- The paper introduces MPAIL2, a planning-based IRLfO algorithm that leverages latent state modeling and off-policy adversarial reward learning to overcome supervision limitations.
- It employs multi-step policy optimization with MPPI control, achieving over 80% success in simulated tasks and robust real-world performance on manipulation challenges.
- The framework demonstrates significant improvements in sample efficiency, stability, and transfer learning, outperforming baseline methods in complex robotic environments.
Planning from Observation and Interaction: An Expert Analysis of MPAIL2 (2602.24121)
Problem Setting and Motivation
This paper introduces MPAIL2, an algorithm for planning-based Inverse Reinforcement Learning from Observation and Interaction (IRLfO), leveraging self-supervised latent world modeling with off-policy updates. The central challenge is observational learning in realistic robotic manipulation environments without access to demonstrator actions or engineered reward functions. The approach is motivated by the limitations of prior LfO, RL, and imitation learning methods that often require high-quality action supervision, dense rewards, or massive prior data—constraints that limit their practical deployment on real robots and restrict generalization across complex tasks and embodiments.
MPAIL2 Algorithmic Framework
MPAIL2 builds upon Model Predictive Adversarial Imitation Learning (MPAIL), enhancing scalability for visual manipulation tasks via:
- Latent State Modeling: Image-based observations are encoded into latent representations. Dynamics, reward, and value are learned in latent space, trading off demonstration efficiency for interaction efficiency.
- Off-policy Adversarial Reward Learning: The inferred reward is learned using adversarial principles, with a gradient penalty regularization to improve stability in non-trivial environments (Wasserstein GAN formulation).
- Multi-step Policy Optimization: Policies are trained to output full H-step plan sequences (not just immediate actions), optimizing a TD(λ)-like return blending model-free and model-based feedback.
- Planning via MPPI: Actions are selected by Model Predictive Path Integral (MPPI) control using trajectory rollouts and value bootstrapping for online iterative refinement.
Figure 1: Overview of the MPAIL2 pipeline demonstrating interaction between encoding, dynamics, reward inference, value estimation, multi-step policy proposal, and trajectory optimization via planning.
The architecture employs compositional modularity for encoder, dynamics, reward, value, and policy models; each is updated independently with gradients derived from respective losses. Crucially, only initial task observations are used to update the reward, decoupling the latent dynamics from downstream task-specific supervision.
Experimental Evaluation: Simulation and Real-World
MPAIL2 is experimentally validated in both simulation (IsaacLab) and real-world robotics (Franka and Kinova arms), targeting block-push and pick-and-place manipulation tasks. The experimental design features stringent constraints: limited demonstrations, image-based observations, and absence of action/reward supervision.
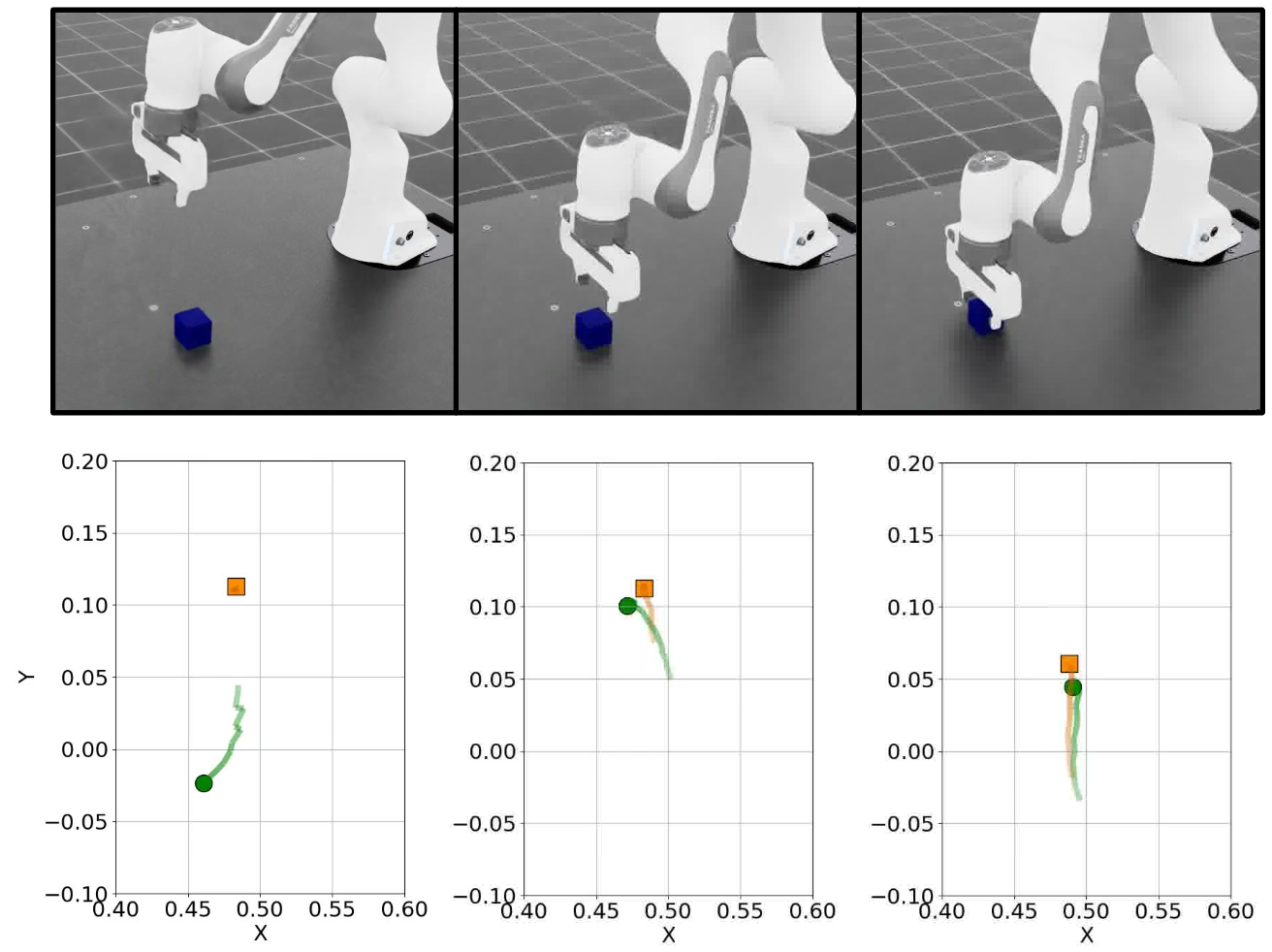
Figure 2: Visualization of a MPAIL2 plan trajectory during a block push task showing predicted XY end-effector trajectories and block dynamics at different time steps—highlighting learned causal effects of contact.
Baseline comparisons include:
- IRL Methods (AIRL, DAC, MAIRL): Adapted to observation-only settings.
- RLPD (RL from Prior Data): Provided ground-truth rewards and action labels.
- Behavior Cloning (Diffusion Policy): Offline implicit policy learning from action-labeled demonstrations.
Evaluations focus on sample efficiency (success per environment interaction), stability, and transfer learning capability. The success metric is computed both for "best" and "last" model checkpoints to capture robustness to training instability.




Figure 3: Examples of the four manipulation tasks evaluated—both simulated and real—spanning pick-and-place and push variants, each requiring nuanced visual-motor coordination.
MPAIL2 demonstrates consistent success rates above 80% in simulated block push (state), with substantial improvement over baselines (see Table 1 in the paper), and achieves robust performance (up to 100% success) in real-world block push within 40 minutes of interaction—highlighting marked improvements in sample efficiency under minimal supervision. In pick-and-place tasks, MPAIL2 outperforms both BC and RL methods, especially in real-world settings where policy-based approaches struggle with generalization and recovery.
Transfer Learning & Continual Adaptation
A salient property of MPAIL2 is its capacity for online transfer: after training on one task, latent world model and planning components enable rapid adaptation to novel task variations (e.g., changing block movement direction or location).
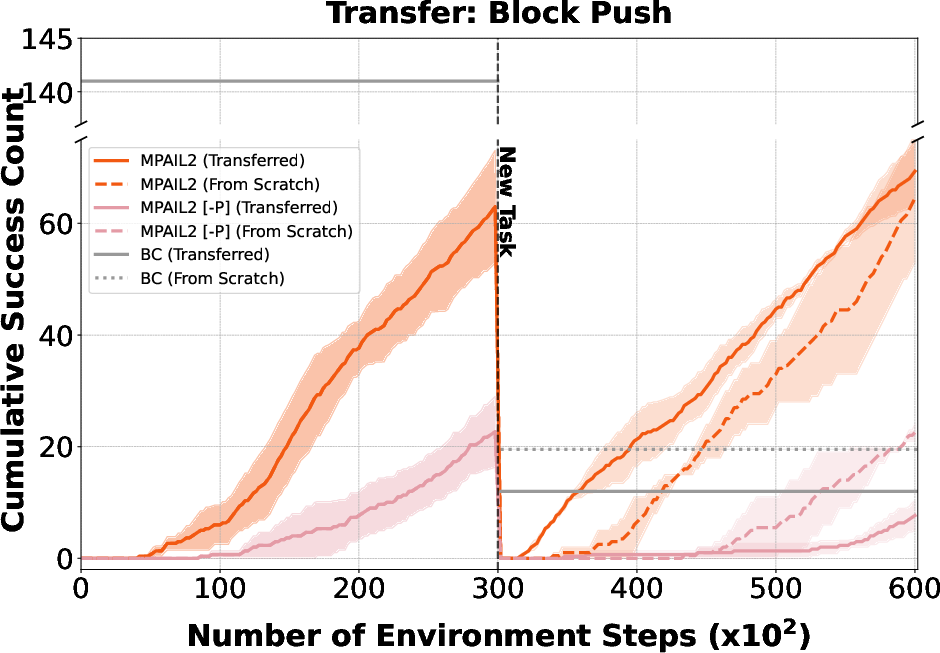
Figure 4: Cumulative success rates in real-world transfer learning experiments: MPAIL2 rapidly adapts to novel task goals compared to baselines that require retraining from scratch.
Moreover, isolating transfer solely in dynamics and encoder further confirms the representational generality for cross-task adaptation, in contrast to conventional policy-centric approaches prone to capacity loss and catastrophic forgetting (Lyle et al., 2022).
Ablations and Efficiency
Comprehensive ablation studies underscore the roles of latent dynamics, offline data replay, and planning. Removal of planning or model-based mechanisms severely degrades interaction efficiency and exposes instability issues in reward learning.
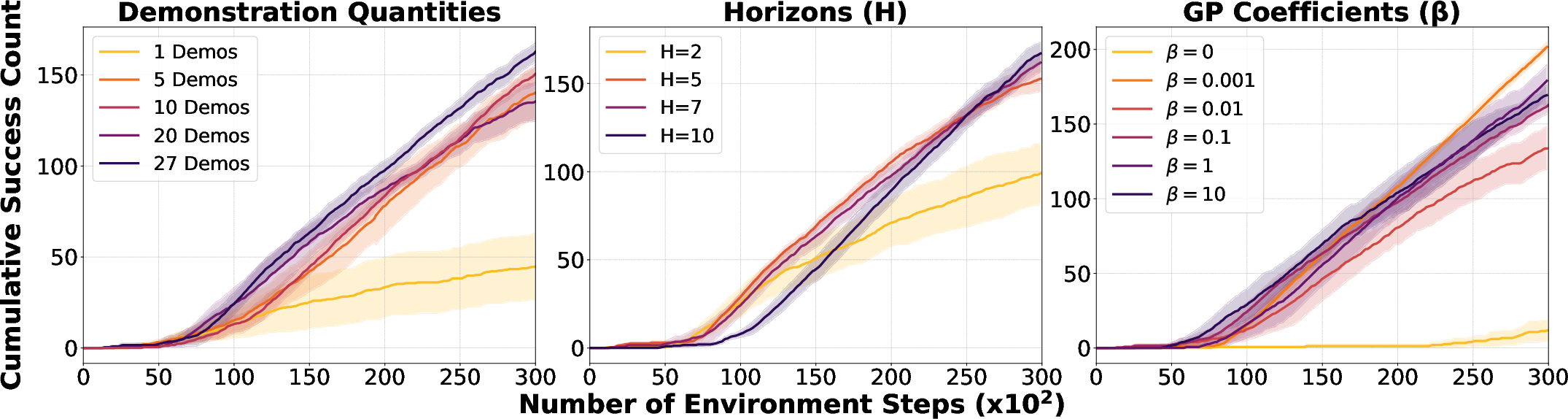
Figure 5: Ablations over demonstration count, horizon length, and gradient penalty magnitude, showing robust performance across hyperparameter ranges.
MPAIL2 achieves up to an order-of-magnitude improvement in time to task completion compared to state-of-the-art RL and BC methods.
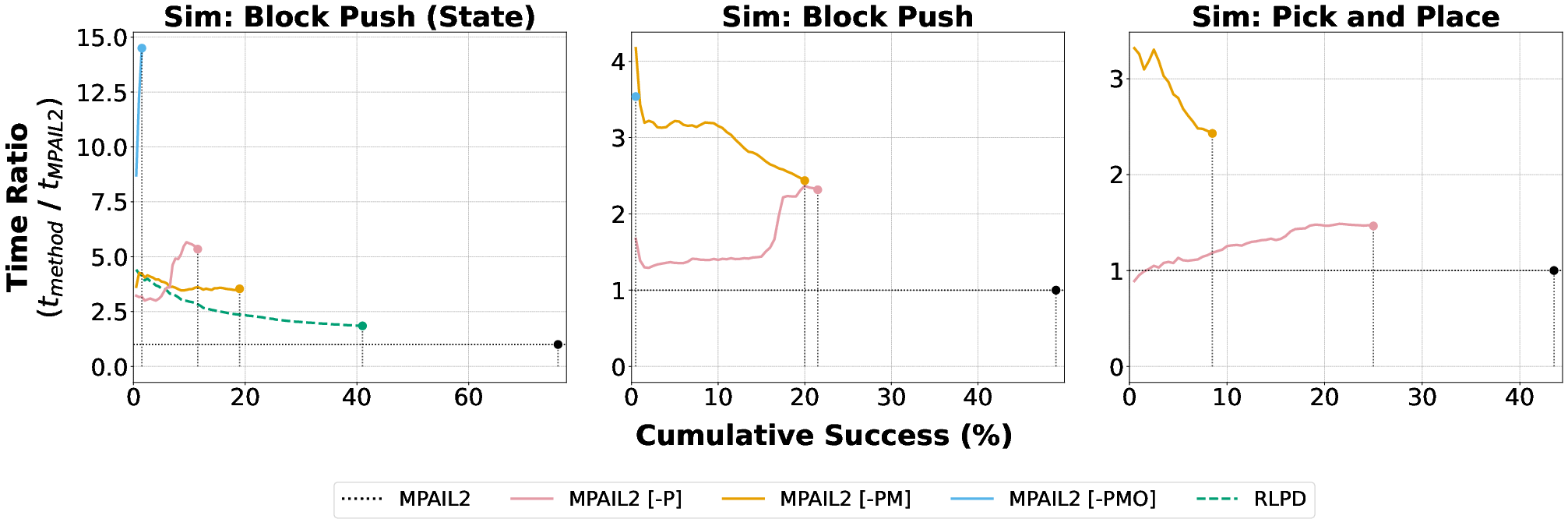
Figure 6: Relative time efficiency plot showing the speedup of MPAIL2 over baselines to reach specified success thresholds.
Success rate stability analyses indicate that planning imparts resilience to adversarial reward collapse and instabilities traditionally problematic for IRL and AIL.
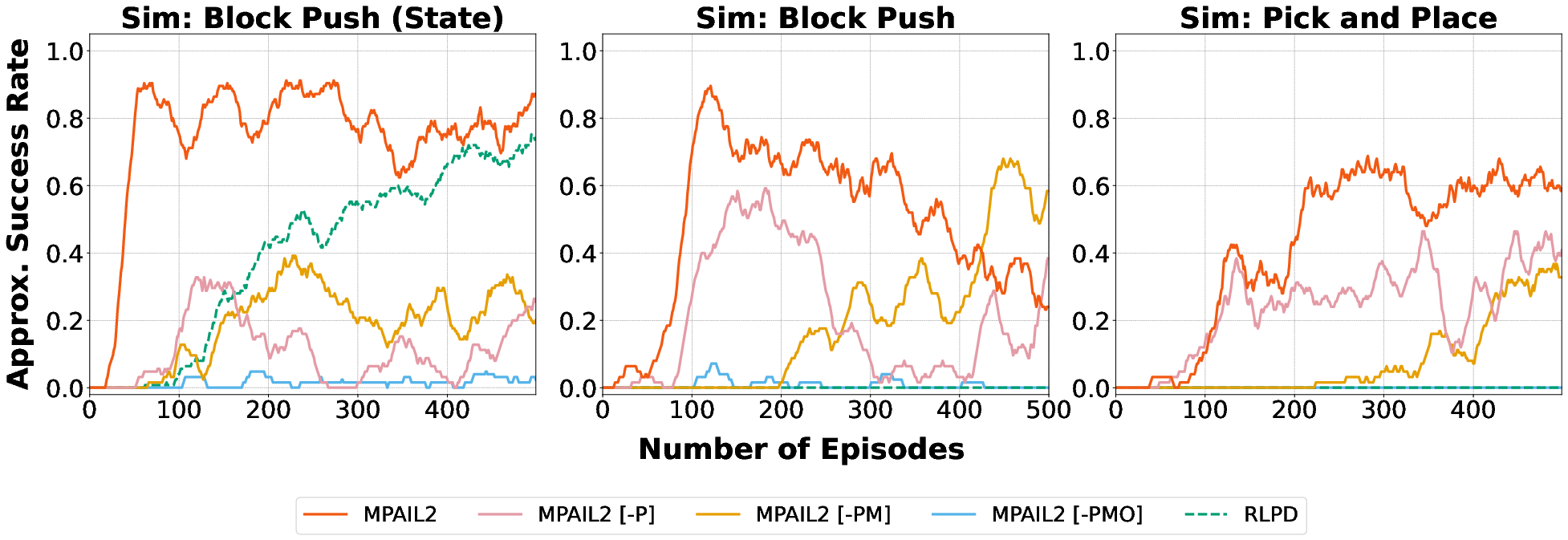
Figure 7: Moving window success rate stability reveals persistent high performance for MPAIL2, while planning-free baselines exhibit performance degradation.
Architectural and Planning Insights
Policy influence analysis reveals that policy-sampled plans contribute marginally to final trajectory scores compared to plans discovered via online latent rollouts (iteration search/optimization), clarifying the importance of iterative planning—even as explicit policy networks act as effective seeds for rollouts.
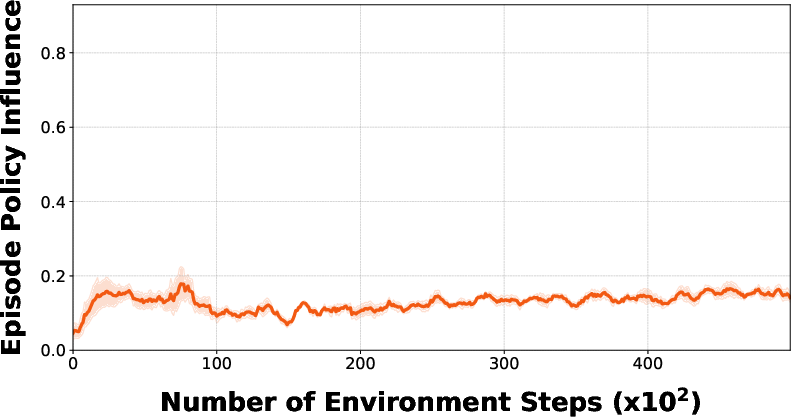
Figure 8: Policy influence metric quantifies the proportion of successful plans arising from explicit policy versus online planning, demonstrating dominance of iterative optimization.
Implications and Future Directions
Practically, MPAIL2 enables visual robotic manipulation from scratch without instrumented reward, action supervision, or domain-specific pretraining, unlocking accessible avenues for non-expert demonstration-driven robot learning. Theoretically, this approach substantiates the utility of implicit iterative planning-based control in improving sample efficiency and transfer—aligning with findings regarding iterative computation in generative models for control (Pan et al., 1 Dec 2025). Planning over world models further facilitates compositional reasoning, uncertainty compartmentalization, and supports continual improvement independent of prior policy representations.
Future directions are:
- Integration of pre-trained vision-language-action models and large-scale cross-embodiment learning (cf. pi_0.5 [black_pi_05_2025], XIRL [zakka_xirl_2022], Cosmos [nvidia_cosmos_2025])
- Enhanced stabilization for adversarial reward learning in non-terminal/sparse tasks (e.g., improved regularization and termination-aware dynamics [shimizu_bisimulation_2024])
- Extension to multi-modal sensory inputs (e.g., tactile [higuera_tactile_2025])
- Investigation of hierarchical planning and compositional skill chaining
- Safety, exploration, and uncertainty handling in open-world physical settings
- Reward-free and action-free world modeling for scalable online imitation (Li et al., 2024)
Conclusion
MPAIL2 represents a rigorous advance in observational robot learning, coupling latent world modeling, stable adversarial reward learning, and iterative trajectory optimization. Empirical results establish strong numerical superiority in sample efficiency and transfer robustness under minimal supervision, confirming planning-based latent control as a practical paradigm for general-purpose robotic manipulation under real-world constraints. The architecture is modular, extensible, and amenable to integration with future multi-task, multimodal, and cross-embodiment learning systems.