- The paper introduces VideoSEG-O3, a multi-turn RL framework that iteratively refines video object segmentation through chain-of-thought reasoning and direct SEG-aware logit calibration.
- It decouples temporal, spatial, and linguistic reasoning to dynamically select keyframes and reduce reasoning rounds by over 20%, enhancing segmentation precision.
- Experimental results on benchmarks like LongRVOS, MeViS, and ReVOS demonstrate significant performance gains, underscoring its potential for interpretable multimodal reasoning.
Introduction and Motivation
Reasoning Video Object Segmentation (RVOS) constitutes a challenging space, requiring precise, context-aware segmentation of dynamic target objects in complex video streams using freely structured linguistic instructions. Prevailing MLLM-based methods are bottlenecked by their limited reasoning depth and cannot actively acquire additional visual evidence—this is particularly detrimental as video queries grow in temporal or semantic complexity. Furthermore, most reinforcement learning (RL) approaches for RVOS optimize explicit coordinate-based prompts, which are indirect and insufficiently representative for unified and fine-grained mask reasoning. The VideoSEG-O3 framework directly addresses these limitations via a multi-turn, RL-enabled, temporal-spatial chain-of-thought (CoT) architecture, supporting emergent autonomous iterative exploration and hierarchical reasoning.
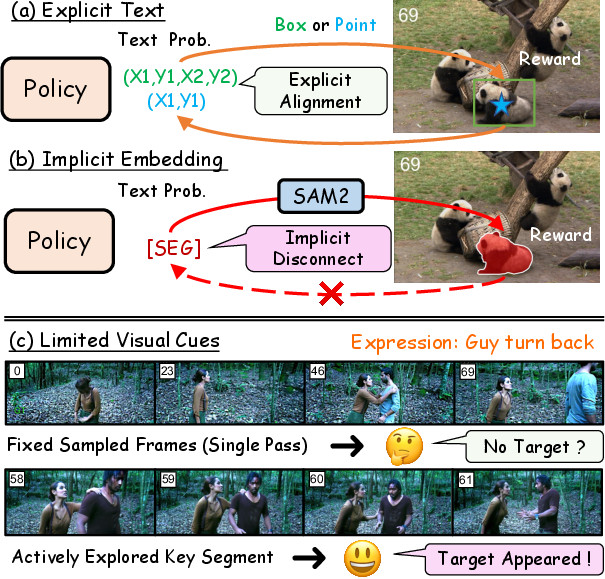
Figure 1: Motivation for VideoSEG-O3, contrasting explicit prompt-based RL, latent embedding disconnection, and the exploration failures of fixed frame sampling strategies.
Model Overview and Architectural Innovations
VideoSEG-O3 departs from traditional single-pass or sequence-frozen MLLM approaches by instantiating a multi-turn sequential decision process. The model is governed by three key imperatives: (i) explicit multi-turn temporal-spatial CoT, (ii) SEG-aware logit calibration bridging the reward-token disconnect, and (iii) decoupling of reasoning dimensions (temporal, spatial, linguistic) via a structured “Decoupled Thinking Trace.”
The model ingests an initial global observation, then iteratively selects critical temporal intervals and keyframes through a specialized <select> token. Each exploration augments the visual input state, allowing for context-dependent and data-efficient allocation of attention toward ambiguous scenes or queries.
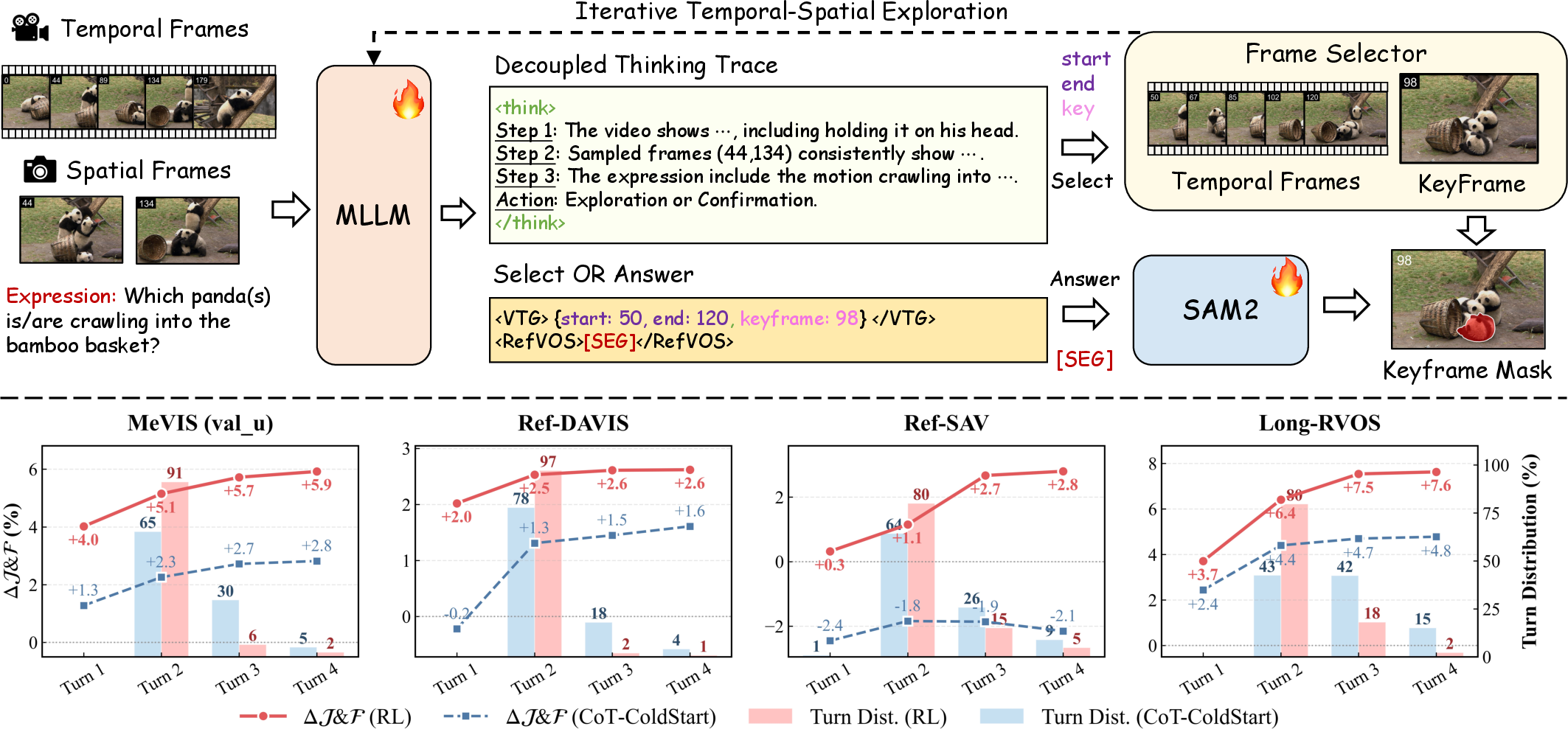
Figure 2: VideoSEG-O3 architecture: MLLM with decoupled hierarchical reasoning, iterative selection token, and statistical analysis of turn-adaptive performance on diverse benchmarks.
Optimization Objectives and SEG-Aware RL
A primary limitation in RL-based RVOS is the decoupling of the mask prediction reward from the model’s textual reasoning path: conventional methods optimize text token likelihood, which is a structurally weak proxy for segmentation quality, especially for implicit embeddings. VideoSEG-O3 introduces SEG-aware logit calibration, directly modulating the [SEG] token’s logits with pixel-wise segmentation probabilities—thus effectively transmitting the mask reward into the RL policy update. The calibration ensures that the actor’s trajectory is simultaneously aligned with textual semantics and the dense high-fidelity segmentation target.
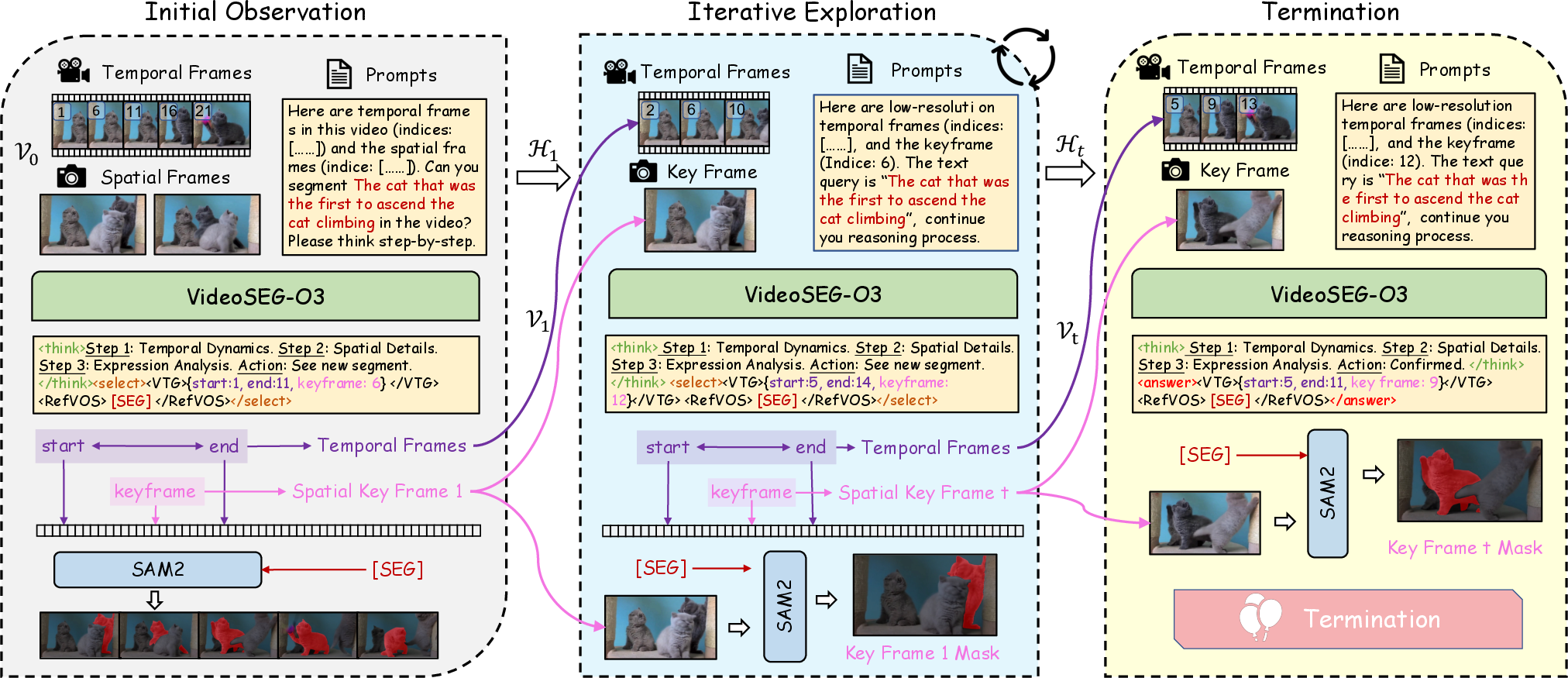
Figure 3: VideoSEG-O3 pipeline: Initial global analysis, multi-turn exploration via <select>, and final mask generation contingent on <answer> output.
The RL phase leverages a composite episodic reward, integrating format constraints, temporal precision, segmentation quality (both keyframe superiority and per-frame quality), and progressive improvement incentives. The hybrid objective includes both the GRPO (Group Relative Policy Optimization) reward and an auxiliary segmentation loss for robust supervision, which stabilizes optimization and maintains discriminative mask decoding during exploration.
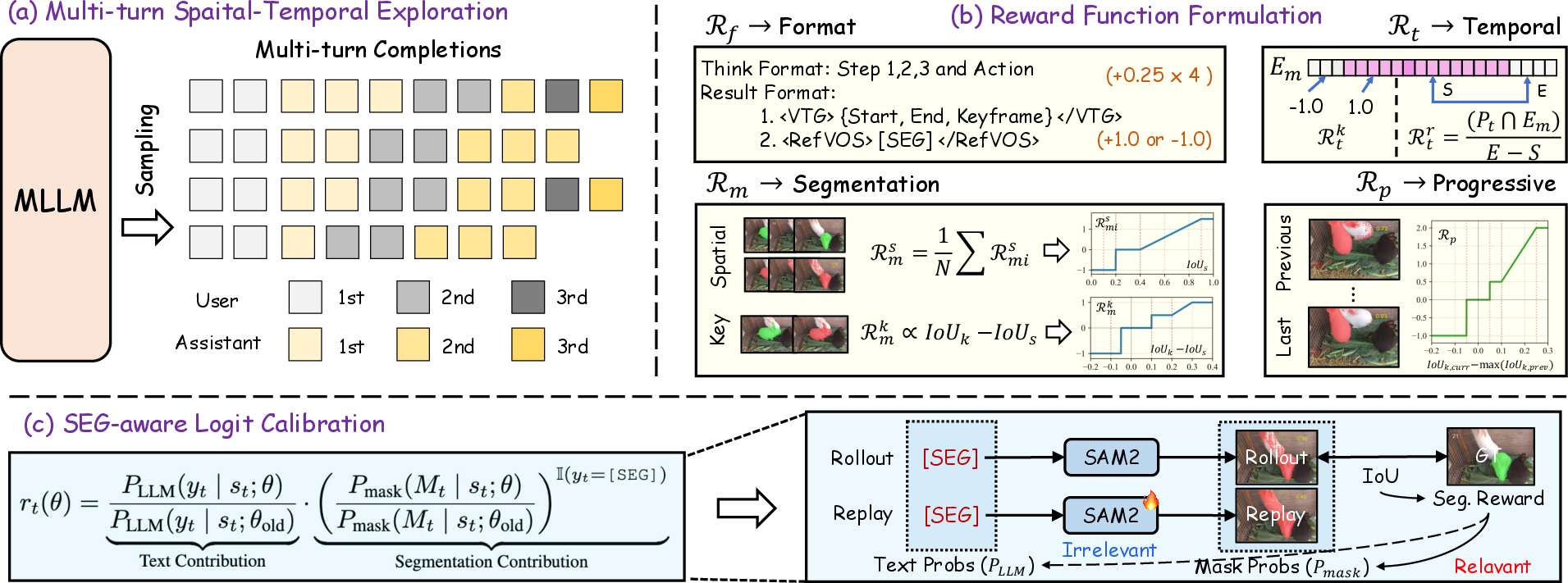
Figure 4: VideoSEG-O3 framework showing multi-turn spatiotemporal CoT, composite RL rewards, and the calibration pathway aligning SEG embedding with pixelwise mask confidence.
Dataset Construction and Training Pipeline
A substantial barrier for CoT-based RVOS is the absence of well-structured chain-of-thought data. The authors introduce VTS-CoT, a synthetic dataset where each sample is constructed with GPT-assisted labeling, including multi-turn, decoupled reasoning trajectories over diverse video referential expressions. The learned policy is hierarchically trained: supervised fine-tuning for segmentation skill and temporal alignment, then CoT cold-start with VTS-CoT, followed by the RL phase that drives active exploration and trajectory optimization.
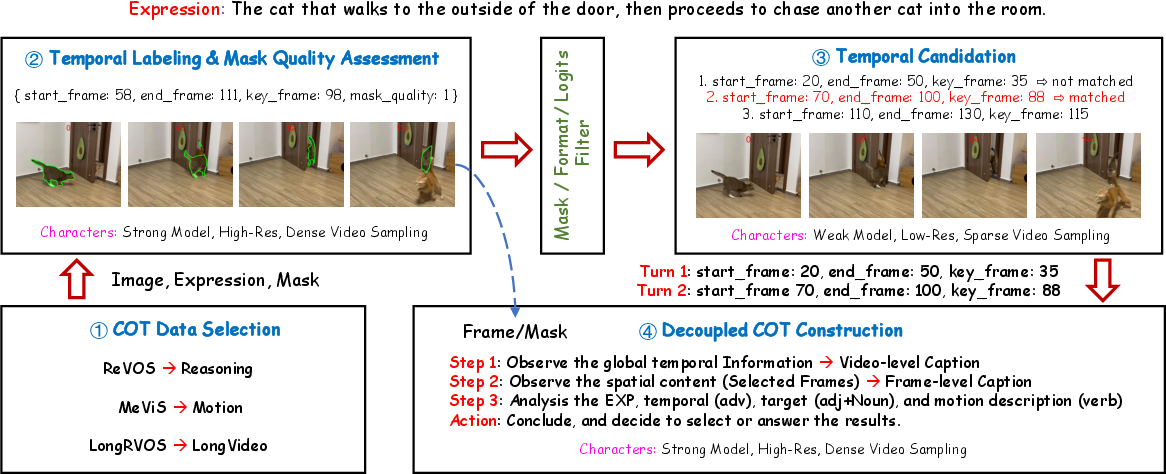
Figure 5: Construction pipeline of the VTS-CoT dataset, featuring data selection, temporal labeling, candidate interval generation, and chain-of-thought assembly.
Experimental Evaluation
Comprehensive experiments establish VideoSEG-O3 as achieving SOTA on standard referring and reasoning VOS benchmarks (MeViS, ReVOS, Ref-Youtube-VOS, GroundMoRe, Long-RVOS, et al.), outperforming both specialized and LLM-based baselines by significant margins: +6.1% JcontentF on LongRVOS, +4.2% on MeViS, and +4.0% on ReVOS.
Multi-stage ablation quantifies distinct performance gains at each training phase, validating the necessity of structured CoT and RL. Notably, RL fine-tuning reduces the average reasoning rounds (subsequent turns) by over 20% while simultaneously boosting overall accuracy—direct evidence of efficient exploration.
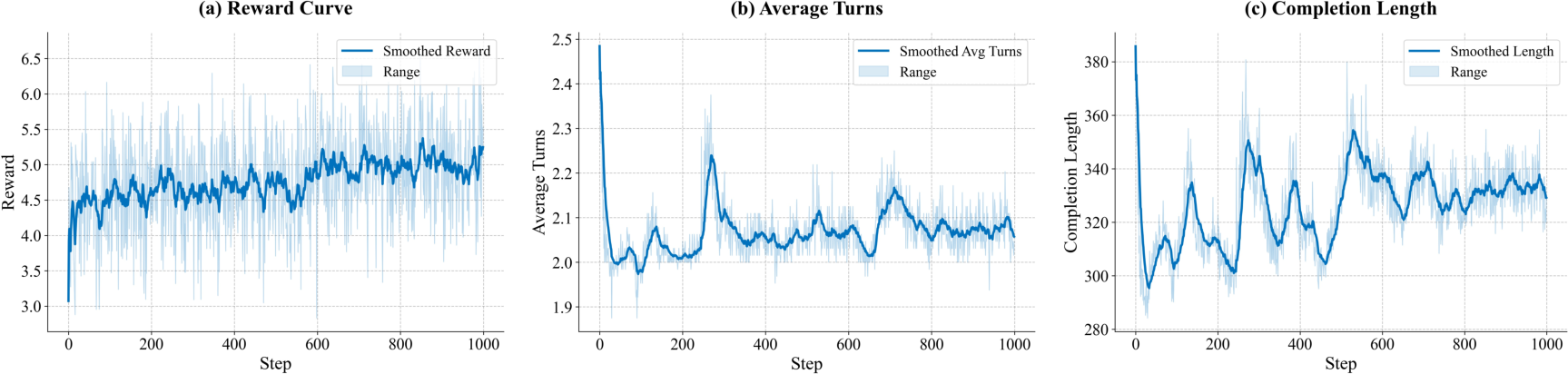
Figure 6: RL training dynamics: reward convergence, decreasing average turns (transition from fixed patterns to adaptive exploration), and stabilization of reasoning trajectory length.
Further, explicit analysis on keyframe selection demonstrates superior discriminative focus—RL adaptation leads to both higher initialization mIoU for keyframes and a marked reduction in frames where the target is absent.
Figure 7: RL-driven improvement in keyframe selection (higher mIoU, lower non-target frame selection ratio) across all major benchmarks.
Visual qualitative results confirm the model’s ability to refine spatial hypotheses or disambiguate complex instructions through multi-round chain-of-thought.

Figure 8: Two-round interactive reasoning and segmentation showing scene context understanding and active refinement.

Figure 9: Three-round iterative refinement illustrating the model's handling of intricate target localization through sequential evidence incorporation.

Figure 10: Iterative reasoning in challenging dynamic scenarios with multi-turn localization and mask correction.
Theoretical and Practical Implications
VideoSEG-O3 sets a new technical direction for VOS research: the demonstration that iterative, RL-driven multi-turn CoT with direct SEG embedding feedback is necessary for optimal reasoning over long and complex videos. The decoupled reasoning paradigm represents a scalable architecture for future MLLMs in spatio-temporal vision and linguistic grounding, reducing over-processing and improving interpretability. Its strong zero-shot capabilities on out-of-domain and descriptive/causal tasks (e.g., GroundMoRe) suggest high adaptability and forward-transfer potential.
This architecture motivates further exploration in:
- RL-based chain-of-thought in other multimodal sequential grounding applications.
- Hardware-aware adaptive exploration (actively minimizing token usage in extreme-length or bandwidth-limited settings).
- Causal and counterfactual segmentation analysis via multi-step visual reasoning.
- Development of real interactive annotation agents, assistive robotics observers, and surveillance systems that require interpretable, multi-step reasoning on unstructured video data.
Conclusion
VideoSEG-O3 advances the frontier of reasoning video object segmentation by fusing multi-turn chain-of-thought RL with segmentation-informed policy calibration. It demonstrates that explicit temporal-spatial reasoning, structural reward alignment, and hierarchical training are essential for high-fidelity, generalizable, and sample-efficient RVOS. The presented results establish a new standard for RVOS tasks, with implications well beyond video segmentation towards general structured multimodal reasoning and interactive vision-language agents.
(2606.06819)