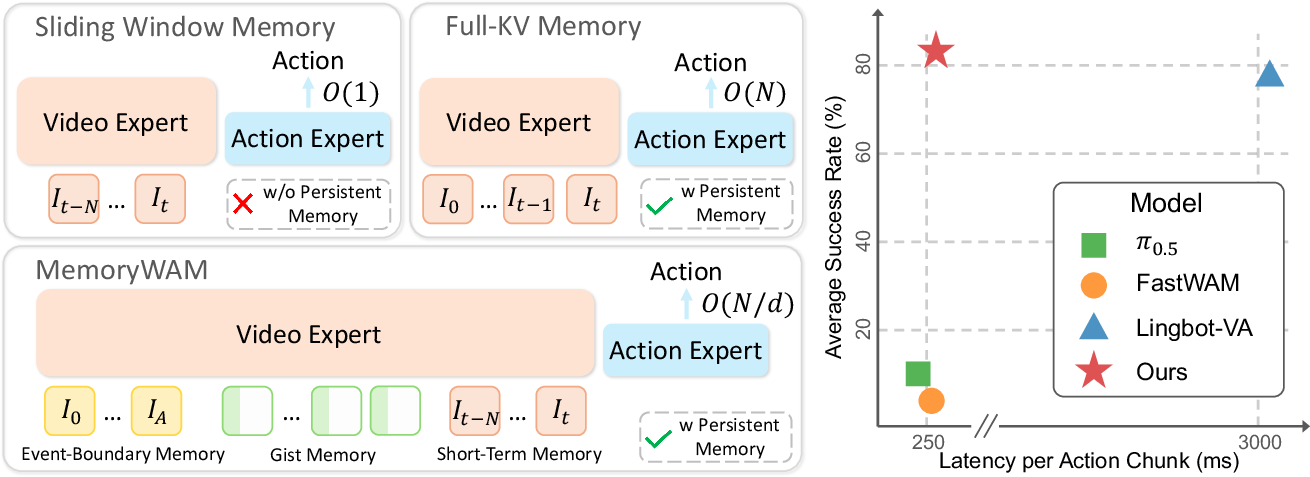
MemoryWAM: Efficient World Action Modeling with Persistent Memory
Abstract: Robust robotic manipulation in the real world requires not only an understanding of the current observation, but also memory and dynamics modeling. World action models (WAMs) possess these capabilities by jointly modeling visual foresight and actions conditioned on both current and historical observations, making them a promising paradigm for robotic manipulation. However, existing WAMs face a fundamental trade-off: methods with efficient inference typically condition only on a bounded window of recent observations and therefore struggle in non-Markovian environments, whereas methods that preserve long histories incur time and space costs that grow substantially with sequence length. To address this challenge, we introduce MemoryWAM, a world action model with efficient persistent memory. MemoryWAM uses a hybrid memory design that combines recent frames, event-boundary anchor frames, and compact gist tokens that summarize long-range history. A tailored attention mechanism enables retrieval of both detailed short-term context and compressed long-term context, supporting memory-dependent decision-making with reduced inference latency and GPU memory usage. Across long-horizon, memory-dependent manipulation tasks in both simulation and the real world, MemoryWAM outperforms strong vision-language-action (VLA) and WAM baselines while maintaining favorable computational efficiency.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper is about teaching robots to remember important things from the past so they can make better decisions now. The authors built a system called MemoryWAM that helps robots do long, tricky tasks (like pressing buttons in a certain order or tracking a hidden object) by remembering what happened earlier without slowing down too much or using too much computer memory.
What questions did the researchers ask?
They focused on two simple questions:
- How can a robot remember the right parts of the past so it doesn’t get confused or forget important details?
- Can we keep this memory without making the robot slow or needing a huge amount of computer power?
How did they do it?
Think of a robot’s “memory” like a student’s notes during a long project. If you try to keep everything you’ve ever seen, your notebook gets too heavy (slow and expensive). If you only keep the last page, you forget earlier instructions (you fail the task). MemoryWAM uses a “just right” approach with three kinds of memory:
- Recent frames (short-term memory): Like keeping the last few pages of notes. The robot keeps the most recent camera frames with full detail for quick, accurate control.
- Anchor frames (event-boundary memory): Like bookmarking the very first page or a big scene change. The robot keeps a few full-detail frames from important moments (for example, the very start of a task), because those often matter later.
- Gist tokens (long-term memory): Like sticky-note summaries. Instead of storing every old frame, the robot keeps a tiny summary (a few special tokens) that captures the key idea of each earlier frame. This saves a lot of space.
Behind the scenes, the system has two “brains”:
- A video brain that learns how the world changes over time (dynamics).
- An action brain that uses what the video brain remembers to choose the next actions.
During training, the system predicts how videos will change (so it learns physics and cause-and-effect). At test time, it doesn’t need to generate future videos; it just uses the learned memory to act fast.
Why this is efficient: Instead of keeping all past details (which gets slower and more memory-hungry the longer the task runs), MemoryWAM keeps full detail only where it’s most useful and stores compressed “gists” for the rest. That means as a task gets longer, the extra cost grows much more slowly.
What did they find?
- Better success on long, memory-heavy tasks: On a challenging simulator benchmark (RMBench), MemoryWAM beat strong baselines that either:
- only used recent views (and forgot earlier facts), or
- kept everything from the past (accurate but slow and heavy).
- MemoryWAM reached about 83% average success, outperforming a strong full-history model (about 78%) and far exceeding short-window models (about 6–10%).
- Real-world wins too: On two real robot tasks:
- Shell Game (find a hidden object after cups are swapped): MemoryWAM succeeded in 18/20 trials, better than the full-history model (13/20) and much better than the short-window model (5/20).
- Look and Press (press buttons a specific number of times based on earlier seen numbers): MemoryWAM succeeded in 15/20 trials, slightly better than the full-history model (14/20), while the short-window model got 0/20.
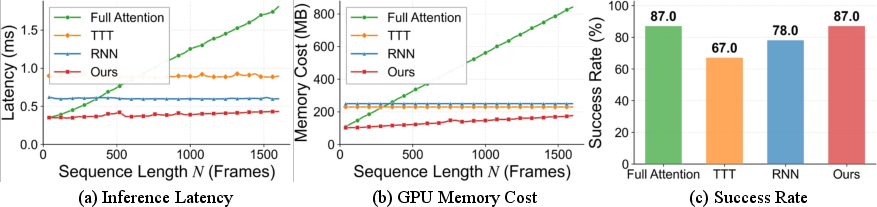
- Faster and lighter: MemoryWAM achieved similar success to the “store everything” approach but with much lower delay (latency) and much less GPU memory during inference.
- Which parts mattered most? When they removed each memory piece:
- Removing gist tokens (the summaries) hurt performance the most, showing long-term summaries are crucial.
- Removing anchor frames or recent frames also hurt, meaning both the “bookmark” and the “last few pages” are important.
- Surprisingly, keeping everything (full history) wasn’t best overall—too much detail can make it harder to find the important parts quickly.
Why does this matter?
- Smarter, quicker robots: Robots can handle longer, more complex tasks that require remembering earlier steps (like sequences, hidden objects, or delayed effects) without getting bogged down.
- More efficient use of hardware: This design saves time and GPU memory, making advanced robot control more practical on real machines.
- A blueprint for memory in AI: The hybrid memory idea—recent detail, key anchors, and sticky-note summaries—could help other long-horizon AI systems (like video understanding or planning) remember the right things efficiently.
In short
MemoryWAM shows that robots don’t need to remember everything to act well—they just need to remember the right things in the right way. By mixing short-term detail, important “bookmarks,” and small long-term summaries, the robot stays both smart and fast.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of concrete gaps and unresolved questions that future work could address:
- Event-boundary detection is fixed, not learned: anchors are hard-coded to the first N_init frames; no mechanism to detect mid-trajectory event boundaries or adapt anchor placement online. Evaluate learned boundary detectors (e.g., surprisal/change-point, instruction-dependent saliency) and compare to static anchoring.
- Long-horizon scalability remains linear: gist memory scales as O(N/d); no bounded-memory policy (e.g., reservoir sampling, clustering, periodic summarization/merging) for very long executions (10k–100k frames). Benchmark memory quality and control success under strict memory caps.
- Gist token formulation is under-specified: gist tokens are described as “learnable parameters,” leaving ambiguity about whether they are content-adaptive per frame or global templates. Precisely define and ablate: per-layer vs shared, static vs updated over time, and how information is written/updated into gist KV across steps.
- Compression fidelity is uncharacterized: no quantitative analysis of how replacing full tokens with M gist tokens affects retrieval accuracy, dynamics modeling error, or downstream control (per layer/scale). Provide information-theoretic or empirical error–compression curves versus L/M, and task-specific sensitivity.
- Lack of interpretability and diagnostics: no tools to inspect what gist tokens store or how queries use them. Add probing tasks, attention visualizations, causal interventions, and representational similarity tests to verify that task-relevant signals are retained.
- Memory management is not adaptive: M (gist slots per frame), N_recent (sliding window), and N_init (anchors) are fixed. Explore learned/adaptive memory budgets, saliency-based selection, knapsack-style allocation per frame, and dynamic eviction/refresh policies.
- No mechanism for mid-trajectory anchors: only initial anchors are kept; tasks with multiple subgoals or reconfiguration events may need later anchors. Implement and evaluate online anchor promotion/demotion triggered by learned boundary detectors.
- Hybridization with adaptation methods is unexplored: TTT and RNN were evaluated as alternatives, not combined with hybrid memory. Test complementary combinations (e.g., TTT on gist slots, recurrent updates to compressed memory, low-rank adapters over hybrid cache).
- End-to-end efficiency is underreported: latency and memory are measured per layer or qualitatively; full-system profiling (all layers, all diffusion steps, action horizon, end-to-end control loop) is missing. Report FPS/Hz, worst-case latency, jitter, and energy across hardware and trajectories.
- Diffusion sampling details are missing: number of denoising steps for the action DiT, samplers, and their effect on latency–performance trade-offs are not stated. Provide ablations of sampling steps, noise schedules, and distillation/consistency training for fast sampling.
- Fairness of comparisons is unclear: MemoryWAM uses a large Wan2.2 video backbone; parameter/data parity with baselines (e.g., LingBot-VA, FastWAM) is not controlled. Include size-matched and pretraining-matched baselines to isolate memory mechanism effects.
- Generalization and robustness scope is limited: two real tasks on one robot/camera; no tests under domain shifts (lighting, clutter, camera pose), sensor dropouts, latency jitter, or severe occlusion. Conduct stress tests and quantify robustness and recovery strategies.
- Multi-modal memory is underutilized: long-term memory compresses video only; past actions, proprioception, and (potential) tactile signals are not persistently modeled. Evaluate joint video–action–state gist memory and its impact on control.
- Instruction dynamics are static: no support for mid-trajectory instruction updates, corrections, or multi-step language interactions. Study how language edits revise the hybrid memory and action plans.
- Extremely long-term dependency tasks are not covered: e.g., multi-room navigation/manipulation or prolonged counting/inventory tasks. Create benchmarks requiring hour-long memory and evaluate memory saturation/failure modes.
- Catastrophic interference and drift in gist memory are unstudied: do gist slots degrade as N grows? Track retention over hours and test consolidation/periodic re-summarization to mitigate drift.
- No theoretical analysis of memory capacity: provide bounds or models relating d=L/M, layer depth, and retrieval error to task success; analyze gradient flow through long-range compressed memories.
- Anchor/gist interaction is not disentangled: how many anchors are optimal, and when do anchors become redundant given strong gist compression? Run controlled sweeps over N_init and M with fixed budgets.
- Failure mode analysis is light: identify characteristic failures (e.g., wrong cup tracking, miscounting button presses) and link them to memory read/write errors; propose detect-and-recover mechanisms (e.g., re-observe, re-anchor).
- Active perception is absent: the policy does not explicitly act to refresh uncertain memory (e.g., re-inspect occluded objects). Study memory-aware action selection that trades off task progress and memory clarification.
- Portability across backbones is untested: reliance on Wan2.2 may limit adoption. Replicate with smaller and open video models/VAEs, and measure performance/efficiency deltas.
- Multi-task scaling is not evaluated: models are trained per task with 50 demos; no results on a single multi-task MemoryWAM, cross-task transfer, or few-shot adaptation using the same memory mechanism.
- Camera configuration generality is unclear: results use a specific 3-camera mosaic; no tests on different sensor rigs, calibration noise, missing views, or mixing RGB-D/LiDAR.
- Continual/episodic memory boundaries are unspecified: does memory reset between episodes? Explore persistent cross-episode memory, privacy/safety constraints, and forgetting strategies.
- Training stability and compute costs for hybrid memory are not reported: quantify training-time overhead of the hybrid mask, KV bookkeeping, and memory writes; study convergence vs. full-history and sliding-window baselines.
- Action horizon design is fixed: h=16 chunking may affect responsiveness and latency. Ablate horizon/stride and assess impact on closed-loop stability and throughput.
- Why full attention underperforms is unexplained: the paper hypothesizes redundancy, but no analysis verifies whether attention dilution, optimization, or overfitting causes the drop. Perform controlled analyses (e.g., retrieval sparsity, pruning) to pinpoint causes.
- Safety and reliability are not addressed: no guarantees that memory summarizes critical safety cues or that mis-summarization is detectable. Add uncertainty estimates over memory reads and fallback behaviors (e.g., re-anchoring, re-sensing).
- Memory content supervision is absent: gist tokens have no explicit auxiliary losses (e.g., contrastive matching to masked frames, keyframe reconstruction). Explore auxiliary objectives to bias memory toward task-relevant factors.
Practical Applications
Practical Applications of MemoryWAM
MemoryWAM introduces a hybrid memory mechanism (recent frames + anchor frames + long-range “gist” tokens) that preserves long-horizon context while reducing inference time and GPU memory from O(N) to O(N/d). This enables memory-dependent decision-making in real-time robotic manipulation and beyond. Below are actionable applications organized by deployment horizon, with sector links and feasibility notes.
Immediate Applications
These can be piloted or deployed now with available hardware (e.g., NVIDIA GPUs/Jetson, RGB cameras) and standard robotics stacks (ROS/Isaac), assuming task-specific fine-tuning is performed.
- Robotics: Long-horizon factory and warehouse manipulation
- Use cases: Multi-step kitting/assembly, order fulfillment with “put back” or “swap” steps, panel/button sequences analogous to Press Button in RMBench, recovery from occlusions or transient cues.
- Tools/workflows: ROS2 controller integrating MemoryWAM action DiT; “memory budgets” (M gist tokens, Nrecent window, Ninit anchors) tuned to latency constraints; event-boundary anchoring at job start; on-device inference on Jetson Orin or data-center GPUs.
- Assumptions/dependencies: Multi-camera calibration and time sync; 10–100 task-specific demonstrations for fine-tuning; non-Markovian tasks where crucial state falls outside a short window; safety cages or force limits for human–robot interaction.
- Service and domestic robots: Multi-step household assistance
- Use cases: “Look then act” routines (e.g., find item, then fetch later after occlusions), cleaning or tidying tasks with initial plan conditioned on early observations, appliance panel/button sequences (e.g., washer settings).
- Tools/workflows: MemoryWAM integrated into home robot stack; anchor frames at task initiation; sliding window for precise manipulation; gist memory for earlier room state.
- Assumptions/dependencies: Robustness to lighting/clutter; trained on in-home data; privacy management for persistent memory (e.g., edge-only storage, ephemeral caches).
- Field maintenance and utilities (energy, oil & gas, manufacturing)
- Use cases: Control panel operations with multi-button sequences; valve manipulation where initial settings matter; inspection tasks requiring recall of earlier configurations occluded later.
- Tools/workflows: Deploy as a “memory-aware” manipulation module in inspection/maintenance robots; log anchor frames for traceability; compress history via gist tokens for embedded compute.
- Assumptions/dependencies: Environmental variability; ATEX/safety certification for hazardous locations; domain-specific demos; intermittent connectivity (edge inference preferred).
- Laboratory automation
- Use cases: Multi-step protocols (identify wells/plates, pipette in order observed earlier, return items to specific positions), where early observations guide later precision steps.
- Tools/workflows: MemoryWAM as a drop-in module in lab robots; anchor the initial scene; sliding window for fine motor tasks; gist tokens for early labeling or layout recall.
- Assumptions/dependencies: Sterility and safety constraints; precise camera–arm calibration; curated demos of protocols; integration with LIMS.
- Teleoperation and shared autonomy co-pilots
- Use cases: Memory-enhanced assistive control that maintains context across occlusions/latency spikes; operator handoff and resumption without losing key past cues.
- Tools/workflows: MemoryWAM running locally to provide suggested actions and “what changed” summaries from gist memory; anchor frames for session start.
- Assumptions/dependencies: Stable low-latency streaming; human override; UI for memory inspection and correction.
- Academic research and benchmarking
- Use cases: Studying memory–efficiency trade-offs; ablations across anchor/gist/window parameters; evaluating non-Markovian control (e.g., RMBench) with open-source implementations.
- Tools/workflows: Integration with simulation frameworks (Isaac/Unity/Gazebo); “Hybrid KV cache” utilities for Transformer-based streaming video/action models.
- Assumptions/dependencies: Access to pretrained video DiTs or VAE backbones (e.g., Wan2.2); GPU availability for 6B-parameter models.
- Software infrastructure: Memory-efficient streaming attention for video-action models
- Use cases: A PyTorch/ROS2 library that implements hybrid KV caching (anchors + gist + window) for any AR video/action Transformer; helps deploy on memory-constrained hardware.
- Tools/workflows: Export as a module configurable by compression ratio d = L/M; profiling tools to balance success vs latency/VRAM.
- Assumptions/dependencies: Transformer-based backbone with accessible attention hooks; licensing for pretrained components.
Long-Term Applications
These require additional research, scaling, validation, or regulatory approvals before reliable deployment.
- Healthcare robotics (surgical and bedside assistance)
- Use cases: Assistive manipulation remembering pre-op setups or earlier tool states; multi-step nursing tasks (medication prep/administration workflows) where initial observations must be recalled safely.
- Potential products: Memory-augmented surgical scrub assistant; bedside task co-pilot with event-boundary anchoring.
- Assumptions/dependencies: Rigorous verification/validation; interpretability and fail-safe mechanisms; medical device regulatory approval; domain datasets with stringent privacy.
- Public-space service robots (airports, hotels, hospitals)
- Use cases: Multi-step tasks that span locations/time (e.g., collect luggage tagged earlier, deliver to a room, then return items), with long-horizon memory across occlusions and crowds.
- Potential products: Memory-aware concierge/porter robots with compact persistent memory for multi-episode tasks.
- Assumptions/dependencies: Robust long-term re-identification; liability and safety certification; privacy frameworks for persistent memory.
- Multi-robot teams with shared compact memory
- Use cases: Teams sharing gist tokens of past events (e.g., initial layout, object IDs) to coordinate tasks like search-and-retrieve, assembly lines with handoffs.
- Potential workflows: Cross-robot “gist exchange” protocol that publishes compressed memory via V2V messaging; anchor-frame snapshots in shared logs.
- Assumptions/dependencies: Communication reliability; standardized positional encodings; conflict resolution and consistency across agents.
- Cross-episode, lifelong personalization
- Use cases: Robots remembering user preferences or environment states across days; replaying anchor frames to quickly re-ground tasks; storage and retrieval of compressed long-term histories.
- Potential products: Home assistants with “memory profiles”; enterprise maintenance robots with job-history recall.
- Assumptions/dependencies: Scalable, privacy-preserving memory stores; continual learning without catastrophic forgetting; mechanisms to expire or redact sensitive memory.
- Autonomous vehicles and mobile manipulation
- Use cases: Memory-efficient long-horizon context for navigation/manipulation (e.g., remembering a blocked corridor earlier, re-planning later; recalling objects previously seen).
- Potential workflows: Hybrid memory integrated into streaming perception–planning stacks; gist tokens summarizing earlier segments.
- Assumptions/dependencies: Adaptation from stationary manipulation to dynamic driving domains; safety certification; multimodal sensor fusion beyond RGB (LiDAR, RADAR).
- Agriculture and construction robotics
- Use cases: Multi-stage tasks where early classification/marking influences later manipulation (e.g., fruit identified earlier, harvested later after occlusions; staged assembly in construction).
- Potential products: Memory-aware crop pickers or layout-aware construction assistants.
- Assumptions/dependencies: Robustness to outdoors variability; domain-specific labeling; safety in unstructured environments.
- Video analytics and monitoring beyond robotics
- Use cases: Long video understanding (e.g., security, industrial process monitoring) that needs to “remember” early events with low compute; anomaly detection using gist memory as compressed context.
- Potential tools: “Gist memory” plugin for long-video Transformers; streaming KV-compaction service for VMS platforms.
- Assumptions/dependencies: Domain-adapted backbones; careful thresholding to avoid missing rare events; privacy-by-design.
- Standards and policy for memory-aware robotics
- Use cases: Procurement and safety standards that include memory–latency budgets, memory explainability, and retention policies for persistent robot memory; benchmark suites for non-Markovian tasks.
- Potential outputs: Guidelines for anchor-frame logging, compressed-memory retention limits, and privacy controls; certification tests based on RMBench-like tasks.
- Assumptions/dependencies: Multi-stakeholder consensus (vendors, regulators, users); agreed metrics for memory fidelity vs latency; alignment with data protection regulations.
- Foundation model pretraining with unlabeled videos for embodied control
- Use cases: Scaling video-side DiTs on web or in-the-wild egocentric video, then fine-tuning action branches with fewer robot demos; leveraging MemoryWAM’s training-time video supervision and inference-time efficiency.
- Potential products: Pretrained “MemoryWAM-style” backbones for various robot form factors (mobile base, single-arm, bimanual).
- Assumptions/dependencies: Access to large-scale video datasets and compute; domain gap reduction; licensing and dataset consent; robust generalization.
Notes on Feasibility Across Applications
- Compute and hardware: While inference is more efficient (O(N/d)), MemoryWAM still uses ~6B parameters; embedded deployment may need pruning/quantization.
- Data requirements: Performance depends on representative demonstrations and camera setups; non-Markovian benefits materialize when tasks truly require long-horizon context.
- Event-boundary detection: The paper anchors initial frames; broader deployments may need robust, automated boundary detection (e.g., change-point/event detectors).
- Safety and privacy: Persistent memory introduces data retention concerns; adopt edge-only storage, short TTLs, and redact sensitive frames; ensure fail-safe behaviors.
- Integration: Best fit with Transformer-based architectures; adaptation to other backbones requires attention-hook access and positional alignment (e.g., shared 3D RoPE).
- Generalization: Cross-domain success needs domain adaptation and robustness to distribution shift (lighting, clutter, dynamics).
Glossary
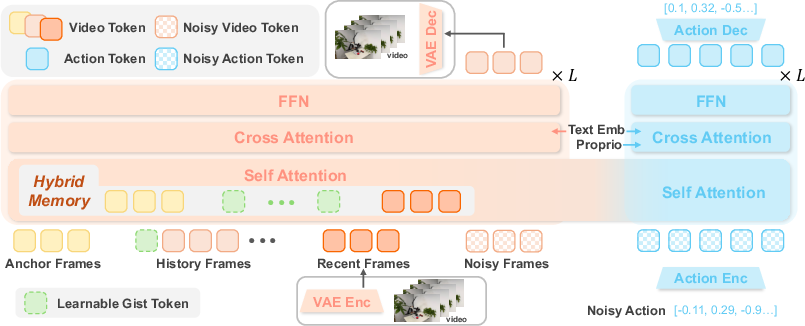
- Anchor frames: Selected frames at salient event boundaries (e.g., task onset) that are stored with full visual tokens to preserve high-fidelity context. "MemoryWAM uses a hybrid memory design that combines recent frames, event-boundary anchor frames, and compact gist tokens that summarize long-range history."
- Attention mask: A binary pattern that constrains which tokens can attend to which others in Transformer attention, shaping information flow. "The attention mask of MemoryWAM is illustrated in Fig.~\ref{fig:attention_mask}."
- Autoregressive Transformer: A Transformer that generates sequences step-by-step, conditioning each step on all previous ones and typically caching past keys/values. "A straightforward approach to retain long-term history is to preserve the full KV cache of all past observations within an autoregressive Transformer \citep{lingbot-va,dreamzero,motubrain}."
- Causal video VAE: A video variational autoencoder with a causal temporal structure that encodes frames conditioned only on past information. "Given the observation , we first encode it into a compact video latent using a causal video VAE~\citep{wan} for computational efficiency."
- Compression ratio: The factor describing how much long-term context is compressed (e.g., from visual tokens to gist tokens, ). "If the compression ratio is defined as , then the long-term cache size becomes"
- Diffusion Transformer (DiT): A Transformer architecture used within diffusion models to process and generate latent representations (video or actions). "MemoryWAM follows the recent video-action diffusion paradigm of world action models, where a pretrained video diffusion transformer (DiT) provides dynamics-aware visual representations and a separate action DiT predicts future actions conditioned on the learned visual dynamics."
- Event-boundary memory: A memory component that prioritizes the state at event boundaries (e.g., at task onset) for efficient retrieval. "Event-boundary memory emphasizes the state at the onset of a task~\citep{zacks2007event}."
- Flow matching: A generative training objective that aligns probability flows between data and noise distributions, used here for both video and action branches. "We use the same continuous flow-matching formulation for both video and action branches with $1000$ training timesteps."
- Gist tokens: A small set of learned tokens per frame that compress and retain long-range historical information. "To maintain efficient long-term memory, MemoryWAM attaches learnable gist tokens to each frame, where ."
- Hybrid memory: A memory mechanism that combines short-term sliding windows, event-boundary anchor frames, and compressed gist tokens to retain persistent context efficiently. "we propose a hybrid memory mechanism that preserves high-fidelity short-term context, maintains a small set of gist tokens summarizing long-range history, and retains anchor frames at task onset."
- Key-value (KV) cache: Stored key and value tensors from previous timesteps used to enable efficient attention over history without recomputation. "During inference, the clean latent of the current observation is forwarded through the video DiT only once to update the video-side key-value (KV) cache :"
- Logit-normal distribution: A probability distribution over a variable in logit space; here used to schedule the diffusion noise levels during training. "We adopt a shifted logit-normal distribution over as the noise schedule"
- Mixture-of-Transformers (MoT): An architectural pattern that organizes multiple Transformer branches (e.g., video and action) into a coordinated mixture. "The two branches are organized in a mixture-of-transformers (MoT)~\citep{mot} architecture."
- Non-Markovian: Describing environments or tasks where the current observation is insufficient for optimal decisions; history matters. "they struggle in non-Markovian environments where decisions depend on long-range history."
- Proprioception: Internal robot state signals (e.g., joint positions/velocities) used as inputs for control and modeling. "The robot state and action are both $14$-dimensional joint vectors (dual-arm); proprioception is projected by a learned linear layer to the text-token dimension and appended to the text context for the action expert."
- Rotary positional embeddings (RoPE): A positional encoding method for attention that rotates query/key vectors to encode positions, here extended to 3D space-time. "Gist tokens are realized as learnable parameters and are placed in the same 3D RoPE coordinate system as their associated video frame"
- Sliding-window attention: An attention scheme that restricts attention to a fixed-size window of recent tokens to control complexity. "Specifically, the original self-attention layer is modified to use sliding-window attention to preserve the capabilities of the pretrained model, while the TTT or RNN module captures long-range temporal dependencies."
- Test-time training (TTT): Adapting a model during inference using self-supervised objectives to capture instance-specific or long-range patterns. "we compare it with three representative memory mechanisms: full attention~\citep{transformer}, test-time-training (TTT)~\citep{ttt}, and recurrent neural networks (RNNs)~\citep{elman1990finding}."
- Video latent: A compact latent representation of a video frame produced by an encoder (e.g., a video VAE) for efficient modeling. "Given the observation , we first encode it into a compact video latent using a causal video VAE~\citep{wan} for computational efficiency."
- Vision-Language-Action model (VLA): A model class that conditions robot actions on visual inputs and language instructions, often via pretrained vision-language priors. "Vision-language-action (VLA) models have demonstrated strong generalization across diverse tasks and environments by transferring semantic priors from pretrained vision-LLMs to robotic manipulation~\citep{rt2,octo,openvla,pi0,groot_n1_2025,rdt1b_2024,galaxea_g0_2025,bridgevla,spatialvla,dexvla_2025}."
- World Action Model (WAM): A dynamics-centric model that jointly represents how the world evolves and what actions to take, conditioned on observations and history. "World action models (WAMs) provide a dynamics-centric alternative to direct observation-to-action policies by modeling how the world evolves in conjunction with robot actions."
Collections
Sign up for free to add this paper to one or more collections.