- The paper introduces Jolia, a model that applies LLM-driven concept-level decomposition to align 3D CT scans with radiology reports without needing segmentation masks.
- The paper demonstrates significant performance gains, with AUROC improvements up to +2.4, through localized contrastive supervision and robust zero-shot classification.
- The paper enhances interpretability by generating organ-level attention maps that yield spatially coherent and anatomically precise feature embeddings.
Concept-Level Vision-Language Contrastive Learning for 3D CT: The Jolia Model
Motivation and Methodological Innovation
Traditional vision-language contrastive pretraining in medical imaging, particularly in CLIP-style frameworks, encodes both images and accompanying radiological reports as global tokens, omitting important anatomical and structural granularity. Radiology reports are notably longer and more structured than natural image captions, describing multiple organs (e.g., “Liver: cyst; Lungs: clear”) per study. This paper introduces ConQuer, a concept-level contrastive pretraining method, and its instantiation for 3D CT called Jolia. ConQuer augments CLIP’s global alignment with parallel, localized alignments for each concept (here, anatomical regions). It decomposes reports using LLMs into concept-specific sections and learns cross-attention queries to pool corresponding image features. Importantly, ConQuer achieves spatial interpretability and anatomical localization without explicit segmentation masks or spatial supervision.
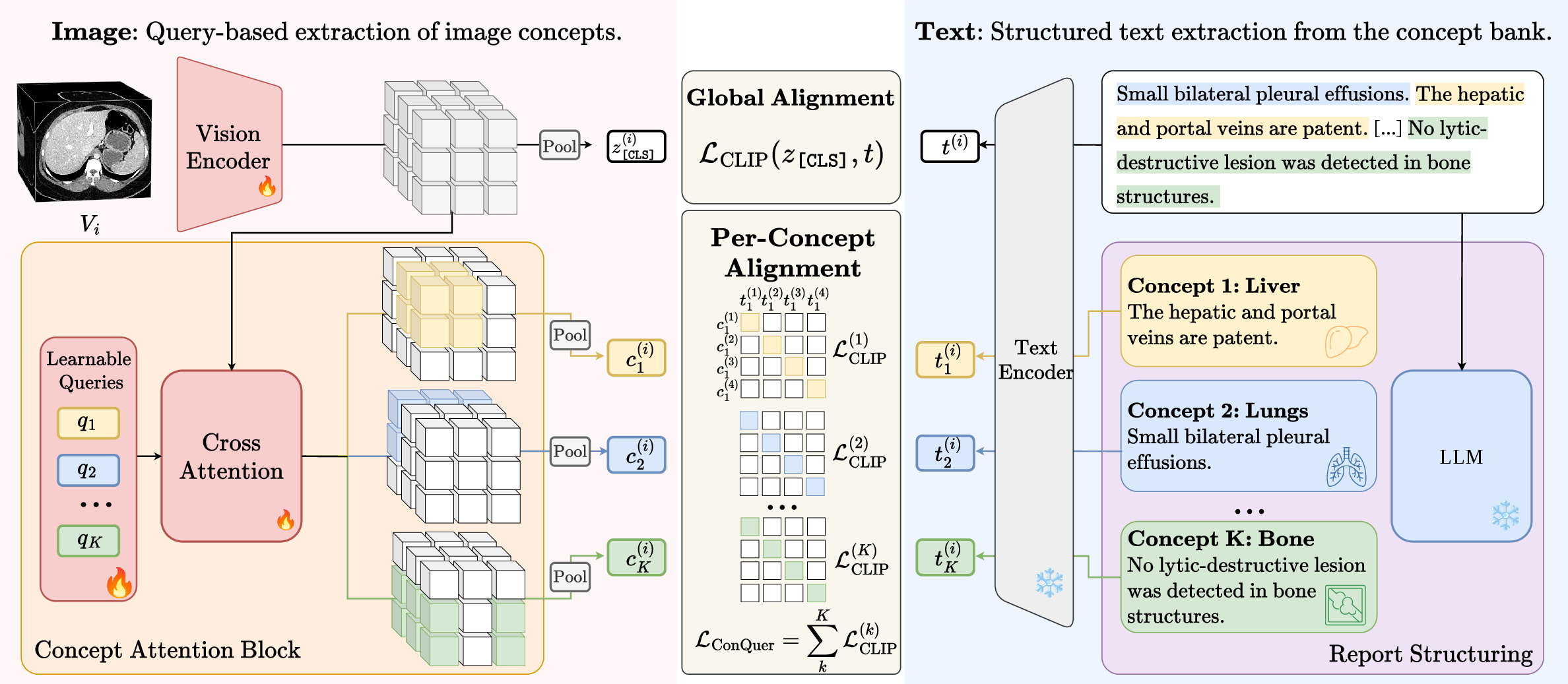
Figure 1: Overview of ConQuer. Paired CT scans and reports are decomposed into concept-level representations and aligned via contrastive objectives for both global and per-concept tokens.
Data Processing and Concept Decomposition
Jolia leverages an LLM-driven pipeline (GPT-5.2) to organize radiology reports into units corresponding to anatomical concepts, under a taxonomy of 102 regions. Each report is split into atomic, organ-tagged sentences, enabling systematic mapping of findings. This decomposition attains high precision and recall (≥0.95 on both chest and abdominal CTs), facilitating robust concept-level contrastive supervision. On the visual side, the model employs learnable cross-attention queries per concept to aggregate image features.
Model Architecture and Contrastive Objective
Jolia experiments with multiple 3D image encoder backbones (Atlas Transformer, ResNet-101, ViT-B), each producing patch-level features and a global [CLS] token. For each concept, a dedicated query token pools features via cross-attention across all scales. The text encoder (frozen Qwen3-Embedding-8B) embeds per-concept report sections and the global report. The composite training objective integrates symmetric InfoNCE contrastive loss per concept with a global CLIP loss, using learnable temperatures and concept masks to handle missing report sections. This forces each query to specialize anatomically and provides inherent spatial interpretability.
Evaluation Protocol
Jolia exposes three feature sets: the global [CLS] token, per-concept tokens, and their concatenation. Downstream tasks include linear probing, zero-shot classification (both short and long prompt variants), radiology report generation, and image-text retrieval. For findings classification, concept-anchored representations are used, pairing findings with relevant organ tokens.
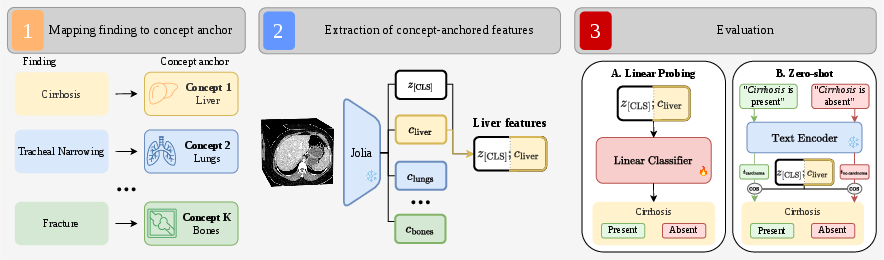
Figure 2: Evaluation protocol for findings classification and zero-shot: concatenation of [CLS] and relevant concept token forms the finding-anchored representation.
Jolia sets a new state of the art across findings classification, robustly outperforming CLIP baselines and segmentation-dependent models. Gains are most pronounced for anatomically localized findings. Linear probing shows Jolia’s combined [CLS]+Query representation improves AUROC by +1.7 to +2.4 on abdomen and +1.0 to +1.5 on chest compared to CLIP, with seed-to-seed variance markedly lower. Concept-grouping ablations indicate that even arbitrary grouping (k-means) improves performance, but anatomical taxonomies yield optimal results.
Zero-shot classification is evaluated with both template aggregation (“prompt sensitivity mitigation”) and LLM-constructed prototypes. Jolia demonstrates high robustness to prompt selection—unlike Merlin and Pillar-0, which see AUROC swings up to 24 points between templates. Long zero-shot (with report prototypes) further corroborates Jolia’s superior long-form comprehension over short-prompt tuned baselines.
Cross-center transfer learning confirms generalizability: Jolia outperforms all baselines under unified taxonomies when trained on one institution and evaluated on another, indicating resilience against domain shifts.
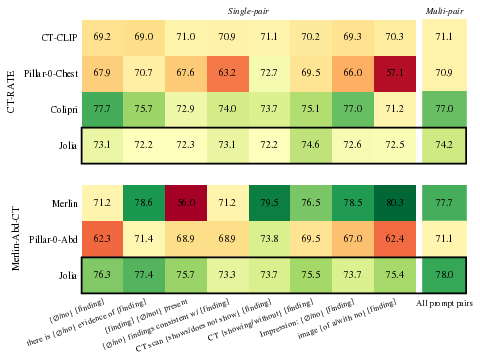
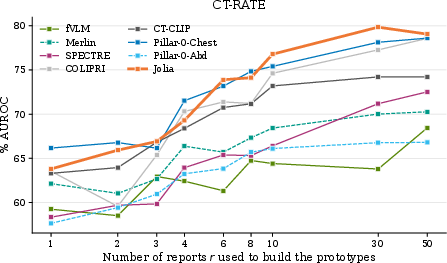
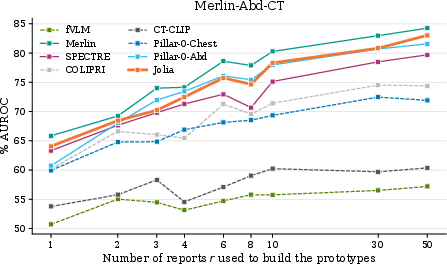
Figure 3: Zero-shot evaluation: (a) AUROC per template and in aggregate; (b) AUROC as a function of report prototype count, showing performance stabilization.
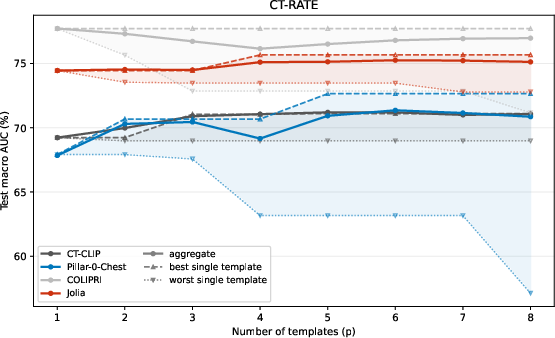
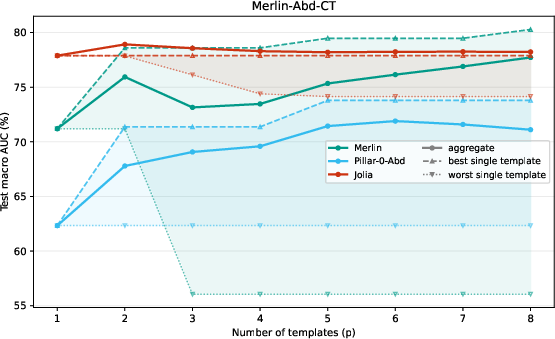
Figure 4: Aggregated zero-shot AUROC vs. prompt count; curves plateau at p≈4, confirming robustness of protocol.
Interpretability and Anatomical Localization
Each cross-attention query yields an attention map revealing anatomical focus without explicit spatial supervision. Compared to segmentation-based methods, Jolia’s maps are highly precise for most organs. PCA visualizations of the feature maps reveal that Jolia produces spatially coherent, anatomically distinctive embeddings, outperforming both CLIP and other foundation models on spatial structure.
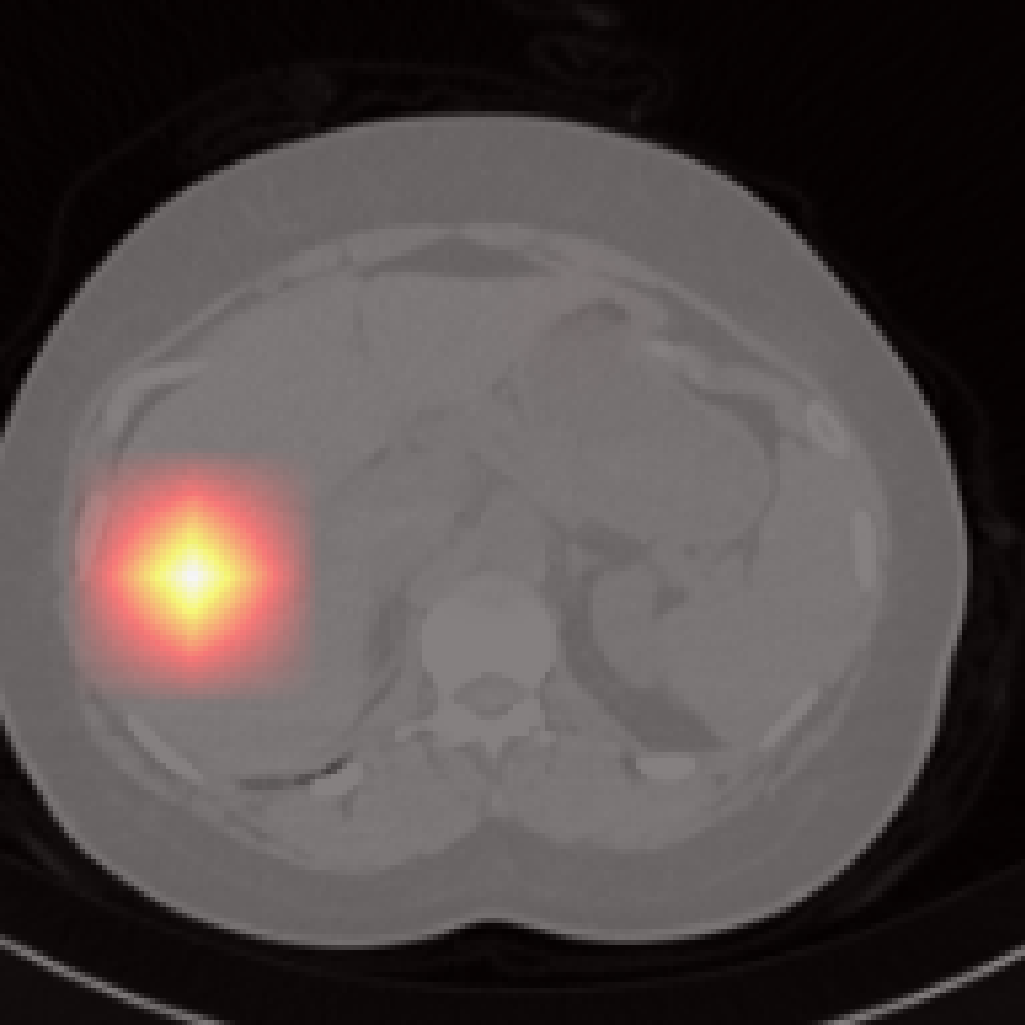
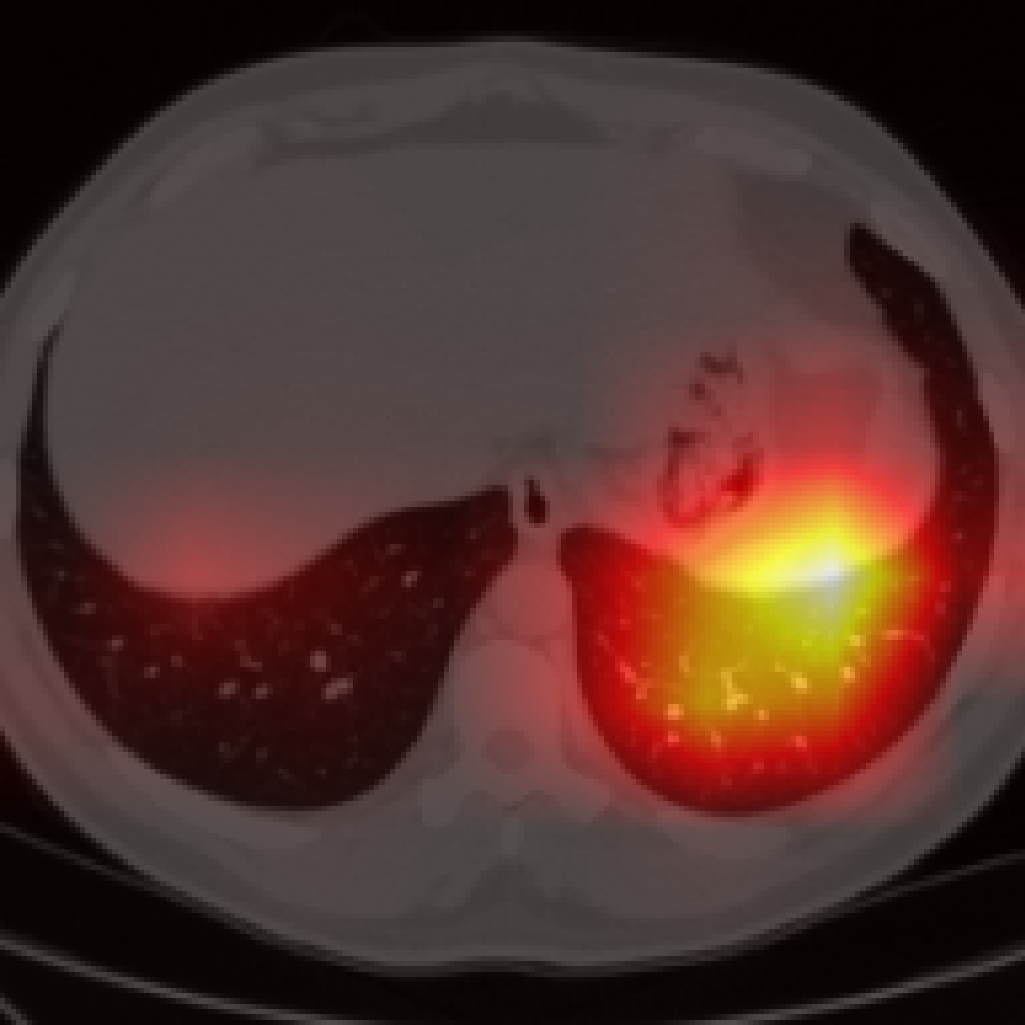
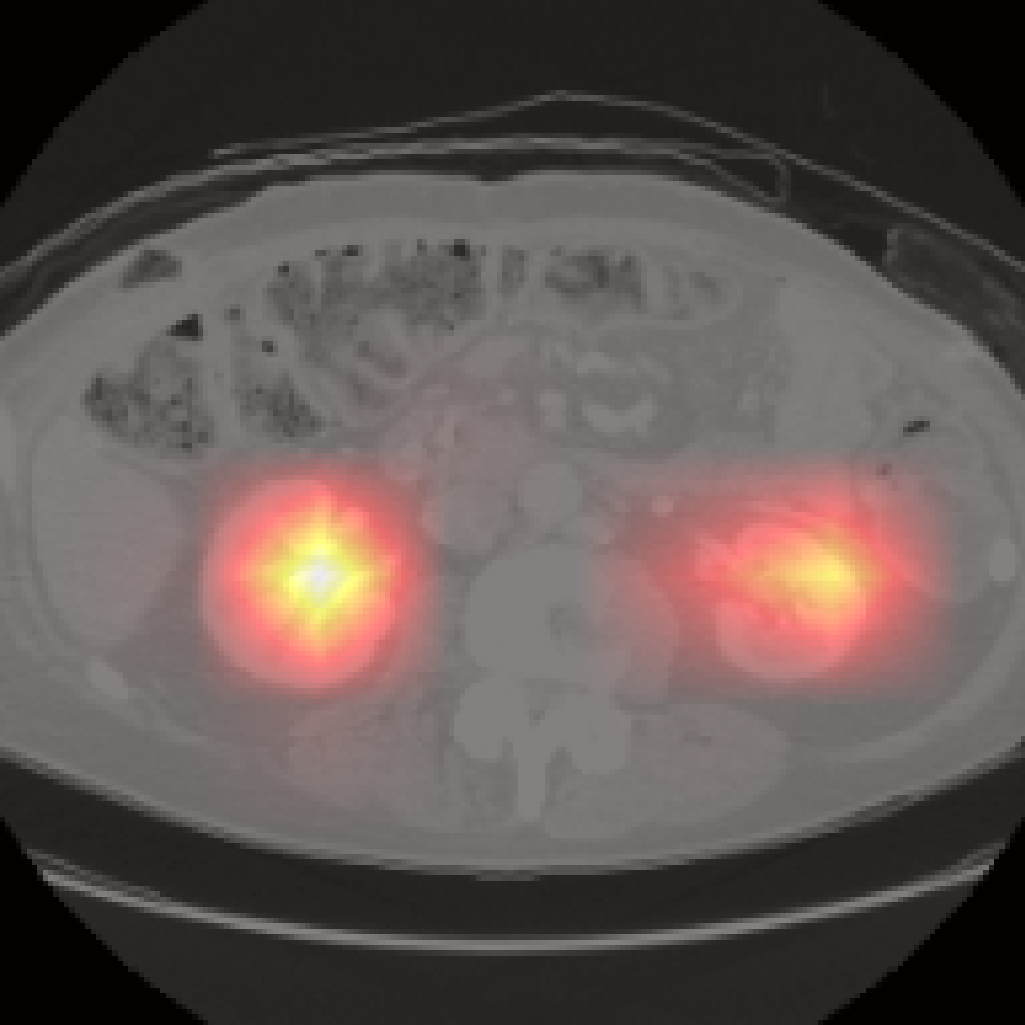
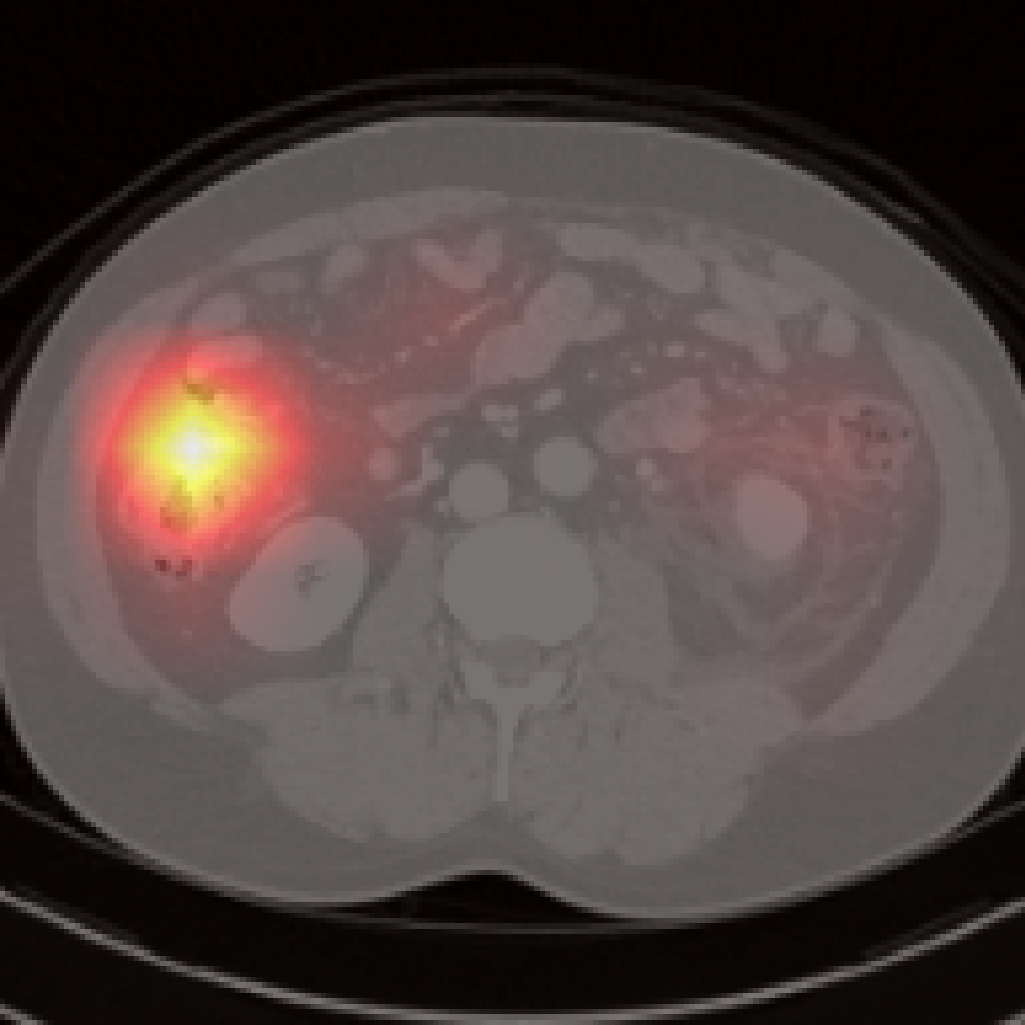
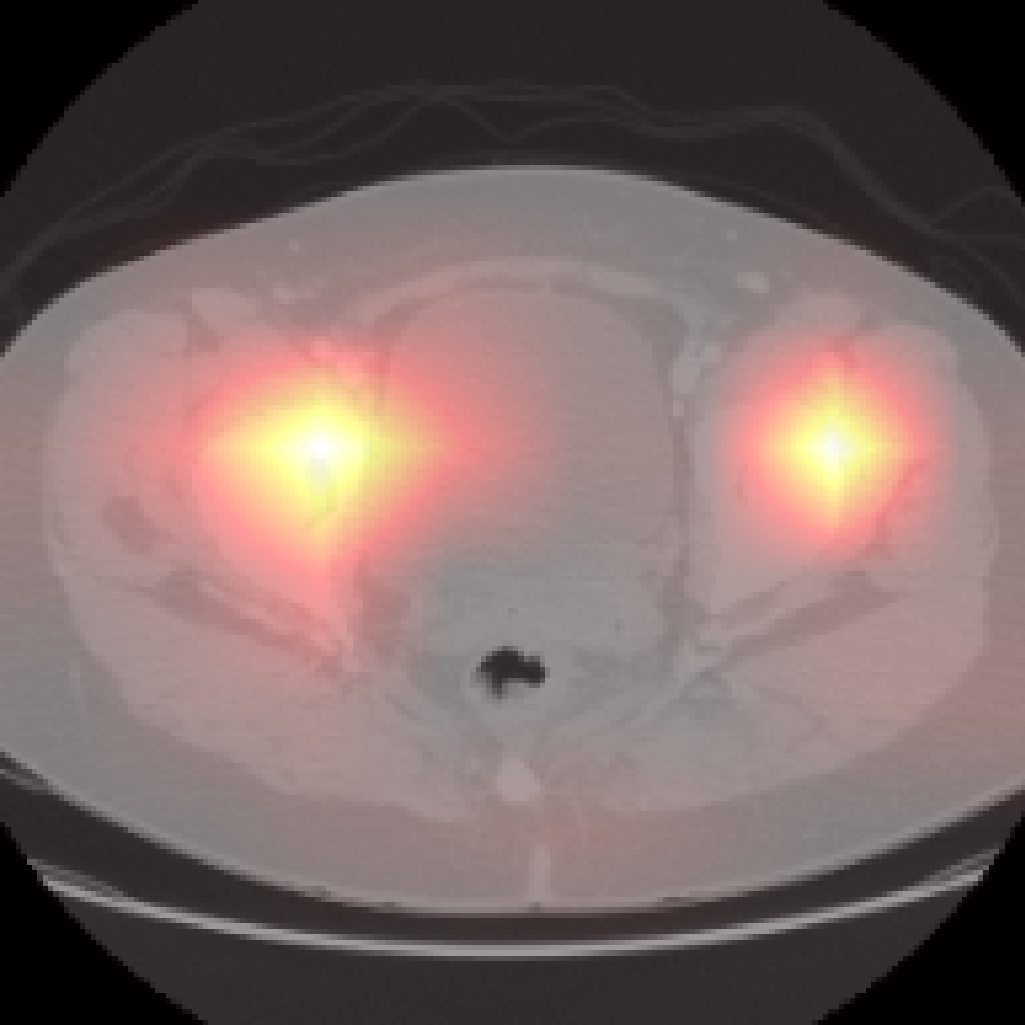
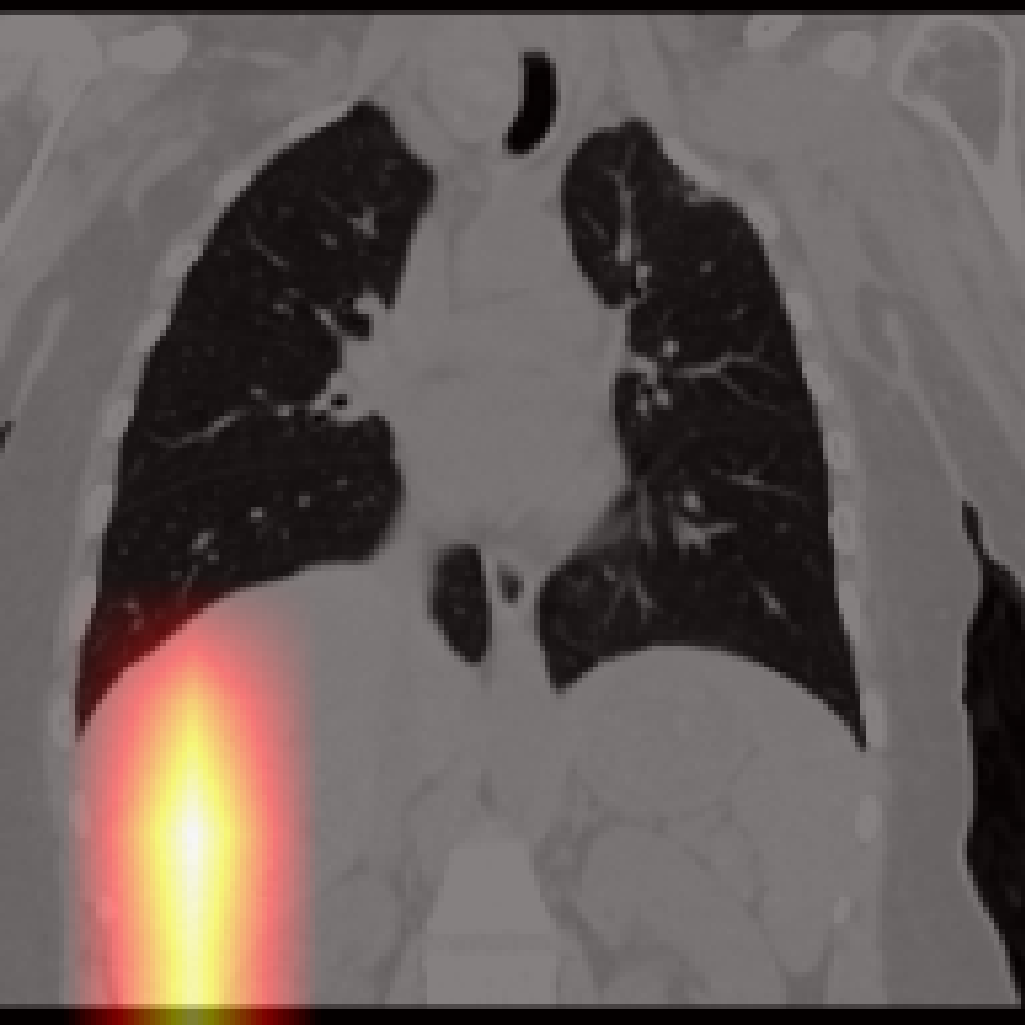
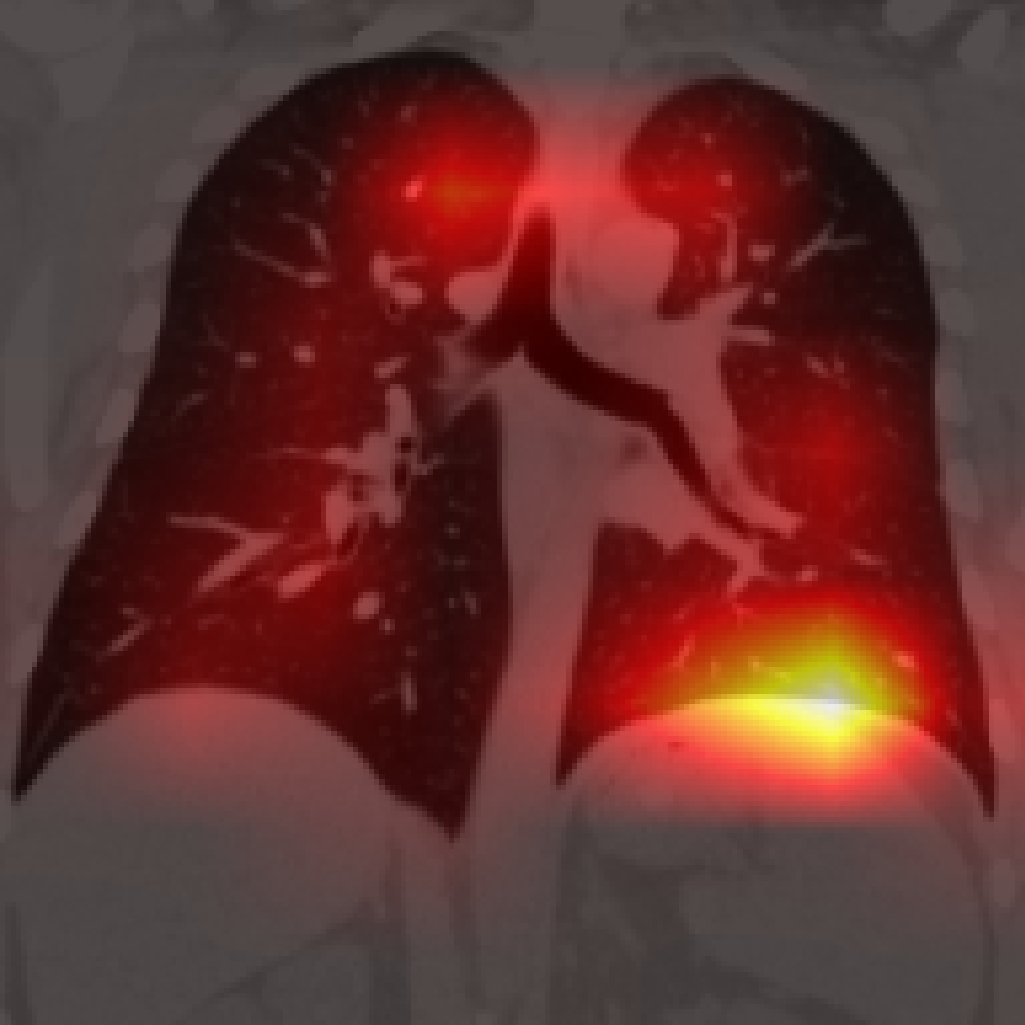
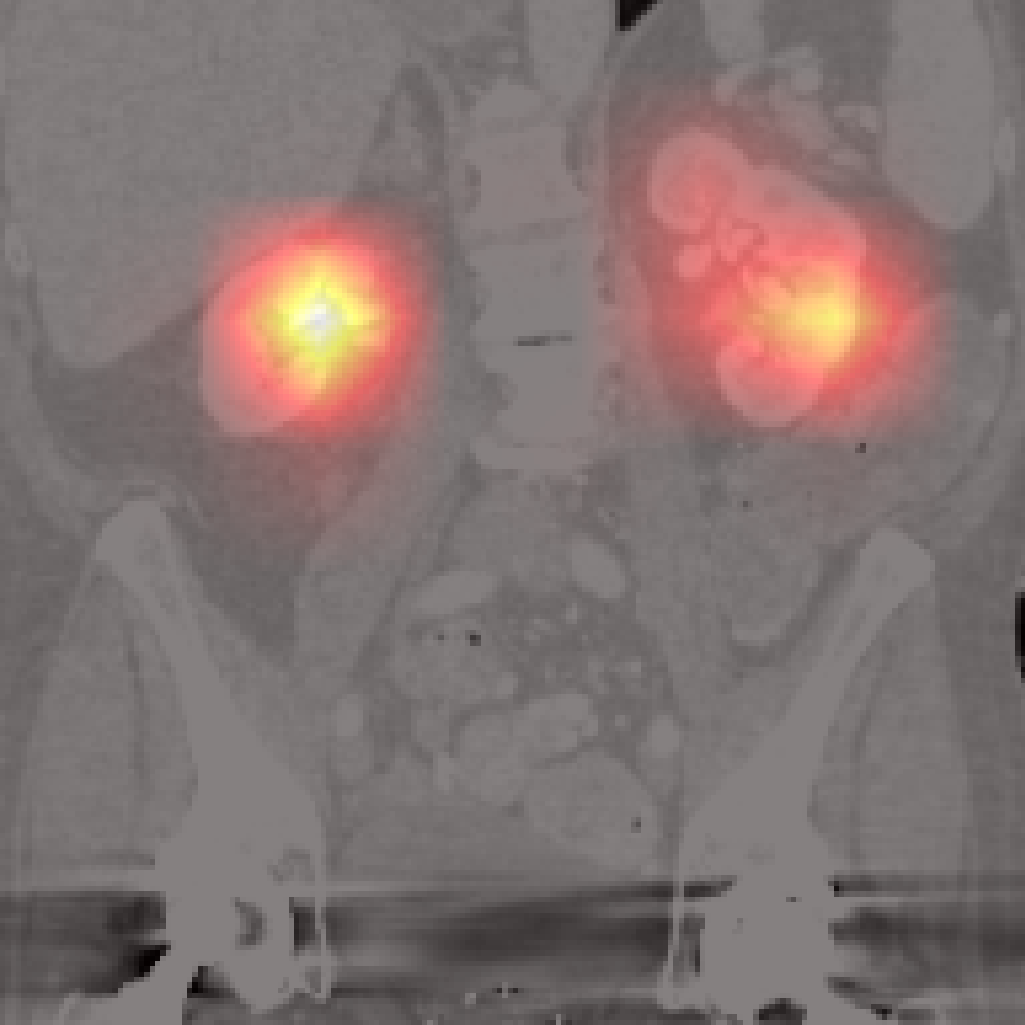
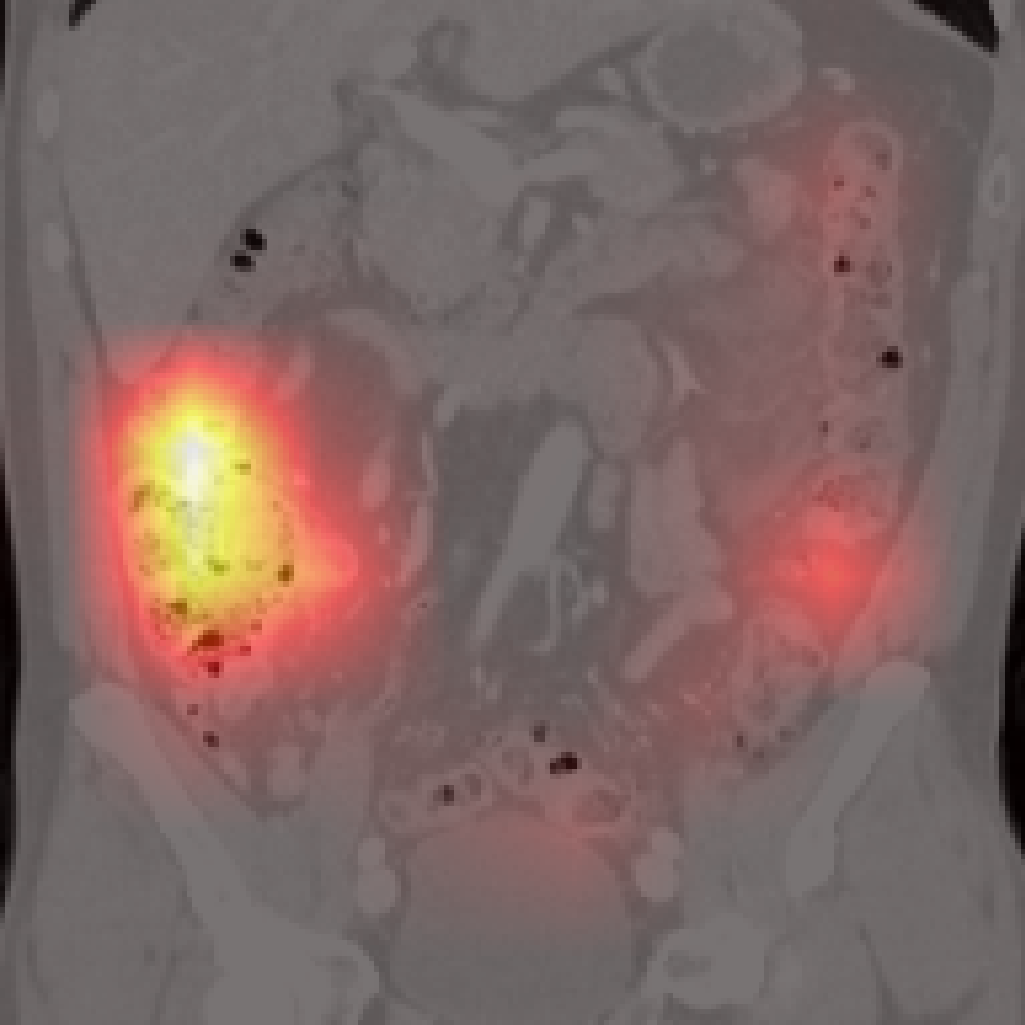
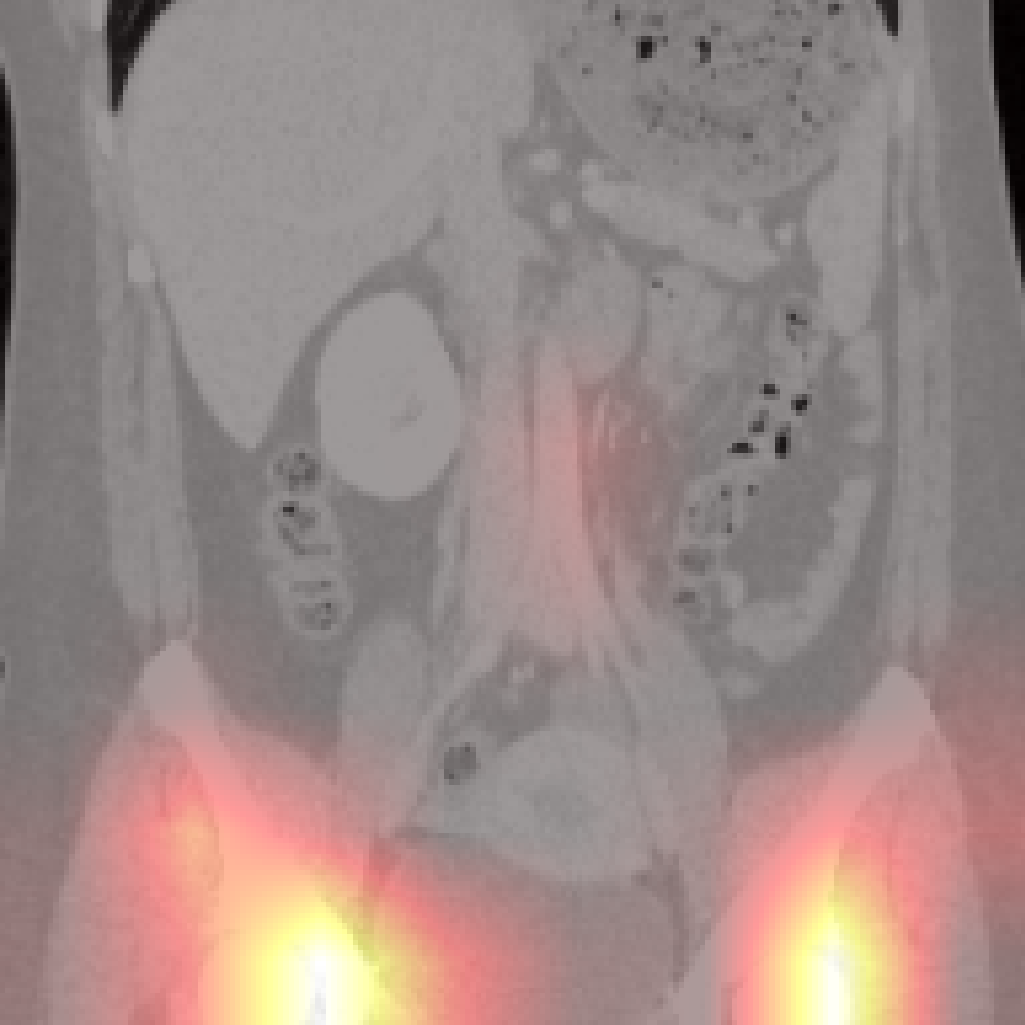
Figure 5: Organ-level attention maps. Cross-attention query maps demonstrate anatomically meaningful focus for each concept.
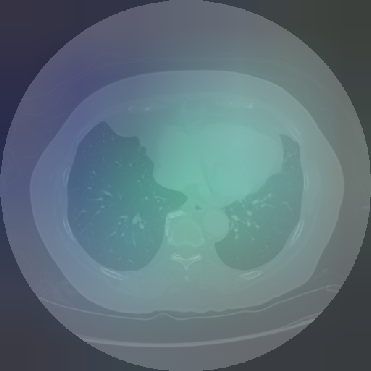
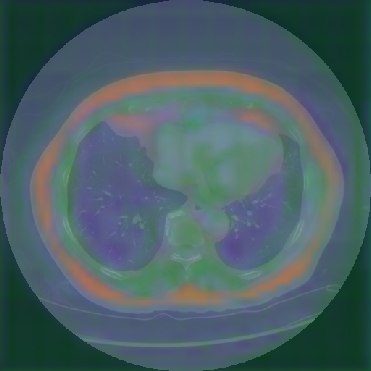
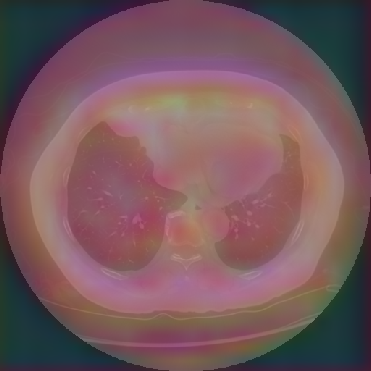
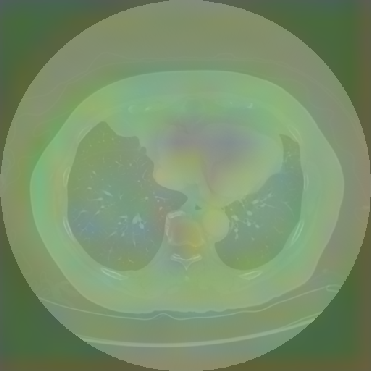
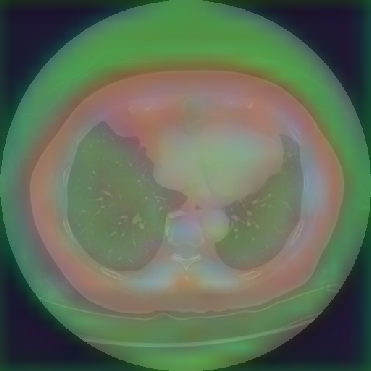

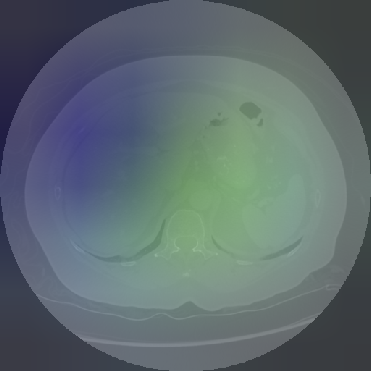
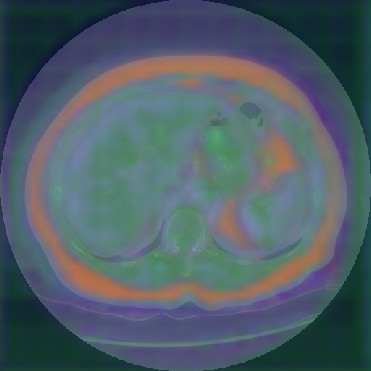



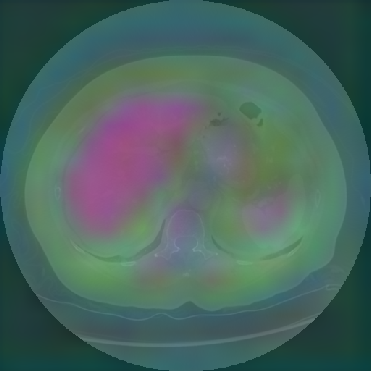

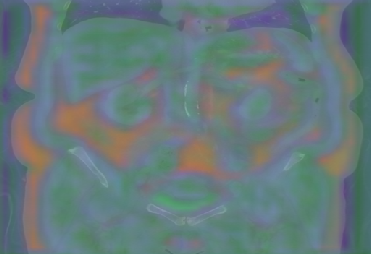



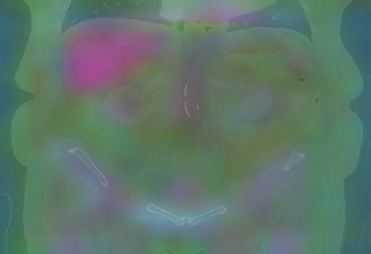
Figure 6: Principal Component Analysis Visualization. Jolia yields the most spatially structured feature maps across all views.
However, there are limitations for small or adjacent structures (pancreas, spleen), where localization is less precise due to weaker contrastive signal and frequent absence of abnormal findings.
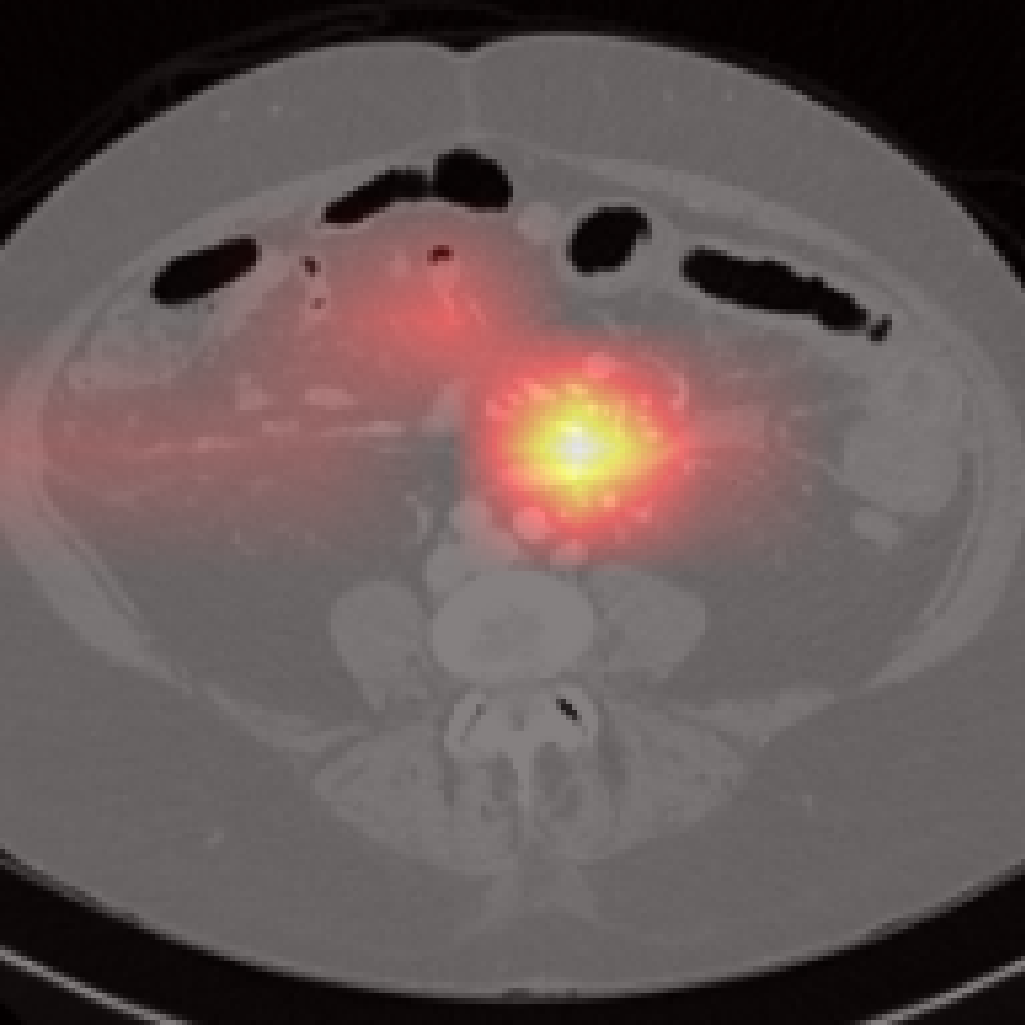
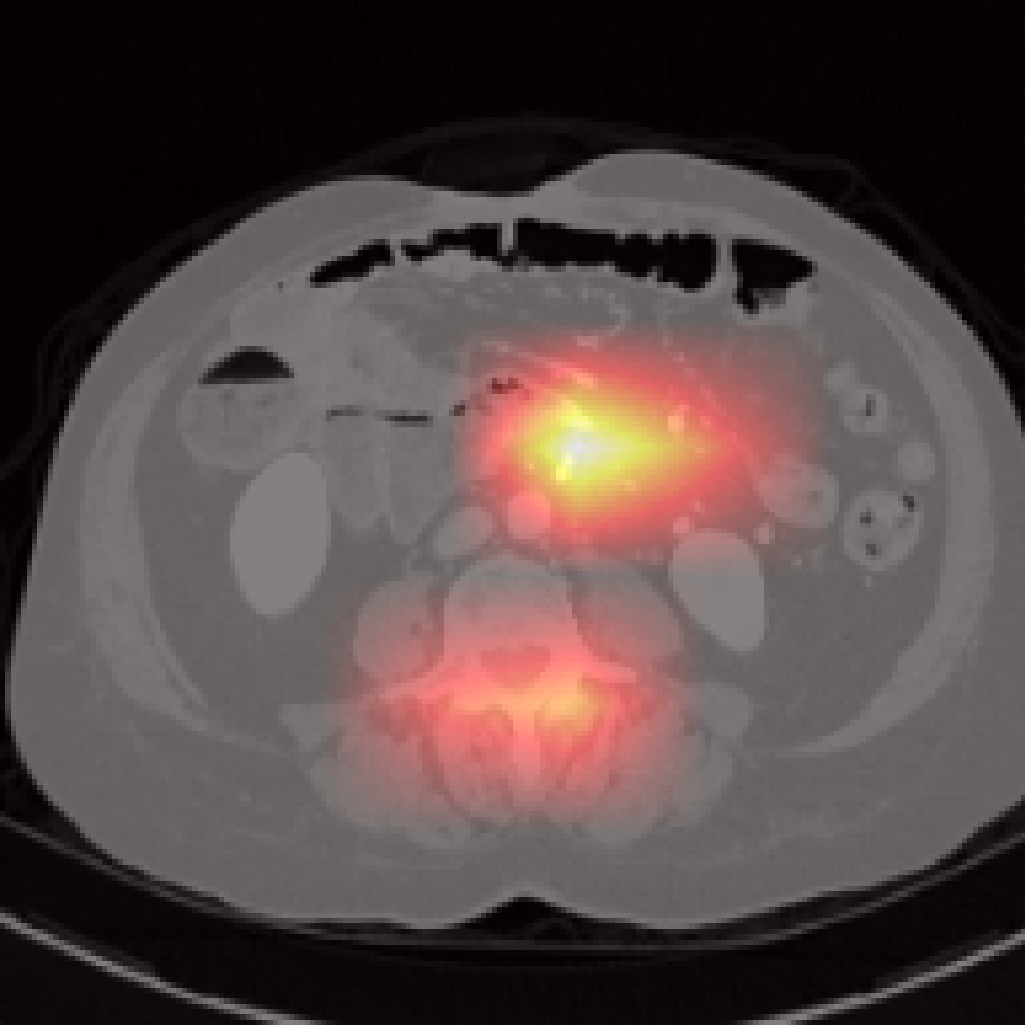
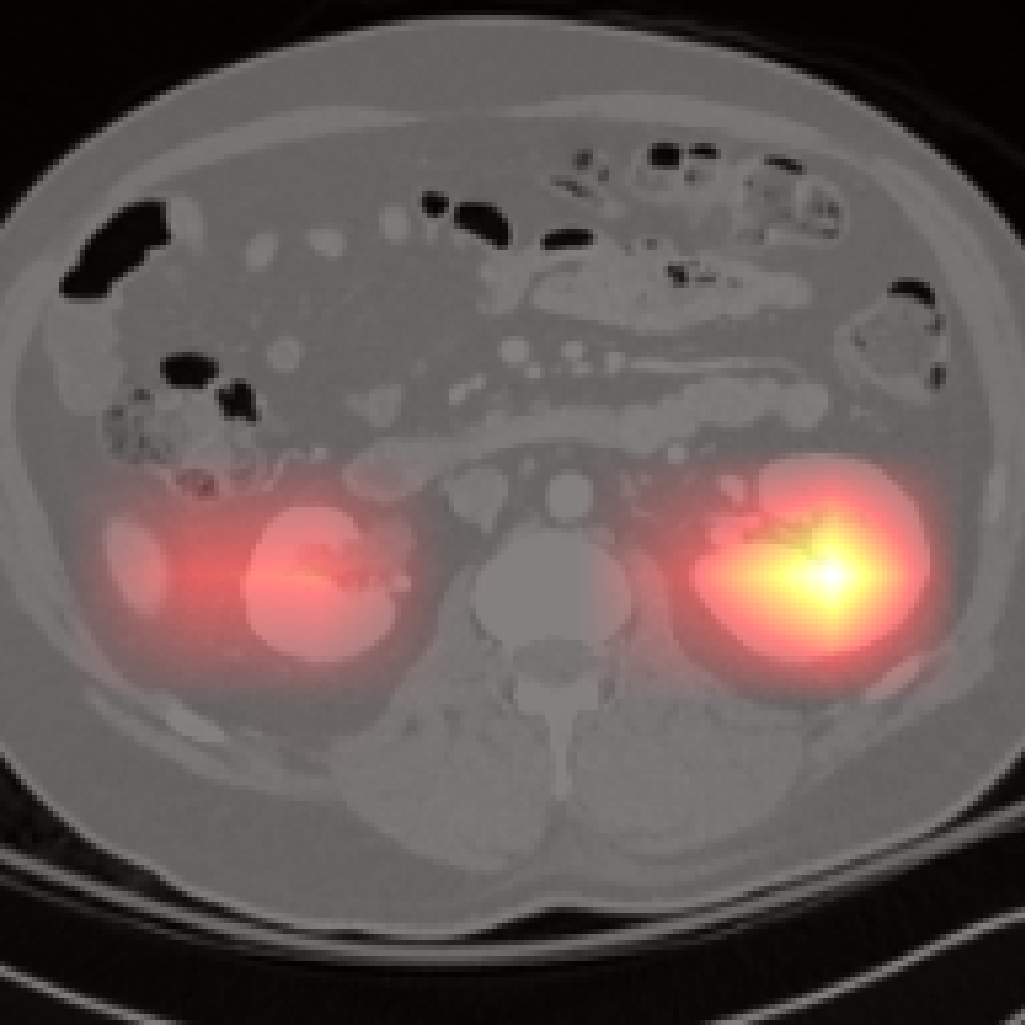
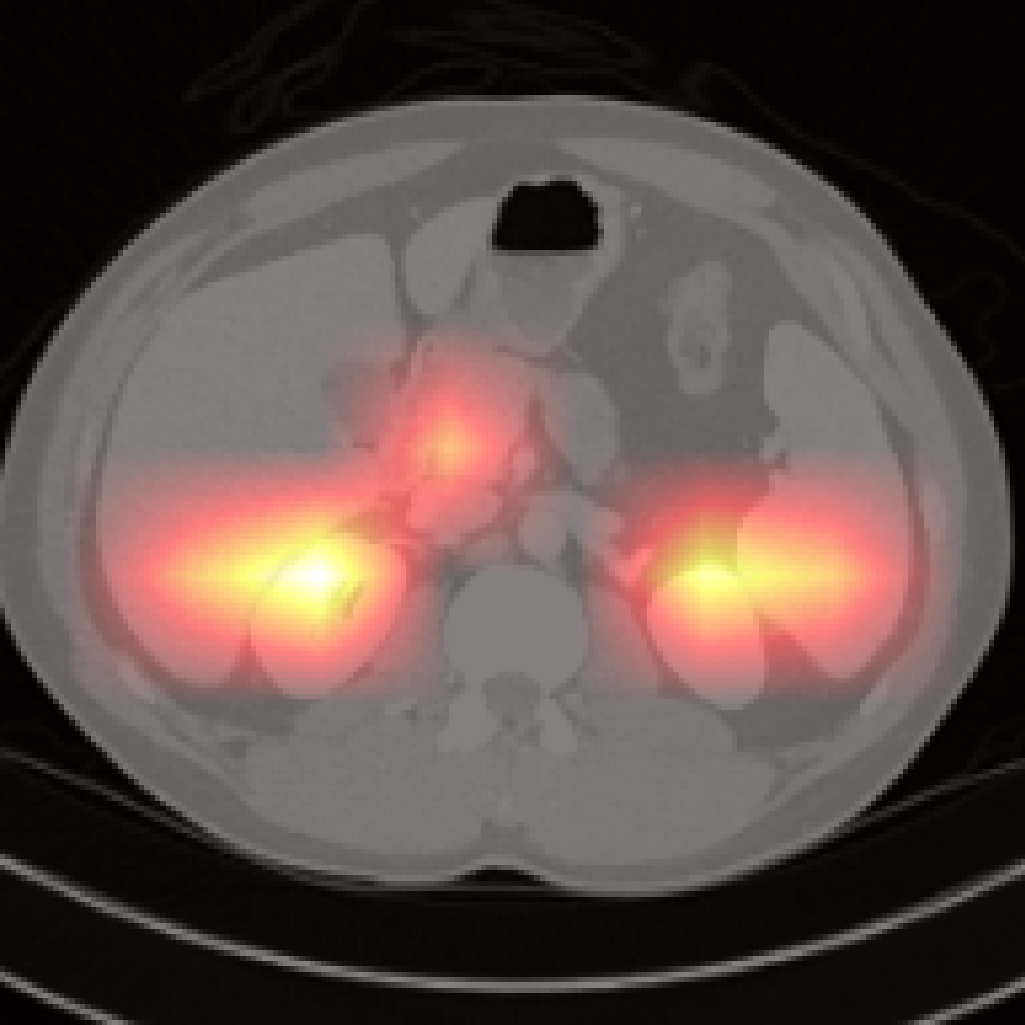
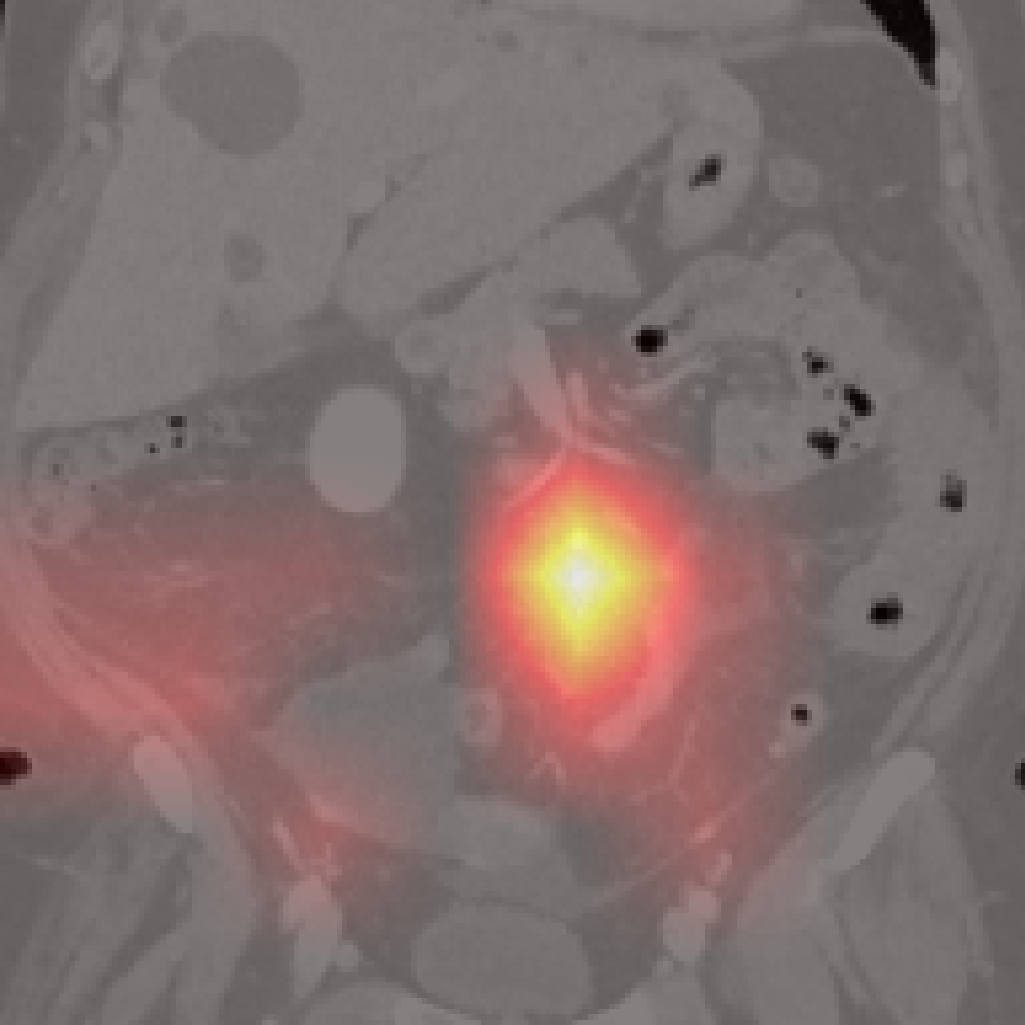
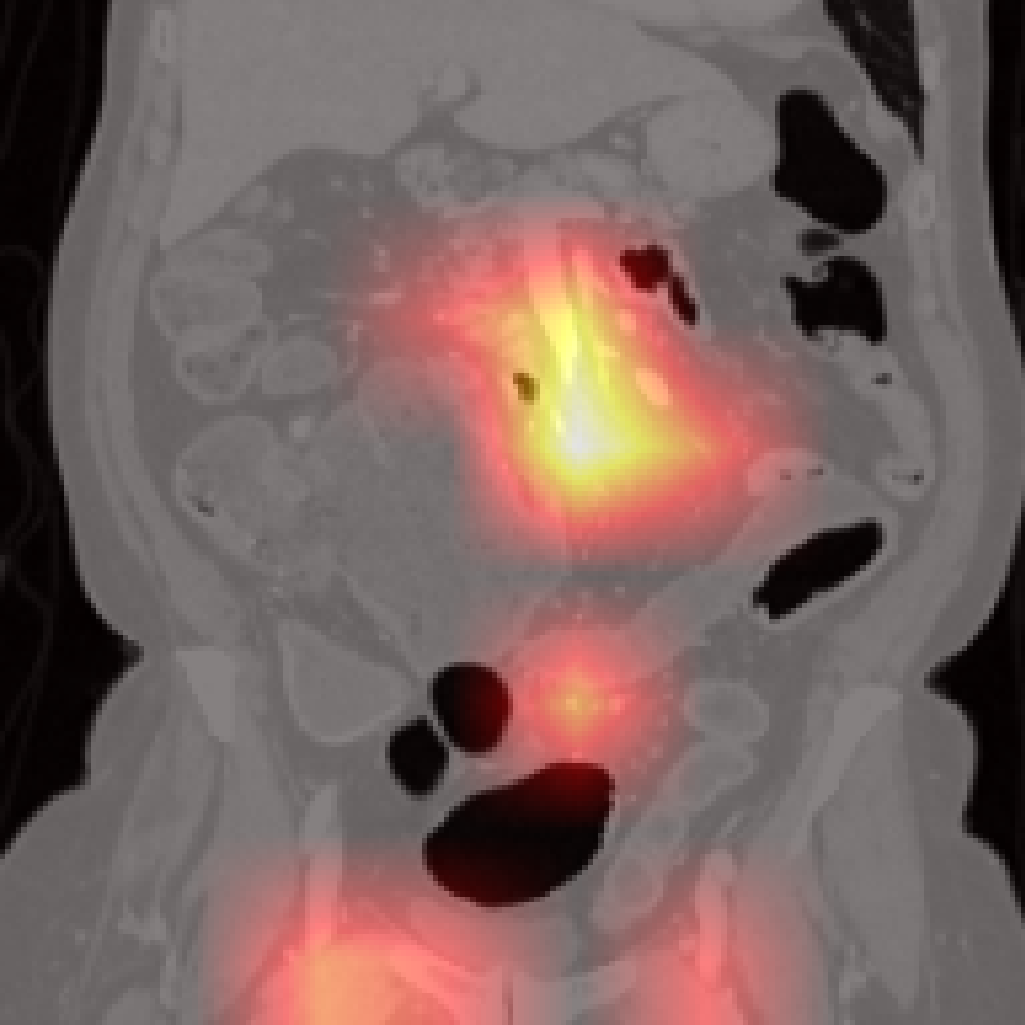
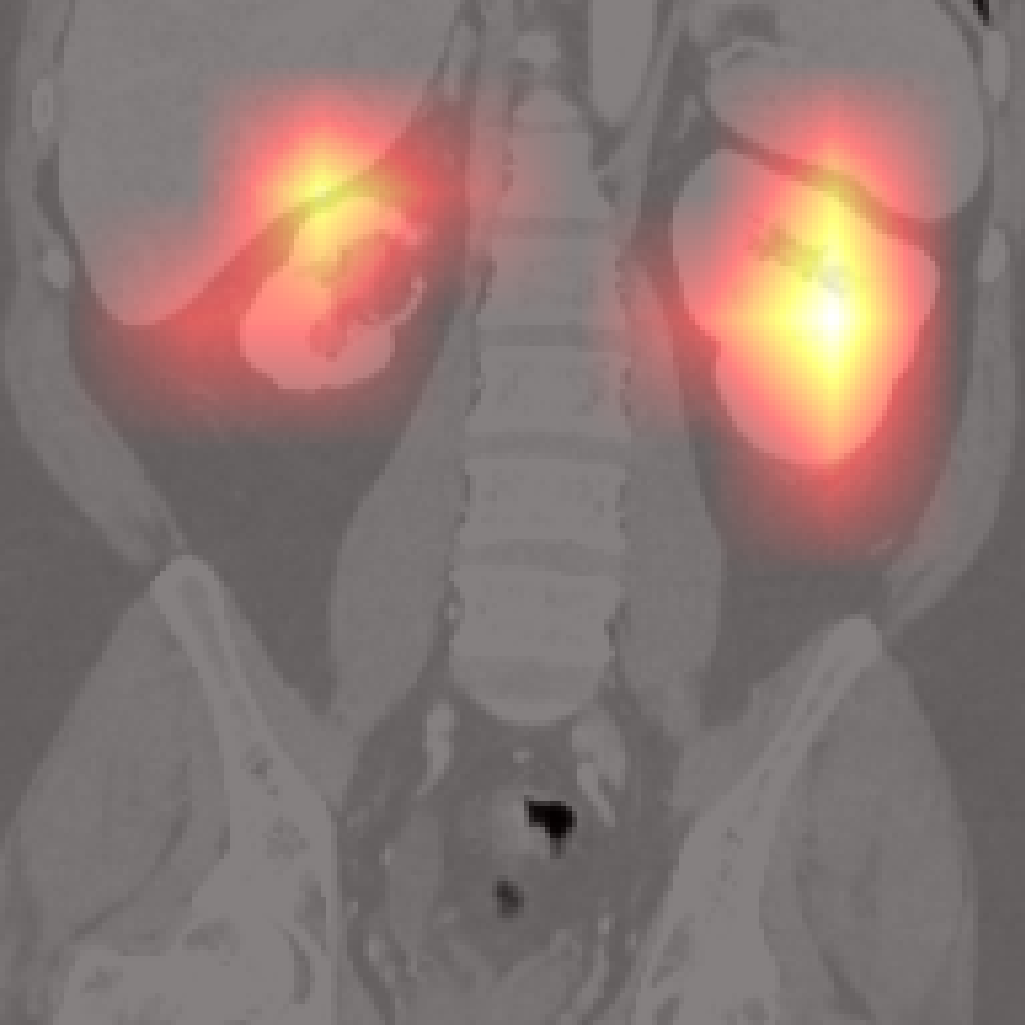
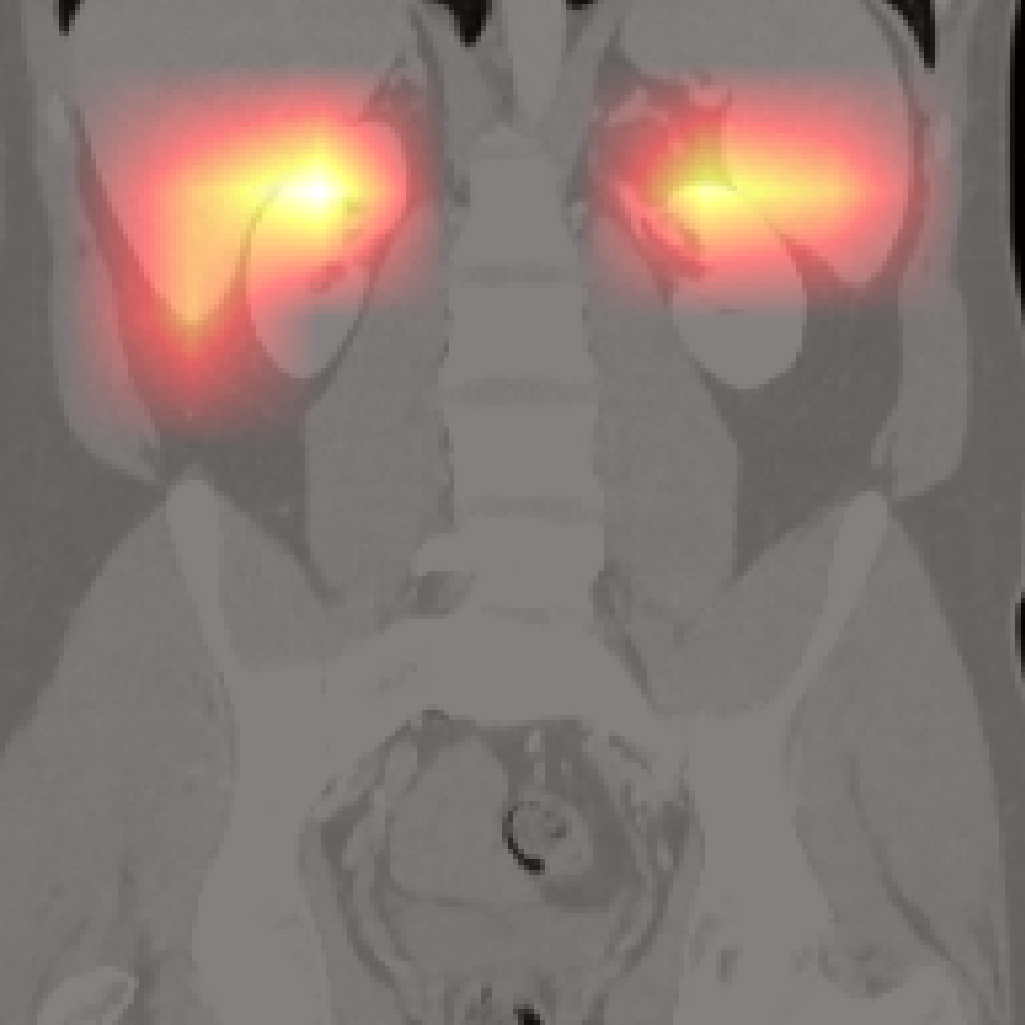
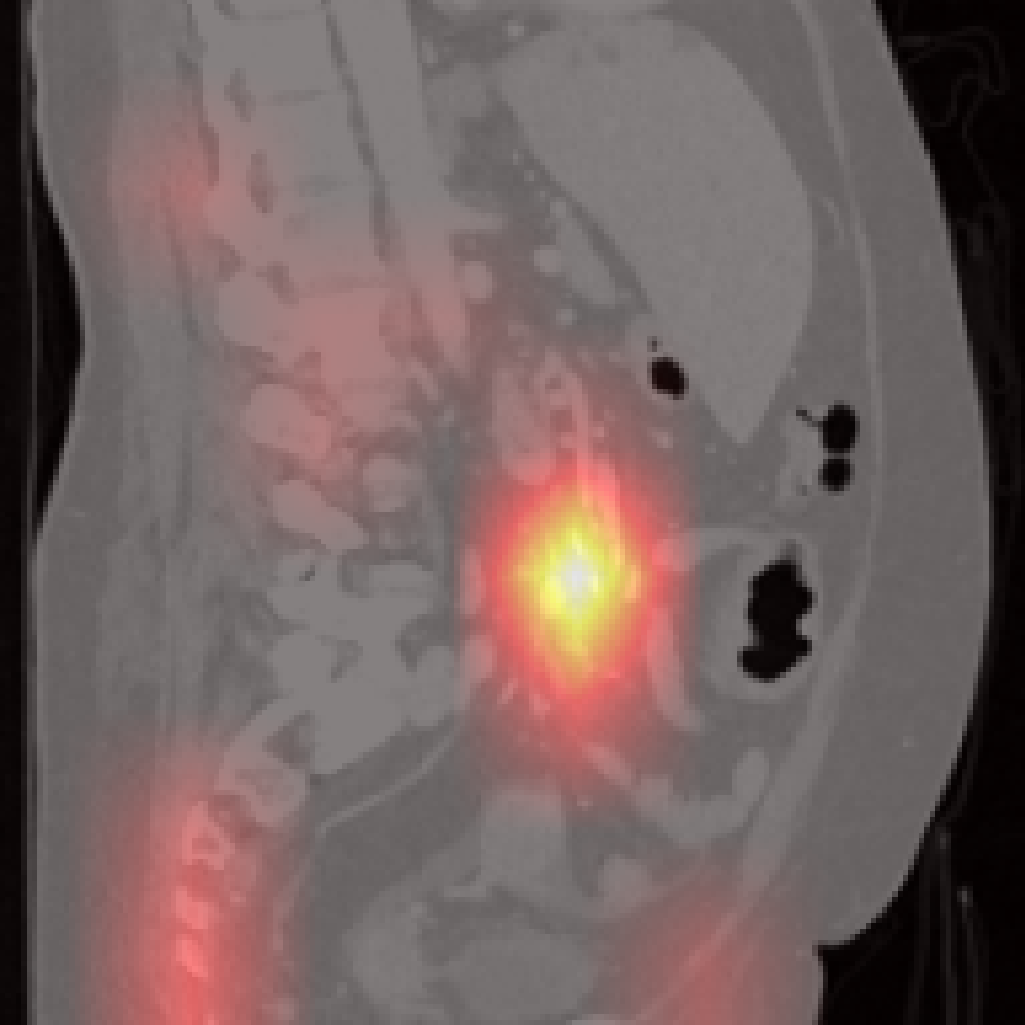
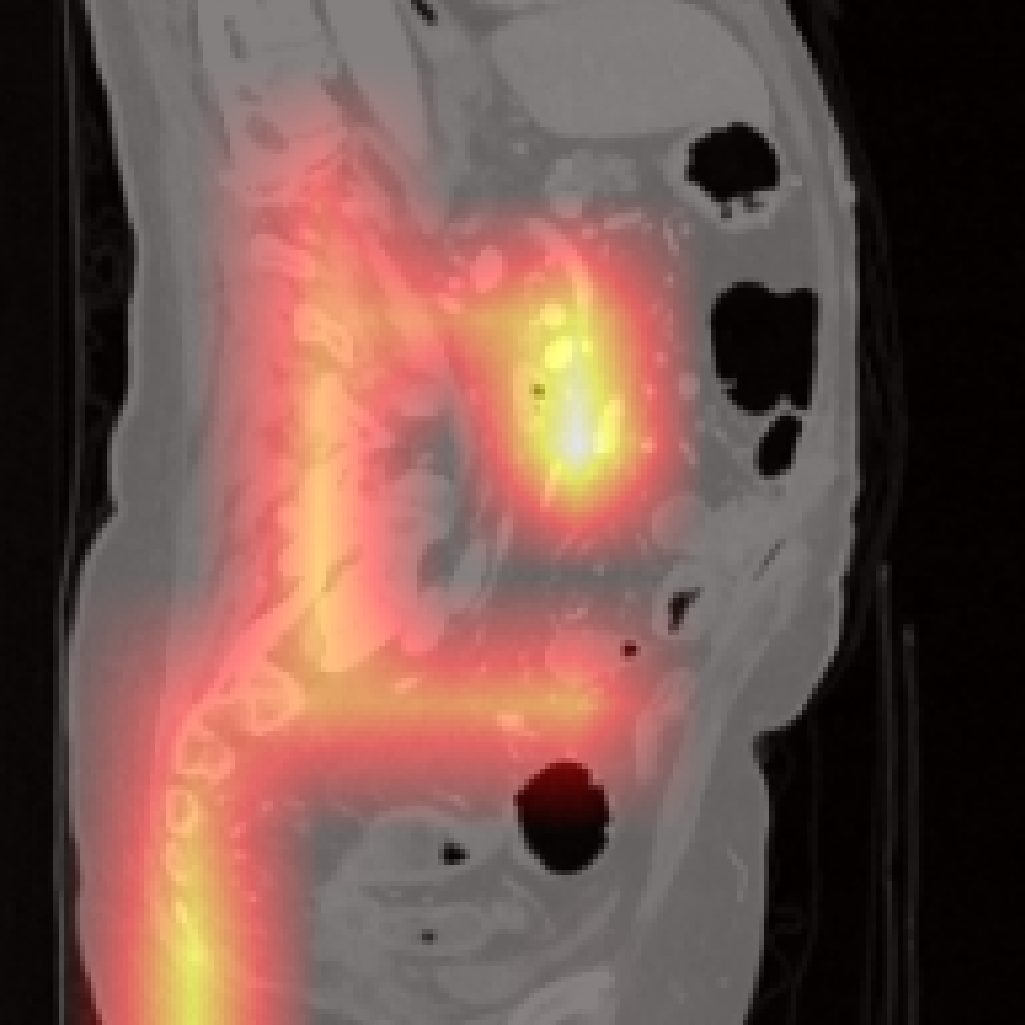
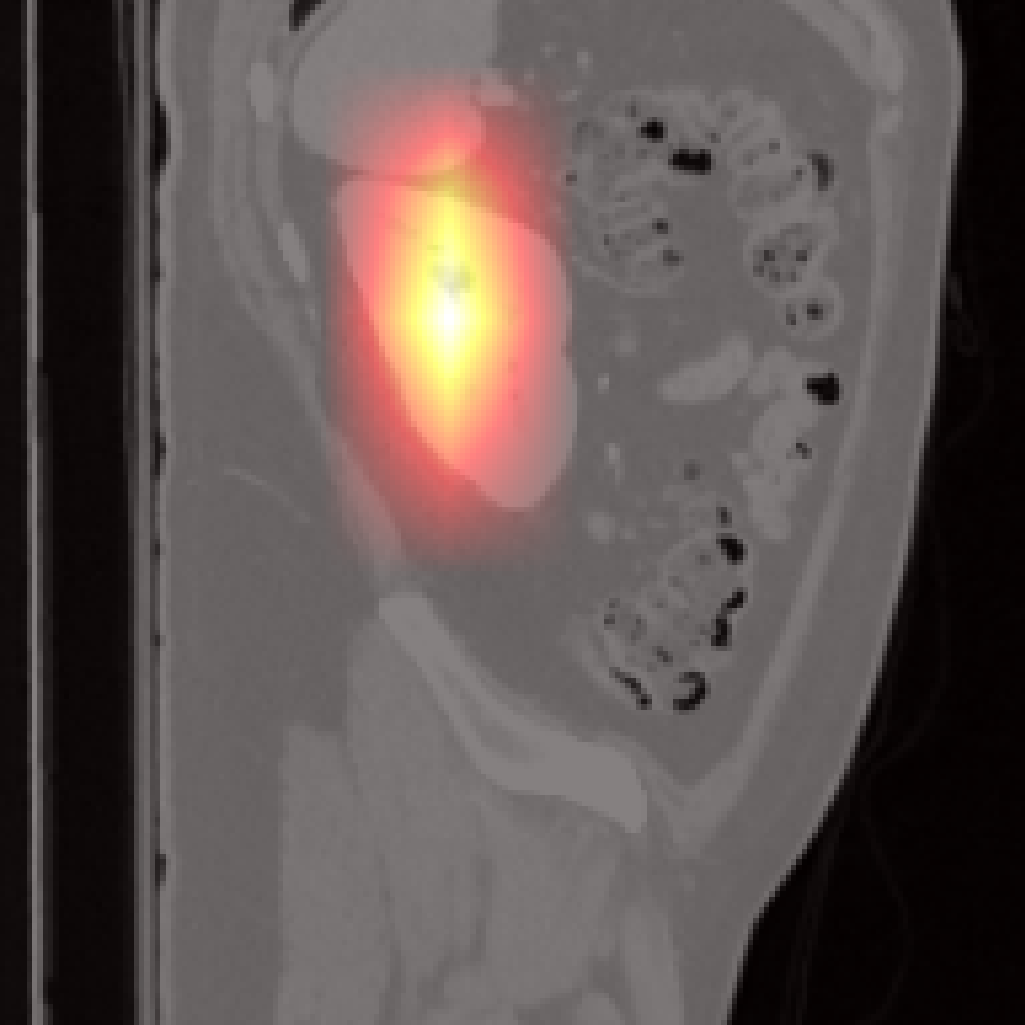
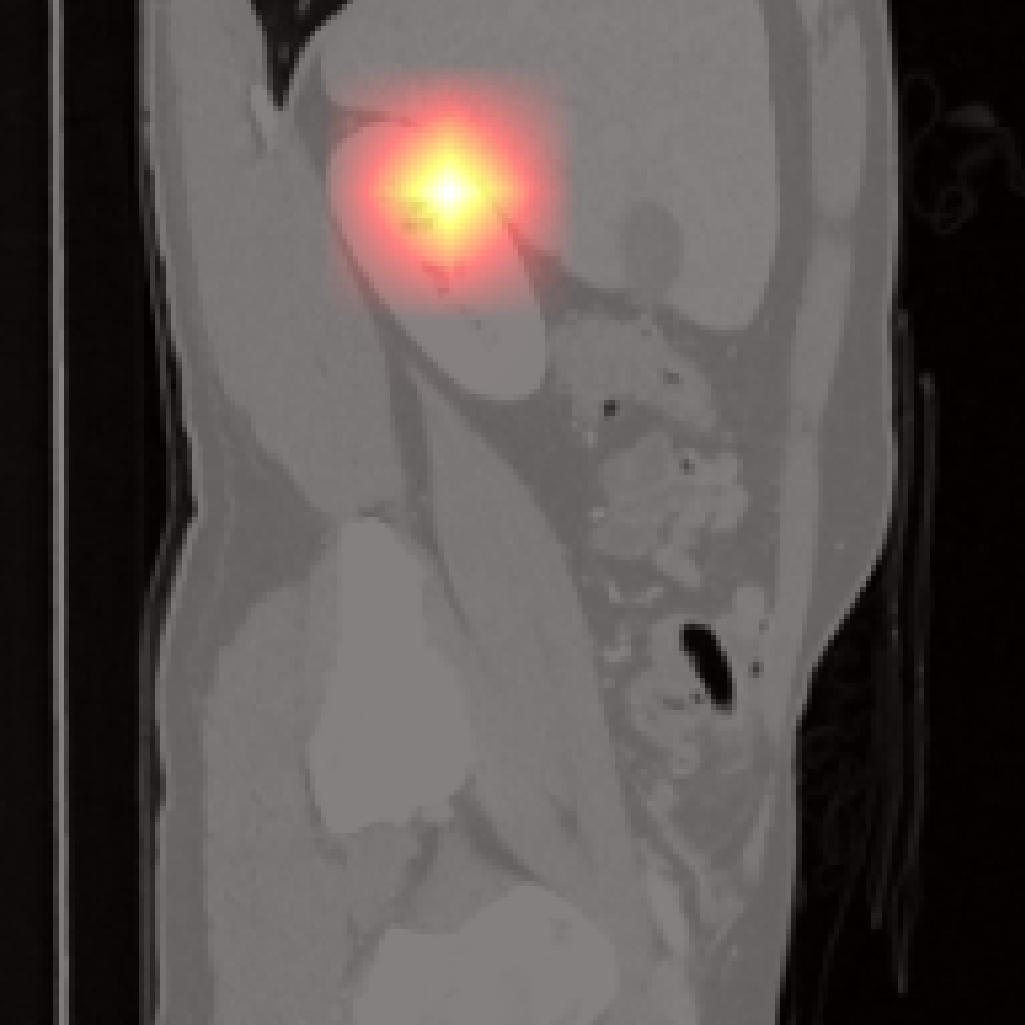
Figure 7: Failure cases: Pancreas and spleen attention maps show lower localization precision compared to larger organs.
Radiology Report Generation
Jolia, combined with a Qwen3.5-9B decoder, achieves best-in-class automatic report generation, outperforming Merlin, MedGemma, and Med3DVLM across most natural language generation and clinical fidelity metrics. Nonetheless, CRIMSON scores reveal persistent under-reporting of abnormal findings, a limitation shared with other encoders and attributable to inherent dataset bias.
Practical and Theoretical Implications
Jolia establishes that concept-level vision-language contrastive alignment—learned from public data without segmentation masks or spatial supervision—outperforms both global-only and mask-dependent approaches. The robustness to anatomical taxonomy, architecture, and domain shift validates the broad applicability of the method. The attention maps and feature visualizations enhance interpretability, supporting downstream decision audits and regulatory clarity.
Future work should address several open avenues: (1) joint training or adaptation of the text encoder to further align report distributions; (2) extension to full-body CT or other anatomical axes (e.g., pathological subtypes); (3) scaling to additional modalities such as MRI; (4) systematic evaluation of dependency on report-splitting LLMs, which could affect generalization.
Conclusion
Jolia, trained with ConQuer, demonstrates strong empirical and interpretative performance for 3D CT vision-language alignment, findings classification, report generation, and cross-center transfer. The concept-level alignment strategy yields substantial gains over global-only objectives and mask-dependent baselines, is robust to architectural choices and concept granularity, and enhances spatial interpretability. These contributions constitute significant steps toward unifying structural reasoning in medical vision-language modeling and inform best practices for future foundation models in computational radiology (2606.24570).

