning. By utilizing projection layers and KL-regularization, it enables robust, scalable policy optimization that benefits from but does not depend on the precision of LLM-generated actions or plans. The demonstrated improvements in reward and success across both discrete and continuous task domains, and the correlation with LLM backbone quality, indicate strong practical and theoretical potential. The approach is well-positioned to facilitate future advances in RL by integrating the evolving strengths of foundation LLMs and remains adaptable to diverse sequential decision-making contexts.