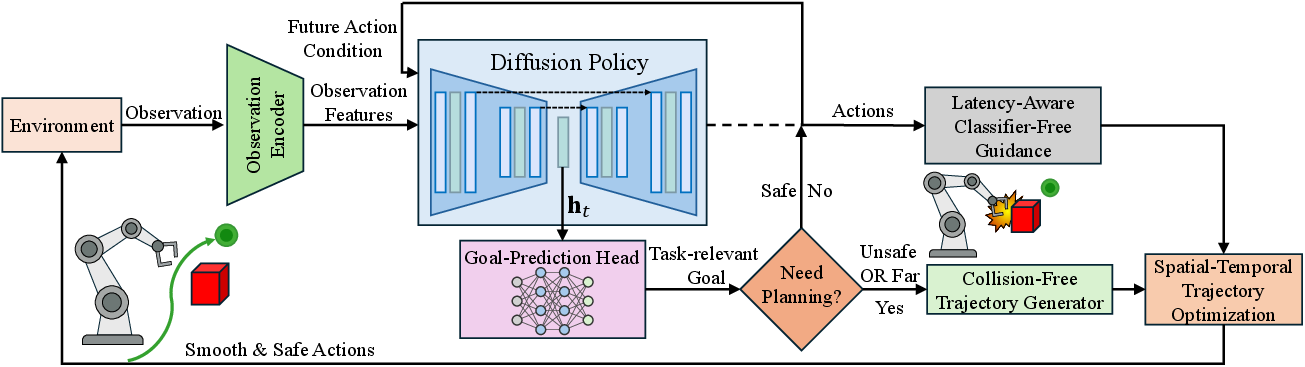
LAGO Policy: Latency-Aware Asynchronous Diffusion Policies with Goal-Directed Collision-Free Planning for Smooth Manipulation
Abstract: Diffusion-based visuomotor policies deployed with asynchronous inference often exhibit inter-chunk discontinuities and lack explicit mechanisms for obstacle-aware execution, leading to jerky motions and collisions that hinder reliable manipulation in real-world scenes. To address these issues, we propose LAGO Policy, a unified asynchronous action-generation framework that integrates trajectory optimization with diffusion policy for smooth and safe execution. LAGO Policy improves inter-chunk consistency via latency-aware classifier-free guidance conditioning on future actions. It further enables goal-directed collision-free trajectory planning by predicting a task-relevant interaction goal from demonstrations. Finally, spatial-temporal trajectory optimization refines the actions to be executed for low-jerk and feasible motion. Extensive real-world experiments demonstrate that LAGO Policy achieves smooth collision-free execution with high task success across challenging manipulation tasks. Project Website: https://lago-policy.github.io/
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
LAGO Policy: Smooth and Safe Robot Motions, Even With Delays and Obstacles
Overview
This paper is about teaching robots to move their arms smoothly and safely while doing everyday tasks, like pouring tea or placing objects, even when the robot’s “thinking” takes time and there are unexpected obstacles in the way. The authors introduce LAGO Policy, a method that mixes a modern learning approach (called a diffusion policy) with smart planning and smoothing so the robot’s motions are continuous (not jerky) and avoid collisions.
What questions does the paper try to answer?
The paper focuses on two big questions that often cause real robots to fail:
- How can a robot keep moving smoothly when it needs time to think between action chunks? (In real life, planning takes time. If the robot keeps stopping to think, motions get jerky.)
- How can a robot safely avoid new obstacles it hasn’t seen in training while still finishing the task?
How does it work? (Methods, in simple terms)
The authors combine three ideas to solve the problems above. Here’s the big picture:
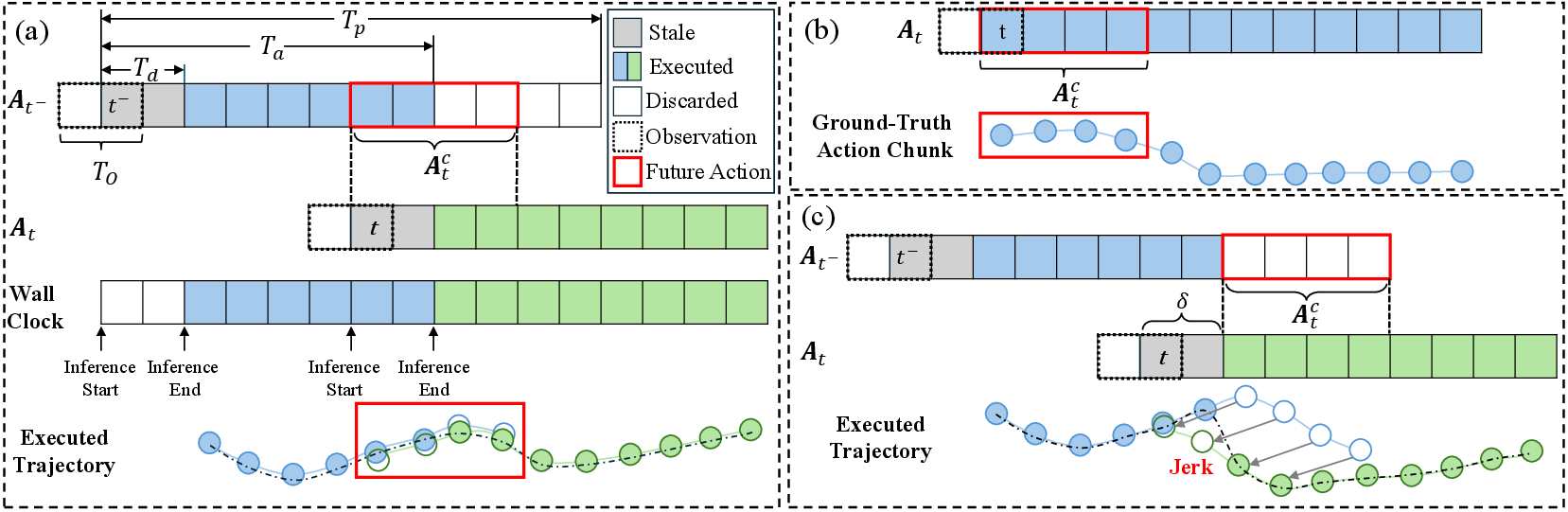
- The robot plans a small set of actions at a time (an “action chunk”) while it is still moving.
- Because planning takes time (latency), the next chunk is based on slightly old information, which can cause mismatches and jerky motion at the boundaries between chunks.
- Also, learned policies often don’t plan around new obstacles, so they can bump into things.
To fix this, LAGO Policy adds three parts:
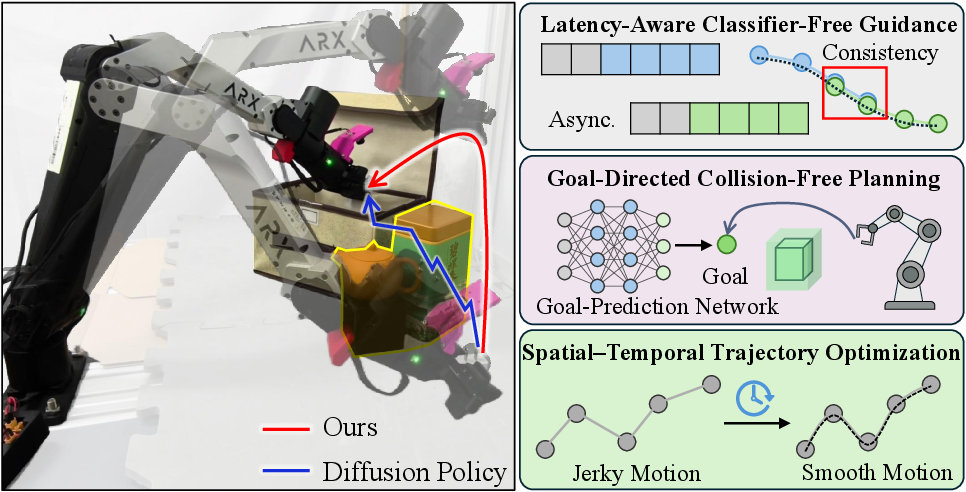
- Latency-aware guidance to keep motion smooth between chunks
- The robot’s brain uses a diffusion model, which is like turning a noisy guess into a clean plan by removing “noise” step by step (similar to sharpening a blurry photo).
- They use a trick called “classifier-free guidance” (CFG): give the model a gentle hint about what the next few actions should look like, so consecutive chunks agree with each other.
- Problem: in the real world, that hint may be a little “late” because of computing delays. Solution: during training, they randomly shift the timing of this hint so the model gets used to delays. This makes it robust when the robot actually moves and plans at the same time (asynchronous inference).
- They also keep this hint separate from the camera observations so the model doesn’t become fragile when the hint arrives slightly early or late.
- Goal prediction to guide obstacle-aware planning
- The robot learns to predict a task-relevant goal from demonstrations (for example: where the cup should end up, or the handle it should go through). Think of it like “what am I trying to reach next?”
- If the robot is far from that goal or a straight path would hit an obstacle, a planner creates a smooth, collision-free path around obstacles toward the goal.
- This planning uses curves (splines) that bend around obstacles, a bit like drawing a smooth line between start and goal that avoids the yellow “do-not-cross” zones.
- Spatial-temporal smoothing for low-jerk motion
- Even after the policy or the planner creates a path, they run a smoothing step that reduces sudden changes in movement (lowers “jerk”), respects speed/acceleration limits, and keeps timing efficient.
- Think of it like ironing out the path so the arm glides smoothly instead of twitching.
Putting it together: at each cycle, the robot predicts an action chunk and a goal. If needed, it plans a safe detour to that goal and then smooths the final path before executing it—all while preparing the next chunk.
What did they find, and why is it important?
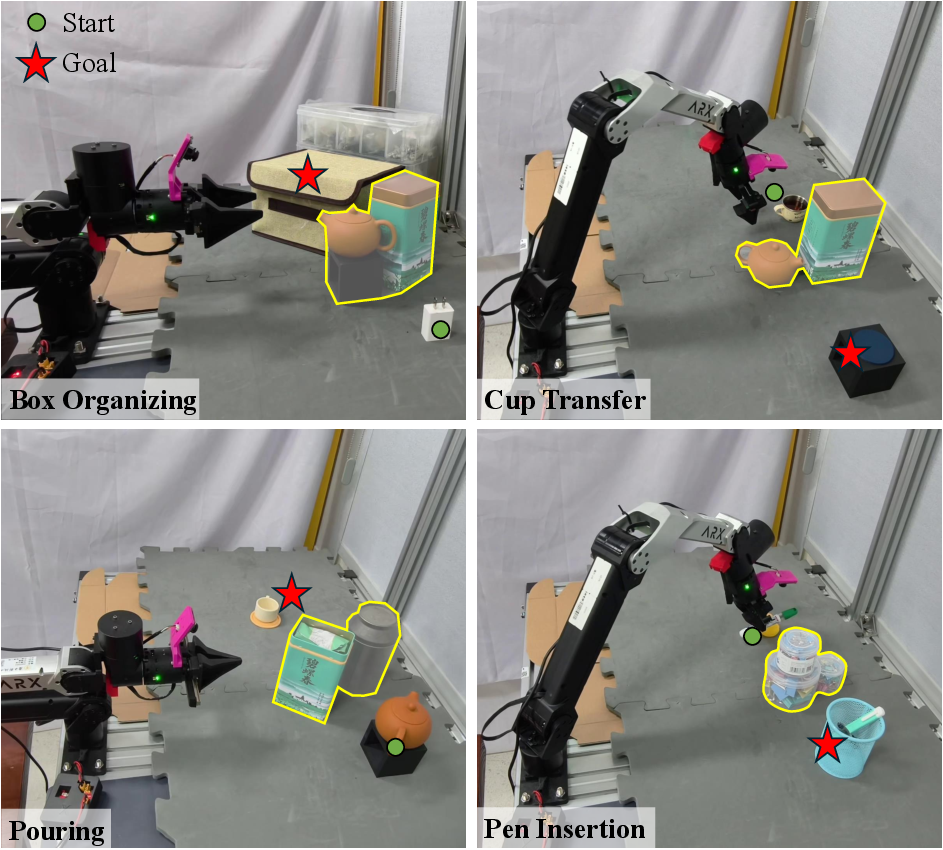
The authors tested LAGO Policy on eight real robot tasks, including:
- Pick-and-place
- Pen insertion
- Pouring (threading the handle and pouring tea without spilling)
- Cup transfer (moving a cup filled with liquid)
- Towel folding
- Box organizing
- Tape hanging
- Screw sorting (with a sliding drawer)
Key results:
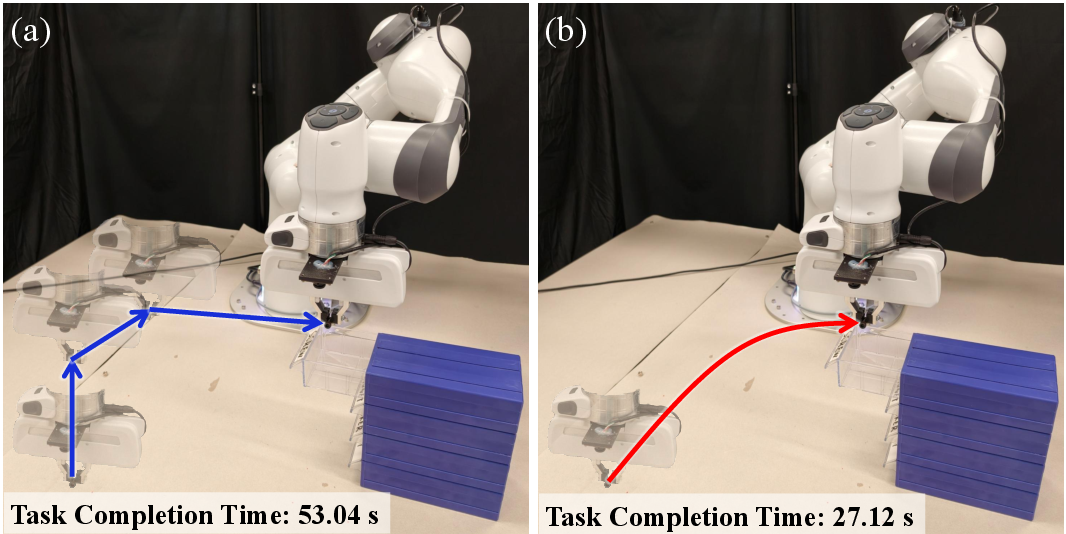
- Smoother motion: LAGO Policy reduces sudden changes (jerk) and improves consistency at the boundaries between action chunks. This means fewer stutters and pauses.
- Better safety: When unexpected obstacles are added, LAGO’s goal-directed planning avoids collisions and keeps the robot on track, while simple “local fixes” (quick short-term corrections) often cause unstable behavior or more errors later.
- Higher success rates: Across multiple tasks, LAGO Policy completes tasks more often, especially in cluttered or obstacle-filled scenes.
- Robust to delays: The latency-aware training makes the system much less sensitive to timing mismatches that happen during real-time operation.
Why it matters:
- Smoothness is crucial for tasks like carrying a cup of tea or pouring, where even tiny jerks can spill liquid.
- Safety is essential when working around people or delicate objects.
- Being robust to delays means the robot can think and move at the same time without awkward pauses.
What could this change in the future? (Implications)
- More reliable home and factory robots: Robots can perform delicate tasks—like organizing a desk or handling objects with liquid—more smoothly and safely.
- Better teamwork with humans: Smoother, collision-aware motion enables robots to work in tighter, more dynamic spaces with people around.
- Stronger generalization: By predicting goals from demonstrations and planning around obstacles, robots can handle new situations better, instead of failing when the scene changes.
In short, LAGO Policy shows how to combine learning (diffusion policies) with planning and smoothing so that robots move more like careful, confident assistants: steady, safe, and goal-focused—even when their brains take a moment to think.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of concrete gaps and unresolved questions that future work could address:
- Latency modeling and adaptation: The paper randomizes the future-action delay via an unspecified distribution
P_δ, but does not measure or model the real inference-latency distribution on hardware, nor adapt the guidance or conditioning to the estimated latency at runtime. How to estimate and trackδonline and adapt the guidance scalew, horizonT_f, or conditioning policy accordingly remains open. - Guidance-scale and conditioning sensitivity: The classifier-free guidance scale
w, drop probabilityp, and future-action horizonT_fare not ablated or tuned systematically across tasks; their effect on stability, smoothness, and success under varying latencies is unknown. - Theoretical guarantees: There is no analysis of stability, bounded discontinuity, or convergence when combining latency-aware CFG with asynchronous chunked execution. Formal conditions under which inter-chunk consistency is guaranteed (as a function of
w,T_f,T_a, and delay distribution) are missing. - Action and state alignment metrics: Inter-chunk continuity is measured in action space only (CON), not in state space (e.g., end-effector pose/velocity continuity across chunk boundaries). The relation between action-space CON and actual executed state continuity (and task performance) remains unquantified.
- Goal label extraction and supervision: The paper does not specify how task-relevant demonstration goals
g*_tare extracted (e.g., heuristics, keyframe mining, optimization, or annotation). Robust, scalable, and task-agnostic goal labeling (including noisy demos) is left undefined. - Goal representation and uncertainty: The goal head predicts a single deterministic goal. Handling ambiguous or multi-stage tasks (multiple subgoals), multi-modal goal distributions, and uncertainty-aware goal prediction (e.g., distributional outputs) are not explored.
- Failure modes of goal misprediction: The system’s behavior when the predicted goal is inaccurate or inconsistent across cycles is not analyzed. Mechanisms for goal validation, correction, or switching (e.g., via confidence thresholds or consistency checks) are absent.
- Planner triggering logic: Planning is triggered by a straight-line collision check and a distance threshold
d_th. The sensitivity of performance tod_th, and more principled triggering criteria that account for global feasibility, latency, or uncertainty, are not studied. - Obstacle representation and perception: The paper assumes collision checking and anchor-point selection on obstacle surfaces, but does not specify how obstacles are perceived, reconstructed, or represented (e.g., voxel grids, signed distance fields, meshes) from multi-view RGB-D under noise/occlusions. A perception-to-planning pipeline (and its robustness) is missing.
- Static vs. dynamic obstacles: The method and experiments focus on static obstacles. Extensions to moving or deformable obstacles, time-dependent constraints, and real-time re-planning under dynamic scenes are not addressed.
- Whole-body collision handling: Collision reasoning is approximated by an end-effector sphere; self-collisions, link-obstacle interactions, grasped-object geometry, and tool extensions are not modeled (acknowledged as future work). Integration with whole-body collision-aware planning remains open.
- Contact and object-centric safety: Safe manipulation constraints for the grasped object (e.g., liquid sloshing limits, force/torque constraints, fragile objects) are not modeled. There is no physics- or task-specific safety cost for contact-rich interactions.
- Planner optimality and guarantees: The spline optimizer guided by A* connectors provides no guarantees of global optimality or completeness. Conditions under which the planner escapes local minima, or fails, are not analyzed.
- Computation and timing budgets: The paper lacks detailed breakdowns of inference time
T_d, planning/optimization time, and their variability. Real-time performance bounds, worst-case latency, and scheduling under tight control loops are unreported. - Joint-space feasibility and dynamics: Spatial-temporal optimization enforces bounds in action space but does not explicitly enforce joint limits, self-collision, torque limits, or dynamic feasibility when mapping task-space trajectories to joint commands. How IK and low-level control ensure feasibility is unspecified.
- Distribution shift quantification: The claim that goal-directed planning “steers back to in-distribution states” is not quantified (e.g., via dataset coverage, state-action density, or representation distances). How far planning can deviate from demonstrations before policy performance degrades is unclear.
- Robustness to sensing errors: The impact of calibration drift, depth noise, lighting changes, and occlusions on goal prediction, collision checking, and planning is not evaluated. Uncertainty-aware perception and robust planning are open directions.
- Generalization across tasks and embodiments: Models are trained per task with 50 demos and evaluated on two arms. Cross-task generalization, multi-task training, transfer to new robots, and robustness to novel objects/scene layouts (beyond added obstacles) are not tested.
- Baseline coverage for safety: Comparisons use a single “Local” safety filter; stronger baselines (e.g., cost-guided diffusion, control barrier function layers, reachability filters from recent literature) are not included, leaving comparative advantages partially unsubstantiated.
- Statistical rigor: Evaluations use 20 rollouts per task without confidence intervals or statistical tests; ablation studies (e.g., w.r.t.
w,T_f,p,d_th, and cost weights λ_s, λ_c, λ_f) are limited, making it hard to assess robustness and sensitivity. - Metric completeness: Smoothness is measured via integrated squared jerk on the executed trajectory; additional metrics (e.g., maximum jerk, frequency-domain smoothness, human-rated smoothness, energy/torque usage, and contact stability) could provide a fuller picture.
- Parameter disclosure and reproducibility: Critical hyperparameters and implementation details are unspecified (e.g.,
P_δ,p,w,d_th, safety margins_m, obstacle mapping modules, and all optimization weights). Clear disclosure and ablations are needed for reproducibility and deployment. - Human and regulatory safety: No discussion of human-robot interaction risks, fail-safe behaviors, certification constraints, or formal safety assurances in shared workspaces.
- Long-horizon task structure: The framework does not explicitly model task graphs or hierarchical subgoals; extending the goal head and planner to multi-step task decomposition and recovery from mid-task failures is an open problem.
- Integration with language/semantic goals: The goal head is purely demonstration-driven; how to incorporate language or semantic conditioning for goal specification and disambiguation is unexplored.
- Adaptation and online learning: There is no mechanism for online adaptation to new obstacles, tools, or task variants (e.g., test-time adaptation, residual learning, or self-supervised refinement), leaving long-term deployment robustness open.
Practical Applications
Overview
Based on the LAGO Policy framework—combining latency-aware classifier-free guidance (LA-CFG), goal-directed collision-free trajectory generation, and spatial-temporal optimization—below are practical, real-world applications spanning industry, academia, policy, and daily life. Each item specifies use cases, sectors, possible tools/products/workflows, and feasibility assumptions or dependencies.
Immediate Applications
These can be deployed with current hardware/software stacks (e.g., ROS2, RGB-D perception, common robot arms) and are validated by the paper’s real-world experiments.
- Bold, low-jerk pick-and-place and kitting in cluttered workcells (Manufacturing, Logistics)
- What: Smooth, continuous, collision-free pick/place and kitting in bins or shelves, even with unforeseen obstacles or latency in compute.
- Tools/products/workflows: ROS2 nodes for LAGO Policy; MoveIt2 integration as a “policy + planner” plugin; occupancy mapping via OctoMap/voxblox/nvblox; GPU-enabled DDIM sampling; B-spline optimizer (EGO-inspired) and MINCO-based smoothing.
- Assumptions/dependencies: Calibrated multi-view RGB-D camera setup; sufficiently accurate workspace occupancy; consistent robot drivers at ≥100–250 Hz; moderate GPU for diffusion inference; guidance scale and optimizer weights tuned per task.
- Delicate fluid handling (pouring, cup transfer) with minimal spill (Food & Beverage, Service Robotics, Healthcare)
- What: Smooth liquid pouring and cup transport with low jerk and inter-chunk consistency (validated by Cup Transfer and Pouring tasks).
- Tools/products/workflows: “SmoothOps” trajectory post-processing using MINCO; LA-CFG enabled asynchronous inference to avoid “stop-and-go.”
- Assumptions/dependencies: Stable gripper actuation; good state estimation around handles/containers; liquid slosh constraints modeled via jerk and acceleration limits.
- Contact-rich insertion (e.g., pen insertion, pegs, connectors) with latency-robust control (Manufacturing, Electronics)
- What: Reduce discontinuities at chunk boundaries to avoid misalignment and maintain contact stability during insertions.
- Tools/products/workflows: LAGO Policy controller with LA-CFG; optional force/torque sensing for added robustness; fixture-specific goal extraction during demonstrations.
- Assumptions/dependencies: Accurate pose estimation of target receptacle; verified gripper compliance and action limits.
- Drawer/door/box organizing with smooth transitions in repetitive cycles (Warehousing, Retail Automation)
- What: Robust execution when visually similar states cause ambiguity (e.g., opening/closing drawers repeatedly).
- Tools/products/workflows: Future-action conditioning via LA-CFG to stabilize mode selection; policy wrappers in ROS2.
- Assumptions/dependencies: Reliable depth sensing in partially occluded scenes; annotated or auto-extracted “interaction goals.”
- Deformable object handling (e.g., towel folding) with consistent gripper commands (Manufacturing, Domestic Robotics)
- What: Reduce failed grasps and mid-transport gripper opens by improving temporal consistency in actions.
- Tools/products/workflows: LAGO Policy drop-in replacement for standard Diffusion Policy; pipeline for collecting teleoperation demonstrations and training with delay randomization.
- Assumptions/dependencies: Demonstrations capture stable grasps and fold strategies; gripper hardware can maintain commanded force.
- Local obstacle avoidance wrapped around learned policies without retraining (Cross-sector)
- What: Use goal-directed trajectory generation as a safety/feasibility layer for existing diffusion policies to avoid collisions with unseen obstacles.
- Tools/products/workflows: “SafeReach Planner” module—B-spline optimization guided by A* over a live occupancy map; plug-in safety layer for current GCPs.
- Assumptions/dependencies: Online obstacle mapping with sufficient refresh rate; ESDF-free planning requires good surface distance estimates and reachable anchor points.
- Cost-effective continuous execution on modest compute (SMEs, Education)
- What: Asynchronous inference maintains continuous motion with slower GPUs; LA-CFG mitigates misalignment from latency.
- Tools/products/workflows: Prebuilt LAGO Policy Docker image; Jetson-class deployment with reduced denoise steps; performance monitors for CON/ISJ metrics.
- Assumptions/dependencies: Acceptable degradation in inference speed; carefully tuned horizons (Tp, Ta, Tf) for the platform.
- Robust teleoperation playback and demonstration smoothing (Academia, Training, Teleoperation)
- What: Use spatial-temporal optimization to smooth recorded teleop trajectories and compensate for network/control delays.
- Tools/products/workflows: “Latency Shield” training augmentation (delay randomization) + MINCO smoothing during replay; logging tools for CON/ISJ.
- Assumptions/dependencies: Synchronized logs; accurate time-stamping; compatible teleop hardware.
- Classroom/lab adoption for research and teaching (Academia)
- What: A reproducible stack to study asynchronous diffusion policies, delay-aware conditioning, and planning-policy integration.
- Tools/products/workflows: Open-source code for LA-CFG; benchmarks and scripts for goal labeling; ROS2/Isaac Sim examples.
- Assumptions/dependencies: Access to a 6–7 DoF arm, RGB-D sensors, and a mid-range GPU.
- HRI-friendly co-bots with improved perceived safety (Workplace Safety, Policy/Standards)
- What: Low-jerk, continuous trajectories that feel safer near humans and reduce sudden movements.
- Tools/products/workflows: Exportable jerk and continuity metrics (e.g., ISJ, CON) as interpretable safety KPIs; dashboards for compliance checks.
- Assumptions/dependencies: Complementary safety layers (CBFs, speed/torque limits); alignment with ISO 10218/TS 15066 guidelines.
Long-Term Applications
These require further research, broader validation, scaling, or additional components (e.g., new sensors, certification, or larger datasets).
- Whole-arm and tool-level collision-aware motion planning integrated with policy (Manufacturing, Construction, Healthcare)
- What: Extend from end-effector spheres to full-body + tool geometries; integrate self-collision and multi-link constraints.
- Tools/products/workflows: Coupling with whole-body planners (MoveIt2, TrajOpt/TOMP); mesh-based SDFs; tighter controller integration.
- Assumptions/dependencies: Real-time signed distance fields; accelerated collision checking; robust parameter tuning for high-DoF constraints.
- Mobile manipulation with base-arm coordination under latency (Logistics, Field Robotics)
- What: Consistent, smooth control across base and manipulator, with goal-directed avoidance at the system level.
- Tools/products/workflows: Multi-agent LA-CFG; shared goal prediction; global planning across SE(2)/SE(3) state spaces.
- Assumptions/dependencies: Unified mapping across base and arm; multi-sensor calibration; additional compute.
- Cloud/edge robotics with variable network delays (Cloud Robotics, Telepresence)
- What: Robust execution with cloud inference by training for wide delay distributions and tighter CFG control.
- Tools/products/workflows: Latency-adaptive sampling schedules; fallback local planners; QoS-aware pipeline.
- Assumptions/dependencies: Reliable cloud-edge links; security and privacy compliance; safe fallbacks on link loss.
- Generalizable goal prediction across tasks via self-supervised labels and language grounding (Software, Education, Robotics)
- What: Auto-extract/learn task goals from demos; condition goal prediction with language to generalize across new tasks.
- Tools/products/workflows: “GoalBridge” toolkit for automatic goal labeling/verification; optional VLM integration.
- Assumptions/dependencies: High-quality multi-task datasets; robust grounding from vision-LLMs; interpretability tools.
- Certified safety wrappers with formal guarantees (Policy/Standards, Healthcare, Collaborative Robotics)
- What: Combine global goal-directed planning with CBFs/reachability (e.g., RAIL) for certifiable safe behavior.
- Tools/products/workflows: Verification toolchains producing formal safety bounds; instrumentation for audit trails.
- Assumptions/dependencies: Formal models of robot and environment; certification agency engagement; additional runtime overhead.
- Multi-robot coordination with latency-aware consistency (Manufacturing, Warehousing)
- What: Synchronize chunked diffusion policies across multiple manipulators to avoid mutual interference and deadlocks.
- Tools/products/workflows: Shared goal maps; conflict-aware planning; inter-robot LA-CFG signals.
- Assumptions/dependencies: High-fidelity shared occupancy; low-latency inter-robot comms; scheduling policies.
- Hardware-aware policy distillation for embedded deployment (Edge AI, Cost Reduction)
- What: Distill LAGO’s diffusion policy + planning into lightweight networks for PLCs or microcontrollers while preserving smoothness.
- Tools/products/workflows: Knowledge distillation; denoising step reduction; quantization/pruning pipelines.
- Assumptions/dependencies: Task-specific re-training; acceptance of slight performance loss; model compression expertise.
- Dynamic obstacle handling with prediction and human-motion forecasting (HRI, Service Robotics)
- What: Integrate obstacle motion prediction to preemptively optimize trajectories toward goals.
- Tools/products/workflows: Online human-motion forecasting fused into collision terms; time-parameterized safety margins.
- Assumptions/dependencies: Additional perception for human tracking; ethical and privacy considerations; real-time performance.
- Energy-aware and wear-minimizing manipulation (Sustainability, Operations)
- What: Optimize for low jerk/acceleration to reduce power peaks and mechanical stress; schedule tasks for minimal wear.
- Tools/products/workflows: Energy and maintenance cost in objective functions; telemetry-based monitoring.
- Assumptions/dependencies: Accurate energy models; controller support for smooth time-scaling; long-term fleet analytics.
- Cross-domain transfer of LA-CFG to other sequential diffusion systems (Academia, Software)
- What: Use delay-randomized conditioning in speech, video, or time-series control where latency shifts cause artifacts.
- Tools/products/workflows: LA-CFG libraries for general diffusion models; benchmark suites for latency robustness.
- Assumptions/dependencies: Availability of temporally aligned conditions; clear definitions of “future action/state” analogs.
- Assistive and medical manipulation under regulated environments (Healthcare, Assistive Tech)
- What: Safe fetching, placement, and fluid handling near patients; smoother motions to increase comfort and trust.
- Tools/products/workflows: Full-stack safety case, including redundancy and fail-safes; clinical validation trials.
- Assumptions/dependencies: Regulatory approval (FDA/CE); medically compliant hardware; stringent reliability and monitoring.
- Advanced digital twin workflows for policy+planner co-design (Industry 4.0, Simulation)
- What: Co-simulate LA-CFG policies with goal-directed planners to validate throughput and safety before deployment.
- Tools/products/workflows: Isaac Sim/Gazebo with voxel maps; automated scenario generation; performance dashboards (CON/ISJ/SR).
- Assumptions/dependencies: Realistic simulation fidelity; domain gap mitigation; robust sim2real transfer strategies.
Notes on feasibility across applications:
- Sensor requirements: Multi-view RGB-D and/or wrist camera, calibration, and reliable occupancy mapping are critical today.
- Data: Task-specific demonstrations with annotated or auto-extracted interaction goals are needed to train the goal predictor.
- Compute: Real-time DDIM sampling (e.g., 8 steps) on a GPU-class device; tuning of horizons and guidance scales.
- Control: Controllers must enforce action/velocity/acceleration limits to realize low jerk in hardware.
- Safety: For human-facing settings, additional certified safety layers remain necessary beyond LAGO’s collision-aware planning.
Glossary
- A: A graph search algorithm that finds least-cost paths using heuristics. "A provides a collision-free connector , from which pairs guide optimization to a smooth collision-free trajectory ."
- Action chunk: A short sequence of consecutive actions produced or executed together by a policy. "policies are typically deployed with asynchronous inference, where the next action chunk is generated in parallel while the robot executes the current one."
- Asynchronous inference: Running model inference in parallel with execution to avoid pauses, which can introduce timing misalignments. "Diffusion-based visuomotor policies deployed with asynchronous inference often exhibit inter-chunk discontinuities and lack explicit mechanisms for obstacle-aware execution"
- B-spline: A smooth, piecewise polynomial curve used to parameterize trajectories via control points. "The end-effector position trajectory is parameterized by a uniform B-spline curve whose decision variables are the control points :"
- CFG dropout: Training trick for classifier-free guidance where the condition is randomly dropped so a single network learns both conditional and unconditional denoising. "To train a single noise-prediction network for both conditional and unconditional denoising, we adopt the CFG dropout scheme~\cite{ho2022classifier}."
- Classifier-Free Guidance (CFG): A conditioning method that mixes conditional and unconditional denoising predictions to steer samples toward a condition. "For smooth and temporally consistent execution, we introduce a latency-aware training scheme with classifier-free guidance (CFG)~\cite{ho2022classifier}."
- Closed-loop: A control setup that continuously uses feedback from observations during execution. "In this context, generative control policies (GCPs) instantiate closed-loop visuomotor controllers via generative models"
- Collision cost: A penalty term in optimization that increases when trajectories intersect obstacles, encouraging clearance. "The collision cost for each control point is accumulated over its associated pairs, and the overall collision cost is"
- Collision-free feasible set: The subset of states or trajectories that satisfy non-collision constraints. "Since most GCPs are trained to imitate demonstrations without explicitly modeling the collision-free feasible set"
- Control barrier functions: Formal safety constraints that ensure states remain within safe sets during control. "VLSA integrates control barrier functions as a safety layer to enforce explicit state constraints~\cite{hu2025vlsa}."
- DDIM: A deterministic or low-variance diffusion sampling procedure that accelerates generation. "At inference, we use DDIM \cite{song2020denoising} sampling to efficiently generate an action sequence"
- DDPM: Denoising Diffusion Probabilistic Models; a diffusion framework that learns to reverse a noise process. "Diffusion Policy adopts a DDPM \cite{ho2020denoising} denoising formulation."
- Demonstration manifold: The distribution of states and behaviors observed in expert demonstrations that policies aim to mimic. "push execution away from the demonstration manifold"
- Denoising: Iteratively removing noise from a sample to reconstruct a clean signal in diffusion models. "diffusion-based policies generate actions through iterative denoising"
- Diffusion Policy: A visuomotor policy approach that models action sequences with conditional diffusion. "In imitation learning, Diffusion Policy models a closed-loop visuomotor controller via conditional action diffusion and executes in a receding-horizon manner to preserve reactivity"
- Distribution shift: A mismatch between training and deployment distributions that can degrade performance. "causing safety-induced distribution shift and compounding errors under closed-loop execution."
- End-effector: The robot’s tool or gripper at the end of the manipulator used to interact with the environment. "The end-effector is approximated as a collision sphere centered at the current position with radius ."
- FiLM: Feature-wise linear modulation; a conditioning layer that modulates network activations by external features. "the observation features are fused to the policy network through FiLM \cite{perez2018film}."
- Future-action condition: A short segment of previously planned but unexecuted actions used to guide current denoising. "we extract a length- subsequence from this unexecuted segment starting at and define it as the future-action condition for the current cycle: ."
- Generative control policies (GCPs): Controllers that use generative models to produce action sequences conditioned on observations. "In this context, generative control policies (GCPs) instantiate closed-loop visuomotor controllers via generative models"
- Global Average Pooling (GAP): A pooling operation that averages features across spatial or temporal dimensions to create fixed-length vectors. "Global average pooling (GAP) is applied to to average over the action-horizon axis"
- Goal-conditioned trajectory optimization: Planning that optimizes a motion toward a specified goal while enforcing constraints like collision avoidance. "we activate goal-conditioned trajectory optimization to generate a smooth collision-free motion toward the predicted goal."
- Guidance scale: A scalar that controls how strongly the conditional prediction influences the guided denoising. "CFG is a guidance technique for conditional diffusion models that strengthens adherence to a condition by combining conditional and unconditional denoising predictions during sampling with a tunable guidance scale."
- Imitation learning: Learning control policies by mimicking expert demonstrations. "visuomotor imitation learning has emerged as a scalable paradigm for acquiring robotic manipulation skills directly from expert demonstrations"
- Integrated Squared Jerk (ISJ): A smoothness metric computed as the time integral of squared jerk along a trajectory. "Smoothness is quantified by the integrated squared jerk (ISJ) of the executed action trajectory:"
- Jerk: The time derivative of acceleration; a measure of how quickly acceleration changes, related to motion smoothness. "Finally, spatial-temporal trajectory optimization refines the actions to be executed for low-jerk and feasible motion."
- Latency-aware: Accounting for delays between prediction and execution in model design or training. "we introduce a latency-aware training scheme with classifier-free guidance (CFG)~\cite{ho2022classifier}."
- Line-of-sight collision check: A straight-line feasibility test that verifies the path between two points is free of obstacles. "We perform a line-of-sight collision check along the straight segment from to "
- MINCO: An optimization framework for generating smooth, feasible trajectories under geometric constraints. "The optimization is solved efficiently using MINCO \cite{wang2022geometrically}, and the optimized trajectory is resampled for execution."
- Noise-prediction network: The model component in diffusion that estimates the noise added at each step to enable denoising. "The reverse process is parameterized by a noise-prediction network ."
- Observation conditioning: The set of encoded observations provided to the policy or denoiser as context. "Given a noisy action sequence at diffusion step and the observation conditioning "
- Perception-execution misalignment: A timing mismatch where actions are conditioned on stale observations relative to execution time. "This creates a perception-execution misalignment because each chunk is conditioned on observations acquired before inference, but is executed after inference finishes"
- Proprioceptive features: Internal sensor signals (e.g., joint positions) describing the robot’s own state. "tightly coupling with the history of visual and proprioceptive features."
- Receding-horizon: A control strategy that plans over a horizon but executes only the first portion before replanning. "Diffusion Policy models a closed-loop visuomotor controller via conditional action diffusion and executes in a receding-horizon manner to preserve reactivity"
- Reachability-based safety filter: A safety mechanism that checks if future states remain in a safe set and modifies actions when necessary. "RAIL applies a reachability-based safety filter that validates candidate motions and switches to a safe fallback when violations are detected"
- Signed distance: A scalar giving the distance to an obstacle with sign indicating inside/outside relative orientation. "forming a signed distance ."
- Spatial-temporal trajectory optimization: Refinement that optimizes both the shape (space) and timing (time allocation) of a trajectory under constraints. "Finally, spatial-temporal trajectory optimization refines the actions to be executed for low-jerk and feasible motion."
- Task-space: A space defined by meaningful operational coordinates (e.g., end-effector pose) rather than joint angles. "we generate a task-space end-effector motion toward ."
- Teleoperation: Human control of a robot remotely to provide demonstrations or direct operation. "Expert demonstrations for all tasks are collected via human teleoperation."
- Trajectory optimization: The process of finding a trajectory that minimizes a cost while satisfying constraints. "we propose LAGO Policy, a unified asynchronous action-generation framework that integrates trajectory optimization with diffusion policy for smooth and safe execution."
- U-Net: A convolutional neural network architecture with encoder–decoder and skip connections, used here in the denoiser. "we attach a goal-prediction head to the denoising U-Net~\cite{ronneberger2015u} to predict a task-relevant goal"
- Visuomotor: Relating vision inputs to motor commands in a control policy. "visuomotor imitation learning has emerged as a scalable paradigm for acquiring robotic manipulation skills directly from expert demonstrations"
Collections
Sign up for free to add this paper to one or more collections.

