Visual Verification Enables Inference-time Steering and Autonomous Policy Improvement
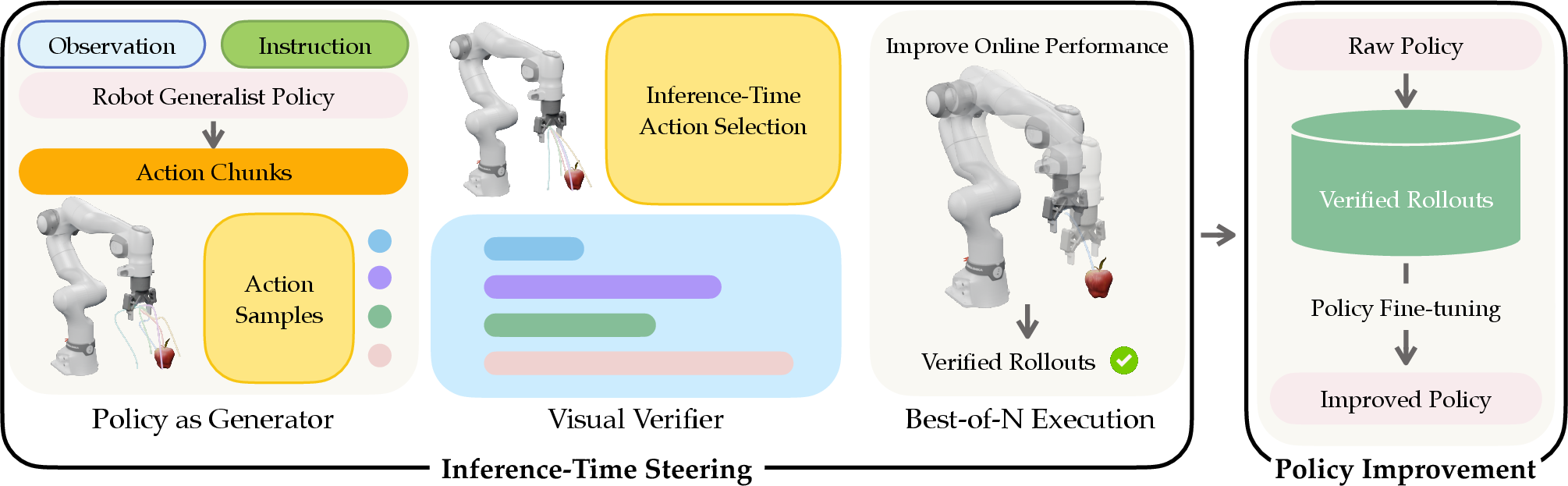
Abstract: Robots deployed in the real world should learn from their experience and improve over time. This requires a mechanism of practicing and learning from feedback. In this paper, we propose VERITAS, a generator-verifier framework for generalist robot policies for inference-time policy steering and self-improvement. We use a pre-trained generalist robot policy as a generator'' and pair it with a gradient-freevisual verifier'' that evaluates actions at inference time. This framework enables inference-time steering that improves policy performance without additional training. We demonstrate that inference-time verification consistently outperforms vanilla generalists without training on additional demonstration data. Additionally, we demonstrate that the verified rollouts provide effective supervision for offline policy improvement: policies fine-tuned on verified self-generated trajectories achieve consistent performance gains. Notably, we find that post-training with verified rollouts achieves comparable efficiency to expert demonstrations, while requiring no human interventions. Our results highlight inference-time verification as a practical and scalable mechanism for improving robotic policies during deployment.


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Explaining “Visual Verification Enables Inference-time Steering and Autonomous Policy Improvement”
What is this paper about?
This paper shows a simple way to make robots smarter while they’re working, without needing more human training data. The idea is to let a robot “try out” several possible moves in its head, have a separate checker look at those choices, and then pick the best one to actually do. The robot also remembers the successful attempts and uses them later to improve itself. The authors call this approach VERITAS.
What questions are the researchers asking?
- Can a robot improve its performance right away—just by thinking harder at decision time—without retraining its main model?
- Can the robot use its own successful attempts as practice data to learn and get even better later on?
- Is this “self-practice” data as useful as expensive human demonstrations?
How does their approach work? (In everyday terms)
Think of a robot with a general “brain” trained on many tasks. VERITAS adds two roles around that brain:
- The generator: like a student who brainstorms several short “mini-plans” (small bursts of actions) it could do next.
- The verifier: like a coach or referee that looks at those mini-plans and scores which one seems most likely to succeed and obey the instructions.
Here’s the simple loop:
- The robot’s brain proposes several short action sequences (like trying different moves in chess before touching a piece).
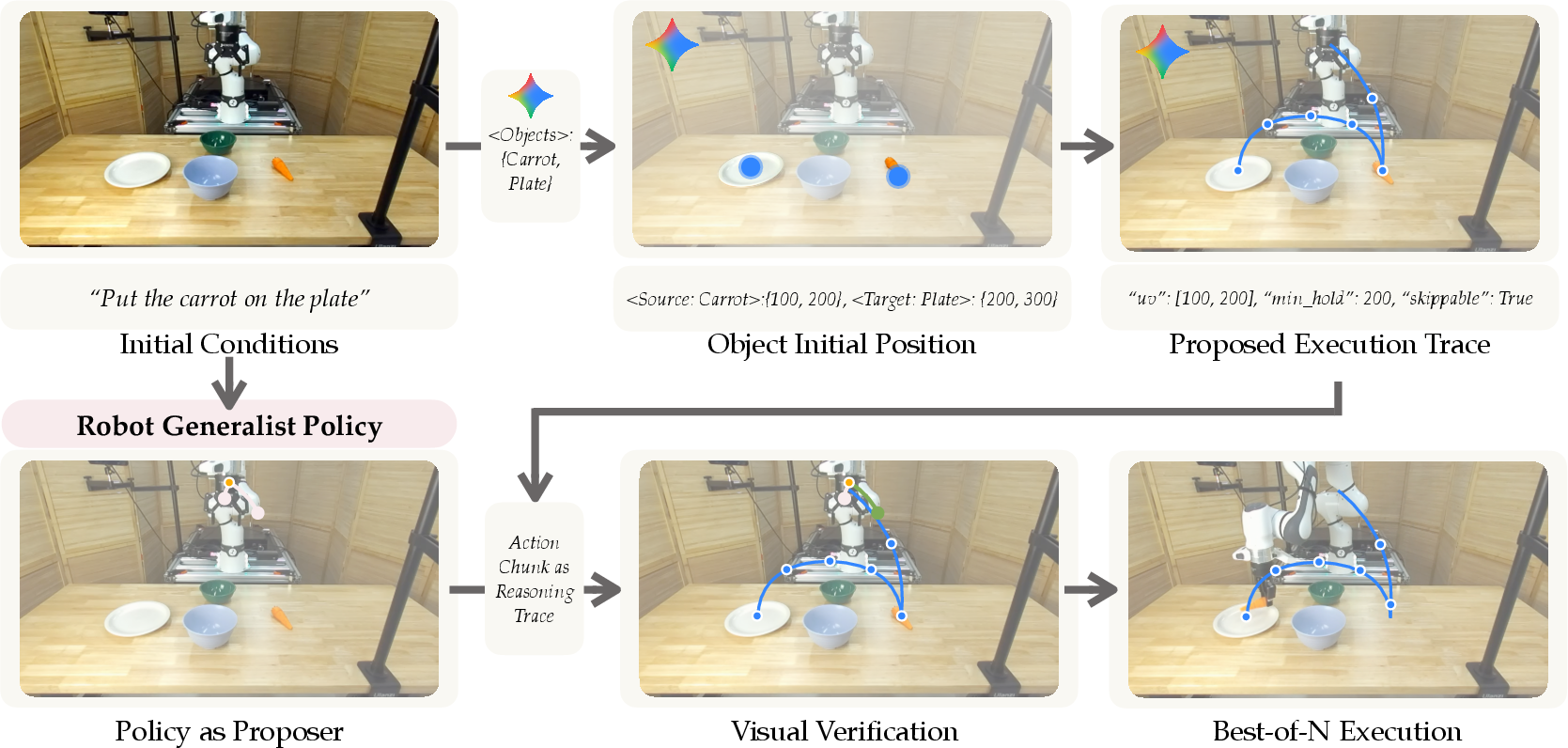
- A visual checker (built using a powerful image-and-text AI) creates a simple visual guide—a few key points in the camera view that outline what a good motion should look like (imagine a dotted line on the image showing the path to follow).
- Each proposed action sequence is scored by how closely it follows that visual guide and whether it looks physically reasonable.
- The robot executes the best-scoring sequence.
- If it works well, the robot saves that successful attempt.
- Later, the robot fine-tunes itself using these saved “good tries,” so it needs fewer guesses next time.
Key terms in plain language:
- Generalist policy: a single robot “brain” that can handle many different tasks, not just one.
- Inference-time steering: steering the robot’s choices while it’s running (no extra training), by testing multiple options and picking the best.
- Action chunks: short sequences of actions (tiny plans) instead of just one tiny move at a time—this gives the checker a bit of “look ahead.”
- Visual verifier: a separate tool that understands the instruction and the camera image, draws a simple path in pixel coordinates, and checks which candidate plan stays closest to that path.
Why this is smart:
- It trades extra thinking (compute) for better performance, instead of needing more human demonstrations.
- The verifier doesn’t need to be trained with gradients; it’s a plug-in checker, so you can add it to many existing robot brains.
What did they find, and why is it important?
The authors tested VERITAS in both simulation and real robots on tabletop tasks like moving or stacking objects.
Main findings:
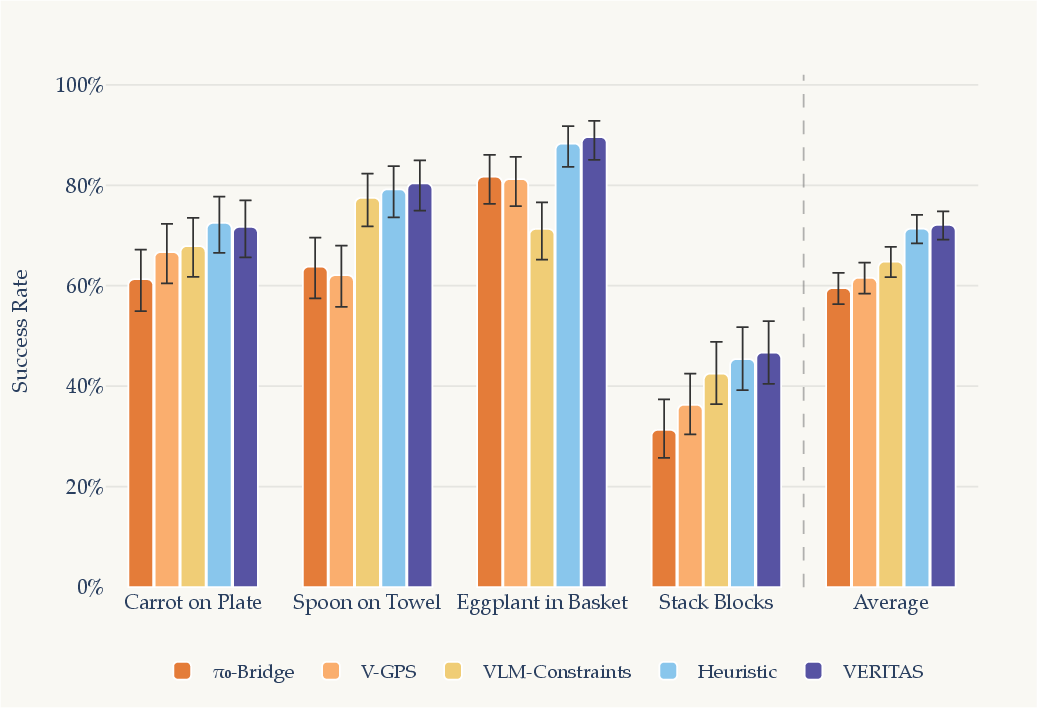
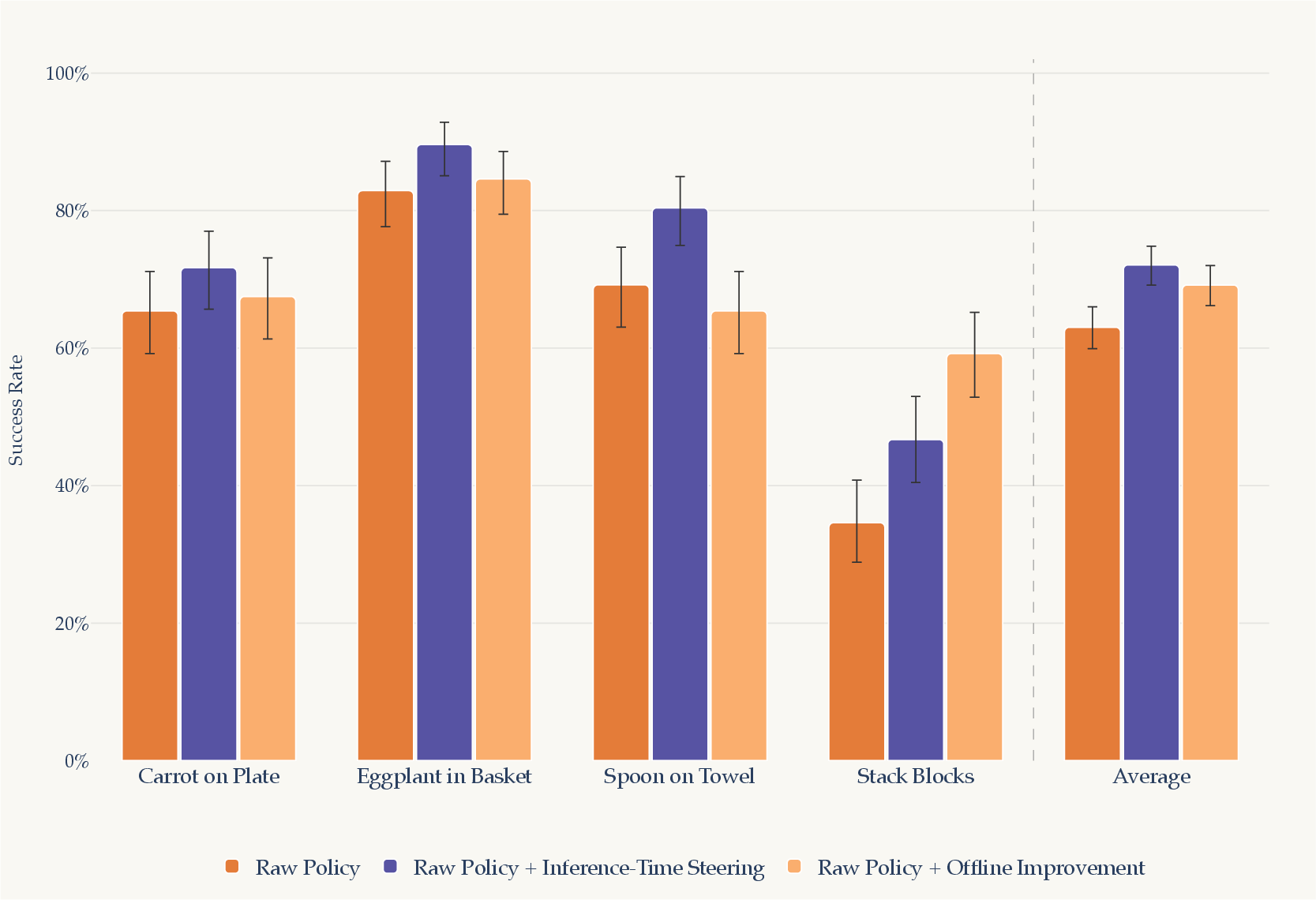
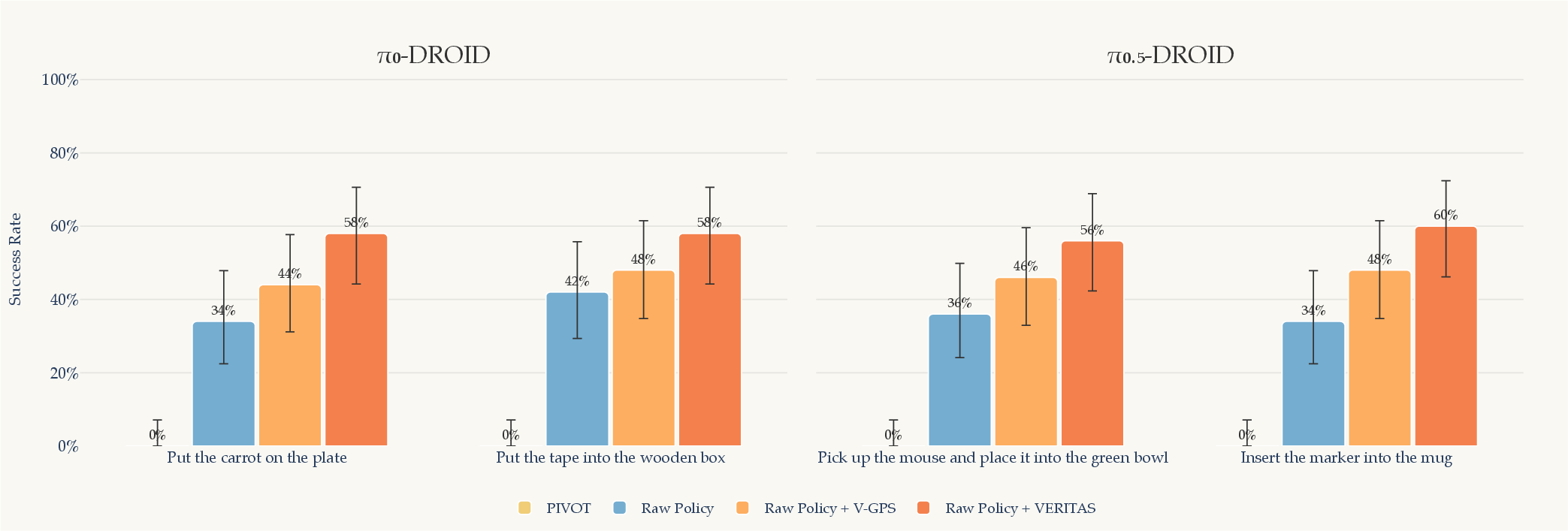
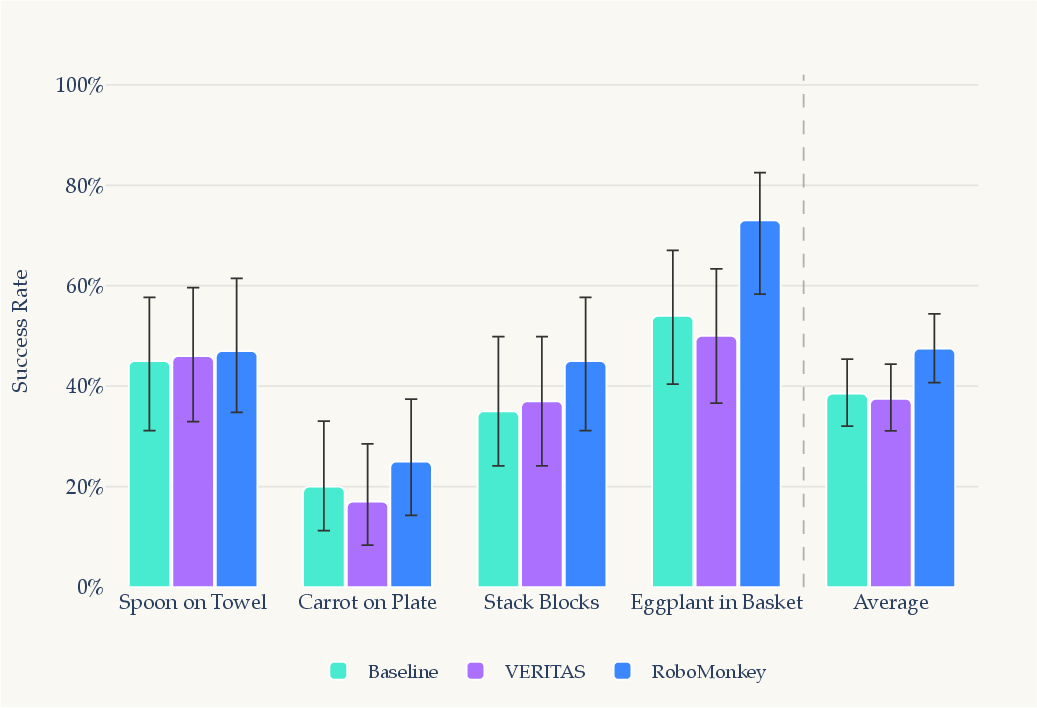
- Immediate gains without retraining: Just sampling a few candidate action chunks (like 5–8) and picking the best improved success rates. On average, success improved by around 12.6% in simulation and about 35% in real-world tests.
- Learning from its own successes: When the robot later fine-tuned on its verified successful attempts, it improved further. In simulation, average success rates rose by about 9.7%, with big boosts on harder tasks (for example, stack blocks went up by ~27.9%).
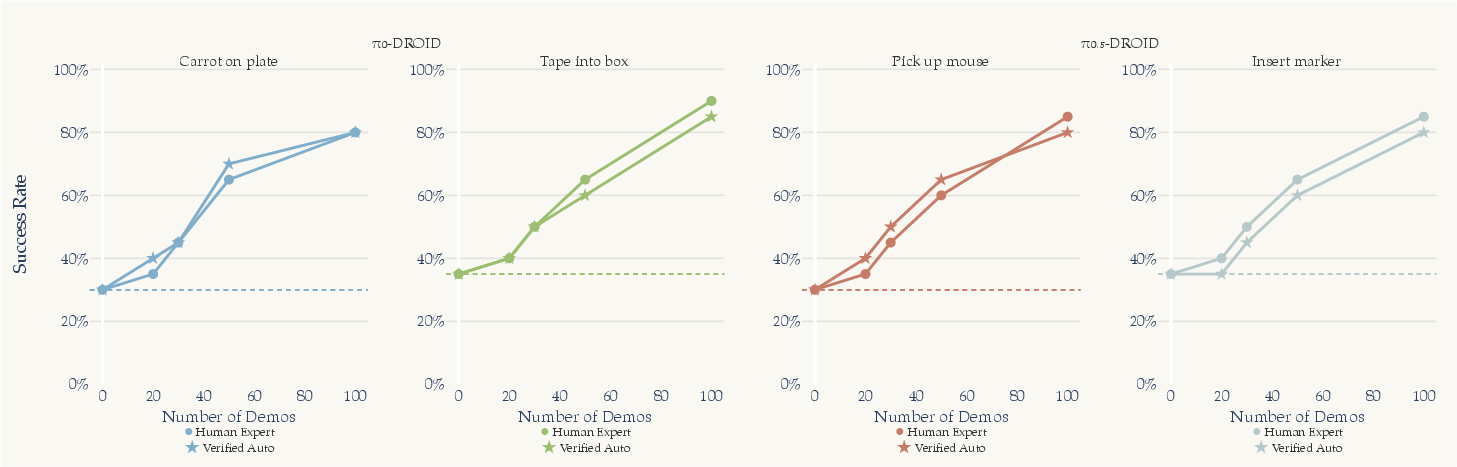
- As good as human demos (at similar sizes): Using 20–100 self-collected, verifier-approved trials to fine-tune the robot often matched or even beat fine-tuning on the same number of human demonstrations. That’s a big deal because human demos are slow and expensive to collect.
- Works across different robot brains and tasks: The method doesn’t depend on one special model; it helped multiple policies in both simulation and the real world.
Why this matters:
- Robots can get better on their own, during deployment, turning their experience into new training data without needing a human teacher.
- It’s safer and more efficient: the robot only executes the best-checked option, and the “good tries” are guaranteed to be physically doable, because the robot just did them.
What’s the bigger impact?
This approach offers a practical path to scalable robot learning:
- Less reliance on human data: The robot gathers its own high-quality practice by verifying itself, which can grow its skills faster and cheaper.
- Turning compute into capability: Instead of collecting more human demos, you can spend a bit more computer power at decision time to get better results.
- Continual improvement: Over time, the robot needs fewer sampled options because it fine-tunes on what worked.
Limitations and future directions:
- It uses more compute at decision time, which might be tricky for very fast, time-critical tasks.
- The visual guide is generated at the start of a task and may struggle if the scene changes a lot mid-task.
- The robot can only pick the best among the options its brain proposes; if none are good, the verifier can’t invent a brand-new move. Stronger base models will make this even better.
In short, VERITAS shows how robots can “think before they act,” pick the smartest move, and then learn from their own successes—getting better with little to no extra help from humans.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a focused list of what remains uncertain or unexplored in the paper, formulated to guide concrete follow-up research.
- Verifier reliability and failure modes
- How robust is the VLM-generated static visual trace to VLM hallucinations, mis-detections, occlusions, lighting changes, and cluttered scenes? Quantify failure rates and their impact on downstream control.
- What is the sensitivity to detector/tracker errors used for object localization, and how should verification degrade gracefully when detections are missing or noisy?
- How does camera calibration error (intrinsics/extrinsics) or end-effector-to-pixel projection error affect verifier scoring and task success?
- Dynamic and non-stationary environments
- The verifier’s visual trace is static per episode; how to update traces online to handle moving objects, tool–object interactions, and scene changes without incurring heavy VLM latency?
- Can closed-loop verification (trace regeneration or local replanning) be done at low latency, and when should the system trigger such updates?
- Physical safety and constraint satisfaction
- The scoring uses geometric adherence to a pixel trace, not explicit safety constraints. How to incorporate collision checking, joint limits, force/torque limits, speed limits, and risk-aware criteria into verification and selection?
- How to prevent “reward hacking” where the policy follows the 2D trace while causing unsafe contacts or failing the true task?
- Predictive fidelity of verification
- The approach scores candidate action chunks using projected end-effector motion without a physics model. How accurate is this prediction in contact-rich tasks (e.g., insertion), deformable objects, or when objects move as a result of actions?
- What minimal forward model (e.g., learned dynamics, contact predictors) is needed to make verification predictive rather than purely geometric?
- Limits of generator quality and diversity
- Best-of- can only select among offered samples; how to ensure sufficient action diversity when the base policy’s action prior is narrow or missing critical modes for a novel task?
- Investigate diversity-promoting sampling, uncertainty-aware/adaptive , and active sampling strategies that trade compute for targeted exploration.
- Verifier generality beyond 2D waypoints
- Many tasks require 3D reasoning, multi-view fusion, depth reasoning, or tactile/force targets (e.g., “insert until seated,” “grasp by the handle”). How to design verifiers that leverage depth, multi-view, proprioceptive, and tactile inputs?
- How to encode non-geometric linguistic constraints (e.g., “gently,” “don’t spill,” “don’t disturb other objects”) into verifiers?
- Continual and online learning
- The paper uses offline fine-tuning on verified trajectories. How to perform safe, continual online updates with safeguards against catastrophic forgetting and distribution drift?
- What data selection, prioritization, or replay strategies best retain coverage and prevent overfitting to verifier-preferred behaviors?
- Biases in self-generated data
- Verified-only logging may bias the dataset toward easy successes and narrow strategies, reducing behavioral diversity. How to incorporate hard negatives, near-misses, and counterfactual relabeling to improve robustness?
- How to detect and correct verifier-induced biases that could steer the policy away from equally valid strategies not favored by the verifier?
- Theoretical characterization
- Provide formal analysis linking verifier accuracy and sample count to expected success improvements; derive conditions under which Best-of- guarantees performance gains and bounds on regret.
- Analyze convergence when distilling verifier-selected behaviors into the policy: will increased alignment reduce the required predictably?
- Compute–latency–performance trade-offs
- Quantify latency, throughput, and energy costs across hardware, control frequencies, horizons , and sample counts ; define guidelines for real-time, latency-critical settings.
- Explore batching, early stopping, or multi-armed bandit allocation of verification budget to balance compute and performance.
- Verifier design and calibration
- Systematically benchmark alternate verifiers (learned value models, constraint checkers, hybrid geometric–learned verifiers) under identical conditions, including calibration curves, AUROC, and task success correlations.
- Develop methods to estimate verifier uncertainty and abstain/ask-for-help policies when confidence is low.
- Long-horizon, hierarchical, and branching tasks
- A single static trace may not capture branching plans or multi-object dependencies. How to couple hierarchical planning (subgoals, skills) with verification at multiple levels of abstraction?
- How to manage language ambiguity and evolving goals (e.g., interactive disambiguation, subgoal verification)?
- Broader benchmarking and generalization
- Real-world evaluation uses two tasks per policy; expand to more tasks, embodiments (mobile manipulation, bimanual), materials (deformables, liquids), and environments to stress-test generality.
- Evaluate cross-robot transfer (camera viewpoints, kinematics), and robustness to environment shifts and camera reconfigurations.
- Success detection and ground-truth evaluation
- What success detectors were used during data curation and evaluation, and how reliable are they? Provide metrics on detector precision/recall and their influence on reported success rates and dataset quality.
- Study cases where the verifier’s notion of “following the trace” diverges from true task completion.
- Interaction with planning and model-based control
- Compare against strong baselines using motion planning (MPC, trajectory optimization) with perception-in-the-loop, and hybrid model-based/model-free controllers.
- Investigate integrating fast planners or world models into the verifier to anticipate contacts, occlusions, and dynamics.
- Prompt sensitivity and VLM choice
- Quantify sensitivity to VLM model choice, prompting strategies, and budget (single vs. multi-call), including robustness to instruction noise and language variations.
- Explore fine-tuning lightweight verifiers versus zero-shot VLMs to balance cost, speed, and reliability.
- Handling partial observability
- The verifier operates on single-view RGB. How to incorporate memory, scene graphs, or persistent object tracking to verify goals under occlusion and across long horizons?
- Data efficiency and cost accounting
- Provide end-to-end cost comparisons (human hours vs. compute hours, cloud costs) to substantiate claims that autonomous data matches human data efficiency in practice.
- Analyze how gains scale with dataset size beyond 100 demos and whether diminishing returns differ between autonomous and human data.
- Reset and autonomy considerations
- Self-improvement experiments assume access to successful executions; describe/reset strategies, automation of resets, and how failure recovery affects scalability and safety in unattended operation.
- Security and misuse risks
- Assess risks of verifier exploitation or adversarial prompts/scenes that could induce unsafe behaviors; propose safeguards and monitoring for real deployments.
- Reproducibility and release
- Critical implementation details (camera calibration, end-effector projection, detectors used, prompts, hyperparameters) are scattered; provide standardized, reproducible configs and ablations to isolate contributions.
Practical Applications
Immediate Applications
Below are concrete, deployable use cases that leverage VERITAS’s generator–verifier framework for inference-time steering and autonomous policy improvement in quasi-static manipulation tasks.
- Robotics & Manufacturing (Assembly, QA, Kitting)
- Use case: Retrofit existing pick-and-place and light assembly cells with inference-time steering to boost success rates without retraining. Deploy a plug-in that samples multiple short action chunks, scores them against a VLM-generated visual trace, and executes the best candidate.
- Tools/Workflows: ROS2/Python plugin for Best-of-N action selection; “TraceGen” module for one-time VLM trace creation; “GeoScore” module for fast per-chunk geometric verification; batched policy inference on a single GPU.
- Assumptions/Dependencies:
- Access to a pre-trained, stochastic generalist policy (e.g., diffusion/flow-matching action head) capable of action chunk sampling.
- Fixed or calibrated camera-to-robot projection for pixel-space scoring; quasi-static scenes (limited need for dynamic trace updates).
- Latency budget that tolerates N≈5–8 samples per decision step; safety interlocks on the robot remain active.
- Warehousing & Logistics (Bin Picking, Order Kitting, Induction)
- Use case: Improve robustness of bin picking and kitting in clutter via inference-time verification of candidate grasps/trajectories; log successful rollouts to self-improve the policy during scheduled maintenance windows.
- Tools/Workflows: Verifier plug-in paired with existing gripper planning stack; nightly offline behavior cloning on verified logs (“Data Flywheel Logger”); A/B gating to ensure no regressions before deploying fine-tuned policy.
- Assumptions/Dependencies:
- Adequate GPU/edge compute for batched sampling.
- Reliable object detection/segmentation for trace conditioning and waypoint grounding.
- Operational policy for data logging/storage and evaluation before policy updates.
- Consumer & Service Robotics (Home Assistance, Hospitality)
- Use case: Increase reliability for routine tasks such as “pick up cup,” “load dishwasher,” or “set table” by using visual guardrails to steer the robot’s motions; continually refine the robot with self-generated, verified data.
- Tools/Workflows: On-device VERITAS module with low-rate VLM trace generation at task start; optional cloud VLM if local models are unavailable; periodic local fine-tuning.
- Assumptions/Dependencies:
- Non-time-critical tasks where sampling overhead is acceptable.
- Stable lighting and camera placement; robust projection of end-effector to image plane.
- Home privacy policies for visual data logging; user consent mechanisms.
- Healthcare Logistics (Non-Clinical Manipulation)
- Use case: Automate hospital supply handling (fetching trays, organizing tools, restocking) with inference-time steering to reduce human supervision and errors; offline self-improvement tuned to hospital-specific layouts.
- Tools/Workflows: Verifier “guardrail” overlay for manipulation tasks; audit trails for verified rollouts; offline fine-tuning with approval gating.
- Assumptions/Dependencies:
- Excludes direct patient-contact procedures; focuses on logistics where quasi-static manipulation is sufficient.
- Compliance with hospital IT/security and data governance; reliable VLM/detector performance on institutional objects.
- R&D and Academia (Lab Automation, Benchmarking)
- Use case: Reduce demo-collection burden in research labs by steering generalist policies and using verified successes as on-policy training data; rapidly iterate across tasks and embodiments.
- Tools/Workflows: Open-source VERITAS SDK; experiment harness for Best-of-N; data curation scripts to auto-filter high-quality rollouts; reproducibility checklists for continual learning.
- Assumptions/Dependencies:
- Availability of open-source generalist policies and VLMs; lab compute for batched inference.
- Calibrated cameras and standard robot kinematics.
- Software & Tooling Vendors (Robotics MLOps)
- Use case: Offer “VERITAS-as-a-Module” for inference-time steering and “Verifier SDK” for domain-specific verifiers (geometric, value-based, hybrid); provide a turnkey “Data Flywheel” pipeline for autonomous post-training.
- Tools/Workflows: Containerized microservices (TraceGen, GeoScore, Logger, Offline BC Trainer); monitoring dashboards for sample count vs. success gains; policies for safe deployment/gating.
- Assumptions/Dependencies:
- Customer robots already run generalist policies; contract terms for data usage and model updates.
- Versioned model registry and rollback mechanisms.
- Safety & Quality Assurance (Cross-Sector)
- Use case: Add the visual verifier as a low-latency “safety filter” to reject implausible or off-task motions; log accept/reject decisions for audits and model debugging.
- Tools/Workflows: Policy-independent scoring module; configurable thresholds for production; red-team scenarios to stress-test verifier selectivity.
- Assumptions/Dependencies:
- Verifier’s false-negative/false-positive trade-offs tuned to environment.
- Clear safety-of-inference compute budgets and fallback behaviors.
- Policy & Operations (Data and Governance)
- Use case: Establish governance processes for self-improving robots: auditing verified logs, provenance tracking for autonomous data, and approval workflows for deploying fine-tuned policies.
- Tools/Workflows: Data retention policies; differential testing against regression suites; human-in-the-loop gates for safety-critical sites.
- Assumptions/Dependencies:
- Legal/privacy compliance for stored video and traces.
- Organizational readiness for continual model lifecycle management.
Long-Term Applications
These applications require further research, scaling, or development to handle dynamics, tighter latency constraints, certification, or more complex embodiments.
- Dynamic, Changing Environments (Retail, Conveyor Tracking, Construction)
- Use case: Extend the verifier to update visual traces online (dynamic trace generation and tracking) so robots can handle moving objects and people.
- Tools/Workflows: Streaming VLM with fast waypoint revision; tighter coupling with object trackers; joint generator–verifier optimization to reduce sample count.
- Assumptions/Dependencies:
- Stable, low-latency perception stack; reliable online re-planning.
- Robustness to occlusions and scene changes not covered by static traces.
- Mobile Manipulation (Hospitals, Hotels, Offices, Warehouses)
- Use case: Couple navigation and manipulation within a unified generator–verifier planner, steering both path plans and manipulation sequences for longer horizons.
- Tools/Workflows: Multi-camera/3D verifiers; value-function distillation of verifier logic for faster inference; integration with SLAM/semantic maps.
- Assumptions/Dependencies:
- Spatiotemporal verifiers with 3D constraints; fleet coordination.
- Richer action priors for long-horizon tasks.
- Safety-Critical Robotics (Surgical Assistance, Laboratory Automation)
- Use case: Certifiable verifiers that provide formal guarantees on trajectory safety and task compliance; combine learned verifiers with rule-based constraints and physics checks.
- Tools/Workflows: Formal methods for verifier thresholds; hybrid safety monitors; compliance documentation and audits.
- Assumptions/Dependencies:
- Regulatory approval; interpretable verifiers; rigorous hazard analysis.
- Extremely low tolerance for false positives/negatives.
- Foundation-Model-Scale Self-Improvement (Cross-Embodiment)
- Use case: Use verifier-curated, on-policy data at scale to continually post-train generalist robot models across multiple embodiments and sites; establish a “marketplace” for verifier modules tailored to tasks.
- Tools/Workflows: Large-scale fleet data pipelines; federated learning for privacy; standardized verifier interfaces and benchmarks.
- Assumptions/Dependencies:
- Cross-site data harmonization, de-identification, and contracts; compute scaling and cost controls.
- Mechanisms to prevent data drift and negative transfer.
- Distilled, Low-Compute Steering (Edge/Embedded Platforms)
- Use case: Distill verifier rejection logic into compact value functions or policies to achieve near real-time steering on edge hardware or micro-controllers.
- Tools/Workflows: Knowledge distillation from VLM-based verifiers; hardware acceleration for sampling; adaptive N selection based on uncertainty.
- Assumptions/Dependencies:
- Sufficient training data for distillation; acceptable approximation error.
- Hardware support for batched inference and on-device learning.
- Cross-Modal Verifiers (Audio–Tactile–Vision)
- Use case: Incorporate tactile/force feedback and audio cues into the verifier for tasks requiring finesse (e.g., insertion, textiles).
- Tools/Workflows: Multi-sensor fusion; temporal consistency scoring; learned simulators for counterfactual scoring.
- Assumptions/Dependencies:
- High-quality tactile/force sensors; robust sensor fusion in the loop.
- Data for training multi-modal verifiers.
- Policy & Standards for Autonomous Self-Improvement
- Use case: Sector-wide standards on how robots collect and use autonomous, verified data; requirements for traceability, user consent, and safety gating.
- Tools/Workflows: Compliance frameworks, audit trails, redlines for deployment without human demos.
- Assumptions/Dependencies:
- Regulatory engagement; consensus on acceptable risk; third-party certification ecosystems.
- Energy & Utilities (Inspection and Manipulation)
- Use case: Extend to outdoor/industrial settings (valve turning, switch operations) with robust verifiers that handle variable lighting, weather, and complex geometry.
- Tools/Workflows: 3D/pose-level verifiers; learned value functions combined with physics constraints; ruggedized sensors.
- Assumptions/Dependencies:
- Domain adaptation for perception; safety protocols for high-risk equipment.
- More expressive action priors for non-tabletop tasks.
- Business Models & Finance (Robotics-as-a-Service)
- Use case: Offer service tiers that trade compute for reduced human demonstration costs; charge for verified self-improvement cycles and policy update SLAs.
- Tools/Workflows: Cost models for compute vs. human data; telemetry on sample counts vs. success improvements; contractual KPIs around autonomy gains.
- Assumptions/Dependencies:
- Transparent ROI models; customer acceptance of autonomous model updates; clear rollback/rollback guarantees.
Notes on Assumptions and Dependencies (Common Across Applications)
- Pre-trained generalist policy must support stochastic sampling of action chunks (e.g., diffusion/flow-matching) and operate within the robot’s kinematic limits.
- Visual verifier requires:
- A competent VLM (local or cloud) to generate static or dynamic pixel-space waypoints.
- Object detection/tracking to ground waypoints when using reference-based traces.
- Accurate camera–robot calibration to project end-effector into image space.
- Task domain should be quasi-static for immediate deployment; dynamic scenes require future work (online trace updates).
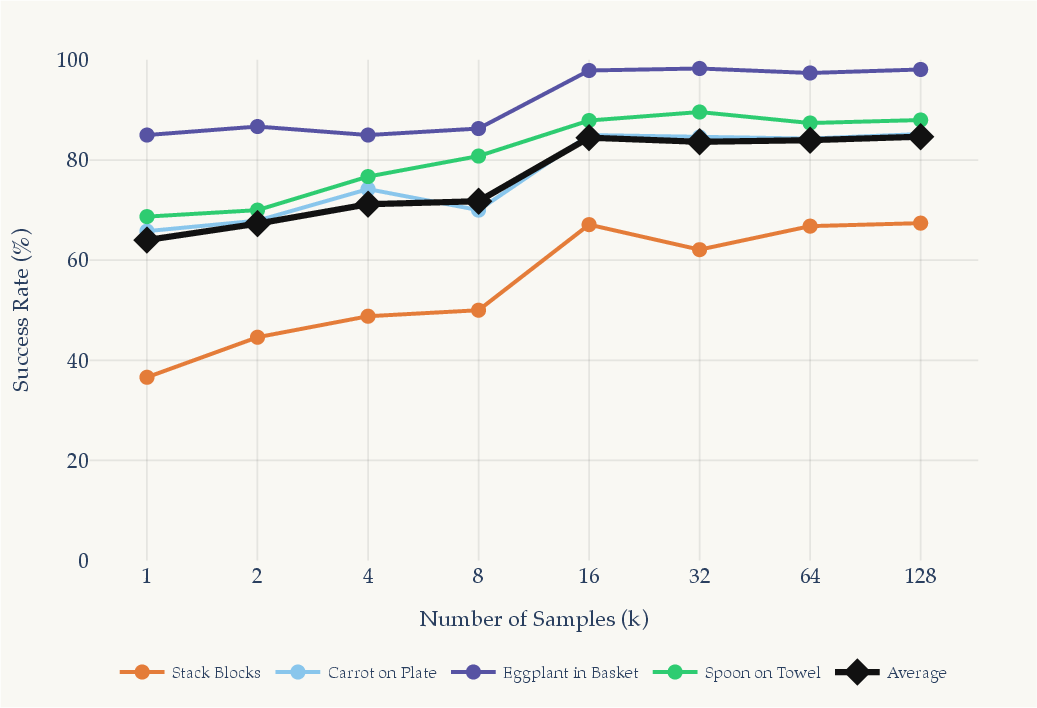
- Compute budget should tolerate Best-of-N sampling; empirical gains saturate around N≈8 with modest overhead.
- Offline improvement demands an MLOps process: high-quality logging, curation of successful rollouts, regression testing, and gated deployment.
- Data governance (privacy, security, IP) and safety compliance are necessary wherever visual data and autonomous updates are used.
Glossary
- Action chunking: Grouping multiple low-level control commands into short sequences executed as a unit to provide temporal context and reduce verification overhead. "we employ action chunking~\cite{zhao2023act, chi2023diffusion}: the policy predicts a sequence of actions of horizon :"
- Action prior: A model’s learned distribution over plausible actions given observations, used as a prior for proposing candidate behaviors. "highlighting the importance of good action priors for improving performance."
- Action primitives: Predefined, parameterized low-level motion or control templates used to compose higher-level behavior. "An approach that uses proposed action primitives and Iterative Visual Optimization for robotic tasks."
- Affordances: Action opportunities offered by the environment that a robot can exploit, such as grasp points or push directions. "exploring diverse, functional affordances~\cite{smith2024STEER} of the scene."
- Behavior cloning: Supervised learning that trains a policy to imitate demonstrated actions from observations. "using standard supervised behavior cloning to obtain updated parameters"
- Best-of-N selection: Test-time strategy of sampling multiple candidate actions and choosing the highest-scored one according to a verifier. "We combine the generator and verifier via Best-of- selection."
- Covariate shift: A mismatch between training and deployment state distributions that causes performance degradation. "standard imitation learning suffers from covariate shift, where policy performance degrades as the robot drifts from the expert's state distribution"
- DAgger: A dataset aggregation algorithm where a learner is trained on states it visits with expert relabeling to mitigate covariate shift. "Classic approaches such as DAgger rely on expert relabeling to correct policy mistakes on-policy"
- Data flywheel: A self-reinforcing loop where deployed executions produce new data that further improves the policy. "forming a data flywheel that distills verification-time reasoning into the policy and enables continual improvement with minimal human supervision."
- Diffusion objectives: Generative training objectives that model action distributions via denoising diffusion processes. "we focus on generative policies trained with flow-matching or diffusion objectives"
- Embodied control: Control methods explicitly accounting for an agent’s physical body and interactions in the environment. "the robotics community has begun exploring mechanisms for embodied control."
- Finite-sample CI: A confidence interval computed from a finite number of trials to quantify uncertainty in measured performance. "Error bars show 95\% finite-sample CI~\cite{vincent2024generalizable}."
- Flow matching: A generative modeling approach that learns continuous-time dynamics to transform noise into data, used here to sample action sequences. "we focus on generative policies trained with flow-matching or diffusion objectives"
- Generator–verifier framework: An architecture where a policy generates candidate actions and an independent module scores and selects among them. "a robotic self-improvement method built around a generator-verifier framework."
- Generalist policy: A single policy trained to perform a wide variety of tasks across domains and embodiments. "A pre-trained generalist policy acts as a stochastic generator"
- Gradient-free: Methods that do not require backpropagation through the verifier or environment to evaluate and select actions. "a gradient-free 'visual verifier' that evaluates actions at inference time."
- Inference-time steering: Adjusting a policy’s behavior at execution time by sampling and selecting actions without updating model parameters. "This framework enables inference-time steering that improves policy performance without additional training."
- Inference-time verification: Evaluating candidate actions at execution time to pick those aligned with the task, improving performance without training. "inference-time verification consistently outperforms vanilla generalists without training on additional demonstration data."
- Iterative Visual Optimization: An optimization procedure that iteratively refines actions using visual feedback to meet task objectives. "An approach that uses proposed action primitives and Iterative Visual Optimization for robotic tasks."
- Kinematically feasible: Actions that are physically executable given the robot’s kinematic constraints. "it is inherently on-policy and kinematically feasible."
- Language-conditioned value function: A value estimator that predicts expected returns given states and natural-language instructions. "trains a language-conditioned value function using offline RL and uses it for steering the generalist policy."
- Mixture-of-transformers: A model architecture that combines multiple transformer experts to process inputs, improving capacity and specialization. "utilizes a mixture-of-transformers backbone with a flow-matching action head."
- Offline policy improvement: Enhancing a policy using previously collected datasets without further environment interaction during training. "provide effective supervision for offline policy improvement"
- Offline reinforcement learning: Learning policies or value functions solely from fixed datasets without online exploration. "using offline RL"
- On-policy: Data generated by the same policy that is being trained or evaluated, aligning training and deployment distributions. "ensuring the training data is strictly on-policy"
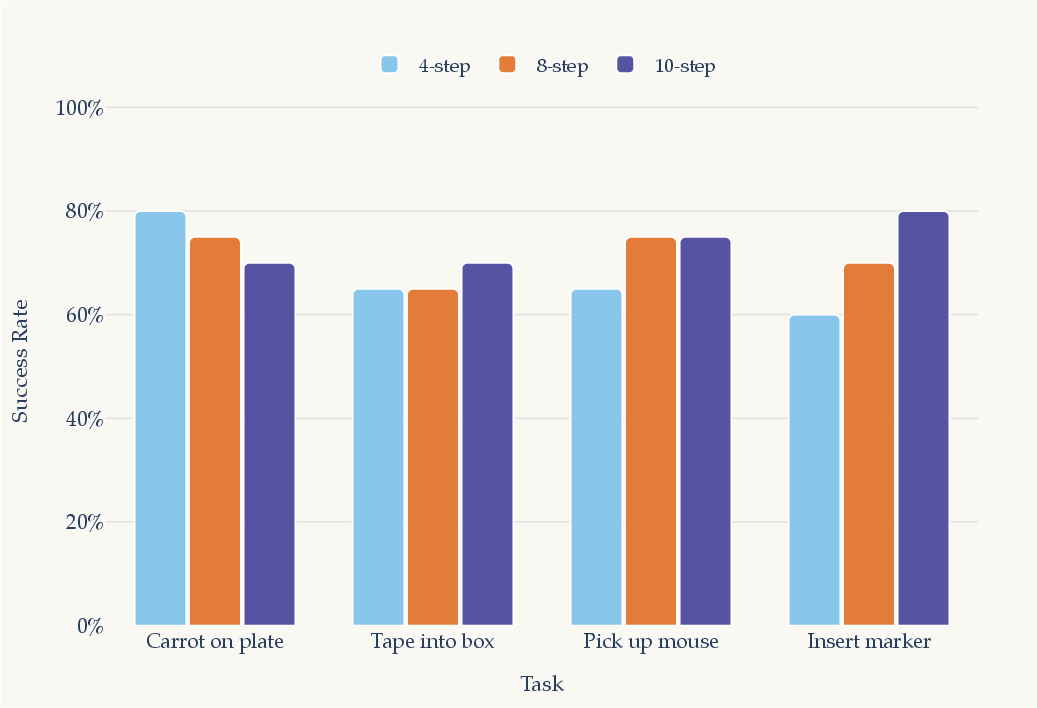
- Open-loop execution: Executing a planned sequence of actions without feedback-based correction during the sequence. "does not significantly degrade with open-loop action execution of up to 10 steps."
- Partially Observable Markov Decision Process (POMDP): A framework modeling decision-making with hidden states and observations that provide partial information. "We formulate the problem of language-guided robotic manipulation as a Partially Observable Markov Decision Process (POMDP)"
- Policy steering: Influencing a policy’s action choices at runtime using external evaluators or constraints. "a generator-verifier framework for generalist robot policies for inference-time policy steering and self-improvement."
- Quasi-static manipulation: Manipulation where motions are slow enough that dynamic effects are negligible, simplifying control and verification. "sufficient for quasi-static manipulation"
- Rollout: A sequence of states and actions produced by executing a policy in an environment. "the verified rollouts provide effective supervision for offline policy improvement"
- Shared autonomy: A paradigm where control is shared between human operators and autonomous systems to improve performance. "shared autonomy frameworks blend human control with autonomous execution"
- Stochastic generator: A policy that samples from a distribution over actions, enabling diverse candidate behaviors. "We instead view the pre-trained policy as a stochastic generator."
- Value function: A function estimating the expected future return from a state (and possibly action), used to assess candidate actions. "Through selecting the best-of- samples using a verifier or value function"
- Vision-Language-Action (VLA): Models that jointly process visual inputs, natural language, and output actions for embodied tasks. "an open-source Vision-Language-Action (VLA) model"
- Vision-LLM (VLM): Models that integrate visual and textual information to perform tasks like grounding, reasoning, and planning. "a frontier vision-LLM (VLM)~\cite{comanici2025gemini}."
- Visual verifier: A verification module that evaluates candidate actions by comparing predicted motion against visually specified goals or traces. "pair it with a gradient-free 'visual verifier' that evaluates actions at inference time."
- World model: A predictive model of environment dynamics used to simulate outcomes of candidate actions for planning or selection. "requires world models' prediction to select reasonable actions for policy steering."
Collections
Sign up for free to add this paper to one or more collections.

