- The paper introduces a novel latent-action framework using a hybrid disentangled VQ-VAE to extract transferable motion codes from human ego videos.
- It pretrains a vision-language model to infer action intentions and adapts to robots with minimal labeled trajectories for robust performance.
- Experimental results show enhanced cross-embodiment generalization, outperforming benchmarks in long-horizon and dual-arm manipulation tasks.
Motion-Focused Latent Action Enables Cross-Embodiment VLA Training from Human EgoVideos
Introduction
The increasing prevalence of Vision-Language-Action (VLA) models has yielded significant leaps in general-purpose robot agents. However, these advances are fundamentally constrained by the reliance on annotated, large-scale robotic datasets with high-fidelity action labeling. The inherent cost, kinematic diversity, and labor intensiveness of collecting such data limit the scalability and embodied generalization of modern VLA architectures. Addressing this bottleneck, "Motion-Focused Latent Action Enables Cross-Embodiment VLA Training from Human EgoVideos" (2606.18955) proposes a data-efficient pretraining paradigm, utilizing egocentric human manipulation videos that are abundant yet lack action labels, to extract universal action priors and facilitate robust adaptation across robot embodiments.
Framework and Methodology
The central contribution is a latent-action-driven framework for VLA pretraining (Figure 1). The method involves three core stages: (1) extraction of transferable latent action codes from unlabeled human videos using a hybrid disentangled VQ-VAE; (2) pretraining a VLM backbone to infer action intentions under supervision from these codes; (3) downstream adaptation on a target robot with minimal labeled trajectories, facilitated by an intent-perception decoupling approach.
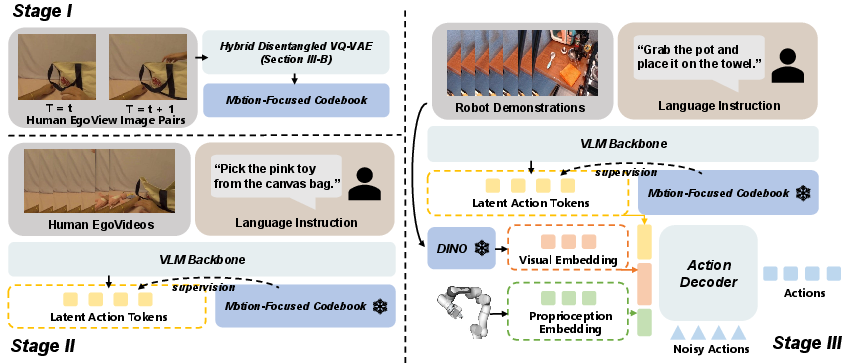
Figure 1: The proposed framework extracts motion-focused latent action codes from human videos, supervises a VLM to infer action intentions, and fine-tunes on a small set of robotic data for cross-embodiment generalization.
Hybrid Disentangled VQ-VAE
At the core of the pipeline is a hybrid disentangled VQ-VAE (Figure 2), which learns to decompose short-term visual change sequences into two discrete bottlenecks: action and background. The encoder leverages DINO v2 visual features and a spatial-temporal transformer, using learnable query latents to attend separately to foreground (motion-related) and background (environmental) changes. Mask-guided decoding, enabled by high-quality segmentation (e.g., SAM2 for human hands, RoboEngine for robots), enforces that the action codebook captures task-relevant motion—effectively suppressing the domain- and environment-specific confounds endemic to egocentric footage.
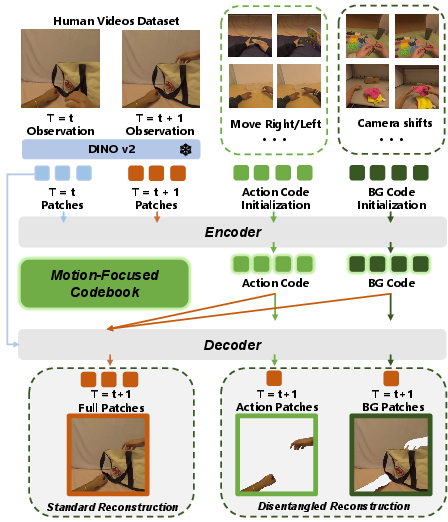
Figure 2: The hybrid disentangled VQ-VAE isolates and quantizes action- and background-related visual variations, providing transferable latent codes.
The action branch typically operates with a codebook of size 16 and encodes frame pairs at a 1s interval into 4 discrete tokens. Training enforces disentanglement via mask-guided, spatial-temporal reconstructions with mask-based loss partitioning, and a dual-path vector quantization objective.
VLM Pretraining and Adaptation
With human videos devoid of explicit action annotations, the VQ-VAE-inferred action tokens are treated as pseudo-labels for autoregressive pretraining of the VLM. This enables the model to map paired observations and instructions to generalized action intention sequences. The backbone Prismatic-7B is used to ensure comparability with state-of-the-art VLA benchmarks.
Downstream, for robot adaptation, the VLM’s output action intent embedding is concatenated with non-VLM, physically grounded visual features (DINO v2, proprioception) and passed to a flow-matching action expert. Importantly, decoupling VLM intention from direct perception is shown to mitigate action hallucination, significantly stabilizing execution by enforcing feedback sensitivity—especially crucial in closed-loop robotic control.
Experimental Evaluation
Single-Arm and Dual-Arm Cross-Embodiment Generalization
Comprehensive experiments validate the framework’s generalization. For single-arm robot transfer, the VQ-VAE and VLM are pretrained solely with third-view videos (BridgeV2, WindowX), then adapted to a distinct Franka arm within LIBERO, using only 50 adaptation trajectories per task. Benchmarked against methods including LAPA, villa-x, UniVLA, pi0/RT-2, the proposed approach achieves competitive or superior average success rates, especially excelling in long-horizon and goal-oriented tasks:
- Long-horizon tasks (LIBERO-Long): Outperforms villa-x by 9.5%, indicating enhanced temporal planning from motion-focused intention embeddings.
- Spatial/Object tasks: Achieves near-or-better performance compared to fully supervised or wrist-camera-equipped methods, despit using no action-labeled robot data for pretraining.
Decoupling perception from intent via DINO v2 embeddings yields notable improvements over models using VLM visual features, verifying the theoretical benefit of the intention-perception design.
Human EgoVideo to Robot Transfer
For more challenging dual-arm settings, human egocentric videos (EgoDex) are used for all pretraining. The method is evaluated in both simulation (RoboTwin 2.0) and on a physical dual-arm robot (Figure 3).
- In simulation: Despite zero robot-side annotation during pretraining, the framework matches or exceeds prior methods (e.g., UniVLA, RDT, ACT, Diffusion Policy) trained on large supervised robot datasets.
- Ablations: Replacing DINO with VLM visual embeddings degrades performance, and freezing the VLM during adaptation reduces but does not eliminate successful adaptation—demonstrating the criticality and transferability of the pretrained latent action intention.


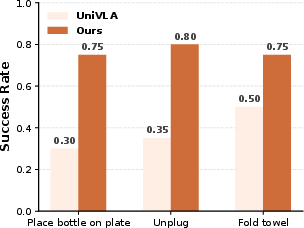
Figure 3: The physical dual-arm robotic platform for real-world evaluation.
Real-world experiments confirm that action intentions acquired from human videos can reliably transfer to complex manipulation tasks, including bimanual and deformable-object challenges, exhibiting better learning efficiency and final performance than strong VLA baselines.
Latent Action Consistency Analysis
A dedicated analysis quantifies cross-embodiment action consistency through iterative domain subspace elimination and Centered Kernel Alignment (CKA). Motion-focused latent actions yield higher CKA between robot and human datasets (mean 0.9139) compared to UniVLA (mean 0.8659), indicating a more embodiment-agnostic and consistent action codebook.
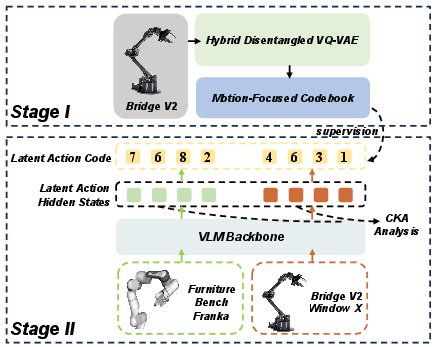
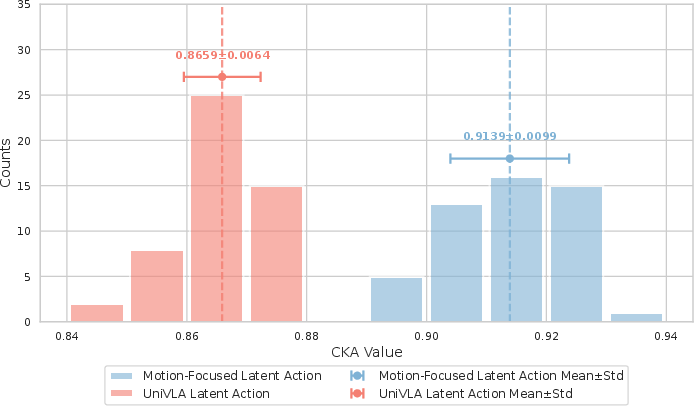
Figure 4: Pipeline for latent action alignment evaluation, removing domain bias and revealing cross-embodiment consistency.

Figure 5: Visualization of latent action codes: the same behavioral pattern maps to the same discrete tokens for robot arms and human hands, despite distinct morphologies.
Implications and Future Directions
This work demonstrates that by learning motion-focused latent actions disentangled from both background and embodiment, VLAs can be effectively pretrained with web-scale, unlabeled human data, and require orders-of-magnitude fewer robot trajectories for adaptation. This pretraining regime bridges the human-to-robot domain gap at the level of action intention rather than pixel or language, yielding robust transfer across disparate morphologies (hands, robot arms) and scenarios (single-arm, dual-arm, deformable manipulation).
Practically, this unlocks data-efficient learning at both scale and scope, especially valuable for real-world robot deployment where collecting large annotated datasets is infeasible. Theoretically, these results support the hypothesis that disentangled latent intentions form a cross-domain manifold amenable to robust downstream grounding. The approach, however, still has limitations in highly fine-grained, low-level motor control, suggesting future work on multi-scale or hierarchical latent frameworks to further enhance dexterity and adaptation.
Conclusion
Motion-Focused Latent Action pretraining offers a principled and demonstrably effective mechanism for preparing VLAs with unlabeled human manipulation videos (2606.18955). Through a hybrid VQ-VAE and intention-perception decoupling, it achieves strong cross-embodiment generalization with extreme data efficiency. The resulting models enable scalable leveraging of the immense prior in human egocentric footage and lay groundwork for more universal, cross-modal, and robust next-generation generalist robot agents.