- The paper demonstrates that unstructured pruning, particularly using the Wanda method at 20% sparsity, can outperform unpruned LLMs in test-time reasoning tasks.
- It contrasts structured pruning, which severely disrupts reasoning by removing entire blocks, with unstructured methods that preserve model architecture and enhance long-chain reasoning.
- Layerwise sparsity allocation strategies like OWL and LayerIF further mitigate performance drops, enabling efficient LLM deployments under strict compute constraints.
Introduction
The paper "Doing More With Less: Revisiting the Effectiveness of LLM Pruning for Test-Time Scaling" (2604.25098) investigates the effect of pruning techniques on the test-time reasoning capacity of LLMs. While prior work found that structured pruning substantially degrades test-time scaling (TTS) reasoning performance, this work provides a systematic empirical analysis contrasting structured with unstructured pruning. The authors comprehensively evaluate multiple pruning and sparsity allocation schemes on long-chain reasoning tasks using modern LLMs (s1.1-7B, Qwen3-8B), challenging the prevailing assumption that parameter pruning is generally detrimental to TTS, especially for complex reasoning.
Structured vs. Unstructured Pruning: Framework and Prior Results
Structured pruning removes entire blocks or layers from an LLM, which, as substantiated by earlier studies, causes breakdowns in reasoning—particularly when an LLM must maintain coherent multi-step chains-of-thought. It directly alters model topology and information flow, often resulting in severe capability loss for long-horizon reasoning tasks.
By contrast, unstructured pruning applies fine-grained masking to individual weights, generating sparsity without modifying the architectural hierarchy. The baseline methods explored for unstructured pruning include Magnitude (masks based on lowest L1 weight norms) and Wanda (masks based on input-activation-weight product magnitudes).
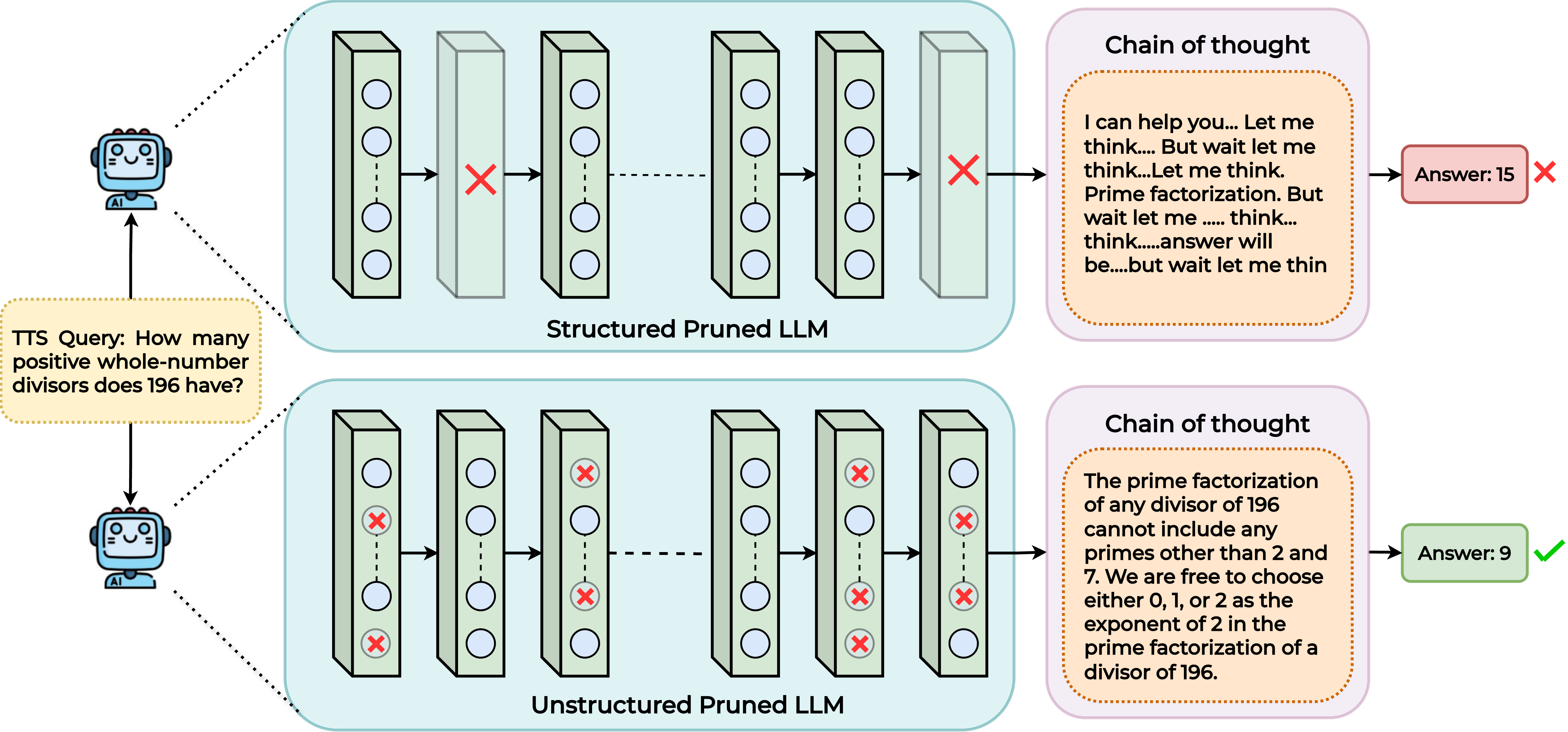
Figure 1: Structured pruning (left) disrupts LLM reasoning and TTS capabilities by removing entire blocks; unstructured pruning (right) selectively removes weights but preserves test-time scaling performance and reasoning integrity.
Experimental Protocol
The study systematically benchmarks pruning effects on four rigorous reasoning datasets—MATH500, AIME24, AMC23, and GPQA-Diamond—representing multi-step mathematical and scientific QA. Models are evaluated with varying compute "thinking token" limits (from 512 to 8192) to control the test-time scaling context.
Two reasoning-centric LLMs are examined (s1.1-7B, Qwen3-8B), with pruning sparsity rates at 10% and 20%. For structured pruning, ShortGPT is the baseline (entire block removal), whereas unstructured pruning comparisons utilize Magnitude and Wanda with three class-leading layer-wise sparsity allocation strategies: Uniform, OWL, and LayerIF.
Empirical Results: Surpassing the Unpruned Baseline
RQ1: Does Unstructured Pruning Hinder or Enhance TTS?
A central claim of the paper is that unstructured pruning, contrary to structured methods, not only avoids performance degradation in TTS settings but often outperforms the unpruned LLM. On both s1.1-7B and Qwen3-8B, unstructured pruning (particularly Wanda at 20% sparsity) achieves up to ~10% relative improvement over the unpruned baseline at intermediate token budgets on challenging tasks such as AIME24 and GPQA-Diamond.
In stark contrast, structured block pruning (ShortGPT) yields consistent and severe reasoning performance drops across all benchmarks and TTS budgets.
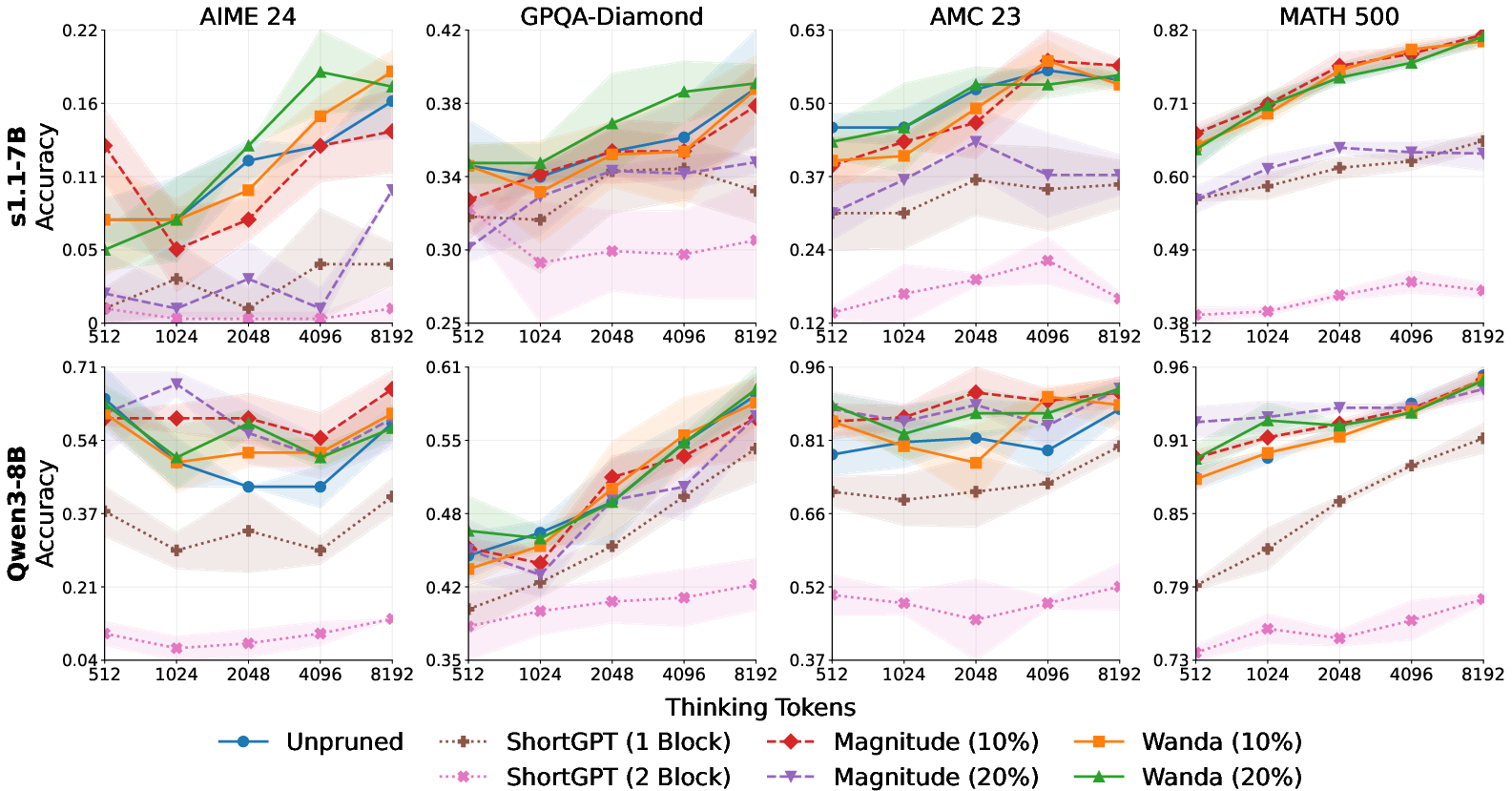
Figure 2: Unstructured pruning (Wanda and Magnitude) either matches or exceeds unpruned LLM performance across four reasoning datasets with 10% and 20% sparsity; structured pruning consistently degrades TTS reasoning.
This empirical outcome forcibly contests the assumption from earlier studies [e.g., Wang et al., 2025] that pruning is intrinsically detrimental for TTS, demonstrating that pruning method granularity dictates impact. The authors discuss their findings in the context of the Lottery Ticket Hypothesis, noting that subnetwork selection via unstructured pruning might preferentially ablate redundant or even detrimental weights, improving generalization and reducing reasoning overfit or hallucination.
Layerwise Sparsity Allocation Strategies
RQ2: Does Allocation Strategy Modulate Effectiveness?
The study further investigates whether the manner of allocating sparsity (layerwise vs. uniform) affects downstream TTS reasoning post-pruning. The approaches tested are:
- Uniform (same sparsity ratio per layer)
- OWL (allocates more sparsity to layers with outlier feature statistics)
- LayerIF (influence-based allocation using estimated parameter quality)
Experiments demonstrate that, for weaker models (s1.1-7B), advanced allocation strategies like OWL and LayerIF can substantially recover or improve performance at high sparsity rates (20%) where simple uniform allocation induces degradation. In high-capacity models (Qwen3-8B), variations in allocation only modestly affect TTS—uniform allocation is surprisingly competitive.
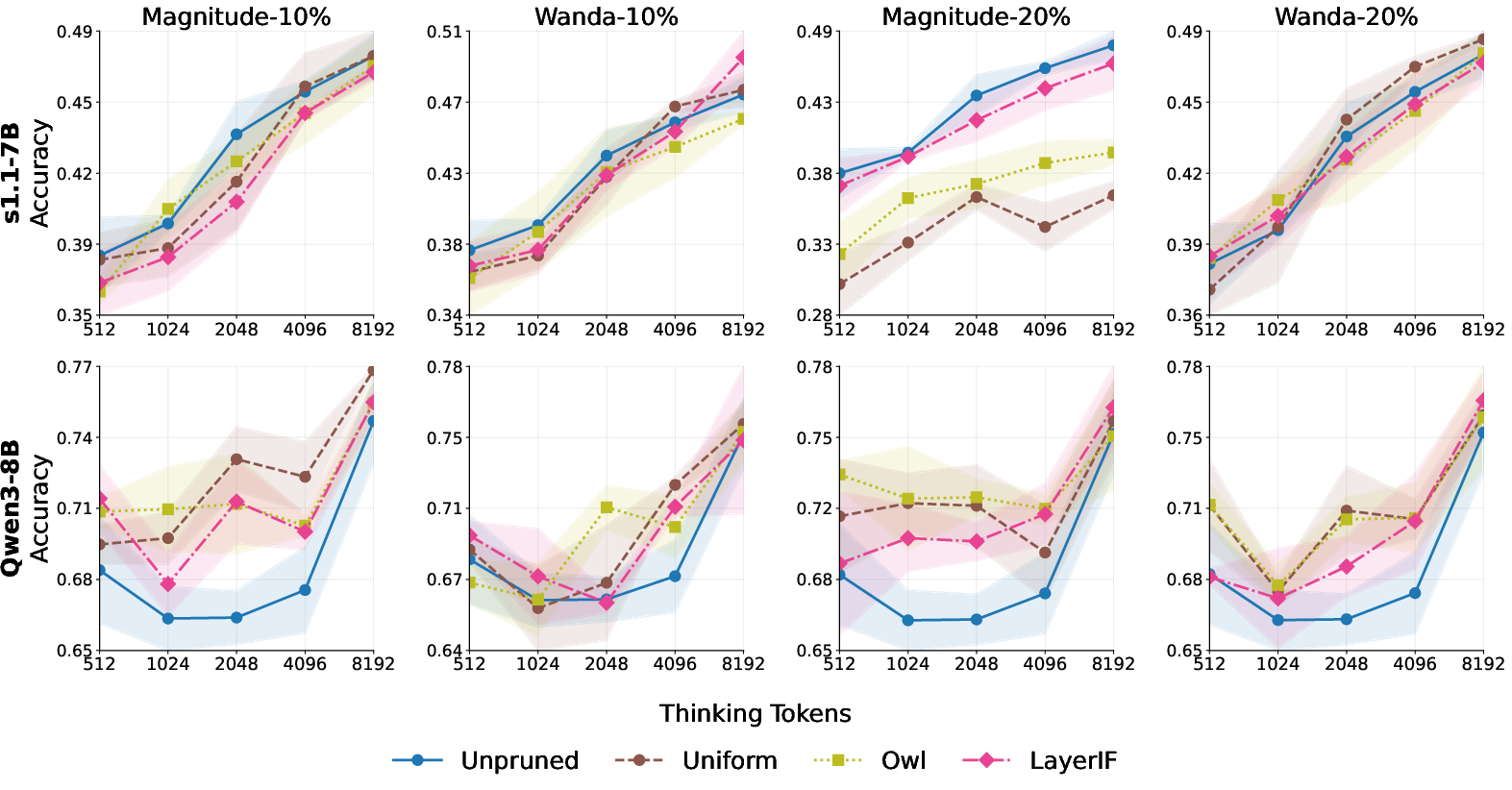
Figure 3: Non-uniform layerwise sparsity allocations (OWL, LayerIF) reliably mitigate or reverse any performance drop from unstructured pruning, especially at higher sparsity, for s1.1-7B and maintain strong performance for Qwen3-8B.
Layerwise ablation analysis reveals that the set of layers pruned by block-based structured pruning rarely overlaps with those selected for aggressive (non-uniform) pruning rates in the unstructured context, explaining differential impacts on model behavior.
Attention vs. MLP Pruning
Additional experiments (see supplement for details) show that isolating pruning to attention or MLP submodules yields minor performance variations; however, the choice of sparsity allocation strategy dominates, particularly for less redundant/overparameterized models.
Theoretical and Practical Implications
These results have several implications:
- For deployment scenarios requiring both efficiency and strong chain-of-thought (CoT)/reasoning, unstructured pruning unlocks the possibility to serve more performant models under compute and memory constraints without resorting to model retraining or finetuning.
- The findings suggest that large-scale LLMs contain substantial parameter redundancy—including components that hinder, rather than help, logical reasoning under TTS regimes.
- The nuanced impact of allocation strategy highlights the importance of further Bayesian, statistical, or data-influence-based pruning heuristics, especially for medium and lower-capacity LLMs.
- These observations likely generalize to other reasoning-promoting inference paradigms, e.g., self-consistency and test-time ensembling, though hybrid effects with other compression techniques (quantization, distillation) warrant in-depth investigation.
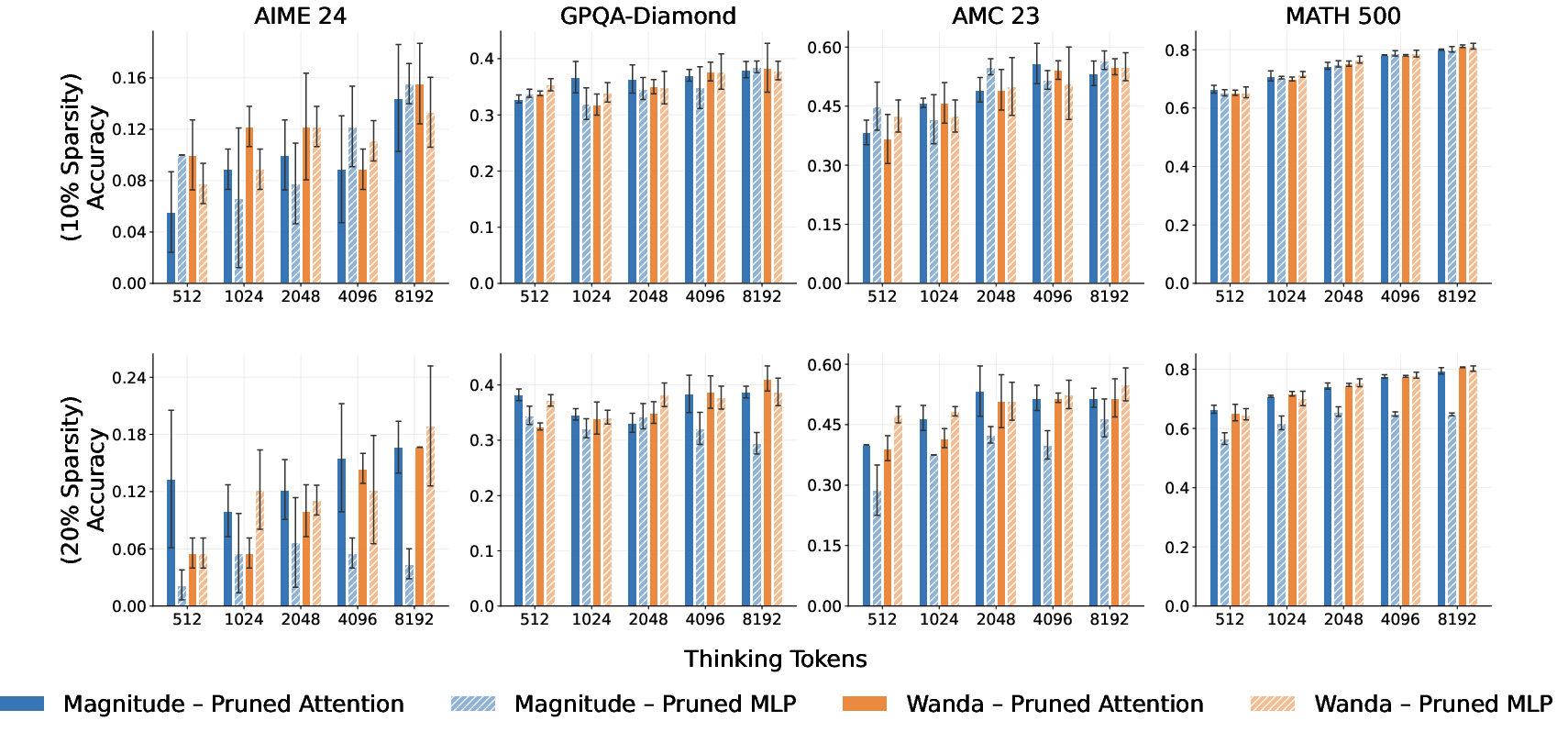
Figure 4: TTS reasoning accuracy for s1.1-7B as a function of sparsity ratio and pruned submodule (Attention or MLP); allocation method is uniform.
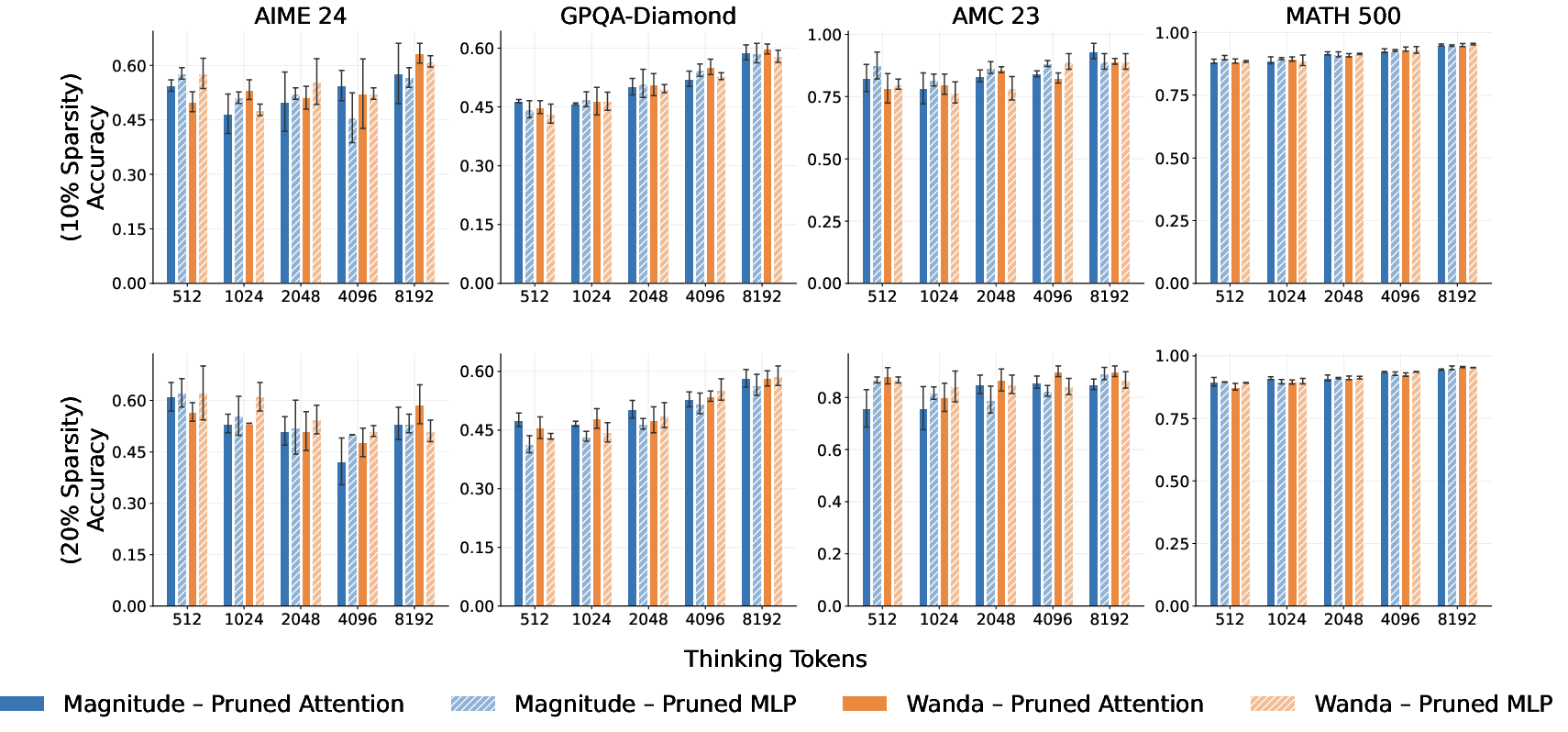
Figure 5: Analogous results for Qwen3-8B, reinforcing the robustness of unstructured pruning for both MLP and attention layers in high-capacity models.
Conclusion
This study rigorously demonstrates that unstructured pruning—particularly with careful layerwise sparsity allocation—can preserve or enhance LLM TTS reasoning performance, in direct contradiction to the consensus surrounding structured pruning. The results furnish evidence that not only is parameter redundancy significant, but some weights may actively interfere with effective CoT-style reasoning when additional compute is leveraged at inference. For high-resource, reasoning-centric deployment, the prudent application of unstructured pruning becomes a tractable path to scaling utility without retraining. These findings motivate the development of advanced, influence-aware pruning and sparsity allocation methods for next-generation LLMs.
References
- "Doing More With Less: Revisiting the Effectiveness of LLM Pruning for Test-Time Scaling" (2604.25098)