- The paper introduces four novel evaluation environments to objectively measure LLMs' ability to use subtext in both social games and story-level tasks.
- It finds that even state-of-the-art models default to literal expression, with explicit common ground significantly boosting implicit, nuanced communication.
- The study highlights practical limitations in theory-of-mind and pragmatic reasoning, emphasizing the need for improved training data and benchmarks for subtextual interaction.
Systematic Evaluation of Subtextual Communication in LLMs
Introduction
This work addresses the quantification of subtextual communication capacities in LLMs, a pivotal aspect of human creative communication frequently missing from computational approaches. The authors introduce four novel evaluation environments to dissect model abilities both in controlled social communication games and in story-level generative/interpretive tasks that critically hinge on implied meaning, audience modeling, and shared knowledge. Emphasis is placed on scenarios inspired by Dixit and Wavelength, establishing both multi-agent and multi-modal contexts, and tasks targeting allegorical understanding and generation. The analysis demonstrates a recurrent bias towards literalness across state-of-the-art models and quantifies both the limits and the nascent social reasoning evident in leading LLMs. The research connects deficits in subtextual communication to weaknesses in theory-of-mind and pragmatic reasoning, and explores ramifications for LLM-driven multi-agent interaction and creative generation.
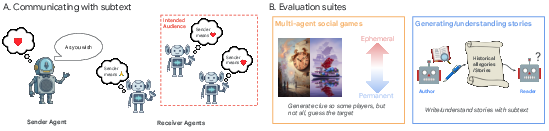
Figure 1: Evaluation protocol for subtextual communication, illustrating both schematic and environment structure for multi-agent creativity tasks in LLMs.
Evaluation Environments and Methodologies
Multi-Agent Communication Games
A unifying formalism is developed wherein an active LLM agent communicates an intent to a subset of receiver agents via an utterance. The sender/receiver mapping and presence or explicit signal of common ground (private shared context) are manipulable variables. Two principal environments are constructed:
- Visual Allusions: Inspired by Dixit, LLM agents must express an intent (select a target image) such that only a subset of receivers selects the same referent based on a generated clue. Scores integrate selectivity of communication, and generated clues are classified as obvious, obscure, or just-right. Image cards are produced with Imagen 4.
- Attuned: Modeled on Wavelength, teams of LLMs communicate their position along an abstract spectrum (e.g., Ephemeral–Permanent) using natural language clues, with scoring tied to selectivity and team-based inference of the sender's position.
Both environments are instantiated with leading foundation models: Gemini-2.5-Pro/Flash, Gemma-3-27B, multiple GPT-5 variants, and Claude-Haiku/Sonnet-4.5.
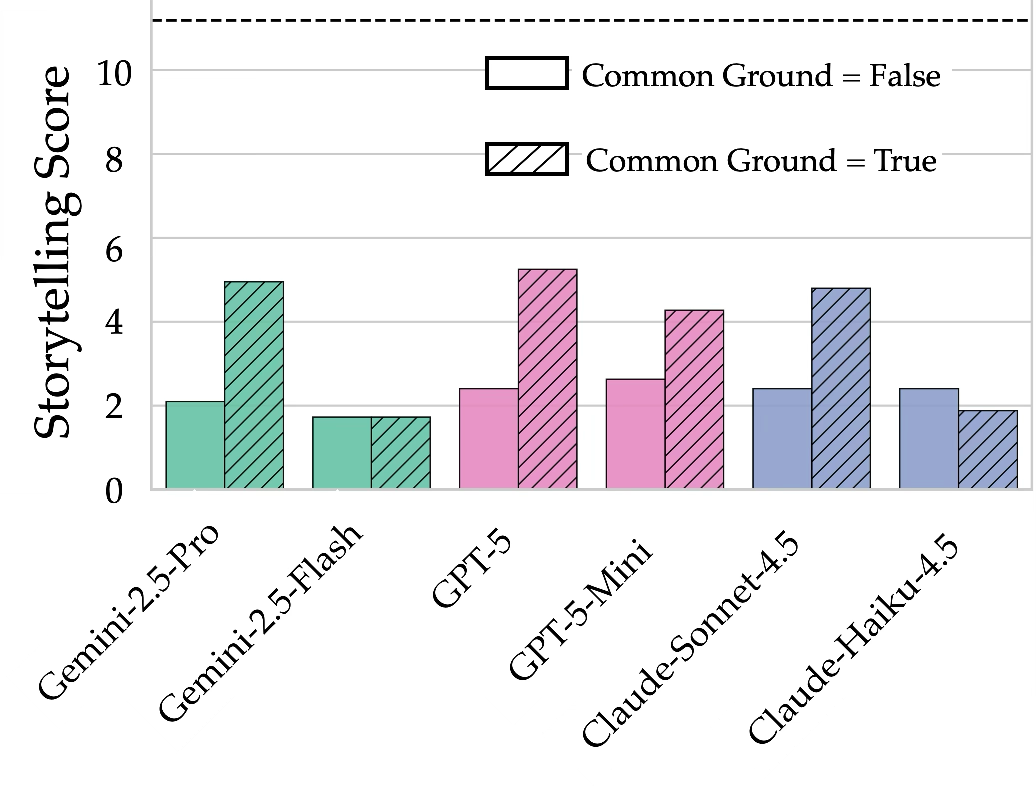
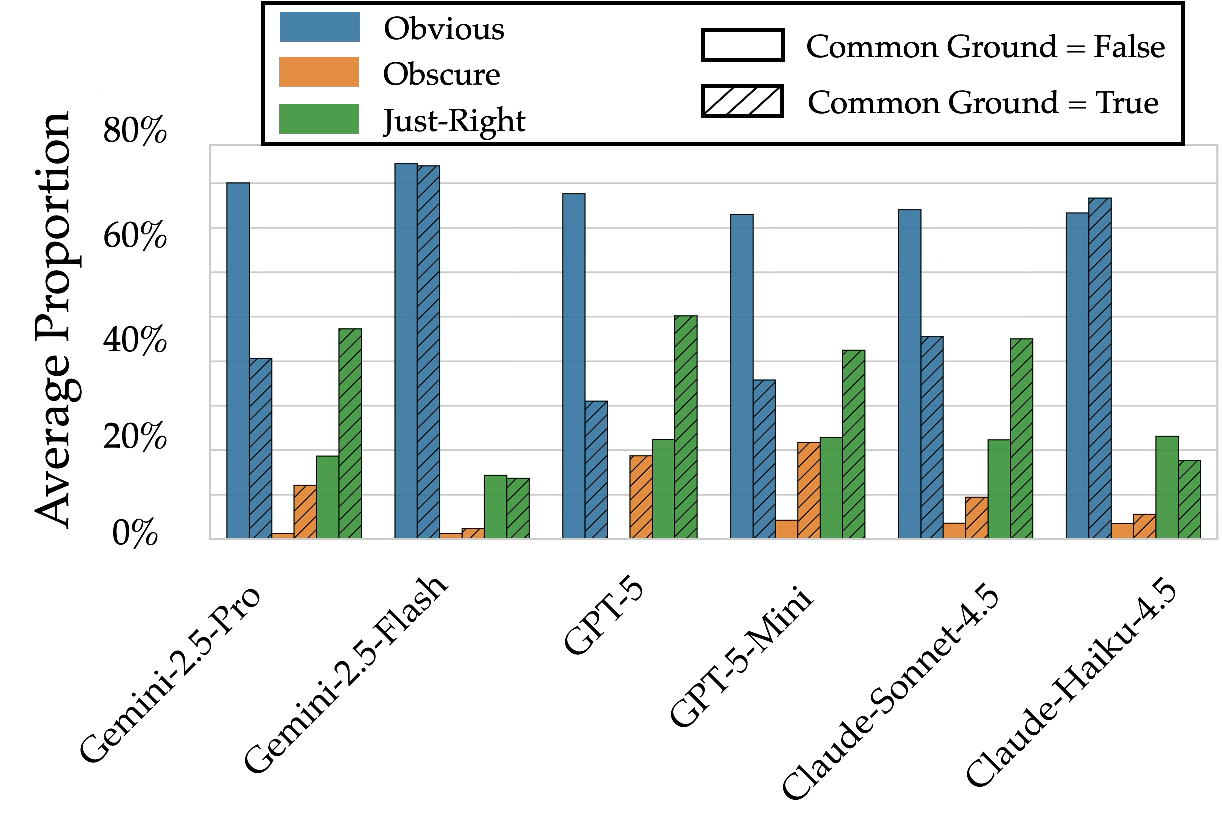
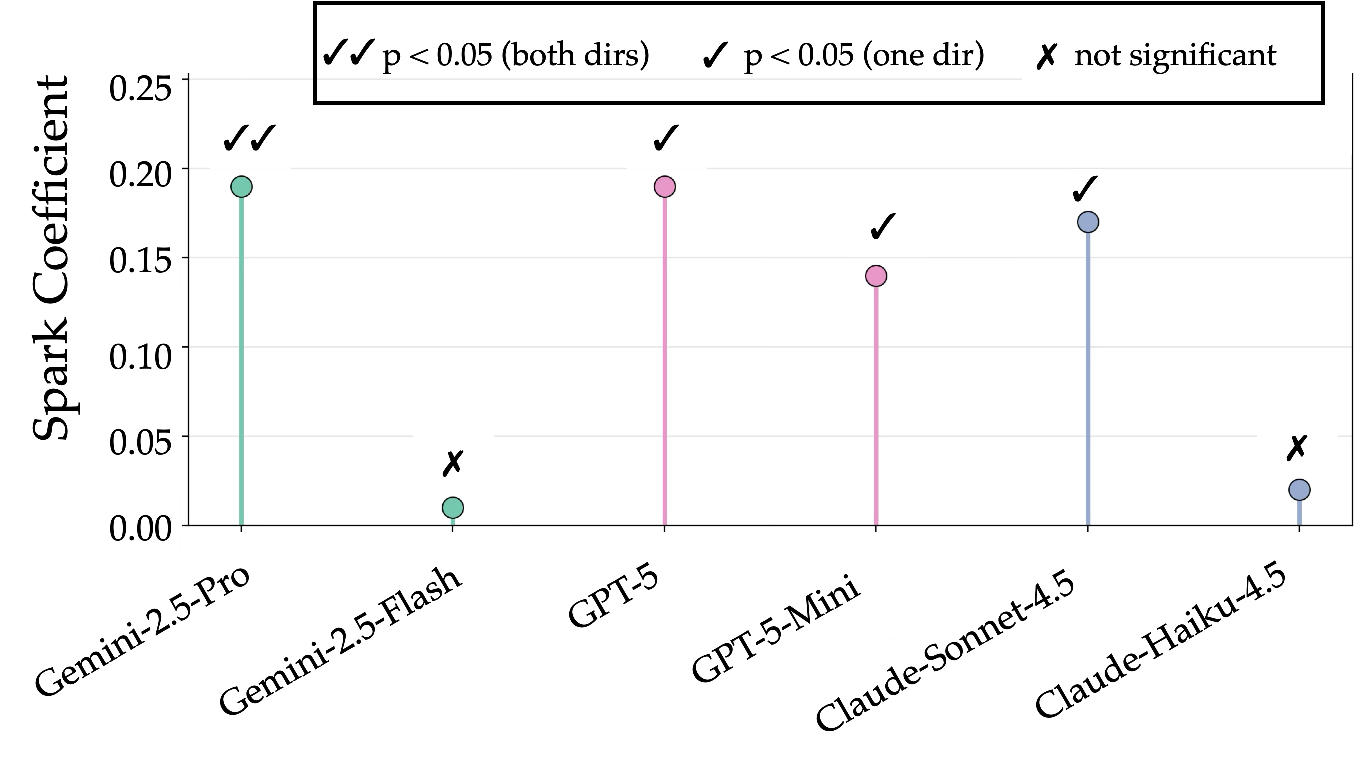
Figure 2: Quantitative storytelling/communication selectivity scores for evaluated models across environments.
Story Encoding and Interpretation
Two further evaluation suites are introduced to target longer-context, high-dimensional subtext operations:
- Historical Allegories: Synthetic allegories (short stories with subtext linking to specific historical events) are generated and models must recover the referenced event under various persona and context manipulations (critic, historian, deep reader) and author/reader biographical information conditions.
- The Aesopian Author: An LLM is tasked with generating stories that signal a “banned” topic to a sympathetic critic but are interpreted as innocuous by a censorious inquisitor—demanding deep pragmatic subtext generation and audience modeling.
Key Empirical Findings
Pervasiveness of Literalness: Across environments, even frontier LLMs default to literal, explicit communication in the majority of instances. For Visual Allusions, Gemini-2.5-Pro produces obvious clues ≈60% of the time; for most models, the fraction of “just-right” subtextual utterances clusters in the 22-39% range, substantially below upper bounds for the task.
Selective Communication with Stated Common Ground: When a common ground is made explicit (i.e., agents are told about their mutual private context), the rate of just-right/implicit communication rises markedly (up to a ~50% reduction in obvious clues). Notably, models fail to reliably infer the presence of shared knowledge when it is not provided explicitly, yielding low “Awareness” scores even when some subtextual clues are incidentally generated.







Figure 3: Example of an “obvious” clue generated in Visual Allusions by Gemma-3-27B, reflecting literal description rather than subtextual indirection.







Figure 4: Representative “obvious” clue from GPT-5-mini, direct rather than leveraging common ground or ambiguity.
Theory of Mind and Pragmatic Reasoning Gaps: Neither Attuned/Wavelength nor Visual Allusions indicate robust recursive reasoning over listeners’ beliefs. Selective communication (preferring one’s teammate) is successful only in approximately a third of cases across leading models—further emphasizing pragmatic deficits. Performance improvements, when present, track closely with model scale and architectural sophistication, not with explicit mechanisms for ToM.
Subtext in Long-Form Generation and Interpretation: The Historical Allegories task reveals that persona and paratextual cues (e.g., author background, reader identity) dramatically shift model interpretation accuracy (e.g., Gemini-2.5-Pro rises from 26% to 73% correct with informative cues). These paratext effects mirror classic findings from literary pragmatics.
Difficulty of Authentic Aesopian Generation: In adversarial author–critic–inquisitor setups, even the best models achieve limited success (GPT-5: ~22% games meeting the subtextual dual-intent criterion). Success requires information asymmetry exploitation and multi-step planning, with most failures arising from being too on-the-nose, resulting in detection by the inquisitor agent.



Figure 5: Example of a successful collaborative subtextual clue (Gemini-2.5-Pro in common ground setting) in Visual Allusions—rare but illustrative of potential when models exploit shared context.
Theoretical and Practical Implications
The empirical results position subtext as a rigorous, quantifiable target for evaluating model pragmatics, communication selectivity, and theory of mind in multi-agent LLM deployments. The demonstrated gaps have several salient implications:
- Social Reasoning Bottlenecks: The overt reliance on explicit clues and the inability to effectively accumulate or infer common ground constrains LLM suitability for applications demanding nuanced audience-dependent communication, such as negotiation, deception-resistance, and collaborative creative tasks.
- Design for Future Benchmarks and Training: Sufficient training data for implicit, interpersonal subtextual signaling is rare; control tasks described here open the possibility of more functionally valid, less annotation-intensive theory-of-mind and pragmatic reasoning benchmarks.
- Dual-Use Considerations: Advancements in this axis also constitute “dual-use” risks (enabling covert or selective communication, steganography, and possible jailbreak circumvention), underscoring the import of monitoring and careful capability deployment.
Limitations and Prospective Research Directions
Key limitations of the present framework include reliance on explicitly signaled subtext goals, lack of human baseline comparison, and exclusion of the latest released models post-experimentation. There is a clear need for work that tests the spontaneous emergence of subtextual strategies when goals are implicit or indirect. Mechanistic interpretability analyses are also warranted to clarify internal audience-modeling representations. Interaction with humans and integration with richer simulation platforms will likely provide stronger ecological validity.
Conclusion
This work establishes a paradigm for rigorous and automatic measurement of creative subtextual communication in LLMs, reveals systematic biases toward explicitness, and quantifies both the progress and significant remaining gaps in scalable social and creative intelligence modeling. Advances in audience adaptation, common ground inference, and pragmatic selectivity are necessary prerequisites for LLMs to approximate the depth and subtlety of human communicative creativity.
Reference: "Beneath the Surface: Investigating LLMs' Capabilities for Communicating with Subtext" (2604.05273)

