Inverting the Bellman Equation: From $Q$-Values to World Models
Abstract: Model-based and model-free reinforcement learning are traditionally viewed as separate paradigms: instead of learning a model of the transition kernel $P$, model-free agents typically estimate value functions tied to a specific policy and reward. In this paper, we challenge this dichotomy by proving that value-based agents trained on a sufficiently rich set of reward functions, e.g. using goal-conditioned RL, implicitly encode a unique and accurate world model. To extract this model in practice, we introduce \textit{$P$-learning}, an inverse analogue to $Q$-learning that samples from an agent's $Q$-values, policies and rewards to decode its internal model of the environment. We then provide sufficient conditions on the type and number of goals for which agents encode the true kernel $P$, covering both stochastic and deterministic MDPs over finite or continuous state spaces. Even when our assumptions are violated, we empirically demonstrate that agents trained on a handful of reward functions encode accurate dynamics in $\texttt{Reacher}$, $\texttt{MountainCar}$ and stochastic variants of $\texttt{FourRooms}$. Surprisingly, we find that policies trained exclusively on a \texttt{Reacher} agent's implicit world model are quasi-optimal on out-of-distribution, velocity-based goals despite position-only training -- suggesting that agents contain hidden generalisation capabilities and providing a new lens into the connection between model-based, model-free, and goal-conditioned RL.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper asks a simple but powerful question: if you train a reinforcement learning (RL) agent on lots of different goals, does it secretly learn a “map” of how the world works? The authors show that the answer is yes. They introduce a method called P-learning that can pull this hidden world model out of an agent’s learned action values (its Q-values). They also prove when this is possible and show it works in practice on popular RL tasks.
Key Questions the Paper Tries to Answer
- When an RL agent is trained on many goals, does it implicitly learn how the world changes when it takes an action (a world model)?
- Can we recover that hidden world model just from the agent’s Q-values and rewards, without interacting with the environment again?
- Under what conditions (types and number of goals) is the model unique and accurate?
- If we extract this model, can it help the agent do well on new tasks it wasn’t trained for?
How the Researchers Approached the Problem
Think of an RL agent like a player in a game:
- Q-values are like a score the agent gives each possible action in a state, telling it how good that action is for a goal.
- A world model is the “map” of the game: if you do X now, what happens next?
- The Bellman equation is a consistency rule that says: “Your current score for an action should match your estimate of what happens next plus the reward you get.” In normal Q-learning, you assume the world model is known (or fixed) and adjust the Q-values to satisfy this rule.
The authors flip this around:
- P-learning (P for “transitions”) treats the agent’s Q-values as fixed and adjusts a candidate world model until the Bellman rule holds. In everyday terms: if you know how good different actions are across many goals, you can reverse-engineer the map that would make those action scores make sense.
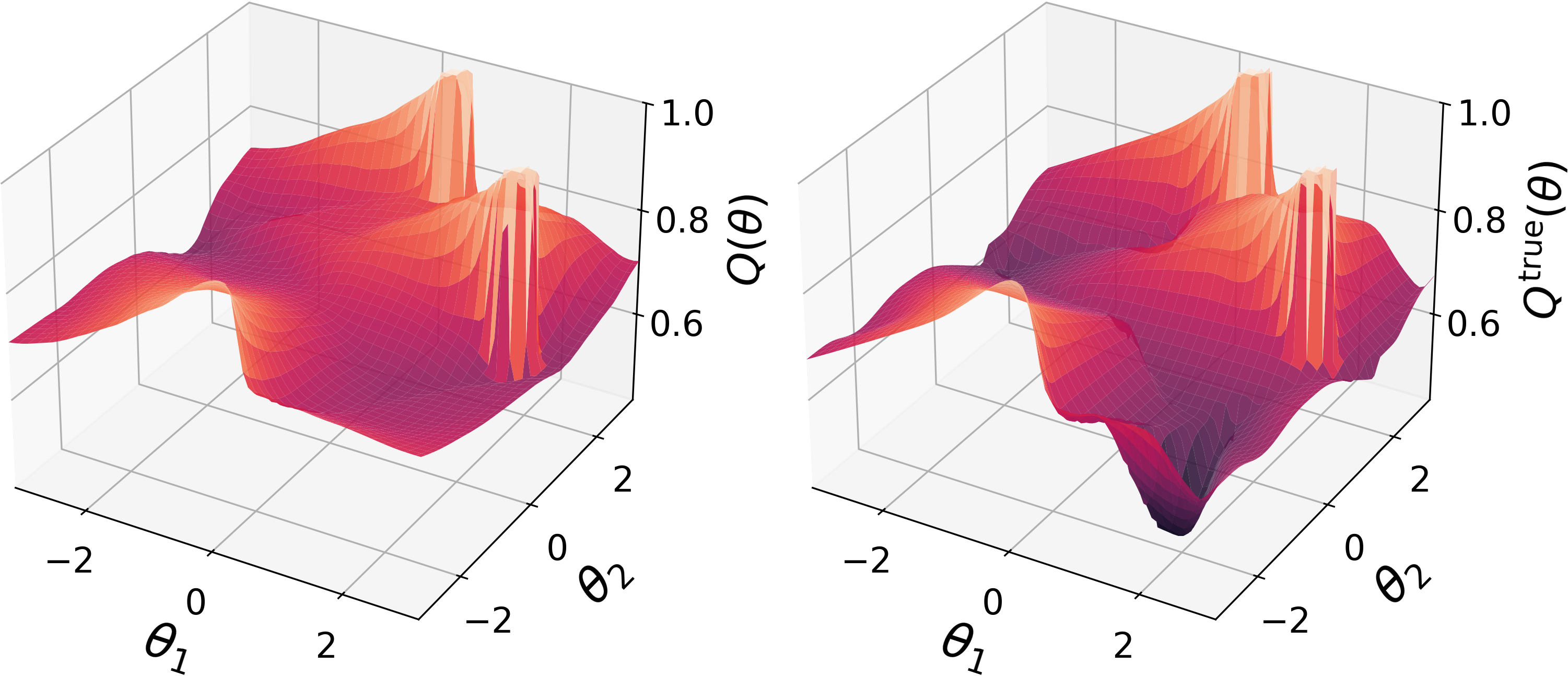
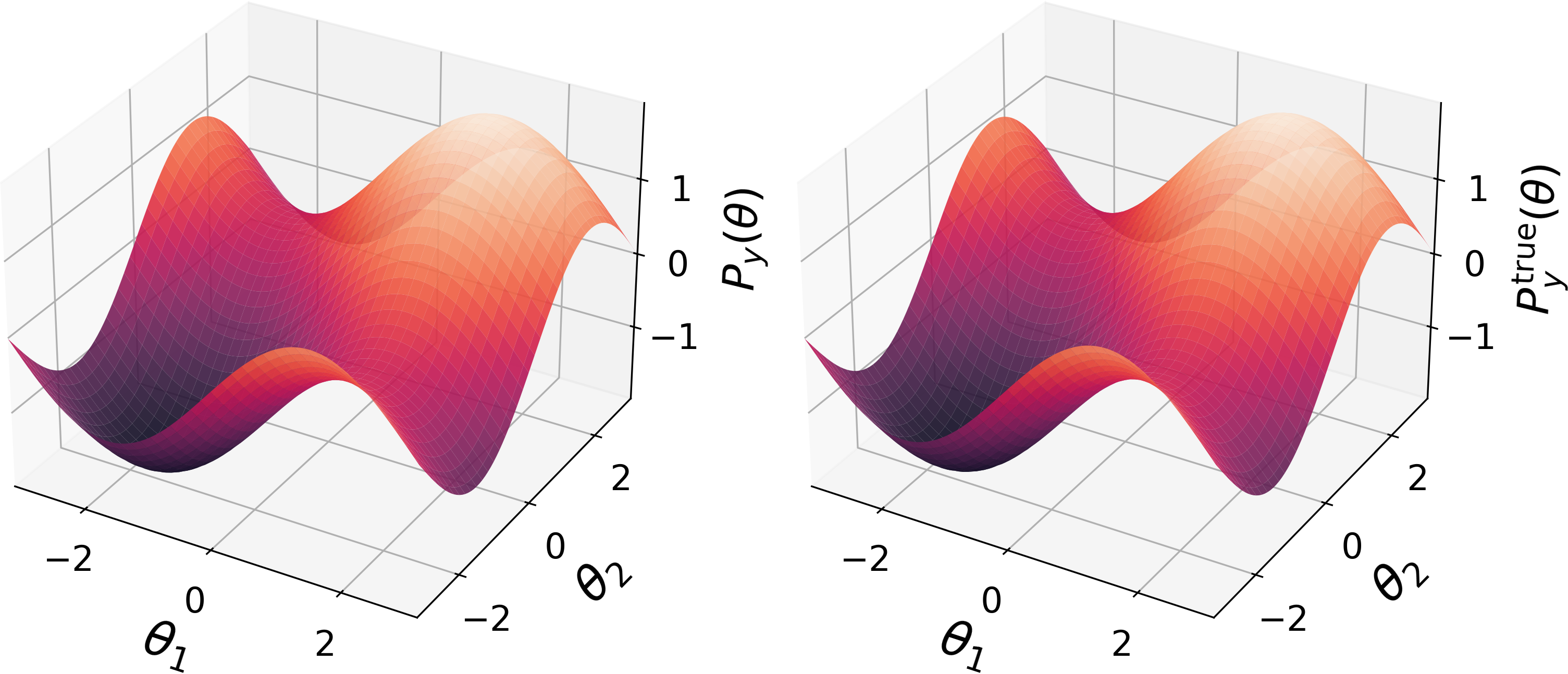
- They prove that, in a simple “table” setting, this process converges to the world model that best matches the agent’s Q-values. When enough and the right types of goals are used, this model is unique—and if the Q-values are correct, it matches the true environment.
- They analyze different cases: predictable worlds (deterministic) vs. worlds with randomness (stochastic), and small, discrete worlds vs. continuous ones (like positions and angles). They explain how many and what kinds of goals are needed in each case so the map is uniquely recoverable.
Analogy: Imagine you only know how long it takes to reach different landmarks from different starting points (those are like Q-values for many goals). If you have enough of these travel-time clues, you can reconstruct the road map (the world model) that must be underneath.
Main Findings and Why They Matter
Here are the highlights, first from theory and then from experiments:
Theoretical Results (what they proved)
- Breaking ambiguity with multiple goals: In general, different worlds can produce the same Q-values for a single goal (this is called “value equivalence”). But:
- In deterministic, discrete worlds, one well-chosen goal often suffices to uniquely identify the world model.
- In stochastic (random) discrete worlds, you usually need enough different goals to “span” the state space—think goals that collectively touch all parts of the world.
- In continuous worlds (like positions and angles), you typically need goals that “cover” the space (e.g., goals spread across the area). For some special reward types (like Gaussian-shaped rewards), a finite number of goals can still be enough in deterministic settings.
- Stability with imperfect Q-values: Even if the agent’s Q-values are only approximate (as in real life), the extracted model is close to the true model, and the authors provide error bounds.
- Convergence: In a tabular setting (small, discrete case), P-learning converges to a clear, best-fitting model for the agent’s Q-values.
Why this matters: It means that, with sufficiently rich goal training, model-free agents (which don’t explicitly learn a world model) actually do internalize one—and we can pull it out.
Experimental Results (what they showed in practice)
They tested P-learning on:
- FourRooms (a grid world), with increasing randomness:
- Deterministic: recovering the model well with just 1 goal.
- “Windy” (local randomness): very few goals needed.
- Teleporting (more randomness): more goals (about 20) were sufficient for near-perfect recovery.
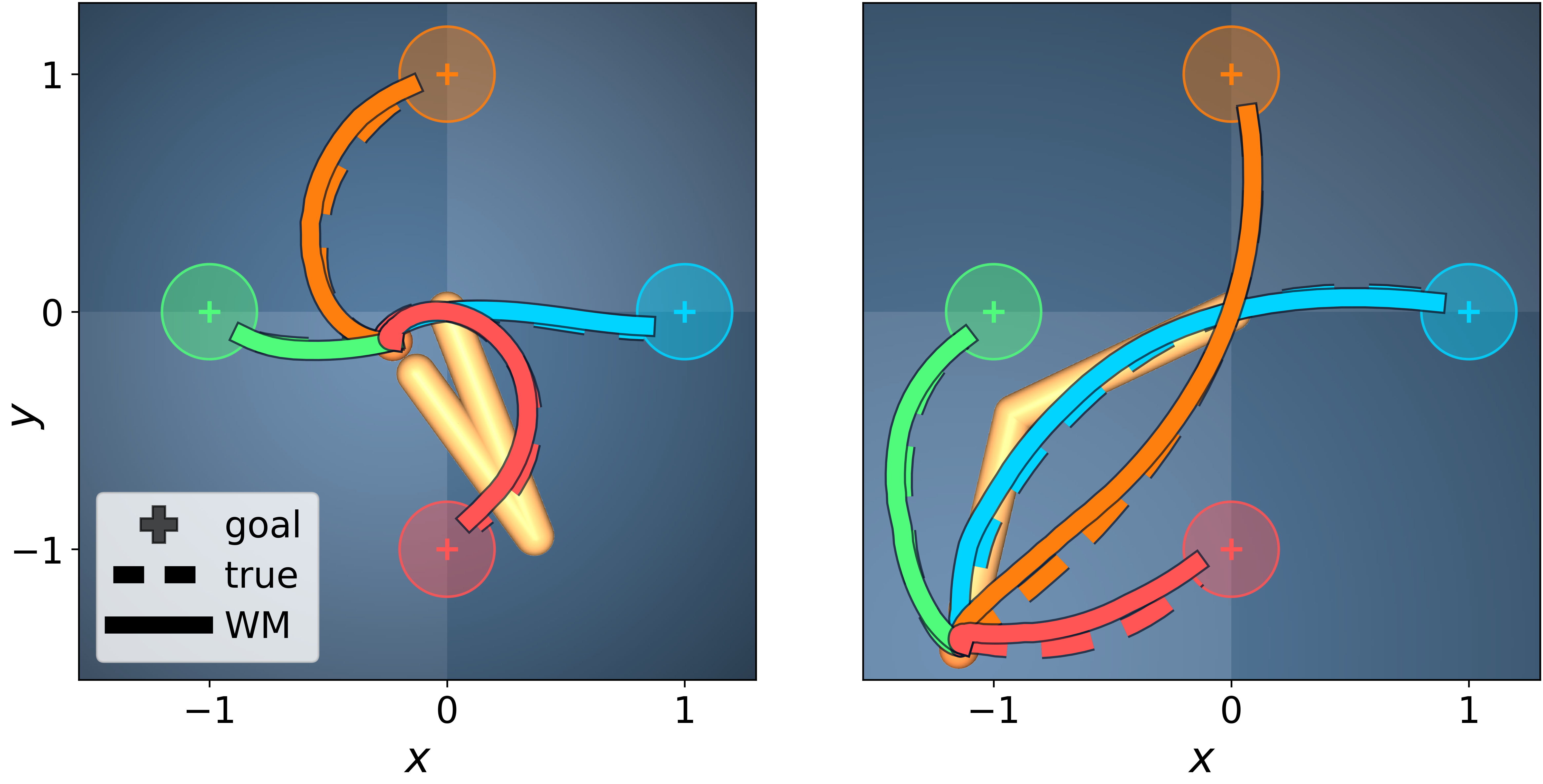
- MuJoCo Reacher (robotic arm; continuous, deterministic):
- Trained on only 4 position-based goals.
- Despite Q-values not being perfect, the extracted world model was extremely accurate.
- Planning only inside the extracted model produced near-optimal behavior for new, out-of-distribution tasks, including goals about joint angles and even angular velocities—variables the rewards never referenced during training.
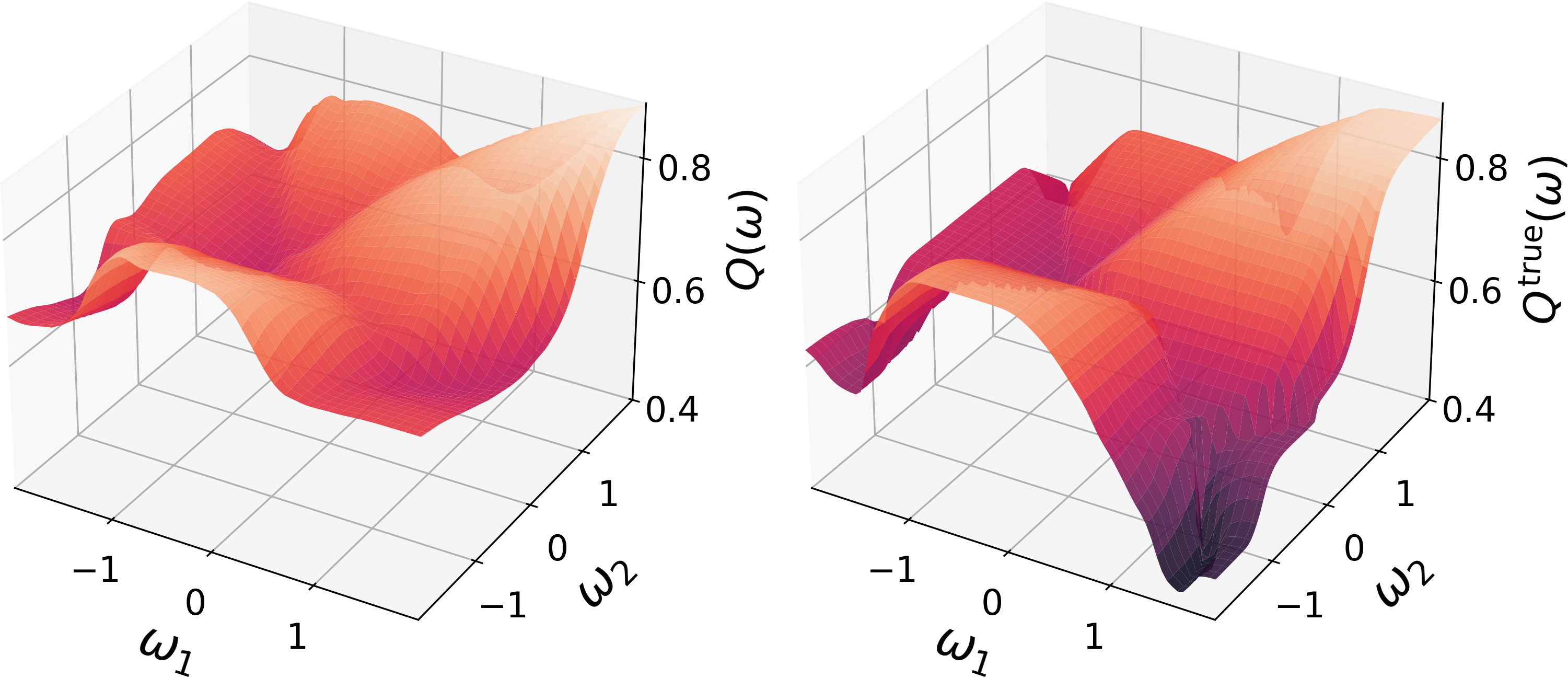
- MountainCar (continuous, deterministic):
- Trained on 4 position-based goals, extracted a highly accurate model.
- A second agent trained on 4 velocity-based goals produced a nearly identical world model. This suggests agents with very different training goals can encode very similar underlying dynamics.
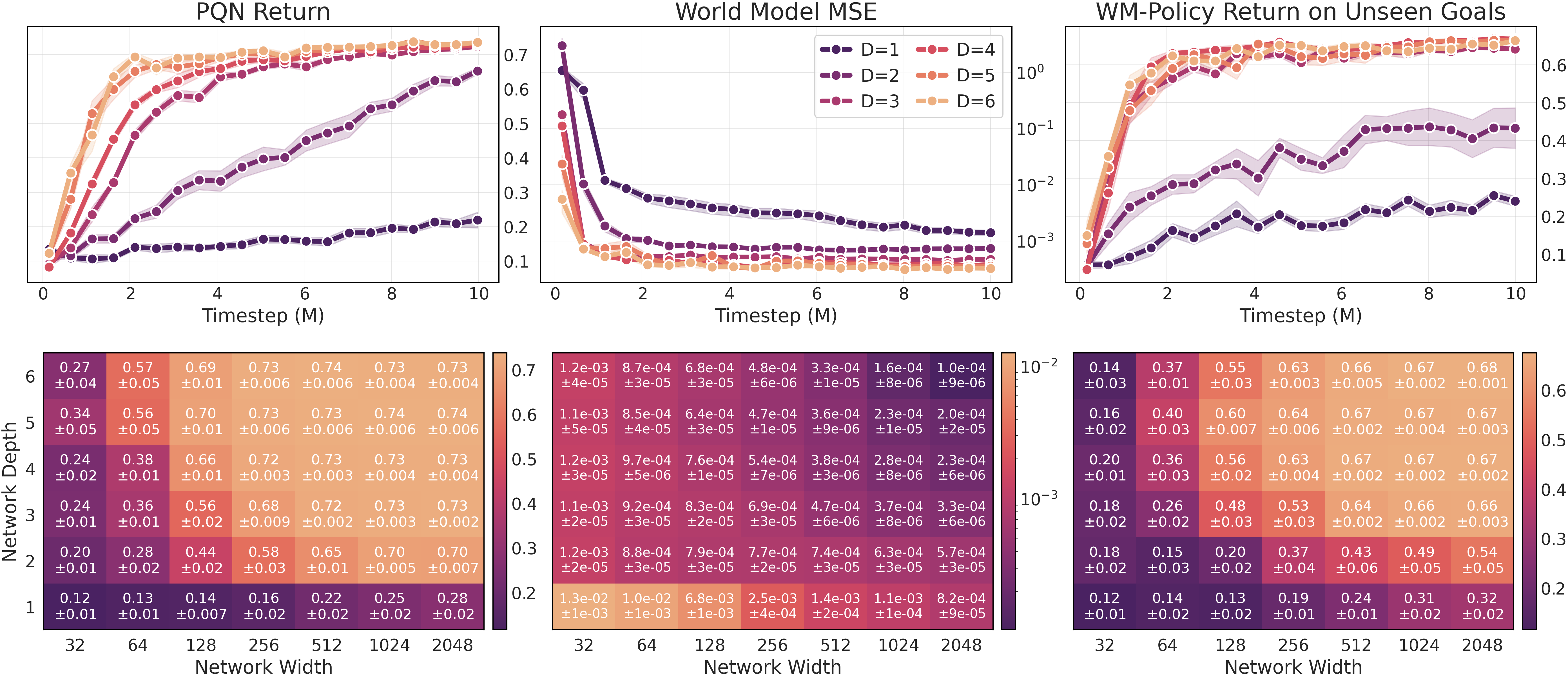
- Strong correlation: Better-performing goal-conditioned agents tended to have more accurate extracted world models. In Reacher, the correlation between agent performance and model accuracy was extremely high.
Why this matters: It shows P-learning works even when the strict theoretical assumptions aren’t fully met (few goals, limited coverage). It also reveals “hidden” generalization: agents trained on one type of goal can, via their internal model, perform well on very different goals.
Implications and Potential Impact
- Unifying model-free and model-based RL: This work blurs the line between these two approaches. Even when we train an agent “model-free,” its value functions can contain a usable model of the world. P-learning makes that model explicit.
- Better reuse of trained agents: If you can extract a world model from an already-trained agent, you can plan for new goals without retraining from scratch—saving time and data.
- Interpretability and safety: Extracted models can help us understand what an agent believes about its environment, which is useful for debugging, auditing, and adapting agents to new tasks.
- Designing better training: Results suggest that training on diverse, well-chosen goals helps agents learn stronger internal models. This could guide how we choose goals in future systems.
In short, the paper shows that if you give an agent a rich diet of goals, it learns more than just how to get rewards—it learns the rules of the world. And with P-learning, we can read that world model out and use it.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of gaps the paper leaves unresolved. Each item is framed to be concrete and actionable for future research.
- Stochastic continuous MDPs with goal-conditioned policies: Theoretical identifiability results currently require unconditional policies; extend proofs (or counterexamples) to general goal-conditioned policies in continuous, stochastic settings.
- Partial observability: No theory or experiments for POMDPs or recurrent value functions; establish identifiability and extraction under observation aliasing and belief-state representations.
- Dependence on known r, π, γ: The method assumes access to the true reward function, the policy used in the Bellman operator, and the discount; analyze robustness to misspecification and develop joint inference for (P, r, π, γ) when one or more are unknown.
- Inverting under the optimality operator: P-learning uses a fixed-policy Bellman operator; characterize identifiability and algorithms when only (or a greedy policy) is available and π is unknown.
- Parametric convergence guarantees: Beyond tabular, there are no guarantees for nonconvex parametric P-learning; derive conditions under which SGD converges to the true model (or bounds the error) in function-approximation regimes.
- Maintaining model validity: Tabular P-learning can leave the probability simplex when M is rank-deficient; analyze convergence and accuracy of projected updates and practical constraints for continuous models (normalization, positivity, support).
- Initialization dependence: With rank-deficient M, the solution depends on ; design principled priors/regularizers (e.g., smoothness, locality, physics constraints) that bias selection toward plausible dynamics and study their effects.
- Sampling distribution d: The objective depends on ; develop active or adaptive sampling strategies that guarantee identifiability and low-variance gradients, and quantify sample complexity.
- Sensitivity to Q-errors: Theory provides finite-MDP bounds, but experiments show high-fidelity P with relatively poor Q; characterize when and why inaccurate Q can still yield accurate P (e.g., noise models, anti-concentration, structure).
- Minimal goal sets: Only sufficient conditions are given; derive necessary (or tighter) conditions and goal-count/sample-complexity bounds for identifiability in deterministic, local, and stochastic regimes.
- Continuous-space goal coverage: Guarantees for indicator goals require large coverage (e.g., $\cG \supseteq \cS \oplus B_\sigma(0)$), yet few goals worked empirically; formally explain when finite, sparse goals suffice via smoothness/controllability assumptions.
- Stochastic continuous experiments: No empirical validation in noisy continuous dynamics; evaluate P-learning under stochastic MuJoCo-like perturbations or injected process noise.
- Long-horizon planning: Planning is demonstrated on short-horizon tasks; quantify compounding model errors over long horizons and their impact on policy optimality in the extracted WM.
- “Local-to-global” hypothesis: The conjecture that local (subset-variable) goals induce accurate global dynamics is unproven; formalize conditions (e.g., observability, coupling, identifiability of latent variables) and test across domains.
- Off-policy training and mismatch: Theory assumes ; analyze extraction when Q is learned off-policy or is a mixture across behaviors, and quantify bias from policy mismatch in P-learning.
- Scalability to high-dimensional observations: No results on image-based states; investigate architectures, regularization, and computational cost to extract P from pixel-based agents.
- Baselines and sample efficiency: No comparison to learning dynamics directly from environment transitions, successor-measure inversion, or MuZero-style models; benchmark accuracy and data efficiency against these alternatives.
- Discount factor effects: can become ill-conditioned as ; assess numerical stability, pseudo-inverse conditioning, and regularization strategies for high-discount settings.
- Termination and options: Results handle “termination upon arrival,” but general termination schemes and options are only sketched; extend theory and practice to arbitrary termination and temporally extended actions.
- Action aliasing: Identifiability when different actions induce similar/identical next-state distributions is not addressed; specify action-separation requirements and their implications for P-learning.
- Multi-step Bellman residuals: Only one-step inversion is studied; investigate whether n-step or λ-returns improve identifiability and data efficiency.
- Query access settings: The method assumes full access to ; study black-box/query models to determine how many and which queries suffice for accurate inversion.
- Uncertainty quantification: There is no propagation of uncertainty from Q to P; develop Bayesian or ensemble P-learning to yield confidence intervals over dynamics.
- Joint (Q,P) training: The paper does not explore co-training Q and P with a consistency loss; evaluate benefits/risks (stability, bias) and provide convergence guarantees.
- Relationship to successor features: Clarify how P-learning behaves when rewards lie in (or outside) a successor-feature subspace, and establish theoretical links or divergences.
- Correlation vs causation: The strong empirical correlation between agent return and WM fidelity does not establish causality; perform controlled interventions to test whether improving WM directly improves performance (and vice versa).
- Reward misspecification: The approach assumes correctly specified reward functions; evaluate how reward shaping/misspecification affects extracted P and whether P-learning can detect inconsistencies.
- Continuous-time limits: No analysis for continuous-time dynamics or SDEs; extend inversion results and algorithms to continuous-time control settings.
Practical Applications
Practical Applications of “Inverting the Bellman Equation: From Q-Values to World Models”
This paper introduces P-learning, an inverse analogue to Q-learning that extracts an agent’s implicit world model (transition dynamics P) from its learned goal-conditioned Q-values, policies, and known rewards. Theoretical results specify when P is uniquely identifiable from Q, and experiments show accurate model extraction and zero-shot planning to out-of-distribution (OOD) goals. Below are actionable applications organized by deployment readiness.
Immediate Applications
- World-model extraction from existing goal-conditioned agents (robotics, simulation software)
- What: Convert a trained model-free agent (with Q and π) into a usable dynamics model P for planning and analysis, using the provided P-learning procedure.
- Potential tools/workflows: Policy-to-Simulator Converter; “WM Extractor” library integrated with popular RL stacks (DQN/SAC/PQN + HER); batch export of Q/π, then P-learning, then planning (VI/MPC) for new goals.
- Assumptions/dependencies: Access to Q-values (or critic), π, and reward functions; sufficiently rich goals or coverage to satisfy identifiability conditions; reasonably accurate Q; near-deterministic settings are easiest.
- Zero-shot task transfer via planning in the extracted WM (robotics, autonomy, games)
- What: Plan for unseen goals (e.g., velocity targets, joint configurations) in the extracted model without environment interaction or retraining.
- Potential tools/workflows: OOD Goal Planner; policy rollout entirely in the WM; quick feasibility checks for new objectives.
- Assumptions/dependencies: Extracted P must be accurate in relevant state dimensions; reward specifications for new goals are available; deterministic or low-noise dynamics improve reliability.
- Auditing and interpretability of agent beliefs (safety, compliance, research tooling)
- What: Compare the extracted P to the ground-truth or a trusted simulator to identify where the agent’s internal model diverges from reality.
- Potential tools/workflows: WM Consistency Monitor; training dashboards tracking WM error alongside return (leveraging the strong correlation observed in the paper).
- Assumptions/dependencies: Ground-truth transitions or a trusted reference simulator; access to internal Q/π; evaluation datasets.
- Goal-set and curriculum design informed by identifiability conditions (academia, RL engineering)
- What: Use the paper’s theory (e.g., spanning/coverage, Gaussian vs indicator goals) to craft minimal goal sets that ensure P is uniquely recoverable.
- Potential tools/workflows: Goal Coverage Analyzer; reward “noise seeding” utility to break value equivalence in deterministic finite MDPs; curriculum scripts that expand goals until rank/injectivity thresholds are met.
- Assumptions/dependencies: Ability to choose or perturb rewards/goals; instrumentation of training pipelines.
- Offline policy improvement for new rewards via the extracted WM (operations research, industrial control)
- What: For a trained agent, extract P and compute improved/alternative policies for new reward functions offline (no environment access).
- Potential tools/workflows: WM-based Planning Head added post hoc; policy libraries that re-plan for new objectives using VI/MPC in P.
- Assumptions/dependencies: Access to agent internals; goal-conditioned or at least multi-goal critic; accuracy of P in the new task’s state-dependence.
- Rapid prototype simulators from black-box training artifacts (simulation, A/B testing)
- What: Where full simulators are hard to maintain, extract usable approximations from trained agents for scenario testing and what-if analysis.
- Potential tools/workflows: “Policy-to-Digital-Twin” utility; CI that validates behaviors against WM-generated trajectories.
- Assumptions/dependencies: Reasonable Q accuracy; stable policy snapshots; domain where state/action spaces are not prohibitively large.
- Training diagnostics and early stopping signals (academia, MLOps for RL)
- What: Track WM error during training to predict final agent performance and generalization (supported by strong Spearman ρ observed).
- Potential tools/workflows: WM Error as a first-class metric; alerts when WM error diverges; model selection by WM accuracy.
- Assumptions/dependencies: Periodic access to model checkpoints; lightweight P-learning variants for frequent evaluation.
- Data augmentation and planning warm-starts for model-based RL (MBRL bootstrapping)
- What: Initialize model-based components (e.g., MBPO/Dreamer dynamics) from P learned via P-learning to improve sample efficiency.
- Potential tools/workflows: WM Distiller; hybrid pipelines where model-free training is followed by P-learning and then MBRL fine-tuning.
- Assumptions/dependencies: Differentiable P parameterization preferred; compatibility between P’s format and downstream MBRL components.
Long-Term Applications
- Safety certification and regulatory auditing of RL controllers (transport, healthcare, energy)
- What: Require deployers to provide the extracted WM and discrepancy reports versus a certified plant model; use WM to test OOD contingency responses offline.
- Potential tools/workflows: Compliance-grade WM Report; WM-based Hazard Analysis; certification templates.
- Assumptions/dependencies: Matured methodology for continuous, stochastic, and partially observable settings; standardized interfaces and benchmarks.
- Reward misspecification detection and correction (AI alignment, governance)
- What: Use inconsistencies between extracted P and known dynamics, or between P-based optimal policy and deployed behavior, to diagnose misspecified rewards and unintended shortcuts.
- Potential tools/workflows: Reward Debugger; counterfactual planners in P to propose alternative rewards achieving intended outcomes.
- Assumptions/dependencies: Access to intended specifications; robust extraction under stochasticity/partial observability.
- Policy-to-simulator pipelines for re-purposing legacy controllers (manufacturing, logistics, robotics)
- What: Convert legacy model-free controllers into reusable digital twins to design and validate new tasks, without retraining from scratch.
- Potential tools/workflows: Controller Upcycling Suite; WM Merge/Diff across software versions.
- Assumptions/dependencies: Ability to instrument or emulate legacy agents; stable behavior under domain shifts.
- Foundation world models via large-scale goal-conditioned pretraining (software, robotics, simulation)
- What: Train GC-RL at scale on rich goal families, then extract a general WM that supports rapid planning for many downstream tasks.
- Potential tools/workflows: WM Hub/Registry; task-agnostic planning services built on shared WMs.
- Assumptions/dependencies: Broad goal coverage; scalable extraction/training; methods to handle high-dimensional continuous/stochastic environments.
- Generalization and transfer across agents via WM alignment (multi-agent systems, platforms)
- What: Extract WMs from multiple agents trained on different goals, align/ensemble them, and plan robustly under model uncertainty.
- Potential tools/workflows: WM Ensemble and Alignment; uncertainty-aware planners over multiple extracted models.
- Assumptions/dependencies: Methods for combining heterogeneous P parameterizations; confidence estimation/calibration.
- Healthcare and clinical decision support (academia, regulated industry)
- What: From policies trained on surrogate outcomes/goals, extract patient trajectory models to simulate alternative treatment goals and constraints.
- Potential tools/workflows: Offline clinical simulators for counterfactual testing; safety-aware planners using extracted P.
- Assumptions/dependencies: Strong causal and ethical safeguards; robust P under stochastic and partially observed dynamics; validated identifiability with observational data.
- Financial decision-making and stress testing (finance)
- What: From trading or allocation policies, extract a dynamics model reflecting agent’s learned market impact to run OOD stress tests and new objective planning.
- Potential tools/workflows: WM-based scenario generators; policy risk analyzers.
- Assumptions/dependencies: Extreme stochasticity and non-stationarity; partial observability; adversarial dynamics.
- Grid and process control contingency planning (energy, industrial control)
- What: Extract WMs from operational RL controllers and use them to plan safe responses to rare events (component failures, demand spikes) under new constraints.
- Potential tools/workflows: WM-backed MPC modules; incident rehearsal in digital twins.
- Assumptions/dependencies: Accurate extraction under stochastic, continuous dynamics; integration with physical constraints and safety margins.
- Extensions to POMDPs and perception-heavy domains (autonomy, embodied AI)
- What: Generalize P-learning to belief dynamics and latent-state models, enabling extraction of “what the agent believes about hidden variables.”
- Potential tools/workflows: Belief-Model Extractors; explainable latent dynamics dashboards.
- Assumptions/dependencies: Advances in identifiability and scalable extraction for partially observed, high-dimensional settings.
- IP/knowledge distillation and model lifecycle management (software, MLOps)
- What: Treat the extracted WM as a compact, transferable artifact encoding environment knowledge; migrate between architectures/vendors; archive for reproducibility.
- Potential tools/workflows: WM Artifact Registry; WM-Diff for debugging regressions; license-aware export/import.
- Assumptions/dependencies: Standardization of P schemas; privacy/IP policies; robust extraction at scale.
Cross-cutting assumptions and dependencies to track
- Access requirements: Q-values (or critic), policies π, and reward functions r must be available; some applications need the ability to instrument training.
- Goal richness: Identifiability hinges on goal coverage/spanning or injectivity (e.g., sufficient number/diversity of goals, Gaussian vs indicator rewards).
- Accuracy and scope: The quality of P is bounded by the accuracy of Q; deterministic settings are easiest; stochastic continuous settings may require unconditional policies or broader goal coverage.
- Parameterization and optimization: Differentiable P parameterizations simplify learning; projection to the probability simplex may be needed when M is rank-deficient.
- Termination and reward design: For sparse goals, termination schemes (e.g., “termination upon arrival”) can materially impact identifiability and extraction quality.
- Compute and integration: Periodic extraction for monitoring requires additional compute; planners (VI/MPC) must be integrated with the extracted P.
Glossary
- Bellman equation: A fundamental recursive relationship expressing the value of a state/action in terms of immediate reward and the expected value of successor states. "effectively inverting the Bellman equation."
- Bellman operator: A mapping that applies the Bellman update to a value function, optionally with respect to a policy or the optimality operator. "the goal-conditioned Bellman operators $\cT^\pi, \cT^\star : \cQ \to \cQ$"
- Bellman residual: The discrepancy between a value function and its Bellman update, used as a training objective in value-based methods. "measure fixed-point violation via the Bellman residual $\mathcal{L}(\theta,\theta_n)\eq \| \mathcal{T}^\star(Q_{\theta_n}) - Q_\theta\|^2_d$"
- Column-injective: A matrix property where all columns are distinct, ensuring unique identification via column-matching. "the (and therefore the kernel ) is unique provided is column-injective: for all ."
- Column separation: The minimum distance between any two columns of a matrix, quantifying injectivity robustness. "we define the column separation of as $\gap(M) \eq \min_{s \neq s'} \norm{M(s) - M(s')}_1$."
- Discount factor: A scalar in [0,1) that downweights future rewards in the return computation. "where is the discount factor"
- Entropy-regularised policies: Policies optimized with an added entropy term to encourage exploration and smoother action distributions. "including a finite failure set over and a treatment of optimal and entropy-regularised policies (functions of )."
- Full rank: A matrix property indicating maximal rank, enabling unique solutions to associated linear systems. "for which is full-rank, and thus "
- Gaussian rewards: Goal rewards shaped as Gaussian functions of state or goal distance, providing dense and smooth feedback. "with Gaussian reward function "
- Goal-conditioned policy: A policy that takes both the state and a goal as input to produce an action distribution. "goal-conditioned policy $\pi : \cS \times \cG \to \Delta(\cA)$"
- Goal-Conditioned RL (GCRL): A reinforcement learning paradigm where agents learn to achieve a variety of goals with goal-dependent rewards. "Goal-Conditioned RL (GCRL)."
- Hindsight Experience Replay (HER): A technique that re-labels trajectories with goals achieved post hoc to improve learning from sparse rewards. "with Hindsight Experience Replay (HER) \cite{Andrychowicz2017}"
- Indicator goals: Sparse goal rewards that provide a binary signal when the state is within a threshold of the goal. "indicator goals defined by "
- Lebesgue measure: A standard measure on Euclidean spaces used to formalize “almost everywhere” statements about sets of parameters. "has full Lebesgue measure."
- Local MDP: An MDP in which each state-action transitions to a limited, bounded set of successor states. "Local MDPs."
- Markov decision process (MDP): A formal model of decision-making with states, actions, transition dynamics, rewards, and discounting. "We consider goal-augmented MDPs $\cM = (\cS, \cA, \cG, P, \mu, r, \gamma)$"
- Markov transition kernel: A function specifying the probability distribution over next states given a current state and action. "Markov transition kernel $P : \cS \times \cA \to \Delta(\cS)$"
- Measure determining: A property of a function family that uniquely identifies probability measures via their integrals against the family. "generalises to whether this family is measure determining or point separating for stochastic or deterministic MDPs"
- Moore–Penrose pseudo-inverse: A generalized inverse of a matrix used to obtain least-squares solutions in rank-deficient or rectangular systems. "where is the Moore--Penrose pseudo-inverse of ."
- Occupancy measure: A distribution over states (and possibly actions) induced by a policy, often representing state visitation frequencies. "and reduces to the occupancy measure \cite{Blier2021}."
- Orthogonal projection: The projection of a point onto a subspace that minimizes Euclidean distance, often describing least-squares solutions. "Equivalently, is the orthogonal projection of onto the set of global minima"
- P-learning: An algorithm that infers a transition model by minimizing the Bellman residual with respect to the dynamics, effectively inverting the Bellman equation. "We call this -learning."
- Point separating: A property of a function family that maps distinct points to distinct values, enabling unique identification of states or transitions. "Then $\{m_g^\pi : g \in \cG\}$ is point separating on $\cS$, hence ."
- Q-iteration: An algorithm that repeatedly applies the Bellman optimality operator to approximate the optimal action-value function. "A classical approach, known as -iteration"
- Q-learning: A temporal-difference control method updating action-values towards Bellman targets without requiring a model of the environment. "including -learning \citep{Watkins89,Watkins1992}"
- Rank-deficient: A matrix lacking full rank, leading to underdetermined systems and non-unique solutions. "when is rank-deficient (), multiple WMs yield identical -values"
- Reparameterisation trick: A gradient estimation technique for stochastic nodes by expressing sampling as a differentiable transformation of noise. "via the reparameterisation trick \cite{Kingma2014, Rezende2014}."
- Robbins-Monro conditions: Conditions under which stochastic approximation procedures converge to a stationary point. "E.g. if the Robbins-Monro conditions are satisfied, stochastic gradient descent (SGD) converges to a stationary point"
- Spearman correlation coefficient: A rank-based measure of statistical dependence between two variables. "The Spearman correlation coefficient between agent return and WM error is ."
- Stochastic gradient descent (SGD): An iterative optimization method using noisy gradient estimates to minimize an objective. "stochastic gradient descent (SGD) converges to a stationary point"
- Successor features: A representation that decouples dynamics from reward by factoring value functions into feature expectations and reward weights. "via successor features \cite{Barreto2017, Borsa2018}"
- Successor function: In deterministic settings, a mapping from state-action pairs to their unique next state, parameterizing the model. "we can parameterise the model as a successor function $P_\phi : \cS \times \cA \to \cS$."
- Successor representation: A value decomposition where state values are expressed via expected discounted future occupancies of states or features. "The successor representation \citep{Dayan1993}"
- Temporal difference (TD) algorithms: Methods that update value estimates using bootstrapped targets based on successive state transitions. "yields a family of temporal difference (TD) algorithms \citep{Sutton1988} including -learning"
- Temporal difference error: The difference between a current value estimate and its bootstrapped target, driving TD updates. "Writing $\delta_{\T, {\T_n} \eq \cT^\star (Q_{\theta_n}) - Q_\theta$ for the temporal difference error"
- Termination upon arrival: An episodic condition that stops further reward accumulation once the goal region is reached. "with indicator rewards $r_g(s') = \mathbf{1}[\norm{s' - g} < \sigma]$ and termination upon arrival."
- Unconditional policy: A policy that does not depend on the goal, i.e., the same behavior is used for all goals. "single unconditional policy for all "
- Value equivalence: The phenomenon where different world models yield identical value functions and policies, obstructing identifiability. "an obstacle formalised as the value equivalence problem"
- Value iteration: A dynamic programming algorithm that iteratively updates state values towards optimality. "train policies exclusively inside the extracted WM using value iteration"
- World model (WM): An internal or learned representation of environment dynamics used for prediction or planning. "extracting the world model contained in an agent's -values."
Collections
Sign up for free to add this paper to one or more collections.

