Emergent Outlier View Rejection in Visual Geometry Grounded Transformers
Abstract: Reliable 3D reconstruction from in-the-wild image collections is often hindered by "noisy" images-irrelevant inputs with little or no view overlap with others. While traditional Structure-from-Motion pipelines handle such cases through geometric verification and outlier rejection, feed-forward 3D reconstruction models lack these explicit mechanisms, leading to degraded performance under in-the-wild conditions. In this paper, we discover that the existing feed-forward reconstruction model, e.g., VGGT, despite lacking explicit outlier-rejection mechanisms or noise-aware training, can inherently distinguish distractor images. Through an in-depth analysis under varying proportions of synthetic distractors, we identify a specific layer that naturally exhibits outlier-suppressing behavior. Further probing reveals that this layer encodes discriminative internal representations that enable an effective noise-filtering capability, which we simply leverage to perform outlier-view rejection in feed-forward 3D reconstruction without any additional fine-tuning or supervision. Extensive experiments on both controlled and in-the-wild datasets demonstrate that this implicit filtering mechanism is consistent and generalizes well across diverse scenarios.




Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
A simple explanation of “Emergent Outlier View Rejection in Visual Geometry Grounded Transformers”
1. What is this paper about?
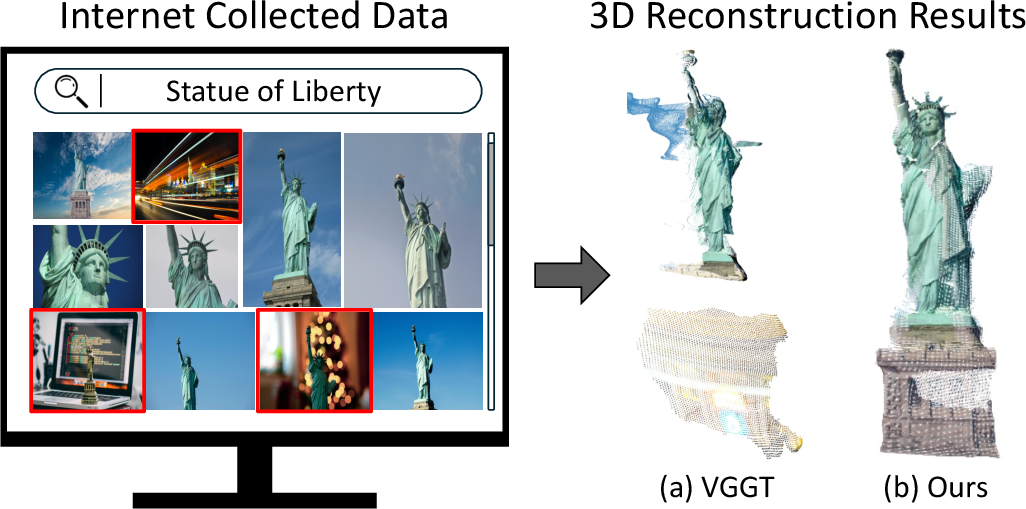
This paper is about making 3D reconstructions from lots of photos more reliable. Imagine you want to build a 3D model of a famous building using pictures from the internet. Some photos will be helpful (they show the building from different angles), but many will be “distractors” (wrong place, wrong object, or no overlap with the others). These bad photos can mess up the 3D model.
The authors show that a modern AI model called VGGT (a transformer for 3D) secretly learns to ignore many of these bad photos—even though it wasn’t trained to do that. They turn this hidden skill into a simple filter that removes bad photos before reconstruction, without retraining the model.
2. What questions did the researchers ask?
They focused on three simple questions:
- Can a feed-forward 3D model (like VGGT), which doesn’t include an explicit “outlier filter,” still tell which photos are useful and which are not?
- If so, where inside the model does this happen?
- Can we use that internal signal to automatically filter out bad photos and get better 3D results, without extra training?
3. How did they study it? (Methods explained simply)
Think of the model as a study group trying to agree on a story about a scene:
- Each photo is a “member” sharing clues (features).
- The model’s “attention” is like how much each member listens to each other.
- If someone talks about a totally different topic (a distractor photo), the group should naturally pay them less attention.
What they did:
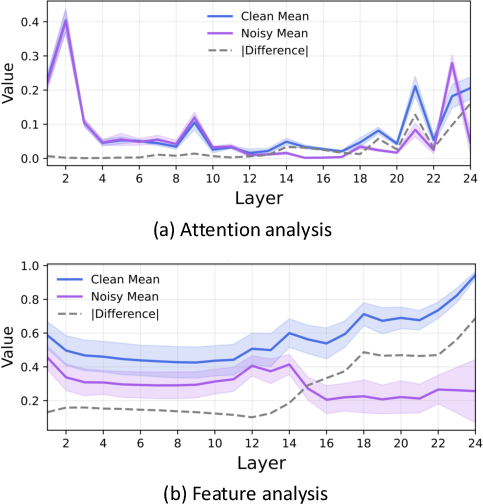
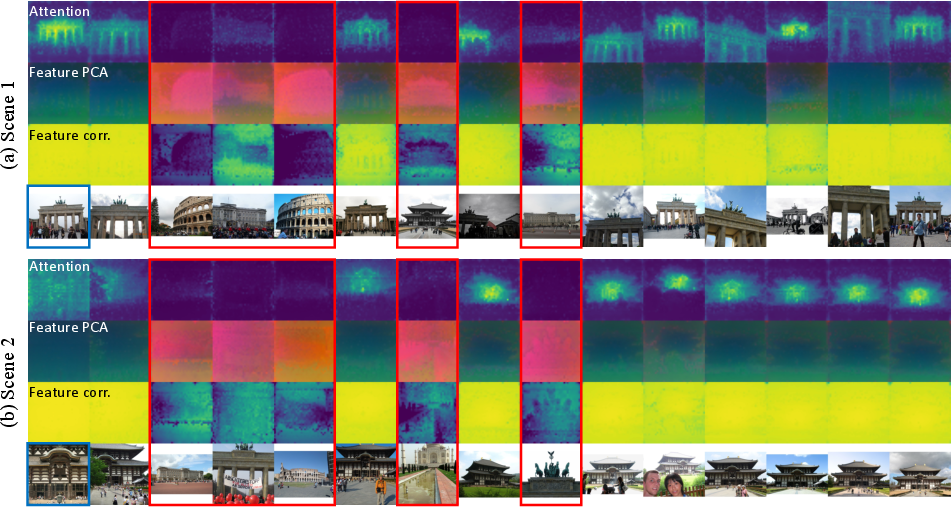
- They looked inside VGGT layer by layer (like peeking into a multi-layered decision process) to see how much each photo “pays attention” to others and how similar their “clues” (features) are.
- They found that in the final layer, the model strongly favors photos that actually match the same scene and downplays distractors.
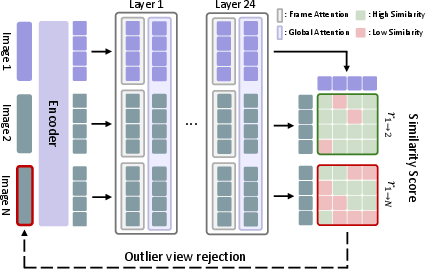
- Using this, they built a simple, training-free filter called RobustVGGT:
- Attention score: how much the model attends from one photo to another.
- Feature similarity: how similar their internal “fingerprints” are.
- 3) Keep only photos whose scores are above a single fixed threshold (like a simple pass/fail).
- 4) Re-run VGGT on just the filtered photos to get the final 3D result.
Key points:
- No retraining.
- No extra modules.
- Just one global threshold that worked across many datasets.
Analogy: It’s like a museum guide organizing a tour. First, they briefly listen to everyone’s suggestions (photos). People who talk about the wrong museum get quietly ignored. Then the guide leads the tour only with the relevant ideas, resulting in a clean, accurate route (the 3D reconstruction).
4. What did they find, and why is it important?
Main findings:
- Emergent skill: VGGT naturally learns to ignore distractors in its last layer, even though it wasn’t taught to do that.
- Two good signals: Both attention and feature similarity in that last layer reliably identify useful vs. bad photos.
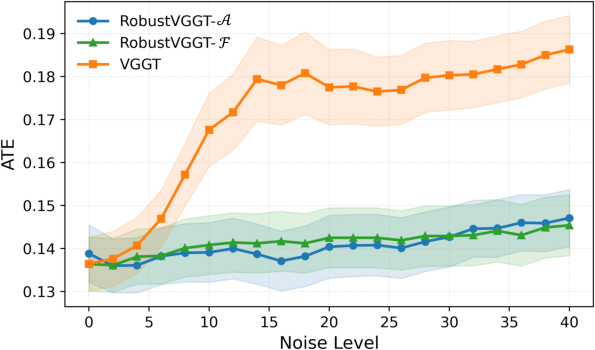
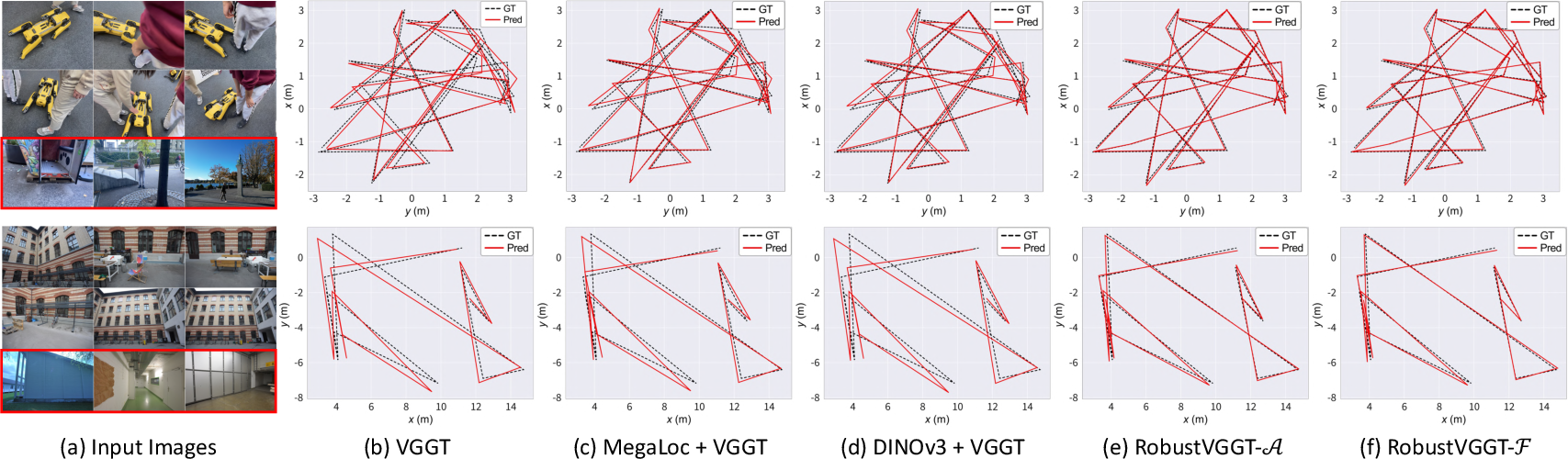
- Strong results: Using these signals to filter photos (“RobustVGGT”) improved camera pose accuracy and depth quality across several challenging datasets, including internet photos and scenes with extra distractors.
- No extra training needed: The method works “as is,” keeping the speed benefits of feed-forward models.
Why it matters:
- Real photo collections are messy. This method makes 3D reconstruction more reliable in real life—when photos are uncurated and contain mistakes, tourists, or totally different places.
- It bridges the gap between old-school pipelines (which verify geometry step by step) and fast new AI models (which usually skip explicit checks).
- It shows that deep models can have useful “hidden behaviors” we can tap into.
5. What’s the bigger impact?
- Better 3D from messy photos: Helpful for AR/VR, robotics, mapping, cultural heritage, and any app that builds 3D from web or phone photos.
- Simpler, faster pipelines: You get robustness like traditional methods without slowing down or adding complex steps.
- New research direction: If models hide useful signals, we can “probe” them to improve stability and trustworthiness—without retraining.
In short, the paper discovers that a modern 3D AI model quietly learns to spot off-topic photos. By reading that internal signal and using a simple filter, the authors make 3D reconstructions cleaner and more reliable, especially in the wild.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, actionable list of what remains missing, uncertain, or unexplored in the paper. Each point is intended to guide future research.
- Mechanistic understanding: What causes the “emergent” outlier suppression at the final layer of VGGT? Conduct causal ablations (e.g., layer/attention-head pruning, training-data perturbations, objective swaps) to determine whether this behavior arises from architecture, training loss, or data distribution.
- Model generality: Does the phenomenon and the proposed filtering hold for other feed-forward reconstruction models (e.g., DUSt3R, Pi3, Grounding models), other transformer architectures, and future VGGT variants?
- Signal choice and fusion: The paper treats attention and feature similarity separately; is there a principled way to combine them (e.g., learned fusion head, reliability weighting per query) that outperforms either alone?
- Threshold selection: The “single global threshold” was tuned on limited datasets. How robust is it under domain shifts (e.g., urban vs. natural scenes, indoor vs. outdoor, different cameras), different image resolutions, and vastly different distractor ratios beyond those tested?
- Adaptive, unsupervised thresholds: Can tau be set per-query or per-scene without supervision (e.g., via mixture modeling, percentile-based thresholds, entropy-based or calibration-based criteria) to handle varying distractor proportions and scene heterogeneity?
- False rejections vs. acceptances: The paper reports distractor rejection success but does not quantify how often clean, geometrically valuable views are incorrectly rejected (nor the downstream impact). Provide precision/recall/F1 for clean-vs-distractor classification and analyze reconstruction trade-offs.
- Long-baseline utility: Do large-baseline, geometrically useful views (which naturally have lower feature similarity/attention) get filtered out? Evaluate controlled cases where long baselines are necessary for triangulation to quantify potential harms.
- Joint consistency across queries: Filtering is defined per-query image, which can yield inconsistent context sets across queries. What is the effect on global coherence (e.g., pose graph connectivity, loop closure)? Explore joint/global selection strategies.
- Runtime and scalability: The method re-runs VGGT after filtering and computes dense cross-view correlations. What is the computational and memory footprint at scale (hundreds/thousands of images, higher resolutions)? Provide complexity analysis and scalable approximations (e.g., token pooling, subsampling, sparse attention).
- Robustness to real-world noise types: The study mainly injects cross-scene distractors. Evaluate robustness to more challenging, realistic noises: near-duplicates with slight edits, heavy occlusions, dynamic objects/motion, severe illumination/weather changes, partial crops, rotations, compression artifacts, and symmetries/repetitive patterns.
- Dynamic and non-static scenes: The approach assumes static scenes. How does filtering perform with temporal changes, moving crowds/vehicles, or structural changes across capture times common in web photo collections?
- Camera intrinsics heterogeneity: How sensitive is the filtering to varied intrinsics (focal lengths, sensor sizes), distortions, and mixed-device datasets? Does it inadvertently favor similar intrinsics over geometric compatibility?
- Ground-truth limitations and metrics: Phototourism and On-the-Go pose/depth evaluations may rely on pseudo-GT or alignment. Include additional 3D metrics (e.g., Chamfer to LiDAR meshes, completeness/density, visibility consistency) and clarify ground-truth sources and alignment biases.
- Failure mode taxonomy: Provide a systematic analysis of failure cases (e.g., look-alike distractors with no overlap, repeated patterns, reflective surfaces, strong perspective distortions) to inform when filtering is likely to err.
- Interaction with classic geometric verification: Explore hybrid pipelines that combine this internal-representation filtering with epipolar checks/RANSAC and bundle adjustment. Quantify when hybrid strategies outperform either alone (e.g., small highly overlapping scenes like RobustNeRF).
- Impact on reconstruction coverage: When views are filtered, what is the effect on scene coverage and completeness (holes, missing surfaces)? Measure trade-offs between robustness and reconstruction density.
- Confidence map synergy: The model predicts per-point confidences. Can these signals be integrated with view-level filtering (e.g., confidence-weighted view scores, bi-level selection) to improve precision?
- Layer sensitivity: The final layer was selected empirically. Do intermediate layers sometimes perform better (e.g., for specific scene types/noise)? Map performance as a function of layer depth and head type.
- Adversarial robustness: Could synthetic or adversarial distractors that maximize attention/feature similarity fool the filter? Test and devise defenses (e.g., regularization, multi-cue consistency).
- Generalization beyond tested domains: Validate the method on out-of-distribution modalities (e.g., aerial/SAR, medical, microscopic) and on very large-scale web collections with heavy long-tail distributions.
- Integration in streaming/online settings: Can the approach support incremental or online reconstruction (e.g., as images arrive), with dynamic thresholds and context management, without costly re-feeds?
- Reproducibility and implementation details: Provide complete implementation guidance for correlation computation (HW×HW complexity), attention aggregation, feature normalization, and re-feeding schedules to ensure replicability across hardware and resolutions.
Practical Applications
Immediate Applications
The paper shows that VGGT’s internal representations naturally suppress outlier views and can be exploited, without retraining, to filter noisy images before feed-forward 3D reconstruction. This enables a set of concrete, deployable improvements to existing pipelines:
- Robust pre-filtering for 3D asset creation from “in-the-wild” photos
- Sectors: software, media/entertainment, AR/VR, e-commerce
- Emerging tools/workflows: a drop-in “view quality scoring” module (RobustVGGT-𝓕/𝓐) that ranks and filters images before running VGGT/DUSt3R/NeRF/3DGS; CLI and Python API to score folders of images and export a filtered set; Blender/Unity plug-ins to prefilter inputs during 3D capture/import
- Assumptions/dependencies: access to VGGT weights and internal features/attention; static or mostly static scenes; enough view overlap among clean images; GPU memory to perform an initial pass and a second pass after filtering; threshold may need minimal calibration under extreme domain shifts
- Web-photo photogrammetry at scale (crowdsourced landmarks, cultural heritage digitization)
- Sectors: cultural heritage, tourism, mapping/GIS
- Emerging tools/workflows: web crawler + retrieval + RobustVGGT filtering + feed-forward reconstruction; bulk processing that rejects off-topic/community photos without hand-tuned VPR thresholds; improved geometry for public 3D archives
- Assumptions/dependencies: licensing/permissions for web imagery; heterogeneous resolutions/EXIF; domain mismatch can require threshold review
- Construction and AECO site documentation from heterogeneous captures
- Sectors: construction/AECO, real estate
- Emerging tools/workflows: mobile uploader that batches worker photos, applies RobustVGGT scoring to keep only geometrically consistent views, then reconstructs as-built 3D; integration with progress-monitoring dashboards
- Assumptions/dependencies: scenes largely static over the capture window; intermittent moving objects don’t dominate; device/offboard GPU availability
- Real estate and e-commerce 3D listing generation from user-submitted photos
- Sectors: real estate, retail/e-commerce, finance (valuation)
- Emerging tools/workflows: server-side prefiltering API to remove irrelevant room/product photos prior to reconstruction; fewer artifacts in customer-facing 3D tours and product models
- Assumptions/dependencies: sufficient overlapping views per listing/product; standardized image intake pipeline
- NeRF/3D Gaussian Splatting training stabilization via geometry-aware view selection
- Sectors: software/ML platforms
- Emerging tools/workflows: a pre-training hook that filters the training set using RobustVGGT-𝓕 scores; auto-curation for synthetic dataset generation; improvement to training time/quality by eliminating harmful frames
- Assumptions/dependencies: access to frames prior to training; compatibility with existing dataset loaders
- Robotics and drone mapping: prefiltering for offboard/in-batch reconstruction
- Sectors: robotics, drones/UAV, surveying
- Emerging tools/workflows: ROS node or pipeline stage that scores batched keyframes and discards poor-overlap frames before map building; improves robustness in ad-hoc or operator-collected imagery
- Assumptions/dependencies: typically offboard or near-real-time (not hard real-time); static environments work best; dynamic scenes require caution
- Dataset curation and QA for academic benchmarks and internal corpora
- Sectors: academia, ML operations
- Emerging tools/workflows: batch scoring to flag and remove distractors; “view relevance” metrics in dataset cards; automatic audit reports of noise levels in collected image sets
- Assumptions/dependencies: intended use is multi-view 3D of static scenes; scripting to expose VGGT intermediate tensors
- Post-production/VFX pipelines for multi-view depth and camera trajectories
- Sectors: film/VFX, media production
- Emerging tools/workflows: selective frame curation based on RobustVGGT-𝓕 similarity before solving for depth/poses; fewer reprojection artifacts, cleaner point clouds
- Assumptions/dependencies: adequate overlap across selected frames; minor additional pass-time to resubmit filtered sets
- Insurance claims and forensics scene reconstruction from mixed-quality user photos
- Sectors: insurance/finance, public safety
- Emerging tools/workflows: submission portal that filters irrelevant shots before reconstruction; more consistent geometry for downstream claim assessment or accident analysis
- Assumptions/dependencies: scene must be static at capture time; photos sufficiently cover the scene from multiple viewpoints
- Lightweight augmentation to retrieval-based SfM
- Sectors: software, mapping/GIS
- Emerging tools/workflows: second-pass geometry-aware filter after VPR (NetVLAD/MegaLoc) to prune visually similar but non-overlapping distractors; wrappers for COLMAP-like pipelines
- Assumptions/dependencies: requires running a feed-forward pass to read attention/feature cues; adds modest compute but can reduce BA failures later
Long-Term Applications
Building on the paper’s findings, several impactful directions emerge that require further research, scaling, or engineering:
- Real-time, on-device robust view selection for AR glasses and mobile capture assistants
- Sectors: AR/VR, mobile computing, consumer apps
- Emerging tools/products: quantized or distilled models exposing “view relevance” in real time to guide users (“move left,” “too similar,” “bad overlap”); on-device filtering prior to reconstruction
- Assumptions/dependencies: efficient architectures exposing internal scores; hardware acceleration; careful power/latency budgets; handling dynamic scenes
- Architectures with explicit, learnable outlier-rejection heads and training objectives
- Sectors: academia, software
- Emerging tools/workflows: supervised/contrastive training for “view consistency” heads; joint optimization of reconstruction and view selection; benchmarks with controlled distractor noise
- Assumptions/dependencies: labeled or synthetic data for outlier training; stability across domains and objects
- Dynamic-scene robustness: separating distractors from transient/moving content
- Sectors: robotics, autonomous systems, sports/event capture
- Emerging tools/workflows: motion-aware attention/features to discount dynamic elements; coupling with optical flow/scene flow; hybrid static-dynamic recon pipelines
- Assumptions/dependencies: new objectives and datasets with dynamics; evaluation protocols for partial scene consistency
- Web-scale 3D archives via cross-modal retrieval + geometry-aware filtering
- Sectors: cultural heritage, education, public sector
- Emerging tools/workflows: text-to-image retrieval to gather candidates, then RobustVGGT-like selection to keep only geometrically consistent subsets prior to reconstruction; public 3D knowledge bases
- Assumptions/dependencies: rights management; large-scale compute; multilingual retrieval aligned with geometric relevance
- Standards and policy for “distractor-robust” 3D reconstruction evaluation
- Sectors: policy/governance, academia, industry consortia
- Emerging tools/workflows: shared protocols and metrics for noise robustness; recommended thresholds/ranges; dataset release guidelines that include distractor distributions
- Assumptions/dependencies: community adoption; diverse scene coverage; alignment with privacy and data-use policies
- Data security and MLOps: geometry-aware filters against dataset poisoning and out-of-domain intake
- Sectors: cybersecurity, ML platforms
- Emerging tools/workflows: automated gates that downrank anomalous or geometrically inconsistent views before storage/training; integration with data versioning and lineage systems
- Assumptions/dependencies: correlation between geometry inconsistency and malicious/out-of-domain content; logging and auditability requirements
- Multi-robot cooperative mapping with cross-agent view filtering
- Sectors: robotics, defense, industrial inspection
- Emerging tools/workflows: cross-robot view relevance scoring to share only useful frames; bandwidth-efficient collaboration; improved global maps
- Assumptions/dependencies: inter-agent synchronization; robust identity and time alignment; partial overlap modeling
- Enterprise digital twin pipelines with automated capture guidance and filtering
- Sectors: manufacturing, energy, smart infrastructure
- Emerging tools/workflows: capture-planning tools that simulate view relevance; automatic filtering during ingestion; fewer artifacts in facility twins used for maintenance/analytics
- Assumptions/dependencies: integration with CMMS/PLM stacks; domain-specific texture/lighting conditions; safety and compliance constraints
- Medical and scientific imaging extensions (e.g., endoscopy-like multi-view recon)
- Sectors: healthcare, scientific research
- Emerging tools/workflows: adapted view-relevance scoring for specialized optics and illumination; improved 3D recon from challenging, partially overlapping sequences
- Assumptions/dependencies: domain shift is large—requires retraining or calibration; strict validation and regulatory approval; patient privacy and safety
Notes on feasibility and deployment
- Core dependency: access to a feed-forward reconstruction model (e.g., VGGT) that exposes intermediate attention and features; some frameworks may require minor code changes to return these tensors.
- Thresholding: the paper reports single global thresholds working across tested datasets; however, extreme domains (e.g., medical, aerial, underwater) may require light calibration.
- Scene assumptions: methods are most reliable for static scenes with at least moderate view overlap; heavy dynamics can confound “distractor” detection.
- Compute: the workflow typically adds an initial pass to score views and a second pass to reconstruct with filtered inputs; pipeline parallelism or caching can mitigate added latency.
- Licensing and governance: ensure rights to process web-sourced images; add dataset cards documenting filtering and its impact on bias and coverage.
Glossary
- AbsRel: Mean absolute relative error used to evaluate depth estimation accuracy after alignment. "AbsRel, a mean absolute relative error, and , percentage of pixels whose predicted-to-GT depth ratio is within 1.25"
- affine-invariant depth estimation: Evaluation protocol that aligns predicted depths to ground truth up to scale and shift. "Following practice in affine-invariant depth estimation~\cite{ke2024repurposing, yang2024depth}, we align the predicted depth maps to the ground truth using a scale and shift"
- alternating attention: Transformer design where layers alternate between different attention types (e.g., frame-wise and global). "alternating attention layers that consist of frame-wise and global attention"
- attention maps: Matrices of attention weights indicating relationships among tokens or views. "attention maps and intermediate features naturally emphasize spatially relevant, 3D-consistent views"
- bag-of-words: Image retrieval representation that quantizes local features into a visual vocabulary. "Early approaches use bag-of-words~\cite{sivic2003video,nister2006scalable} or VLAD-based encoding"
- bundle adjustment: Nonlinear optimization that jointly refines camera parameters and 3D structure. "followed by bundle adjustment ~\cite{triggs1999bundle}"
- CLS token: Special transformer token used as a global descriptor of an image. "regardless of how we derive a global descriptor, e.g., CLS token or GeM pooling"
- COLMAP: A widely used SfM system with geometric verification and robust filtering. "Systems like COLMAP~\cite{schonberger2016structure} include these multi-stage procedures and are resilient to outlier views"
- correlation map: A matrix of pairwise feature correlations across spatial positions of two images. "we first compute a pixel-wise correlation map~\cite{rocco2017convolutional} across all spatial positions"
- cosine similarity: Similarity measure between feature vectors based on the cosine of the angle between them. "the cosine similarity between the query feature map and each context feature map, which is computed pixel-wise on -normalized features"
- cost volumes: Volumetric representations encoding matching costs across depth hypotheses for depth inference. "Learning-based multi-view 3D reconstruction has largely advanced through cost volumes that infer per-view depth followed by fusion"
- cross-view attention: Attention linking tokens across different images to model inter-view relationships. "We show cross-view attention maps and intermediate feature–similarity maps from the final layer of VGGT"
- decoder heads: Output modules in a network that predict specific quantities like pose or depth. "to feed to dedicated decoder heads to estimate and , along with a dedicated head for direct regression"
- dot-product attention: Attention mechanism computed via dot products of queries and keys. " is obtained from dot-product attention between query and key projections"
- epipolar consistency checks: Geometric constraints ensuring correspondences lie on epipolar lines between two views. "stages such as geometric verification, epipolar consistency checks, and RANSAC-based outlier rejection"
- feed-forward 3D reconstruction: Direct prediction of geometry and poses without iterative optimization or explicit matching. "feed-forward 3D reconstruction models lack these explicit mechanisms"
- frame-wise attention: Attention computed within individual frames to model intra-view relationships. "alternating attention layers that consist of frame-wise and global attention"
- GeM pooling: Generalized mean pooling used to aggregate features into a global descriptor. "e.g., CLS token or GeM pooling~\cite{radenovic2018fine}"
- geometric verification: Procedures that validate matches using geometric constraints (e.g., epipolar geometry, RANSAC). "handle such cases through geometric verification and outlier rejection"
- global attention: Attention across frames or the entire set to model inter-view/global context. "alternating attention layers that consist of frame-wise and global attention"
- -normalized features: Features scaled to unit norm to stabilize similarity computations. "computed pixel-wise on -normalized features and then averaged over pixels"
- multi-head averaged attention: Attention weights averaged across heads in a multi-head attention module. " the multi-head averaged attention"
- multi-view 3D reconstruction: Recovering 3D structure and camera poses from multiple overlapping images. "Multi-view 3D reconstruction~\cite{hartley2003multiple,schonberger2016structure}, the task of recovering scene geometry and camera poses from images with overlapping views"
- NetVLAD: Neural VLAD-style descriptor used for image retrieval and place recognition. "learned descriptors such as NetVLAD~\cite{arandjelovic2016netvlad}, GeM~\cite{radenovic2018fine}, MegaLoc~\cite{berton2025megaloc} and DELF~\cite{noh2017large}"
- outlier-view rejection: Filtering images that are inconsistent with scene geometry to improve reconstruction. "perform outlier-view rejection in feed-forward 3D reconstruction without any additional fine-tuning or supervision"
- pointmap: A per-image set of 3D points aligned with image pixels, optionally with confidences. "Another seemingly reasonable option is to leverage the per-point confidence scores predicted with each pointmap to discard unreliable 3D points"
- RANSAC-based outlier rejection: Robust estimation technique that removes mismatches by consensus. "stages such as geometric verification, epipolar consistency checks, and RANSAC-based outlier rejection"
- Relative Pose Error (RPE): Error in relative motion between consecutive frames, measured in translation and rotation. "RPE and RPE, translational/rotational errors between consecutive frames."
- Sim(3)-aligned RMSE: Trajectory error after aligning predictions to ground truth with a similarity transform (scale, rotation, translation). "ATE, a Sim(3)-aligned RMSE of camera centers"
- Structure-from-Motion (SfM): Pipeline that estimates camera parameters and 3D structure from multiple images. "Classical Structure-from-Motion (SfM) pipelines address this challenge through stage-wise filtering and verification"
- transformer-based encoder: Network component using transformer blocks to process image features. "a transformer-based encoder and alternating attention layers that consist of frame-wise and global attention"
- triangulation: Computing 3D point positions from multiple camera views using geometric constraints. "triangulation~\cite{hartley1997triangulation}"
- unprojecting: Lifting per-pixel depths into 3D points using estimated camera poses. "unprojecting using estimated poses "
- visual place recognition (VPR): Identifying the location of an image using visual descriptors and retrieval. "followed by image retrieval or VPR to identify candidate views"
- view graph: Graph connecting images based on matches, used to initialize or optimize SfM. "integrated into systems like COLMAP~\cite{schonberger2016structure} to initialize the view graph"
- view-graph optimization: Global optimization over a graph of views and their relationships. "global view-graph optimization and bundle adjustment are particularly effective"
- view selectivity: Model tendency to emphasize geometrically consistent views and downweight distractors. "exhibits an emergent form of view selectivity in its internal representations"
- VLAD-based encoding: Aggregation method that summarizes local descriptors into a compact global vector. "VLAD-based encoding~\cite{jegou2010aggregating}"
Collections
Sign up for free to add this paper to one or more collections.