Freeing the Law with LOCUS: A Local Ordinance Corpus for the United States
Abstract: Progress in legal AI increasingly depends on access to authoritative legal text at scale. Yet one of the most consequential layers of American law remains largely absent from existing machine-readable corpora: local ordinances. Local codes govern zoning, housing, business licensing, public health, noise, animal control, and many other domains of everyday regulation, but they are fragmented across vendor platforms designed for human browsing rather than bulk research access. We introduce LOCUS - the Local Ordinance Corpus for the United States - a comprehensive corpus and county-harmonized access layer for U.S. municipal and county ordinance codes. The raw corpus, available for release to researchers, represents nearly all publicly available municipal and county ordinance codes. The resulting raw corpus contains codes from 9,239 cities and counties. A smaller county-harmonized LOCUS access layer provides coverage for the largest 2,309 of 3,144 U.S. counties, accounting for a majority of the population. We use OCR to handle the myriad of document formats that have kept the law from being a public resource. We release the corpus with coverage metadata to support reproducibility, downstream legal AI research, and the incremental expansion of machine-readable access to local law. We train a collection of ModernBERT-based classifiers and scorers to facilitate analyzing U.S. local law among several dimensions, such as opacity and paternalism, that have not previously been studied at this scale. LOCUS-v1 and its derivative models are available at: https://huggingface.co/datasets/LocalLaws/LOCUS-v1

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces LOCUS, a giant, searchable library of local laws (called “ordinances”) from across the United States. Local ordinances are the everyday rules made by cities and counties—things like noise limits, pet rules, building permits, curfews, and business licenses. These rules affect people’s daily lives, but they’re scattered across many websites and formats that are hard to download or search in bulk. The authors collected and cleaned these laws so researchers, public-interest groups, and AI systems can study them at a national scale.
What were the main goals?
The authors wanted to:
- Gather local laws from thousands of city and county websites into one place.
- Turn those laws into clean, computer-readable text so they can be searched and analyzed.
- Add simple labels (like “what topic is this?”) to help people find the parts that matter.
- Score each law along four “sliders” (how clear, how strict, how paternalistic, how urgent-sounding) to compare rules across places.
- Create a fair, county-by-county “map” of local law so researchers can compare regions and build better legal AI tools.
How did they build LOCUS?
To make this huge library, the team used a step-by-step process. Here’s what they did, in everyday language:
1) Collecting the laws
They found and downloaded local codes (often big PDF files) from the platforms that host city and county laws. This wasn’t simple: websites used different structures, had anti-bot protections, and sometimes printed laws in unusual ways. The team wrote custom tools and did manual recovery where needed.
2) Turning pages into text
Many laws were scanned or formatted awkwardly. The team used OCR (Optical Character Recognition)—think of it as a “text-reading camera”—to convert images of pages into clean text. They standardized everything (like removing page numbers and headers) so the text reads in the right order.
3) Splitting and labeling the laws
They split the big documents into chunks that correspond to individual rules or sections. Then they used AI models to:
- Filter out non-law parts (like tables of contents).
- Label each chunk’s “function” (e.g., a rule, an enforcement section, or just background info).
- Label each chunk’s “topic” (e.g., buildings, zoning, business, nuisance/noise, or other).
You can think of this like organizing a messy bookshelf into labeled folders so you can quickly find the right page.
4) Creating a county-based “access layer”
To make comparisons easy, they picked one representative code per county—either the county’s own code or the largest city’s code in that county—whichever was longer (as a simple stand-in for “most complete”). This gives each county one main set of local laws to search and compare, even though in real life both city and county rules can apply.
5) Scoring laws on four “sliders”
They trained AI models to give each law scores along four dimensions:
- Enforcement discretion: How much freedom do officials have to decide when and how to enforce it?
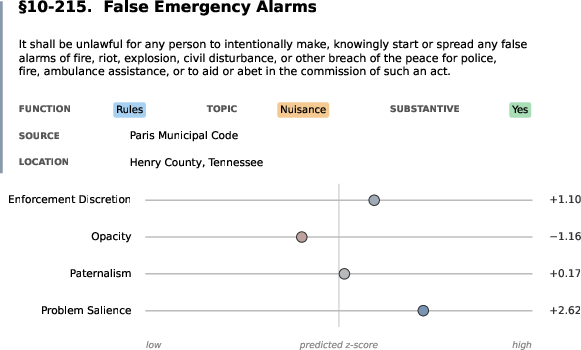
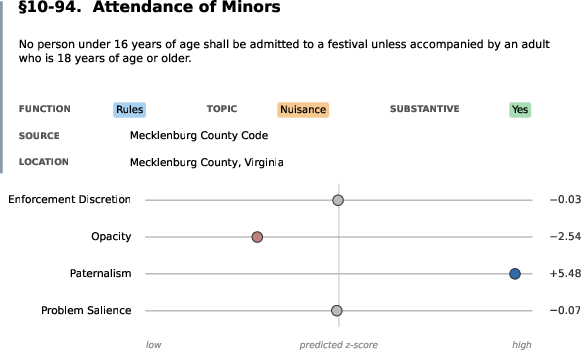
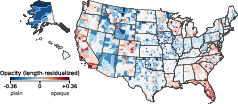
- Opacity: How confusing is it for a normal person to understand what the rule requires?
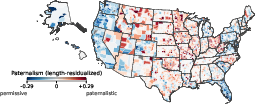
- Paternalism: Is the rule aimed at protecting the person from themself, or protecting others/the public?
- Problem salience: Does the law present the issue as urgent or serious?
To teach the models, they compared pairs of laws (like a tournament) and decided which one was “more” of a dimension (e.g., more confusing). Then they used a ranking system (similar to how video games rank players after matches) to give each law a score. Finally, they trained a fast model to predict those scores for lots of laws at once.
What did they find, and why does it matter?
Here are the key takeaways the authors report:
- They built a massive, national dataset of local ordinances:
- About 9,239 city and county codes.
- Around 7 million pages turned into text.
- Over 2.2 million labeled law sections (“chunks”).
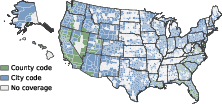
- A county-by-county “access layer” covering the largest 2,309 of 3,144 counties—representing roughly 94% of the U.S. population.
- Most chunks are substantive rules (not just headings or procedures). Common topics include buildings, business licensing, zoning, and nuisance (like noise and public order), with many others in “other” (such as government or animal rules).
- City vs. county differences:
- County codes tend to include more zoning/land-use rules.
- City codes often include more nuisance and public-order rules.
- Regional patterns and clarity:
- On average, counties’ laws are more opaque (harder to understand) than cities’.
- Some states stand out—for example, Florida’s local laws scored as especially opaque in this dataset, but not especially paternalistic.
- Opacity and paternalism don’t really move together (they’re only weakly related), meaning confusing laws aren’t necessarily more or less paternalistic.
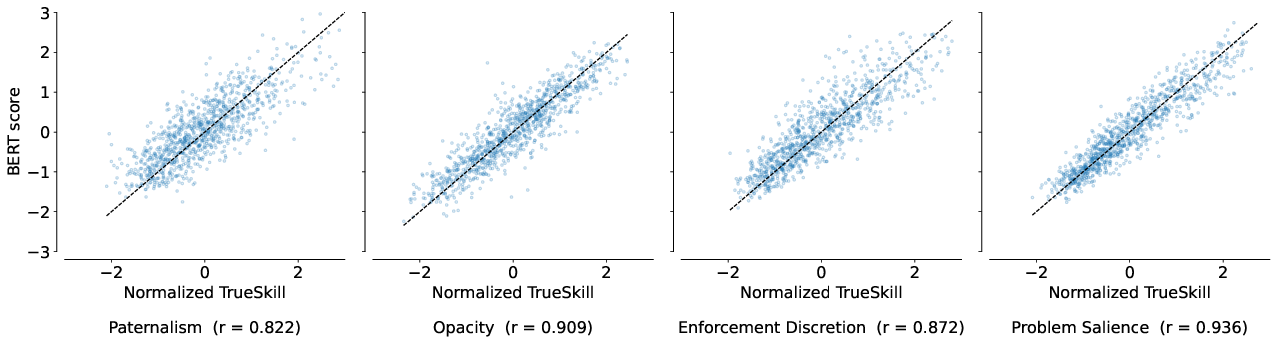
- The scoring models worked well for the four dimensions, showing strong agreement with the tournament-style rankings.
Why this matters:
- LOCUS makes it possible to search and compare local rules across the nation—something that was very hard before.
- It helps researchers spot patterns (like curfews for minors), compare policies across places, and ask new questions about fairness, clarity, and enforcement.
- It lays the groundwork for AI systems that can handle multi-layered law (state, county, city) more reliably.
What’s the impact of this work?
In simple terms: this project turns scattered, hard-to-get local rules into a public, research-ready resource. That has several big effects:
- For communities and journalists: It’s easier to look up and compare local rules that affect daily life.
- For researchers and policymakers: It enables nationwide studies about how different places regulate housing, businesses, noise, land use, and more.
- For AI and technology: It creates the training and test data needed to build smarter legal search tools and AI that can reason through layers of law (state vs. county vs. city).
The authors stress that LOCUS is a starting point for access and comparison, not a final answer about which law “wins” in every situation. Real legal questions can still require expert analysis. But with LOCUS, the law is no longer “locked away” in scattered PDFs—it’s organized and observable, so people and tools can actually use it.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise, actionable list of what remains missing, uncertain, or left unexplored in the paper.
- Coverage gaps: 835 of 3,144 counties are absent from the county-harmonized release; quantify which counties and characterize systematic differences (e.g., population density, vendor platform) to guide targeted expansion.
- Missing intra-county codes: Selecting only the county code or the largest city per county ignores all other municipalities; design a multi-municipality access layer (e.g., top-k cities per county or full municipal coverage) and measure the coverage gains by topic.
- Applicability mapping: A city code chosen to represent a county does not apply to unincorporated areas or other cities; add geospatial applicability metadata (city limits, unincorporated areas) per segment to indicate who is actually governed.
- Selection heuristic validity: Page length is used as a proxy for coverage; validate this against alternative proxies (e.g., count of substantive sections, topic diversity, cross-reference density) and report which best predicts real coverage.
- Temporal versioning: No snapshot/version control is provided; implement dated snapshots with per-section amendment dates, ordinance numbers, and change logs to enable longitudinal analyses.
- Update cadence: No plan for periodic refresh; define and evaluate an incremental recrawl/change-detection pipeline (e.g., diff-based monitoring of vendor platforms) with staleness metrics.
- OCR quality assurance: OCR performance is asserted but not quantified on this corpus; measure page-level WER/CER and structural retention (headers, lists, tables) on a stratified sample and publish error profiles by layout/vendor.
- Table/map/figure handling: Zoning maps, fee tables, forms, and embedded images may be lost or mangled by OCR; develop specialized parsers for tables and image-to-structured-data extraction, and quantify recovery rates.
- Segmentation accuracy: The pipeline segments “individual laws” but reports no evaluation; create a gold-standard set of section/subsection boundaries to assess precision/recall of segmentation across diverse code styles.
- Citation parsing and linking: Cross-references (intra-code, inter-code, and to state law) are not resolved; build a citation extraction and link-resolution layer to enable graph queries and multi-layer reasoning.
- Provenance completeness: Section-level provenance (source ordinance, adoption date, amendment history) is not preserved; extract and normalize provenance fields to support legal traceability.
- Annotation reliability: Function/topic/substance labels derive from LLM zero-shot annotations with limited review; construct a human-expert gold set, report inter-annotator agreement, and calibrate models to human ground truth.
- Sparse evaluation metrics: Classifier performance (precision/recall/F1, per-class confusion matrices) is not reported; provide full metrics by function/topic and by jurisdiction type (city vs county).
- Topic taxonomy granularity: Five merged topics leave ~1/3 categorized as “Other”; design a richer, multi-label taxonomy (e.g., animal control, public health, parking, signage, licensing, noise) and benchmark gains in coverage/precision.
- Domain adaptation: No test of generalization across regions/vendors; perform cross-region and cross-vendor transfer evaluations to diagnose distributional shifts.
- Normative scorer validity: Paternalism, opacity, discretion, and salience are subjectively defined; conduct human pairwise judgments with legal experts and lay readers to assess validity and cultural/region sensitivity.
- LLM-as-judge bias: Only one model and rubric were used; compare multiple evaluators (different LLMs, human panels), randomize and counterbalance prompts beyond A/B order, and quantify evaluator-induced variance.
- Uncertainty propagation: TrueSkill scores and regression outputs are used without reporting uncertainty; expose confidence intervals/variance per segment and propagate uncertainty through downstream analyses.
- External validity: No linkage to outcomes; test whether axes correlate with measurable phenomena (e.g., complaint rates, citation volumes, code enforcement actions, permitting delays, litigation, health or housing outcomes).
- Authority resolution: The corpus does not model preemption, delegation, or conflict; create benchmarks with ground-truth controlling authority per issue, incorporating state statutes, charters, and home-rule provisions.
- Geographic edge cases: Multi-county cities, consolidated city-counties, and special districts are handled ad hoc; formalize a normalization strategy and publish mappings to avoid double counting/misassignment.
- Representativeness bias: Coverage is 94% by population but likely underrepresents small/rural jurisdictions; quantify demographic/geographic bias and apply weighting or targeted data collection to correct it.
- Tribal and special jurisdictions: Tribal governments, school districts, and special-purpose districts are absent; assess feasibility, legal status, and methods to incorporate these bodies’ ordinances.
- Language accessibility: Non-English or bilingual ordinances (e.g., Spanish) are not addressed; detect language, include translations where available, and evaluate intelligibility across languages.
- Granularity of “law” units: “Individual laws” are not formally defined (section vs subsection vs paragraph); standardize granularity with stable identifiers and report how granularity affects retrieval and scoring.
- Retrieval/QA baselines: No end-to-end retrieval or QA benchmarks are provided; release tasks with queries, relevance judgments, and authority labels to evaluate legal IR over local ordinances.
- Benchmark contamination: Using LLMs for labeling risks leakage into future evaluations; partition datasets and document model/data provenance to maintain uncontaminated test sets.
- Tooling and APIs: Aside from a small leaderboard site, no search or programmatic API is released; provide a public API with pagination, filters (topic, function, jurisdiction), and bulk access endpoints.
- Access constraints: 7,000 additional documents require signed release; clarify legal/ethical basis, governance, and reproducibility implications, and explore open alternatives (e.g., per-jurisdiction permissions).
- Reproducibility of pipeline: Key components (OCR model, GPT-5.4-nano) are proprietary or time-variant; provide containerized, open-source fallbacks and exact model hashes/checkpoints for reproducibility.
- End-to-end error budget: The paper does not quantify cumulative errors across OCR → segmentation → labeling → scoring; produce an error budget and sensitivity analysis to identify dominant failure modes.
- Harmonization side effects: County-level harmonization may distort topic distributions (e.g., zoning vs nuisance); quantify distortions and propose stratified analyses that preserve city/county distinctions.
- Ethical considerations: Normative labeling (e.g., “paternalism,” “opacity”) may invite value-laden interpretations; document safeguards, transparency notes, and community review processes for responsible use.
- Maintenance plan: No governance or sustainability model (contributors, issue tracking, scheduled releases) is described; establish a public roadmap, contribution guidelines, and periodic release policy.
Practical Applications
Immediate Applications
The following applications can be deployed now using LOCUS-v1’s released corpus, metadata, and models, along with the described OCR/processing pipeline and county-harmonized access layer.
- Legal search and retrieval API for local ordinances
- Sector: software, LegalTech, civic tech
- What: Package the corpus and metadata as a searchable API with county-level endpoints, full-text search, and filters by function/topic (Rules, Enforcement; Buildings, Business, Zoning, Nuisance, Other).
- Tools/products/workflows: REST API; RAG connectors for LLM assistants; county-to-code resolver; embeddings-based search; “open-law” developer SDK.
- Assumptions/dependencies: Timely updates to codes; adherence to hosting platforms’ terms; coverage gaps where codes are not publicly accessible; the county-harmonized proxy may not reflect the controlling authority for a specific question.
- SMB regulatory onboarding and checklists
- Sector: RegTech, small business services, finance (SMB lending)
- What: Auto-generate jurisdiction-specific checklists for permits, licenses, fees, penalties, and effective dates for opening/expanding a business.
- Tools/products/workflows: Workflow builders mapping regulated activities → required filings; permit timelines; fee calculators; “enter your county/business type → compliance plan.”
- Assumptions/dependencies: Extraction accuracy for permits/fees varies by code quality; local preemption and exemptions can alter requirements; human legal review for high-stakes use.
- Real estate and proptech due diligence
- Sector: real estate, construction, insurance
- What: Zoning/building/nuisance snapshots for parcels in a target county/city; highlight sections with high enforcement discretion (risk) or opacity (time-to-permit risk).
- Tools/products/workflows: Due-diligence reports; GIS layer overlays that summarize topical coverage and “risk axes” (opacity, enforcement discretion).
- Assumptions/dependencies: County-harmonized selection sometimes chooses a city code (or vice versa); not a substitute for parcel-level, state law, or charter-specific analysis.
- Policy dashboards for code intelligibility and paternalism
- Sector: government, policy research, public-interest orgs
- What: Public dashboards benchmarking jurisdictions on opacity, paternalism, and discretion to support plain-language reform and enforcement accountability.
- Tools/products/workflows: “Code complexity scorecards”; redlining candidates for simplification; tracking improvement across code revisions.
- Assumptions/dependencies: Dimension scorers are trained from LLM pairwise judgments; face construct validity limits; require jurisdiction buy-in to inform reforms.
- Civic Q&A assistants for residents
- Sector: civic tech, public libraries, city portals
- What: Retrieval-augmented chatbots to answer “How do I get a permit?”, “What are the noise hours?”, or “Are backyard chickens allowed?”
- Tools/products/workflows: County-aware RAG; guardrails that show provenance links and disclaimers; escalation to human clerks.
- Assumptions/dependencies: Must warn users about layered authority (state preemption, county vs. city); periodic retraining for code updates.
- Compliance intelligence for enterprises operating across counties
- Sector: compliance, logistics, hospitality, retail
- What: Bulk scanning to detect conflicts in signage, hours, business licensing, public space, and nuisance rules across multi-site footprints.
- Tools/products/workflows: Batch audits; diffing when codes change; alerting for high-salience issues (e.g., curfews affecting store hours).
- Assumptions/dependencies: Accuracy depends on OCR quality and topic/function classifiers; legal sign-off required for enforcement actions.
- Government code modernization and housekeeping
- Sector: government IT, law departments, codifiers
- What: Use structural vs. substantive classifiers to remove formatting noise, normalize headers, detect cross-reference inconsistencies, and flag opaque provisions for rewriting.
- Tools/products/workflows: “Code linting” CI/CD pipeline; complexity/opacity scanners; duplicate/obsolete section detectors.
- Assumptions/dependencies: Local adoption and integration with codification workflows; careful treatment of legal history/source notes.
- Journalism and public-interest investigations
- Sector: media, watchdog NGOs
- What: Identify and map curfew laws, alcohol possession rules, or patterns of high-discretion enforcement across regions; produce comparative stories.
- Tools/products/workflows: Query notebooks; map visualizations; topic/discretion filters to find “needles in a haystack.”
- Assumptions/dependencies: Model scores are probabilistic and should be corroborated; county harmonization may obscure intra-county variation.
- Academic benchmarks for legal reasoning with layered authority
- Sector: academia (NLP, law, public policy)
- What: Create retrieval, extraction, and reasoning tasks involving city/county/state overlap, preemption, and delegation; evaluate LMs beyond contracts/cases.
- Tools/products/workflows: New benchmark suites; controlled test sets using provided coverage metadata; pairwise preference scoring recipes for “normative axes.”
- Assumptions/dependencies: Requires careful separation between training/eval to avoid data contamination; openness of downstream model licensing.
- OCR and document-processing pipeline reuse
- Sector: software, public records digitization, archives
- What: Apply the low-cost OCR→Markdown→segmentation pipeline to other public corpora with diverse layouts (e.g., administrative codes, health regulations).
- Tools/products/workflows: Batch OCR services; header/section detection templates; plug-in for Modal-style batch inference.
- Assumptions/dependencies: Availability of the OCR model and batch inference environment; TOS for source sites; QA for critical documents.
- GIS-ready county substrate for cross-dataset linkage
- Sector: urban planning, public health, econ dev
- What: Link county-harmonized codes with Census, health, or economic datasets to study relationships between regulation and outcomes.
- Tools/products/workflows: County-level join keys; notebooks for merged analyses; policy maps correlating code axes with demographic/economic indicators.
- Assumptions/dependencies: Ecological inference risks; code axes are correlational, not causal; city/county functional differences require stratified analysis.
- Alternative legal content platforms
- Sector: LegalTech data vendors, open-law repositories
- What: Augment case/statute offerings with unified municipal/county codes; enable federated search and licensing for law firms and clinics.
- Tools/products/workflows: Index integrations; deduplicated code catalogs; “local-law” facets in legal research tools.
- Assumptions/dependencies: Ongoing maintenance of hosting links; respect for codifier/vendor constraints; clear provenance.
Long-Term Applications
The following applications require additional research, scaling, ground-truthing, or ecosystem collaboration (e.g., continuous updates, cross-layer legal linking, or stronger validity tests).
- Hierarchical authority reasoning and “controlling rule” engines
- Sector: LegalTech, public sector
- What: Systems that determine, for a given issue and location, whether state, county, or municipal law controls and how conflicts resolve.
- Tools/products/workflows: Multi-layer legal graph linking statutes, preemption doctrines, charters, and ordinances; reasoning models with jurisdiction-aware logic.
- Assumptions/dependencies: Expert-labeled ground truth; state-specific preemption rules; doctrinal variation; high-stakes validation.
- Automated multi-jurisdiction compliance advisors
- Sector: RegTech, enterprise software
- What: End-to-end assistants that synthesize federal–state–local requirements, produce step-by-step filings, and schedule inspections.
- Tools/products/workflows: Structured extraction of requirements/fees/exceptions; calendarized workflows; form autofill; clerk e-submission integrations.
- Assumptions/dependencies: Stable APIs to local permitting systems; reliable exception handling; legal oversight for advice.
- Conflict and preemption detection
- Sector: government, litigation support, policy
- What: Detection of ordinance–statute conflicts, redundancies, or gaps; support for preemption litigation and code harmonization.
- Tools/products/workflows: Cross-reference resolvers; similarity and entailment models across layers; human-in-the-loop resolution.
- Assumptions/dependencies: High precision required; authoritative linkage between code provisions and state law; frequent updates.
- Plain-language drafting and code simplification assistants
- Sector: government, civic tech, accessibility
- What: Rewrite opaque sections into intelligible language while preserving legal effect; simulate readability/opacity improvements.
- Tools/products/workflows: Rewrite suggestions with diff and risk flags; readability and opacity metrics; iterative human/legal review workflow.
- Assumptions/dependencies: Semantic equivalence verification; legislative approval processes; public participation norms.
- Causal policy evaluation using normative dimensions
- Sector: academia, policy research, philanthropy
- What: Test whether opacity, discretion, or paternalism correlate with enforcement disparities, economic outcomes, or public health—and estimate causal effects.
- Tools/products/workflows: Quasi-experimental designs; data linkages with outcomes (violations, fines, business formation); pre-registration and robustness checks.
- Assumptions/dependencies: Data availability and quality; addressing selection and measurement bias; institutional review for sensitive analyses.
- Real-time code change tracking and alerting at national scale
- Sector: data infrastructure, LegalTech, civic tech
- What: Continuous monitoring of 9k+ jurisdictions for ordinance updates with semantic diffs and downstream alerting.
- Tools/products/workflows: Crawlers with anti-bot resilience; canonicalization; section-level diffing; webhook-based notifications.
- Assumptions/dependencies: Vendor cooperation and TOS; throttling constraints; sustainable funding for maintenance.
- Local-law–tuned foundation models
- Sector: AI/ML, LegalTech
- What: Pretrain/finetune models specifically on municipal and county text to improve retrieval, extraction, and layered reasoning.
- Tools/products/workflows: Domain-adaptive pretraining; supervised signals from LOCUS classifiers/scorers; benchmarks for generalization across jurisdictions.
- Assumptions/dependencies: Licensing for derivative models; prevention of data contamination in evaluation; privacy/ethics for any non-public additions.
- Internationalization of the pipeline
- Sector: global civic tech, comparative law
- What: Extend the OCR, segmentation, classification, and scoring pipeline to other countries’ local laws, enabling cross-national comparisons.
- Tools/products/workflows: Localization of classifiers and rubrics; multilingual OCR/LLMs; country-specific harmonization units (e.g., municipalities/regions).
- Assumptions/dependencies: Legal availability of texts; differing administrative geographies; translation/annotation quality.
- Insurance and credit risk scoring using regulatory signals
- Sector: insurance, finance
- What: Incorporate enforcement discretion and opacity as covariates in underwriting or credit risk models for location-dependent operations.
- Tools/products/workflows: Feature engineering pipelines; ablation studies; fairness and regulatory audits.
- Assumptions/dependencies: Demonstrated predictive validity; regulatory acceptance; guarding against proxy discrimination.
- Smart permitting and e-government integration
- Sector: govtech
- What: Orchestrations that validate application completeness against code requirements, route to the right agency, and forecast inspection needs.
- Tools/products/workflows: Schema-aligned requirement graphs; validation services; status trackers; applicant guidance chat.
- Assumptions/dependencies: APIs to legacy systems; change management within agencies; security and privacy compliance.
- Court and bar tools for local-law litigation and counseling
- Sector: legal services
- What: Brief-building assistants that surface relevant overlapping authorities and flag potential conflicts or delegation issues.
- Tools/products/workflows: Multi-layer retrieval; argument graph builders; citation hygiene checks with provenance.
- Assumptions/dependencies: High accuracy and strong citations; malpractice risk management; continuous updates.
- Urban planning simulations under alternative code regimes
- Sector: urban planning, energy/construction
- What: Model how changes in zoning/building rules affect housing supply, permitting times, and energy/code compliance pathways.
- Tools/products/workflows: Scenario generators linking code edits to development constraints; parameterized policy sandboxes.
- Assumptions/dependencies: Structural modeling choices; data about permitting pipelines; integrating non-legal constraints (market, infrastructure).
Notes on feasibility across applications:
- LOCUS’s county-harmonized layer is an access substrate (longest available county or largest city code), not a doctrine of controlling authority; high-stakes decisions require layered legal analysis.
- OCR artifacts and LLM-derived labels introduce noise; critical workflows need human validation and/or conservative thresholds.
- Continuous updates, provenance, and jurisdictional buy-in are pivotal for production systems.
- Ethical, fairness, and legal compliance (TOS, public domain status, privacy) must be addressed in productization.
Glossary
- Bayesian skill rating system: A probabilistic framework for estimating latent skill from pairwise outcomes. "the Bayesian skill rating system, TrueSkill"
- born-digital: Documents originally created in digital form rather than scanned from physical media. "born-digital, exported, and scanned documents, etc."
- codification: The organization of laws into a structured, ordered code. "the structure of codification itself."
- county-harmonized access layer: A standardized county-level interface providing reproducible access to local ordinance texts. "a comprehensive corpus and county-harmonized access layer for U.S. municipal and county ordinance codes."
- county-harmonized release: A dataset version aligned to counties by selecting a representative local code per county. "Its county-harmonized release adopts a transparent simplification"
- cross-references: References within legal texts to other sections or laws used to define obligations or context. "permits, fees, penalties, effective dates, and cross-references."
- doctrine-sensitive legal analysis: Legal reasoning that accounts for layered authorities and doctrines determining which rules control. "rather than as a substitute for doctrine-sensitive legal analysis."
- ECHR: A legal NLP corpus derived from European Court of Human Rights cases. "Neural network era corpora such as ECHR~\citep{chalkidis2019neural} and pile of law~\citep{henderson2022pile}"
- Enforcement Discretion: The degree to which enforcement depends on official choice rather than citizen conduct. "Enforcement Discretion (highly discretionary to non-discretionary) --- how much selective judgment does the law leave to officials?"
- geographic substrate: A shared spatial framework used to index and compare legal texts across jurisdictions. "common geographic substrate on which local legal text can be searched, compared, and connected to population, geographic, Census, and policy data."
- harmonization: Standardizing diverse sources into a common representational scheme while noting trade-offs. "harmonization must be explicit about what it preserves and what it abstracts away."
- home-rule provisions: State constitutional or statutory rules granting municipalities autonomy to legislate locally. "home-rule provisions"
- jurisdictional layer: The level of government (state, county, municipal) whose authority applies to a legal question. "identify the relevant jurisdictional layer"
- LightOnOCR-2-1B: An open 1B-parameter OCR vision-LLM used to convert page images to text. "LightOnOCR-2-1B"
- LLM-as-a-Judge: A methodology where LLMs evaluate or compare outputs as a proxy for human judgment. "Inspired by LLM-as-a-Judge~\citep{zheng2023judging}"
- ModernBERT: A family of efficient transformer encoders used here for classification and regression over legal texts. "ModernBERT-based classifiers and scorers"
- municipal codes: The compiled ordinances enacted by a city or town. "there is unfortunately no single source where you can find a comprehensive collection of all municipal codes."
- mutually exclusive and exhaustive: A partitioning where categories do not overlap and collectively cover the entire set. "counties form a mutually exclusive and exhaustive national geography"
- OlmOCR-Bench: A benchmark suite for assessing OCR systems on document images. "OlmOCR-Bench~\citep{poznanski2025olmocr}"
- optical character recognition (OCR): Technology that converts images of text into machine-readable text. "optical character recognition (OCR)"
- orality detector: A model that scores text along an oral–literate continuum. "an AI-powered orality detector"
- pairwise comparison: Evaluation by comparing items in pairs to determine relative ordering on a dimension. "Pairwise comparison aligns better with human judgement than direct/numeric scoring"
- Paternalism: A normative dimension indicating whether a law targets self-regarding behavior for the actor’s own good. "Paternalism (paternalistic to externality oriented) --- is it protecting the actor from themself or protecting others/the public?"
- Pearson correlation: A statistic measuring linear association between predicted and true scores. "We compute Pearson correlation on the test set."
- preemption doctrines: Legal principles dictating when higher-level laws override lower-level ordinances. "preemption doctrines"
- Problem Salience: A dimension reflecting how strongly a law frames an issue as important or urgent. "Problem Salience (highly salient to unimportant) ---how strongly does it represent the issue as important, urgent, or threatening?"
- provenance metadata: Information about the origin or source context of a document that affects interpretation. "jurisdiction type is not merely provenance metadata."
- Qwen-3: A base model architecture on which the OCR VLM is built. "based on Qwen-3"
- regression head: A neural network layer that outputs continuous scores for prediction tasks. "a ModernBERT-base with a linear regression head"
- state-local or county-municipal overlap: Situations where multiple government levels regulate the same issue area. "state-local or county-municipal overlap."
- substantive laws: Provisions imposing rules or specifying enforcement, as opposed to structural or procedural text. "the majority are judged to be substantive laws in nature."
- TrueSkill: A Bayesian rating algorithm used to infer latent scores from pairwise outcomes. "normalized TrueSkill scores"
- vision-LLM (VLM): A model that jointly processes visual and textual inputs. "vision-LLM (VLM)"
- z-score: A normalized score indicating how many standard deviations a value is from the mean. "normalize the scores to their z-score"
- zero-shot approach: Labeling or classification without task-specific training examples by leveraging general-purpose models. "two-level zero-shot approach"
Collections
Sign up for free to add this paper to one or more collections.