- The paper introduces FR3D, which decouples ego-motion from scene dynamics to enable temporally stable and geometry-consistent 3D reconstructions.
- It employs a teacher-student distillation strategy with masked transformers to autoregressively predict future latent tokens for both pose and spatial features.
- The framework demonstrates superior long-horizon performance on datasets like KITTI and nuScenes, highlighting its potential for autonomous driving and robotics.
Future Dynamic 3D Reconstruction with Disentangled Ego-Motion: A Technical Perspective on FR3D
Introduction
The paper "Future Dynamic 3D Reconstruction: A 3D World Model with Disentangled Ego-Motion" (2606.18250) introduces FR3D, a world modeling architecture for dynamic 3D scene prediction from monocular visual input. FR3D is motivated by the need for geometric consistency in future scene understanding, particularly under the constraints of physically plausible reasoning required in autonomous driving and embodied planning. The work departs from the prevailing paradigm of video-based (2D) generative world models by predicting a 3D latent representation and, crucially, explicitly decoupling ego-motion from scene dynamics at the latent state level.
FR3D Architecture
FR3D receives a sequence of monocular context images and outputs a temporally persistent 3D reconstruction, autoregressively rolling forward poses (ego-motion) and scene structure.
The model employs a teacher-student distillation strategy. The "teacher" is an off-the-shelf pre-trained 3D reconstruction foundation model (such as CUT3R), providing a tokenized latent scene representation. The student model—FR3D—learns to forecast the evolution of these latent tokens, leveraging two masked transformers: one for ego-camera pose (Pose Masked Transformer) and one for scene structure (Spatial Masked Transformer). These transformers process the respective latent tokens, with bidirectional cross-attention to enable interdependent and physically consistent forecasting.
The approach fundamentally differs from feature-based world models that do not disentangle ego-motion from world-motion, a design choice shown to yield more temporally stable and geometry-consistent forecasts—particularly in long-horizon rollout scenarios.

Figure 1: The FR3D world model, taking monocular context images as input, decouples future ego-motion from 3D scene structure, handling highly dynamic traffic and complex maneuvers.
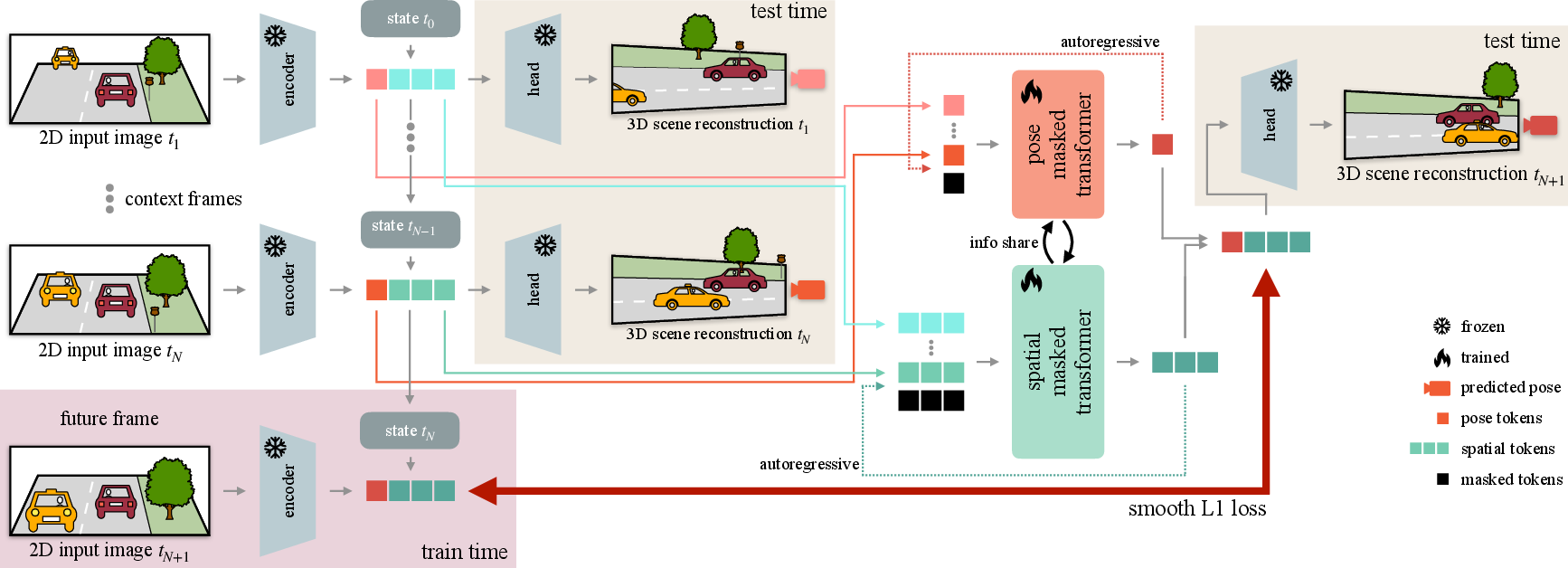
Figure 2: FR3D autoregressively predicts future 3D latent scene tokens and ego poses, decoding them via foundation model heads into consistent depth and pose estimates for each future frame.
Disentanglement Mechanism and Training Paradigm
Decoupling ego-motion from scene evolution is realized by separating pose tokens (camera) and spatial tokens (geometry). Each is rolled forward using dedicated transformers with information sharing through cross-attention. The latter is critical; the dependency of scene appearance on pose (and vice versa in dynamic scenes) allows constraints to propagate, regularizing predictions and improving error control over rollout.
FR3D is trained with an autoregressive, sliding-window strategy, gradually increasing reliance on its own predictions as input. This robustifies the transformers to distributional drift caused by compounding prediction errors. The distillation loss leverages the smooth L1 distance between predicted and "teacher" tokens.
Empirical Results
Quantitative Evaluation
FR3D demonstrates robust zero-shot performance across out-of-distribution datasets, including KITTI and nuScenes, with models trained solely on Waymo sequences. Metrics focus on depth estimation accuracy (AbsR, δ1) and pose accuracy (ATE, RPE_t, RPE_R). Across all horizons (up to 2.5s in nuScenes), FR3D consistently outperforms strong feature-predictive baselines (DINO-Foresight, CUT3R-Foresight) and naive temporal models (Copy Last). Its generalization is attributed to operating in the latent space of the foundation model and effective teacher-student knowledge transfer.
Notably, the model delivers superior long-horizon performance, maintaining geometric stability and outperforming models lacking explicit disentanglement, especially in dynamic scenes.
Qualitative Analysis
Results on challenging, zero-shot dynamic driving scenes display smooth trajectory prediction, successful anticipation of turning maneuvers, and plausible forecasting of the motion of other agents, such as vehicles and cyclists, despite significant visual and motion domain shift.

Figure 3: Qualitative zero-shot predictions by FR3D on nuScenes, demonstrating consistent multi-agent forecasting and robust ego/scene disentanglement.

Figure 4: Left-turn maneuver predicted on nuScenes; FR3D yields a smooth future ego trajectory, while the teacher (oracle) exhibits noisy pose estimates.

Figure 5: Failure cases on Waymo: dynamic objects with strong lateral motion induce prediction errors, mixing lateral and longitudinal motion in the absence of sufficient diverse training data.
Ablation and Analysis
Detailed ablations on Waymo decompose the contribution of autoregressive training, pose-geometry information sharing, and resolution. The joint modeling of pose and spatial features with cross-attention yields the most substantial improvements in long-horizon consistency, both in depth and pose, highlighting the necessity of physically meaningful disentanglement. Experiments further quantify the scale drift under extended rollout—FR3D exhibits some drift relative to the teacher, but background (static) scene regions remain substantially more stable than dynamic foregrounds.
Disentanglement is further validated via a fixed-camera setting, where only world-motion should exist; static regions remain largely invariant in FR3D's rollouts, while dynamic regions change as predicted.
Practical and Theoretical Implications
By forecasting a persistent 3D latent state with pose-geometry disentanglement, FR3D aligns more closely with requirements of embodied planning and control in physical environments—advancing beyond photorealistic "video world" simulators towards agents that reason about explicit 3D geometry. The approach enables robust, zero-shot generalization without the prohibitive data and compute scaling intrinsic to 2D world models. These properties are essential for autonomous driving, robotics, and any domain where agents must maintain physically plausible models of unseen environments over time.
The architecture exposes the limitations of naive 2D feature-based rollouts—specifically, their rapid degradation in geometric consistency and physical validity—and provides a blueprint for integrating strong 3D inductive priors by leveraging foundation model encoders/decoders in a data-efficient, modular student framework.
The observed failure modes—such as lateral motion bias and scale drift—indicate areas for future work, including integration of explicit scale representations, augmentation with more diverse or synthetic data, and stronger hybrid geometric priors (e.g., physics simulators or object-level reasoning).
Conclusion
FR3D sets a new standard for future 3D reconstruction from monocular images, establishing the importance of ego-motion disentanglement and foundation model distillation in dynamic world modeling. The framework's demonstrated generalization and long-horizon stability both empirically and conceptually advance the design of world models suitable for downstream embodied AI tasks. Future research may extend this paradigm to multi-modal sensor input, integrate tighter uncertainty quantification, or more tightly couple the model with downstream planning and decision modules.


