- The paper introduces WSRVOS, a novel model that replaces pixel-level annotations with text-only supervision to reduce labeling effort.
- It employs contrastive referring expression augmentation and bi-directional vision-language feature selection to achieve robust segmentation.
- Experimental results across benchmarks show significant improvements in IoU metrics and real-time inference at 58 FPS.
Weakly-Supervised Referring Video Object Segmentation via Text Supervision
Motivation and Context
Referring Video Object Segmentation (RVOS) requires segmenting objects in a video, guided by a natural language description. Supervised RVOS methods leverage pixel-level mask annotations, incurring high labeling costs, particularly for lengthy videos. Previous weakly-supervised variants rely on bounding box or point annotations, which still demand substantial manual effort. The paper "Weakly-Supervised Referring Video Object Segmentation through Text Supervision" (2604.17797) proposes WSRVOS: an end-to-end method that substitutes all spatial supervision with text-only supervision, leveraging advances in multimodal LLMs (MLLMs) to generate rich training signals.
Methodological Innovations
WSRVOS introduces several novel modules, enabling video object segmentation trained solely from text expressions:
- Contrastive Referring Expression Augmentation: Enriches each video’s original referring expression by generating multiple positive and negative expressions via an MLLM. Positive expressions capture fine-grained visual details, actions, and inter-instance relations. Negatives alter key attributes or actions, yielding hard negatives for better discriminative alignment.
- Bi-directional Vision-Language Feature Selection and Interaction: Visual and linguistic features are extracted with frozen encoders and refined via bi-directional selection—each modality selects tokens most relevant to the other, minimizing redundancy and irrelevant information. Cross-modal attention layers further strengthen mutual representation enrichment.
- Instance-Aware Expression Classification: Employs a Multiple Instance Learning (MIL)-inspired proposal aggregation and expression matching scheme, aggregating diverse proposal features and scoring correspondence to expressions. The classification flow is non-parametric, keyed by linguistic feature transposes, while the segmentation flow is learnable.
- Positive-Prediction Fusion: Pseudo-masks are synthesized by fusing predictions from multiple positive expressions, weighted by confidence scores derived from cross-modal similarity. These pseudo-labels support mask-level training through focal and DICE losses.
- Temporal Segment Ranking Constraint: Imposes an ordering on mask overlaps, enforcing that temporally proximate frames exhibit higher mask IOU, reflecting plausible object motion consistency.
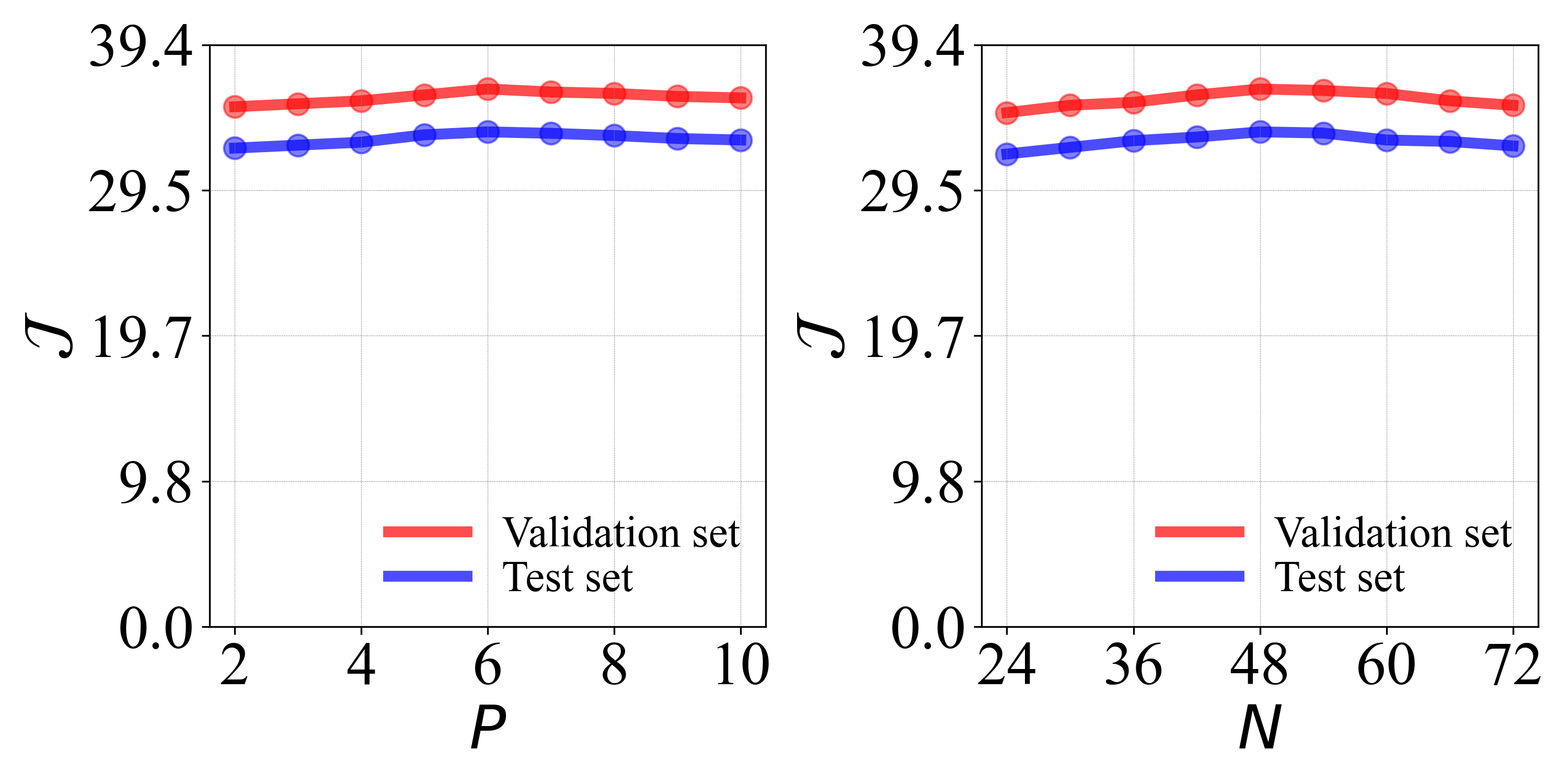
Figure 1: Parameter variation for the number of generated positive and negative expressions shows optimal performance around P=6, N=48.
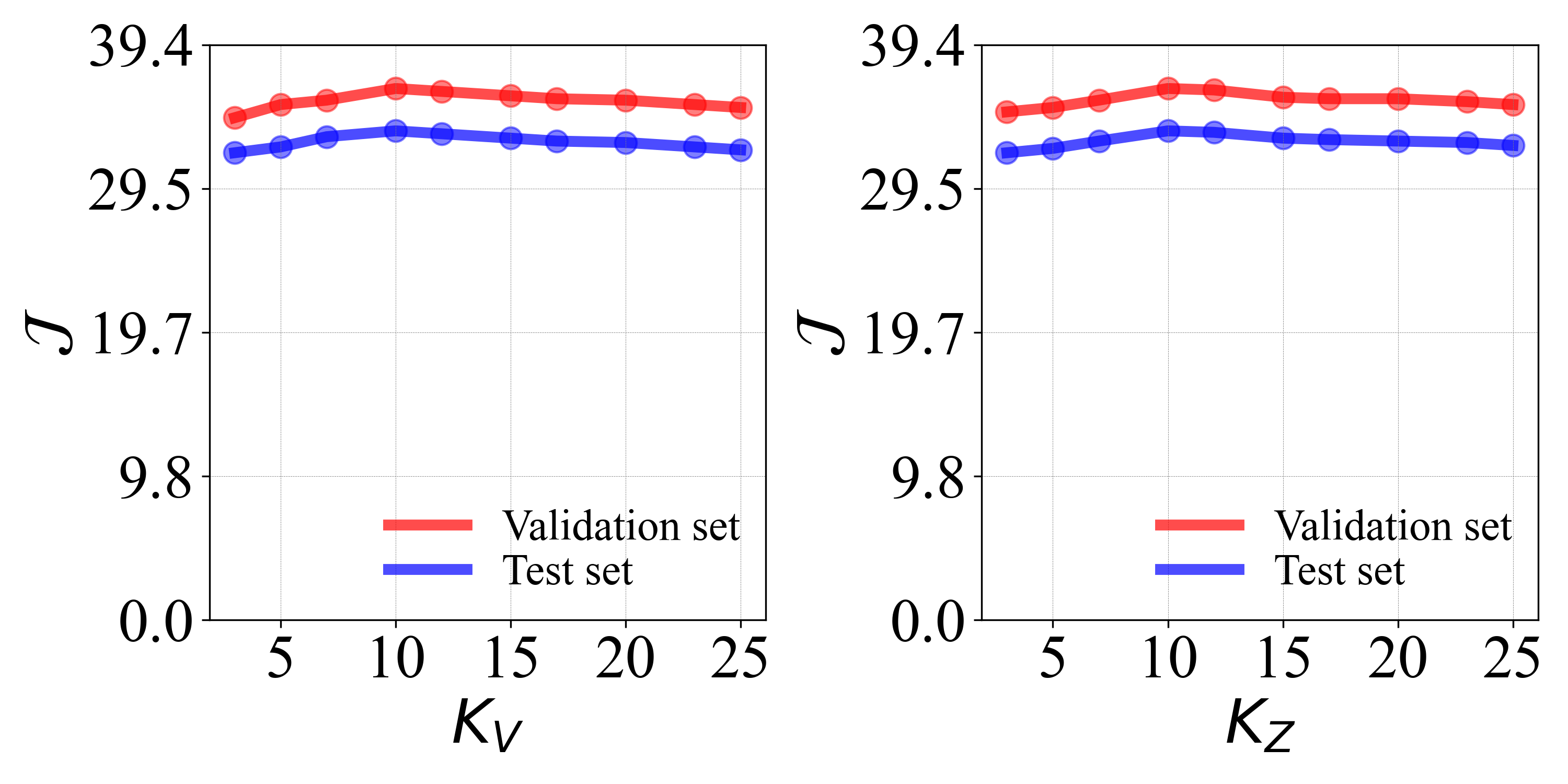
Figure 2: Performance analysis for feature selection size in the bi-directional vision-language module; KV=KZ=10 yields maximal accuracy.
Experimental Analysis
The approach was evaluated on four RVOS benchmarks: A2D-Sentences, J-HMDB Sentences, Refer-YouTube-VOS, and Refer-DAVIS17. WSRVOS utilized Video-Swin-Tiny and RoBERTa as the visual and linguistic encoders respectively in all experiments.
Numerical Results: WSRVOS outperformed prior text-supervised methods by significant margins:
- On A2D-Sentences, WSRVOS improved Overall IoU by +7.1% and Mean IoU by +5.7% compared to the previous best weakly-supervised RIS adaptation.
- On Refer-YouTube-VOS and Refer-DAVIS17, improvements of +7.1% and +7.3% were observed in JcontentF metrics, highlighting strong cross-dataset generalization.
- WSRVOS achieved comparable or better accuracy than point-supervised OCPG (e.g., +0.5% on Refer-YouTube-VOS F, +0.8% on Refer-DAVIS17 F) despite requiring no spatial annotations.
The model demonstrates competitive efficiency with only 31M parameters and real-time inference at 58 FPS, outperforming both SOTA fully-supervised and weakly-supervised alternatives in computational footprint.
Ablations and Analysis
Extensive ablation studies confirm the efficacy of each pipeline component:
Practical and Theoretical Implications
WSRVOS suggests that text-only supervision, when harnessed via multimodal generative models and appropriate discriminative feature selection and alignment, can substitute for spatial annotations in video segmentation. This presents a scalable paradigm for training video segmentation models on vast, annotation-poor corpora, particularly relevant for domains like surveillance, interaction, or editing.
The theoretical implication is that dynamic and semantically diverse video content can be successfully grounded in weak linguistic signals given careful multimodal token selection, robust negative sampling, and cross-modal proposal matching strategies. The success of MIL mechanisms in multimodal settings invites exploration of non-parametric, semantic-keyed classification flows in broader vision-language tasks.
Future Directions
Practical extensions include scaling up to longer videos, incorporating temporal language cues, and combining text-only supervision with automatic MLLM pseudo-label generation for continual learning. Further research may focus on improving robustness to occlusion and distinguishing between multiple similar-category instances, as highlighted by failure cases.
Integration with closed/open-vocabulary segmentation, visual grounding, and video QA pipelines offers potential for unified multimodal video understanding systems. The pipeline’s reliance on MLLMs also motivates investigation into continual finetuning and adaptation for evolving language and domain requirements.
Conclusion
WSRVOS establishes a new baseline for weakly-supervised RVOS, achieving near-SOTA mask accuracy using only text expressions for supervision. Its comprehensive pipeline leverages multimodal LLMs, bi-directional token selection, proposal aggregation, and fusion-based pseudo-labeling, coupled with temporal regularization. The results demonstrate that appropriately structured text supervision—supported by MLLMs and robust discriminative learning—can efficiently drive video object segmentation, with implications for scalable vision-language training and practical deployment beyond the reach of exhaustive annotation.
