Improving Behavioral Alignment in LLM Social Simulations via Context Formation and Navigation
Abstract: LLMs are increasingly used to simulate human behavior in experimental settings, but they systematically diverge from human decisions in complex decision-making environments, where participants must anticipate others' actions and form beliefs based on observed behavior. We propose a two-stage framework for improving behavioral alignment. The first stage, context formation, explicitly specifies the experimental design to establish an accurate representation of the decision task and its context. The second stage, context navigation, guides the reasoning process within that representation to make decisions. We validate this framework through a focal replication of a sequential purchasing game with quality signaling (Kremer and Debo, 2016), extending to a crowdfunding game with costly signaling (Cason et al., 2025) and a demand-estimation task (Gui and Toubia, 2025) to test generalizability across decision environments. Across four state-of-the-art (SOTA) models (GPT-4o, GPT-5, Claude-4.0-Sonnet-Thinking, DeepSeek-R1), we find that complex decision-making environments require both stages to achieve behavioral alignment with human benchmarks, whereas the simpler demand-estimation task requires only context formation. Our findings clarify when each stage is necessary and provide a systematic approach for designing and diagnosing LLM social simulations as complements to human subjects in behavioral research.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper is about teaching LLMs—like advanced chatbots—to act like human participants in experiments. The authors show that LLMs can sometimes make very different choices from people, especially in tricky situations where you have to think about what others might do. They introduce a simple two-step method to make LLMs’ choices match human behavior much better.
What questions is the paper trying to answer?
The paper asks: When we use LLMs to “pretend” to be people in research studies, how can we make their choices line up with real human decisions—especially in complex situations where people watch others, learn from signals, and change their beliefs?
How did the researchers test their idea?
The authors propose a two-step framework, inspired by how people solve problems:
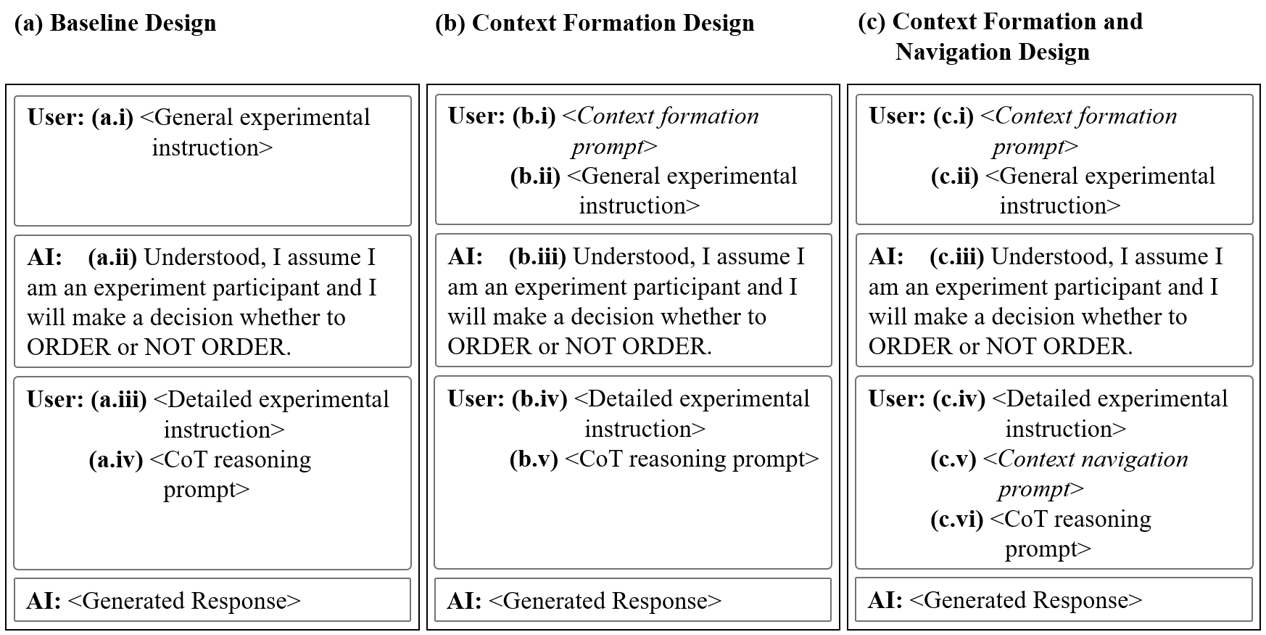
- Step 1: Context formation. Make sure the model clearly understands the full setup of the task—what the rules are, what information is available, and what the goal is. Think of this like giving the model a detailed map of the game it’s playing.
- Step 2: Context navigation. Guide the model on how to reason inside that setup—how to use clues, update beliefs, and choose. This is like giving it directions on how to move through the map to reach the goal.
They compared three prompting styles:
- Baseline: Only basic instructions (and a standard “think step by step” nudge), but no special help forming the context or navigating it.
- Context formation only: Make the task setup very explicit, but don’t guide the reasoning steps.
- Context formation + navigation: Make the task setup explicit and also guide how to reason with it.
They tested this on three different decision problems and checked whether the LLMs’ choices matched known human results:
- A sequential buying game with quality signaling: People see wait times or queues and use them as hints about product quality. Example: if no one is waiting, maybe the product is bad; if there’s a long queue, maybe it’s good.
- A crowdfunding game with costly signaling: Backers send signals that can cost them, and others decide whether to join based on those signals.
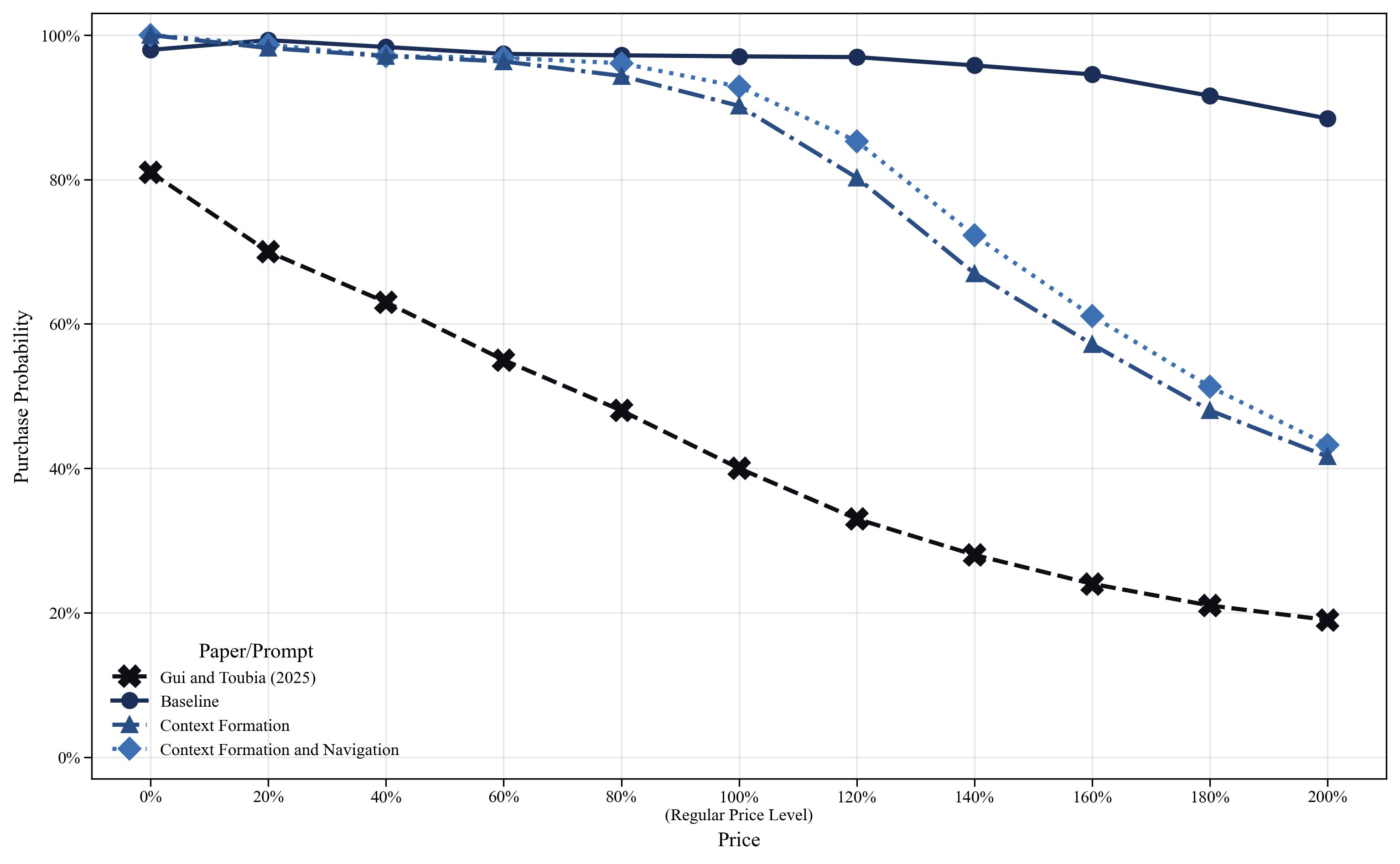
- A simple demand task: People’s choices follow the basic “law of demand” (if price goes up, people buy less).
They tried several state-of-the-art models (GPT-4o, GPT-5, Claude 4.0 Sonnet-Thinking, DeepSeek-R1) and checked how close their choices were to human data.
Key terms in plain language:
- Social simulation: Letting AI “stand in” for people in experiments.
- Behavioral alignment: How closely AI decisions match human decisions.
- Strategic interdependence: Your best move depends on what others do.
- Belief formation: Changing your mind when you see new clues (like a queue length).
- Signaling: Sending a clue to others (like a wait time or a costly action) that tells them something hidden (like quality).
What did they find, and why is it important?
Main findings:
- In complex, strategic situations (like the queue and crowdfunding games), you need both steps—context formation and context navigation—to match human behavior. If you only give the model the rules (map) but no reasoning guidance (directions), it often still behaves differently than humans.
- In simpler tasks (like the demand task), just context formation (a clear map) is usually enough for the model to match human choices.
- Generic “think step by step” prompts alone are not reliable. If the model’s mental picture of the task is wrong or incomplete, careful reasoning won’t help—it will just reason well about the wrong thing.
Why this matters:
- Researchers and companies want to use LLMs instead of expensive, slow human experiments when possible. But they need to trust that the AI will behave like people. This paper shows a practical way to make that happen more reliably, especially in harder, more realistic settings where people watch others and learn from signals.
Concrete example from the queue experiment:
- Without the two-step method, the model ignored the idea that the queue reveals product quality. It just did a simple math comparison and often made different choices than people.
- With both steps, the model started using the wait time as a clue—just like humans—and its choices matched the human results.
What does this mean for the future?
- When a decision environment is simple, giving the model a clear description of the task can be enough.
- When the environment is complex and social (people react to others and to signals), you must also guide how the model should reason: hold an initial belief, look at clues, update that belief, then decide.
- As LLMs get better at reasoning, they may need less hand-holding on navigation—but they will still need clear, accurate context formation. If the “map” is wrong, even a smart model will go the wrong way.
- This framework offers a checklist for building trustworthy AI social simulations: first fix the model’s understanding of the setup, then guide how it should think within that setup. This can help academics and practitioners design better simulations, diagnose why they fail, and know what to tweak.
In short, the paper gives a clear, practical recipe for making AI “act human” in experiments: give it the right map and the right directions—especially in complex social situations where people read signals and adjust their beliefs.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a consolidated list of concrete gaps, limitations, and open questions that the paper leaves unresolved and that future research could address:
- Formalize and empirically validate the assumption that, conditional on identical inputs , across tasks and models; provide quantitative bounds, diagnostics, and failure cases.
- Operationalize “complex decision-making environments” with measurable constructs (e.g., indices of strategic interdependence, belief-updating complexity, information asymmetry) to predict when context navigation is necessary.
- Develop validated methods to measure the internal task representation and navigation strategy (beyond inspecting CoT traces), such as pre-decision comprehension checks, structured process-tracing, and third-party coding of reasoning steps.
- Test for and mitigate training-data leakage (e.g., models memorizing published experiments), using obfuscated task framings, novel payoff structures, and unseen experimental variants to ensure alignment is not driven by memorized results.
- Expand evaluation beyond the focal and two additional tasks to a broader, diverse suite (multi-round, dynamic games, bargaining, auctions, negotiations, social dilemmas) to assess generalizability.
- Quantify model sensitivity and reproducibility across versions, providers, and families (including fully open-source models) and document how RLHF/RLVR or system-level instructions affect alignment.
- Systematically study inference-time parameter sensitivity (temperature, top-p, sampling strategies, self-consistency) on alignment outcomes and variance, with standardized protocols and multi-seed replication.
- Incorporate and validate human-like heterogeneity (e.g., demographics, cognitive styles, risk preferences) rather than relying on a single homogeneous LLM agent; evaluate if personas or calibrated priors improve distributional alignment.
- Design and compare principled navigation prompts that map to human heuristics (e.g., bounded Bayesian updating, recognition of social signals, rule-of-thumb thresholds) and quantify which elements drive improvements (ablation studies).
- Distinguish the effects of prompt content from length or structure; run controlled ablations to test whether alignment gains stem from specific context formation elements versus generic verbosity or framing.
- Provide effect-size alignment, not only significance-based replication: compare estimated coefficients and marginal effects to human benchmarks with appropriate clustering and uncertainty quantification.
- Address ecological validity trade-offs: when and how should “unblinding” (explicit context formation) be applied without inducing demand characteristics that depart from human experimental conditions?
- Evaluate alignment in interactive, repeated, and learning environments (agents updating beliefs over rounds, memory across interactions, social feedback), rather than one-shot sequential decisions without memory.
- Measure belief alignment explicitly (e.g., eliciting posterior beliefs, confidence, perceived signal informativeness) to verify that action alignment is underpinned by human-like belief formation.
- Test robustness under parametric perturbations (changing priors, payoffs, costs, signal structures) to assess whether the framework adapts or overfits to one design.
- Quantify whether “advanced reasoning models reduce reliance on navigation” with cross-model comparisons and controlled reasoning interventions; report the magnitude of reduction and residual need for guidance.
- Explore hybrid approaches that combine the proposed framework with light calibration/fine-tuning on related human datasets; measure sample efficiency and cross-task transfer.
- Establish metrics for representation accuracy (C) and navigation fidelity (N) and automate diagnostics (e.g., representation QA probes, contradiction checks, consistency scores) to flag misalignment early.
- Model and tune stochasticity to match human noise levels (e.g., temperature tuning informed by human choice variability) and evaluate whether variance alignment improves external validity.
- Investigate potential over-rationality or unintended biases introduced by navigation prompts; ensure prompts do not push models toward unnatural strategies relative to human bounded rationality.
- Examine cross-linguistic and cross-cultural generalizability: does the framework maintain alignment for non-English tasks or populations with different norms and priors?
- Compare against stronger baselines (persona prompting, social-CoT, ReAct/ToT, few-shot behavior examples) to ensure the demonstrated gains are not benchmark-dependent.
- Provide full replication details (data, code, prompts, seeds, model versions) and standardized benchmarks to facilitate independent verification and cumulative progress.
- Analyze multi-agent reasoning about others’ strategies explicitly (e.g., level-k, cognitive hierarchy, belief hierarchies) and test whether navigation prompts can reliably instantiate such models.
- Address ethical and governance issues in deploying synthetic subjects (e.g., misuse risks, representational harms, bias amplification) and propose safeguards within the framework.
- Evaluate real-world applicability (field-like stimuli, rich interfaces, noisy contexts) beyond tightly controlled, text-only lab replications.
- Test failure modes where context formation might harm alignment (e.g., making latent structure too explicit) and develop criteria for when to keep aspects implicit.
- Differentiate alignment of process versus outcome: ensure models follow human-like reasoning paths rather than only reproducing final choices; propose process-alignment metrics.
- Investigate automatic or semi-automatic prompt generation for context formation and navigation (prompt optimization, meta-prompting) and assess stability across tasks.
Practical Applications
Overview
This paper introduces a two-stage framework to improve behavioral alignment in LLM social simulations:
- Context formation: explicitly specify the experimental design to establish an accurate representation of the decision task and its context.
- Context navigation: guide the reasoning process within that representation to make decisions.
Validated across multiple SOTA models and decision environments, the key finding is environment-contingent: simple, non-strategic tasks often require only context formation; complex, strategically interdependent and belief-driven tasks require both stages. Below are practical, real-world applications derived from these findings, methods, and innovations.
Immediate Applications
The following applications can be deployed now using current LLMs (e.g., GPT-4o, GPT-5, Claude-4.0-Sonnet-Thinking, DeepSeek-R1) and standard toolchains (e.g., LangChain), by incorporating the paper’s context formation and context navigation prompts into existing workflows.
Industry
- Marketing and product research: synthetic pretesting of ads, messages, product descriptions, and pricing in non-strategic settings (e.g., demand estimation, concept tests) using context formation templates.
- Assumptions/dependencies: tasks mirror simple choice architectures; prompt adherence; monitoring for demographic/cultural coverage gaps.
- A/B test acceleration: run “synthetic pilots” to downselect variants before human or live tests, reducing iteration cycles.
- Assumptions/dependencies: human validation for finalists; careful guardrails to avoid replacing live tests.
- UX and conversion optimization: simulate funnel steps with synthetic users to identify friction points when no strategic interdependence is present (e.g., single-user checkout flows).
- Assumptions/dependencies: user heterogeneity modeled via personas; avoid overfitting to prompt personas.
- Pricing research for individual, one-shot choices (e.g., price elasticity screens, willingness-to-pay ladders) under clear instructions.
- Assumptions/dependencies: law-of-demand-like settings; strict context formation to avoid confounds.
- Crowdfunding page optimization (non-strategic elements): test copy, visuals, and perk framing effects on initial interest.
- Assumptions/dependencies: avoids simulating social contagion dynamics; human confirmation still needed.
- Tooling/workflows:
- “Context Formation Wrapper”: a reusable prompt module that unblinds and standardizes task context before any question.
- “Synthetic Pretest Pipeline”: orchestrates LLM cohorts to screen variants, logs reasoning traces for QA.
Academia
- Low-cost piloting for experimental designs: use context formation-only simulations to (i) debug instructions, (ii) detect confounds, and (iii) calibrate difficulty in non-strategic tasks.
- Assumptions/dependencies: retain human pilots for final validation; report simulation settings in pre-registrations.
- Replication teaching labs: classroom exercises replicating classic findings in simple environments using the paper’s evaluation protocol and CoT trace inspection.
- Assumptions/dependencies: careful selection of non-strategic experiments; student guidance on interpretation limits.
- Method diagnostics: analyze CoT traces to identify whether misalignment stems from task misrepresentation (formation problem) or reasoning path (navigation problem).
- Assumptions/dependencies: reasoning transparency enabled; privacy-safe log handling.
- Tooling/workflows:
- “Alignment Diagnostic Dashboard”: aggregates CoT traces and flags formation/navigation failures.
- Open prompt libraries for formation vs. formation+navigation, versioned with experiment metadata.
Policy
- Rapid, low-stakes message testing (e.g., public information campaigns on recycling, basic safety guidance) where choices are largely individual and non-strategic.
- Assumptions/dependencies: clear scope; avoid simulating contested, strategic behaviors; human stakeholder review.
- Preliminary instrument refinement: refine survey items and vignettes with context formation to reduce ambiguity before fielding to citizens.
- Assumptions/dependencies: avoid drawing behavioral inferences beyond clarity checks; ethical review.
- Tooling/workflows:
- “Policy Copy Preflight”: context formation prompts ensure citizens’ task understanding; logs confusion points.
Daily Life
- Personal decision support prompting: apply context formation in personal finance, travel planning, or time management (“Help me specify all constraints and goals first, then reason”) and, when choices involve multi-step trade-offs, add navigation guidance (“state beliefs, interpret cues, update, decide”).
- Assumptions/dependencies: user provides accurate constraints; refrain from relying on simulations of other people’s behavior.
- Tooling/workflows:
- “Decision Canvas Prompt”: a template that elicits objectives, constraints, uncertainty, and steps before advice.
- “Belief-Update Checklist”: a short navigation script for planning (“initial belief → cues → update → choice”).
Long-Term Applications
These applications require further research, scaling, validation with human benchmarks, or development of new capabilities (e.g., domain fine-tuning, governance, or evaluation standards).
Industry
- Strategic market simulators: multi-agent simulations of competitive reactions, social contagion, or signaling (e.g., launch timing games, queue signaling effects, crowdfunding with costly signaling) using formation+navigation.
- Assumptions/dependencies: validated belief-update routines; heterogeneity modeling; periodic human calibration; domain shift audits.
- Synthetic customer panels for longitudinal and networked behaviors: simulate cohort evolution, peer effects, and adoption cascades under policy/price changes.
- Assumptions/dependencies: stable macro priors; graph-structure realism; governance on synthetic-to-real data blending.
- Agentic experimentation systems: autonomous agents that design, run, and analyze multi-arm experiments with formation+navigation guardrails, escalating to humans when uncertainty is high.
- Assumptions/dependencies: robust fail-safes; drift detection; compliance guardrails.
- Products/workflows:
- “Context Engine SDK”: APIs that standardize formation/navigation layers across product teams.
- “Strategic Behavior Sandbox”: safe environment for simulating belief formation, signaling, and coordination, with bias and safety checks.
Academia
- Theory-driven hybrid simulations: integrate behavioral theory modules (belief updating, reciprocity, bounded rationality) with formation+navigation prompts to test mechanisms before costly human trials.
- Assumptions/dependencies: explicit model documentation; preregistration of simulation assumptions; multi-lab human replications.
- Domain-specific aligned models: fine-tuned LLMs on verified behavioral datasets (e.g., Centaur-like models) to generalize across related decision environments.
- Assumptions/dependencies: data availability, licensing; cross-task generalization; out-of-distribution tests.
- Standards and reporting: community protocols for social-simulation validity, including formation/navigation specification, model/version, temperature, and alignment metrics.
- Assumptions/dependencies: consensus-building across disciplines; repositories for prompts and traces.
- Products/workflows:
- “Behavioral Alignment Benchmark Suite”: task bank spanning simple-to-complex environments with human baselines.
- “Trace Provenance Tools”: capture, redact, and share reasoning traces reproducibly.
Policy
- Policy sandboxes with strategic interdependence: simulate responses to interventions with belief dynamics (e.g., vaccination uptake under social signaling, energy conservation with neighbor feedback, congestion pricing with anticipatory route choices).
- Assumptions/dependencies: formation+navigation rigor; demographic and cultural representativeness; ethics review; continual recalibration.
- Regulatory impact micro-simulations: anticipate market gaming or unintended signaling from new rules (e.g., financial disclosures, platform transparency measures).
- Assumptions/dependencies: domain expertise; adversarial behavior modeling; real-world pilots to validate.
- Products/workflows:
- “Causal Policy Simulator”: encodes rules, incentives, and observables; enforces explicit belief-updating steps; supports sensitivity analyses.
- “Equity Lens Module”: probes heterogeneous effects across simulated demographic personas.
Daily Life
- Group decision facilitation: structured agents that help families/teams coordinate under constraints and partial information (e.g., budgeted event planning with shared preferences), using formation+navigation.
- Assumptions/dependencies: consented data-sharing; conflict-resolution guardrails; transparency about assumptions.
- Personal learning companions for strategic reasoning: tutors that teach belief formation and updating through interactive, multi-agent cases (e.g., signaling and screening problems).
- Assumptions/dependencies: curriculum alignment; assessments against human reasoning benchmarks.
- Products/workflows:
- “Strategic Reasoning Tutor”: stepwise navigation practice on classic games and real-life analogs.
- “Household Planner Agent”: codifies constraints, signals, and updates for shared decisions.
Cross-Cutting Assumptions and Dependencies
- Alignment premise: LLM outputs approximate human responses when given the same query, accurate context (C_H), and appropriate navigation (N_H); must be routinely verified against human benchmarks.
- Task complexity gating: simple, non-strategic tasks often need only context formation; complex, strategic tasks require formation+navigation—misuse leads to spurious confidence.
- Model variance: effects vary across LLM families and versions; freeze versions for studies; log parameters (e.g., temperature).
- Reasoning transparency: access to and auditing of CoT traces are crucial for diagnosing misalignment; ensure privacy-safe handling.
- Heterogeneity and representativeness: simulate diverse personas; document sampling; test robustness across demographics/cultures.
- Governance and ethics: avoid substituting synthetic for required human evidence; clearly label synthetic insights; comply with data and experimentation regulations.
- Toolchain reliability: dependency on API uptime, costs, and token limits; consider on-prem or open models for sensitive domains.
- Continual validation: periodic recalibration against new human data and drift detection to maintain fidelity over time.
Glossary
- AI Agents: Software entities powered by AI that can perceive, reason, and act autonomously within environments or tasks; "AI Agents"
- Behavioral alignment: The degree to which LLM-generated decisions match human participants' decisions; "behavioral alignment with human benchmarks"
- CDF (cumulative distribution function): A function giving the probability that a random variable is less than or equal to a value; " is the CDF of the standard normal distribution"
- Chain-of-Thought (CoT) reasoning: A prompting technique that elicits step-by-step reasoning before a final answer; "Chain-of-Thought (CoT) reasoning"
- Confoundedness: A design issue where effects are mixed with unintended influences, undermining causal interpretation; "can induce confoundedness in LLM-based simulations"
- Context Engineering: Systematically shaping prompts and inputs to establish an appropriate task context for LLMs; "Context Engineering"
- Context formation: Explicitly specifying the experimental design to build an accurate internal representation of the task; "The first stage, context formation, explicitly specifies the experimental design"
- Context navigation: Guiding the reasoning process within a given task representation to arrive at decisions; "The second stage, context navigation, guides the reasoning process"
- Costly signaling: Signals that credibly convey information because they impose a cost on the sender; "a crowdfunding game with costly signaling"
- Demand estimation: Inferring demand or related parameters from observed behavior or data; "a demand-estimation task"
- Dummy variable: A binary indicator used in regression to represent categories or conditions; " is a dummy variable equal to 1 if the delivery wait time is and 0 otherwise"
- Ecological validity: The extent to which an experimental setup resembles real-world conditions; "to preserve ecological validity"
- Endogenous belief formation: Beliefs formed from information generated within the interaction (e.g., others’ actions), not imposed externally; "strategic interdependence and endogenous belief formation"
- Interaction effect: An effect where the impact of one variable on an outcome depends on another variable; "We estimate the interaction effect between wait time and treatment condition Q50"
- LangChain: A software framework for building LLM-driven agents and applications; "We adopt LangChain,"
- Law of demand: The principle that quantity demanded typically falls as price rises, ceteris paribus; "driven by the law of demand"
- LLM social simulations: Using LLMs as synthetic subjects to simulate human behavior in experiments; "LLM social simulations"
- Management Science Replication Project: A coordinated effort to replicate published studies in Management Science; "Management Science Replication Project"
- Manipulation checks: Procedures to verify that participants received and understood the intended treatment; "piloting and manipulation checks"
- Persona adjustments: Prompting models to assume specific identities or traits to influence responses; "persona adjustments"
- Probit model: A regression model for binary outcomes linking probabilities via the normal CDF; "We estimate the following probit model:"
- Quality signaling: Conveying product quality through observable indicators rather than direct disclosure; "sequential purchasing game with quality signaling"
- Reinforcement learning with human feedback (RLHF): Training models using human preference judgments to shape behavior; "reinforcement learning with human feedback (RLHF)"
- Reinforcement learning with verifiable rewards (RLVR): Training with objective, checkable reward signals to guide learning; "reinforcement learning with verifiable rewards (RLVR)"
- ReAct: A prompting/agent approach that interleaves reasoning and action; "synergizing reasoning and action (ReAct)"
- State-of-the-art (SOTA): The most advanced available models or techniques at a given time; "state-of-the-art (SOTA) models"
- Strategic interdependence: Situations where each agent’s optimal action depends on others’ actions; "strategic interdependence and endogenous belief formation"
- Supervised fine-tuning (SFT): Further training an LLM on labeled examples to align it with target tasks; "supervised fine-tuning"
- Tree-of-Thoughts (ToT): A prompting method that explores and evaluates multiple reasoning branches; "tree-of-thoughts"
- Unblinding: Revealing hidden aspects of the design to avoid confounds or misinterpretation; "unblinding as a remedy"
Collections
Sign up for free to add this paper to one or more collections.

