Continual Learning via Sparse Memory Finetuning
Abstract: Modern LLMs are powerful, but typically static after deployment. A major obstacle to building models that continually learn over time is catastrophic forgetting, where updating on new data erases previously acquired capabilities. Motivated by the intuition that mitigating forgetting is challenging because trainable parameters are shared across all tasks, we investigate whether sparse parameter updates can enable learning without catastrophic forgetting. We introduce sparse memory finetuning, leveraging memory layer models (Berges et al., 2024), which are sparsely updated by design. By updating only the memory slots that are highly activated by a new piece of knowledge relative to usage on pretraining data, we reduce interference between new knowledge and the model's existing capabilities. We evaluate learning and forgetting compared to full finetuning and parameter-efficient finetuning with LoRA on two question answering tasks. We find that sparse memory finetuning learns new knowledge while exhibiting substantially less forgetting: while NaturalQuestions F1 drops by 89% after full finetuning on new facts and 71% with LoRA, sparse memory finetuning yields only an 11% drop with the same level of new knowledge acquisition. Our results suggest sparsity in memory layers offers a promising path toward continual learning in LLMs.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper is about helping big LLMs keep learning new things over time without “forgetting” what they already know. The authors show a new way to update a model’s memory very carefully and sparsely, so it can absorb fresh facts while protecting its existing skills.
Goals and Questions
The paper sets out to answer simple but important questions:
- How can we teach a LLM new facts and skills after it has been deployed, without wiping out older knowledge?
- Can updating only a small, carefully chosen part of the model’s memory stop catastrophic forgetting?
- Is this sparse updating as good at learning new things as standard methods like full finetuning or LoRA, but with less damage to past abilities?
How the Method Works (everyday explanation)
Think of a LLM like a huge library full of drawers (its parameters). When you learn something new, you don’t want to rearrange the whole library; you want to put the new info in the few drawers that matter, so you don’t mess up everything else.
The authors use special “memory layers” inside the model:
- A memory layer is like a giant wall of small drawers (memory slots). Each time the model reads a word, it looks up only a tiny number of drawers that seem relevant (like checking the top 32 drawers out of millions).
- Normally, if you train the model on new data, lots of drawers change. That can overwrite old knowledge and cause forgetting.
- Their idea: update only the small set of drawers that are clearly important for the new information, and keep all the other drawers frozen.
How do they pick those important drawers? They use a simple ranking trick called TF‑IDF:
- TF (term frequency): How often a drawer gets used in the current batch of new info.
- IDF (inverse document frequency): How common that drawer is across lots of general data from pretraining.
- Together, TF‑IDF finds drawers that are “hot” for the new info but not commonly used elsewhere. That means they’re more likely to be specific to the new fact, so changing them won’t harm general knowledge.
In practice:
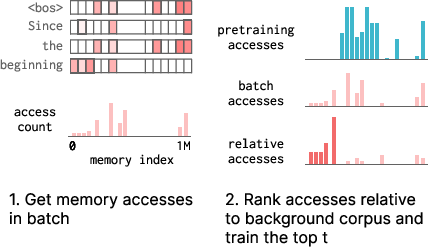
- For each training step on new data, the model counts which drawers (memory slots) it used.
- It scores each slot with TF‑IDF relative to a background set of data (like typical pretraining text).
- It then only “opens” the top t slots for updating (for example, 500 or 10,000), and blocks updates to all other slots. This is the “sparse memory finetuning” idea.
This is different from:
- Full finetuning: Updating many (or all) model parameters, which risks overwriting old skills.
- LoRA: Adding small “adapter” modules to update fewer parameters. LoRA forgets less than full finetuning, but often learns less.
Experiments and Approach
The authors tested their method on two question answering scenarios:
- Learning single facts (TriviaQA):
- The model sees one fact at a time, written in different paraphrases, and must learn it immediately.
- This simulates “small data” learning, like teaching a model a personal preference or a new rule with very few examples.
- Sparse memory finetuning updates only the top t ranked memory slots per batch.
- Learning from documents (SimpleQA with Wikipedia paragraphs):
- The model reads a stream of document chunks and trains step-by-step.
- Each batch includes different synthetic rewrites of the same paragraph to help learning without mixing in unrelated text.
They compare:
- Full finetuning (updating all relevant parameters),
- LoRA (parameter-efficient adapters),
- Sparse memory finetuning (their method).
They also tried different training settings (like learning rate) and found that the choice of optimizer matters. Using SGD (a simple training rule) with sparse memory finetuning reduced forgetting more than AdamW in their setup, while the baselines did not get the same benefit.
Main Findings and Why They Matter
Here are the key results, explained simply:
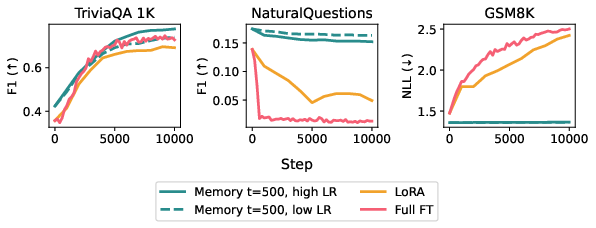
- Sparse memory finetuning learns new facts just as well as full finetuning and LoRA, but forgets far less.
- On TriviaQA facts, after learning new information:
- Full finetuning caused a 89% drop on NaturalQuestions (a held-out benchmark).
- LoRA caused a 71% drop.
- Sparse memory finetuning caused only an 11% drop, while still learning the new facts to the same level.
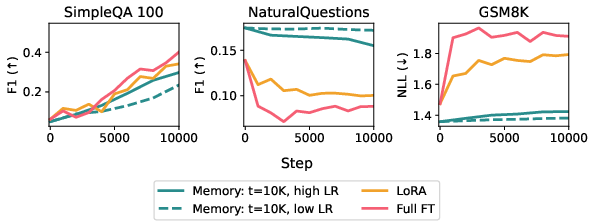
- On document-based QA, sparse memory finetuning matched the target task performance of full finetuning and LoRA, but again showed much less forgetting on other tests.
- When ranking which memory slots to update, TF‑IDF works better than just counting accesses (TF only), because it avoids “common drawers” that are used for general language knowledge.
- Overall, there’s a tradeoff between learning new things and remembering old ones. Their method pushes the balance in a good direction: it learns a lot while forgetting very little.
Why this is important:
- It suggests a practical path to “continual learning” for LLMs—keeping them up to date without retraining from scratch or replaying huge amounts of old data.
- It’s more efficient than storing and revisiting tons of past examples, which becomes increasingly impractical as models gain more experience.
Implications and Potential Impact
This research points to a future where:
- LLMs can steadily improve over time—learning from new facts, user feedback, and real-world interactions—without losing their basic abilities.
- Personalization becomes safer: you can teach a model specific preferences or facts without breaking its general knowledge.
- The idea of “sparse updates” could be applied beyond facts to skills like reasoning or coding, where simply retrieving a document doesn’t solve the problem. Carefully choosing which tiny parts of the model to update may help it grow in complex ways.
In short: updating only the most relevant tiny slices of a model’s memory can make continual learning possible, helping models learn new things while keeping what they already know.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of what remains missing, uncertain, or unexplored in the paper, framed to guide actionable future research:
- External validity beyond QA tasks
- Evaluate sparse memory finetuning on diverse settings (code generation, multi-step reasoning, instruction following, dialog alignment, tool-use) rather than only factual/document QA and limited GSM8K NLL.
- Assess performance on long-context tasks and multi-hop reasoning where memory slot interactions may be more complex.
- Scale and capacity
- Validate the approach on larger base models (e.g., 7B–70B) and larger memory pools (10–100M+ keys), quantifying learning/forgetting, throughput, and memory-bound inference effects.
- Study long-horizon continual updates (e.g., 105–106 steps) to understand memory slot saturation, fragmentation, collisions, and whether eviction or consolidation policies are needed.
- Architecture choices
- Systematically analyze the effect of memory layer placement (which transformer layers), number of memory layers, and per-layer memory sizes on learning and forgetting.
- Examine the impact of changing retrieval hyperparameters (top-k, number of heads, value dimensions) and product-key configurations on both effectiveness and efficiency.
- What to update: keys vs values
- The method updates only memory values; quantify how updating keys (and/or query/gating projections) affects learning capacity, stability, and forgetting, and whether selective key updates are beneficial.
- Ranking and selection strategy
- Develop and compare alternative ranking functions beyond TF-IDF (e.g., Fisher/gradient-based importance, mutual information, per-token/sequence-level salience, domain-aware weighting, or learned selectors).
- Investigate adaptive selection of t (trainable indices) per input/batch and under varying data regimes, including principled criteria for increasing/decreasing t online.
- Quantify sensitivity to batch composition and augmentation strategies (e.g., paraphrase density), and evaluate single-example updates without synthetic augmentations.
- Background corpus dependence
- More robustly study how the choice, size, and coverage of the background corpus for IDF affects forgetting across domains, especially when pretraining distribution is unknown, shifting, or proprietary.
- Explore dynamic background indices (e.g., updating IDF counts over time), domain-conditioned IDF, or multi-domain preservation objectives.
- Optimizer effects and fairness of comparisons
- Provide a rigorous optimizer analysis (SGD vs AdamW vs other adaptive methods) controlling for confounds across methods, including momentum/weight decay interactions with sparse masking.
- Report results with consistent optimizers across baselines and multiple seeds, including statistical significance, to isolate the contribution of sparsity from optimizer choices.
- Efficiency and systems considerations
- Measure training-time overhead of tracking memory accesses and computing TF-IDF rankings at scale; propose efficient instrumentation and caching strategies.
- Benchmark inference-time latency and throughput impacts of memory layers vs standard FFNs/MoE, including memory bandwidth constraints and hardware implications.
- Robustness and safety
- Test resilience to noisy, conflicting, or adversarial updates (e.g., incorrect facts), and design mechanisms for rollback/unlearning at the memory-slot level.
- Explore privacy-preserving continual learning (e.g., per-user isolation of slots, multi-tenant settings), and the risk of cross-user interference in shared memory pools.
- Interaction with existing continual learning methods
- Compare against strong CL baselines beyond LoRA and full finetuning (e.g., EWC, SI, rehearsal/replay, task expansion methods), including hybrid approaches (sparse memory + replay/regularization).
- Evaluate synergy with retrieval-augmented generation (RAG), e.g., when to write knowledge to parametric memory vs retrieve externally, and how to coordinate the two.
- Generalization measurements and metrics
- Use richer forgetting metrics (e.g., instruction-following, safety alignment benchmarks, calibration) and track catastrophic forgetting over longer timescales.
- Provide quantitative analysis of “core set” alignment across large samples, not just qualitative examples, and measure how well TF-IDF identifies truly semantic slots.
- Update scheduling realism
- Test more realistic online training streams (mixed domains, non-iid sequences, interleaved tasks) and varying sequence lengths, rather than homogeneous batches of paraphrases or single-source documents.
- Hyperparameter robustness
- Conduct broader sweeps and sensitivity analyses for t, learning rates, top-k, memory sizes, and augmentation strategies, including ablations on the necessity of synthetic augmentations (Active Reading) vs raw documents.
- Maintenance and lifecycle management
- Develop policies for memory lifecycle (eviction, compaction, deduplication, consolidation) to prevent drift and manage capacity under continuous updates.
- Explore mechanisms for versioning and auditing updates to memory slots to support traceability and safe deployment.
- Theoretical grounding
- Provide theoretical or formal analysis explaining why TF-IDF-based selection reduces interference, and under what conditions it is optimal or suboptimal.
- Model interference dynamics in sparse memory layers, characterizing how slot usage distributions relate to forgetting and learning efficiency.
Practical Applications
Immediate Applications
Below is a set of actionable, real-world use cases that can be deployed now using the paper’s sparse memory finetuning (SMF) approach on memory-layer LLMs. Each item summarizes the application, relevant sectors, potential tools/workflows, and key assumptions or dependencies.
- Hotfix factual updates for production LLMs (software, enterprise support, e-commerce, media)
- Description: Rapidly patch models with new or corrected facts (e.g., product specs, pricing, release notes, breaking news) while minimizing degradation of general capabilities, avoiding costly data replay.
- Tools/workflows: “Sparse Memory Patch Manager” to compute TF-IDF over batch vs background corpus; per-update gradient masks; automated learning–forgetting monitoring; patch rollback/versioning.
- Assumptions/dependencies: Availability of memory-layer models; background corpus that represents pretraining; careful choice of top-t and learning rate; operational guardrails to prevent unintended interference.
- Per-user preference learning without catastrophic forgetting (consumer assistants, education, productivity)
- Description: Persist user-specific facts (names, preferences, routines) with small, reversible updates that won’t erode general skills.
- Tools/workflows: On-device or per-tenant memory patches; lightweight feedback-to-update pipeline; patch TTLs; opt-in privacy controls; evaluation of held-out tasks to track retention.
- Assumptions/dependencies: On-device or server-side finetuning capability; privacy-compliant logging of memory accesses; small-data update regimes suited to SMF.
- Fast compliance/policy updates (finance, healthcare, insurance, legal)
- Description: Quickly incorporate evolving regulations, clinical guidelines, and internal policies while preserving broad reasoning and QA performance.
- Tools/workflows: Controlled policy update batches; audit logs of updated memory slots; rollback and “policy patch” registry; pre-deployment validation against held-out benchmarks.
- Assumptions/dependencies: Rigorous domain evaluation; multi-stakeholder review; documented background corpus (e.g., domain pretraining snapshot).
- Better maintenance for customer support chatbots (software, e-commerce, telecommunications)
- Description: Stream updates from new FAQs, product changes, and operational notices into the model with less forgetting than full finetuning or LoRA.
- Tools/workflows: Document ingestion with Active Reading-style augmentation; batch-level TF-IDF ranking; safety gates; A/B testing of patches; periodic Pareto tuning of learning vs forgetting.
- Assumptions/dependencies: Document augmentation pipeline; continuous evaluation; trained staff to monitor and revert patches.
- Edge/on-prem continual learning without large replay (industrial, defense, regulated infrastructure)
- Description: Incrementally update models deployed in constrained environments using sparse patches instead of replaying large pretraining corpora.
- Tools/workflows: Packaged IDF snapshots shipped with the model; secure patch application; offline monitoring dashboards; patch revert procedures.
- Assumptions/dependencies: Memory-layer architecture on edge; secure training capability; reliable background corpus selection.
- Academic replication and methodology for continual learning research (academia)
- Description: Use SMF as a practical baseline to study catastrophic forgetting vs learning capacity, compare optimizers (SGD vs AdamW), and investigate background corpus effects.
- Tools/workflows: TF-IDF memory-index selection library; gradient masking utilities; standardized learning–forgetting benchmarks (NQ, GSM8K, SimpleQA).
- Assumptions/dependencies: Access to memory-layer LLMs and logging of memory accesses; reproducible data streams; compute resources for sweeps.
- MLOps safeguards: forgetfulness dashboards and Pareto tuning (software, platform engineering)
- Description: Operational guardrails to track trade-offs between learning new information and retaining capabilities; automated tuning of top-t and LR.
- Tools/workflows: “Forgetfulness dashboard” displaying target vs held-out metrics; Pareto frontier explorer; alerting for degradation; patch diffs and rollback buttons.
- Assumptions/dependencies: Instrumentation that logs memory accesses; routine held-out evaluation; policy for patch acceptance/rollback.
- Data minimization for privacy (policy, privacy engineering)
- Description: Reduce dependence on replay buffers containing user data by favoring sparse parametric updates and patch deletion to honor “right to be forgotten.”
- Tools/workflows: Patch-level provenance and deletion; per-tenant isolation; compliance reporting of updated slot indices.
- Assumptions/dependencies: Regulatory acceptance; robust procedures to remove patches and verify no residual effects; multi-tenant isolation.
- Personal daily assistants that truly remember
- Description: Store personal facts (pronunciations, dietary restrictions, device names) without degrading general capabilities.
- Tools/workflows: Lightweight per-session update batches; small top-t values; local patch cache with easy rollback.
- Assumptions/dependencies: Device or cloud finetuning channel; background corpus representative of general language use.
Long-Term Applications
The following applications are promising but require further research and engineering (e.g., scaling, robustness, generalized scoring beyond TF-IDF, broader evaluations). They extend SMF from factual updates toward skill acquisition, reasoning, and multi-tenant systems.
- Lifelong coding assistants that learn from user corrections (software development)
- Description: Incrementally absorb project-specific patterns, style preferences, and refactorings while retaining broad coding ability.
- Tools/workflows: Code-aware memory ranking (e.g., AST- or symbol-level indices); patch provenance tied to repos; continuous evaluation on held-out coding tasks.
- Assumptions/dependencies: Generalization beyond factual QA; scoring functions adapted to code semantics; strong safeguards to prevent propagation of bugs.
- Skill acquisition for autonomous agents and robotics (robotics)
- Description: Store task-specific procedures or subskills in sparse memory while minimizing interference with existing behaviors.
- Tools/workflows: Integration of memory layers into policy networks; environment-aware ranking (beyond TF-IDF); curriculum streaming with patch validation.
- Assumptions/dependencies: Mapping from sensorimotor experience to memory indices; safety-critical evaluation; reliable rollback of learned behaviors.
- Continual healthcare decision support with evolving guidelines (healthcare)
- Description: Safely ingest guideline updates and local protocols while preserving diagnostic reasoning and QA performance.
- Tools/workflows: Evidence-linked patch updates; clinical validation pipelines; interpretable audit of memory slots; rollback and risk assessments.
- Assumptions/dependencies: Regulatory approval; extensive testing; background corpus that captures foundational medical knowledge.
- Federated sparse memory updates across organizations (cross-sector)
- Description: Aggregate sparse patches from multiple clients (e.g., hospitals, banks) while controlling interference and privacy.
- Tools/workflows: Secure patch aggregation; conflict resolution across overlapping memory indices; differential privacy; per-client IDF stats.
- Assumptions/dependencies: Federated protocols; patch merging strategies; privacy guarantees; standardization of memory-layer architectures.
- Knowledge-patch marketplaces and versioned distribution (software ecosystem)
- Description: Distribute curated “knowledge patches” (e.g., tax law updates, domain encyclopedias) for memory-layer models.
- Tools/workflows: Patch registries with semantic diffing; licensing and provenance; compatibility checks; automated retention tests.
- Assumptions/dependencies: IP and security controls; standardized patch formats; vendor collaboration.
- Multi-tenant isolation and selective forgetting (policy, platform)
- Description: Per-tenant memory partitions and precise removal of tenant-specific patches to satisfy data deletion rights.
- Tools/workflows: Tenant-aware slot isolation; forensic tools to trace slot usage; deletion semantics with post-removal retention audits.
- Assumptions/dependencies: Reliable identification of impacted slots; guarantees that deletions do not harm global performance; governance frameworks.
- Adaptive educational tutors and training systems (education)
- Description: Persist learner-specific misconceptions, mastery signals, and goals without degrading general pedagogy.
- Tools/workflows: Concept-level memory mapping; human-in-the-loop oversight; fairness monitoring; sparse updates aligned to learning objectives.
- Assumptions/dependencies: Validation across diverse learners; mitigation of bias; richer ranking beyond TF-IDF for pedagogical content.
- Hybrid RAG + sparse parametric updates (software, knowledge management)
- Description: Combine retrieval for long-tail content with SMF for high-frequency or critical facts to reduce latency and improve reliability.
- Tools/workflows: Policy deciding when to update parametric memory vs rely on retrieval; joint monitoring of RAG and SMF components; rollback of param updates.
- Assumptions/dependencies: Robust controllers to avoid overfitting; evaluation of end-to-end quality; careful handling of conflicts between retrieved and memorized content.
Notes on Assumptions and Dependencies Across Applications
- Architectural prerequisites: The approach depends on memory-layer LLMs (e.g., product-key memory with trainable keys/values) and instrumentation to log memory accesses.
- Ranking and background corpus: TF-IDF-based selection requires a representative background corpus; poor choice can increase forgetting. Future work may explore task-aware ranking (sequence-level, domain-specific IDF).
- Optimizer and hyperparameters: The paper reports improved forgetting behavior with SGD for SMF; optimizer choice, top-t, and learning rate are critical to the learning/forgetting Pareto.
- Domain scope: Demonstrated primarily on factual QA. Extending to reasoning, coding, and skill learning will require new scoring functions, broader evaluation, and safety guardrails.
- Monitoring and rollback: Operational success hinges on forgetfulness dashboards, patch versioning, and quick rollback mechanisms, especially in regulated domains.
- Privacy and governance: Patch provenance, per-tenant isolation, and deletion workflows enable compliance (e.g., data minimization, right-to-be-forgotten), subject to regulatory acceptance and robust technical guarantees.
Glossary
- Active Reading: A document-augmentation technique that generates synthetic variations to improve learning from text. "We use Active Reading \citep{lin2025learning} to generate synthetic augmentations of the chunk."
- AdamW: An optimizer that combines Adam with decoupled weight decay for regularization. "We initially used AdamW for all methods before realizing that adaptive per-parameter step sizes, weight decay, and momentum can interact with sparsity in unexpected ways."
- Adapter: Lightweight modules added to neural networks to enable parameter-efficient finetuning without modifying most base weights. "Expansion-based approaches add new parameters such as adapter, LoRA modules, or MoE experts for each task \citep{rusu2016progressive,wang2024wise,houlsby2019parameter,hu2021lora,gritsch2024nexus,shen2023moduleformer}."
- Catastrophic forgetting: The loss of previously learned capabilities when a model is updated on new data. "A key barrier to continual learning is catastrophic forgetting \citep{mccloskey1989catastrophic}: when updating on a stream of new information, models often lose previously acquired capabilities."
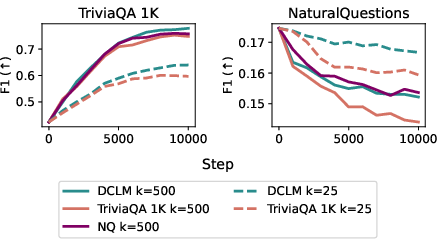
- DataComp-LM (DCLM): A large pretraining corpus used as background data for ranking memory indices. "For our main experiments, we use the memory accesses on 1000 random batches of DCLM \citep{li2024datacomplm} as a representative sample of generic pretraining data."
- Dropout: A regularization method that randomly zeroes activations during training to reduce overfitting. "Regularization methods such as dropout \citep{srivastava2014dropout}, weight decay \citep{loshchilov2019decoupled}, or KL penalties \citep{ouyang2022training} restrict parameter updates to preserve performance to stay close to initialization."
- Elastic Weight Consolidation (EWC): A technique that penalizes changes to parameters important for previous tasks, measured via the Fisher information. "Elastic Weight Consolidation \citep{kirkpatrick2017overcoming} regularizes updates to preserve parameters that are ``important'' to previous tasks, as measured with the Fisher information matrix."
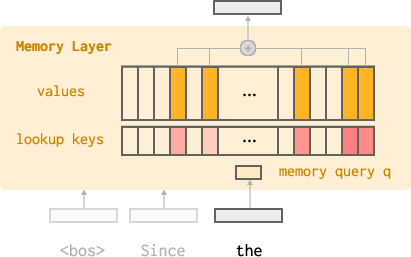
- Feedforward network (FFN): The MLP component in a Transformer block, often replaced or augmented in architecture variants. "For the memory-augmented model, we swap out the feedforward network (FFN) in the middle of the model (layer 12 out of 22) with a lookup into a memory pool of size 1M, memory accesses per token, 4 memory heads, and a value dimension of $1024$."
- Fisher information matrix: A measure of parameter importance used to regularize updates in continual learning. "Elastic Weight Consolidation \citep{kirkpatrick2017overcoming} regularizes updates to preserve parameters that are ``important'' to previous tasks, as measured with the Fisher information matrix."
- Gating (input-dependent): A mechanism that modulates outputs based on the input, often via element-wise scaling. "An input-dependent gating is applied to the weighted sum of the top values, which then becomes the output of the memory layer."
- Grafting: A method that isolates task-specific parameters to enable learning with minimal interference. "Work such as grafting has found that as little as 0.01\% of model parameters are responsible for model performance on a particular task \citep{panigrahi2023task}, and that these parameters can be isolated to enable continual learning with less forgetting."
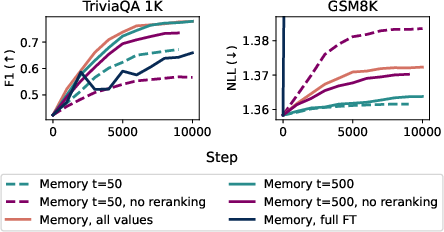
- GSM8K: A math word problem benchmark used to evaluate reasoning and forgetting. "Sparse memory finetuning learns more on the target facts, while forgetting much less on held-out benchmarks (NaturalQuestions and GSM8K)."
- HellaSwag: A commonsense reasoning benchmark used as a held-out task to assess forgetting. "For held-out performance, we measure F1 score on NaturalQuestions \citep{kwiatkowski2019natural} and accuracy on HellaSwag \citep{zellers2019hellaswag}."
- KL penalties: Regularization terms based on Kullback–Leibler divergence that keep updated models close to initial behavior. "Regularization methods such as dropout \citep{srivastava2014dropout}, weight decay \citep{loshchilov2019decoupled}, or KL penalties \citep{ouyang2022training} restrict parameter updates to preserve performance to stay close to initialization."
- LoRA: Low-Rank Adaptation; adds small trainable matrices to large models for efficient finetuning. "We compare sparse memory finetuning to full finetuning and parameter-efficient finetuning with LoRA \citep{hu2021lora}."
- Memory-bound: A regime where inference speed is limited by memory access rather than computation. "since each token only activates a small set of parameters rather than a large expert, decoding efficiency can be much improved, given the memory-bound nature of inference."
- Memory heads: Parallel subcomponents in memory layers that use different key projections, analogous to attention heads. "k=32 per memory attention head, out of 1M total indices."
- Memory layer: A parametric key–value memory module integrated into Transformers, queried via attention-like mechanisms. "Memory layers \citep{berges2024memorylayersscale,he2024mixturemillionexperts,weston2015memorynetworks} add a trainable parametric memory that can be queried via an attention-like mechanism."
- Mixture-of-Experts (MoE): An architecture that routes inputs to different experts; here, memory locations act as many small experts. "This approach can also be thought of as a mixture-of-experts (MoE) architecture \citep{shazeer2017outrageously} with a large number of small experts, one for each memory location~\citep{he2024mixturemillionexperts}."
- NaturalQuestions: A question-answering benchmark used to assess knowledge retention. "For held-out performance, we measure F1 score on NaturalQuestions \citep{kwiatkowski2019natural} and accuracy on HellaSwag \citep{zellers2019hellaswag}."
- Negative log-likelihood (NLL): A loss metric measuring how well the model predicts target tokens; lower is better. "Compare to the results in \cref{fig:main-tqa}: Sparse memory finetuning with SGD achieves TQA 1K F1 0.7, NQ F1 0.15, and GSM8K NLL 1.5."
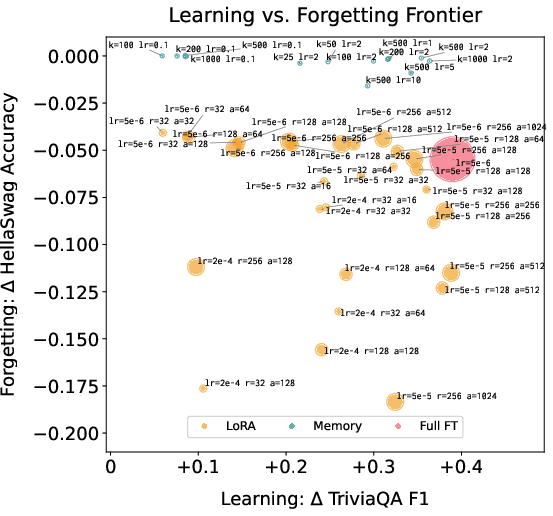
- Pareto frontier: The set of models that are not dominated in the tradeoff between learning and forgetting. "We see that sparse memory finetuning indeed Pareto dominates, learning more while forgetting less."
- Product keys: A technique that factorizes keys to enable efficient lookup over very large memory indices. "To perform memory lookups efficiently, memory layers use product keys~\citep{lample2019largememorylayersproduct} to decompose the keys into two halves, enabling efficient lookup across a large number of indices."
- Query projection: A learned mapping from inputs to query vectors used to retrieve memory entries. "Given an input and query projection ,"
- Replay-based methods: Techniques that mitigate forgetting by rehearsing samples from previous tasks or pretraining corpora. "Finally, replay-based methods reduce forgetting by maintaining a buffer of previous tasks or pretraining samples to rehearse during training \citep{robins1995catastrophic, lesort2022continual, scialom2022continual,chen2025continual}."
- Retrieval-augmented generation (RAG): A method that augments generation by retrieving relevant documents at inference time. "We tested our method on factual learning tasks, for which retrieval-augmented generation (RAG) is a natural present-day solution."
- Self-attention: A mechanism that computes weighted interactions among token representations within a sequence. "The standard Transformer block consists of a self-attention layer, followed by a feedforward network."
- SiLU: The Sigmoid Linear Unit activation function, defined as x·sigmoid(x). "and ."
- Sparse memory finetuning: The proposed method that updates only highly relevant memory slots to reduce interference and forgetting. "We introduce sparse memory finetuning, leveraging memory layer models \citep{berges2024memorylayersscale}, which are sparsely updated by design."
- Stochastic Gradient Descent (SGD): An optimizer that updates parameters using noisy gradient estimates from mini-batches. "Switching to SGD further decreased the forgetting on held-out tasks, although interestingly we did not see similar benefits for full finetuning and LoRA"
- TF-IDF: Term Frequency–Inverse Document Frequency; here, a ranking score to select memory indices that are specific to a batch relative to a background corpus. "We use TF-IDF as a ranking score, identifying a set of indices to update with each gradient step that minimally interferes with the model's existing knowledge."
- Top-: Selecting the k highest-scoring items (e.g., memory keys) for retrieval or computation. "identify the top keys."
- Top-: Selecting t memory slots to make trainable in each step based on a ranking criterion. "We introduce sparse memory finetuning, updating just the top memory slots that are more frequently accessed on a certain batch relative to some background corpus (e.g. pretraining data)."
- Transformer: A neural architecture built from self-attention and feedforward layers, widely used in language modeling. "We replace one FFN in the middle of the transformer with a memory lookup."
- TriviaQA: A question-answering dataset used for learning new facts in the experiments. "We use 1K questions from the TriviaQA test set and rephrase them as statements."
- Weight decay: A regularization technique that penalizes large parameter values to prevent overfitting. "Regularization methods such as dropout \citep{srivastava2014dropout}, weight decay \citep{loshchilov2019decoupled}, or KL penalties \citep{ouyang2022training} restrict parameter updates to preserve performance to stay close to initialization."
Collections
Sign up for free to add this paper to one or more collections.