- The paper introduces a controlled generator–separator pipeline to isolate representation retention factors in continual learning.
- It empirically quantifies the interplay of sparsity, superposition, and representation strength, revealing that strong features buffer forgetting.
- The study leverages SINDy to establish causal linkages between latent capacity allocation and task-induced interference.
Mechanistic Insights into Representation Retention in Continual Learning
Controlled Experimental Framework for Representation Retention
The paper "Sparsity, Superposition, and Forgetting: A Mechanistic Study of Representation Retention in Continual Learning" (2606.20431) develops a synthetic, controlled environment to disentangle the causal mechanisms underlying retention and forgetting in continual learning (CL). The framework centers on a generator–separator pipeline: fixed, randomly initialized neural networks systematically produce signals and labels according to specified sparse latent features. This approach bypasses confounds inherent to real-world datasets, such as entangled feature co-occurrence and uncontrolled semantics.
The experimental setup leverages trainable encoder, classifier, and decoder modules, trained in sequential fashion using experience replay—a protocol chosen for its minimal confounding and widespread adoption. Task distributions are defined by activating disjoint subsets of latent features, allowing precise measurement of task-induced interference and representational overlap.
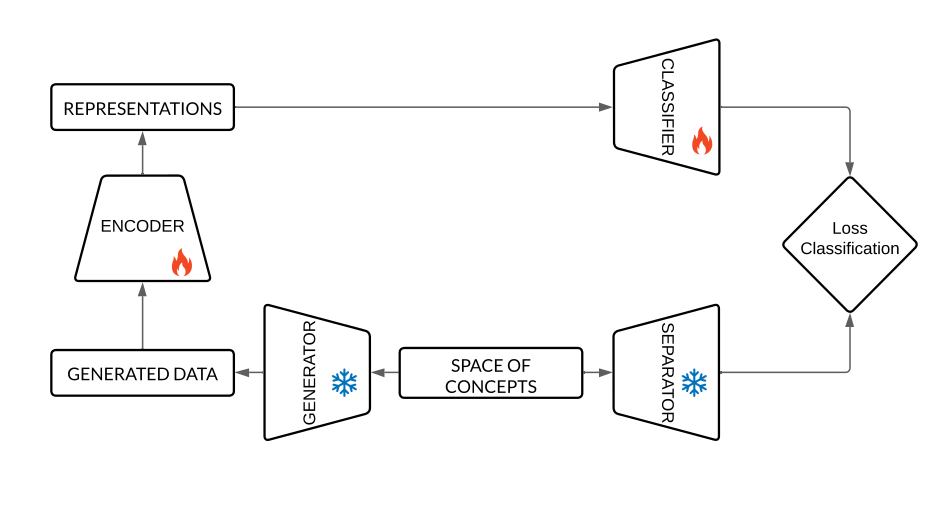
Figure 1: Experimental setup diagram: generator and separator are frozen, encoder/classifier/decoder are sequentially trained with experience replay.
Operational Metrics: Feature, Representation, Superposition, and Retention
Key operationalizations are made explicit. Features are defined geometrically: a direction or linear subspace in the model's activation space, following the linear representation hypothesis. Representation strength is quantified as the norm of the encoded pure-feature vector, R(i,t)=∥wi(t)∥2. Superposition strength, S(i,t), aggregates squared projections of other feature directions onto a given feature, measuring directional overlap. Retention corresponds to the temporal derivative of representation strength, F(i,t)=∂t∂R(i,t).
To relate retention to superposition and representation, the paper utilizes Sparse Identification of Nonlinear Dynamical Systems (SINDy), fitting sparse polynomial relations to feature-level dynamics. This enables formal causal scrutiny of the interplay between overlap, signal strength, and exposure history in feature retention.
Feature-Level Superposition, Dynamics, and Forgetting
Empirical investigation addresses three central questions:
- Does sparsity drive superposition in CL?
- Are polysemantic (overlapping) features more prone to forgetting?
- How does sparsity affect task-level allocation of latent capacity?
A series of heatmaps and joint temporal plots provide granular visibility into these dynamics.
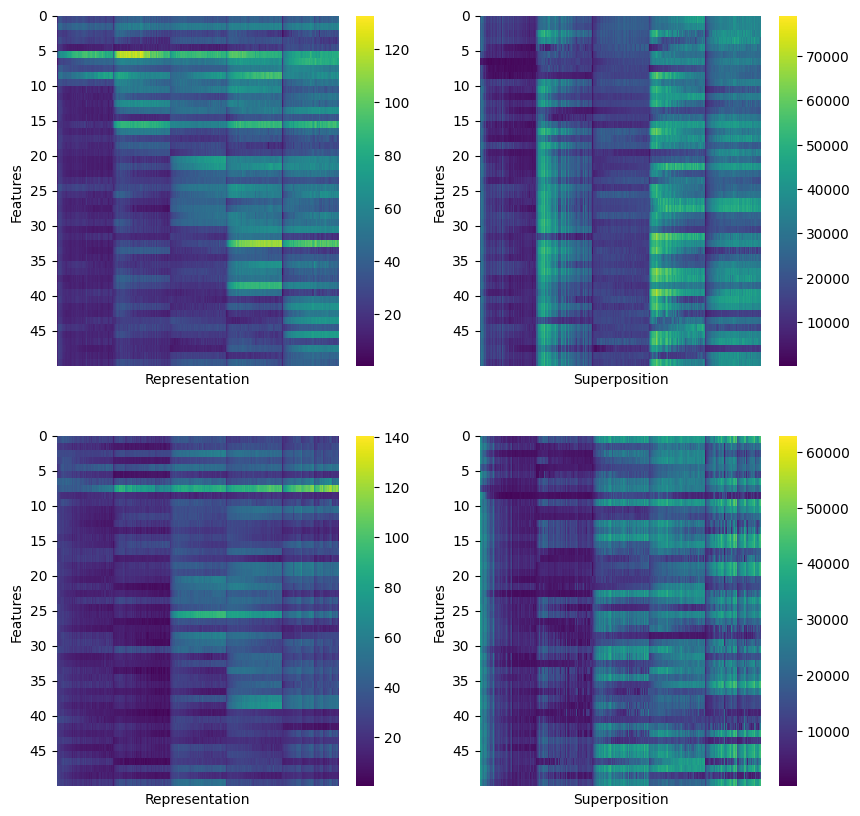
Figure 2: Superposition and representation heatmaps across time for different sparsity levels; higher sparsity induces higher overlap.
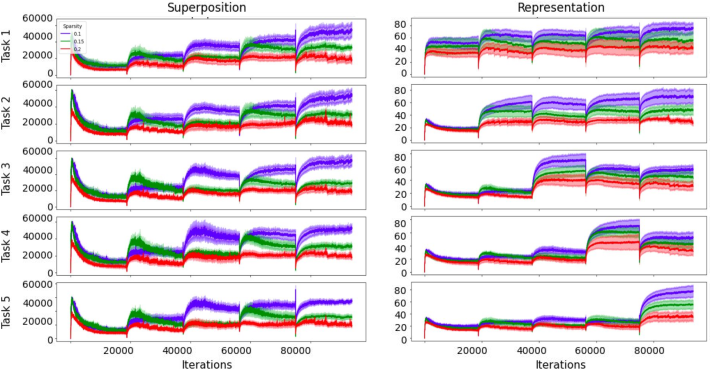
Figure 3: Temporal dynamics of superposition and representation illustrate boundary-specific dips and subsequent recovery.
Key findings include:
- Sparser features exhibit higher overlap: Increased sparsity forces the network to compress more feature directions into fewer latent dimensions, economizing capacity via superposition.
- Superposition grows with task sequence but dips at task boundaries: Transient boundary dips indicate task-specific interference and rapid latent realignment.
- Strong representations mitigate forgetting even under high superposition: High representation strength acts as a resilience factor; forgetting predominantly concentrates in low-R, high-S regimes.
SINDy-derived relations confirm that vulnerability to forgetting is exacerbated for weakly represented features with high overlap, especially soon after task exposure. In contrast, features that rapidly build strong representations buffer further interference, remaining stable even in highly shared subspaces.
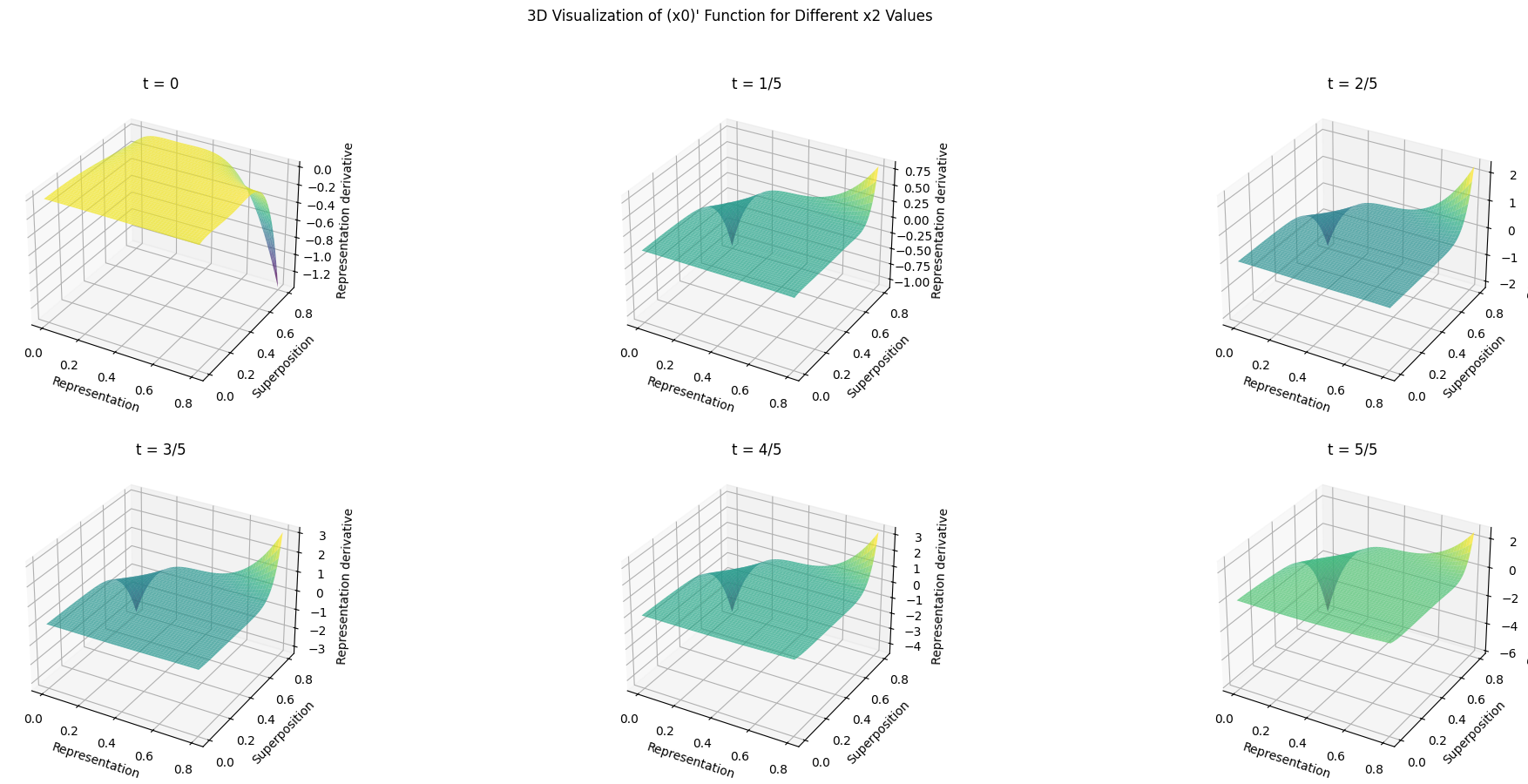
Figure 4: Retention evolution as a function of representation strength and superposition; negative retention is concentrated in low-R, high-S regime.
Task-Level Effective Rank and Latent Capacity Allocation
Task embedding analysis leverages effective rank to quantify how much latent "volume" is allocated per task, serving as a proxy for representational capacity. Both the aggregate and per-task effective rank increase with feature sparsity: sparser feature regimes induce broader occupancy of latent directions across tasks, despite more feature-level overlap.
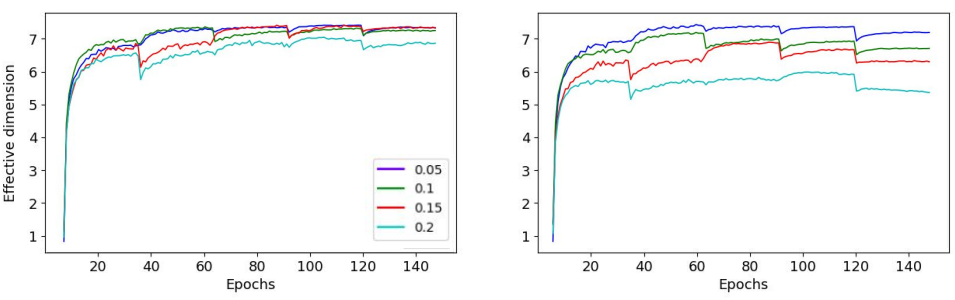
Figure 5: Sum of effective ranks across all tasks grows with sparsity, reflecting broader latent capacity usage.
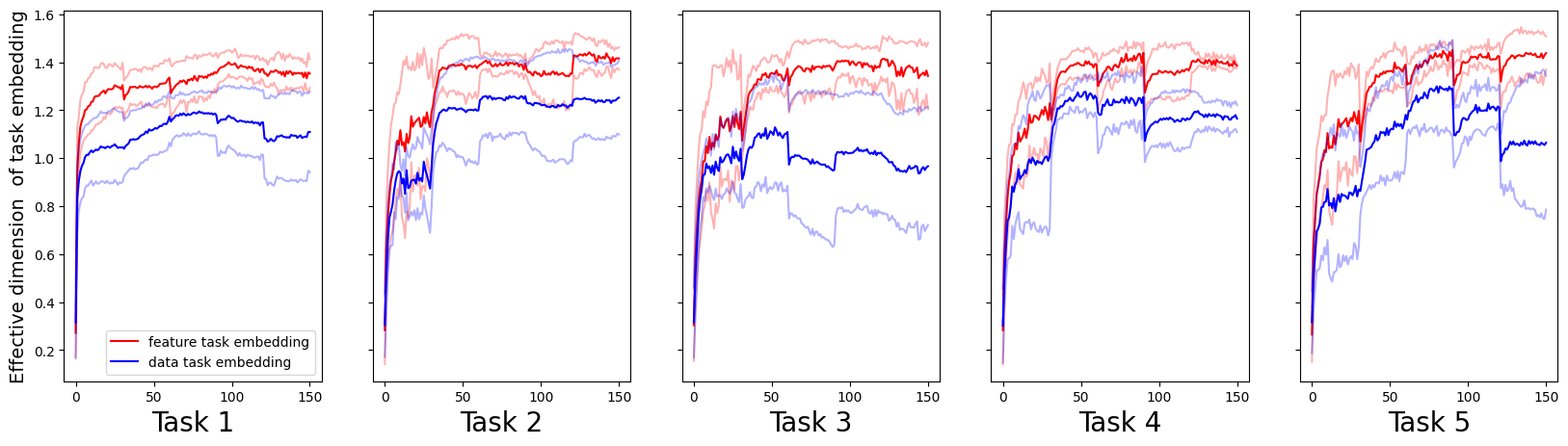
Figure 6: Evolution of task embedding effective dimensions; each task region maintains comparable effective rank regardless of training exposure.
Notably, effective rank contractions at task boundaries echo feature-level boundary dips, pointing to structured transient compression and subsequent expansion as the network consolidates new representations.
Robustness Across Settings and Methodological Stability
Alternative architectural settings and varying bottleneck sizes yield qualitatively consistent results: sparsity reliably amplifies superposition, boundary effects persist, and retention loss is stable in low-R, high-S regions. Instability analyses confirm robustness of main interactions, albeit with some variability in SINDy coefficient selection.
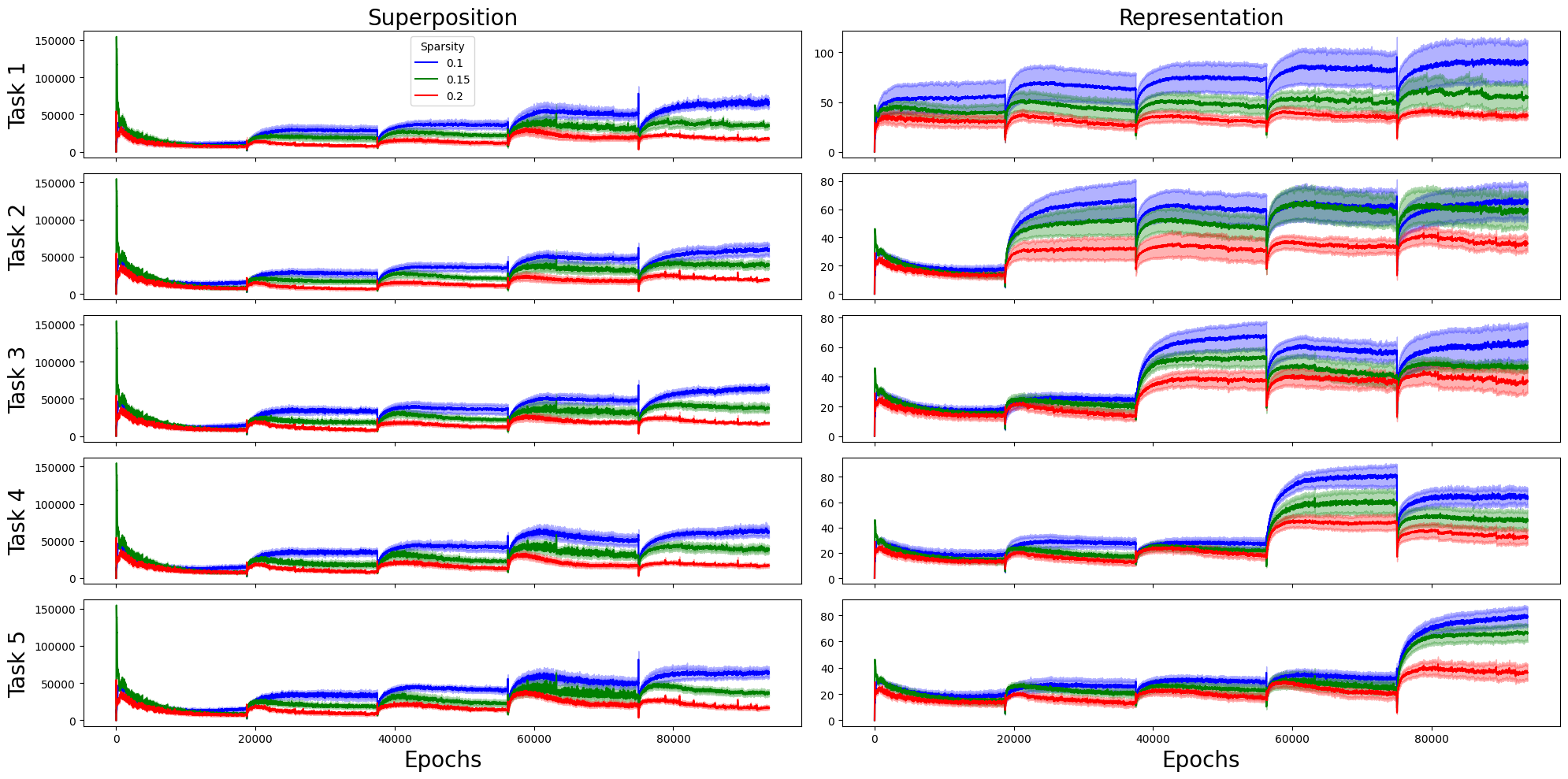
Figure 7: Dynamics of superposition and representation in time for setting 2.
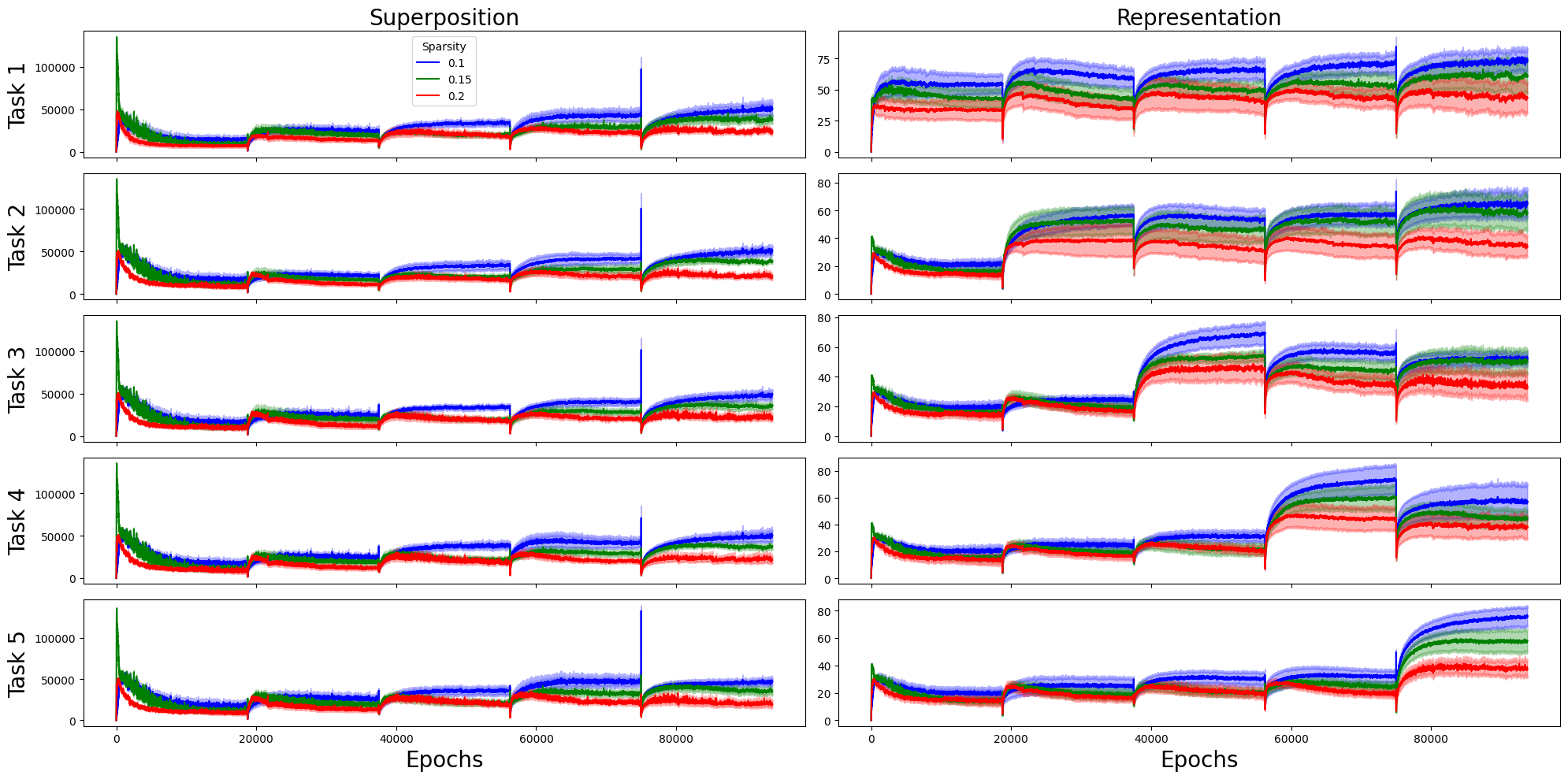
Figure 8: Dynamics of superposition and representation in time for setting 3.
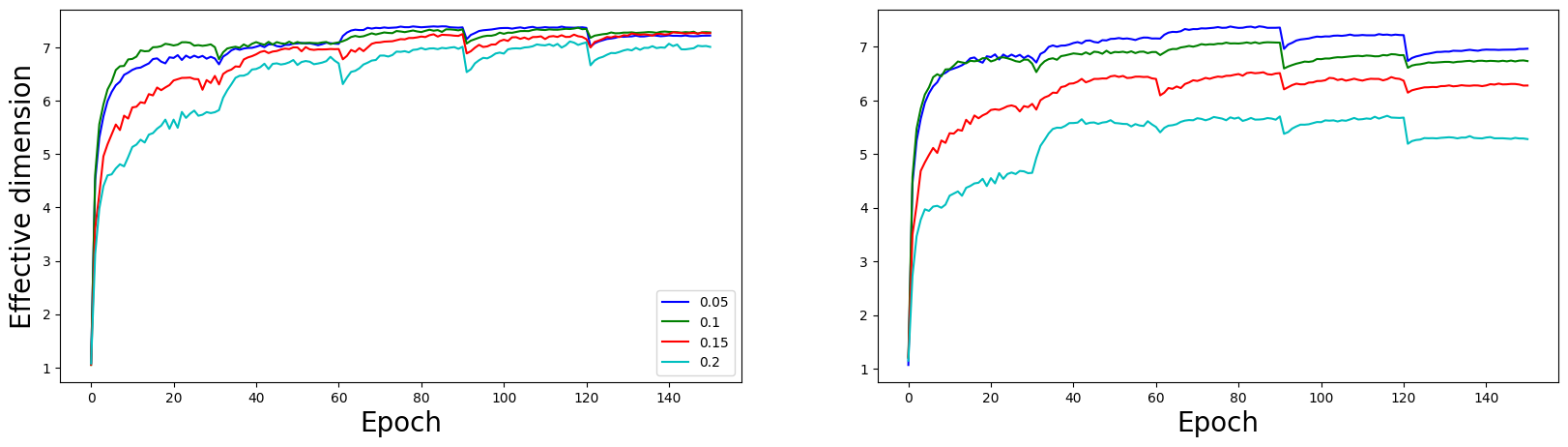
Figure 9: Effective dimensions of tasks vs sparsity (setting 2).
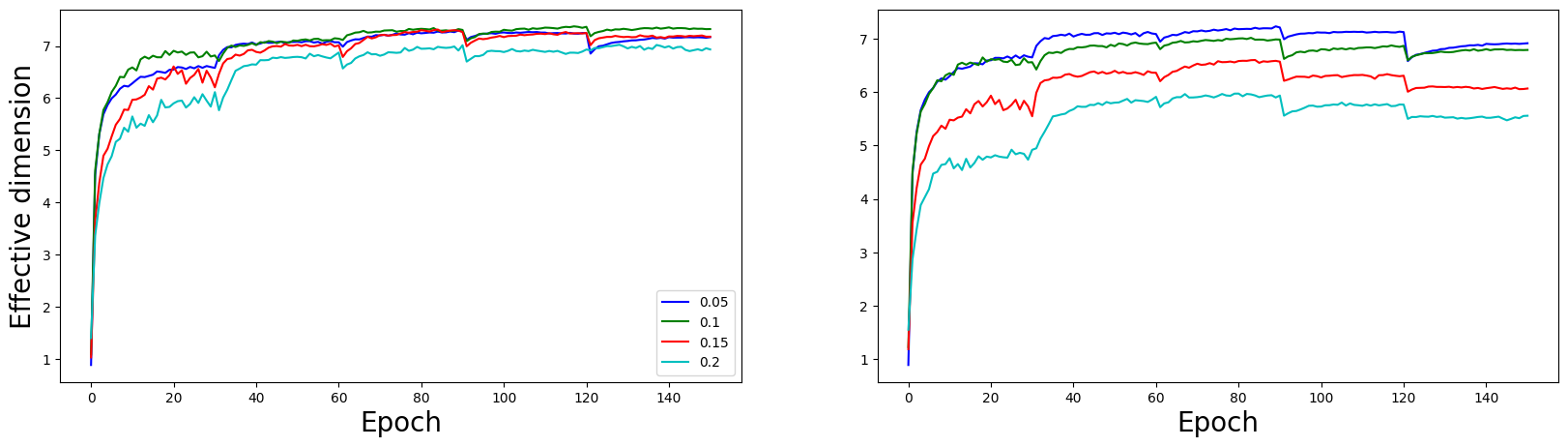
Figure 10: Effective dimensions of tasks vs sparsity (setting 3).
Theoretical and Practical Implications
The findings refine the prevalent intuition that “more superposition means more forgetting.” In reality, forgetting is not determined by superposition alone—it is modulated by the interaction of representation strength, overlap, and latent capacity allocation. Key theoretical implications:
- Polysemantic representations are not intrinsically vulnerable: Their susceptibility is a function of accumulated strength and timing; strong embeddings within shared subspaces are stable.
- Capacity-aware evaluation is critical: Effective rank diagnostics alongside accuracy curves offer a multidimensional lens for retention, especially in regimes of latent pressure.
Practically, these insights suggest diagnostic probes for CL: tracking retention loss in low-R/high-S(i,t)0 regions, scheduling experience replay to attenuate boundary dips, and algorithmic interventions focused on consolidating vulnerable, overlapped features.
Limitations and Future Directions
Limitations include uniform feature sparsity, disjoint task supports, polynomial-limited SINDy dynamics, and retention proxy not being directly linked to task-wise accuracy. Future work should address heterogeneous sparsity patterns, controlled feature-task overlap, richer dynamic classes (non-polynomial terms), and direct mapping of retention measures to classifier performance.
Conclusion
The paper establishes a robust toy-world framework for mechanistic analysis of representation retention in continual learning. It demonstrates that superposition arises as an economical response to sparsity-induced capacity pressure, but retention dynamics are mediated by representation strength and capacity allocation. Algorithmic recommendations include capacity-aware diagnostics and interventions tailored to vulnerable feature regimes. The operational probes—pure-feature embeddings, overlap metrics, and effective-rank traces—form a reusable basis for principled mechanistic studies in both synthetic and realistic CL benchmarks.

