- The paper presents the Equation-to-Behavior paradigm that embeds cognitive models into language models for realistic human persuasion simulations.
- It employs structured prompt engineering and reinforcement learning to align belief-updating with models ranging from Bayesian to motivated reasoning.
- Empirical results from legal decision simulations demonstrate that larger models accurately capture human-like biases and improve persuasion effectiveness.
Cognitive Model-Guided Simulation of Human Persuasion Games with LLMs
Introduction
The simulation of human decision-making in strategic contexts is foundational for robust AI agent design and alignment. "Using Cognitive Models to Improve LLM Simulation of Human Persuasion Games" (2606.17657) addresses the underexplored domain of leveraging formal cognitive and behavioral economic models to direct and evaluate LLM behavior in multi-agent persuasion settings. Standard approaches, relying chiefly on persona-based prompting or preference learning, lack mechanisms to specify or enforce empirically grounded cognitive biases. The Equation-to-Behavior paradigm introduced here offers a methodology for rigorously instantiating a broad spectrum of cognitive models—including Bayesian, affine distorted, motivated updating, and Grether’s α–β models—directly into LLM agents via prompt design and reinforcement learning (RL) objectives.
The experimental setting is structured around strategic Sender-Receiver (prosecutor-judge) interactions modeled from legal decision-making, drawing on richly annotated, crowd-validated trial records from the Old Bailey proceedings. This controlled, high-fidelity environment allows for precise behavioral benchmarking under diverse cognitive specifications, setting a precedent for future studies integrating cognitively precise agents into LLM-based simulations and training pipelines.

Figure 1: Overview of the Equation-to-Behavior approach. Cognitive models specify belief updating for LLM agents, facilitating controllable, realistic simulations in strategic interactions.
The Equation-to-Behavior Paradigm
The central innovation is systematically embedding computational cognitive models as behavioral constraints on LLM simulated agents, rather than relying solely on natural-language persona (“be more skeptical,” “act as a stubborn judge”) which lacks formal cognitive guarantees. The Equation-to-Behavior pipeline comprises (1) prompt engineering: translating belief-updating equations into highly structured prompts, and (2) reinforcement learning: directly optimizing for adherence to cognitive-model-determined belief trajectories.
Four primary model families are considered, capturing the diversity of empirically-validated human updates:
- Bayesian Updating: Normative probabilistic inference, providing baseline rational agent simulations.
- Affine Distortion: Linear interpolation between prior and evidence, controlling conservatism via a mixing coefficient.
- Motivated Updating: Nonlinear distortion toward reference beliefs, modeling motivated reasoning and selective updating.
- Grether’s α–β Model: Generalizes prior/likelihood weighting, explicitly capturing base-rate neglect and over-/underweighting of evidence.
Each model permits explicit parameterization and thus systematic manipulation within agent populations.
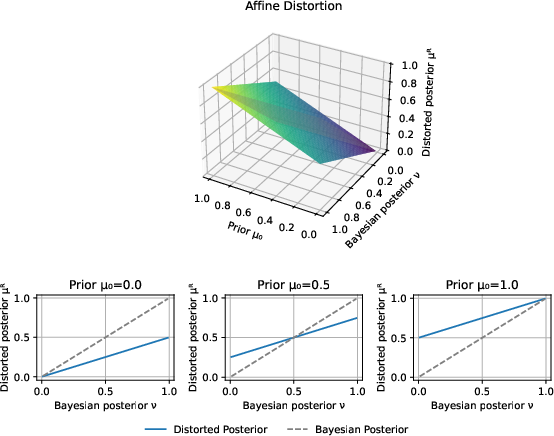
Figure 3: Affine distortion surface; the distorted posterior as a function of Bayesian posterior ν and prior μ0 (top) and cross-sections for selected priors (bottom).
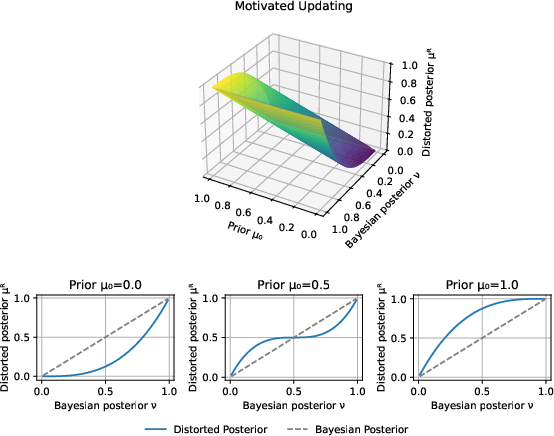
Figure 5: Motivated updating introduces nonlinearity and asymmetry, amplifying evidence in preferred directions.
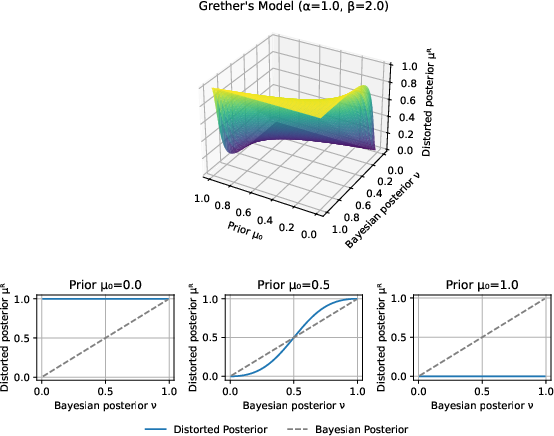
Figure 7: Grether’s α–β model surface; parameter variation induces under- and over-inference effects.
Empirical Evaluation
Dataset and Task Construction
A large-scale trial dataset is constructed from annotated Old Bailey proceedings, with each legal case decomposed into multiple evidential units and dependency structures. Automated LLM annotation is validated by crowdworkers, demonstrating strong inter-annotator agreement on both evidence strength and structural attributes.
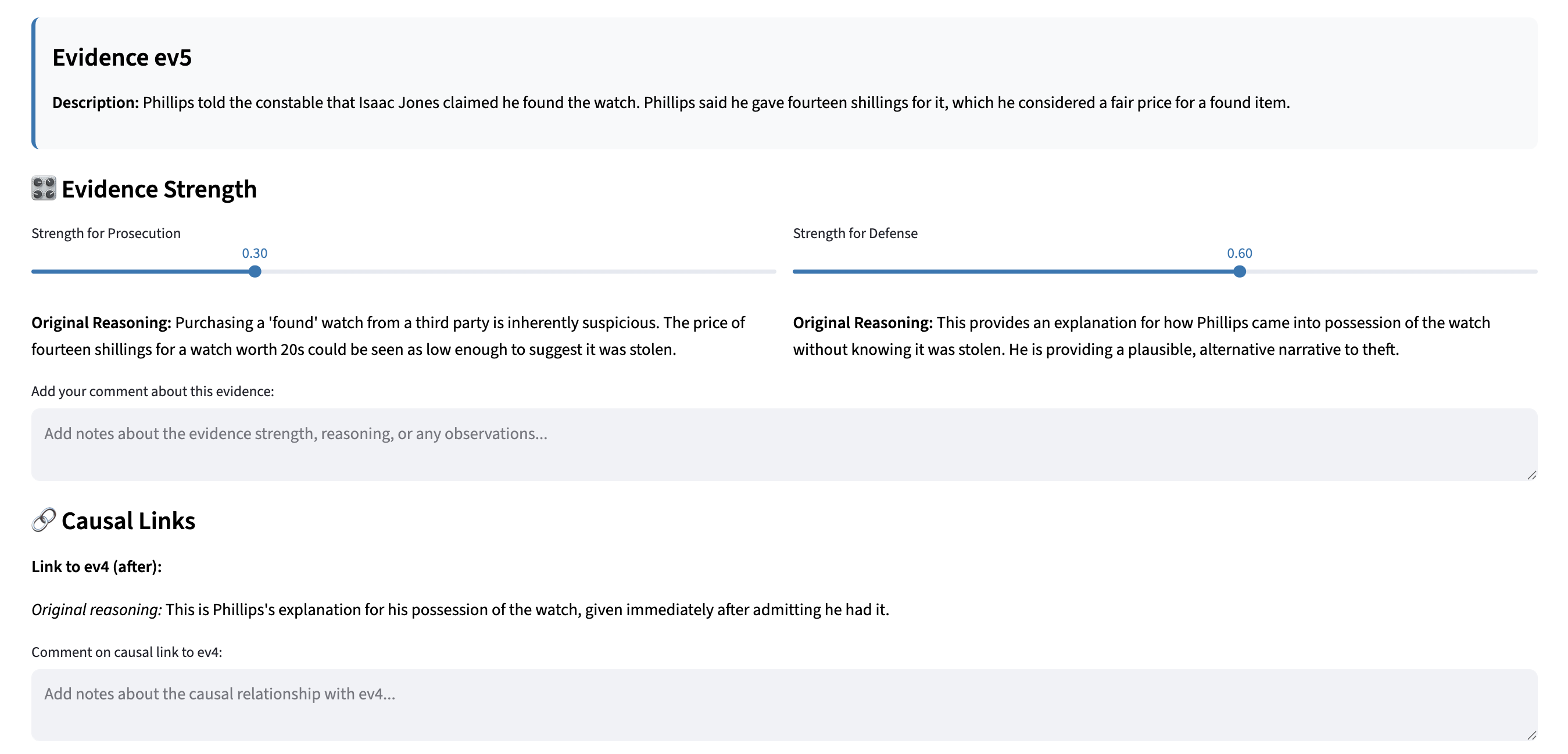
Figure 2: Annotation interface for crowdworkers, used for validating LLM-generated evidential labels and causal links.
Zero-Shot Prompting: Model Capacity and Limitations
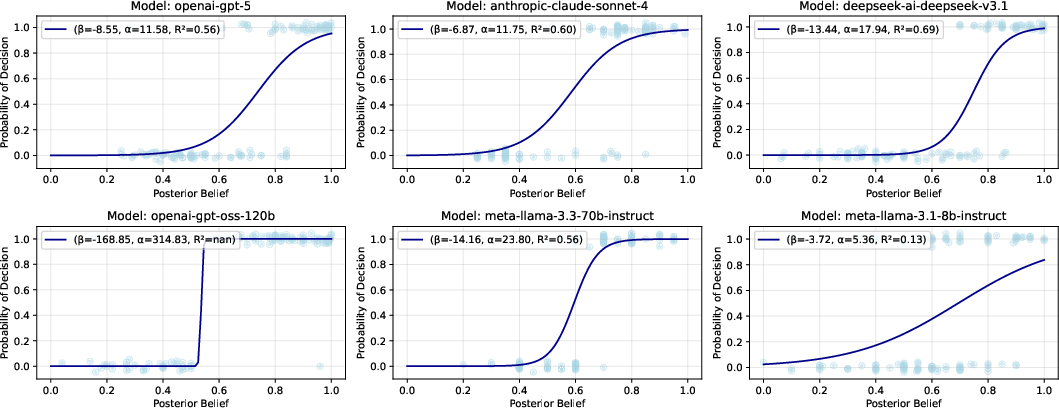
Experiments reveal that large LLMs (GPT-5, Claude-Sonnet-4, DeepSeek-V3.1) can reliably implement parametric updating procedures under Equation-to-Behavior prompts, accurately reproducing both Bayesian and a range of non-Bayesian belief trajectories as anticipated by the theoretical models.
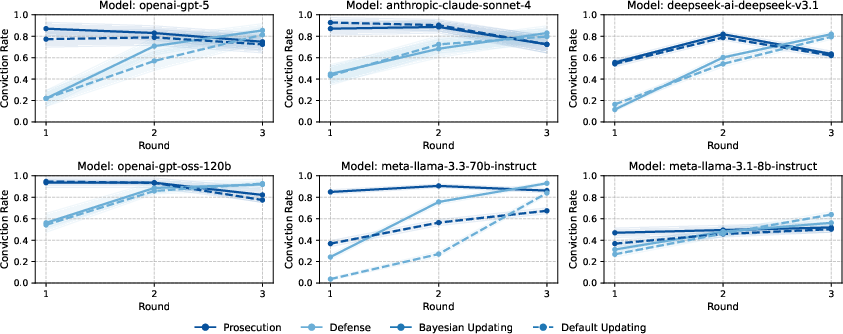
Figure 4: Conviction rates (y-axis) by round under Bayesian or default updating, in prosecution vs. defense-favoring evidence orders. LLMs display order effects and monotonicity violations indicative of human-like biases.
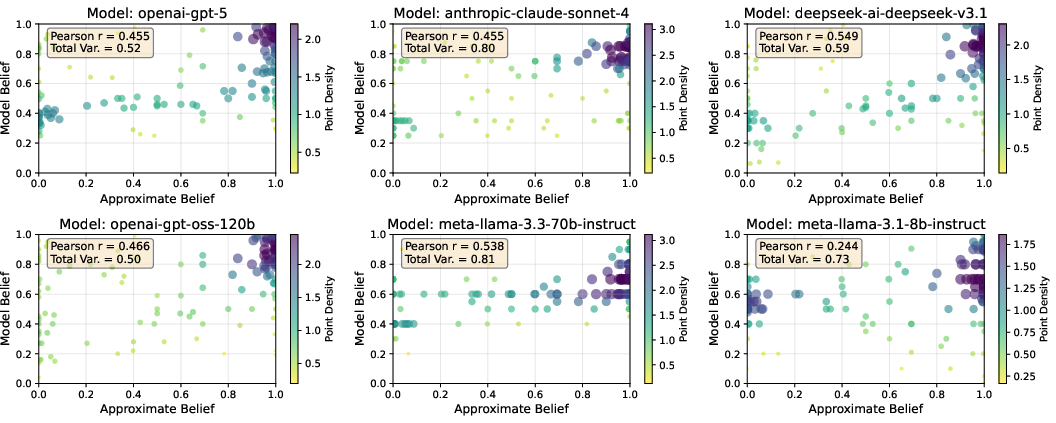
Figure 6: Elicited posterior beliefs from LLMs (realistic) compared to Bayesian predictions (approximate) under independence; large models better approximate Bayesian structure.
Order-of-evidence manipulations clearly induce primacy and recency biases, violating Bayesian order-invariance and mirroring motivational influences observed in human judge populations.
On non-Bayesian models, large LLMs capture convexity, asymmetry, and under/over-inference as parameterized. Smaller models (Llama-3.1-8B, etc.) generally fail to respond reliably to equation-based prompts, defaulting toward baseline rationality.
Reinforcement Learning: Training Small Models to Simulate Human-like Belief Updating
To address prompt-following deficiencies in small-scale models, the authors introduce Equation-to-Behavior RL. Here, LLMs are trained—using the veRL+GRPO RLHF framework—against diverse cognitive reward targets, with explicit L1-based rewards measuring distance to ground-truth belief trajectories for sampled cognitive model parameterizations.
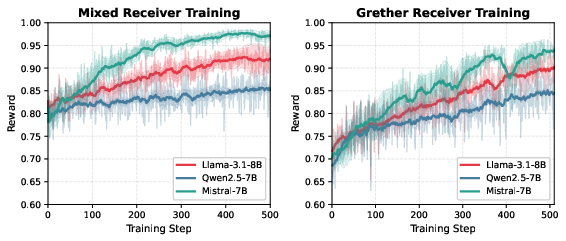
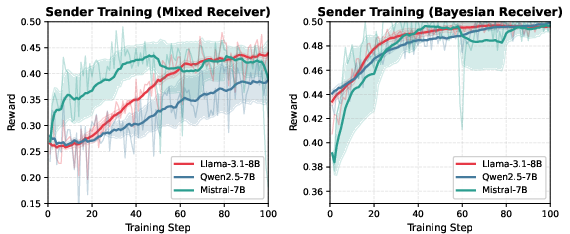
Figure 8: RL reward curves for Receiver training. All three models (Llama-3.1-8B, Qwen-2.5-7B, Mistral-7B) show significant post-training improvement, approaching ground-truth beliefs.
Quantitatively, trained models generalize robustly to both out-of-distribution parameter settings and to cognitive models not encountered during training, with mean belief error reductions of approximately 26.5% and consistent improvements across Grether, affine, motivated, divisible (non-Bayesian), and correlation-neglect regimes.
Mechanistic and Behavioral Analysis
Finer-grained behavioral analyses underscore that:
Downstream and Generalization Impacts
Training Senders against Realistically Heterogeneous Receivers
Senders trained exclusively against Bayesian Receivers exhibit suboptimal strategies in mixed-parameter environments. RL-based sender training against diverse, cognitively parametrized receivers yields improvements of 2.5%–12% in average belief change (persuasion effectiveness), showing direct utility for curricula including realistic cognitive heterogeneity.
Realistic Evaluation: Equation-to-Behavior versus Persona Prompting
Equation-to-Behavior Prompting achieves higher verdict match rates to real judges than persona-based prompting in simulated Old Bailey sessions, with gains of up to 9.1% (Claude-Sonnet-4), underscoring the value of explicit parametric control over behavioral simulation.
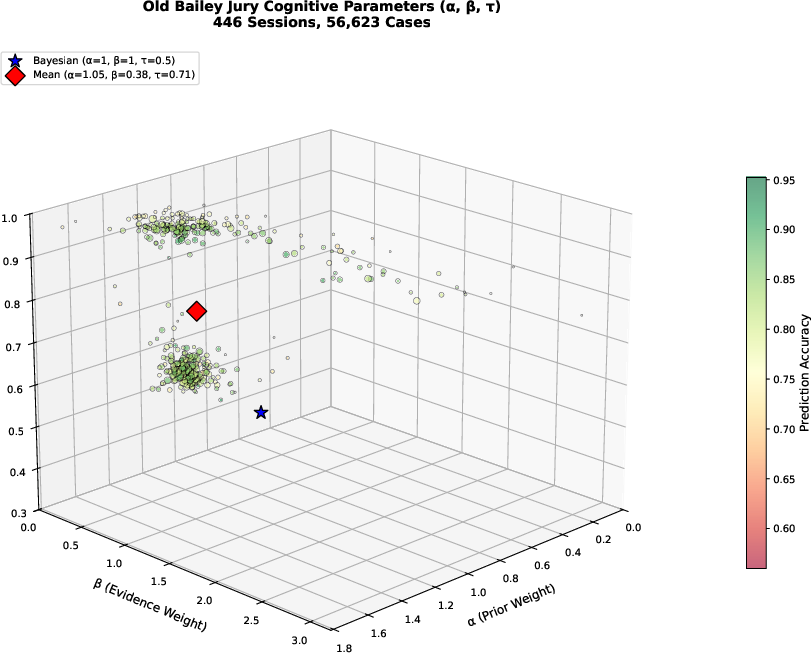
Figure 12: Distribution of Grether β0–β1 parameters across 446 real court sessions, justifying the need for empirically diverse cognitive simulations.
Implications and Future Directions
The Equation-to-Behavior framework provides a generalizable paradigm for LLM agent design and evaluation in strategic environments, facilitating both high-fidelity simulation of human cognitive diversity and modular transfer to reinforcement learning pipelines. The findings underscore several key implications:
- Practical: AI systems deployed as social agents, policy advisors, or legal simulators should incorporate robust modeling of heterogeneous, empirically observed human inference patterns to prevent systematic failures and misalignment.
- Theoretical: Results confirm the non-existence of universally optimal persuasion strategies due to the impossibility of globally ranking updating rules; thus, robust agent design mandates explicit modeling of receiver cognitive diversity [de_clippel2022non-bayesian].
- Methodological: Fine-tuning smaller LLMs in environments constructed from Equation-to-Behavior models enables efficient, scalable training for heterogeneity without large-scale human data collection.
Future research trajectories include extending these frameworks to broader strategic settings (negotiation, discourse, voting), developing more refined or higher-dimensional cognitive model classes, and integrating cognitive control into multi-modal and embodied AI agents.
Conclusion
This work establishes both a theoretical and practical foundation for embedding cognitive science and behavioral economic models within LLM agents, enabling calibrated, controllable, and realistic simulation of human strategic decision-making across persuasive social domains. The results indicate that even small-scale open LLMs, when appropriately trained, can robustly instantiate empirically validated belief updating behaviors, facilitating their use in scalable training, evaluation, and alignment workflows for interactive AI agents.