- The paper introduces competence-aware reward shaping that adapts reasoning length based on evolving model competence during training.
- It leverages an EMA-smoothed competence estimate, stage-aware effort scoring, and posterior amplification to balance exploration and efficiency.
- Experimental results on video reasoning benchmarks show improved accuracy and token efficiency compared to static reward strategies.
Competence-Aware Reward Shaping for Adaptive Reasoning Length in Video-MLLMs
In the domain of multimodal video reasoning, reinforcement learning (RL)-based optimization of Video-MLLMs has historically relied on static mechanisms for reasoning-length control, such as fixed rewards and penalties. Such static strategies are fundamentally mismatched to the dynamic evolution of model competence during training. Early-stage truncation of reasoning may suppress necessary exploration, while late-stage tolerance of verbosity results in redundant chains and inefficient decoding. The "CARE: Competence-Aware Reward Shaping for Adaptive Reasoning Length in Video-MLLMs" framework addresses this challenge by introducing competence-aware reward shaping, aiming to balance exploration and efficiency dynamically as the model's competence develops.
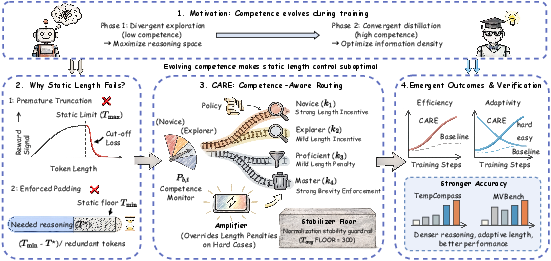
Figure 1: CARE's core motivation is to evolve reward preference over reasoning effort according to competence, avoiding static design mismatches throughout RL training.
Framework and Algorithmic Design
CARE is architected as a training-time reward controller fully integrated into the GRPO (Generalized Regressive Preference Optimization) pipeline, with no inference-time overhead. At each optimization step, CARE extracts three key signals from policy rollouts: group pass rate (Pg), chain-of-thought (CoT) reasoning length (ℓ(h)), and an EMA-smoothed competence estimate (Pb,t). CARE routes optimization into progressive behavioral regimes based on these signals:
- Competence Estimation: An EMA of batch pass rates provides a low-variance global state of model maturity, serving as the routing basis for reward adaptation.
- Stage-Aware Effort Scoring: Training is partitioned into four progressive stages (Novice, Explorer, Proficient, Master) based on competence thresholds. Reward preference is shifted from protecting extended exploration (low competence) to favoring concise, information-dense reasoning (high competence). Batch-level statistics normalize effort scoring to prevent conflating verbosity with inherent task complexity.
- Posterior Amplifier: CARE amplifies reward for unexpectedly strong performance on historically difficult samples, modulating incentives based on the divergence between instant rollouts and the global competence baseline.
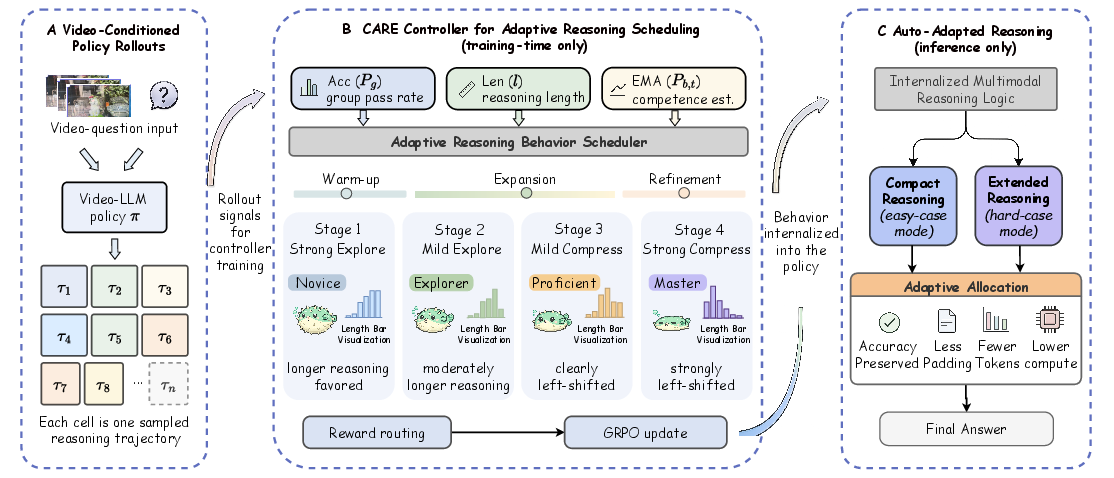
Figure 2: The CARE framework routes reward incentives during RL according to competence estimates, internalizing adaptive reasoning behaviors for dynamic allocation during inference.
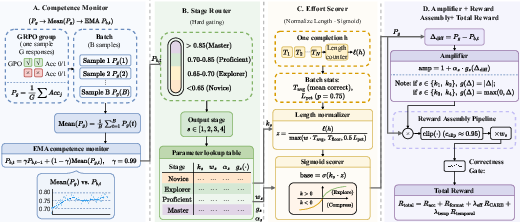
Figure 3: CARE's training pipeline consists of group pass-rate calculation, competence estimation, stage routing, effort normalization, posterior reward amplification, and reward assembly.
Experimental Evaluation and Numerical Results
CARE is evaluated on a suite of challenging video reasoning benchmarks, including VSI-Bench, VideoMMMU, MMVU, MVBench, TempCompass, and VideoMME, against state-of-the-art video-language and RL-based models.
CARE demonstrates superior performance, consistently outperforming baselines under identical backbone and input configurations. For instance, with the Qwen2.5-VL-7B backbone and 16-frame input, CARE improves VSI-Bench from 30.3 to 33.9 and VideoMMMU from 47.2 to 50.2. Performance further scales with more frames (up to 64), reaching 36.2 on VSI-Bench and 62.3 on VideoMME. CARE not only strengthens multi-step video reasoning but also general video understanding.
Ablation studies highlight the necessity of each CARE component:
Training Dynamics and Efficiency Analysis
CARE induces a characteristic expansion-compression cycle of reasoning length. Early-stage training is marked by broader reasoning exploration (longer chains), while later stages progressively compress redundant traces, yielding concise, dense, and information-rich reasoning. Token efficiency is markedly improved, with CARE producing higher reward per generated token throughout RL.
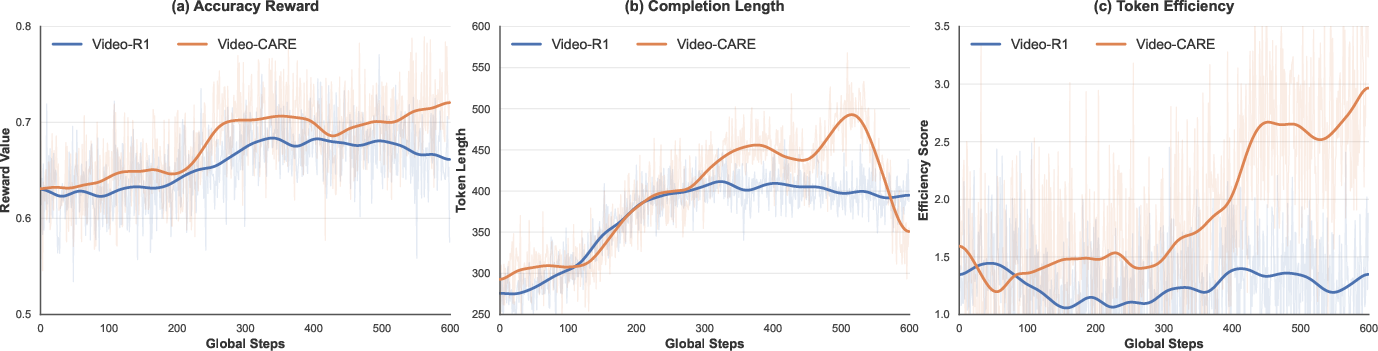
Figure 5: CARE achieves higher accuracy reward, adaptively adjusts response length, and realizes superior token efficiency compared to Video-R1 during RL training.
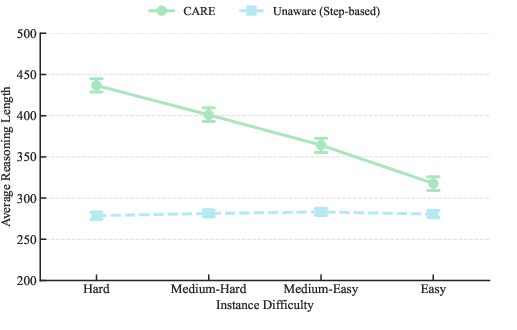
Length allocation is monotonic with difficulty: harder instances receive longer reasoning traces, while easier cases are compressed. CARE reduces computational cost without collapse, maintaining a difficulty-sensitive response budget and increasing reasoning density.
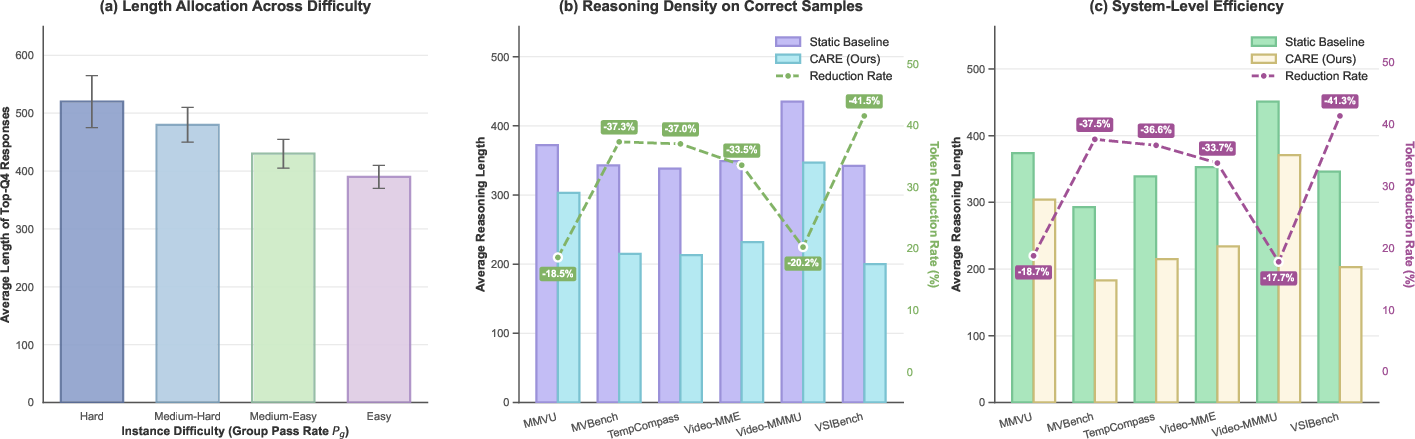
Figure 6: CARE systematically compresses reasoning length while preserving correctness and efficiency across difficulty groups and benchmarks.
Hyperparameter Sensitivity and Policy Robustness
CARE displays stability across variations of competence thresholds, length tolerance, and minimum reasoning floor. The default setting achieves the strongest accuracy-length trade-off, indicating robustness rather than fragility.
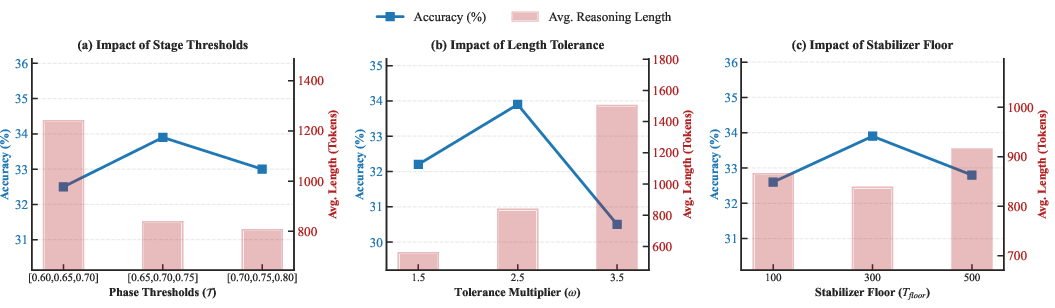
Figure 7: Hyperparameter sensitivity analysis shows CARE operates optimally across stage thresholds, length tolerance, and floor, avoiding token growth and accuracy degradation.
Kernel density estimation demonstrates competence retention under compression: instance pass-rate distributions shift rightward, and the failure tail contracts, confirming that compression is competence-aware and does not degrade performance.
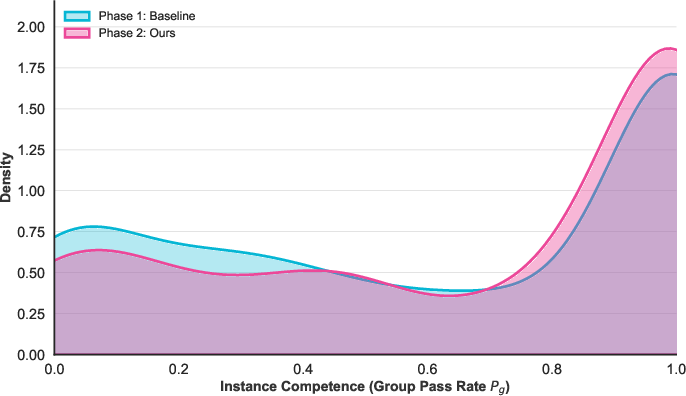
Figure 8: CARE training increases the density of near-perfect competence instances, indicating high-quality compression.
The expansion-compression cycle is visualized by reasoning-length distributions, showing adaptive modulation across training phases.
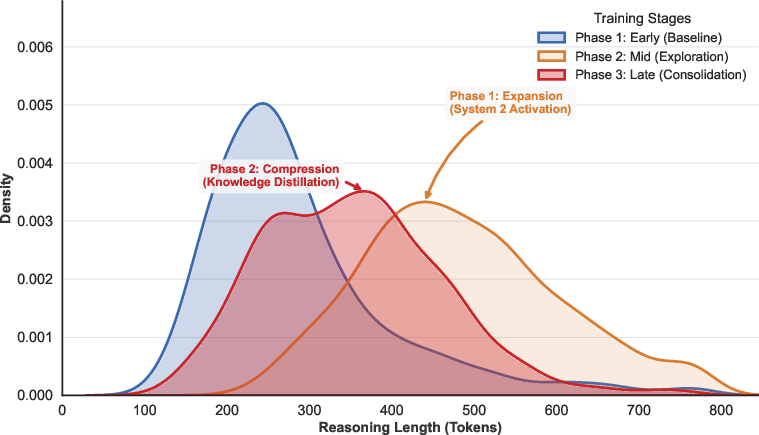
Figure 9: CARE expands the reasoning space early and compresses unnecessary tokens late, facilitating automatic policy refinement.
Case Studies and Qualitative Analysis
Qualitative evaluation under viewpoint occlusion reveals CARE's capacity for information retention and error correction. CARE revisits evidence, updates reasoning as new visual cues become available, and avoids premature commitment to erroneous interpretations, unlike baselines which rely on longer but less informative traces.
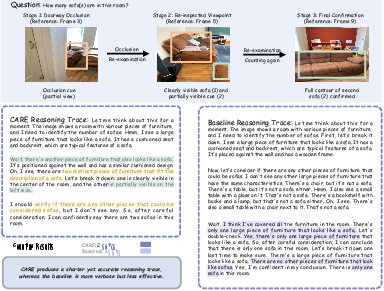
Figure 10: CARE's adaptive reasoning correctly updates object count under occlusion, outperforming static-length baselines.
Theoretical and Practical Implications
CARE establishes a principled mechanism for automatic curriculum progression in RL for multimodal reasoning. The non-stationary allocation of reasoning budget according to policy competence fundamentally resolves the mismatch in static reward strategies. Practically, CARE accelerates convergence, reduces token overhead, and strengthens both spatial-temporal and compositional reasoning in Video-MLLMs. The framework's modular reward shaping could be extended to other multimodal domains, including images, documents, and embodied settings. Further research may incorporate finer-grained adaptive controls for other computational aspects of the reasoning process.
Conclusion
CARE introduces competence-aware reward shaping for adaptive reasoning length optimization in multimodal video reasoning. By integrating stable competence estimation, stage-aware reward routing, normalized effort scoring, and posterior amplification, CARE enables dynamic transition from exploration to efficiency, improving accuracy, efficiency, and training stability. The resulting expansion-compression cycle for reasoning length, difficulty-sensitive allocation, and competence retention suggest CARE is a robust paradigm for balancing reasoning optimization with computational efficiency. Extending CARE-like signals to broader settings and more control axes represents a promising direction for future AI model training.