- The paper introduces ClinEnv, a multi-stage simulation environment using real EHR data to decompose patient admissions into sequential decision stages, enabling evaluation of LLMs as attending physicians.
- Its methodology leverages automated case construction via MIMIC-IV and interactive agent querying, with dual metrics that assess both clinical outcomes and process efficiency.
- Key results reveal a significant performance gap in long-horizon decision-making, underscoring the need for improved multi-step planning and resource-efficient information gathering.
ClinEnv: An Interactive Multi-Stage Long Horizon EHR Environment for Agents
Problem Setting and Motivation
LLMs have achieved notable performance on static multiple-choice and knowledge-centric benchmarks within the medical domain. However, these benchmarks are fundamentally limited in their abstraction of clinical tasks: real-world inpatient practice involves making sequential, irreversible decisions under uncertainty, active information search, and continuous management over long event horizons. Static question answering does not probe the agent's ability to plan, contextualize, or selectively acquire information in temporally extended patient trajectories.
Existing interactive and medical agent benchmarks (e.g., EHRSQL, AgentClinic) offer partial engagement with information seeking or simulated interaction, but none instantiate the full challenge of attending-physician-level longitudinal management grounded in real EHR (Electronic Health Record) data. Benchmarks either collapse clinical reasoning into atomized database operations or restrict ‘ground truth’ to simulated, limited vignettes, thus failing to test process-aware agentic competence in hospital care.
The ClinEnv Benchmark: Architecture and Pipeline
ClinEnv introduces the Longitudinal Inpatient Simulation (LIS) paradigm, which operationalizes a multi-stage, interactive simulation for evaluating LLMs as attending physicians on real-world EHR data. The environment applies the following pipeline:
- Automated Case Construction: Using MIMIC-IV, each admission is decomposed via a pipeline into an ordered sequence of decision stages. Decisions are automatically extracted from discharge notes and temporally anchored using structured EHR events, without manual annotation. Each stage is classified by type (diagnosis, medication, procedure, plan) and then enriched deterministically from EHR tables. This process ensures complete traceability of ground-truth actions and highly granular temporal localization.
- Interactive Multi-Agent Environment: At each stage, clinical information is siloed between specialized agents (patient, nurse, lab, history), and the model must actively query these sources to gather facts before making management decisions. The environment only exposes agent roles with available context in the current stage.
- Dual Evaluation Metrics: Outcome quality is deterministically scored using ontology-grounded schema—ATC for medications, ICD hierarchy for diagnoses/procedures—via Hungarian matching, enabling type-specific and partial credit. Process quality is quantified by information coverage, efficiency (coverage per agent query rate), and financial/resource costs (e.g., unnecessary laboratory expenditure).
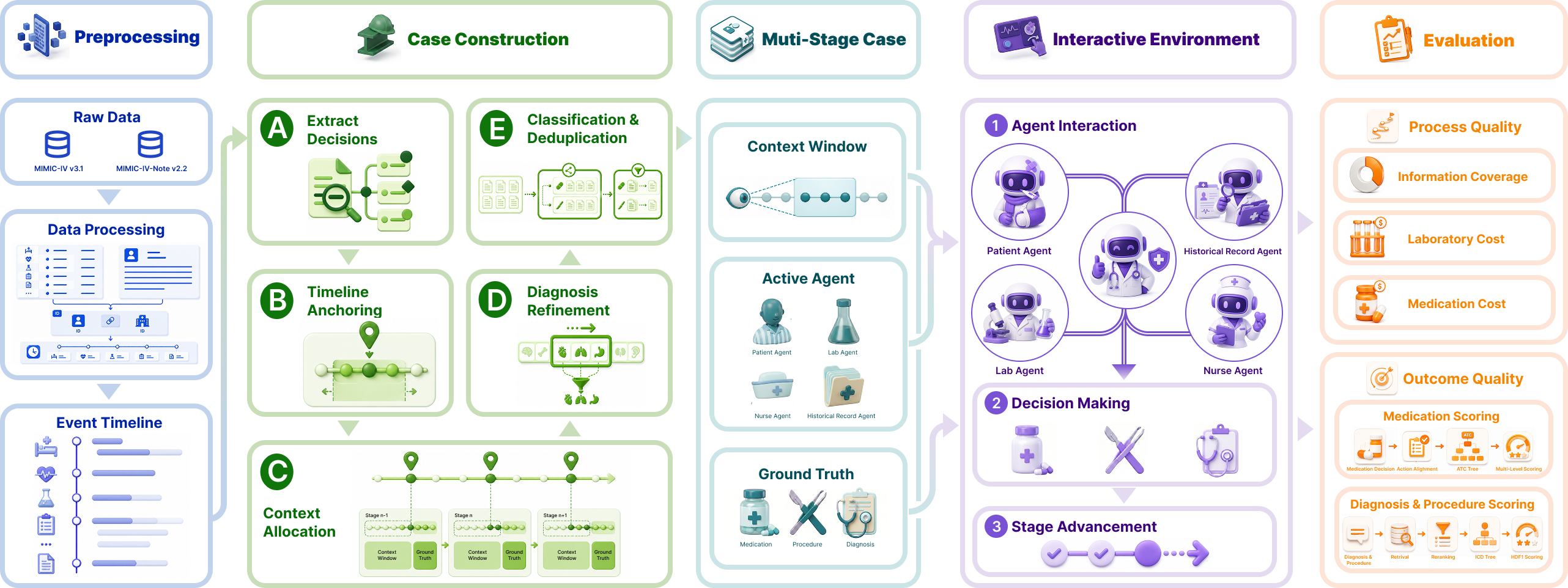
Figure 1: Overview of ClinEnv. Admissions are processed into event timelines, segmented by a stage-construction pipeline, and evaluated interactively with agent querying and dual scoring.
Experimental Protocol, Data, and Composition
ClinEnv is constructed from 3,509 admissions in MIMIC-IV, producing 9,297 decision stages and 26,043 ground truth decision points (71.7% diagnosis, 21.4% medication, 6.9% procedure). The mean case horizon is 2.65 stages, stratifying for both short and long admissions.
The benchmark supports two evaluation modes: direct (oracle access to all context) and interactive (only accessible through agent querying; models begin with zero data and must accumulate observations through explicit actions).
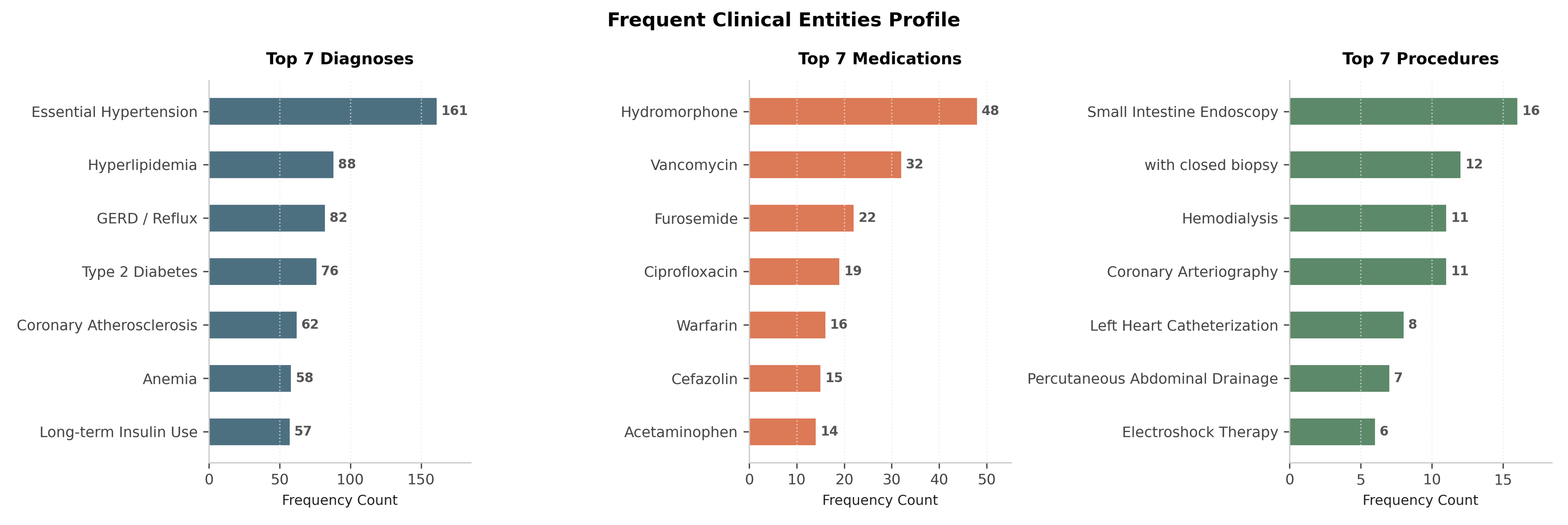
Figure 2: Distribution of frequent diagnoses, medications, and procedures in structured ground truth across ClinEnv.
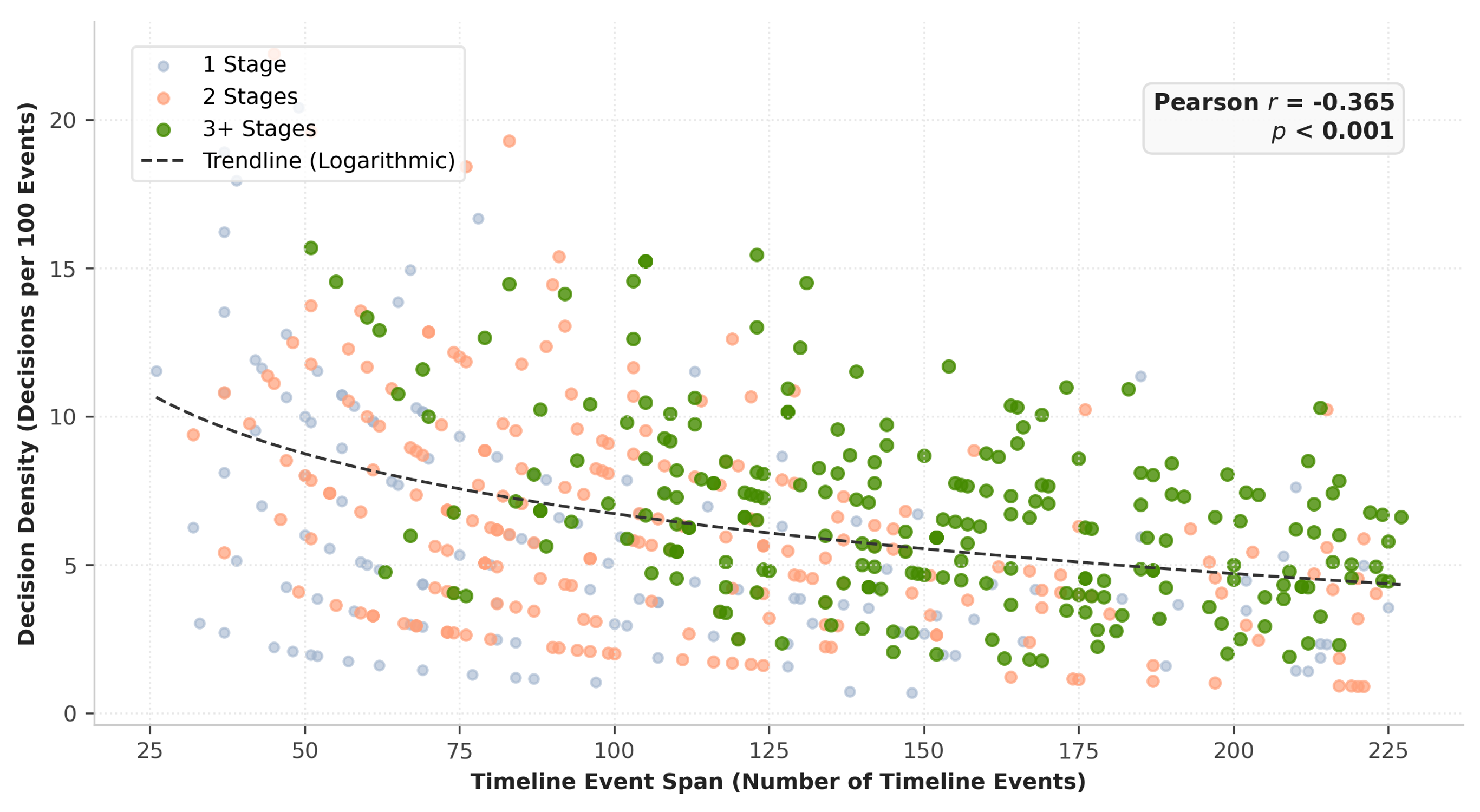
Figure 3: Decision density as a function of timeline span. Longer trajectories concentrate information, requiring integration of broader context per decision.
Key Results
Seven LLM variants, including proprietary (GPT-5.4) and open-source (Llama-3.1, Gemma) families, are benchmarked. The strongest model (GPT-5.4) reaches an overall decision F1 of only 0.31, with 0.51 on diagnosis and 0.097 on medication stages. Importantly, outcome quality is decoupled from process quality: Llama-3.1-70B achieves the top medication match but with the lowest information coverage and highest lab waste, while GPT-5.4-nano achieves competitive accuracy with minimal queries and waste.
Long-Horizon and Stage-Wise Analysis
Case difficulty is sharply horizon-sensitive. In long-horizon cases (≥3 decision stages), F1 scores drop dramatically (GPT-5.4: 0.306 → 0.235). Performance tracks stage index: decision F1 drops monotonically through sequential management episodes, not due to shrunken information access (coverage remains stable or climbs), but due to efficiency decay—models make increasingly redundant/futile queries as the clinical trajectory extends.
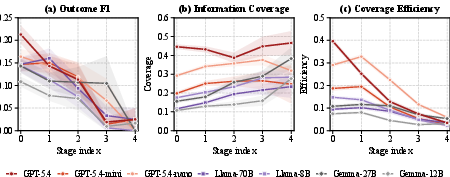
Figure 4: Per-stage analysis: Decision F1 declines over stages, information coverage rises, but coverage efficiency collapses—highlighting mounting difficulty in clinical reasoning relative to information access.
A core claim is that clinically targeted information gathering both raises relevant evidence acquisition and reduces resource waste. Models with higher coverage systematically achieve lower wasted laboratory cost ratio, rather than simply ordering more tests.
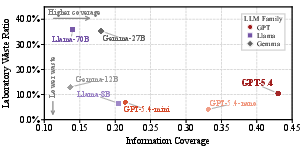
Figure 5: Information coverage-waste frontier; higher coverage correlates with lower laboratory waste, identifying the desirable frontier for clinically competent agents.
Decision Type Decomposition
Diagnosis recovery is achievable (GPT-5.4: 0.51), but management actions remain intractable (medication/procedure F1 ≈ 0.10–0.17). The primary failure is not action selection (e.g., start/stop) but agent selection—the models frequently propose reasonable drug classes but seldom match ground-truth agents, even with partial (ATC) credit. Increased information retrieval does not translate to improved management decisions, underscoring the distinction between ‘knowing’ and ‘deciding’ under constraints.
Practical and Theoretical Implications
ClinEnv demonstrates that static and outcome-only medical LLM benchmarks substantially overestimate clinical readiness. Benchmarking that ignores information-seeking process and sequential reasoning not only fails to audit resource stewardship but also misjudges real-world medical competence, especially under long time horizons.
Decisive progress in agentic clinical LLMs requires improvement in multi-step planning and context-resolved management selection, not only factual recall or entity extraction. The persistent gap between information retrieval and decision execution underlines the need for research into agentized LLMs capable of sample-efficient strategy acquisition, adaptive plan revision, and explicit cost-benefit reasoning—in effect, models must engage in process-oriented evidence management at parity with practicing clinicians.
Limitations and Future Directions
ClinEnv measures alignment with observed (not always optimal) clinical practice; a competent but alternative management strategy may not be captured by the ground truth. Data is drawn from a single US academic medical center with localized coding and billing practices, warranting evaluation in broader, international hospital systems. Further, while construction automates EHR translation to cases, some typological decisions rely on LLM classifiers, inviting scrutiny for potential pipeline bias.
Prospective research includes (1) training LLM-based agents with integrated process feedback from ClinEnv, (2) developing more granular scoring schemas for sub-decision logic (e.g., diagnostic-therapeutic concordance), and (3) expanding the agent framework to interdisciplinary, team-based clinical scenarios.

Figure 6: Stage-level runtime example: The agent queries information channels before committing a medication action; both decision error and process metrics are recorded.
Conclusion
ClinEnv sets a rigorous new standard for evaluating LLMs as agentic clinicians, emphasizing the dissociation between what models can recognize and what they can decide under realistic, sequential, and information-limited settings. By revealing the persistent gap in simulated management and process efficiency, ClinEnv provides a critical infrastructure for the iterative advancement of clinically aligned, process-aware medical foundation models.

