Large Language Models Do Not Always Need Readable Language
Abstract: LLMs are commonly prompted and interfaced with human-readable natural language, even when the intended reader is another model. This paper investigates whether semantic information can be encoded in compact, non-standard textual forms that sacrifice human readability while remaining recoverable by LLMs. We refer to this class of model-centric textual representations as BabelTele, approached here not as a fixed protocol but as an empirical probe into LLMs' capacity to generate and interpret such representations. Through readability diagnostics, model likelihood measures, human questionnaires, and downstream task evaluations, we find that BabelTele can substantially depart from ordinary natural language while preserving core semantics for instruction-tuned LLMs. As a task-agnostic representational paradigm, BabelTele demonstrates high information density, maintaining 99.5% semantic fidelity even when the text volume is condensed to 27.9% of its original length. We further evaluate its semantic robustness in cross-model transfer, agent memory, and multi-agent communication. Results suggest that BabelTele can reduce context overhead while generally maintaining reliable downstream performance, although its effectiveness depends on the compressor-reader pair and task setting. These findings indicate that human readability, natural-language typicality, and model-side semantic recoverability can be partially decoupled, opening a path toward model-native representations in future exploration of LLM systems.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper explores a simple idea: when two AIs talk to each other, do they really need to use full, human-style sentences? Or can they use a short, “AI-friendly” shorthand that humans find hard to read, but AIs can still understand perfectly? The authors call this compact, model-focused way of writing “BabelTele.”
What questions were the researchers asking?
The team asked a few easy-to-understand questions:
- Can an AI pack the meaning of normal text into a much shorter, weirder-looking form that another AI can still understand?
- How much can they shrink the text while keeping the meaning?
- Do different AIs understand each other’s BabelTele, or is it like each AI having its own private code?
- Does using this compact text still let AIs do well on real tasks like answering questions, remembering information, and communicating with other AI “agents”?
- Does this save space without making the AI spend much more time “thinking” to decode it?
How did they test the idea?
The researchers tried a practical approach using everyday analogies:
- Think of natural language as a long, polite letter.
- Think of BabelTele as an ultra-condensed text message full of emojis, symbols, arrows, short words from different languages, and odd punctuation—hard for people to read, but still clear to AIs trained on huge amounts of varied text.
What they did:
- They fed long documents to an AI “compressor,” asking it to produce BabelTele (the compact version) without worrying about human readability.
- They then asked a “reader” AI to answer questions using either the original text, a normal human-readable summary, or the BabelTele version.
- They checked:
- Human readability (could people make sense of it? usually no),
- How “typical” the text looked to LLMs (BabelTele looks unusual),
- How accurate the AIs were at answering questions,
- How many tokens (pieces of text) were saved,
- And whether different AIs could understand the BabelTele produced by other models.
They also tested BabelTele in:
- Long-document question answering,
- AI “agent” memory (storing and recalling information),
- Multi-agent communication (AIs passing messages to solve tasks),
- And situations where the text is longer than a model’s input limit.
Key term explained:
- “Tokens”: tiny chunks of text that AIs read. Fewer tokens means less memory and lower cost.
- “Compression”: making the text much shorter while keeping the key ideas.
- “Chain-of-thought tokens”: the AI’s own step-by-step reasoning it writes out while solving a problem.
What did they find?
Here are the most important results:
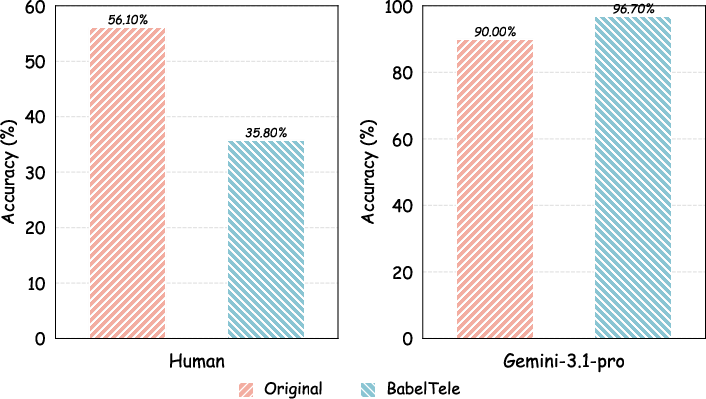
- AIs can read very compressed, weird-looking text: BabelTele looks strange to humans and doesn’t follow normal grammar, but instruction-tuned AIs can still recover the meaning and answer questions well.
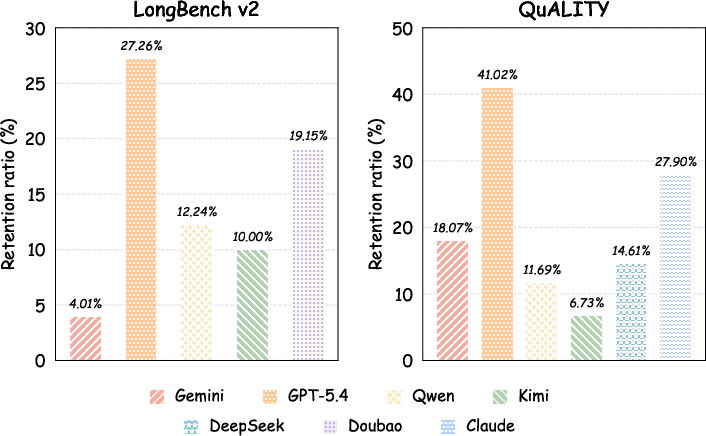
- Big shrink, tiny meaning loss: In some tests, the text was cut to about 28% of its original size while keeping about 99.5% of the meaning. That’s like turning a 10-page chapter into less than 3 pages without losing the main ideas.
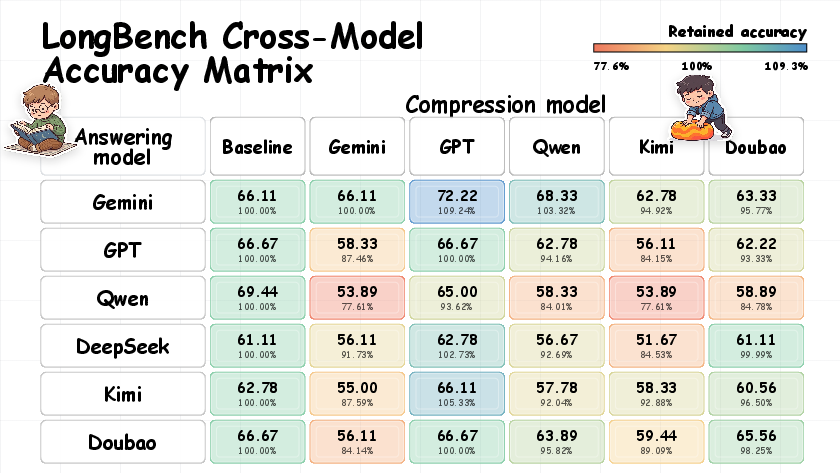
- Works across different AIs (mostly): BabelTele often transfers across different models (from one company/family to another), though success depends on which model compressed the text and which model reads it. It’s not a single “universal code,” but it’s surprisingly portable.
- Good on real tasks:
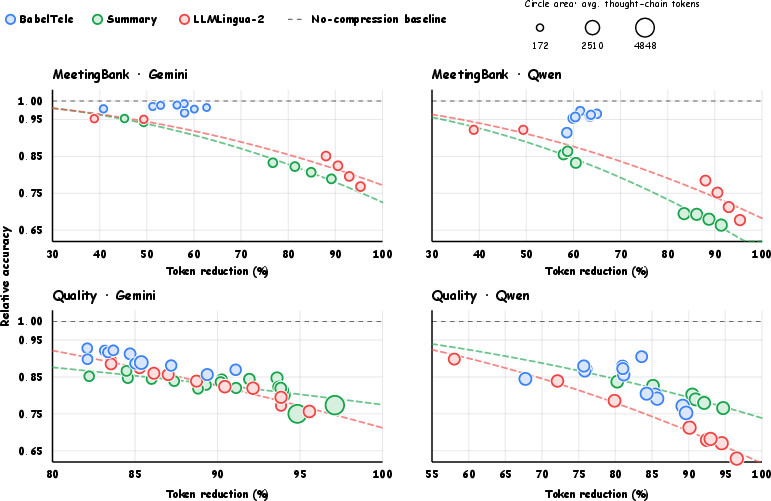
- Long-document QA: BabelTele kept higher accuracy at strong compression compared to normal summaries and a popular prompt-compression method.
- Agent memory: It reduced tokens while keeping accuracy close to the original and often better than a regular summary.
- Multi-agent chats: It cut message size a lot while keeping performance almost the same, even when two different AIs were talking.
- Over-long inputs: When documents were too long for the AI’s input limit, BabelTele helped squeeze in more important information and improved accuracy over simple truncation.
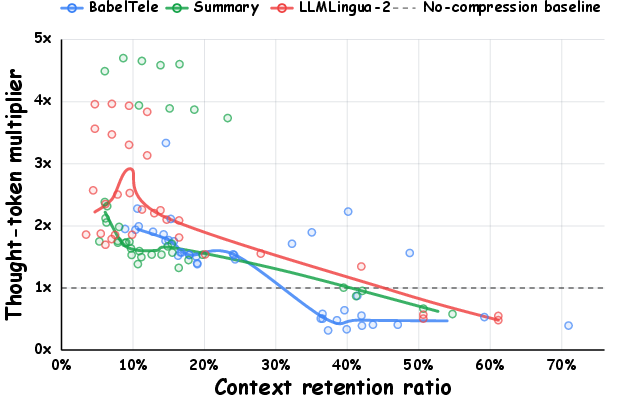
- Thinking cost is manageable: When you compress hard, AIs sometimes write slightly longer reasoning steps to reconstruct details, but BabelTele didn’t cause more “thinking” cost than normal summaries—and sometimes less.
Why this matters:
- It shows that human readability and AI understanding aren’t the same thing. AIs can understand compact, unusual text that people can’t.
- It points to a new kind of “model-native” language: short, dense, and designed for machines, not humans.
Why is this important?
- Saves space and money: Shorter text means fewer tokens—useful for long contexts, memory systems, and multi-agent teamwork.
- Helps with long documents: You can fit more key ideas into a model’s limited input window.
- Speeds up systems: Less text to pass around means faster AI pipelines, especially when many messages are exchanged.
- Opens new design possibilities: Instead of forcing everything into perfect human language, we can let AIs use their own efficient shorthand for internal steps, while still translating back to human-readable text when needed.
What are the limits and cautions?
- Not always universal: Whether BabelTele works well depends on which model creates it and which one reads it.
- Some extra reasoning: Very strong compression can make the AI think a bit more to fill in details.
- Safety concerns: Since BabelTele is hard for people to read, using it in sensitive areas (like medical or legal settings) should be done carefully to avoid hidden errors or misunderstandings.
- Early-stage idea: This is an empirical study—it shows that the phenomenon exists and is useful, but we don’t fully understand how or why AIs decode this so well.
Bottom line
The paper shows that AIs don’t always need plain, human-style sentences to understand each other. They can use a compact, mixed-symbol “shorthand” that saves lots of space while keeping meaning. This could make future AI systems more efficient, especially for long contexts, memories, and multi-agent teamwork—paving the way for model-native representations that are optimized for machines first, humans second.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of missing pieces, uncertainties, and unexplored questions that could guide future research:
- Formalization of “semantic fidelity”: How is the reported 99.5% semantic fidelity defined, measured, and validated beyond task accuracy (e.g., entailment, factual consistency, information coverage, error typology)?
- Mechanism of recoverability: Do models internally “decompress” BabelTele into natural language before reasoning, or reason directly over the symbolic form? Design controlled probes (forced paraphrase-then-answer vs. answer-only) and mechanistic analyses to test this.
- Rate–distortion theory for LLM-native text: Can we formalize an information-theoretic framework (bits per semantic unit, distortion metrics) to characterize the compression/accuracy frontier and identify optimal operating points?
- Ablations on “Principles of Symbolic Collapse”: Which components (omnilingual lexical selection vs. symbols vs. punctuation graphs) contribute most to recoverability and compression? Provide systematic ablation and controlled variants.
- Controllability of compression ratio: How can users specify or guarantee target retention/compression levels reliably across inputs and models (e.g., RLHF or decoding constraints for ratio control)?
- Tokenization confounds: Are gains robust across tokenizers? Evaluate density per byte/character and across heterogeneous tokenizers to avoid over-attributing improvements to tokenizer idiosyncrasies.
- Cross-model transfer determinants: What properties of compressor-reader pairs (training data overlap, multilingual coverage, tokenizer similarity, alignment recipe) predict transfer success/failure? Build predictive models of portability.
- Adaptive pairing and “handshake” protocols: Can compressors probe reader capabilities and adapt the symbolic form/ratio automatically for a specific reader model?
- Robustness to noise and channel errors: How tolerant is BabelTele to token drops, corruptions, or adversarial perturbations compared to natural-language summaries? Quantify graceful degradation and introduce error-correcting schemes if needed.
- Safety and policy evasion: Do BabelTele strings bypass moderation/jailbreak filters or watermarking more easily than natural language? Develop red-team evaluations and detection/mitigation tools specialized for non-standard text.
- Human auditability and governance: How can humans verify, audit, or debug opaque intermediate messages in safety-critical workflows? Explore reversible variants, dual-view outputs, or mandatory “audit trails.”
- Domain and task coverage gaps: Performance is shown for long-document QA, meetings, agent memory, and code repo QA; evaluate on math/code generation, complex planning, tool use, multimodal tasks, and low-resource/specialized domains.
- Generalization across languages/scripts: BabelTele uses cross-lingual fragments; assess reliability, bias, and fairness across languages, scripts, and culturally specific content.
- Long-horizon agent settings: Do compressed messages accumulate drift over many dialogue turns or across iterative compress–summarize cycles? Study compounding errors and stabilization mechanisms.
- Multi-agent protocol design: Beyond token savings and single-score outcomes, analyze coordination failures, miscommunication types, and the effect of role asymmetry or noisy channels in multi-agent BabelTele exchanges.
- Reader-side cost beyond token counts: Measure wall-clock latency, memory footprint, and API cost (including retries) to quantify the true runtime trade-offs of compression-induced longer reasoning chains.
- Calibration and uncertainty: Does compression increase answer overconfidence or underconfidence? Add calibration metrics (ECE/Brier) and uncertainty-aware decoding when reading BabelTele.
- Fidelity of fine-grained information: Test edge cases (dates, numbers, temporal order, negation, coreference) where lossy symbolic collapse may disproportionately harm factual precision.
- Learned compressors vs. prompt-elicited: Compare zero-shot prompting to supervised/fine-tuned compressors optimized for specific readers and tasks; study whether training stabilizes ratio control and transferability.
- Interoperability with RAG pipelines: How should BabelTele interact with retrieval, chunking, reranking, and memory stores? Evaluate end-to-end systems where compression decisions are retrieval-aware.
- Extensibility beyond text: Can analogous model-native representations be developed for multimodal inputs (images/audio) or function-call/tool outputs, and are they similarly portable across models?
- Reproducibility and moving targets: Many results rely on proprietary APIs that evolve; provide versioned artifacts and open-weight replications to ensure longitudinal comparability.
- Ethical, legal, and compliance implications: How do opaque intermediate messages impact explainability mandates, audit requirements, data provenance, and user consent in regulated domains?
- Failure analysis and diagnostics: Provide systematic error taxonomies (what information is lost, when, and why) and actionable diagnostics to detect when BabelTele becomes unsafe or unreliable.
- Security and steganography risks: Could BabelTele be exploited for covert data exfiltration or hidden instructions? Develop detectors and safe encodings that preserve oversight.
- Reader alignment dependence: How much does recoverability rely on instruction-tuning/RLHF? Benchmark base vs. instruction-tuned models and quantify the alignment’s role in decoding.
- Scaling laws that aren’t monotonic: Why does comprehension not improve monotonically with model size within a family? Identify architectural/training factors that drive non-monotonic behavior.
- Standardized benchmarks and metrics: Establish public, diverse benchmarks and shared metrics (readability, portability, fidelity, robustness, safety) to fairly compare BabelTele-style methods to natural-language compression baselines.
Practical Applications
Immediate Applications
Below are concrete, deployable applications that leverage the paper’s findings on readability-relaxed, model-native textual representations (“BabelTele”), which preserve semantics for LLMs while reducing token and bandwidth overhead.
- Context-cost reduction for RAG pipelines
- Sector: Software, search, enterprise knowledge management
- Use case: Pre-compress retrieved passages and background documents into BabelTele before insertion into the LLM’s context window to reduce API costs and fit more evidence.
- Tools/products/workflows:
- “BabelTele Context Optimizer” middleware for LangChain/LlamaIndex that compresses retrieved chunks on-the-fly.
- Tuning knobs for target compression ratio per model pair; automatic fallback to natural-language summaries on failure cases.
- Assumptions/dependencies:
- Instruction-tuned LLMs interpret BabelTele reliably; performance depends on compressor–reader pairing and compression intensity.
- Some APIs may restrict certain Unicode/symbols; sanitizer needed.
- Moderation/audit layers must auto-decompress for human review when required.
- Long-document and codebase QA within limited context windows
- Sector: Software engineering, legal, finance, research
- Use case: Fit large code repos, contracts, filings, or literature reviews into limited context by chunk-level BabelTele compression (paper shows gains on Code Repo QA Long).
- Tools/products/workflows:
- IDE plugin that pre-compresses code files and diffs for code assistants.
- Contract analysis tool that compresses clauses to preserve citations and obligations in dense form.
- Assumptions/dependencies:
- Calibrate compression ratio to avoid excessive chain-of-thought growth.
- Ensure references/anchors (e.g., function names, clause IDs) are retained or mapped for traceability.
- Memory compression for autonomous agents
- Sector: Agent frameworks, customer support, productivity assistants, gaming NPCs
- Use case: Compress episodic memory, logs, and notes to keep long-horizon context accessible without ballooning tokens (paper shows competitive accuracy on LoCoMo with ~50% tokens).
- Tools/products/workflows:
- “BabelTele Memory Compactor” for frameworks like AutoGen/CrewAI/MemGPT that stores and retrieves compressed memories.
- Heuristics to selectively expand/decompress only relevant memory spans at query time.
- Assumptions/dependencies:
- Short sessions compress less; moderate compression may be optimal.
- Safety and audit trails require reversible expansion for human inspection.
- Low-overhead multi-agent communication
- Sector: Multi-agent orchestration, ops automation, trading bots, simulations
- Use case: Replace verbose natural-language messages between agents with BabelTele to cut inter-agent tokens while preserving task performance (paper reports ~39–44% token savings with stable scores).
- Tools/products/workflows:
- “BabelBus” message bus that enforces compression of intermediate states, tool outputs, and negotiation messages, with auto-expand toggles for debugging.
- Assumptions/dependencies:
- Cross-model portability varies; establish compressor–reader whitelists and pairwise tests.
- Complex tool outputs (e.g., JSON schemas) should not be compressed arbitrarily; compress only free-text payloads.
- API cost and latency optimization for production LLM services
- Sector: SaaS, customer support, analytics, productivity suites
- Use case: Compress system prompts, FAQs, and long user histories to reduce token spend and latency while maintaining answer quality.
- Tools/products/workflows:
- A gateway that compresses context for model-facing calls and expands content for any human-facing logs.
- Dynamic control: adapt compression ratio based on current context length or cost budget.
- Assumptions/dependencies:
- Monitor chain-of-thought token growth to avoid negating input savings.
- Ensure compliance by keeping human-readable audit logs via on-demand decompression.
- Heterogeneous model collaboration in ensemble/cascade systems
- Sector: MLOps, model routing, evaluation
- Use case: Compress intermediate outputs from a “planner” model for downstream “solver” models of different vendors to reduce cross-call payloads.
- Tools/products/workflows:
- “Pairwise Compatibility Profiler” that benchmarks compressor–reader pairs and selects prompts/ratios with best retention.
- Assumptions/dependencies:
- Portability depends on compressor; more aggressive compressors can degrade decoding for some readers.
- Non-monotonic relation with model size; bigger is not always better—profile each pair.
- Bandwidth-efficient background messaging on edge and low-connectivity setups
- Sector: IoT, mobile, robotics, field operations
- Use case: Transmit compressed LLM instructions/state updates from cloud to on-device models with small contexts and limited bandwidth.
- Tools/products/workflows:
- Edge agent SDK that receives BabelTele messages and locally expands or directly reasons over them.
- Assumptions/dependencies:
- Unicode handling and tokenizer support must be robust on-device.
- Safety filters should operate on expanded messages for human oversight when necessary.
- Governance-aware logging and moderation pipelines
- Sector: Compliance, trust & safety, auditing
- Use case: Because BabelTele is less human-readable, deploy automatic expansion for logging, monitoring, and content moderation; flag un-decodable segments.
- Tools/products/workflows:
- “Decode-for-Moderation” step in the inference pipeline before storage or human review.
- Assumptions/dependencies:
- Avoid using BabelTele to bypass moderation or transparency requirements; institute policy that all compressed content must be decodable for audit.
- Research and teaching aids for compression and LLM robustness
- Sector: Academia, model evaluation
- Use case: Use BabelTele as a probe for decoupling human readability from model decodability; stress-test cross-model transfer and context efficiency.
- Tools/products/workflows:
- Open-source “BabelTeleEval” benchmark suite with accuracy–retention curves and chain-of-thought overhead metrics.
- Assumptions/dependencies:
- Comparison baselines (summaries, extractive compression) should be matched on token budgets for fair evaluation.
Long-Term Applications
These opportunities are promising but will require further research, scaling, standardization, or productization beyond the paper’s current experimental scope.
- Standardized model-native encoding protocols
- Sector: Software, interoperability, standards bodies
- Vision: Define open “LLM-to-LLM telegraphic” formats with versioning, symbol sets, and compliance suites to improve cross-model decodability.
- Potential products:
- Interop layer for multi-vendor model fleets; compressors tuned to target a shared core dialect.
- Assumptions/dependencies:
- Community agreement on symbol handling, Unicode ranges, and safety rules.
- Vendor cooperation and certification processes.
- Learned compressors trained for BabelTele-like semantics
- Sector: ML systems, foundation models
- Vision: Train compressors (e.g., in-context autoencoders or RL-tuned generators) to optimize accuracy–retention and minimize reasoning overhead, yielding robust, portable encodings.
- Potential products:
- Task/domain-specialized compressors (legal, medical, code) with guaranteed fidelity.
- Assumptions/dependencies:
- Access to training data and evaluation harnesses; alignment to avoid harmful obfuscation.
- Black-box compatibility (no reliance on hidden states for general applicability).
- Safety, transparency, and audit standards for obfuscated AI communication
- Sector: Policy, regulation, compliance engineering
- Vision: Policies that require auto-decompression for human auditors; rules on when model-native encodings are allowed (e.g., disallowed in safety-critical human-facing outputs).
- Potential tools:
- Auditable logs guaranteeing reversible expansion; cryptographic attestations of faithful decompression.
- Assumptions/dependencies:
- Broad stakeholder buy-in; defined risk tiers per domain (healthcare, aviation, finance).
- Tokenizer and hardware co-design for symbolic encodings
- Sector: AI hardware, runtime optimization
- Vision: Tokenizers and kernels optimized for common BabelTele patterns to reduce token counts and latency further (e.g., multichar symbols mapped to single tokens).
- Potential products:
- “Dense-symbol” tokenizer packs; inference runtimes exploiting structured symbolic patterns.
- Assumptions/dependencies:
- Backward compatibility with existing models; retraining or adaptation layers as needed.
- Privacy-preserving, machine-preferrable storage for organizational knowledge
- Sector: Enterprise knowledge management, security
- Vision: Store corpora in compact, less-human-readable but machine-decodable form to lower storage/egress costs and reduce casual human exposure to sensitive data.
- Potential products:
- Encrypted + model-decodable archives with on-demand expansion keys and audit trails.
- Assumptions/dependencies:
- Clear safeguards so compression isn’t misused as security-by-obscurity; robust key management and access controls.
- Agent-swarm protocols and semantic streaming
- Sector: Robotics, simulations, logistics, AIOps
- Vision: Telemetric “semantic packets” transmitted as BabelTele streams for coordination among many agents (e.g., fleet management, multi-robot planning).
- Potential products:
- Low-bandwidth agent buses with QoS tiers and reliability checks (CRC-like semantics for decode success).
- Assumptions/dependencies:
- Real-time decode performance; graceful degradation when decoding confidence drops.
- Curriculum and pretraining leveraging compressed semantics
- Sector: Foundation model training, education tech
- Vision: Pretrain/fine-tune models on mixtures of natural language and BabelTele to build stronger internal mappings between dense symbols and semantics; improve long-context reasoning.
- Potential products:
- Dual-dialect models that natively “think” in compressed form and “speak” fluently when needed.
- Assumptions/dependencies:
- Data generation pipelines for high-quality compressed corpora; careful alignment to avoid degraded human communication skills.
- Robust detection and mitigation tools for obfuscated harmful content
- Sector: Safety, platform integrity
- Vision: Build detectors that identify BabelTele-like text and automatically decode or flag for enhanced scrutiny to prevent filter evasion.
- Potential products:
- “Obfuscation-aware” moderation services; decode-before-filter pipelines.
- Assumptions/dependencies:
- Reliable detection despite evolving encodings; minimal false positives on legitimate compressed traffic.
- Domain-certified compressors for safety-critical sectors
- Sector: Healthcare, aviation, finance, legal
- Vision: Compressors validated to preserve mandated information categories (e.g., clinical findings, risk factors, fiduciary disclosures) with measurable fidelity and error bounds.
- Potential products:
- Regulated BabelTele profiles with coverage checklists; conformance tests and monitoring dashboards.
- Assumptions/dependencies:
- Rigorous, domain-specific evaluations; liability and compliance frameworks for failures.
- Human–AI collaboration UIs with semantic “zoom”
- Sector: Productivity, BI, analytics
- Vision: Interfaces that display compressed, model-native representations for machine workflows, with instant “zoom to natural language” for human oversight.
- Potential products:
- Toggleable views in dashboards and IDEs; provenance links from compressed snippets to original evidence.
- Assumptions/dependencies:
- Fast, faithful, and explainable decompression; UX research to balance efficiency with transparency.
These applications rest on core findings from the paper: (1) LLMs can decode compact, non-natural language surface forms with high semantic fidelity; (2) compression improves the accuracy–retention frontier versus standard summaries/extractive methods in several settings; (3) chain-of-thought overhead doesn’t uniquely penalize BabelTele; and (4) cross-model portability exists but depends on compressor–reader pairing and compression aggressiveness. Implementations should therefore include guardrails: pairwise profiling, moderate compression targets, decode-for-audit paths, and safety/compliance checks.
Glossary
- Accuracy-retention frontier: The trade-off curve showing how task accuracy changes as less of the original context is retained after compression. Example: "BabelTele forms a more favorable accuracy-retention frontier across multiple benchmarks and reader models."
- Activation-based representations: Encodings derived from a model’s internal activations rather than surface text, often requiring special access to the model. Example: "A separate line of work explores activation-based or learned internal representations"
- Abstractive prompt compression: Compressing prompts by generating concise summaries or rephrasings rather than selecting/deleting original tokens. Example: "Other work studies abstractive or natural-language prompt compression"
- Agent memory: The stored, structured memory that agentic LLM systems use to carry information across steps or sessions. Example: "agent memory, and multi-agent communication."
- Agentic systems: LLM-driven setups where models act as agents with planning, memory, or tool use across steps. Example: "long-context and agentic systems"
- BabelTele: A model-centric, high-density textual representation that deprioritizes human readability while remaining interpretable by LLMs. Example: "We refer to this class of model-centric textual representations as BabelTele"
- Black-box API settings: Scenarios where only input-output access to a model is available, with no access to internals or gradients. Example: "black-box API settings and heterogeneous model ecosystems."
- Chain-of-thought tokens: Tokens in an LLM’s generated reasoning steps, used as a proxy for inference effort. Example: "reader chain-of-thought token overhead"
- Compression ratio: The degree to which text is reduced in length relative to the original, typically expressed as a percentage. Example: "evaluating it across multiple dimensions including compression ratio, semantic fidelity, human readability, cross-model transferability, and downstream utility"
- Context overhead: Excess context tokens that increase cost or burden without proportionate task benefit. Example: "context overhead is a persistent bottleneck."
- Context retention ratio: The fraction of original context tokens that are kept after compression. Example: "under different context retention ratios"
- Context window: The maximum number of tokens a model can process in a single input. Example: "when the original input exceeds the model context window"
- Cross-model portability: The ability of compressed representations to be used effectively by different models without specialized adaptation. Example: "we evaluate its cross-model portability across state-of-the-art LLMs."
- Cross-model transferability: The degree to which compressed representations from one model remain decodable and useful to other models. Example: "BabelTele exhibits robust cross-model transferability across diverse proprietary and open-weight model families in a zero-shot manner."
- Dale-Chall score: A readability metric based on a list of familiar words; higher values indicate harder text. Example: "with a Dale-Chall score of 16.70"
- Downstream tasks: End tasks (e.g., QA, retrieval, memory) used to evaluate the utility of representations or methods. Example: "downstream task evaluations"
- Few-shot generalization: The capability of LLMs to perform tasks from a few examples provided in the prompt. Example: "GPT-3 demonstrated strong few-shot generalization through text-based prompting"
- Hidden states: Internal model activations that represent intermediate computations across layers or time steps. Example: "access to hidden states"
- Information-theoretic view: Analyzing communication or modeling through information theory concepts like channel capacity and efficiency. Example: "From an information-theoretic view, communication systems aim to transmit information efficiently under channel constraints"
- Instruction-tuned: Refers to LLMs fine-tuned to follow natural-language instructions reliably. Example: "instruction-tuned LLMs"
- Instructional probes: Purpose-designed prompts that elicit specific behaviors to study or induce certain representations. Example: "we design instructional probes that encourage the compressor C to produce model-readable encodings"
- LongBench v2: A benchmark suite focusing on long-context understanding and evaluation. Example: "LongBench v2"
- Long-context benchmarks: Evaluations involving lengthy inputs that test models’ ability to use extended context. Example: "across multiple long-context benchmarks under a task-agnostic protocol"
- MeetingBank: A dataset of meeting transcripts used for long-context QA and analysis. Example: "MeetingBank"
- Model-native representations: Representations optimized for LLM consumption and decoding rather than human readability. Example: "opening a path toward model-native representations in future exploration of LLM systems."
- Multi-agent communication: Message passing between multiple LLM agents collaborating on tasks. Example: "multi-agent communication."
- Natural-language typicality: How likely a text is under standard natural-language distributions (fluency and norm adherence). Example: "human readability, natural-language typicality, and model-side semantic recoverability can be partially decoupled"
- Perplexity (PPL): A language-model likelihood metric; lower PPL indicates higher predicted probability of text. Example: "yielding order-of-magnitude higher PPL than both original and summary texts."
- Readability diagnostics: Measurements assessing how easy text is for humans to read and understand. Example: "Through readability diagnostics"
- Readability-relaxed semantic projection: Formulating compression by de-emphasizing human readability while preserving meaning for model decoding. Example: "BabelTele formulates compression as a readability-relaxed semantic projection."
- Selective Context: A prompt-compression method that filters tokens or sentences by their information content. Example: "Selective Context filters tokens or sentences according to self-information."
- Self-information: The information content of a token, often measured as the negative log-probability under a model. Example: "according to self-information."
- Semantic density: The amount of meaning conveyed per unit of text; higher density means more meaning in fewer tokens. Example: "these properties are valuable for human readers, but they reduce semantic density."
- Semantic fidelity: The degree to which the original meaning is preserved after transformation or compression. Example: "maintaining 99.5% semantic fidelity"
- Semantic recoverability: The ability of a model to reconstruct or infer the intended meaning from a compressed form. Example: "model-side semantic recoverability"
- Symbolic collapse: Replacing verbose language with compact symbols or cross-lingual cues to increase density. Example: "Symbolic Collapse: Replacing verbose linguistic structures with compact symbols, emojis, mathematical/logical operators, and punctuation."
- Token budget: The available token capacity for inputs and/or outputs under model or cost constraints. Example: "under similar token budgets"
- Tokenizer modifications: Changes to the tokenization scheme or vocabulary to alter how text is segmented. Example: "no gradient updates or tokenizer modifications"
- Zero-shot cross-model comprehension: The ability of models to understand compressed inputs produced by other models without any joint training. Example: "A Universal Cipher? Zero-Shot Cross-Model Comprehension"
- Zero-shot prompting: Prompting a model without providing task-specific examples or fine-tuning. Example: "through zero-shot prompting"
Collections
Sign up for free to add this paper to one or more collections.

