The Benchmark Illusion: Pruned LLMs Can Pass Multiple Choice but Fail to Answer
Abstract: Compressing LLMs reduces memory use and inference cost, but it can also create failures that standard benchmarks miss. A pruned model may still perform well on multiple-choice evaluations, yet fail to answer the same question in open generation. We ask what pruning changes: does it erase the correct answer, or does it make the answer harder to produce as the top output? We study this question with multilingual question answering, tracking the same questions before and after pruning. We find a benchmark illusion. Under high-sparsity pruning, especially Wanda, models often fail in greedy open generation while still selecting the correct answer under multiple-choice scoring. In these recognition-only errors, the answer is usually not gone, but demoted: it often reappears with beam search, sampling, or one in-context example. Overall, multiple-choice benchmarks can overstate the usability of compressed LLMs, creating an evaluation blind spot. Compressed models should be tested on what they can produce, not only on what they can recognize.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper looks at what happens when we make LLMs smaller and cheaper to run by “pruning” them—basically trimming away many of their internal connections. The surprise: after pruning, a model can still pick the right answer in a multiple-choice test but fail to say that same answer when asked openly. The authors call this the benchmark illusion, because standard benchmarks (often multiple-choice) can make a pruned model look fine even when it struggles in real use.
What questions did the researchers ask?
- When pruning hurts a model, does it erase the knowledge of the correct answer, or does the model still “know” the answer but fail to produce it as its top response?
- How big is the gap between being able to choose the right answer from a list (recognition) and being able to say it unaided (production)?
- Can broader search methods (like trying a few different answers) or tiny hints (one example in the prompt) bring the right answer back?
- Does this problem happen across different languages, models, and datasets, and does model size matter?
How did they test it?
Think of two kinds of school tests:
- Multiple-choice: the right answer is in the list; you just select it.
- Open-ended: you must write the answer from scratch.
The researchers gave models the exact same questions in different formats to see what changed before and after pruning.
Here’s their approach in simple terms:
- They started with questions that the original (unpruned) model could both say correctly (open-ended) and choose correctly (multiple-choice).
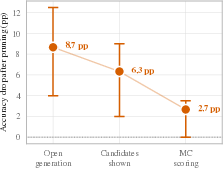
- After pruning, they re-tested the same questions in three ways: 1) Open generation: the model must say the answer itself with “greedy decoding” (it always picks the most likely next word). 2) Multiple-choice scoring: the model sees a few options and picks the most likely one. 3) Candidate-shown generation: the correct answer and some distractors are shown in the prompt, and the model tries to say the answer.
- They also tried broader decoding methods:
- Beam search: instead of always taking the single most likely next word, the model keeps several top possibilities and explores them.
- Sampling: the model tries multiple “samples” of likely answers rather than sticking to a single most likely path.
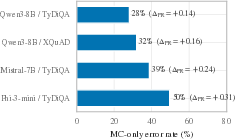
- They ran this on multilingual question-answering tasks (like TyDiQA and XQuAD) using several model families (such as Qwen, Mistral, and Phi). Multilingual data is helpful because pruning hurts some languages more than others, creating many test cases.
Key terms explained:
- Pruning: removing many small or less-important weights (connections) in the model to make it smaller and faster.
- Greedy decoding: always taking the top next token (word piece). It’s fast, but if the top choice is slightly wrong at the start, the whole answer can go off track.
- Beam search / sampling: broader searches that consider several likely next words or try multiple answer paths.
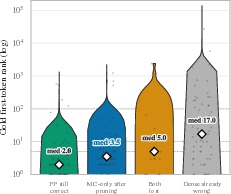
- Token rank: how high up the correct next word is in the model’s list of possibilities. Rank 1 means “most likely,” rank 3 means it’s close but loses to a couple of competitors.
What did they find?
Here are the main takeaways, kept simple:
- The “benchmark illusion” is real: after pruning, models often fail to say the right answer on their own but still pick it correctly from a multiple-choice list. In other words, they can “recognize” but not “produce.”
- Demotion, not deletion: pruning usually doesn’t erase the answer. Instead, it downgrades the correct first word from about rank 1 to rank 3–4. That’s enough for greedy decoding to miss it, even though the model still “has” the answer inside.
- More help means less damage: formats that give the model more support (like showing options) are less affected by pruning than open-ended answering. Showing the actual correct answer in the prompt helps a lot; just showing unrelated options or only wrong choices does not.
- Recovery is possible:
- Beam search and sampling often “dig up” the right answer that greedy decoding missed, showing the knowledge is still reachable.
- Even one in-context example (a very short demo in the prompt) can shrink the gap in several languages.
- It’s widespread: the pattern shows up across different models (Qwen, Mistral, Phi) and datasets (TyDiQA, XQuAD).
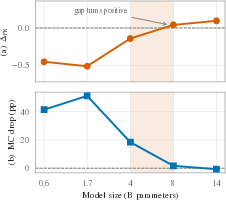
- Model size matters (within one family): in larger Qwen models (8B and 14B), multiple-choice accuracy stays strong while open-ended answering gets worse after pruning—classic benchmark illusion. In smaller Qwen models, pruning more often harms even multiple-choice selection, suggesting real loss, not just demotion.
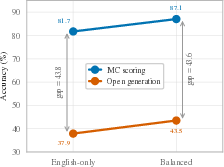
- Better calibration helps overall but doesn’t fix the gap: tuning pruning with more balanced, multilingual data improves accuracy in general, but the difference between open-ended and multiple-choice performance still remains.
A concrete example they share:
- Question: “When were the Azores discovered?”
- Before pruning: the model says “Around 1427” (correct).
- After pruning: greedy decoding says “the 15th century” (not precise), but the correct first word for the exact answer still ranks 3rd. The model also picks the right choice in multiple-choice mode. So the answer wasn’t erased—just knocked out of first place.
Why does this matter?
- Real users ask open-ended questions. If a pruned model only looks good on multiple-choice tests, it may still disappoint in real conversations.
- Benchmarks can mislead. A pruned model may score well on leaderboards but struggle to produce correct answers when it counts.
- Better testing is needed. Compressed models should be checked on what they can actually say, not just what they can recognize from options.
- Practical tips:
- If you must prune, consider using beam search, limited sampling, or a tiny example in the prompt to recover many “near-miss” answers.
- For smaller models, pruning may cause true knowledge loss; for larger ones, the answer is often still there but hidden just below the top choice.
Bottom line
Pruning often makes answers harder for the model to say, not harder to know. Multiple-choice benchmarks can hide this problem. To trust a compressed LLM, test whether it can produce correct answers on its own—not just recognize them in a list.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
- Mechanistic cause of “answer demotion”: which layers, heads, or weight groups (e.g., FFN vs. attention) drive the observed probability mass shifts that push gold tokens from rank 1 to ranks 3–4 after pruning.
- Margin dynamics: how pruning changes the top-1 logit margin (gold vs. nearest competitor) across tokens, positions, and languages, and whether margin-aware pruning could preserve greedy generation.
- First-token vs. sequence effects: whether errors predominantly originate at the first token or accumulate later; how teacher-forced vs. free-running likelihoods diverge post-pruning.
- Task generality beyond extractive QA: does the benchmark illusion hold for code generation, math/logic (chain-of-thought), long-form reasoning, translation, summarization, tool use, and multi-turn dialogue.
- Compression method coverage: whether the demotion-vs-erasure pattern persists under other techniques (quantization, distillation, low-rank/adapters, structured pruning, sparse training, iterative prune–fine-tune, L0/L1 regularization).
- Sparsity regime mapping: how the production–recognition gap evolves as a continuous function of sparsity (low to extreme), and whether there is a critical threshold where recognition collapses.
- Post-pruning recovery strategies: comparative efficacy and cost of light fine-tuning, distillation, RLHF, or LoRA adapters in restoring greedy production vs. recognition; sample efficiency and stability across languages.
- Decoding practicality: compute/latency trade-offs of beam/sampling recovery relative to pruning savings; which search settings (beam width, temperature, top-p, length penalties) best recover pruned models in real deployments.
- In-context learning scope: how the gap closes as a function of the number, language, and format of demonstrations (0→k-shot, CoT exemplars, cross-lingual exemplars); sensitivity to prompt templates.
- Calibration design space: whether more principled, multilingual, task-balanced, or per-layer calibration (vs. English-only) can preferentially restore production without equivalently boosting recognition.
- Tokenization effects: how tokenizer choice, vocabulary coverage, and segmentation quality drive language-specific degradations and recoverability; whether BPE vs. byte-level tokenization changes the gap.
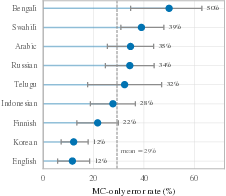
- Low-resource language boundary: disentangling contributions of training corpus size, orthography/tokenization, and morphology to lower recoverability in languages like Bengali and Telugu.
- Distractor difficulty realism: beyond character n-gram similarity, how semantically adversarial or paraphrastic distractors (and more than 4 options) affect MC-only rates and ΔPR.
- Recognition probe validity: developing format-minimal probes that reduce lexical/format cues in MC to isolate “recognition” from formatting advantages (e.g., masked cloze or pairwise ranking without option formatting).
- Evaluation metric sensitivity: robustness of conclusions to answer normalization (synonyms/paraphrases), span matching vs. exact string, and partial-credit metrics (e.g., F1) in multilingual QA.
- Statistical power and variance: larger-scale evaluations (beyond 200 items/language) and across seeds to quantify confidence intervals for dissociation rates, recoverability, and ΔPR.
- Cross-family scale boundary: whether the Qwen 8B/14B boundary generalizes; systematic sweeps across more model families and sizes to test the “capacity/redundancy” hypothesis for demotion vs. erasure.
- Layerwise/logit-lens diagnostics: whether intermediate representations retain gold-token evidence post-pruning even when final logits fail; where along the stack demotion emerges.
- Interaction of pruning with quantization: combined effects on demotion vs. erasure and on gap size; whether certain orderings (prune-then-quantize vs. quantize-then-prune) are less harmful.
- Language-conditioned pruning: feasibility of masks tailored per language or dynamically selected at inference to preserve top-1 for targeted locales without losing global sparsity benefits.
- Robustness to prompt templates: sensitivity of the gap to different chat/completion formats, instruction styles, and language-specific prompt engineering.
- Beam search behavior: whether beam search introduces mode collapse or biases that differ by language/task post-pruning; comparison with reranking via separate scorers.
- Confidence and calibration: how pruning alters probability calibration (e.g., ECE), entropy, and over/under-confidence; relation between calibration shifts and increased top-1 errors.
- Safety and hallucinations: whether demotion increases generic, vague, or overconfident incorrect generations; impact on hallucination rates in open generation vs. MC settings.
- Ranking ability vs. generation ability: does pruning preserve relative ranking (top-k accuracy) while harming absolute generation; how MC performance scales with number of options (k).
- Candidate-shown generation vs. MC scoring: why supplying options improves production only when the gold is present; what differences in gradients/logit updates under these two formats explain the effect.
- Causal interventions: whether adding small logit biases for gold tokens or penalizing top competitors restores generation, indicating purely ranking-based failures.
- Real-world user impact: human evaluation to quantify perceived utility loss from production failures despite strong MC scores; scenarios where candidate lists are unavailable.
- Compute-aware evaluation: standardized benchmarks that jointly report accuracy and inference cost under practical decoding settings to avoid overstating usability of pruned models.
- Pruning objectives: designing pruning criteria that explicitly preserve top-1 margins or target tokens critical to exact-answer generation (e.g., dates, numbers, named entities).
- Cross-lingual interference: whether pruning that preserves high-resource languages disproportionately demotes low-resource ones; mapping weights that are language-specific vs. shared.
- Error taxonomy: beyond MC-only, characterizing other post-pruning failure types (formatting errors, near-synonym outputs, partial answers) and their recoverability profiles.
Practical Applications
Immediate Applications
The paper’s findings enable several deployable changes to how compressed LLMs are built, evaluated, and used today. The bullets below highlight specific use cases, sectors, candidate tools/workflows, and feasibility considerations.
- Paired-format evaluation in CI/CD for compressed models (Software/ML Ops, Academia)
- What to do: Integrate paired-item testing and the Δ_PR metric into model compression pipelines to measure open-generation vs multiple-choice (MC) performance on the same items.
- Tools/workflows:
- “Paired-Format Eval Suite” that runs free-form, candidate-shown, and MC scoring modes on identical prompts; logs headroom-normalized drops and MC-only (recognition-only) rates.
- Hooks for pruning frameworks (e.g., Wanda, SparseGPT) to auto-run these tests after each mask change.
- Assumptions/dependencies: Access to representative task data; capability to compute log-likelihoods per candidate; minor additional compute and latency for added tests.
- Decode-time fallback to recover demoted answers (Software/ML Ops, Customer Support, Education)
- What to do: When greedy decoding confidence is low or early tokens show high entropy, automatically fall back to beam-5 or small-sample nucleus decoding; optionally insert a single in-context example for knowledge-intensive prompts.
- Tools/workflows:
- “Decoding Fallback Middleware” that monitors first-token probabilities and triggers beam search/sampling or 1-shot prompting.
- Product setting: “Accuracy boost mode” that adds small latency but improves answerability on compressed models.
- Assumptions/dependencies: Acceptable latency/compute overhead; guardrails for sampling to manage hallucination risk.
- Task/UX redesign to match model’s retained strengths (Product, Education, Customer Support)
- What to do: For knowledge checks and internal search, prefer MC- or candidate-assisted UIs over open-ended answers when using highly pruned models; where free-form is required, show top-k short suggestions rather than a single output.
- Tools/workflows:
- Enterprise helpdesk UI that surfaces 3–4 candidate answers; auto-selects if top-1/2 probability mass is clear.
- Education apps: use MC drills for compressed on-device tutors; switch to cloud model for open-response grading.
- Assumptions/dependencies: Availability of plausible distractors or retrieval-backed candidate lists; user acceptance of candidate-style interactions.
- Language-aware deployment and calibration (Global Products, Public Sector, Education)
- What to do: Use balanced multilingual calibration for pruning; route low-resource language queries to less-pruned or uncompressed variants; monitor language-specific Δ_PR.
- Tools/workflows:
- Language router that selects model variant by locale and task criticality.
- “Calibration Kit” that builds pruning masks from multilingual samples, not only English.
- Assumptions/dependencies: Coverage in calibration data for target languages; capacity to host multiple variants.
- Model cards and monitoring that report “production vs recognition” (Industry Standards, Compliance)
- What to do: Add Δ_PR, MC-only rates, and recoverability metrics (beam/sample reachability) to model cards and observability dashboards.
- Tools/workflows:
- “Benchmark Illusion Monitor” to track near-miss ranks of gold first tokens, recoverability rates, and format gaps during canary and post-deploy.
- Assumptions/dependencies: Logging infrastructure for token-level probabilities; privacy controls for telemetry.
- Procurement and QA checklists for compressed LLMs (Policy/Procurement, Regulated Sectors: Healthcare, Finance, Government)
- What to do: Require open-generation tests alongside MC benchmarks during vendor evaluation; set thresholds for Δ_PR and recoverability on domain QA.
- Tools/workflows:
- Procurement templates specifying paired-format performance gates; domain-specific evaluation sets.
- Assumptions/dependencies: Availability of domain datasets with exact answers; vendor cooperation to expose decoding scores.
- Edge/on-device assistants with small-beam or 1-shot hints (Consumer Devices, Robotics, Automotive, Energy-constrained IoT)
- What to do: For offline/pruned assistants, enable a low-width beam fallback or embed a tiny 1-shot instruction template for factual questions.
- Tools/workflows:
- On-device decoding library supporting beam-3; cached mini exemplars per task (e.g., QA style).
- Assumptions/dependencies: Tight latency budgets; memory for small beams; careful tuning to avoid battery drain.
- Academic benchmarking and dataset design (Academia, Open-Source)
- What to do: Release paired-format benchmark splits and leaderboards that report open-gen, candidate-shown, MC, and reachability metrics.
- Tools/workflows:
- Public leaderboards with Δ_PR and MC-only rates; scripts that generate hard distractors and candidate ablations.
- Assumptions/dependencies: Community agreement on formats; stable APIs for token log-probs across models.
- Safety triage via near-miss detection (Healthcare/Legal advisory, Safety Ops)
- What to do: Detect “near-miss” answers (gold token ranks ~3–6) and route to broader decoding or human review for high-stakes queries.
- Tools/workflows:
- Confidence-and-rank-based router with escalation policies for critical domains (e.g., medical dosing, compliance).
- Assumptions/dependencies: Defined criticality taxonomy; acceptance of higher latency for escalations.
Long-Term Applications
The paper suggests research and standardization directions to make compressed models reliably produce correct top outputs, not only recognize them.
- Pruning objectives that preserve “production strength,” not just recognition (Software/Algorithms, Academia)
- What to build: New pruning losses that explicitly maintain top-1 margins on key tokens/answers (e.g., margin-aware pruning, KL on top-k ranks, greedy-robust masks).
- Potential products: “Production-Preserving Pruner” integrated into compression suites.
- Assumptions/dependencies: Access to representative tasks and gold answers; compute for mask optimization or light post-pruning training.
- Post-pruning repair via distillation of top-1 behavior (Software/Training, Education/Healthcare/Finance verticals)
- What to build: Self-recovery distillation from the uncompressed teacher that restores first-token ranks for high-value QA; small supervised fine-tunes targeting Δ_PR hotspots.
- Potential products: “Top-1 Restorer” fine-tune modules per domain.
- Assumptions/dependencies: Teacher model availability; rights to run and store teacher/student data; risk of overfitting.
- Adaptive decoding controllers (Systems, Edge/Cloud Platforms)
- What to build: Bandit/learning-based policies that choose greedy vs beam vs sampling vs 1-shot on a per-query basis to minimize cost at target accuracy.
- Potential products: Smart decoders in inference servers; edge runtimes with cost-aware policies.
- Assumptions/dependencies: Online feedback loops; safety constraints for sampling; HW support for efficient beams.
- Architectural “answer head” protection and sparse-friendly designs (Model Architecture, Hardware/Compilers)
- What to build: Modules or adapters that focus on preserving the early-token distribution under pruning (e.g., low-rank adapters for first-token logits, protected subnets).
- Potential products: Prune-ready architectures; compiler passes that keep critical paths dense.
- Assumptions/dependencies: Co-design of model and pruning; evidence that protected components generalize across tasks.
- Standards for compression evaluation beyond MC (Policy/Standards, Industry Consortia)
- What to do: Establish certification that mandates open-generation, candidate-shown, and reachability reporting; language-specific thresholds and fairness checks.
- Potential products: “Compressed LLM Usability Standard” similar to model cards but tied to procurement.
- Assumptions/dependencies: Cross-industry collaboration; test set curation; auditing infrastructure.
- Fair multilingual compression practices (Public Sector, Global Products)
- What to do: Policy and tooling to ensure pruning does not disproportionately harm low-resource languages; require Δ_PR and recoverability by language.
- Potential products: Regional calibration packs; fairness dashboards for compression.
- Assumptions/dependencies: Sufficient multilingual data; governance structures to enforce fairness goals.
- Domain-certified compressed models (Healthcare, Finance, Legal)
- What to build: Verticalized compressed models with documented Δ_PR under domain QA plus human-in-the-loop fallback for near-misses.
- Potential products: “Edge-clinical QA lite” with verified open-generation retention and triage policies.
- Assumptions/dependencies: Regulatory approval; curated domain datasets; auditable logs of decoding decisions.
- Hardware and runtime support for low-cost beams (Semiconductors, Cloud/Edge Providers)
- What to build: Kernels and accelerators optimized for small-width beam search and top-k sampling to make recoverability cheap.
- Potential products: Inference accelerators exposing beam primitives; TGI/TensorRT backends with beam-friendly scheduling.
- Assumptions/dependencies: Vendor investment; sufficient demand; benchmarking showing cost–benefit.
- Interaction patterns that reduce reliance on a single top-1 output (Product/UX Research)
- What to build: Conversational flows that ask clarifying questions or present ranked candidates when uncertainty is detected, especially on compressed models.
- Potential products: “Adaptive QA” chat widgets that toggle between suggestions and free-form.
- Assumptions/dependencies: User acceptance; careful UX to avoid burdening users.
- Automated Δ_PR discovery and hotspot targeting (AutoML, MLOps)
- What to build: Systems that locate prompts/domains/languages where Δ_PR is high, then auto-calibrate masks or apply targeted repair.
- Potential products: “PR-Gap Optimizer” that iteratively tunes masks and adapters.
- Assumptions/dependencies: Iterative training budget; robust measurement pipelines; avoidance of evaluation overfitting.
Notes on Feasibility and Risk
- Compute–latency trade-offs: Beam/sampling and 1-shot prompting add cost; deploy selectively (confidence/routing).
- Safety: Sampling can increase hallucinations; use domain-aware guardrails and escalate high-stakes queries.
- Data coverage: Balanced multilingual calibration requires representative corpora; missing languages will remain brittle.
- Measurement dependencies: Some diagnostics (e.g., token-rank logging) require access to logits and may be unavailable in closed APIs.
- Model size effects: The benchmark illusion is strongest in larger Qwen-family models; smaller models may need different mitigations (recognition itself can degrade).
Glossary
- activation statistics: neuron activation signals used to score or prioritize weights during pruning. "scores weights using magnitude and activation statistics."
- balanced multilingual calibration: calibrating pruning using a multilingual dataset to avoid language bias in what the mask preserves. "balanced multilingual calibration is a more practical alternative that also helps."
- beam search: a decoding algorithm that explores multiple high-probability sequences in parallel to find better outputs than greedy decoding. "broader decoding methods such as beam search or sampling"
- candidate-shown generation: an evaluation format where the prompt shows the correct answer with distractors and the model must generate the answer. "candidate-shown generation, the prompt lists the correct answer together with three distractors, and the model must generate the answer."
- character trigram overlap: a similarity measure based on overlapping three-character sequences, used to construct hard distractors. "most similar to the gold answer by character trigram overlap."
- chat templates: model-specific prompt formats for conversational models. "both prompted with their native chat templates,"
- checkpoints: specific saved versions of a model’s parameters. "smaller Qwen checkpoints more often lose recognition itself."
- dissociation rate: the share of items that remain correct in MC but fail in open generation after pruning. "We measure this with the dissociation rate: the fraction of both-correct items that become multiple-choice-only (MC-only) after pruning."
- distractors: incorrect answer options included alongside the correct one to form multiple-choice lists. "three distractors"
- fp16: half-precision (16-bit) floating-point numeric format used for model weights/activations. "The uncompressed fp16 model provides a crucial baseline here."
- free-form open generation (FF): answering without being shown candidates, typically via unconstrained text generation. "We use FF to denote free-form open generation"
- gold (answer/token): the ground-truth answer or token used for evaluation. "selects the gold answer from candidates."
- greedy decoding: decoding that chooses the highest-probability next token at each step. "we compared standard greedy decoding against oracle recoverability"
- greedy open generation: producing an answer via greedy decoding without answer options. "fail in greedy open generation"
- hard distractors: carefully chosen, highly confusable incorrect options. "replace the standard distractors with hard distractors"
- headroom-normalized accuracy drop: accuracy decrease scaled by the available “headroom” to make drops across formats comparable. "Here, is the headroom-normalized accuracy drop after pruning."
- in-context example: a demonstration included in the prompt (few-shot) to guide the model’s behavior. "one in-context example."
- layer-wise reconstruction: reconstructing each layer’s outputs during pruning to preserve behavior. "SparseGPT uses layer-wise reconstruction with second-order approximations,"
- log-likelihood: the logarithm of the probability assigned to a sequence, used to score options. "scored by log-likelihood"
- MC-only (multiple-choice-only) errors: cases where the model succeeds on multiple-choice but fails on open generation. "We refer to these as ``MC-only'' errors."
- multiple-choice scoring: evaluating by computing likelihoods of provided options and selecting the highest-scoring one. "multiple-choice scoring"
- next-token distribution: the probability distribution over the next token given the current context. "next-token distribution"
- nucleus sampling: stochastic decoding that samples from the smallest set of tokens whose cumulative probability exceeds a threshold p. "10 nucleus samples ()"
- one-shot pruning: a single-pass pruning approach without subsequent retraining. "one-shot pruning methods such as Wanda"
- optimization-based mask learning: learning which weights to keep/remove by solving an optimization problem. "optimization-based mask learning"
- oracle recoverability: whether the correct answer appears anywhere among outputs under broader decoding (an upper bound, not an accuracy). "oracle recoverability"
- paired analysis: comparing the same items across conditions (e.g., before/after pruning) and formats to isolate effects. "we run a paired analysis."
- paired-item test: evaluating the same question in multiple formats to separate recognition from production. "We introduce a paired-item test"
- perplexity: a standard LM evaluation metric reflecting how well a model predicts text. "perplexity can remain stable"
- production-recognition gap (Δ_PR): the difference in degradation between open generation and multiple-choice recognition. " is positive"
- prune gap: difference between uncompressed and pruned model accuracy under a given setting. "the prune gap, defined as fp16 accuracy minus pruned accuracy,"
- pruning mask: a binary selection over weights indicating which are kept or removed. "the pruning mask simply discards the ``wrong'' languages,"
- quantization: compression by reducing numerical precision of weights/activations. "quantization"
- reachability: whether the correct answer can still be produced under broader decoding even if greedy fails. "Reachability asks whether the answer appears under broader decoding,"
- recognition-only errors: failures where the model can select the correct option but cannot produce it freely. "In these recognition-only errors, the answer is usually not gone, but demoted:"
- second-order approximations: methods leveraging curvature (e.g., Hessian) to approximate effects during pruning. "second-order approximations,"
- sparse training: training that enforces or promotes sparsity in model parameters. "sparse training"
- sparsity: proportion of weights set to zero in a pruned model. "at 0.5 sparsity,"
- SparseGPT: a one-shot LLM pruning method using layer-wise reconstruction with second-order approximations. "SparseGPT"
- symbolic pruning metrics: hand-crafted scoring rules for deciding which weights to prune. "symbolic pruning metrics"
- tokenization: splitting text into tokens according to a model’s vocabulary rules. "more difficult tokenization,"
- TyDiQA: a multilingual question answering benchmark used in the experiments. "TyDiQA"
- Wanda: a one-shot pruning method that scores weights using magnitude and activation statistics. "Wanda"
- XQuAD: a cross-lingual question answering dataset used to validate generality. "XQuAD"
Collections
Sign up for free to add this paper to one or more collections.