When Agent Automation Becomes Profitable: Quantifying and Insuring Autonomous AI Risk through Trace-Economic Underwriting
Abstract: AI agents can now take irreversible actions in operational systems, but agent-caused losses are still not clearly assigned, priced, or transferred. Providers often disclaim consequential damages, users are left with uncompensated losses, and default human review limits the efficiency gains of automation. We ask when autonomous AI deployment can become economically acceptable despite failure risk. Our answer is to quantify risk at the customer-task-trace episode level and transfer it through insurance. Automation is acceptable when its expected benefit exceeds the premium, control cost, and remaining risk. This requires a defined role with bounded permissions and comparable traces. We introduce trace-economic underwriting, which maps tool-use traces to customer exposure and claimable loss, then uses this representation for pricing, control, and risk transfer. It uses deterministic economic labels rather than an LLM judge. In our trace-to-loss testbed, trace-economic pricing reduces pricing MAE from $17.7K to $569 and removes regressive cross-subsidy. A 300-trace expert audit accepts 295 labels unchanged. On 1,000 real SWE-smith traces, trace-conditioned controls reduce CVaR95 by 72%. Theorem~1 gives a finite-sample scope condition. We release code, labels, and audit sheets.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about (big picture)
AI “agents” can now do real things on their own—like editing code, changing databases, sending messages, or moving money. That’s useful, but one bad click can delete data or break a system. Today, if an AI agent causes damage, the costs are often unclear and not covered: providers usually say they aren’t responsible, and users eat the loss. So companies keep humans in the loop, which slows things down and reduces the benefit of automation.
This paper asks a simple question: When does letting an AI act on its own actually make economic sense? The authors’ answer is to measure risk per job using the agent’s action logs and then use insurance to cover that risk. They propose a method called “trace-economic underwriting” that turns what the agent did (its “trace”) plus the customer’s situation into a fair price for insurance and smart rules about when to stop the agent or ask for human review.
What the researchers wanted to find out
They focused on a few easy-to-understand goals:
- How can we fairly measure the risk of an AI agent for each specific customer and task, instead of pricing by the AI model brand?
- How can we turn an agent’s action log into an estimate of possible money loss that could be claimed under an insurance contract?
- When should the system auto-allow actions, ask for human review, sandbox (limit) the action, or stop it—based on whether that prevents more expected loss than it costs?
- Under what conditions is it even possible to price this risk accurately with the data we have?
How their approach works (in everyday terms)
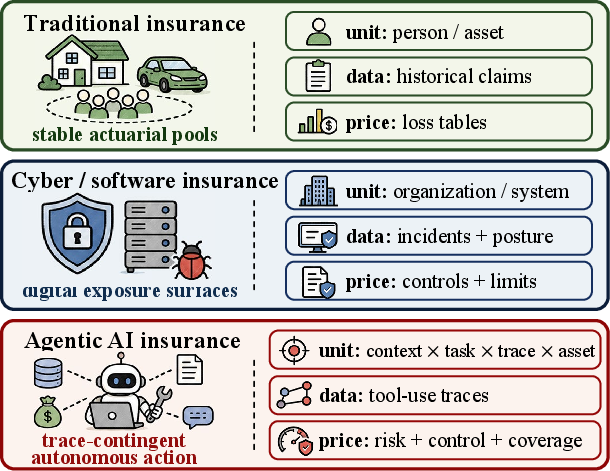
Think of an AI agent like a new employee. You don’t judge risk only by what company made their training course (the “model”). You look at:
- who they’re working for (customer),
- what job they’re doing (task and permissions),
- what they actually did (their action-by-action “trace” or log),
- what could be harmed (assets and their value),
- and what the insurance contract covers (deductible, limits, coinsurance).
Here’s the basic recipe they use:
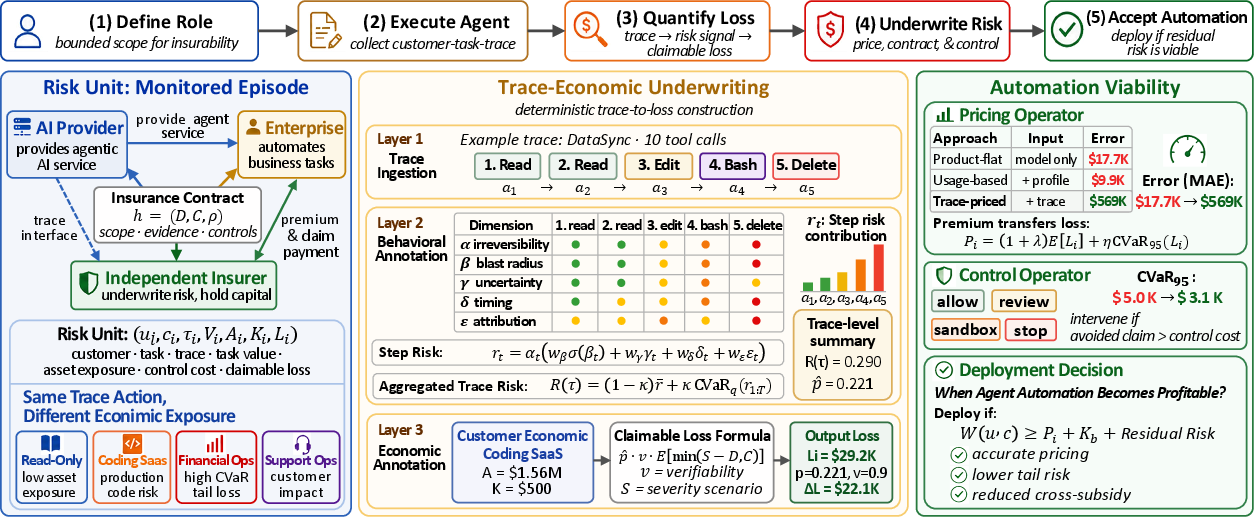
- Define a “role” with clear boundaries The agent must work within a defined role (e.g., “read-only analyst,” “coding assistant with limited write access,” or “finance ops with approval required”). This makes different episodes comparable, like grouping players by position in a sport.
- Read the “flight recorder” (the action trace)
The system parses the agent’s log into action types (read, write, delete, message, database, financial, execute). It tags each action along five simple, human-understandable dimensions:
- Irreversibility: Can this be undone? (Reading is reversible; deleting a database usually isn’t.)
- Blast radius: If it goes wrong, how much could it affect?
- Uncertainty: How unsure is the agent here?
- Timing: Did this action happen early or late in the process?
- Attribution/verifiability: Can we prove the action caused the loss?
- Turn those tags into risk numbers you can audit They combine the five dimensions into a risk score for the whole trace. No black-box AI judging the labels—just clear, documented rules anyone (auditors, customers, insurers) can check.
- Add the economics and the contract They mix the trace risk with customer information (like asset value) and contract terms (deductible, limit, coinsurance) to estimate “claimable loss”—what an insurer might actually have to pay if things go wrong.
- Set prices and controls using that same evidence
- Pricing: The premium is based on expected loss plus an extra amount for rare, very bad events (tail risk).
- Controls: The system decides whether to allow, review, sandbox, or stop an action if the expected loss avoided is bigger than the cost of intervening (like paying a human reviewer for 5 minutes).
Key idea: Pricing moves money (transfers loss); control prevents loss. You need both.
What they found and why it matters
The authors tested their method on a mix of synthetic portfolios and real agent traces (including 1,000 coding-agent traces from SWE-smith). Main results:
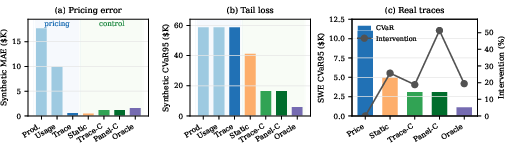
- Much more accurate pricing per episode When they priced insurance by “product/model” alone, the average pricing error was about $17,700 per episode. Using the trace-economic approach cut that to about$569. That’s a huge improvement and means customers aren’t unfairly overcharged or undercharged.
- Fairness: no more hidden cross-subsidy Flat, product-level pricing made low-risk users (like read-only or simple web automation) subsidize high-risk deployments (like financial ops) by $17K–$20K per episode. Trace-based pricing removed this regressive subsidy so each user pays for their own risk.
- Expert audit: rules are understandable and hold up Human experts reviewed 300 randomly sampled trace labels and accepted 295 unchanged, suggesting the rules are sensible and auditable.
- Real risk reduction with smart controls Using trace-aware controls cut the “worst 5% losses” (a tail risk measure often called CVaR at 95%) by 72% on 1,000 real traces—while reviewing far fewer cases than a heavy-handed human-review policy. In short: better protection, less friction.
- A clear boundary on what’s insurable A central theorem shows that accurate, data-driven pricing is only possible when the agent’s role is defined and permissions are bounded. If an agent can do anything, anywhere, you can’t gather comparable examples to learn from—so you can’t price it responsibly. Translation: general-purpose, no-rules agents aren’t insurable “as is”; role-bounded agents are.
Why these findings are important
- Safer, smarter automation Companies can let AI agents operate autonomously when it makes financial sense: if the expected benefit is bigger than the insurance premium, the cost of controls, and any risk that remains.
- Less unnecessary human review Instead of reviewing everything “just in case,” the system reviews only when it’s cost-effective. That keeps speed and efficiency while still preventing serious accidents.
- Fair and stable markets Charging by actual episode risk avoids overcharging low-risk users and stops a “market spiral” where safe customers drop out and only risky ones stay. That stability benefits everyone.
- Practical rules, not vague promises Using simple, auditable labels and clear contract terms (like deductibles and limits) makes it easier for insurers, customers, and regulators to understand and trust the system.
Final takeaways (what this means going forward)
- The right unit for judging and insuring agent risk isn’t the AI product—it’s the specific customer-task-trace episode under a defined role with bounded permissions.
- With trace-economic underwriting, automation can be profitable and responsibly insured even when failure isn’t impossible—because risk is measured, priced, and controlled in a clear, contract-ready way.
- However, this approach isn’t for open-ended, do-anything agents. For those, there isn’t enough structure to learn from or to write fair insurance. The path forward is to narrow the agent’s role, collect comparable histories, and then price and control based on what the agent actually does.
The authors released code, labels, and audit materials, aiming to help turn today’s messy “who pays when AI breaks stuff?” problem into a fair, measurable, and insurable system that supports safe, useful autonomy.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The following points identify what remains missing, uncertain, or unexplored in the paper and suggest concrete directions for future research:
- Data and calibration: No closed-claims dataset exists linking agent traces to adjudicated losses under real contracts; collect and standardize episode-level datasets (customer profile, task, trace, permissions, loss, evidence, settlement outcome) to calibrate severity tables, verifiability/attribution discounts, and premium loadings beyond scenario-derived anchors.
- Domain coverage: Empirical validation relies heavily on coding (SWE-smith) traces; build comparable trace corpora and economic labels for high-stakes domains (financial ops, healthcare workflows, support operations, ERP/CRM automation, data engineering) to test transferability and domain-specific calibration.
- Role specification: The approach depends on “defined roles” with bounded permissions; develop formal, auditable role-spec schemas (permitted tools/APIs, authority caps, state-access boundaries, failure modes) and methods to verify role compliance at runtime.
- Sample complexity in practice: Theorem 1 gives a role-bounded identification threshold but does not quantify , , and for real agent stacks; measure these quantities across common frameworks (e.g., LangChain, OpenAI functions, enterprise RPA) and estimate the data budget needed per role to reach reliable trace pricing.
- Runtime control realism: Control decisions assume a simple review cost K and expected avoided claim; empirically measure review/sandbox frictions, latency budgets, productivity impacts, and user acceptance across organizations, and compare static, panel, and trace-conditioned controls in live A/B deployments.
- Attribution and verifiability: The current attribution proxy is simplistic; design and validate trace-evidentiary standards (chain-of-custody, tamper-proof telemetry, external-state witnesses) and adjudication procedures for contested causality, partial verifiability, and multi-actor involvement.
- Systemic risk quantification: The systemic-loss toy model leaves and the systemic severity distribution under-specified; quantify cross-customer/cross-platform correlations (e.g., model updates, shared tool failures, SaaS outages) and design reinsurance layers or public backstops with empirically grounded parameters.
- Moral hazard and gaming: Pricing/control presumes truthful traces; analyze and mitigate strategic behavior (log tampering, tool routing to evade irreversibility gates, deliberate under-action to lower risk scores) via secure telemetry, attestations, and penalty clauses.
- Privacy and governance: Insurer monitoring of customer-task-trace episodes raises privacy/compliance concerns; specify data-minimization, anonymization, retention, and access-control policies that preserve underwriting utility while meeting regulatory requirements (e.g., GDPR/AI Act).
- Parameter learning: Risk weights (), link parameters (), and CVaR settings are weakly calibrated; develop robust estimation procedures (e.g., Bayesian calibration with priors from incident taxonomies, cross-role regularization, drift-aware updates) and quantify uncertainty in premiums and controls.
- Loss taxonomy completeness: Economic labels focus on direct operational losses; extend severity coverage to regulatory fines, contractual breaches, reputational harm, data privacy violations, and third-party liabilities, and clarify exclusions/sublimits with evidence rules.
- Counterfactual validity: Policy evaluation uses scenario-calibrated counterfactuals; formalize causal identification for avoided-claim estimates (instrumentation, interference assumptions, sensitivity analyses) and validate with live randomized gates.
- Experience rating and dynamics: Pricing is episode-level and largely static; study multi-episode experience rating, learning effects (agents and users adapt), concept drift from model updates, and periodic recalibration policies to maintain actuarial accuracy.
- Multi-agent and cross-episode exposure: The framework treats single-agent episodes; characterize interactions among multiple agents and cross-episode dependencies (e.g., cumulative writes, staged workflows) and their effect on attribution, severity, and controls.
- Contract adjudication processes: Deterministic labels support auditability, but practical claims handling (discovery, evidentiary standards, dispute resolution) is not specified; prototype end-to-end claims workflows and measure cycle times and contest rates.
- Reinsurance and capital modeling: Portfolio solvency analysis is synthetic; develop capital models (RBC, stress tests, catastrophe layers) for agent portfolios, calibrate tail loadings to market constraints, and evaluate participation impacts under real capital charges.
- Regulatory alignment: Map trace-economic underwriting to concrete regulatory requirements (EU AI Act risk management, audit trails, incident reporting) and identify gaps where regulations lack evidentiary or role-spec guidance.
- Fairness and market effects: While the paper shows regressive cross-subsidy removal, fairness across protected customer groups is not studied; assess disparate impacts of trace-based pricing and controls, and design guardrails (caps, community-rated layers) to prevent exclusion of small or resource-constrained users.
- Tool/action taxonomy portability: Action classification and risk dimensions are hand-crafted; validate portability to diverse tool ecosystems (databases, financial APIs, robotic process automation, cloud admin) and create shared taxonomies and parsers to reduce bespoke engineering per role.
- Open-ended agents: The method explicitly excludes exploration/self-improving loops; investigate minimal-scoping strategies (caps, staged permissions, runtime authority frontiers) that make parts of open-ended systems insurable, or formalize criteria for when public-risk governance must replace private underwriting.
- Security of telemetry: The approach relies on accurate logs; specify and test cryptographic attestation, secure enclaves, and third-party monitoring to ensure telemetry integrity and non-repudiation.
- Buyer value measurement: Viability uses (buyer value) but lacks empirical estimation; measure customer-specific automation value and integrate it into deployment decisions alongside premiums, controls, and tail capital.
- Standardization: There is no industry standard for episode schemas, economic labels, or evidence rules; develop open standards and benchmarks that enable cross-insurer comparability and regulatory oversight.
Practical Applications
Immediate Applications
The following applications can be deployed now, building on the paper’s deterministic trace-to-loss representation, role-bounded deployment, and trace-conditioned pricing/control results (e.g., 72% CVaR95 reduction and sharp pricing MAE improvements).
- Industry (Software/DevOps): “Insurance-ready” agent deployments for coding and IT automation
- What: Define agent roles (e.g., “SaaS coding assistant”), bound permissions, and export the standardized episode object with the five trace dimensions (irreversibility, blast radius, uncertainty, position, attribution). Use trace-conditioned gates (allow/review/sandbox/stop) when avoided claim > review cost.
- Tools/Products/Workflows:
- Runtime policy engines embedded in agent frameworks (e.g., LangChain/AutoGen/OpenAI Assistants plugins) computing R(τ) live.
- CI/CD guardrails for destructive commands (e.g., rm -rf, DROP TABLE) that trigger review or sandboxing based on trace risk and asset values.
- Premium calculators using CVaR-loaded pricing for each episode; dashboards for risk, expected claim, and avoided loss.
- Assumptions/Dependencies: High-quality logs; role scoping and permissions; customer-provided asset values/review costs; acceptance of deterministic labeling; initial calibration for p=σ(aR+b); legal approval of evidence rules; privacy-preserving logging.
- Industry (Customer Support/CRM): Safe automation of ticket handling and CRM updates with selective oversight
- What: Apply trace gating to LLM support agents that write to CRM or billing fields; intervene only when expected claim net of deductible/limit exceeds review friction.
- Tools/Products/Workflows: CRM connectors that tag irreversible field writes; predefined sublimits/coinsurance for low-verifiability content edits; review queues for high R(τ) actions.
- Assumptions/Dependencies: Clear attribution/verifiability definitions for database writes; episode schema integrated into CRM audit logs.
- Industry (Finance Ops/Back Office): Risk-priced autonomy for reconciliation, invoice processing, and ledger updates
- What: Introduce per-episode premiums and dynamic gating for bots that touch financial systems; apply higher deductibles/coinsurance for partial-verifiability outputs.
- Tools/Products/Workflows: AP/AR bots with trace-economic hooks; pre-commit checks for journal entries; automated calculation of expected claim vs review cost.
- Assumptions/Dependencies: Strong attribution evidence for writes; strict role boundaries; alignment with internal controls (SOX) and audit trails; potential reinsurance for systemic failures.
- Insurance (Carriers/MGAs): Pilot trace-economic underwriting programs for agentic AI
- What: Offer riders or standalone policies priced at the customer-task-trace level; couple premiums with runtime control recommendations to reduce tail risk and capital needs.
- Tools/Products/Workflows: Underwriting workbench ingesting episode objects; rulebooks for severity/coverage; parametric-like triggers based on verifiable traces; coinsurance/sublimits for low-verifiability claims; reinsurance layers for systemic risk.
- Assumptions/Dependencies: Contract clauses that fix evidence rules; solvency models with CVaR; actuarial governance; client cooperation for logging and role scoping.
- Platform Vendors/Cloud Providers: “Insured autonomy” SKUs and telemetry standards
- What: Provide standardized logging, episode exports, and permission-scoped roles to make customers insurable; optionally bundle third-party insurance.
- Tools/Products/Workflows: Managed “episode schema” APIs; permission templates; built-in verifiability attestations (e.g., tamper-proof logs, integrity checks).
- Assumptions/Dependencies: Vendor legal posture on consequential damages; secure logging; partner insurer appetite.
- Risk/Compliance (CISOs, CROs, Procurement): ROI-based autonomy governance
- What: Replace blanket human-in-the-loop defaults with trace-conditioned oversight, using the viability function G⋆ to decide when autonomy is economically justified.
- Tools/Products/Workflows: Governance dashboards (expected claim, tail capital, review friction, buyer value); procurement requirements for role scoping and episode logging; vendor due diligence checklists for trace-economic readiness.
- Assumptions/Dependencies: Organizational consensus on review costs and buyer value; policy acceptance; training for claims evidence handling.
- Legal/Contracts: Evidence-based coverage terms for agent deployments
- What: Contract templates codifying deductibles, limits, coinsurance, exclusions, sublimits, and evidence rules (attribution/verifiability) aligned with trace-economic labels.
- Tools/Products/Workflows: Clause libraries for partial-verifiability claims; systemic-risk carve-outs and reinsurance references; dispute-resolution procedures referencing logs.
- Assumptions/Dependencies: Enforceable log integrity; regulator acceptance of evidence standards; client data-sharing agreements.
- Academia/Standards Bodies: Benchmarks, datasets, and parser standards
- What: Extend the released code/labels to non-coding domains (web, databases, workflow); establish open benchmarks using the episode schema; stress-test auditability and portability.
- Tools/Products/Workflows: Community datasets with deterministic labels; ablation studies; sample-complexity validations; ISO-like proposals for action classes and risk dimensions.
- Assumptions/Dependencies: Consent to share traces; redaction protocols; funding for longitudinal data collection.
- Daily Life (Prosumer/SMBs): Safe use of off-the-shelf AI automations
- What: Adopt tools that apply review-on-risk for website updates, email campaigns, or bookkeeping bots; opt into per-episode micro-coverage for risky actions.
- Tools/Products/Workflows: Low-code platforms with built-in risk meters and one-click review; optional micro-deductibles for destructive operations.
- Assumptions/Dependencies: Simpler severity scales; basic attribution; willingness to share minimal telemetry with insurer.
Long-Term Applications
These applications require further research, scaling of claims data, standardization, integration across vendors, or regulatory development.
- Insurance Markets: Mature, standardized AI autonomy insurance with pooled claims data
- What: Industry-wide claims databases tied to episode schemas; rating models updated from real closed claims; capital markets (cat bonds) for systemic AI ops risk.
- Tools/Products/Workflows: Shared loss registries; standardized severity tables; portfolio CVaR optimization; reinsurance treaties for model-update/systemic layers.
- Assumptions/Dependencies: Data-sharing frameworks (possibly via secure MPC); regulatory approval; anti-adverse selection measures.
- Cross-Enterprise Control Planes: Optimization of autonomy level vs premium vs throughput
- What: Enterprise “autonomy controllers” that jointly minimize expected claim + tail capital + review cost subject to SLA constraints, dynamically tuning permissions and oversight.
- Tools/Products/Workflows: Policy orchestration platforms; simulation sandboxes; integration with workflow engines and identity/permissions systems.
- Assumptions/Dependencies: High-fidelity calibration; multi-agent coordination; robust organizational change management.
- Robotics/Industrial Automation: Trace-economic coverage for physical agents
- What: Extend five-dimension trace assessments to robots (irreversibility/blast radius include physical damage/injury); insure task-bounded roles (e.g., warehouse picking, inspection).
- Tools/Products/Workflows: Robot telemetry mappers to episode objects; verifiability oracles for actions; safety interlocks as pre-loss controls; premiums reflecting physical exposure.
- Assumptions/Dependencies: Rich sensor logs; safety certification alignment; higher regulatory scrutiny; injury and third-party liability integration.
- Healthcare (Clinical Workflows): Risk-priced autonomy in non-trivial medical contexts
- What: Coverage for agentic tasks such as order entry suggestions, coding, scheduling, or bounded medication reminders with clinician-in-the-loop thresholds.
- Tools/Products/Workflows: EHR-integrated episode logging; evidence rules for clinical verifiability; sublimits/coinsurance for low-verifiability decisions; standardized scope-of-practice roles.
- Assumptions/Dependencies: Regulatory approvals (HIPAA/GDPR, EU AI Act); rigorous audit trails; calibrated severities for patient safety; clinical governance.
- Finance (Front-Office/Trading): Risk-weighted autonomy with real-time premium signals
- What: “Pay-as-you-act” coverage where premiums and interventions update intra-day based on evolving trace risk; restricted authority frontiers for booking/trading.
- Tools/Products/Workflows: Millisecond-level telemetry; parametric triggers; integration with risk limits, market surveillance, and kill switches.
- Assumptions/Dependencies: Extremely low-latency adjudication signals; market oversight; strong systemic-risk layers.
- Public Sector/Critical Infrastructure: Procurement standards and public backstops
- What: Mandate role scoping and episode auditability in government agent deployments; establish public insurers-of-last-resort for systemic AI ops risks.
- Tools/Products/Workflows: AI Act-aligned guidance; centralized backstop funds; certification schemes for trace-economic readiness.
- Assumptions/Dependencies: Legislative processes; funding; clear systemic-risk boundaries.
- Standards and Ecosystems: Global schemas and taxonomies for agent risk
- What: ISO-like standards for action classes, risk dimensions, attribution metrics, and evidence rules; interoperability across vendors and insurers.
- Tools/Products/Workflows: Conformance tests; certification bodies; shared reference implementations.
- Assumptions/Dependencies: Industry coordination; backward compatibility for legacy logs.
- Training-Time Feedback: Agents that learn to minimize insured loss surfaces
- What: Incorporate R(τ) and insured loss into training objectives (reward shaping) so agents naturally avoid high-irreversibility/high-blast actions unless economically justified.
- Tools/Products/Workflows: Offline datasets with labeled episodes; counterfactual policy evaluation; safe exploration protocols.
- Assumptions/Dependencies: Stable, auditable reward definitions; prevention of gaming; oversight for distribution shifts.
- Privacy-Preserving Sharing: Federated calibration and underwriting analytics
- What: Secure multiparty computation and federated learning to calibrate p and severity without exposing raw logs; differential privacy for benchmarking.
- Tools/Products/Workflows: Federated risk analytics platforms; privacy budgets; zero-knowledge proofs for claims evidence.
- Assumptions/Dependencies: Cryptographic assurances; regulator acceptance of privacy-preserving evidence.
- Consumer Micro-Insurance: Household agents with per-episode coverage
- What: Smart home/IoT, personal finance, or device-management agents with micro-deductibles and automatic review on high-risk actions (e.g., payment changes, device resets).
- Tools/Products/Workflows: Home hubs exporting simplified episode objects; app-level dashboards of risk and premiums; opt-in coverage toggles.
- Assumptions/Dependencies: Simple severity scales; user-friendly consent and evidence; affordable distribution.
- Automated Claim Adjudication: Parametric-like triggers and verifiability oracles
- What: Semi-automated claims settlement when deterministic evidence rules are satisfied (e.g., confirmed destructive DB write) with fallbacks to human adjudication for low-verifiability cases.
- Tools/Products/Workflows: Verifiability oracles; tamper-evident logs; provenance attestations; smart contracts or off-chain rules engines.
- Assumptions/Dependencies: Legal recognition of parametric proxies; robust anti-fraud measures; dispute-resolution frameworks.
- Capital Markets Integration: Reinsurance and AI operational risk-linked securities
- What: Transfer tail and systemic layers to capital markets using portfolio-level CVaR metrics and scenario triggers based on shared episode data.
- Tools/Products/Workflows: Risk models audited by third parties; transparent systemic event definitions (e.g., model update failures); investor disclosures.
- Assumptions/Dependencies: Market appetite; reliable systemic-loss modeling; harmonized disclosures.
Notes on feasibility across all applications:
- Core dependencies: defined roles with bounded permissions; comparable, high-integrity logs; deterministic, auditable labeling rules; access to customer economic parameters (asset/task value, review cost); calibrated p(·) and severity tables; governance for privacy and data sharing; coinsurance/sublimits/exclusions for low-verifiability claims; reinsurance or public backstops for systemic risk.
- Key assumptions to monitor: regulator and insurer acceptance of trace evidence; stability of calibration under distribution shifts; organizational capacity to implement runtime control without excessive friction; avoidance of perverse incentives or gaming of the risk signal.
Glossary
- Adverse selection: A market failure where mispricing drives low-risk buyers out, leaving a higher-risk pool and raising average costs. "Adverse selection. Product-flat pricing creates a market failure: low-risk customers exit after subsidizing high-risk deployments, the pool becomes increasingly financial, and the flat premium rises toward high-risk cost."
- Attribution (verifiability): The ability to tie a loss to specific agent actions and verify it for claims adjudication. "Here is claim probability, is conditional severity, is attribution/verifiability, and is pre-loss review or sandbox cost."
- Bayes pricing rule: Setting prices equal to the expected loss conditional on available information. "Proposition~1 is the law of total variance applied to the Bayes pricing rule ."
- Blast radius: The potential scope or extent of impact an action can have on assets. "Layer~2 assigns five inspectable dimensions to each action: irreversibility , blast radius , epistemic uncertainty , temporal position , and causal attribution ."
- Coinsurance: A policy term where the insured shares a fixed fraction of covered losses after the deductible. "An insurance contract specifies deductible , limit , coinsurance , and evidence rules for claimability."
- Consequential-damage disclaimers: Contractual clauses that limit liability for indirect or consequential losses. "Providers often limit responsibility through consequential-damage disclaimers,"
- Counterfactual policy evaluation: Assessing alternative pricing or control policies using observed traces without deploying them live. "The same representation supports counterfactual policy evaluation across pricing and control policies."
- Cross-subsidy: When one group overpays to subsidize another group’s risk within a pooled pricing scheme. "and removes regressive cross-subsidy."
- CVaR (Conditional Value at Risk): The expected loss in the tail beyond a specified quantile, capturing severity of worst outcomes. "On 1,000 real SWE-smith traces, trace-conditioned controls reduce CVaR by 72\%."
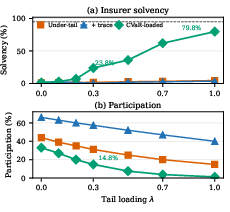
- CVaR-loaded premiums: Premiums augmented by an explicit charge for tail risk measured via CVaR. "CVaR-loaded premiums protect the insurer at the cost of lower buyer participation."
- Deductible: The amount the insured must pay out-of-pocket before insurance coverage applies. "An insurance contract specifies deductible , limit , coinsurance , and evidence rules for claimability."
- Defined role: A bounded task and permission profile that yields comparable, auditable traces for pricing and control. "This requires a defined role with bounded permissions and comparable traces."
- Epistemic uncertainty: Uncertainty due to incomplete knowledge about the environment or task, affecting the risk of actions. "Layer~2 assigns five inspectable dimensions to each action: irreversibility , blast radius , epistemic uncertainty , temporal position , and causal attribution ."
- Finite-sample identifiability: The condition under which reliable estimation is possible with limited data given a bounded feature space. "Theorem~1 explains the scope: trace pricing is finite-sample identifiable only when a defined role bounds the trace feature space."
- Insurability: The feasibility of transferring risk via insurance given measurable exposure, verifiable losses, and workable contract terms. "Insurability depends on asset value, claimability, attribution, deductible, limit, and intervention cost,"
- Law of total variance: A variance decomposition principle used to quantify the value of additional information for pricing accuracy. "Proposition~1 is the law of total variance applied to the Bayes pricing rule ."
- Limit (policy limit): The maximum amount an insurer will pay for a covered loss. "An insurance contract specifies deductible , limit , coinsurance , and evidence rules for claimability."
- Product-flat pricing: Charging the same premium for all users of a product regardless of their actual exposure or trace. "product-flat pricing pools heterogeneous customers"
- Public backstop: Government-provided coverage as insurer of last resort for catastrophic or systemic losses. "Thus trace segmentation must be paired with limits, reinsurance, exclusions, or a public backstop for systemic loss."
- Reinsurance: Insurance purchased by insurers to transfer portions of risk to other insurers. "Deductibles, limits, coinsurance, exclusions, sublimits, and reinsurance are not post-hoc legal details:"
- Solvency: An insurer’s ability to meet its financial obligations, often requiring capital for tail losses. "Under-tail pricing remains insolvent even with trace information, while CVaR-loaded pricing raises solvency from 1.7\% to 23.8\% at and from 4.5\% to 79.8\% at ."
- Sublimits: Specific caps within a policy that restrict coverage for certain perils or categories. "Deductibles, limits, coinsurance, exclusions, sublimits, and reinsurance are not post-hoc legal details:"
- Systemic loss: Losses arising from broad, correlated failures that affect many insureds simultaneously. "Thus trace segmentation must be paired with limits, reinsurance, exclusions, or a public backstop for systemic loss."
- Tail capital: Capital held to absorb extreme, low-probability losses in the tail of the loss distribution. "the premium formula must explicitly carry tail capital,"
- Tail risk: The risk of rare but severe losses in the extreme tail of the loss distribution. "tail risk falls only when the same trace signal triggers pre-loss control,"
- Trace-economic underwriting: An underwriting approach that maps tool-use traces to economic exposure for pricing, control, and risk transfer. "We introduce trace-economic underwriting, which maps tool-use traces to customer exposure and claimable loss, then uses this representation for pricing, control, and risk transfer."
- Usage-based pricing: Pricing conditioned on customer profile, task category, and usage context rather than product identity alone. "usage-based pricing adds customer profile and task category;"
- Verifiability: The degree to which a claimed loss can be substantiated with evidence for payout. "Layer~3 maps , customer profile, task category, asset value, and contract terms to claim probability , conditional severity , and verifiability :"
Collections
Sign up for free to add this paper to one or more collections.