- The paper introduces RLIR, which leverages an Inverse Dynamics Model to convert high-dimensional video outputs into actionable signals.
- It employs Group Relative Policy Optimization to achieve a 5-10% improvement in action-following accuracy compared to baseline methods.
- The framework demonstrates robust scalability across autoregressive and diffusion models, enhancing both visual quality and action precision.
Reinforcement Learning with Inverse Rewards for World Model Post-training
This paper presents a novel framework, Reinforcement Learning with Inverse Rewards (RLIR), designed to enhance the action-following capability of video world models through post-training. Building on existing reinforcement learning principles, RLIR uses an Inverse Dynamics Model (IDM) to translate high-dimensional video outputs into low-dimensional action spaces, providing an objective and verifiable reward signal. The paper showcases RLIR's effectiveness across various generative paradigms, achieving significant improvements in action-following accuracy and visual quality.
Introduction and Motivation
World models serve as virtual environments that simulate dynamic interactions, crucial for applications that require agents to comprehend and manipulate high-dimensional input modalities like video. Despite advancements in visual fidelity and temporal consistency, these models struggle with accurately following human-specified actions. Traditional reinforcement learning approaches often fail due to the high cost and bias of human preference annotations and the difficulty of designing rule-based verifiers for video quality. RLIR addresses these challenges by mapping video outputs to action sequences using an IDM, thus enabling reinforcement learning based on action accuracy.

Figure 1: Inverse Dynamics Model (IDM) is highly sensitive to subtle environmental changes and action magnitudes.
Methodology
Reinforcement Learning with Inverse Rewards
The core idea of RLIR is to extract reward signals from generated video sequences by predicting the conditioning actions through an IDM. This framework allows for comparison between inferred and ground-truth actions, leveraging Group Relative Policy Optimization (GRPO) to improve alignment.
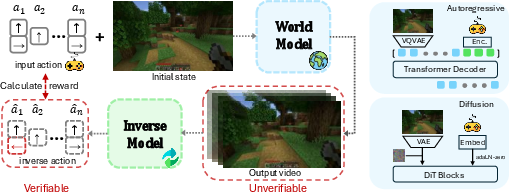
Figure 2: Overview of RLIR. RLIR utilizes an IDM to derive reward signals from video sequences, optimizing the world model using GRPO.
Application to Autoregressive and Diffusion Models
RLIR is applied to both autoregressive models like MineWorld and diffusion models like NFD. In MineWorld, action tokens are excluded from loss calculations to focus optimization on visual tokens. NFD employs Diffusion Forcing to generate video frames progressively, adapting GRPO to incorporate action rewards in the denoising process.
Experimental Results
Comprehensive evaluations demonstrate that RLIR consistently enhances action-following accuracy by 5-10% and improves visual quality metrics. Comparative analyses show that RLIR outperforms baseline methods, achieving near-theoretical upper bounds in action precision across model architectures and parameter scales.

Figure 3: Qualitative comparison between RLIR and baseline outputs. RLIR reduces action inconsistencies and image blurring.
Analysis
Comparative studies with existing reward models like VideoAlign and RLVR-World underscore RLIR's robustness and scalability. Unlike human-preference and pixel-level rewards, RLIR provides semantically aligned, frame-level rewards that mitigate biases inherent in alternative methods.
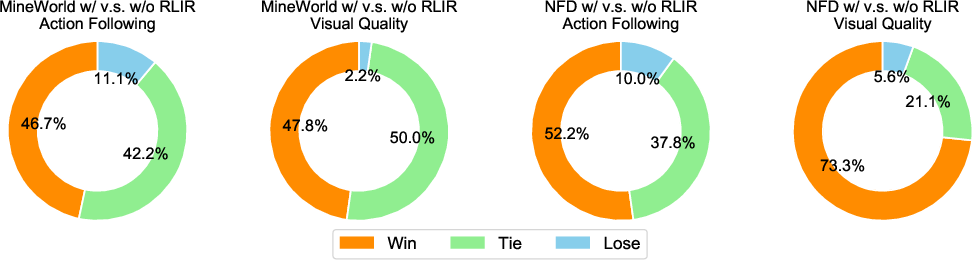
Figure 4: Human evaluation results indicate RLIR's superiority in both visual quality and action-following capabilities.
Conclusion
The development of RLIR marks a significant advancement in the post-training of world models, establishing a framework where model outputs are evaluated against objective action signals. RLIR not only improves action-following and visual fidelity but also provides a pathway for future research in scaling world model performance and broadening applications across diverse domains.

