Secrets of RLHF in Large Language Models Part II: Reward Modeling
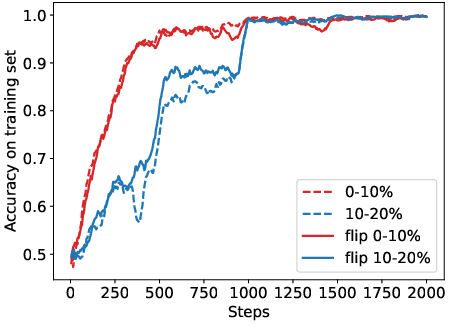
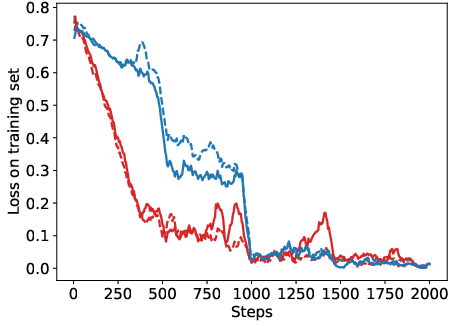
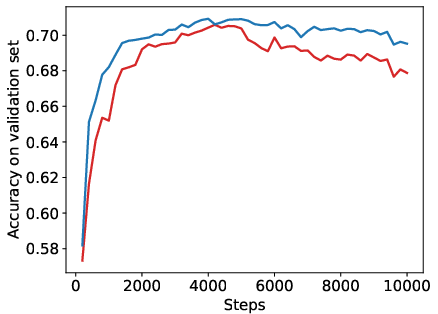
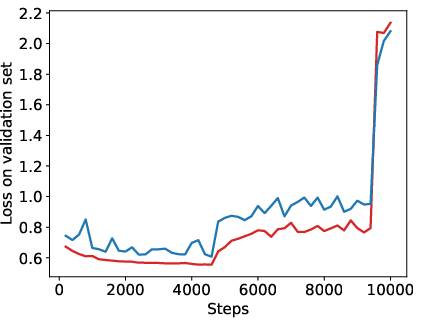
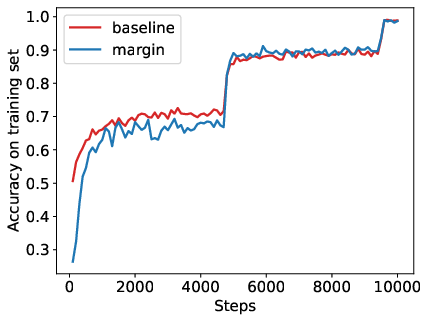
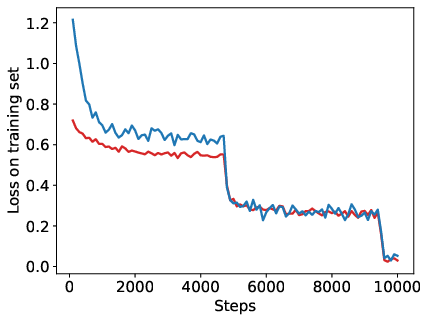
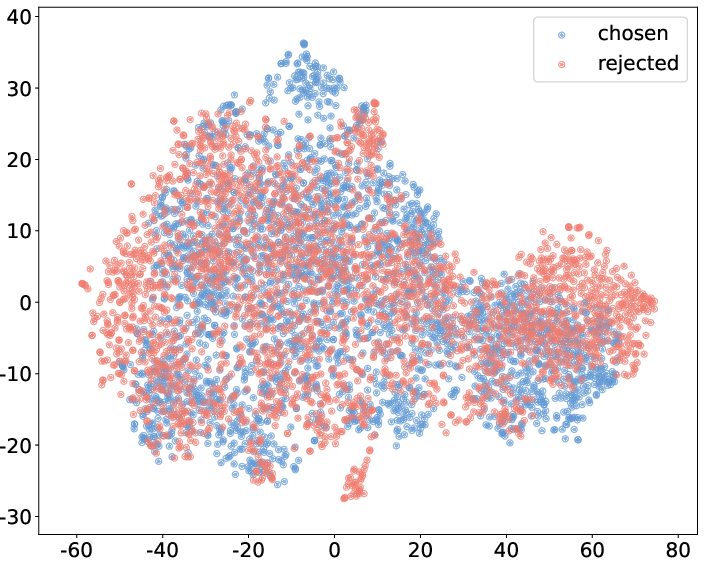
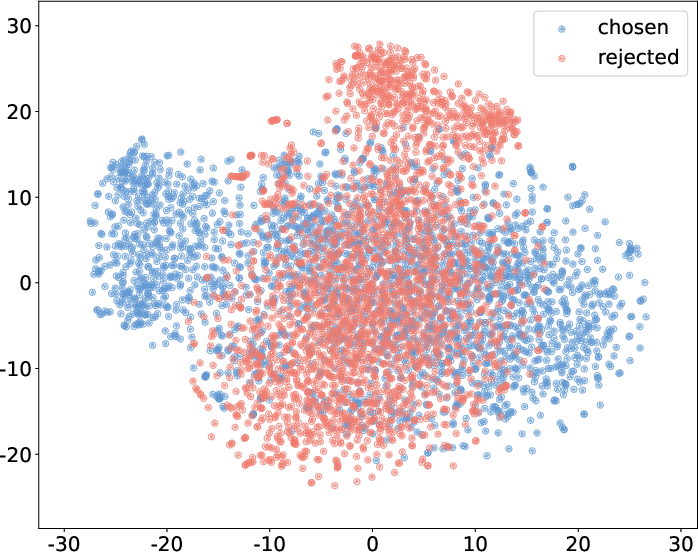
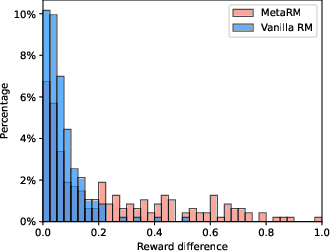
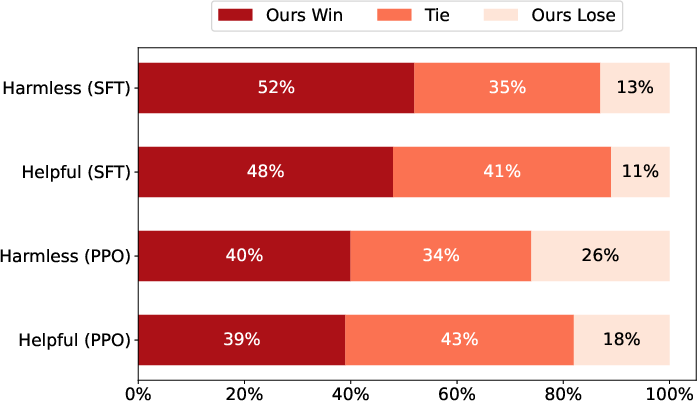
Abstract: Reinforcement Learning from Human Feedback (RLHF) has become a crucial technology for aligning LLMs with human values and intentions, enabling models to produce more helpful and harmless responses. Reward models are trained as proxies for human preferences to drive reinforcement learning optimization. While reward models are often considered central to achieving high performance, they face the following challenges in practical applications: (1) Incorrect and ambiguous preference pairs in the dataset may hinder the reward model from accurately capturing human intent. (2) Reward models trained on data from a specific distribution often struggle to generalize to examples outside that distribution and are not suitable for iterative RLHF training. In this report, we attempt to address these two issues. (1) From a data perspective, we propose a method to measure the strength of preferences within the data, based on a voting mechanism of multiple reward models. Experimental results confirm that data with varying preference strengths have different impacts on reward model performance. We introduce a series of novel methods to mitigate the influence of incorrect and ambiguous preferences in the dataset and fully leverage high-quality preference data. (2) From an algorithmic standpoint, we introduce contrastive learning to enhance the ability of reward models to distinguish between chosen and rejected responses, thereby improving model generalization. Furthermore, we employ meta-learning to enable the reward model to maintain the ability to differentiate subtle differences in out-of-distribution samples, and this approach can be utilized for iterative RLHF optimization.
First 10 authors:
- Scalable agent alignment via reward modeling: a research direction, 2018.
- Alignment of language agents. arXiv preprint arXiv:2103.14659, 2021.
- The rise and potential of large language model based agents: A survey. arXiv preprint arXiv:2309.07864, 2023.
- Training language models to follow instructions with human feedback. Advances in Neural Information Processing Systems, 35:27730–27744, 2022.
- Training a helpful and harmless assistant with reinforcement learning from human feedback. arXiv preprint arXiv:2204.05862, 2022.
- Constitutional AI: Harmlessness from AI feedback, 2022.
- Specific versus general principles for constitutional ai. arXiv preprint arXiv:2310.13798, 2023.
- The history and risks of reinforcement learning and human feedback. arXiv e-prints, pages arXiv–2310, 2023.
- Pitis, S. Failure modes of learning reward models for llms and other sequence models. In ICML 2023 Workshop The Many Facets of Preference-Based Learning. 2023.
- On the fragility of learned reward functions. arXiv preprint arXiv:2301.03652, 2023.
- Characterizing the impacts of instances on robustness. In Findings of the Association for Computational Linguistics: ACL 2023, pages 2314–2332. 2023.
- Learning to summarize from human feedback. CoRR, abs/2009.01325, 2020.
- Fine-tuning language models from human preferences. CoRR, abs/1909.08593, 2019.
- Improving alignment of dialogue agents via targeted human judgements. CoRR, abs/2209.14375, 2022.
- Proximal policy optimization algorithms. CoRR, abs/1707.06347, 2017.
- Rank analysis of incomplete block designs: I. the method of paired comparisons. Biometrika, 39(3/4):324–345, 1952.
- Way off-policy batch deep reinforcement learning of implicit human preferences in dialog. CoRR, abs/1907.00456, 2019.
- Preventing reward hacking with occupancy measure regularization. In ICML Workshop on New Frontiers in Learning, Control, and Dynamical Systems. 2023.
- Training deep neural networks on noisy labels with bootstrapping. arXiv preprint arXiv:1412.6596, 2014.
- When does label smoothing help? In H. M. Wallach, H. Larochelle, A. Beygelzimer, F. d’Alché-Buc, E. B. Fox, R. Garnett, eds., Advances in Neural Information Processing Systems 32: Annual Conference on Neural Information Processing Systems 2019, NeurIPS 2019, December 8-14, 2019, Vancouver, BC, Canada, pages 4696–4705. 2019.
- Llama 2: Open foundation and fine-tuned chat models. CoRR, abs/2307.09288, 2023.
- Secrets of rlhf in large language models part i: Ppo. arXiv preprint arXiv:2307.04964, 2023.
- Unsupervised learning of visual features by contrasting cluster assignments. Advances in neural information processing systems, 33:9912–9924, 2020.
- Simcse: Simple contrastive learning of sentence embeddings. arXiv preprint arXiv:2104.08821, 2021.
- Training a helpful and harmless assistant with reinforcement learning from human feedback. CoRR, abs/2204.05862, 2022.
- Deep reinforcement learning from human preferences. Advances in neural information processing systems, 30, 2017.
- A survey of reinforcement learning from human feedback. arXiv preprint arXiv:2312.14925, 2023.
- On the sensitivity of reward inference to misspecified human models. arXiv preprint arXiv:2212.04717, 2022.
- Models of human preference for learning reward functions. arXiv preprint arXiv:2206.02231, 2022.
- Open problems and fundamental limitations of reinforcement learning from human feedback. arXiv preprint arXiv:2307.15217, 2023.
- Towards understanding sycophancy in language models. arXiv preprint arXiv:2310.13548, 2023.
- Evaluating and mitigating discrimination in language model decisions. arXiv preprint arXiv:2312.03689, 2023.
- Fine-tuning language models from human preferences. arXiv preprint arXiv:1909.08593, 2019.
- Improving generalization of alignment with human preferences through group invariant learning. arXiv preprint arXiv:2310.11971, 2023.
- Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288, 2023.
- Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality, 2023.
- Tl; dr: Mining reddit to learn automatic summarization. In Proceedings of the Workshop on New Frontiers in Summarization, pages 59–63. 2017.
- Openassistant conversations–democratizing large language model alignment. arXiv preprint arXiv:2304.07327, 2023.
- The curious case of neural text degeneration, 2020.
- High-dimensional continuous control using generalized advantage estimation, 2018.
- A survey on evaluation of large language models. arXiv preprint arXiv:2307.03109, 2023.
- Judging llm-as-a-judge with mt-bench and chatbot arena. arXiv preprint arXiv:2306.05685, 2023.
- Self-polish: Enhance reasoning in large language models via problem refinement. arXiv preprint arXiv:2305.14497, 2023.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.

