How Transparent is DiffusionGemma?
Abstract: LLM reasoning transparency is a critical affordance for understanding model decisions, mitigating misuse and misalignment, and debugging surprising model behaviors. However, DiffusionGemma performs a larger fraction of its computation in a continuous latent space; does this make its reasoning less transparent? We study this question by decomposing transparency into two components: variable transparency, whether we understand intermediate snapshots of a model's computational state; and algorithmic transparency, whether we can use these snapshots to reconstruct the process by which the model arrived at its outputs. Naively, DiffusionGemma has poor variable transparency: its opaque serial depth, the amount of serial computation that occurs in between interpretable model states, seems at first 28.6X higher than the corresponding autoregressive Gemma 4 model. However, we show that we can map the information flowing between denoising steps through an interpretable token bottleneck with no decrease in downstream performance. Treating these intermediate states as interpretable reduces the opaque serial depth to just 1.1X that of Gemma 4. Algorithmic transparency is harder for diffusion models than for autoregressive models because all token predictions in the canvas can change at every denoising step, giving the model the power to implement complicated distributed algorithms during the denoising process. To begin bridging this gap, we conduct a suite of interpretability case studies, uncovering initial evidence of novel diffusion-specific phenomena such as non-chronological reasoning, token and sequence smearing, and intermediate-context reasoning. Finally, we test monitorability, a key application of transparency that measures whether model outputs are useful for downstream tasks. We find that DiffusionGemma is similarly monitorable to Gemma 4.



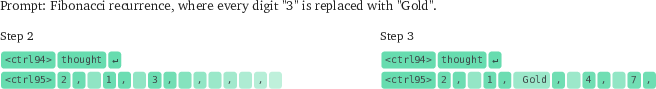
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about
This paper asks a simple question: can we see how a new kind of AI model “thinks” while it’s working? The model is called DiffusionGemma. Unlike many chatbots that write one word at a time, DiffusionGemma works more like an artist who keeps editing an entire page of text over many passes. The authors study how “transparent” this process is—that is, how much we can understand about what’s happening inside as it reasons.
They break transparency into two parts:
- Variable transparency: Can we look at snapshots of the model’s work-in-progress and understand them?
- Algorithmic transparency: Do those snapshots let us piece together the actual steps the model took to reach its final answer?
What questions the researchers asked
In kid-friendly terms, the team wanted to know:
- Does DiffusionGemma do most of its thinking “in its head” in a way we can’t see, or can we peek in while it works?
- Can we translate the model’s private notes (its internal numbers) into words we can read, without hurting how well it performs?
- Do DiffusionGemma’s intermediate thoughts help another system catch mistakes or risky behavior (this is called “monitorability”)?
- How does DiffusionGemma actually reason—does it always think left-to-right like a typical writer, or can it jump around and change earlier words later?
How they studied it (in plain language)
Think of DiffusionGemma as writing on a whole “canvas” of many tokens (small pieces of words) at once. It repeatedly:
- looks at the current canvas and its own internal notes,
- updates its guesses for every position, and
- repeats until the page looks good.
Here’s what the researchers did:
- Measuring “opaque serial depth” (how long it thinks invisibly): Imagine a long hallway where some doors are windows you can look through, and some are solid walls. The “opaque serial depth” is the longest stretch of hallway where you can’t see inside. They compared DiffusionGemma’s invisible stretches to a normal one-word-at-a-time model (Gemma). At first glance, DiffusionGemma seemed to have a much longer invisible stretch.
- Turning private notes into readable guesses: Between each edit pass, DiffusionGemma passes along two things: a canvas of tokens (regular text guesses) and a big matrix of numbers (its “self-conditioning vectors”)—think of these as private notes. The team built a way to translate most of those private notes into a small set of likely tokens (top guesses) that humans can understand, much like translating a secret code back into words.
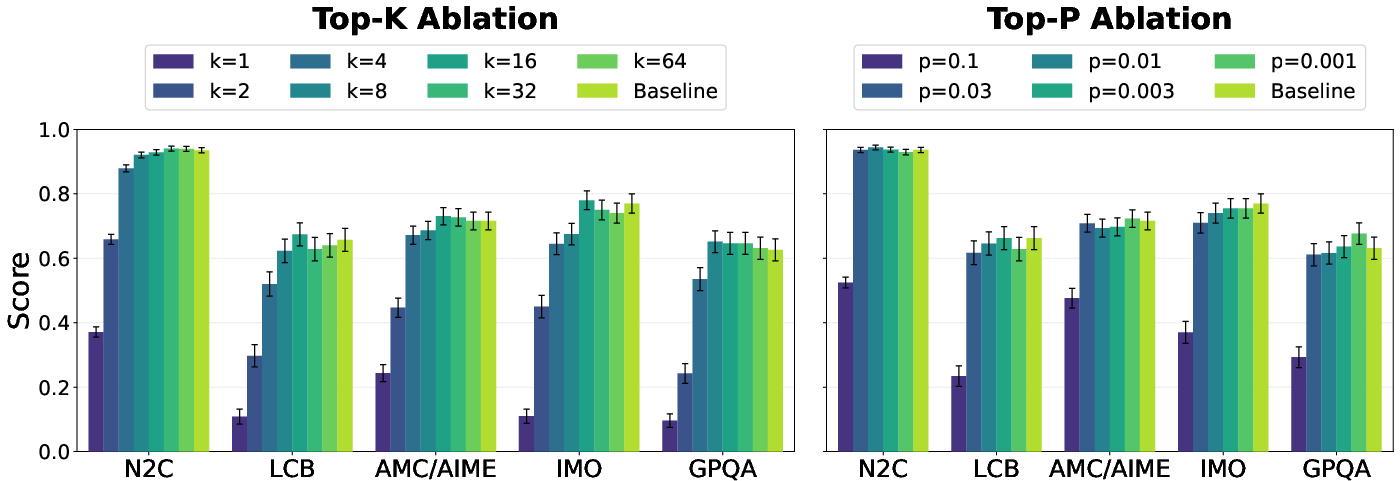
- Checking performance doesn’t drop: They tested whether doing this translation (keeping only a handful of top guesses at each position) still lets the model perform just as well on coding and math benchmarks.
- Case studies of how it thinks: They visualized how the model’s guesses changed over time to see patterns like changing earlier words later, predicting the answer length early, or keeping multiple possible wordings in mind at once.
- Monitorability tests: Using existing evaluations, they checked whether another AI (a “monitor”) can read the model’s thoughts and answers to catch key properties (like whether it took a risky shortcut). They compared DiffusionGemma to Gemma on these tests.
What they found and why it matters
- The “invisible thinking” isn’t as bad as it looks: If you treat only the final text as visible, DiffusionGemma seems to have about 28.6 times more invisible thinking than the normal model. But once you translate its private notes into a small number of readable token guesses, the invisible stretch shrinks dramatically—down to roughly 1.1 times the normal model. In everyday terms: with the right “translation,” you can see almost as much of DiffusionGemma’s thinking as with regular models.
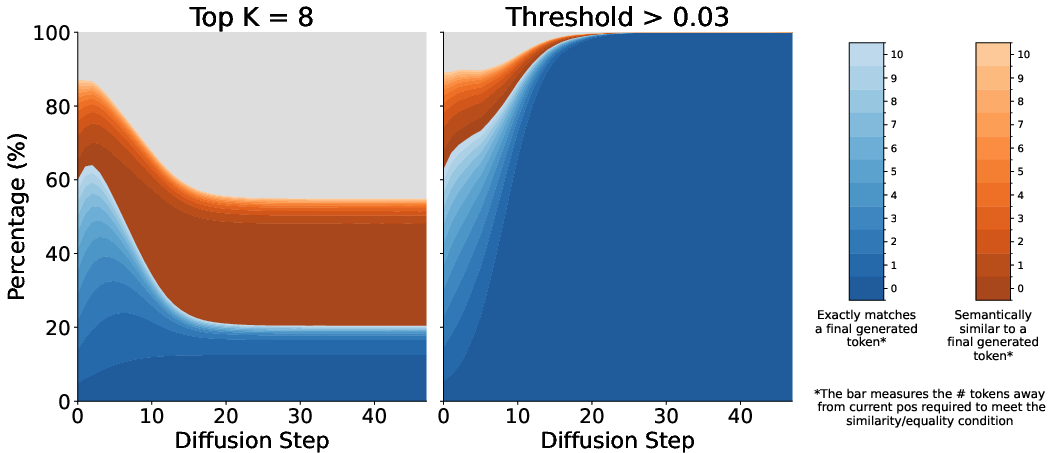
- The private notes are mostly understandable: The top guesses extracted from the private notes usually match the final or nearby tokens. In other words, the model’s “private notes” mostly look like early drafts of the words it will eventually write—so they’re interpretable.
- Performance stays strong: Keeping only a few top token guesses at each step (instead of all the private numbers) didn’t hurt the model on key tests. That’s good news: we can have transparency without sacrificing ability.
- Diffusion-specific reasoning patterns:
- Non-chronological reasoning: It can decide the overall length of its answer very early, and it can go back and change earlier words after writing later parts.
- Token smearing: Sometimes it spreads a likely token across several nearby positions before choosing exactly where it belongs.
- Sequence smearing: It can briefly hold two different versions of a sentence in mind at once before picking one.
- Intermediate-context reasoning: It may use temporary tokens to compute the next steps (like writing a “3” to do math) and then later replace them with a required word (like “Gold”), so the intermediate token never appears in the final output but was essential during reasoning.
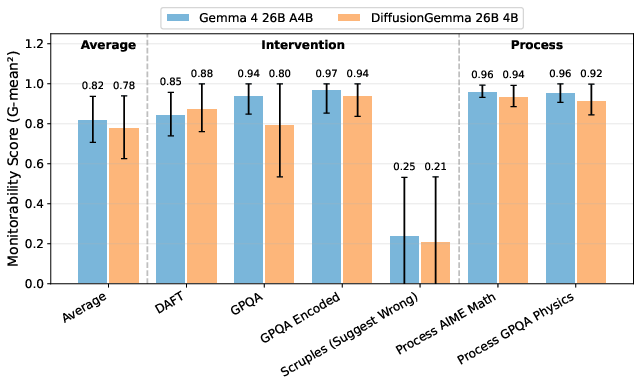
- Monitorability looks similar to standard models: On tests where another system tries to judge what happened by reading the model’s thinking and answers, DiffusionGemma was about as monitorable as the normal Gemma model. This is encouraging for safety and oversight.
Why this matters: If we can see and understand a model’s reasoning, we can better detect mistakes, misuse, or dangerous behavior. These results suggest that diffusion-style text models can remain transparent and monitorable—if we design and analyze them thoughtfully.
What this could mean in the future
- Good news for safety and debugging: Even though DiffusionGemma reasons differently from classic left-to-right models, its intermediate steps can be translated into human-understandable tokens with little to no loss in performance. That means we can still check its thinking, teach it better, and catch problems.
- Keep checking new designs: This success depends on how DiffusionGemma was built and trained. Future models might handle their private notes differently and become harder to interpret. So, developers should keep running these kinds of transparency checks as models evolve.
- New ways of thinking to understand: Because diffusion models can jump around, change earlier parts later, and hold multiple drafts at once, we’ll need tools that track not just what the model writes, but when and how its guesses evolve. That can help us understand and guide more powerful systems down the road.
In short: DiffusionGemma shows that even new, more flexible ways of generating text can still be made understandable. With the right tools, we can peek into the process, see what’s going on, and use that insight to keep AI safer and more reliable.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a focused list of unresolved issues that future work could concretely address:
- Interpretable bottleneck verification beyond benchmarks: The claim that self-conditioning vectors can be mapped to interpretable token sets with “no decrease in downstream performance” is supported on a limited benchmark suite; test across broader domains (safety-critical tasks, tool use, long-context reasoning, multilingual settings) to validate generality.
- Causal necessity of tokenized intermediates: The Logit Lens-based projection shows sufficiency for performance, but not that those token projections are causally necessary. Use causal tracing/activation patching across steps to test whether replacing St with top-token proxies preserves the computation pathway, not just end accuracy.
- Characterization of “Other” intermediate tokens: Even under the p > 0.03 filter, a non-trivial fraction of tokens remains uncategorized. Systematically analyze what information these tokens carry (e.g., gradient-based attribution to outputs, probing classifiers) and whether they encode opaque reasoning or harmless noise.
- Out-of-distribution effects in ablation design: The ablation sets low-probability logits to a constant to preserve the probability of retained tokens. Compare against alternatives (−∞ masking, unigram/bigram/trigram baselines, temperature rescales) to ensure conclusions aren’t an artifact of an OOD intervention.
- Quantifying bottleneck size and load-bearing content: Replace the qualitative O(c) claim with per-step distributions of retained tokens per position under different p/k thresholds, and report how this varies with task type, denoising step, and canvas length.
- Intermediate-state monitorability: Evaluate monitors that consume intermediate tokenized snapshots (or raw St) vs monitors that see only final CoT/output, to quantify the incremental monitoring value of inter-step states.
- Adversarial obfuscation risk: Stress-test whether a model can hide misaligned intent in St while emitting innocuous intermediate tokens (or innocuous final CoT). This includes adversarial fine-tuning to exploit non-token-aligned subspaces or to encode deceptive plans between steps.
- Training choices that preserve transparency: Identify and empirically test which architectural/training constraints (e.g., soft-embedding alignment, penalties on non-embedding directions, auxiliary decoding losses) most reliably keep St token-aligned. Conversely, quantify transparency regressions under outcome-based RL, latent-space regularizers, or architectural variants without soft embedding.
- Serial depth measurement realism: Opaque serial depth was profiled at 256k context and T=48 steps; report depth across realistic T with adaptive stopping and across canvas sizes, and include distributional depth metrics (median, tail) on real workloads.
- Partial interpretability regimes: The study assumes a binary choice (bottleneck interpretable vs not). Develop and apply metrics for partial interpretability (e.g., fraction of bottleneck information recoverable as interpretable tokens, mutual information with token space) and relate these to effective serial depth.
- Sampling policy sensitivity: EB sampling and scheduled temperatures may shape transparency. Compare to greedy/top-k/nucleus sampling and different entropy thresholds to see how sampling affects smearing, non-chronological edits, and monitorability.
- Frequency and impact of non-chronological reasoning: Case studies show phenomena (retroactive correction, skeleton-first coding, early length prediction), but their prevalence and effect on reliability aren’t quantified. Measure frequency across datasets and associate with error modes or brittleness.
- From spacing to semantics in smearing: Sequence smearing is shown for spacing/length resolution; test whether smearing frequently represents distinct semantic plans (e.g., two algorithmic approaches) and whether monitors can parse these branches in-flight.
- Lock-in dynamics: Identify conditions that produce premature “lock-in” to incorrect spans (e.g., local entropy thresholds, canvas position, step schedules). Explore mitigations (adaptive entropy bounds, delaying commitment in high-impact spans) and measure trade-offs with performance.
- Canvas size and multi-canvas effects: Study how transparency (smearing, non-chronological edits, monitorability) scales with canvas length C and the number of canvases, especially for long-form generation where reasoning bridges canvases.
- Language and domain coverage: All analyses appear English-centric and text-only. Test whether intermediate interpretability and monitorability hold in other languages, code-mixed inputs, and domain-specific tokenizations (e.g., code, math-heavy text).
- Mechanistic localization of length prediction: Early length estimation is observed but not mechanistically explained. Trace where padding confidence emerges (layers/heads) and whether it can be decoupled or controlled without harming performance.
- Operationalizing “transparent enough”: The paper lacks a deployment-oriented threshold for acceptable transparency. Propose measurable criteria (e.g., minimum fraction of inter-step info recoverable as interpretable tokens; monitor AUC uplift from intermediates) to inform go/no-go decisions.
- Monitor confounds from CoT length: DiffusionGemma produces shorter CoT than Gemma; since longer CoT is typically more monitorable, control for CoT length (e.g., via thought-budget prompts or truncation/expansion) to isolate architecture effects on monitorability.
- Missing outcome-property comparisons: Outcome-property evaluations where DiffusionGemma “never misbehaves” preclude direct comparison. Construct synthetic or controlled tasks ensuring matched error rates to compare monitorability under equivalent failure regimes.
- Cross-architecture baselines: Compare transparency/monitorability and smearing phenomena with other latent-reasoning architectures (e.g., Universal Transformers, Mamba, vertical recurrence methods) to isolate what is diffusion-specific vs general to latent recurrence.
- Causal graphs over denoising steps: Beyond case studies, derive quantitative influence maps across steps (e.g., inter-step causal mediation of token revisions) to formalize algorithmic transparency and identify recurrent “planning-then-refine” patterns.
- Privacy and logging implications: Monitoring intermediate canvases at scale introduces storage/telemetry risks. Evaluate privacy leakage and memorization risks from logging St or inter-step tokens, and propose safe logging/aggregation strategies.
- Robustness under instruction changes: Assess whether small changes to task instructions (e.g., output format, “answer-first” vs “reason-first”) systematically alter the distribution of non-chronological edits or lock-in rates, impacting transparency.
- Stability under distribution shift: Test whether the observed interpretability and monitorability hold under distribution shifts (adversarial prompts, jailbreak attempts, noisy inputs), where latent computations may deviate most from token-aligned pathways.
- Tool use and multi-agent settings: Evaluate if intermediate transparency persists when the model invokes tools or coordinates multi-agent plans, where latent scheduling and plan branching may intensify.
- Scaling laws for transparency: Provide empirical scaling trends (model size vs fraction of interpretable inter-step info, prevalence of smearing, monitor uplift from intermediates) to predict transparency at frontier scales.
- Reproducibility of visual analyses: Release the visualization tooling and standardized datasets/prompts used for case studies, enabling systematic replication and quantitative benchmarks for non-chronological and smearing phenomena.
Practical Applications
Immediate Applications
The following applications can be deployed now by leveraging the paper’s methods, measurements, and insights. Each item lists relevant sectors, possible tools/workflows, and key assumptions or dependencies.
- Transparent inter-step logging for diffusion LLMs
- What: Capture and expose diffusion-step bottleneck states as interpretable tokens using a probability threshold (e.g., p > 0.03) or top-k (e.g., k = 8), with minimal capability loss.
- Sectors: Software, safety/security, platform/MLOps.
- Tools/workflows: Inter-step token logger; p-threshold filter; red-team monitor feeds; privacy-aware logging (sampling/truncation).
- Assumptions/dependencies: Access to intermediate states; architecture aligns self-conditioning with embeddings; k/p settings validated for target tasks; storage/compliance constraints.
- Monitorability parity checks for diffusion models
- What: Run adapted monitorability evaluations (per Guan et al.) to verify that diffusion models are as monitorable as autoregressive baselines.
- Sectors: Safety/security, governance, evaluation services.
- Tools/workflows: Monitor training/inference pipelines; benchmark suites; G-mean scoring; regression dashboards.
- Assumptions/dependencies: Representative tasks; final-output-only monitoring may miss intermediate-context reasoning; requires task-matched monitors.
- Opaque serial depth reporting in model cards
- What: Include empirical/analytical opaque serial depth and its sensitivity to “interpretable bottleneck” assumptions in model transparency disclosures.
- Sectors: Governance/policy, industry, academia.
- Tools/workflows: Serial-depth analyzer; templated reporting; CI checks on new model variants.
- Assumptions/dependencies: Analyzer availability; architecture disclosures; stable interpretable-bottleneck mapping.
- Inference cost and memory bandwidth reduction via bottleneck compression
- What: Replace dense self-conditioning states with sparse token mixtures (top-k or p-threshold) between denoising steps to reduce activation size and inter-stage transfer.
- Sectors: Cloud/edge inference, efficiency engineering.
- Tools/workflows: Lightweight Logit-Lens projector in serving; activation sparsification; compatibility tests across evals.
- Assumptions/dependencies: No significant capability loss at chosen sparsity levels; compatibility with batching and distributed serving.
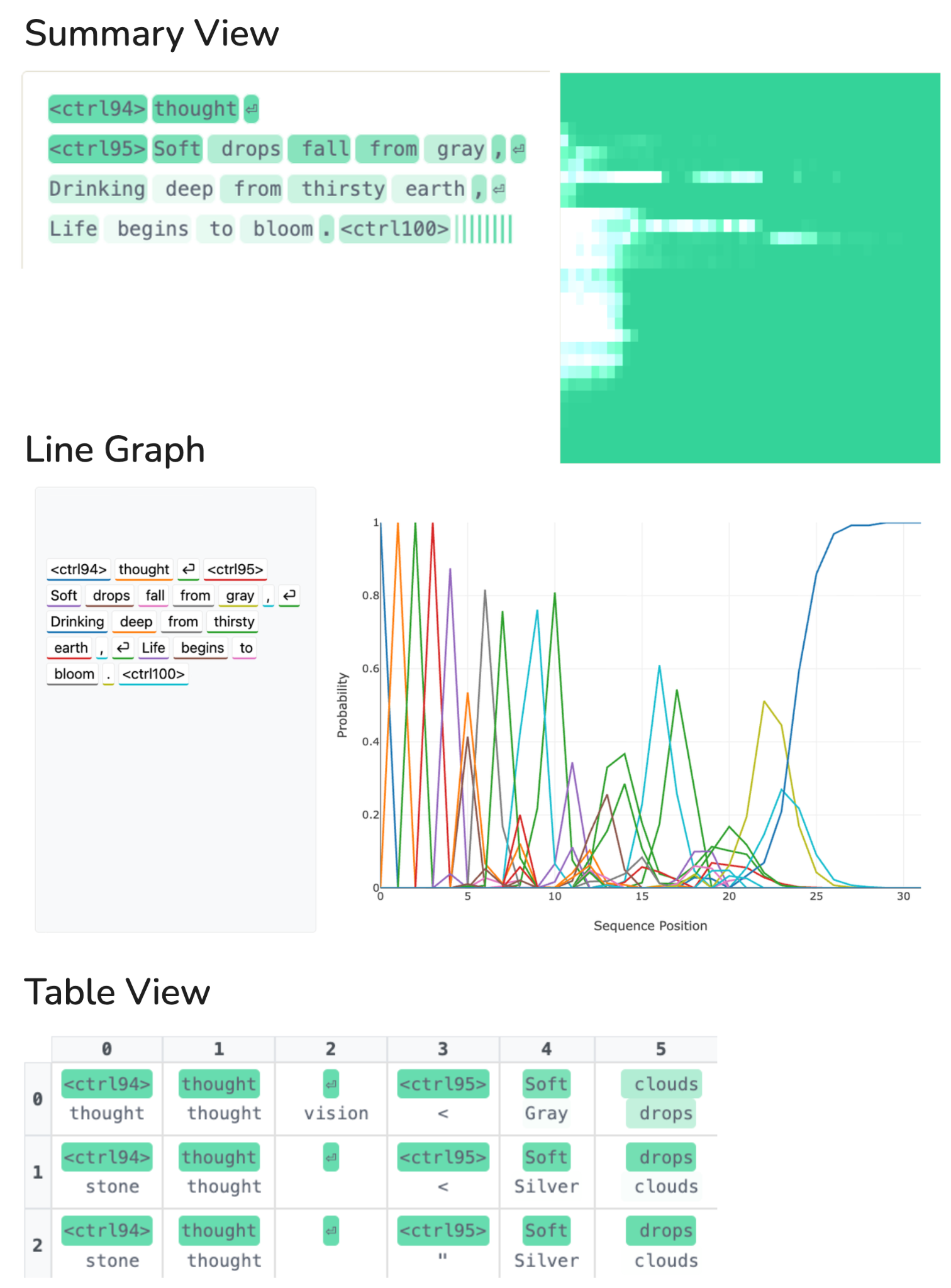
- Reasoning visualization for debugging and red-teaming
- What: Use Summary, Line Graph, and Sampling Table views to diagnose non-chronological reasoning, self-correction, and (sequence/token) smearing in failure analyses.
- Sectors: Software safety, research, developer tooling.
- Tools/workflows: Internal IDE plug-ins; session replays; incident post-mortems.
- Assumptions/dependencies: Access to per-step logits/softmax; developer training; privacy controls for logged reasoning.
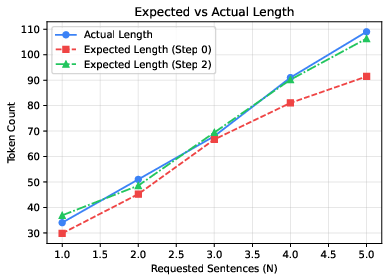
- Early length prediction for user experience and resource planning
- What: Estimate final output length from padding probabilities after 1–2 denoising steps to drive progress indicators, streaming UX, and preallocation of buffers/quotas.
- Sectors: Product/UX, platform engineering.
- Tools/workflows: Expected-length estimator using cumulative padding CDF; streaming throttles; quota forecasters.
- Assumptions/dependencies: Stable padding behavior across prompts; calibration per domain and model version.
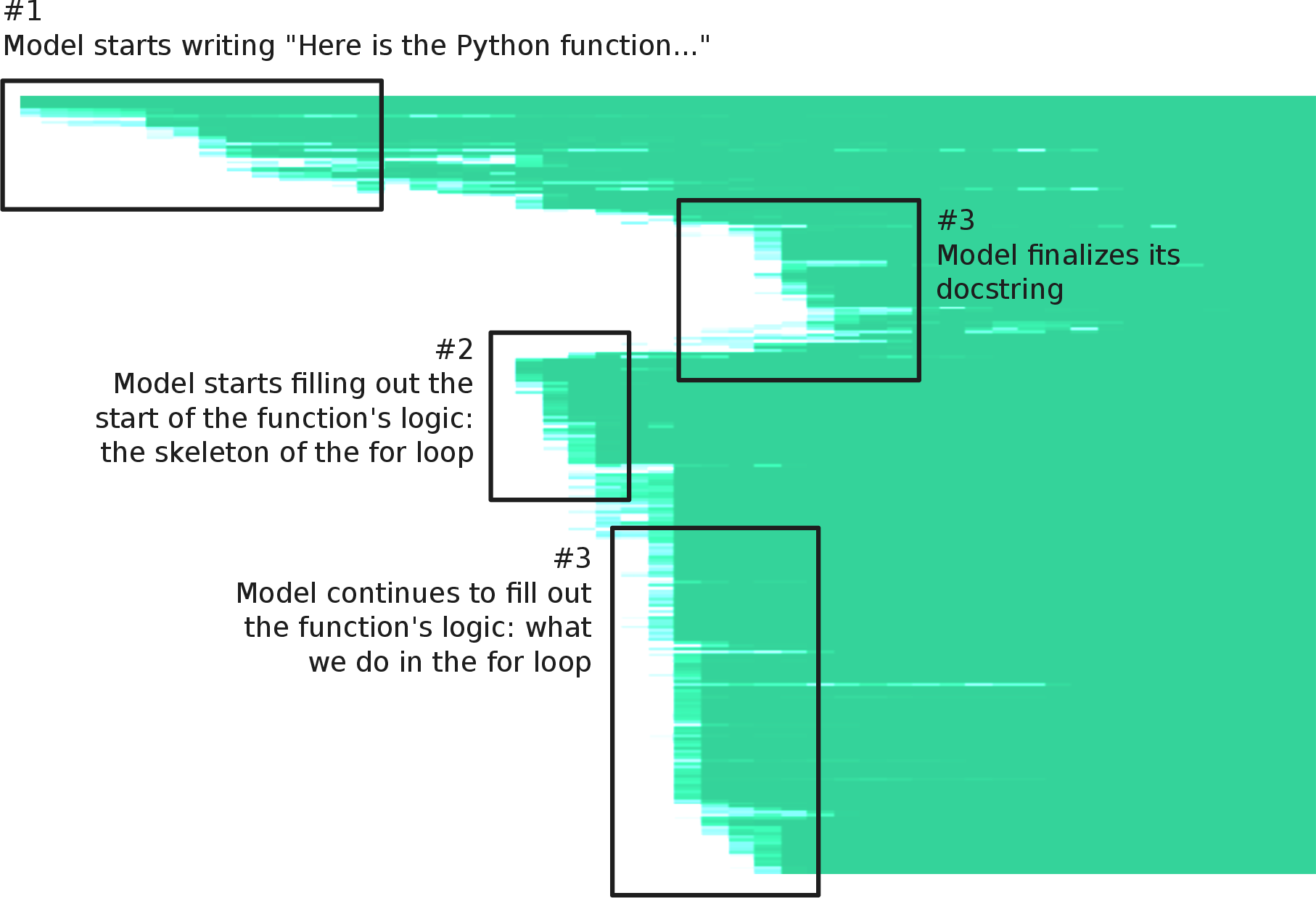
- Code generation “skeleton-first” streaming
- What: Stream structural scaffolding (function signatures/blocks) before details, reflecting model’s non-chronological code planning; improves IDE UX and human-in-the-loop editing.
- Sectors: Software/dev tools.
- Tools/workflows: IDE integration that locks stable structure early; delayed filling of variable names/comments; conflict resolution on late shifts.
- Assumptions/dependencies: Robust detection of stability; guardrails for “lock-in” failure modes.
- Risk flags from sequence/token smearing
- What: Surface “multiple hypothesis” states (sequence smearing) to monitors as risk signals for potential goal drift, deception, or brittle reasoning.
- Sectors: Safety/security, risk operations.
- Tools/workflows: Smearing detectors from per-position token mass dispersion; monitor features; alerting thresholds.
- Assumptions/dependencies: Access to inter-step probability distributions; validated mappings from smearing patterns to risk.
- Retroactive self-correction detection for oversight
- What: Track when answers flip after later reasoning; use as a cue to request clarification or slow down finalization in high-stakes domains.
- Sectors: Healthcare, finance, legal, enterprise support.
- Tools/workflows: Flip detectors; finalization delay policies; “confidence gating” for critical tokens.
- Assumptions/dependencies: Well-calibrated confidence and flip detection; domain-specific thresholds.
- Transparency-preserving architecture guidance
- What: Adopt projection-to-embeddings and avoid training regimes that degrade interpretability (e.g., heavy outcome-only RL) to maintain monitorability.
- Sectors: Model development, alignment.
- Tools/workflows: Architecture checklists; training-time transparency metrics; ablation tests (k/p thresholds).
- Assumptions/dependencies: Findings generalize to related architectures; tracking causal links between training choices and transparency.
- Privacy-aware CoT-lite logging
- What: Log only high-probability inter-step tokens (p-thresholded) instead of full token distributions to reduce sensitive information leakage while retaining monitorability signal.
- Sectors: Compliance, data privacy, enterprise.
- Tools/workflows: Data minimization policies; retention schedules; DLP scanning on logs.
- Assumptions/dependencies: p-threshold captures most informative content; legal review for CoT/latent logging.
- Academic replication and benchmarking kits
- What: Reproduce bottleneck ablations, serial depth metrics, and case studies across models to build comparative transparency benchmarks.
- Sectors: Academia, evaluation consortia.
- Tools/workflows: Open-source scripts; standardized prompt suites; shared visualizations.
- Assumptions/dependencies: Model access; consistent sampling configs; publication of intermediate APIs.
Long-Term Applications
The following applications likely need additional research, scaling, or ecosystem development before broad adoption.
- Transparency standards and audits for latent reasoning models
- What: Regulatory and industry standards requiring disclosure of opaque serial depth, inter-step monitorability, and access to interpretable bottlenecks for third-party auditors.
- Sectors: Policy/governance, certification.
- Tools/workflows: Standardized audit protocols; attestation formats; red-team audit trails.
- Assumptions/dependencies: Consensus definitions and benchmarks; secure interfaces for auditors; privacy-preserving access.
- Training objectives that enforce variable transparency
- What: Incorporate losses/regularizers that align self-conditioning with token embeddings and penalize opaque latent computation to preserve inter-step interpretability.
- Sectors: Model R&D, alignment.
- Tools/workflows: Transparency regularization; distillation to token bottlenecks; curriculum that rewards interpretable inter-steps.
- Assumptions/dependencies: No major capability trade-offs; scalability to larger models and multimodal settings.
- “Transparency SDK” for diffusion LLMs
- What: A cross-vendor toolkit bundling inter-step logging, smearing/flip detectors, length estimators, monitor training, serial-depth profilers, and visualization dashboards.
- Sectors: Developer tooling, safety platforms.
- Tools/workflows: Modular APIs; integrations with APM/MLOps; SOC2/ISO-compliant logging.
- Assumptions/dependencies: Vendor cooperation; stable intermediate-state APIs; performance overhead acceptable.
- Hardware and runtime co-design for sparse inter-step tokens
- What: Accelerators/runtimes optimized for sparsified self-conditioning (token mixtures vs dense vectors), reducing bandwidth and latency across denoising loops.
- Sectors: Hardware, cloud inference.
- Tools/workflows: Kernel support for sparse softmax-to-embedding projections; pipeline-parallel token channels.
- Assumptions/dependencies: Stable sparsity patterns; model architectures that retain token-aligned latents.
- Incident forensics and legal discovery on diffusion reasoning traces
- What: Post-hoc reconstruction of algorithmic reasoning paths (order-of-prediction, smearing, corrections) for compliance, liability, and root-cause analysis.
- Sectors: Legal/compliance, enterprise risk.
- Tools/workflows: Immutable reason-trace logs; causality reconstruction tools; evidentiary chain-of-custody.
- Assumptions/dependencies: Logging policies and retention; admissibility standards; privacy and trade-secret constraints.
- Cross-domain diffusion transparency (multimodal/planning/robotics)
- What: Extend interpretable bottlenecks and monitorability to diffusion-based planners and multimodal generators (image/video/text), enabling oversight of non-chronological plan updates.
- Sectors: Robotics, media safety, autonomous systems.
- Tools/workflows: Tokenization of intermediate latents (e.g., symbolic plan tokens); mixed-modality monitors.
- Assumptions/dependencies: Effective token-like interfaces for non-text latents; generalization of smearing/flip concepts.
- Multi-agent oversight that tracks competing hypotheses
- What: Supervisory agents that watch sequence smearing to map and score competing internal hypotheses, escalating when high-risk branches emerge.
- Sectors: Safety/security, enterprise ops.
- Tools/workflows: Hypothesis graph builders; risk scoring from dispersion patterns; human-in-the-loop escalation.
- Assumptions/dependencies: Reliable mapping from probability dispersion to meaningful hypotheses; low false alarm rates.
- Safety cases that rely on monitorability guarantees
- What: Formal deployment safety cases that treat monitorability metrics (and bottleneck interpretability) as core claims for acceptable residual risk.
- Sectors: Critical infrastructure, healthcare, finance.
- Tools/workflows: Assurance cases; quantitative monitorability KPIs; runtime policy hooks tied to monitors.
- Assumptions/dependencies: Predictive validity of monitor metrics; regulator acceptance; strong runtime enforcement loops.
- User-facing “reasoning timeline” features
- What: Opt-in visual timelines showing how answers converged (early length estimates, self-corrections), improving trust and teaching problem-solving.
- Sectors: Education, productivity.
- Tools/workflows: UI components for stepwise convergence; pedagogical prompts; accessibility review.
- Assumptions/dependencies: Users understand and value timelines; privacy safeguards; concise and accurate summaries.
- Privacy-first latent logging frameworks
- What: Cryptographic and federated methods for logging inter-steps (e.g., secure enclaves, on-device summarization) to balance oversight with data minimization.
- Sectors: Privacy tech, compliance.
- Tools/workflows: TEEs, differential privacy on inter-step distributions, retention controls.
- Assumptions/dependencies: Utility of summaries remains high; performance overhead manageable.
- Research on failure modes from lock-in and late flips
- What: Systematic study to predict and mitigate “locking-in” to wrong answers and late-stage corrections in high-stakes settings.
- Sectors: Safety research, reliability engineering.
- Tools/workflows: Controlled interventions; flip/lock-in predictors; adaptive sampling policies.
- Assumptions/dependencies: Generalizable predictors; minimal performance regressions.
- Sector-specific oversight adapters
- What: Domain-tailored monitors (e.g., medical dosing, financial compliance) trained to read inter-step tokens and detect risky non-chronological reasoning patterns.
- Sectors: Healthcare, finance, legal, gov.
- Tools/workflows: Domain datasets; monitor fine-tuning; escalation workflows to SMEs.
- Assumptions/dependencies: High-quality labeled corpora; stakeholder-defined risk taxonomies; model access policies.
Glossary
- Adaptive stopping: Early termination of the denoising process when predictions have stabilized, typically using an entropy-based criterion. "Unless stated otherwise, we use adaptive stopping, which stops sampling when the entropy in predicted tokens is low and model predictions are no longer changing."
- Algorithmic transparency: The degree to which one can reconstruct and understand the procedures a model uses to arrive at its outputs from intermediate states. "Algorithmic transparency is harder for diffusion models than for autoregressive models because all token predictions in the canvas can change at every denoising step, giving the model the power to implement complicated distributed algorithms during the denoising process."
- Autoregressive: A generation paradigm where tokens are produced left-to-right, each conditioned only on previously generated tokens. "Most current frontier AI systems are autoregressive reasoning models that reason in natural language via chain of thought (CoT)."
- Bidirectional attention: An attention mechanism that allows each position to attend to both preceding and following positions in the sequence. "We then proceed through the rest of the transformer (which notably uses bidirectional attention) until we reach the final predicted logits"
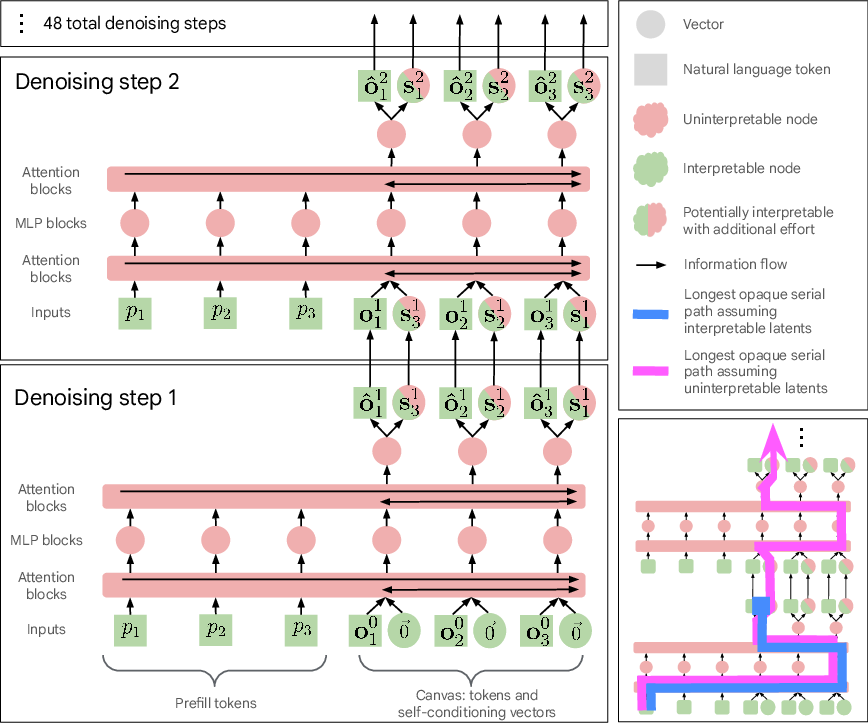
- Canvas: The fixed-length sequence of tokens that a text diffusion model iteratively refines across denoising steps. "produces an output canvas, consisting of tokens ."
- Chain of thought (CoT): Explicit natural-language reasoning traces produced by a model as intermediate steps toward an answer. "Most current frontier AI systems are autoregressive reasoning models that reason in natural language via chain of thought (CoT)."
- Denoising loop: The repeated sequence of forward and sampling steps that refine the canvas in a diffusion model. "DiffusionGemma inference consists of a setup stage followed by iterations of a denoising loop, each step consisting of a forward pass and a sampling step."
- Denoising step: A single iteration within the denoising loop that updates the canvas and self-conditioning matrix. "In each denoising step , the model takes as input the canvas and the self-conditioning matrix $\mathbf{S}^{t-1} \in \mathbb{R}^{C \times d_\text{model}$ from the previous step and produces updated canvas tokens and an updated self-conditioning matrix $\mathbf{S}^t \in \mathbb{R}^{C \times d_\text{model}$."
- Dynamic thinking: An evaluation setting or decoding mode that permits variable amounts of intermediate reasoning before finalizing outputs. "We enable dynamic thinking for all evals."
- Entropy-Bounded sampling (EB sampling): A sampling scheme that preserves low-uncertainty token choices while re-sampling high-uncertainty ones. "We then compute via Entropy-Bounded (EB) sampling~\citep{ben2026accelerated}, which keeps low entropy tokens and renoises high entropy tokens; see \Cref{app:arch} for more details."
- Gated MLP: A multilayer perceptron with gating that modulates the flow of information through its channels. "We pass through a gated MLP and then add it to the embeddings of the canvas tokens ."
- Information bottleneck: A constrained interface that limits what information can pass between stages (here, between denoising steps). "These two quantities form an information bottleneck between denoising steps."
- Intermediate-context reasoning: Reasoning that uses transient intermediate tokens or states that may not appear in the final output but influence it. "To begin bridging this gap, we conduct a suite of interpretability case studies, uncovering initial evidence of novel diffusion-specific phenomena such as non-chronological reasoning, token and sequence smearing, and intermediate-context reasoning."
- Key-value activations: The attention key/value representations computed from the prompt and reused during subsequent steps. "The prompt is passed through the model once to get key-value activations; these activations are static for the denoising loop and attended back to during each sampling step's forward pass."
- Logit Lens: A technique for projecting internal activations or logits into token space to interpret intermediate model states. "We thus perform experiments that restrict the information in to just a few tokens per sequence position using the Logit Lens~\citep{nostalgebraist2020logitlens}."
- Monitorability: The extent to which model outputs provide sufficient evidence for downstream monitors to infer properties of the model’s behavior. "Finally, we test monitorability, a key application of transparency that measures whether model outputs are useful for downstream tasks."
- Multi-canvas sampling: A method for generating sequences longer than the fixed canvas by chaining multiple canvases. "Multi-canvas sampling: Since the canvas has a fixed length , generating outputs longer than tokens requires multi-canvas sampling."
- Non-chronological reasoning: Reasoning that does not follow left-to-right order, allowing later tokens to influence earlier ones. "We explore a number of interesting phenomena unique to text diffusion models, including non-chronological reasoning, token and sequence smearing, and intermediate-context reasoning."
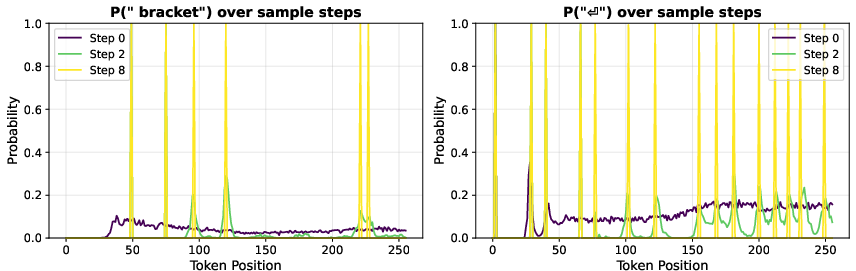
- Opaque serial depth: The longest chain of serial computation that does not pass through an interpretable intermediate state. "Naively, DiffusionGemma has poor variable transparency: its opaque serial depth, the amount of serial computation that occurs in between interpretable model states, seems at first 28.6X higher than the corresponding autoregressive Gemma 4 model."
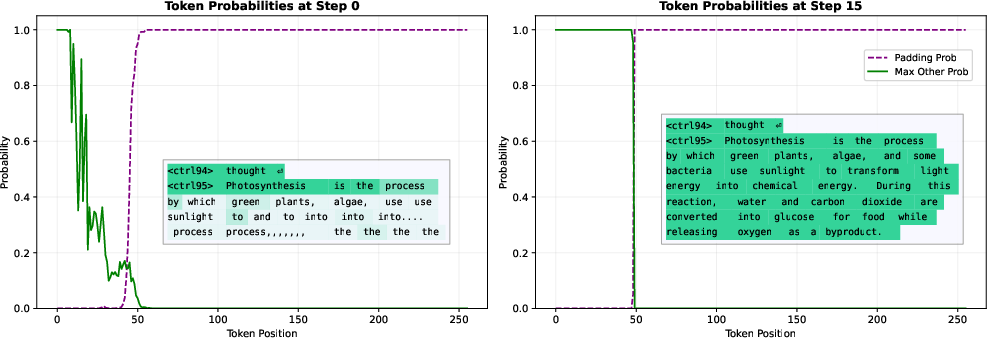
- Padding token: A special token indicating end-of-sequence or unused positions, often predicted with high confidence for positions beyond the intended output. "after the first denoising step, the model has converged to predicting the padding token (end-of-sequence) with near-100\% probability for all positions beyond 55."
- Retroactive self-correction: Revising earlier token predictions based on later reasoning within the same diffusion process. "Summary View showing retroactive self-correction on the square numbers prompt, from step 4 to step 7."
- Self-conditioning: Feeding transformed predictions from the previous step back into the model as continuous vectors to guide the next step. "Between each iteration of the denoising loop, we pass the current canvas and a self-conditioning matrix $S^{t} \in \mathbb{R}^{C \times d_\text{model}$ to the next denoising step."
- Sequence smearing: Temporarily maintaining multiple alternative sequence hypotheses with probability mass spread across them before converging. "A more dramatic version of this phenomenon is sequence smearing: situations where the model maintains two or more semantically distinct candidate sequences simultaneously, with probability mass distributed across both, before eventually converging on one."
- Soft embedding: Mapping a probability distribution over tokens back into embedding space via a weighted sum of token embeddings. "The new self-conditioning matrix is computed by embedding the shaped logits back into the model's embedding space via a soft embedding:"
- Text diffusion model: A generative model that iteratively denoises an entire token canvas rather than generating strictly left-to-right. "DiffusionGemma is a newly released text diffusion model."
- Token bottleneck: A constraint where information between steps is forced through a (typically small) set of tokens, aiding interpretability. "we show that we can map the information flowing between denoising steps through an interpretable token bottleneck with no decrease in downstream performance."
- Token smearing: Distributing probability mass for a single token over multiple adjacent positions when its exact placement is uncertain. "In these cases, we observe token smearing: the model places probability mass for a single token across multiple adjacent positions simultaneously."
- Variable transparency: How well intermediate variables or states of a model can be understood by humans. "We study this question by decomposing transparency into two components: variable transparency, whether we understand intermediate snapshots of a model's computational state; and algorithmic transparency, whether we can use these snapshots to reconstruct the process by which the model arrived at its outputs."
Collections
Sign up for free to add this paper to one or more collections.