- The paper introduces VGTW, a distractor-aware transformer architecture that directly suppresses transient distractors to enhance 3D reconstruction accuracy.
- It employs a mask prediction head and novel training losses, such as Distractor Suppression Loss, to enforce cross-view feature consistency and minimize geometric errors.
- Experimental results demonstrate that VGTW outperforms existing methods on challenging benchmarks, achieving state-of-the-art performance without explicit 3D supervision.
Introduction and Motivation
Feed-forward, end-to-end 3D reconstruction methods have significantly advanced in efficiency and flexibility, yet they falter when real-world image collections deviate from the classic static-scene, perfect geometry assumption. In practical captures, transient distractors such as moving objects, partial occlusions, and non-rigid deformations induce geometric inconsistencies across views, fundamentally challenging robust geometry learning. Existing methods, both classic and recent (e.g., NeRF-based, 3D Gaussian Splatting), either iteratively marginalize transients at considerable computational expense or rely on brittle post-filtering schemes.
The Visual Geometry Transformer in the Wild (VGTW) directly confronts the ill-posed nature of recovering static 3D geometry from inconsistent, unstructured input views, posing two technical questions: (1) Can transient distractors be reliably isolated and suppressed within a feed-forward attention-based multi-view geometry model? (2) How can supervision from only 2D data be leveraged to achieve full 3D generalization in the wild?
VGTW Architecture and Distractor-Aware Training
VGTW is instantiated on top of competitive permutation-equivariant transformer frameworks (e.g., VGGT, π3) and extends their core architecture with distractor-aware modules (Figure 1). Input images are encoded via DINO-based patch embeddings, and processed through interleaved view-wise and global self-attention transformer layers, culminating in dense geometric and confidence outputs.
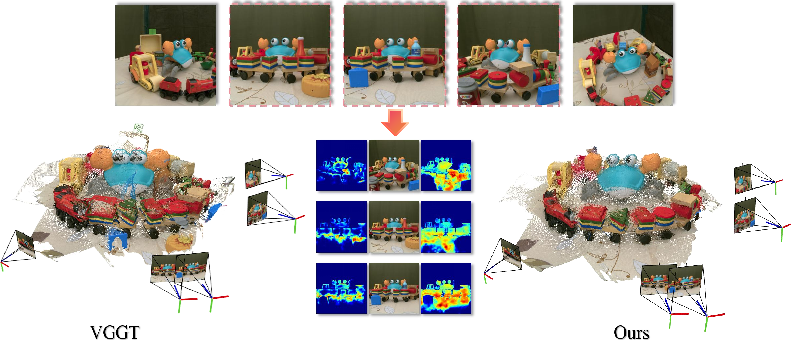
Figure 1: VGTW is a feed-forward method for distractor-free 3D reconstruction from highly inconsistent multi-view input. Center: the model’s confidence maps highlight reliable regions.
Unlike previous work, VGTW introduces a mask prediction head trained to output dense distractor masks, supervised using the newly annotated RobustNeRF-Mask dataset with pixel-level transient annotations. This head facilitates three novel training constraints, realized via LoRA-tuned transformers:
- Distractor Suppression Loss drives cross-view similarity in identified distractor regions below a small fixed margin, minimizing attention leakage to dynamic content.
- Cross-View Consistency Loss pulls static features together only when reliable matches exist, governed by patch similarity, thus reinforcing geometric coherence without over-constraining for large epipolar deformations or parallax.
- Mask BCE Loss directly optimizes alignment to ground-truth pixel labels.
This enables the transformer’s attention mechanism to robustly filter out transients at both training and test time, without any explicit 3D supervision.
Analysis of Distractor Suppression Mechanisms
Extensive analysis demonstrates transient-aware attention is both necessary and sufficient for robust 3D point cloud estimation in unconstrained environments. By visualizing attention maps, feature similarity, and final 3D reconstructions (Figure 2 and Figure 3), clear mode collapse occurs when attention is not properly suppressed—dynamically inconsistent regions are aggregated, inflating confidence and producing geometric artifacts in reconstruction.
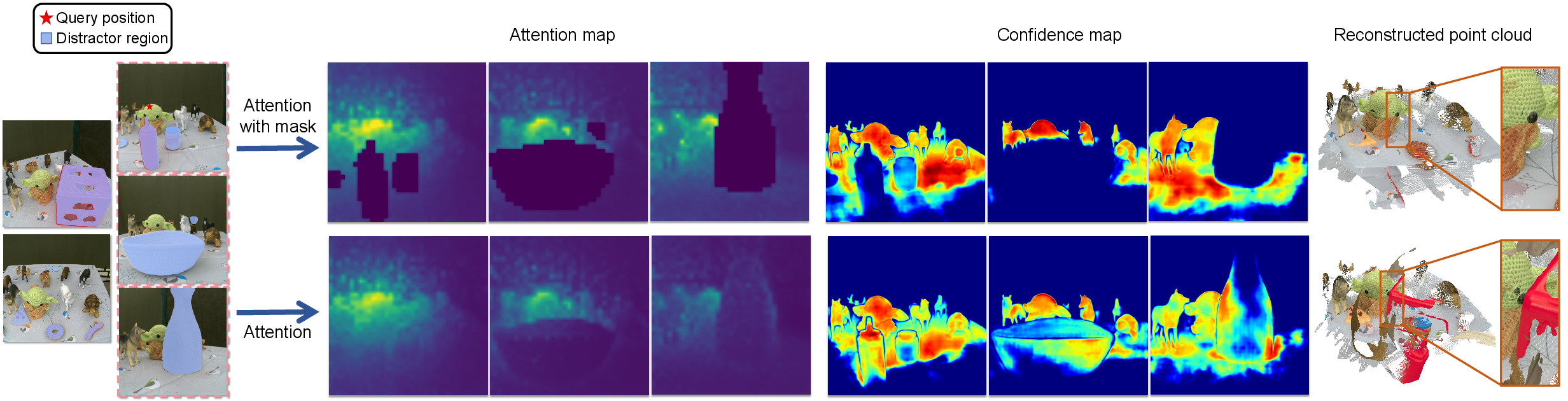
Figure 2: The effect of using the distractor mask in the attention map, generated confidence map, and point cloud reconstruction.

Figure 3: Visualization of VGTW’s attention, feature similarity, confidence maps, and resulting point cloud—clean separation of distractors is visible.
Masking-out distractor regions within attention maps using either ground truth or learned masks results in significant recovery of correct geometry, validated by quantitative reductions in geometric error and increased normal consistency. The feature decoupling mechanism, visualized via cross-view similarity maps, further demonstrates removal of correlation between static and dynamic regions.
Experimental Evaluation
VGTW is evaluated on multiple challenging benchmarks (RobustNeRF, NeRF-On-the-go, DAVIS), employing precise depth and point map metrics (accuracy, completeness, normal consistency). Results consistently show that VGTW (when equipped with distractor-aware training and masking) achieves state-of-the-art overall performance, particularly in medium/high occlusion and challenging distractor scenarios (see Figure 4, Figure 5, and Table summaries).
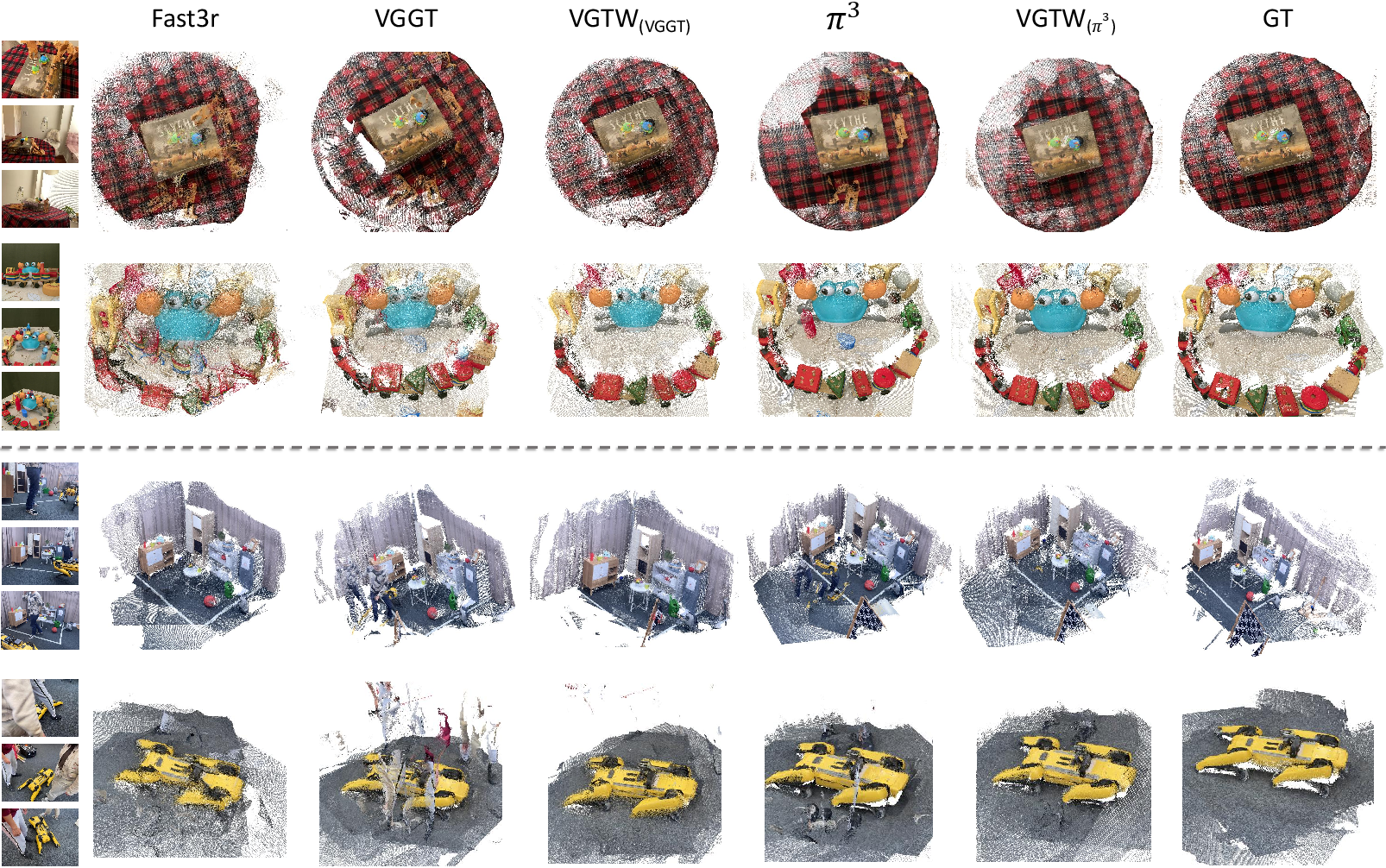
Figure 4: Point map estimation results—RobustNeRF (above), NeRF On-the-go (below). VGTW achieves significantly cleaner results.

Figure 5: VGTW qualitative results: rows 1-3 RobustNeRF objects, 4-6 NeRF On-the-go; distractors are effectively suppressed.
Compared to baselines such as Fast3R, VGGT, and DUSt3R, VGTW yields considerably lower accuracy and completeness errors and much higher normal consistency, especially notable in high-occlusion test cases or when trained on data with noisy distractor annotations. The architecture’s fully feed-forward nature ensures inference-time efficiency is preserved (matching VGGT), and severe test-time data contamination is gracefully handled thanks to explicit feature separation and robust mask prediction.
Ablation studies corroborate the essential contribution of suppressive and cross-view consistency losses—removing either yields elevated distractor artifacts and geometric ghosting (Figure 6).
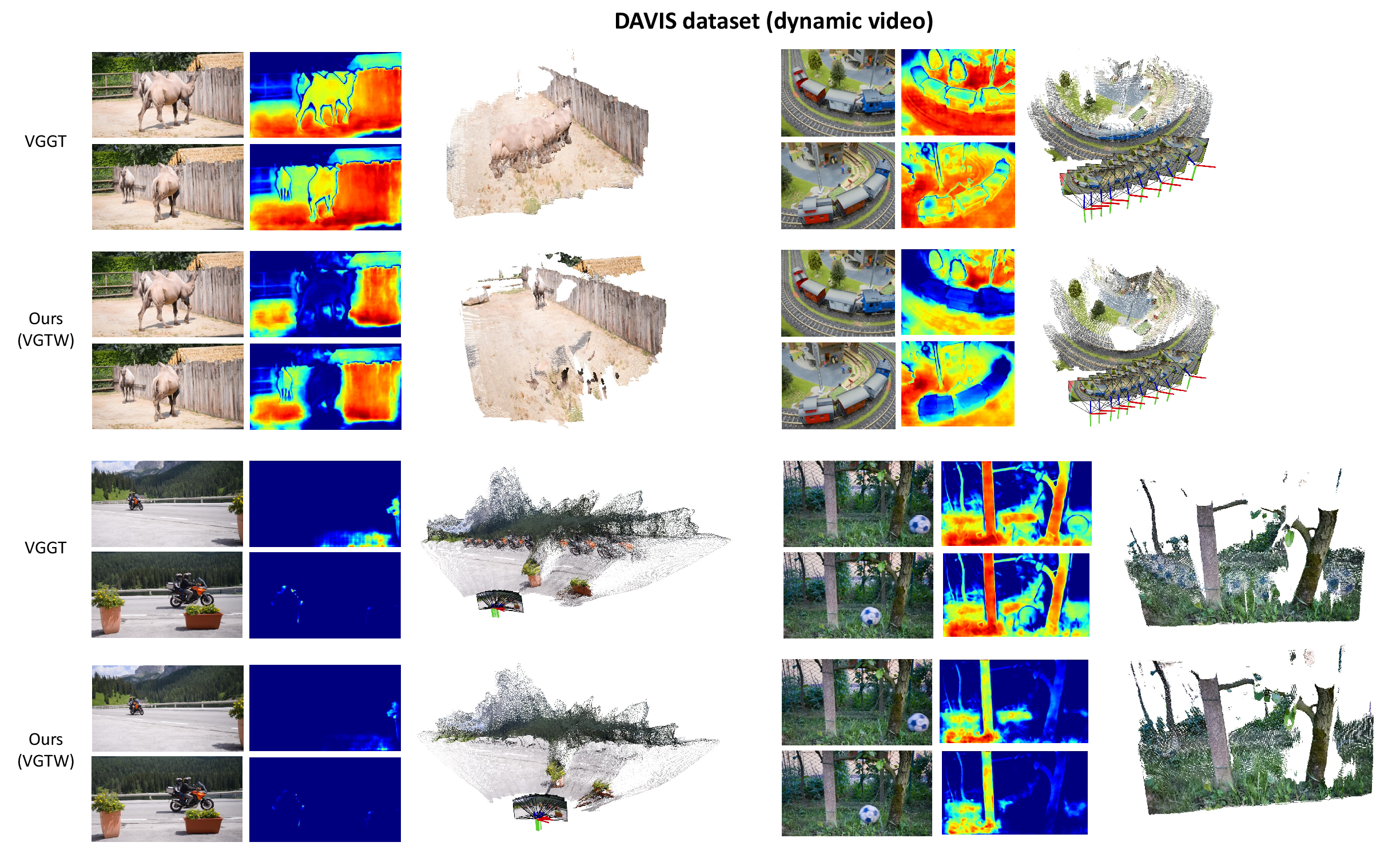
Figure 6: Qualitative results on DAVIS showing VGTW (top) vs. baseline VGGT (bottom); dynamic objects (e.g., moving camels, motorbike riders) are successfully suppressed.
Moreover, cross-domain and static-scene evaluations indicate VGTW’s distractor-aware design does not compromise reconstruction quality when distractors are absent (Figure 7).
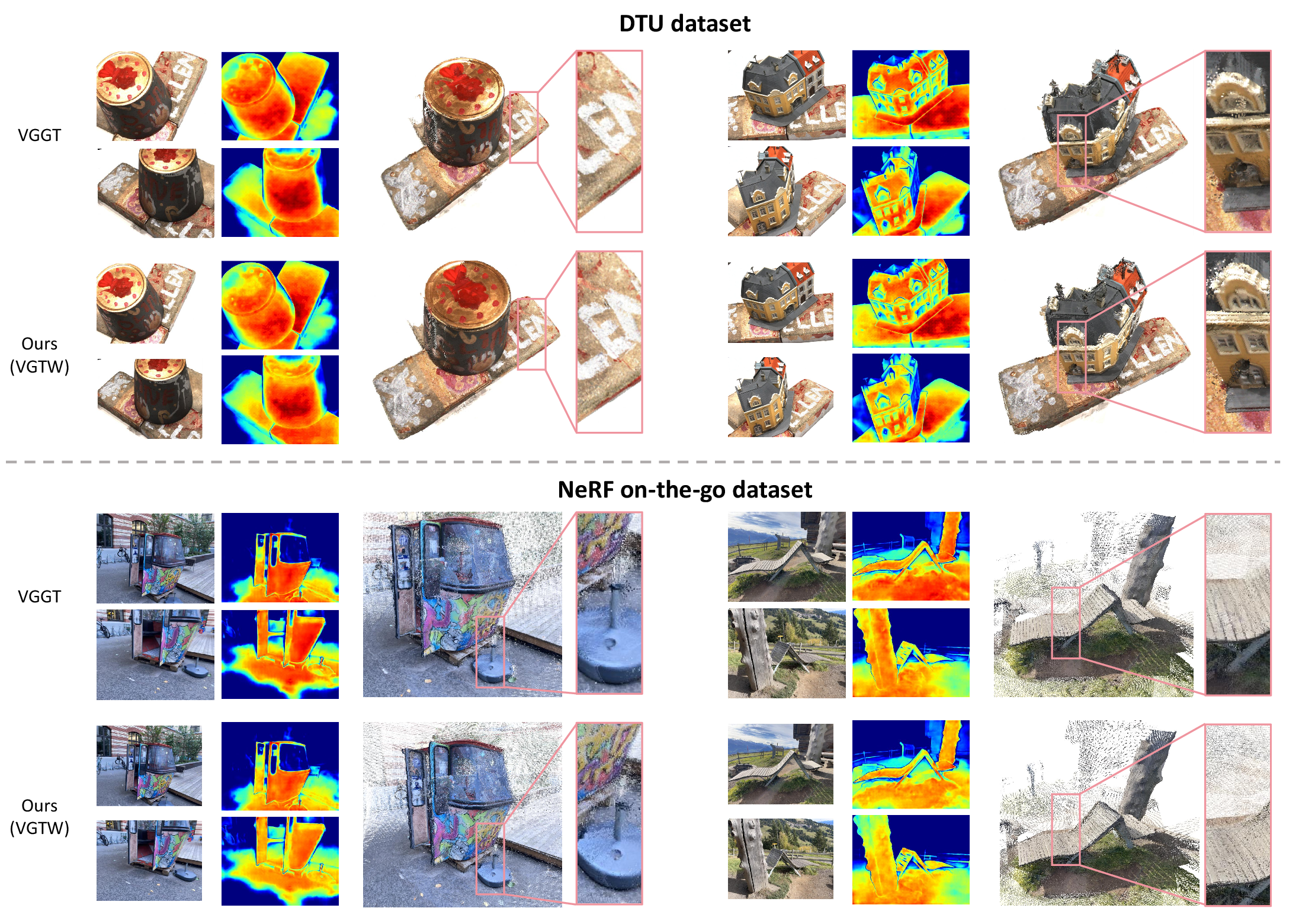
Figure 7: VGTW on static, distractor-free DTU and NeRF On-the-go scenes: performance matches the original VGGT.
Practical and Theoretical Implications
VGTW seamlessly adapts to real-world sequences featuring arbitrary numbers and types of transient distractors, without the latency or overfitting risks of per-scene optimization. It achieves state-of-the-art geometry recovery using only weak 2D supervision and limited annotation budgets (RobustNeRF-Mask provides ∼1000 images). In practical scenarios—such as crowd-sourced photo collections, outdoor street scenes, or dynamic video—VGTW offers a scalable, robust, fully automated 3D modeling pipeline.
Theoretically, the results furnish strong evidence that carefully constructed attention-based training objectives and supervision signals are sufficient for dynamic scene filtering, closing the gap between the speed of feed-forward models and the robustness previously exclusive to iterative or optimization-based pipelines. The auxiliary loss design (cross-view feature margin and similarity-weighted consistency) may generalize to other multi-view vision tasks under real-world, weakly supervised settings.
Future Directions
Several avenues are open for extension: (1) scaling up annotated datasets to improve robustness in highly cluttered or non-rigid environments; (2) extending distractor-aware mechanisms to downstream 3D tasks such as SLAM or object-centric tracking; (3) investigating mask separation at finer granularities (e.g., via scene semantics or temporal consistency); and (4) unifying with appearance and pose prediction models for holistic vision pipelines.
Conclusion
VGTW constitutes a novel, efficient, and highly robust framework for 3D geometry estimation from unconstrained in-the-wild imagery. Through distractor-aware training, explicit cross-view feature separation, and mask prediction—realized on top of state-of-the-art permutation-equivariant transformers—VGTW establishes a new paradigm for feed-forward reconstruction pipelines, offering both high-fidelity geometry and generalization to dynamic, open-world settings.

