You Don't Need Strong Assumptions: Visual Representation Learning via Temporal Differences
Abstract: Progress in AI has largely been driven by methods that assume less. As compute and data increase, approaches with weaker inductive biases generally outperform those with stronger assumptions. This is particularly characteristic of the field of Visual Representation Learning, where approaches have gone from being dominated by Supervised Learning, to Weakly Supervised Learning, to the now widespread success of Self-Supervised Learning without human labels. Yet, even modern Self-Supervised Learning approaches still depend on strong inductive biases such as augmentations, masking, or cropping. If this trend holds, even these remaining biases should become bottlenecks at scale -- and our experiments confirm this: the optimal strength of inductive biases decreases as data grows. This motivates the search for approaches that rely on fewer assumptions. To this end, we introduce Temporal Difference in Vision (TDV), a new paradigm for self-supervised learning from video that avoids existing inductive biases, relying instead on a causal assumption that the past causes the future. TDV functions by jointly training an image encoder and a motion encoder so that the current frame's representation plus the encoded motion equals the next frame's representation. Despite not leveraging any strong inductive biases, TDV matches state-of-the-art recipes on dense spatial tasks, laying the foundation for representation learning without strong assumptions.





Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Explaining “You Don’t Need Strong Assumptions: Visual Representation Learning via Temporal Differences”
1) What is this paper about?
This paper is about teaching computers to understand videos without using lots of hand-made tricks. The authors introduce a new way, called Temporal Difference in Vision (TDV), that learns by watching how things change from one video frame to the next. Instead of relying on heavy “shortcuts” like random crops or color changes during training, TDV uses a simple idea: the near future can be predicted from the recent past.
2) What questions are the authors asking?
The authors ask:
- Can we learn strong visual features from videos while using fewer built‑in assumptions or tricks?
- Is a simple “cause → effect” idea (the past helps predict the future) enough to guide learning?
- As we get more data, do methods with fewer assumptions actually do better?
3) How does their method work?
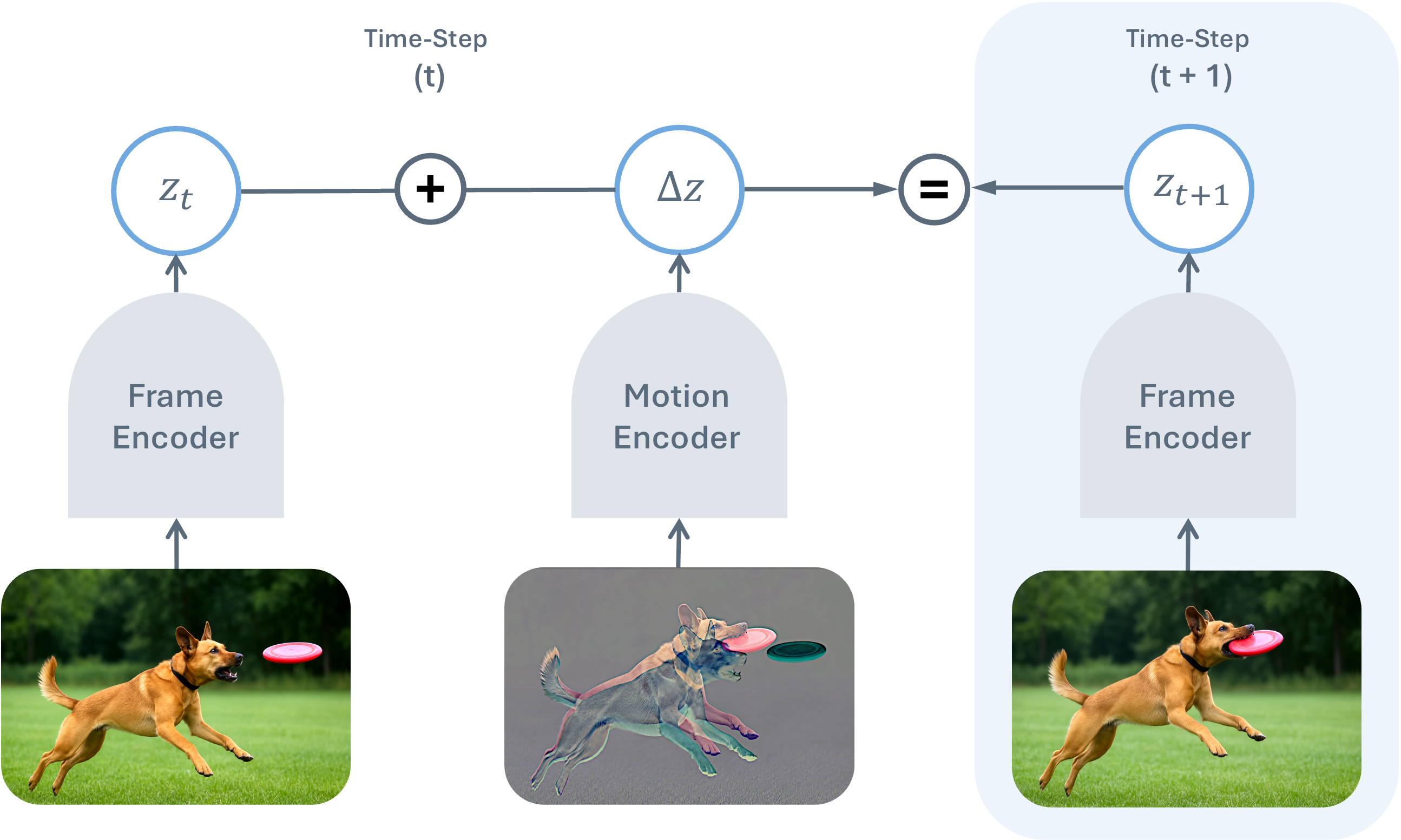
Think of a video like a flipbook. Each frame is a picture, and the difference between two frames is motion (what moved, where it moved, and how). TDV learns two things at the same time:
- An image “summarizer” (called a frame encoder) that turns a frame into a compact representation (like smart notes the computer keeps about the image).
- A motion “summarizer” (called a motion encoder) that turns the change between two frames into a compact motion note.
The key idea is simple:
- If is the representation (the smart notes) of the current frame, and is the representation of the motion between the current frame and the next one, then the next frame’s representation should be about:
In words: next = now + motion.
Why this makes sense:
- Between two nearby frames, most of the scene doesn’t change. Only moving parts (like a dog jumping or a frisbee flying) change. So the “difference” is smaller and easier to describe than the whole image.
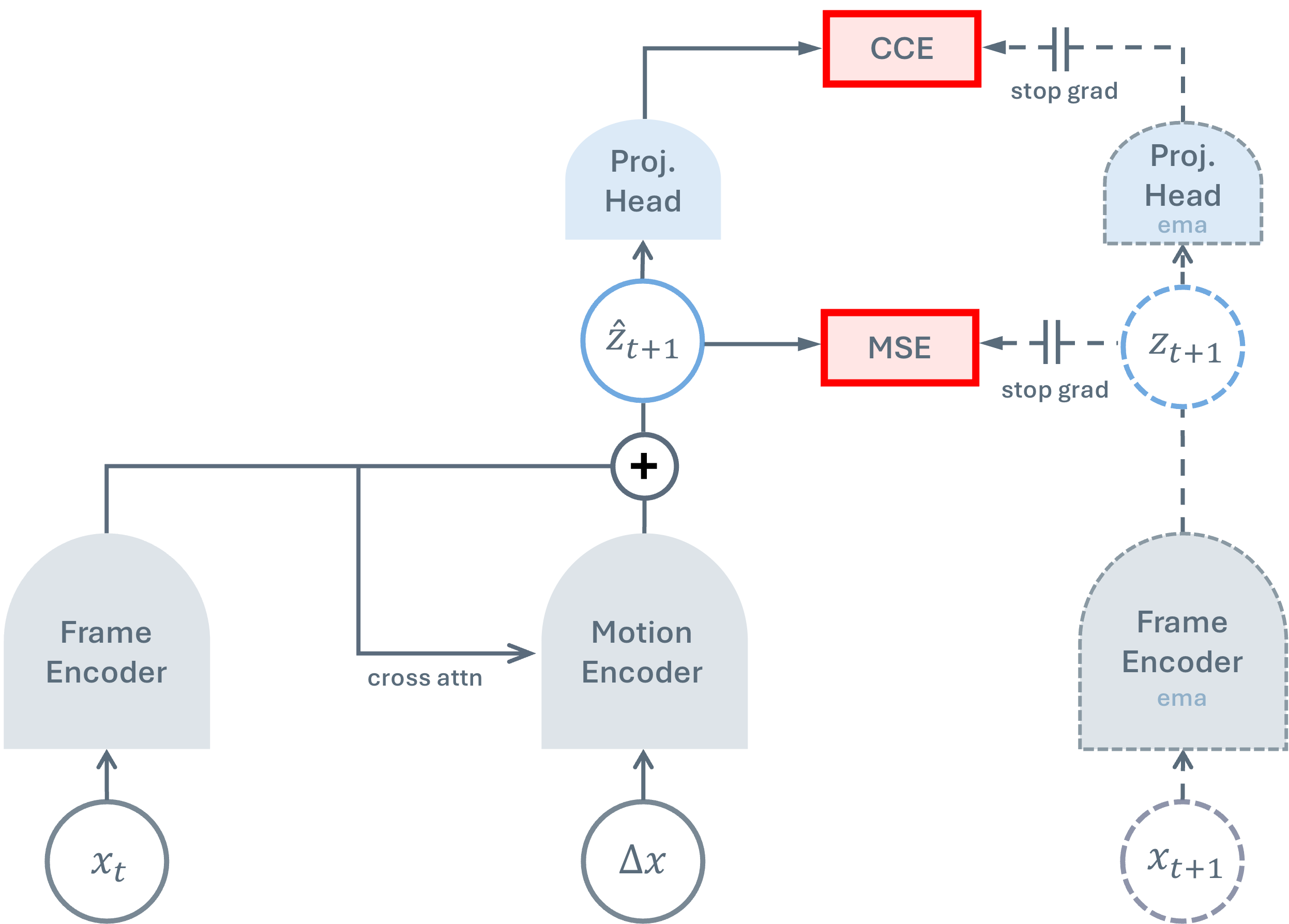
How the learning is stabilized:
- Teacher–student setup: There are two copies of the image summarizer. The “teacher” is a slowly updated copy of the “student.” The student tries to match the teacher’s target for the next frame. This prevents the model from cheating by making every frame look the same (a failure called “collapse”).
- Two training signals:
- A “make the next frame’s notes match” signal (a mean‑squared error in the representation space).
- A “don’t make everything identical” signal (a DINO-style cross‑entropy that keeps features informative).
Key terms in everyday language:
- Representation: a compact set of numbers that captures what matters in an image (like organized bullet points instead of raw pixels).
- Encoder: a tool that makes those smart notes from raw images or motion.
- Inductive bias: a built-in assumption or trick you add to guide learning (like always cropping images). Too many strong biases can hold you back at large scale.
- Self‑supervised: learning from the data itself without human labels.
- Collapse: when the model gives the same answer for everything (useless).
- Temporal difference: using the change between consecutive frames to learn.
4) What did they find, and why is it important?
Here are the main takeaways from their experiments:
- Less bias wins with more data: When they tested different “assumption strengths” (like how much of an image to mask), they found that as the dataset grows, weaker assumptions perform better. This supports the idea that heavy tricks can become bottlenecks at scale.
- TDV works without strong tricks: Even though TDV doesn’t use common heavy tricks (like random crops, color jitter, or masking), it learns good features.
- Strong on motion and structure tasks: TDV often beats popular methods (like DINO and iBOT) on tasks that need precise motion and spatial understanding, such as optical flow (tracking how each pixel moves) and stereo depth (estimating distance from pairs of images).
- Competitive on segmentation: On semantic segmentation (labeling each pixel by object type), TDV is close to DINO and iBOT, though sometimes slightly behind. That’s notable because TDV isn’t using the usual augmentations that often help with semantics.
Why this matters:
- It shows we can learn from videos using a natural, general idea—“the past predicts the future”—instead of many hand-tuned tricks.
- It suggests a path toward methods that improve as data scales, without getting stuck because of strong assumptions.
5) What’s the impact, and what could come next?
- Scales better with big data: Methods with fewer hard-coded assumptions often keep improving as we throw more data and compute at them. TDV fits that direction.
- Works beyond images: The “past predicts the future” idea can apply to other timed data, like audio or sensor readings in robots.
- Faster video processing: In the future, you might only need to compute a full representation for the first frame, then use light-weight motion updates for later frames—similar to how video compression stores key frames and small in‑between changes.
Limitations and future work:
- Not the best yet on all semantic tasks: Without augmentation tricks, TDV can lag slightly on some semantic benchmarks. There’s room to combine the strengths of both worlds.
- Needs bigger, better video data: The authors think that with larger, higher-quality video datasets and tuning, TDV could scale even further.
In short, TDV shows that a simple, natural assumption—“nearby future can be predicted from the recent past”—is enough to learn useful visual features from video, often matching or beating methods that rely on heavy training tricks. It’s a promising step toward more general, scalable learning.
Knowledge Gaps
Below is a single, actionable list of concrete knowledge gaps, limitations, and open questions that remain unresolved in the paper and can guide future research:
- Scaling behavior: Establish data/model/compute scaling laws for TDV by pretraining on substantially larger and more diverse video corpora (e.g., Kinetics-700, Something-Something V1+V2 combined, Ego4D, YouTube datasets) with systematic hyperparameter retuning and report trends in downstream performance and stability.
- Baseline coverage: Compare TDV against strong video SSL baselines that also exploit temporal structure (e.g., VideoMAE/VideoMAE‑V2, V-JEPA variants, TimeSformer-based SSL, Midway Networks) under matched data and compute to contextualize TDV’s gains and trade-offs.
- Semantic gap: Quantify and close the semantic performance deficit by studying the minimal set of weak invariances (e.g., mild crop/resize, color jitter, or patch dropout) that can be added to TDV without eroding its spatial/temporal strengths; report the full trade-off curve (dorsal vs. ventral tasks).
- Motion input choice: Test robustness and effectiveness of alternative motion inputs beyond raw RGB differences (e.g., learned low-level features, brightness-normalized deltas, optical flow, event-like gradients, multi-frame deltas) and measure sensitivity to illumination changes, compression artifacts, and noise.
- Global camera motion: Analyze TDV’s behavior under dominant egomotion (pans, zooms, shakes) and evaluate whether subtracting estimated camera motion, using stabilization, or conditioning on egomotion signals improves representations.
- Shot boundaries and edits: Introduce and evaluate mechanisms to detect and handle hard cuts or large scene changes (e.g., train-time cut detectors or curriculum that skips such pairs) to prevent degenerate motion encodings at discontinuities.
- Variable temporal gaps: Study training with variable and longer frame skips (Δt > 1) and multi-step prediction; quantify how temporal horizon affects representation quality on motion- and geometry-sensitive tasks.
- Additive update assumption: Test alternative latent composition operators beyond z_{t+1} ≈ z_t + Δz (e.g., gated residuals, multiplicative interactions, affine transforms, or group-action/Lie-algebra updates) and assess whether they better capture complex dynamics.
- Long-range temporal modeling: Extend TDV with memory/recurrent or temporal-attention mechanisms over multiple frames to capture acceleration, occlusion cycles, and longer-term dependencies; analyze benefits vs. added complexity.
- Collapse prevention theory: Provide theoretical or empirical characterization of stability regions for the joint MSE + DINO losses (e.g., sensitivity to prototype count, centering, temperature settings, teacher EMA momentum) and derive guidelines for robust training across datasets.
- Architectural biases: Quantify how much representation quality depends on ViT-specific choices (patch size, absolute vs. rotary positional encoding, tokenization) by comparing alternative backbones (ConvNets, Mamba/state-space models, hybrid CNN‑ViT) and positional schemes.
- Motion/appearance disentanglement: Diagnose whether Δz encodes object motion vs. camera motion vs. appearance changes; develop probes/metrics for disentanglement and test auxiliary objectives (e.g., camera/scene factor heads) to encourage separation.
- Uncertainty and stochasticity: Incorporate probabilistic or multimodal prediction (e.g., variational Δz, ensembles) to handle inherently unpredictable dynamics and evaluate whether uncertainty-aware TDV improves downstream robustness.
- Robust loss design: Evaluate alternative prediction losses (e.g., Huber, Charbonnier, cosine, feature-wise adaptively weighted losses) for the temporal MSE term to reduce sensitivity to outliers, occlusions, or annotator-free noise.
- Task breadth: Expand downstream evaluations to additional spatial–temporal tasks (e.g., tracking, video object segmentation, action segmentation, structure-from-motion/SLAM, monocular depth/normal estimation, keypoint estimation) to more comprehensively characterize TDV’s capabilities.
- Detection and instance-level semantics: Assess transfer to detection/instance segmentation (e.g., COCO, LVIS) with standard fine-tuning protocols to quantify how the lack of invariance biases affects object-centric tasks.
- Video-to-image transfer: Systematically study domain shift from video-pretrained features to static-image tasks and isolate factors (frame selection, motion magnitude, dataset bias) that hinder or help transfer.
- Efficiency claims: Substantiate the proposed codec-like efficiency benefit by profiling a streaming inference setup where only the motion encoder updates subsequent frames; report savings (GFLOPs, latency, energy) vs. accuracy trade-offs.
- Multi-modality: Validate TDV’s domain-agnostic claim by extending to other temporally coherent modalities (audio, proprioception, tactile) and to multimodal settings (e.g., audio–video), measuring cross-modal transfer and complementarity.
- Data quality and diversity: Quantify the impact of data curation (video quality, motion richness, scene diversity) on TDV’s performance, and establish dataset properties (e.g., motion statistics) that predict successful pretraining.
- Failure modes: Characterize common failure cases (fast nonrigid motion, heavy occlusions, low light, severe compression) and design targeted training curricula or augmentations (e.g., synthetic occlusions, motion blur) to mitigate them.
- Representation analysis: Investigate whether Δz lives in a low-dimensional subspace, how its spectrum evolves during training, and whether learned motion bases are consistent across videos; explore interpretability and compositionality of motion vectors.
- Minimal assumptions quantification: Formalize and empirically validate a measurable notion of “assumption strength” applicable to TDV (beyond masking ratios in image JEPAs) and correlate it with performance across scales to strengthen the central hypothesis.
Practical Applications
Immediate Applications
The following applications can be deployed now, leveraging TDV’s strengths in motion- and structure-centric representation learning (optical flow, stereo, segmentation) without heavy augmentations or labels.
- Visual perception backbones for robotics (robotics)
- Use TDV-pretrained encoders to improve optical flow, stereo depth, and scene segmentation modules in SLAM/visual odometry, navigation, and manipulation tracking.
- Tools/workflows: replace or initialize perception backbones in ROS/Isaac stacks; fine-tune on task-specific video with minimal labels; integrate into stereo/flow heads trained on MPI-Sintel/SceneFlow.
- Assumptions/dependencies: temporal consistency and predictable short-horizon dynamics; camera calibration quality; domain shift handling (indoor/outdoor); compute budget for initial pretraining.
- Autonomous driving perception stack improvements (automotive)
- Enhance motion estimation and disparity components (EPE improvements and lower “bad pixel” rates) for tracking, occupancy flow, and lane/obstacle segmentation.
- Tools/workflows: plug TDV features into flow/stereo heads; use as pretrain for UPerNet/segmentation decoders on Cityscapes/ADE-like datasets.
- Assumptions/dependencies: high-frame-rate video with synchronized sensors; strict validation/verification; compliance with safety standards.
- Low-label video model bootstrapping (software/ML ops)
- Rapidly pretrain video encoders on in-house unlabeled footage to cut annotation costs for downstream detectors/segmenters.
- Tools/workflows: TDV pretraining on proprietary video, then lightweight fine-tuning; integrate with OpenMMLab (MMSeg) heads; simple KNN/linear probes for QC.
- Assumptions/dependencies: access to sufficiently long, temporally consistent video; storage and governance policies for video data.
- Sports tracking and broadcast analytics (media/entertainment)
- Improve player/ball tracking, motion heatmaps, and event segmentation using TDV’s motion-preserving features.
- Tools/workflows: fine-tune TDV encoders for multi-object tracking; faster shot/change detection and smooth camera motion compensation.
- Assumptions/dependencies: broadcast video variability (zoom/camera switches); potential domain fine-tuning.
- Industrial inspection and anomaly detection (manufacturing)
- Use motion-centric features to detect deviations on production lines (e.g., misalignment, stoppages) with minimal labels.
- Tools/workflows: train TDV on normal operations video; unsupervised change-point detection; integrate with PLC/SCADA dashboards.
- Assumptions/dependencies: stable camera placement; consistent cadence; handling of lighting changes.
- Smart surveillance and retail analytics (security/retail)
- Robust motion-based anomaly and flow analysis (crowd movement, queue dynamics) without heavy labeling or augmentation heuristics.
- Tools/workflows: edge deployment where TDV features support low-latency flow/seg inference; on-premises analytics respecting privacy constraints.
- Assumptions/dependencies: privacy-compliant data handling; on-device compute for real-time or near-real-time inference.
- AR/VR motion-aware rendering and stabilization (consumer electronics)
- Better motion estimation for reprojection, stabilization, and dynamic background segmentation on headsets/cameras.
- Tools/workflows: TDV features feeding reprojection maps and per-pixel motion fields; improved temporal consistency in rendering pipelines.
- Assumptions/dependencies: high FPS, low-latency pipelines; calibration for rolling shutter or motion blur.
- Video editing and post-production aids (creative software)
- Improved temporal object tracking, matte propagation, and stabilization leveraging TDV motion encodings.
- Tools/workflows: NLE plugins for robust tracking and mask propagation; batch precompute TDV features for long clips.
- Assumptions/dependencies: varied footage quality; handling abrupt scene cuts and occlusions.
- Academic benchmarking and teaching (academia)
- Evaluate dorsal-stream metrics (flow/stereo/temporal correspondence) with fewer inductive biases; study causality-based learning signals.
- Tools/workflows: side-by-side comparisons to DINO/iBOT; ablation/negative results as teaching material on collapse prevention and EMA teachers.
- Assumptions/dependencies: availability of standard datasets (SSv2, Sintel, SceneFlow); reproducible training with EMA teacher and centering.
- Energy-aware video understanding pipelines (software/edge)
- Prototype pipelines where only the first frame uses a heavy encoder and subsequent frames use a lighter TDV motion encoder to update representations.
- Tools/workflows: mixed-resolution or keyframe+delta processing for on-device analytics.
- Assumptions/dependencies: engineering to maintain accuracy over long sequences; drift correction via periodic re-encoding.
- Personal fitness and form analysis (daily life/consumer apps)
- Motion-focused rep counting and form tracking from smartphone or webcam without extensive labels.
- Tools/workflows: integrate TDV-pretrained features into pose/motion heads; rapid adaptation to new routines.
- Assumptions/dependencies: consistent camera viewpoint; handling of occlusions and clothing variability.
Long-Term Applications
These opportunities require further research, scaling, engineering, or standardization but align closely with the paper’s core ideas around causality-driven, low-bias representation learning.
- Unified multimodal temporal difference learning (robotics/embodied AI)
- Extend TDV beyond vision to audio, proprioception, touch; learn a shared temporal representation for sensor fusion and world modeling.
- Potential products: embodied foundation models that predict next-state embeddings across modalities.
- Dependencies: large-scale synchronized multimodal datasets; training stability across modalities; sensor noise handling.
- Scalable, low-bias vision foundation models (software/AI platforms)
- Build large TDV-style pretraining across high-quality Internet/egocentric video to rival augmentation-heavy methods at scale.
- Potential products: general-purpose backbones optimized for motion/structure reasoning with plug-and-play downstream heads.
- Dependencies: access to massive, rights-cleared video corpora; robust hyperparameter scaling; improved teacher-student schedules; better data diversity.
- TDV-inspired learned video codecs (media infrastructure/energy)
- Replace or augment classical codecs with latent frame+motion updates; drastically reduce compute for repeated full-frame encoding.
- Potential products: “TDV Codec” for inference-side analytics or end-to-end compression; standards contributions.
- Dependencies: real-time constraints; hardware support; standardization (MPEG/AV1 ecosystems); rigorous benchmarks on compression quality and energy.
- Continuous on-device learning from egocentric streams (consumer/edge)
- Causality-based self-supervision running locally on AR glasses or mobile devices, continuously adapting to user environments.
- Potential products: privacy-preserving personal visual models that improve motion understanding and segmentation over time.
- Dependencies: robust on-device training; memory/compute constraints; drift and catastrophic forgetting mitigation; privacy-by-design frameworks.
- Medical video understanding (healthcare)
- TDV-pretrained encoders for endoscopy, laparoscopy, ultrasound video: better motion tracking and tool/tissue interaction cues with fewer labels.
- Potential products: assistive intraoperative guidance or post-hoc video review tools focusing on motion anomalies.
- Dependencies: stringent clinical validation; domain-specific fine-tuning; regulatory approvals; dataset curation and bias assessments.
- Advanced driver assistance and autonomy with causal priors (automotive)
- Use TDV as part of predictive perception to anticipate short-horizon dynamics (e.g., pedestrian intent, occlusion emergence).
- Potential products: predictive modules that improve planning robustness under partial observability.
- Dependencies: end-to-end validation in simulation and real-world; safety and interpretability requirements; robust behavior under sensor faults.
- Video data governance and compression-aware policy (policy/standards)
- Inform standards for energy-efficient AI vision pipelines; promote self-supervised, low-label training on privacy-preserving video.
- Potential outputs: benchmarking suites for energy/accuracy trade-offs; guidance for compliant large-scale video pretraining.
- Dependencies: cross-industry collaboration; privacy legislation; standardized metrics for temporal learning and sustainability.
- Event-based and neuromorphic sensing integration (hardware/sensors)
- Apply TDV principles to event cameras where temporal differences are native signals; enable low-latency motion representations.
- Potential products: ultra-low-power perception for drones/AR with event-driven TDV backbones.
- Dependencies: dataset availability; adaptation of motion encoder to event streams; specialized hardware toolchains.
- Intelligent video retrieval and summarization (enterprise/media)
- Causal, motion-centric embeddings for retrieving “how things moved” rather than only “what things are,” and for summarizing dynamic scenes.
- Potential products: motion-aware search engines; highlight reels focusing on action patterns.
- Dependencies: large-scale indexing infrastructure; hybrid semantic+motion retrieval schemas; user-facing UX for motion queries.
- Education and training simulations (education/defense/enterprise)
- TDV-based agents that understand and predict short-horizon changes to coach users in simulators (e.g., maintenance, sports drills).
- Potential products: training assistants monitoring temporal skill sequences (procedural steps) rather than only static correctness.
- Dependencies: domain-accurate simulators; longitudinal temporal datasets; alignment of motion cues with pedagogical goals.
Common Assumptions and Dependencies Across Applications
- Causality and temporal consistency: TDV assumes the immediate future is predictable from the recent past; works best with stable frame rates and limited abrupt cuts.
- Data quality and domain shift: benefits from representative, high-quality video; may require fine-tuning for new domains (e.g., medical vs. consumer).
- Training stability: relies on teacher-student EMA, centering, and MSE + self-distillation losses to avoid collapse; sensitive to hyperparameters at scale.
- Compute and hardware: pretraining cost remains non-trivial; edge applications benefit from partial re-encoding (keyframe + motion) and hardware acceleration.
- Privacy and compliance: large-scale video pretraining and deployment must address data rights, anonymization, and regulatory requirements.
Glossary
- ADE20K: A large-scale semantic segmentation dataset with diverse scenes used to evaluate segmentation models. "on ADE20K and Cityscapes."
- augmentation: Data transformations applied during training (e.g., flips, color jitter, crops) to encourage invariances in learned representations. "depend on strong inductive biases such as augmentations, masking, or cropping."
- autoencoding: A self-supervised approach that trains models to reconstruct inputs, often in pixel space. "learned representations primarily via autoencoding"
- [email protected]: A stereo depth metric measuring the percentage of pixels with disparity error greater than 0.5 pixels. "[email protected]"
- causality: The principle that causes precede effects, used here as an assumption that the immediate future is predictable from the past. "We argue for assuming causality: that causes precede their effects, and the immediate future is therefore predictable from the past."
- centering: Normalizing a distribution by subtracting a running mean to prevent collapse or dominance of a single mode. "The teacher distribution is additionally centered with a running mean to prevent dimensional collapse in the absence of temperature asymmetry."
- channel attention: A mechanism that re-weights feature channels to emphasize informative features, often used in video or recognition models. "rely on a global channel attention mechanism to recalibrate features across long-range differences."
- Cityscapes: A benchmark dataset for urban scene understanding and semantic segmentation. "on ADE20K and Cityscapes."
- CLS token ([CLS] token): A special token in transformer architectures representing a global summary of the input sequence. "plus an additional [CLS] token,"
- CNNs (Convolutional Neural Networks): Neural architectures with convolutional layers that impose spatial locality and translation equivariance biases. "convolutional neural networks (CNNs)"
- collapse (representation collapse): A failure mode where representations become constant or non-informative, often due to trivial solutions in self-supervised training. "removing assumptions such as augmentations or masking often leads to degraded representations or collapse."
- contrastive learning: A self-supervised paradigm that pulls together representations of positive pairs and pushes apart negatives. "self-supervised contrastive approaches such as SimCLR~\cite{chen2020simple} and MoCo~\cite{he2020momentum}"
- cross-attention: An attention mechanism that conditions one sequence’s processing on another sequence’s representations. "conditioned on the current frame via cross-attention."
- cross-entropy loss: A classification-style loss on probability distributions; used here between student and teacher projections to avoid collapse. "a DINO-style~\cite{caron2021emerging} cross-entropy on the projection heads prevents collapse."
- DINO: A self-distillation method for vision that uses a teacher-student setup to learn powerful image representations. "DINO~\cite{caron2021emerging}"
- dorsal stream: The “where/how” visual pathway in the brain associated with motion and spatial processing. "which is performed in the human brain by the dorsal stream"
- endpoint error (EPE): An optical flow metric measuring the average Euclidean distance between predicted and ground-truth flow vectors. "on EPE (endpoint error, the average pixel-level distance between predicted and ground truth flow vectors)."
- equivariance (translation equivariance): A property where transformations of the input lead to corresponding transformations in the output, such as shifts handled by CNNs. "translation equivariance biases of CNNs"
- exponential moving average (EMA): A running average that gives more weight to recent updates; used to update teacher parameters smoothly. "whose parameters are a slowly-evolving exponential moving average (EMA) of the student."
- frame encoder: A network that maps an image frame into a latent representation space. "the frame encoder embeds the current frame"
- global attention: An attention mechanism that can relate all token pairs, typical of Vision Transformers. "in favor of global attention."
- iBOT: A self-supervised vision method using masked prediction and self-distillation. "iBOT~\cite{zhou2021ibot}"
- ImageNet-1k: A large-scale image classification dataset commonly used for pretraining and benchmarking. "KNN accuracy on ImageNet-1k"
- inductive bias: Built-in assumptions or constraints in learning algorithms that guide generalization; strong biases can limit scalability. "approaches with weaker inductive biases generally outperform those with stronger assumptions"
- invariance objective: A learning goal that makes representations invariant to certain transformations (e.g., crops), potentially discarding some information. "adding an invariance objective over cropped patches"
- JEA (Joint-Embedding Architecture): A family of self-supervised models that learn by aligning embeddings from different views, sometimes without conditioning on latent variables. "Joint-Embedding Architecture (JEA) variants"
- JEPA (Joint Embedding Predictive Architectures): Models that predict in a latent embedding space rather than in pixel space to learn more abstract features. "Joint Embedding Predictive Architectures (JEPAs)"
- k-NN retrieval: A non-parametric evaluation method that retrieves nearest neighbors in representation space to assess embedding quality. "such as linear probing, k-NN retrieval, and action recognition"
- latent space: A learned feature space where inputs are represented as vectors capturing salient information. "where prediction is done in a latent space as opposed to in the raw pixel space."
- local/global crops: Augmentations that crop images at different scales to create varied views for training invariances. "such as local/global crops"
- low-rank (intrinsically lower rank): Describes data or differences that lie in a lower-dimensional subspace relative to the full input, easing compression/modeling. "the raw RGB pixel difference between frames is intrinsically lower rank than the frames themselves"
- masking ratio: The proportion of input masked during training in masked modeling setups, controlling task difficulty and bias strength. "masking with values of , , and as a continuous proxy"
- mean squared error (MSE): A regression loss that penalizes squared differences; here used to align predicted and target latent representations. "a mean-squared error on the representations"
- Midway Networks: A method that learns from temporal differences in video combined with augmentation-based invariance. "Midway Networks~\cite{hoang2025midway} learn representations directly from temporal differences in video"
- motion encoder: A network that encodes the pixel-level change between frames into a latent motion shift. "the motion encoder turns the raw pixel difference between frames into a latent motion shift"
- motion vector: A latent vector capturing inter-frame changes to transform one frame’s representation into the next. "adding a learned motion vector to the current frame's representation."
- mAcc (mean per-class accuracy): A segmentation metric averaging per-class accuracy across classes. "mAcc (mean per-class accuracy)"
- mIoU (mean intersection over union): A common semantic segmentation metric averaging IoU across classes. "mIoU (mean intersection over union)"
- MPI-Sintel: A benchmark dataset for evaluating optical flow methods. "Optical Flow on MPI-Sintel."
- optical flow: The per-pixel motion field between consecutive frames, used to evaluate temporal and spatial correspondence. "On optical flow, {TDV} consistently outperforms both DINO and iBOT"
- patch tokens: Per-patch embeddings in Vision Transformers representing local regions of the input. "we apply this loss over both the [CLS] token and the patch tokens"
- positional encodings: Encodings added to transformer inputs to inject position information into the model. "standard absolute positional encodings consistently outperform RoPE"
- projection head: A small network mapping embeddings to a space suitable for self-supervised objectives (e.g., prototypes). "on the projection heads"
- prototypes (prototype distributions/dimensions): Learnable vectors or categories in projection space used for clustering-like self-supervision. "over the prototype dimensions of the projection head."
- RoPE (Rotary Position Embedding): A positional encoding technique that rotates query/key vectors in attention to encode positions. "consistently outperform RoPE~\cite{su2024roformer}"
- running mean: A continuously updated average used here to center teacher distributions during training. "centered with a running mean"
- SceneFlow: A synthetic dataset suite for training and evaluating stereo depth estimation. "SceneFlow (final)"
- self-distillation: Training a student network to match a slowly updated teacher model’s outputs without labels. "Self-distillation approaches~\cite{grill2020bootstrap} relax these assumptions via a slow-moving teacher"
- self-supervised learning: Learning representations without human-provided labels by exploiting structure within the data. "Self-Supervised Learning without human labels."
- semantic segmentation: Pixel-wise classification of an image into semantic categories. "On semantic segmentation, {TDV} achieves results comparable to DINO and iBOT"
- SomethingSomethingV2 (SSV2): A video dataset emphasizing object manipulations and motion, used for pretraining. "SomethingSomethingV2 (SSV2)"
- stop-gradient: An operation that blocks gradient flow through a tensor to prevent trivial solutions in teacher-student setups. "Stop-gradients block the teacher from receiving gradients."
- stereo depth: Estimation of per-pixel disparity/depth from stereo image pairs. "and stereo depth"
- TDV (Temporal Difference in Vision): The proposed self-supervised method that predicts the next frame’s representation via an additive motion shift. "Temporal Difference in Vision ({TDV})"
- temporal consistency: The property that adjacent frames in video change gradually, enabling temporal learning signals. "video has high temporal consistency"
- Temporal Difference (Reinforcement Learning): A class of RL methods that learn by bootstrapping predictions over time; used here by analogy. "By analogy to Temporal Difference in Reinforcement Learning~\cite{sutton1988learning}"
- temperature (softmax temperature): A scaling factor in softmax that controls distribution sharpness in self-supervised projection spaces. "normalized with temperatures and respectively (in practice, we set )."
- temperature asymmetry: Using different temperatures for teacher and student distributions; its absence can risk collapse without centering. "in the absence of temperature asymmetry"
- teacher-student framework: A self-supervised setup where a student matches a slowly updated teacher to avoid collapse. "we adopt a teacher-student framework following DINO"
- translation equivariance: The property that a shift in input leads to a corresponding shift in the output; a bias of CNNs. "translation equivariance biases of CNNs"
- UperNet: A semantic segmentation architecture used as the downstream head in experiments. "Semantic Segmentation Performance With UperNet."
- ViT (Vision Transformer): A transformer-based vision model that processes images as sequences of patches with global attention. "Vision Transformers (ViTs)"
- video codecs (motion vectors in codecs): Compression systems that exploit temporal redundancy by storing keyframes and inter-frame motion vectors. "the motion vectors used in classical video codecs"
- world modeling: Learning to predict or model the dynamics of the environment; here contrasted with transferable representation learning. "target world modeling rather than transferable representations."
Collections
Sign up for free to add this paper to one or more collections.