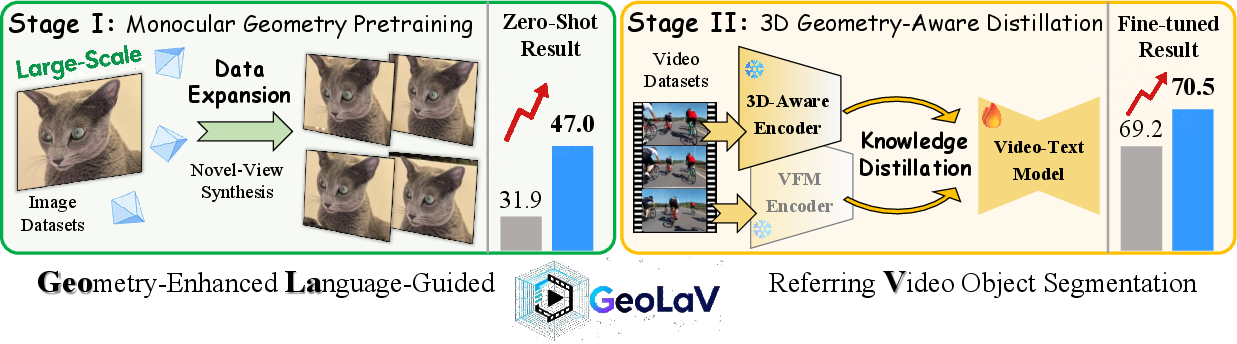
- The paper introduces a two-stage framework that couples monocular geometry pretraining with geometry-aware distillation to enhance video segmentation.
- It employs novel-view synthesis, depth estimation, and dual teacher guidance to enforce cross-frame geometric and semantic consistency.
- Empirical results show improved spatial precision and tracking stability, achieving state-of-the-art scores on standard RVOS benchmarks.
Geometry-Aware Distillation for Text-Driven Referring Video Object Segmentation
Text-driven Referring Video Object Segmentation (RVOS) requires segmenting target objects in videos as specified by natural language prompts. Existing approaches rely heavily on pretraining with large-scale 2D image datasets, failing to expose models to cross-frame geometric consistency or viewpoint variations crucial for spatial reasoning. This omission results in segmentation models with limited geometric awareness, weak spatial and temporal understanding, and poor generalization to complex video scenes. Furthermore, most models rely on naive segmentation losses, without explicit modeling of 3D geometry, hindering tracking stability under significant camera or object motion.
GeoLaV addresses these deficiencies by integrating explicit geometric priors and 3D structural knowledge. The framework consists of two main stages:
Architecture and Methodology
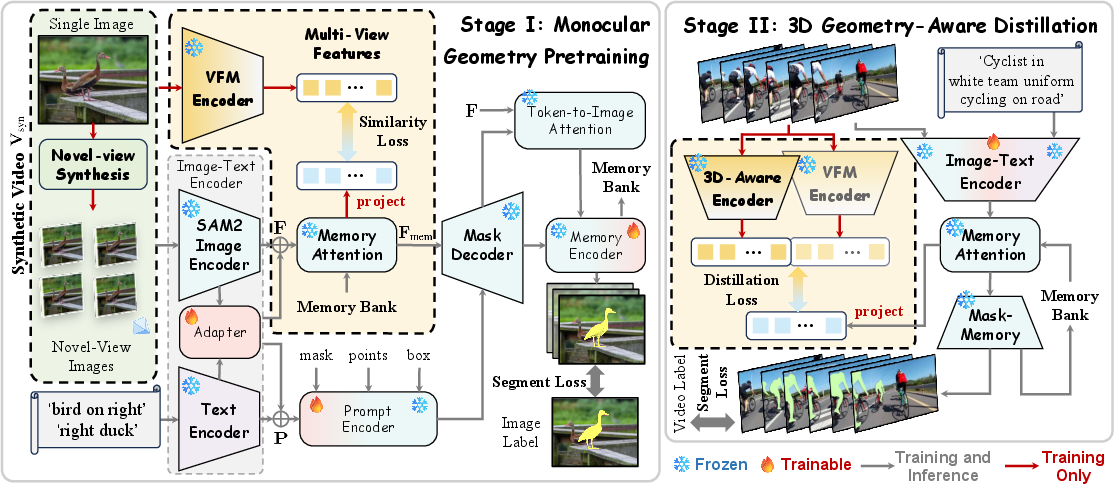
Stage I: Monocular Geometry Pretraining (MGP)
This stage synthesizes geometry-consistent view sequences from single images to facilitate spatially robust representation learning. The pipeline involves:
- Depth Estimation: Employing feed-forward monocular geometry models (e.g., π3, VGGT) to generate scale-invariant depth maps from RGB input.
- 3D Lifting and Camera Simulation: Projecting pixels into 3D space and simulating camera trajectories (linear, piecewise-linear, or curved) to create novel viewpoints. Each synthetic frame is generated via rigid 3D transformations, maintaining geometric coherence and depth-correspondence.

Figure 2: The pipeline for novel-view synthesis through 3D lifting, camera simulation, occlusion handling, and inpainting.
- Occlusion Handling and Inpainting: Occlusion masks and inpainting networks restore visual completeness and mitigate artifacts from novel view generation.
- Geometry-Consistent Supervisory Signals: Visual foundation model (VFM) encoders (e.g., DINOv3) extract features, which are aligned via a projection head with the memory-attention features from the SAM2 backbone. Feature alignment is enforced through auxiliary cosine similarity loss.

Figure 3: Examples of synthesized view sequences along physically valid 3D camera trajectories for geometry-consistent pretraining.
Stage II: Geometry-Aware Distillation (GAD)
Upon initialization with the geometry-consistent weights, the backbone is fine-tuned on real video datasets, leveraging dual supervision:
Empirical Evaluation
GeoLaV demonstrates substantial improvements across standard RVOS benchmarks, including Ref-Youtube-VOS, Ref-DAVIS17, and MeViS, relative to both non-large and large VLM-based baselines. The method achieves:
- 70.5 JcontentF on Ref-Youtube-VOS,
- 72.5 JcontentF on Ref-DAVIS17,
- 50.0 JcontentF on MeViS,
with notable gains over prior approaches such as SAMWISE and ReferDINO. Zero-shot evaluation on unseen video domains after image-only pretraining shows over +15.1 improvement on Ref-Youtube-VOS compared to the SAMWISE baseline.

Figure 5: Qualitative comparison against SAMWISE, showing enhanced spatial precision and tracking stability.
Ablation studies affirm that performance improvement is driven by geometry-consistent pretraining and explicit 3D-aware distillation, not merely the exposure to more synthetic frames. Depth-based 3D warping brings larger gains than planar augmentation, and full two-stage training yields the highest scores.


Figure 6: Geometric consistency comparison (left: planar vs. GeoLaV) and feature representations (right: dual teacher distillation yields feature clusters with clear object separation).
Theoretical and Practical Implications
GeoLaV validates the hypothesis that explicit 3D geometry priors and monocular novel-view synthesis can compensate for the lack of diverse and annotation-rich video data. The deterministic multi-frame synthetic pipeline scales efficiently, offering a paradigm for geometry-aware pretraining in the absence of real videos. The geometry-aware distillation process leverages both geometric and semantic cues, enabling robust cross-frame correspondence and improved temporal consistency in segmentation.
Practically, GeoLaV's methodology is applicable to any scenario where spatial or temporal consistency is critical but high-quality video annotation resources are lacking. The approach is compatible with generic vision-language backbones and teacher models, facilitating transfer learning for other multimodal, spatiotemporal tasks.
Future Directions
Potential avenues include open-vocabulary segmentation, incorporation of larger teacher models with broader 3D semantic understanding, and scaling the synthetic training regime for even longer or more diverse camera trajectories. Extensions toward streaming video, continual learning, and multimodal 3D understanding are also tractable given the modularity of the framework.
Conclusion
GeoLaV establishes a principled two-stage pipeline for geometry-enhanced video segmentation by coupling monocular geometry pretraining with geometry-aware distillation. By injecting both 3D structure and semantic priors, the method achieves state-of-the-art performance while maintaining computational efficiency and robust generalization, providing a foundation for further advances in multimodal video understanding (2606.24464).