- The paper demonstrates that compression decouples accuracy from uncertainty, showing that high accuracy can mask unreliable uncertainty estimates.
- The evaluation employs conformal prediction with metrics like coverage rate and set size to assess impacts of quantization and pruning on LLMs.
- Results reveal that larger models buffer uncertainty inflation under compression, though threshold effects can lead to abrupt calibration failures.
Introduction
The paper "Does Compression Preserve Uncertainty? A Unified Benchmark for Quantized and Sparse LLMs via Conformal Prediction" (2606.01850) provides a systematic and large-scale empirical analysis of whether model compression methods—specifically quantization and pruning—preserve uncertainty calibration in LLMs. While the literature has focused predominantly on accuracy retention, this work targets the critical gap regarding the reliability of uncertainty estimates under compression, motivated by deployment needs in safety- and cost-sensitive applications where robust uncertainty quantification is essential.
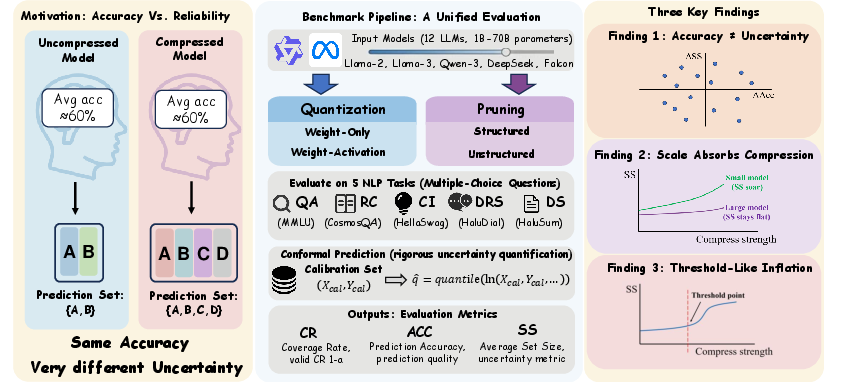
Figure 1: The benchmark framework covers diverse model families, compression paradigms, and NLP tasks, revealing that accurate compressed models may have divergent uncertainty characteristics.
Benchmark Design and Methodological Foundations
The authors establish a unified benchmark consisting of 12 LLMs (1B--70B parameters), covering four model families including dense and MoE architectures, and spanning five representative NLP tasks (MMLU, CosmosQA, HellaSwag, HaluDial, HaluSum). The benchmark evaluates four compression axes: weight-only quantization, weight-activation quantization, unstructured pruning, and structured pruning. For each model-task-compression tuple, uncertainty is quantified using conformal prediction with both LAC and APS nonconformity scores, ensuring distribution-free, finite-sample coverage guarantees.
Crucially, the evaluation strictly isolates compression effects, keeping data splits, calibration protocols, and prompting strategies (base, shared, and task-specific) fixed across all experimental cells. The key metrics are:
- Prediction Accuracy (Acc): Top-1 accuracy.
- Coverage Rate (CR): Fraction where true label falls inside conformal prediction set, sanity-checking validity.
- Set Size (SS): Primary uncertainty metric, capturing average prediction set cardinality; lower SS denotes higher model confidence.
Compression-Decoupled Uncertainty Dynamics
A central finding is the systematic decoupling between accuracy and uncertainty under compression. Weight-only quantization (e.g., W4A16) typically maintains both Acc and SS near baseline for medium and large models, but weight-activation quantization (e.g., W4A4) and aggressive pruning quickly degrade uncertainty, often without proportional loss of accuracy.
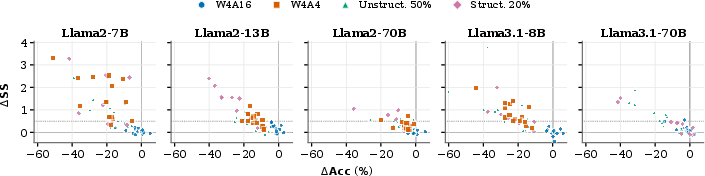
Figure 2: Scatter-plots of accuracy and uncertainty changes demonstrate that compression-induced variations in accuracy and uncertainty are not consistently negatively correlated, invalidating accuracy as a sole proxy for deployment fitness.
Notable observations:
- Compressed models can exhibit stable accuracy with increased uncertainty (e.g., Llama2-13B, AWQ on CI: accuracy improves but SS increases).
- Sharp accuracy drops with minimal SS change are also observed.
- The dispersion of compression-induced changes contracts as model parameter count increases, indicating a scale-robustness effect.
The Scale Effect: Buffering Compression-Induced Uncertainty
Model scale is a dominant moderator of uncertainty inflation. Large models (e.g., Llama2-70B, Qwen3-32B) maintain flatter and lower SS trajectories even under high compression intensities. For instance, moving from 7B to 70B, uncertainty inflation under QuaRot W4A4 drops by nearly an order of magnitude.
Pruning results similarly demonstrate that compression-induced uncertainty inflation is sharply mitigated in larger architectures. However, model scale is not universally protective: large models remain vulnerable to method+task-specific pathological cases (e.g., Llama3.1-70B, Magnitude pruning on CI).
Threshold Effects: Nonlinear Uncertainty Inflation in Compression
When varying compression ratios (e.g., pruning sparsity from 0% to 50%), uncertainty inflation is highly non-monotonic and threshold-like, not gradual. For various models and pruning methods, SS remains flat even at high sparsity, but surpassing certain task+model-specific thresholds leads to sharp increases in uncertainty set size.
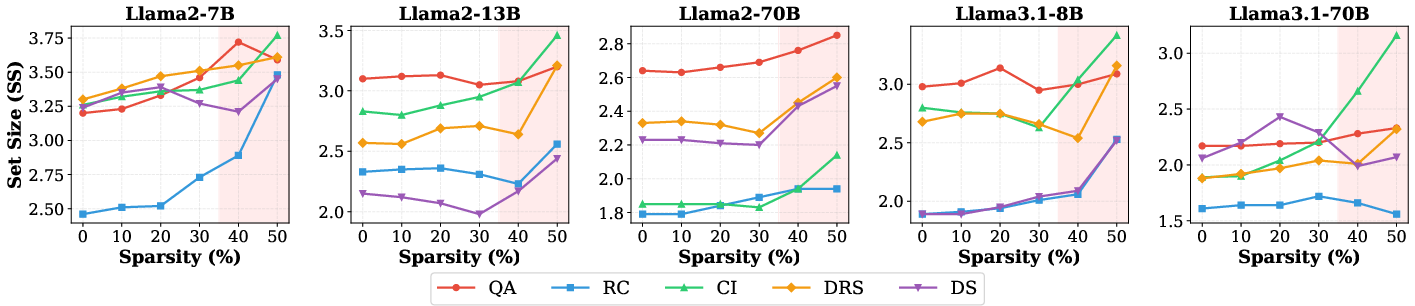
Figure 3: SS as a function of Wanda sparsity reveals task- and scale-specific thresholds where uncertainty inflates abruptly, especially in small/medium models.
This nonlinearity cautions against fixed-compression evaluation: methods stable at 30–40% sparsity can become unreliable at 50%, emphasizing the need for multi-level compression robustness analysis.
Compression Method Comparisons: Quantization, Pruning, and MoE Models
- Weight-only quantization (especially AWQ, RTN, and GPTQ at W4A16) is the most uncertainty-preserving regime across the board. Even at 4-bit, large models maintain baseline-level uncertainty on core tasks.
- Weight-activation quantization and low-precision (W4A4) regimes are highly destabilizing for uncertainty, except in very large models.
- Pruning methods are highly sensitive to algorithmic sophistication and structural constraints. Recent approaches like SparseGPT and Wanda attenuate uncertainty inflation versus magnitude pruning but require careful configuration per model-task.
- MoE models (e.g., Qwen3-30B-A3B) show pronounced method dependence: some pruning/quantization schemes yield both higher accuracy and improved SS, while others completely collapse uncertainty guarantees.
Empirical Claims and Noteworthy Results
- Accuracy and uncertainty are consistently decoupled by compression, invalidating accuracy as a universal metric for deployment readiness.
- Larger models consistently buffer against uncertainty degradation, but do not eliminate it, especially near compression thresholds.
- Uncertainty inflation as a function of compression exhibits threshold-like jumps rather than monotonic increase.
- Single metric or compression-level evaluation does not suffice; thorough, multi-dimensional benchmarks are necessary for safe deployment.
Implications and Future Directions
Practical Impact
These results have direct implications for practitioners deploying LLMs in high-stakes or uncertainty-sensitive applications. The use of accuracy-only evaluation risks silent failure of uncertainty calibration, especially for smaller or aggressively compressed models. The threshold phenomenon indicates that conservative compression settings may "seem safe" until a brittle breaking point is crossed.
Methodological Recommendations
The authors strongly recommend SS evaluation via conformal prediction as a standard pipeline component for compressed LLMs. Additionally, larger models are to be preferred under aggressive compression if uncertainty reliability is required. Benchmarking should probe a continuous range of compression ratios, not merely evaluate at a single preset.
Theoretical and Research Impact
The findings highlight the inadequacy of current compression evaluation practice and raise open questions about the structural and algorithmic factors affecting uncertainty preservation (e.g., under what architectural or algorithmic conditions does thresholding emerge, and can these regimes be predicted or mitigated a priori?). Furthermore, conformal methods are only directly applicable to classification; extension to open-ended generation and structured prediction under compression remains a high-priority research avenue.
Conclusion
This benchmark establishes that uncertainty is an indispensable evaluation axis for compressed LLMs, not recoverable from accuracy alone. The decoupling, thresholding, and scale effects elucidated in this work necessitate a rethinking of compression method selection and deployment protocols. The open-sourced benchmark and analysis provide a framework for more holistic, uncertainty-aware LLM compression research, and its integration into practical, safety-critical NLP pipelines.