- The paper demonstrates that integrating inverse dynamics in JEPA-style latent models prevents encoder collapse and yields action-aligned representations.
- Empirical results show that SMWM recovers intrinsic state dimensions by filtering distractors, achieving up to 84% planning success in complex tasks.
- The method provides a minimal anti-collapse mechanism without reconstruction losses, enabling effective control in diverse 2D and 3D environments.
Sensorimotor World Models: Perception for Action via Inverse Dynamics
Motivation and Problem Statement
Traditional world models in RL and control seek to predict future observations or states given actions, often relying on pixel-level reconstruction or reward signals. This approach, however, suffers from high-dimensionality, irrelevant detail retention, and representation collapse: the encoder may degenerate to mapping all observations to a constant embedding, trivializing dynamics prediction and rendering the model useless for control. Recent JEPA-style latent models transfer prediction directly to the embedding space, but require elaborate anti-collapse mechanisms such as frozen encoders, auxiliary distributional regularizers (e.g., SIGReg, VICReg), or exponential-moving-average targets. The paper proposes sensorimotor world models (SMWM), advancing a principled approach rooted in perception-for-action: world representations should encode only controllable degrees of freedom, discarding action-irrelevant distractors.
Methodology: Inverse Dynamics Regularization
SMWM comprises an encoder fθ, a forward dynamics model gϕ, and an inverse dynamics model hψ, all jointly trained from offline, reward-free trajectories containing (ot,at,ot+1) tuples. The forward model is supervised with mean-squared error between predicted and true next embeddings, while the inverse model predicts executed actions from consecutive embeddings, also under mean-squared error. The joint objective
L=Lfwd+λLinv
ensures the encoder receives both forward and inverse gradients, preventing collapse and inducing action-aligned representations. The inverse loss anchors the representation to action-relevant structure without imposing geometric priors on the embedding space.
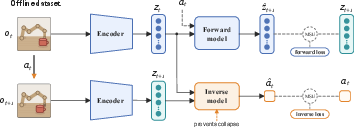
Figure 1: SMWM architecture, showing encoder, forward, and inverse dynamics models, each interacting with the offline dataset.
Empirical Analysis: Latent Structure and Controllability
In controlled experiments using dot-world environments (single/multiple dots with varying controllable and distractor degrees), SMWM reliably recovers the intrinsic state dimension:
In the absence of inverse loss, the encoder collapses entirely, confirming the necessity of action prediction as an anti-collapse mechanism.
Commutativity and Latent Action Geometry
The encoder and forward model approximately commute: encoding after action application coincides with applying the learned latent intervention. This establishes approximate equivariance, and empirical analysis demonstrates that forward rollouts in latent space track encoded ground-truth trajectories. Actions manifest as latent translations, visualized by autoregressive rollouts and corresponding embeddings.
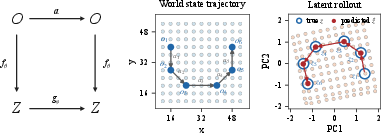
Figure 3: Joint encoder and forward model commute, with rollouts in latent space tracking ground-truth embeddings.
Filtering Uncontrollable Distractors
Varying environment structure yields a consistent correspondence between effective latent dimension and controllable degrees of freedom, regardless of distractor prevalence. The encoder's variance allocation matches the true action span and disregards stochastic distractors.
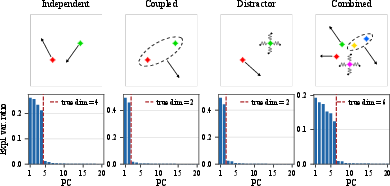
Figure 4: PCA spectra for environments with multiple dots and distractors; latent dimension matches controllable structure.
A further visualization using asymmetric sprite agents with varied action interfaces shows the encoded representation systematically preserves only controlled pose variables, averaging over uncontrolled ones.
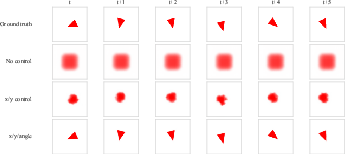
Figure 5: Sprite reconstructions with different action interfaces; controlled variables are preserved, uncontrolled ones averaged.
Goal-Conditioned Planning and Downstream Control
Planning is performed by encoding start and goal observations, rolling out the learned forward dynamics model in latent space, and optimizing action sequences with CEM. SMWM matches or outperforms SIGReg regularization on diverse environments: 2D navigation, contact-rich manipulation, continuous control, and high-dimensional 3D tabletop manipulation. The largest margin emerges in OGBench-Cube, a complex 3D manipulation task, where SMWM achieves an 84% planning success rate versus SIGReg's 59%.
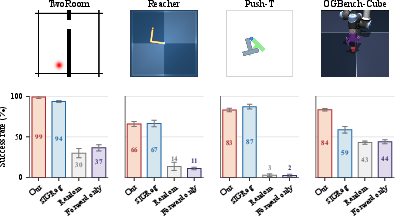
Figure 6: Planning success rates across environments; SMWM matches or surpasses SIGReg, particularly in 3D tasks.
Robustness to planning horizon shows stable performance as goal offset increases, with SMWM maintaining success across longer rollouts in TwoRoom and OGBench-Cube.
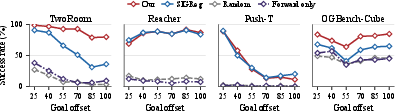
Figure 7: Goal-conditioned planning robustness against horizon.
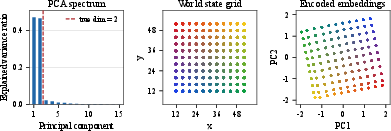
Latent Geometry and Physical State Probing
Analyzing held-out embeddings and their PCA spectra confirms SMWM's compactness: dominant axes align with controllable state variables (e.g., Cartesian coordinates, angles). Ground-truth physical quantities are linearly or nonlinearly recoverable from embeddings. SIGReg baselines, in contrast, allocate variance across many PCs and are less interpretable.
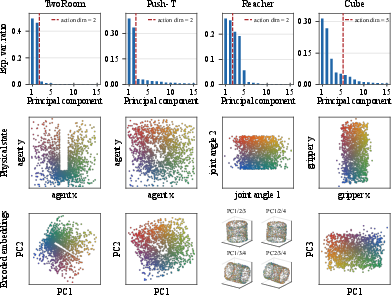
Figure 8: SMWM embeddings' PCA spectra and subspace projections; geometry mirrors environment state topology.
Practical Implications and Theoretical Insights
SMWM provides a minimal yet effective anti-collapse mechanism with a single hyperparameter, free from distributional priors and reconstruction loss. Empirical results indicate superior interpretability, compactness, and downstream control performance in both 2D and 3D environments. The model aligns with causal representation learning and enactive perception principles, organizing latent spaces by controllable structure. Approximate equivariance and latent interventions afford future theoretical investigation into group-structured representations, compositionality, and causal abstraction.
Limitations and Future Work
SMWM assumes actions are recoverable from consecutive observations; failures may arise when action-induced changes are invisible or ambiguous. The current model does not encode velocity or history-dependent quantities; incorporating observation histories and multi-step inverse objectives is a potential extension. Biased behavioral policies may yield action-correlated distractors, a challenge for the encoder. Long-horizon planning remains susceptible to compounding error; more robust data regimes and integration of inverse heads into hierarchical planners are natural future directions.
Conclusion
SMWM demonstrates that inverse dynamics regularization suffices to stabilize and organize JEPA-style latent world models. The learned representations are compact, interpretable, track controllable degrees of freedom, filter out distractors, and yield competitive planning performance across varied tasks. The work indicates that perception-for-action principles can be effectively instantiated in latent representation learning, advancing both practical world modeling and theoretical understanding of sensorimotor contingencies in intelligent agency.