- The paper introduces RLER, a dual paradigm for video reasoning that decouples evidence reinforcement during training from evidence-based arbitration during inference.
- It leverages Group Relative Policy Optimization with tailored rewards to produce precise, machine-readable evidence from video frames.
- Experimental results show state-of-the-art performance, confirming improved robustness and interpretability in complex multimodal tasks.
Reinforce to Learn, Elect to Reason: A Dual Paradigm for Video Reasoning
Video reasoning with Large Multimodal Models (LMMs) has been impeded by single-pass inference strategies that neglect systematic validation of reasoning chains and lack evidential grounding. These limitations are exacerbated by the long temporal dependencies and inherent noise of video data, which magnify the risks of spurious correlations and non-robust inferences. Even state-of-the-art LMMs, including recent RL-finetuned models, typically generate an answer directly without verifying cross-frame evidence alignment. This paradigm not only complicates error detection but also impairs reliability and interpretability in contexts that require transparent, verifiable, and evidence-centric reasoning.
RLER: Dual Evidence-Centric Training and Inference
"Reinforce to Learn, Elect to Reason" (RLER) (2604.04379) introduces a dual paradigm explicitly decoupling (1) the reinforcement of evidence emission during training and (2) evidence-aligned arbitration during inference. The goal is to shape the model to produce machine-readable, structured evidence and subsequently reason by aggregating and verifying this evidence—closing the loop in a way that enhances both reliability and interpretability.
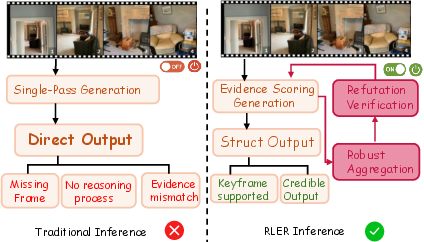
Figure 1: RLER inference contrasts with traditional single-pass inference by generating structured outputs, scoring cross-candidate evidence, aggregating by evidence weight, and performing a refutation check to return credible answers.
RLER-Training: Reward Shaping for Evidence-Centric Outputs
Training leverages Group Relative Policy Optimization (GRPO) with three core task-driven reward signals:
- Frame-sensitive Reward: Maximizes correct citation of key video frames within reasoning traces to enhance cross-frame and temporal grounding.
- Think-transparency Reward: Favors readable and parsable chains-of-thought, optimizing for interpretable and non-verbose rationales with a robust length normalization.
- Anti-repetition Reward: Penalizes n-gram repetition, increasing informational density and discouraging vacuous, low-information patterns.
These are aggregated with classic format and accuracy rewards to shape the policy toward structured, evidence-rich, and schema-compliant outputs.
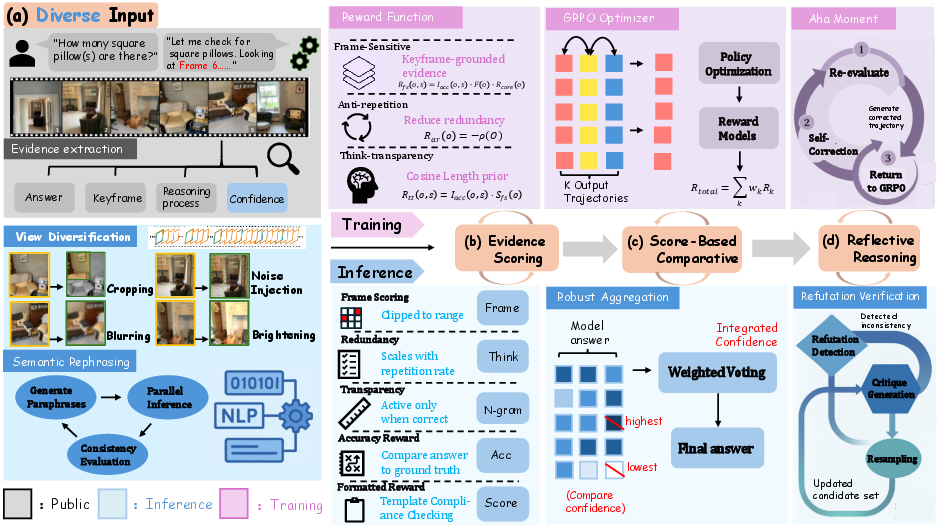
Figure 2: RLER-Training employs GRPO with novel rewards for structured evidence and explicit keyframe citation; RLER-Inference orchestrates diverse candidates, parses structure, scores evidence, aggregates, and performs refutation.
RLER-Inference: Evidence-Aligned Orchestration and Election
Inference employs a train-free orchestrator that models decision-making as an evidence-weighted election among a small, diverse set of structured candidates:
- Diversified Sampling: Candidates are generated via diverse input perturbations (e.g., decoding temperature, visual cropping).
- Evidence Parsing: Each candidate is parsed to extract answer, cited keyframes, reasoning trace, and a confidence proxy.
- Evidence Scoring: Each candidate receives a composite score reflecting frame-grounding, transparency, non-redundancy, and confidence. This mirrors the reward structuring in RLER-Training.
- Weighted Aggregation: A robust election mechanism (outlier removal, evidence-weighted scoring) selects the answer supported by the most consistent evidence. Early stopping is dynamically triggered when consensus is robust.
- Referee-style Self-Check: A final, automatic critique verifies sufficiency of frame citations; if counter-evidence is detected, reweighting and resampling are triggered.
This process integrates all forms of explicit evidence, assigning maximal influence to candidates whose reasoning aligns with cross-candidate, cross-frame evidence.
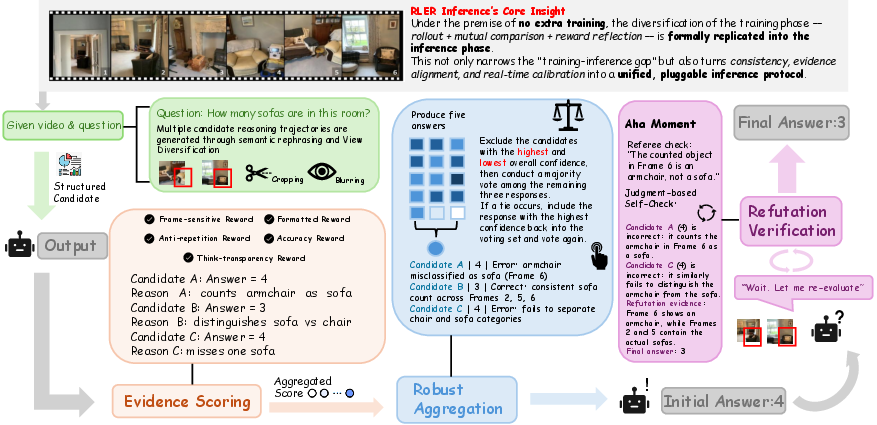
Figure 3: A case study highlights how RLER forms structured candidates from diverse inputs, scores and aggregates evidence, and verifies/refutes to revise and finalize the answer.
Emergent Behaviors and "Aha Moment"
RLER-Training induces self-correction behaviors, notable for spontaneous "aha moments" where the model internally detects inconsistencies, interrupts its chain-of-thought, and restarts reasoning. These emergent self-tests are leveraged at inference for targeted self-review, further enhancing reliability and enabling principled corrections in ambiguous or error-prone cases.

Figure 4: RLER-Training elicits emergence—the model engages in self-review and explicit correction, exemplified by internally identifying contradictions and recalibrating its hypothesis.
Experimental Results
Empirical evaluation on 8 public video reasoning benchmarks demonstrates consistent state-of-the-art performance among open-source LMMs:
- Video Reasoning: Achieves 43.3% on VSIBench and 54.2% on VideoMMMU.
- General Understanding: Notable 68.5% on VideoMME (without subtitles), 76.2% on TempCompass, and 72.9% on MVBench.
- Long Video Understanding: 50.7% on LVBench and 63.0% on LongVideoBench.
RLER's design delivers an average +6.3% improvement relative to strong LMM baselines, with a modest computational footprint (Kˉ=3.1 candidates per question), outpacing both single-sample and static multi-sample paradigms. Ablations confirm that the absence of any core reward or inference module yields measurable accuracy degradation and impairs evidence alignment.
Theoretical and Practical Implications
This evidence-aligned dual paradigm challenges the conventional end-to-end or single-chain-of-thought frameworks, suggesting that decoupling evidence production from arbitration leads to higher trustworthiness and robustness in temporally complex, multi-view reasoning domains. The RLER approach enables principled integration of diverse rationales while guaranteeing that elected answers are both interpretable and verifiable with explicit evidence trails.
The implicit link between reward shaping and arbitration further suggests extensions to other high-noise, high-complexity multimodal tasks such as scientific/medical video analysis, surveillance summarization, and interactive agent systems. The paradigm's flexibility with a given LMM backbone and its decoupled inference orchestration facilitate adoption in systems constrained by compute or requiring deployment-time adjustability.
Future Directions
Potential future work includes scaling RLER to mixed-modal (video, audio, text) tasks, integrating continual learning for evolving long-horizon contexts, and formalizing the detection and handling of emergent self-correction patterns. The self-contained, schema-guided nature of training and inference also enables straightforward integration into federated or privacy-preserving reasoning systems.
Conclusion
RLER presents a principled, evidence-centric dual-paradigm for video reasoning. By explicitly shaping structured, machine-checkable evidence during training and aggregating by that evidence at inference, RLER substantially enhances the robustness, reliability, and interpretability of LMM-based video understanding. The observed empirical improvements, efficient compute–quality tradeoff, and emergence of self-correction behaviors consolidate RLER as a technical advancement for trustworthy multimodal reasoning.

