Closing the Reflection Gap: A Free Calibration Bonus for Agentic RL
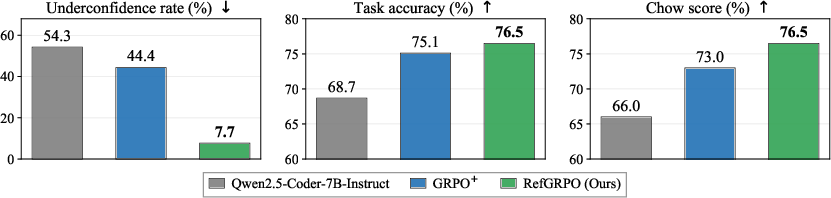
Abstract: LLMs are increasingly deployed as agents that interact with external environments and observe feedback such as execution results, error messages, and tool outputs. A well-functioning agent should be able to leverage this feedback to accurately assess its own performance. Yet we find a persistent reflection gap: LLM agents tend to mis-assess their own outputs after observing concrete environment feedback -- even for questions they correctly answered -- and standard RL barely helps due to a credit-assignment mismatch. To close this gap, we propose RefGRPO, a simple yet effective fix that augments standard RL algorithms with two key ingredients: a free calibration bonus computed by contrasting the agent's own reflection with the actual outcome (requiring no additional reward model, LLM judge, or external annotation), and a dynamic schedule on its coefficient. Compared to standard RL baselines, our method simultaneously improves reflection calibration (e.g., reduces underconfidence rate $44.4\% \to 7.7\%$) and task accuracy (e.g., $75.1\% \to 76.5\%$) on text-to-SQL across five benchmarks. The resulting calibrated reflection turns the agent into its own verifier grounded in environment feedback, which further enables (i) better self-improvement that uses reflections as pseudo-rewards without outcome supervision, and (ii) more effective test-time selective prediction by committing only to rollouts flagged as correct.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about
This paper studies how AI agents (like LLMs, or LLMs) can better judge their own work after they try something and see what happened. Think of a student who solves a problem, checks the result, and then decides, “Was I right or wrong?” The authors find that today’s LLM agents often misjudge themselves even after seeing clear feedback from the environment (like error messages or results). They call this the reflection gap. They then introduce a simple reinforcement learning (RL) add‑on, called RefGRPO, that helps agents become more honest and accurate about whether they got things right—without needing extra human labels or special judge models.
The main questions the paper asks
- Do LLM agents accurately assess their own answers after seeing concrete feedback (for example, running a SQL query and seeing results or errors)?
- Why doesn’t standard RL fix poor self-assessment?
- Can a simple, “free” addition to RL training make agents both more accurate at tasks and better at knowing when they’re right or wrong?
- If agents become well-calibrated (good at knowing when they’re correct), can that help them improve themselves and make better choices at test time?
How the researchers approached it
Here’s the basic setup, in everyday terms:
- Action: The agent tries something (for example, writes a SQL query to answer a question about a database).
- Observation: The environment reacts (the query runs and returns results or an error message).
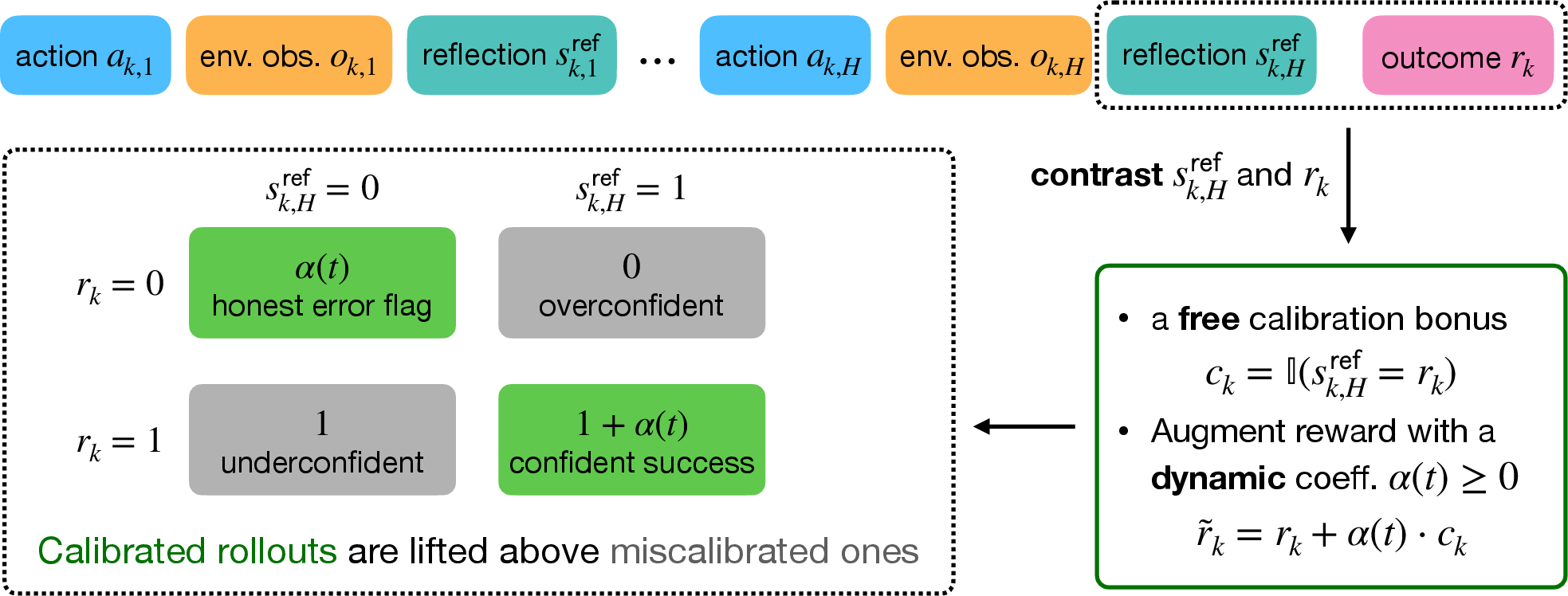
- Reflection: The agent looks at the action and the feedback and gives a simple score: 1 if it thinks the answer is correct, 0 if it thinks it’s wrong.
Later, the system checks the true outcome (correct or incorrect) and gives a reward for RL training. In standard RL, the model learns mostly from “Was the final answer right?” That sounds fine, but it causes a problem:
- Credit assignment mismatch: If the agent honestly says “I think I’m wrong” and it really is wrong, standard RL still gives a negative signal overall (because the outcome is wrong). That trains the agent to stop admitting mistakes.
- If the agent wrongly doubts itself (says “I’m wrong” when it was actually right), the positive outcome reward can encourage that underconfidence.
To fix this, the authors add two simple ideas on top of a common RL method (GRPO):
- A “free” calibration bonus
- The agent already has two pieces of info after each attempt: its own reflection (0/1) and the true outcome (0/1).
- Give a small extra bonus if the reflection matches the outcome: .
- This bonus is “free” because it needs no extra data, judge, or labels—just what’s already there.
- A dynamic schedule for the bonus
- Start training with a bigger weight on the bonus so the model learns to reflect honestly early on.
- Slowly shrink that weight later so the model focuses more on getting the task itself correct, while keeping the honest reflection it learned.
The authors test this on text-to-SQL tasks (turning natural-language questions into SQL queries) across five benchmarks, using open models like Qwen and Llama. They measure:
- Task accuracy: How often the final answer is correct.
- Reflection accuracy: How often the agent’s self-judgment matches the true outcome.
- Overconfidence: Saying “right” when wrong.
- Underconfidence: Saying “wrong” when right.
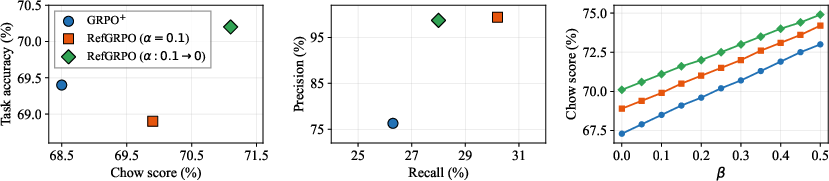
- Chow score: A combined score that rewards correct answers fully and gives partial credit when the agent correctly “abstains” (flags its own answer as wrong). This captures both getting things right and knowing when you haven’t.
What they found and why it matters
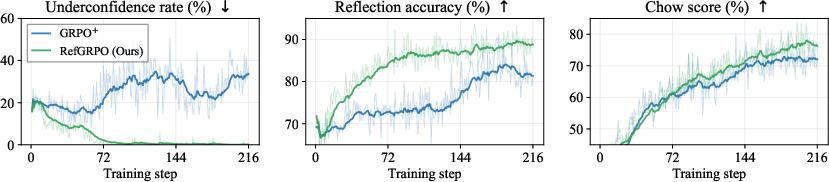
- Standard RL leaves a reflection gap. Even after training, agents still badly misjudge themselves. In particular, they’re often underconfident: they say “wrong” even when the answer is correct.
- RefGRPO closes much of that gap. On a strong base model (Qwen2.5-Coder-7B) in multi-turn settings:
- Underconfidence dropped from 44.4% to 7.7%.
- Task accuracy increased from 75.1% to 76.5%.
- The unified Chow score improved from 73.0% to 76.5%.
- It works without extra supervision. The calibration bonus uses only the agent’s own reflection and the known outcome—no additional models or labels.
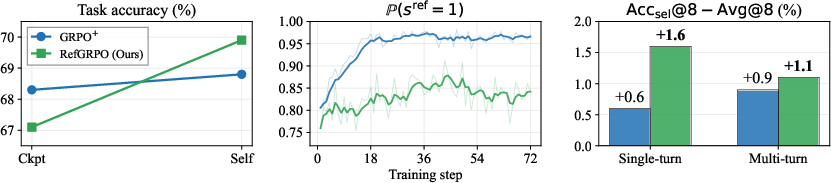
- Better self-improvement. Once reflections are well-calibrated, they can be used as “pseudo-rewards” to keep training the model without needing the true answer every time. In tests, starting from a RefGRPO checkpoint led to bigger accuracy gains than starting from a standard RL checkpoint.
- Better selective prediction. When generating multiple answers at test time, the agent can “commit” only to the rollouts it flags as correct. With RefGRPO, this selective strategy beat always-commit baselines, meaning the agent picked better answers more reliably.
- Compared to other specialized SQL models, the RefGRPO-trained model had more informative reflections (its self-judgments actually helped distinguish right from wrong).
What this could change
- More trustworthy agents: If an AI can say “I’m confident this is right” and usually be correct—and also admit “I think this is wrong” when it is—then people can rely on it more, knowing when to double-check.
- Lower supervision costs: Because the calibration bonus needs no extra judge or labels, it’s easy and cheap to add to training.
- Stronger self-bootstrapping: Well-calibrated agents can use their own judgments to improve further, even when ground-truth labels aren’t available.
- Practical decision-making: In the real world, it’s valuable to act only when confident. These methods help AIs decide when to proceed and when to ask for help.
Limitations and next steps:
- The authors tested up to 7B-parameter models; trying larger models is a logical next step.
- They used a simple yes/no reflection. Extending to a confidence score between 0 and 1 could make the agent’s self-judgments even more useful.
Knowledge Gaps
Below is a consolidated list of concrete knowledge gaps, limitations, and open questions left unresolved by the paper. These items are intended to guide actionable future research.
- Generalization beyond text-to-SQL: Validate RefGRPO on other agentic settings with environment feedback (e.g., program synthesis with execution, tool-use/web agents, robotics/control) to test domain-transfer and robustness.
- Scalability to larger models: Assess behavior at >7B scales (e.g., 13B–70B, frontier models) to check whether calibration gains persist or saturate with scale.
- Noisy/partial/delayed feedback: Evaluate robustness when environment outcomes are noisy, delayed, stochastic, or only partially observable; measure degradation and design noise-aware bonuses.
- Non-binary outcomes: Extend the calibration bonus to multi-class or continuous outcomes (e.g., graded scores, reward magnitudes) and compare proper scoring rules vs. indicator bonuses.
- Probabilistic reflection instead of binary: Train models to output calibrated probabilities in and evaluate with Brier score, ECE, reliability diagrams, AUROC for error detection; compare against the current binary reflection.
- Thresholding strategies: If probabilistic reflection is adopted, study threshold selection criteria (fixed vs. adaptive vs. risk-controlled) and their impact on accuracy/coverage trade-offs.
- Asymmetric miscalibration costs: Explore asymmetric bonuses that differentially penalize overconfidence vs. underconfidence, aligning with application-specific risk profiles.
- Alternative supervision for reflection: Compare RefGRPO to a simple supervised objective that directly trains a reflection head to predict from (cross-entropy/Brier), alone and combined with RL on task tokens.
- Separate verifier baselines: Benchmark against external verifier models trained on to predict correctness and assess whether RefGRPO matches or complements verifier-based pipelines.
- Token-level credit routing: Investigate whether computing bonuses that backpropagate only through reflection tokens (or conversely only through task tokens) yields better disentanglement of acting vs. judging.
- Gradient masking choices: Ablate the decision to mask reflection tokens in self-improvement only; test masking (or not) during the main RL phase and measure effects on calibration and task accuracy.
- Schedule design and adaptivity: Systematically study sensitivity to values and (stage lengths), and explore adaptive/auto-tuned schedules (e.g., based on online calibration metrics or meta-gradients).
- Group size sensitivity: Analyze the effect of number of rollouts per prompt () on calibration and stability; characterize performance for (no group normalization) where GRPO’s relative advantage collapses.
- Interaction with KL regularization: Reintroduce and ablate KL-control strength to quantify stability–performance trade-offs and avoid potential distributional drift due to KL removal.
- Theoretical guarantees: Provide formal analysis showing how the calibration bonus interacts with group-normalized advantages to improve reflection calibration without sacrificing asymptotic task optimality.
- Failure mode analysis: Diagnose when underconfidence occurs (e.g., specific query/result patterns, error-message types, zero-row returns, complex schemas) and which observation cues the model fails to interpret.
- Degenerate strategies and reward hacking: Test for strategies like always committing or always abstaining, or learning reflections that track base rates (e.g., always predict success) rather than genuine interpretation of feedback.
- Coverage-constrained selective prediction: Evaluate calibration under explicit coverage constraints and risk-control criteria (e.g., conformal prediction, risk-controlling prediction sets) rather than unconstrained lift only.
- Long-horizon credit assignment: Move beyond using only the final reflection to also leverage intermediate reflections for per-turn credit and early stopping; analyze how intermediate reflection quality evolves across turns.
- Multi-environment non-stationarity: Stress-test under distribution shift (unseen databases, schema perturbations, adversarial feedback, changing execution engines) to evaluate robustness and calibration drift.
- Computational overhead and practicality: Quantify the token/time/compute cost added by reflection prompts and multi-turn rollouts; report throughput/latency impacts and cost–benefit trade-offs.
- Data efficiency: Measure gains as a function of training set size and outcome-availability; test semi-supervised settings where outcomes are missing for a fraction of episodes.
- Interaction with exploration: Study how the calibration bonus interacts with sampling temperature, entropy, and asymmetric clipping; determine whether it reduces or improves exploration in multi-step environments.
- Integration with preference-based RLHF: Examine applicability when verifiable execution rewards are absent and feedback comes from humans or learned reward models; define reflection–outcome contrast under preference uncertainty.
- OOD calibration vs. accuracy trade-off: Explicitly evaluate whether improved calibration persists under OOD tasks while maintaining (or gracefully degrading) task accuracy.
- Schema/task complexity stratification: Report calibration metrics by database size, join depth, nesting, and linguistic complexity to identify where RefGRPO helps most/least.
- Selective-prediction policies: Beyond binary commit, explore top-k filtering, majority/plurality voting conditioned on reflection, and cost-aware selection policies.
- Self-improvement stability: Assess longer self-improvement runs for reward collapse or drift (e.g., commit-rate collapse to 1 or 0) and devise safeguards (e.g., entropy floors, calibration regularizers).
- Comparison to auxiliary multi-tasking: Test auxiliary losses (e.g., predicting execution error type, result cardinality) to enrich the world model and see if they synergize with the calibration bonus.
- Interpretability of reflection: Probe attention/attribution to verify that reflections genuinely use environment feedback (o) rather than spurious cues; ablate feedback tokens to quantify reliance.
- Reproducibility and open resources: Release code, prompts, and training logs for independent verification of calibration metrics (including parsing of “valid reflections”), especially for multi-turn setups.
Practical Applications
Overview
The paper introduces RefGRPO, an augmentation to outcome-only RL for LLM agents that interact with environments (e.g., tools, databases, execution sandboxes). By adding a free calibration bonus (based on agreement between the agent’s post-feedback reflection and the actual outcome) and a dynamic schedule on that bonus, RefGRPO closes a “reflection gap,” improving both calibrated self-assessment and task accuracy. The result is an agent that can act as its own verifier grounded in environment feedback, enabling verifier-free self-improvement and more effective selective prediction.
Below are actionable, real-world applications grouped by immediacy. Each item notes sectors, example tools/products/workflows, and key assumptions/dependencies.
Immediate Applications
These can be deployed now in settings with verifiable outcomes (e.g., pass/fail signals from tools, execution environments, or APIs).
- Software engineering and data engineering (software, data/analytics)
- Use case: Text-to-SQL assistants, BI/analytics query bots, and data ops agents that generate queries, execute them, inspect results/errors, and decide whether to commit or retry.
- Tools/workflows: Integrate RefGRPO into RL pipelines for SQL/code agents; enforce “commit gating” based on calibrated reflection; auto-retry or escalate on self-flagged errors; track Chow score and miscalibration rates.
- Assumptions/dependencies: Access to execution engines with binary or near-binary correctness signals; reliable parsing of reflection tokens; modest compute for RL fine-tuning and multi-rollout sampling.
- Coding agents with test-driven verification (software/DevOps)
- Use case: Code generation, bug-fixing, CLI task execution, and infrastructure updates where tests/logs provide immediate pass/fail feedback.
- Tools/products: CI/CD bots that only merge changes when unit/integration tests pass and reflection agrees; “self-verifying” code assistants that rerun or abstain when uncertain.
- Assumptions/dependencies: High-quality test suites or health checks; environment feedback is trustworthy; reflection prompt format is robust.
- Robotic process automation (RPA) and web/task automation (software/enterprise)
- Use case: Form filling, record updates, and workflow automation with tool response codes or confirmation pages as feedback.
- Tools/workflows: Selective prediction with k-rollout sampling; commit only to runs flagged correct; schedule calibration-heavy early training then decayed for performance.
- Assumptions/dependencies: Clear success indicators (e.g., confirmation IDs); ability to sample multiple runs where needed; cost-vs-latency trade-offs.
- LLMOps: Training and monitoring for calibrated agents (software/ML platforms)
- Use case: Upgrade existing outcome-only GRPO/RLAIF pipelines to include calibration bonus and Chow-score monitoring.
- Tools/products: “Calibrated RL” trainers (plugins for TRLX/OpenRLHF); dashboards for under/overconfidence, Chow score; alerting when calibration drifts.
- Assumptions/dependencies: Group-normalized RL training with outcome signals during fine-tuning; minimal code changes to add reward augmentation.
- Verifier-free self-improvement on unlabeled but executable tasks (software/education)
- Use case: Continue RL using self-reflection as pseudo-reward when ground-truth outcomes are costly or unavailable, as long as environment feedback exists (e.g., code with tests, SQL with DB execution).
- Tools/workflows: Periodic calibration-focused training followed by self-improvement phases that mask reflection tokens and update task tokens only.
- Assumptions/dependencies: Environments must provide informative feedback; maintain healthy commit rates (avoid trivial always-commit collapse) via initial calibration phases.
- Safer autonomy via abstention and escalation (cross-sector)
- Use case: Gate irreversible actions; abstain and notify humans when reflection flags likely error.
- Tools/workflows: Policies that route self-flagged cases to human-in-the-loop review; SLAs keyed on calibrated abstention rates.
- Assumptions/dependencies: Human oversight capacity; clear escalation paths; tolerance for abstention in UX.
- Customer support and CRM automation (enterprise software)
- Use case: Agents that create/update tickets, accounts, or orders through APIs; verify success from API responses and commit only when reflected as correct.
- Tools/workflows: Selective commit; automated retries with different tool parameters; calibration dashboards for operations teams.
- Assumptions/dependencies: Stable API semantics with clear success/failure; logging and audit trails.
- Finance back-office/data reporting (finance/enterprise)
- Use case: Query generation for reconciliations and reporting; commit gating ensures only validated results are released.
- Tools/workflows: Self-verifying reporting pipelines; scheduled jobs with selective prediction; automatic exception queues for self-flagged mismatches.
- Assumptions/dependencies: Executable queries with deterministic correctness; compliance-approved audit logging for abstentions and escalations.
- Education and coding/math tutors (education/edtech)
- Use case: Tutors that run code/math solutions against auto-graders; present solutions only when verified; otherwise encourage iteration or reflection.
- Tools/workflows: Calibrated self-assessment to guide hints; per-student Chow-score tracking; selective reveal of “trusted” solutions.
- Assumptions/dependencies: Accurate auto-graders; acceptable latency for multi-rollout sampling in learning platforms.
- Security and compliance automation (software/security)
- Use case: Post-execution sanity checks (e.g., config diffs, integrity verifications) coupled with reflection; rollback or seek approval when flagged.
- Tools/workflows: Policy enforcement that binds action to reflection-outcome agreement; audit logs on calibration metrics.
- Assumptions/dependencies: Reliable post-action verification checks; governance frameworks that accept abstention paths.
Long-Term Applications
These require further research, scaling, domain adaptation, or stronger/safer outcome signals.
- Clinical decision support and healthcare operations (healthcare)
- Use case: Agents suggesting orders or care plans that verify against tool outputs (e.g., CDS systems) and abstain on uncertainty; triage scheduling and administrative workflows with API confirmations.
- Potential products: Calibrated agent plugins for EHRs; selective-prediction-driven CDS gateways.
- Dependencies/assumptions: High-fidelity, clinically validated outcome proxies; stringent safety, robustness, and regulatory approval; rich feedback beyond binary signals.
- Physical robotics and process control (robotics/manufacturing)
- Use case: Agents that assess task success post-sensor feedback (assembly completion, pick-and-place success) and decide whether to proceed or retry.
- Potential tools: Calibrated reflection heads for multimodal policies; selective execution orchestrators in factory cells.
- Dependencies/assumptions: Reliable success/failure signals or learned validators; real-time constraints; robustness to non-binary or delayed outcomes.
- Autonomous driving and field operations (mobility/energy)
- Use case: Post-event verification (e.g., lane change success, safe stop) with calibrated self-assessment to gate downstream maneuvers or call for human takeover.
- Potential tools: Onboard calibration modules; fleet-level Chow-score monitoring.
- Dependencies/assumptions: Extremely high safety standards; long-horizon, delayed, and noisy rewards; certification hurdles.
- Trading and risk-aware financial agents (finance)
- Use case: Verify order execution and strategy signals with calibrated reflection; abstain on trades when uncertainty is high; selective deployment of strategies.
- Potential tools: Risk-aware selective prediction frameworks; reflection-logged compliance audits.
- Dependencies/assumptions: Delayed/partial rewards and confounders; adversarial markets; regulation.
- Scientific discovery and lab automation (science/biotech)
- Use case: Agents that run experiments, analyze instrument feedback, and calibrate success judgments to guide next steps without continuous supervision.
- Potential tools: Verifier-free self-improvement for protocol optimization; calibrated experiment planners.
- Dependencies/assumptions: Reliable, automated measurement pipelines; non-binary and stochastic outcomes; domain-specific safety constraints.
- Cross-domain self-training at scale (“verifierless RLHF”) (ML infrastructure)
- Use case: Broad semi-supervised RL where agent reflections provide pseudo-rewards across many tool-using domains, reducing dependency on labeled outcome data.
- Potential products: General-purpose “Calibrated Agent SDK” bundling reflection prompts, reward augmentation, and scheduling; large-scale reflection-outcome logs for continual learning.
- Dependencies/assumptions: Widespread availability of trustworthy environment feedback; safeguards against reward hacking or reflection gaming.
- Multi-agent systems with reciprocal verification (software/systems)
- Use case: Agents verifying each other’s outputs via calibrated reflections; team-based selective prediction (commit if ≥N agents agree and reflect success).
- Potential tools: Consensus protocols weighted by Chow scores; conflict-resolution orchestrators.
- Dependencies/assumptions: Communication overhead and latency; correlated failure modes; aggregation safety.
- Governance and policy frameworks for calibrated autonomy (policy/regulation)
- Use case: Standards that mandate abstention and explainable reflection-outcome logs for high-stakes deployments; procurement criteria using Chow score thresholds.
- Potential products: Compliance toolkits for reflection logging and calibration audits.
- Dependencies/assumptions: Sector-specific regulations; third-party auditing capacity; accepted benchmarks.
- Confidence-driven personal assistants (consumer)
- Use case: Assistants that perform email/calendar/file operations only when post-feedback reflection indicates success; ask for confirmation otherwise.
- Potential tools: OS-level agent orchestration with selective execution and user prompts.
- Dependencies/assumptions: Rich tool APIs with success indicators; user tolerance for abstentions; privacy controls.
Key Cross-Cutting Assumptions and Dependencies
- Verifiable environment feedback: RefGRPO relies on outcome signals during training; best-suited to domains with clear pass/fail or high-quality proxies (tests, execution, API confirmations).
- Reflection design: Current work uses binary reflections; extending to calibrated probabilistic confidence may broaden applicability but needs research.
- Compute and sampling: Effective selective prediction often benefits from multiple rollouts; latency/cost trade-offs must be managed.
- Reward integrity and safety: Guard against reward hacking (e.g., misreporting reflections); enforce parsing checks and logging; adopt human-in-the-loop for high stakes.
- Generalization: Results are shown in text-to-SQL; adaptation to domains with delayed, noisy, or non-binary rewards requires careful shaping and possibly auxiliary validators.
- Scheduling: Dynamic calibration schedules are important to avoid sacrificing task performance; hyperparameters may require domain-specific tuning.
Glossary
- Abstention: In selective prediction, the option for a model to refrain from committing to an answer, often receiving partial credit instead of risking an incorrect prediction. "β controls how much we credit honest error detection (which can be interpreted as abstention)."
- Advantage (normalized advantage): In policy-gradient RL, a centered and scaled measure of how much better a rollout’s reward is relative to its group, used to weight policy updates. "and the advantage is normalized with respect to the group mean and standard deviation over outcome rewards ."
- Agentic setting: A learning/evaluation setup where the model acts as an agent interacting with an environment over turns, receiving feedback and adjusting behavior. "We introduce the Chow score from statistical learning to the agentic setting as a unified metric for task accuracy and reflection calibration"
- Asymmetric clipping: A PPO-style technique that clips the policy ratio with asymmetric bounds to encourage exploration while preventing instability. "(ii) apply the asymmetric \clip(\rho, 1- , 1+) to encourage exploration and prevent entropy collapse"
- Calibration bonus: An extra reward given when the agent’s post-feedback reflection agrees with the true outcome, incentivizing calibrated self-assessment. "we compute the binary calibration bonus "
- Chow score: A unified selective-prediction metric that combines correctness on committed answers with credit for abstaining when uncertain. "across five metrics: task accuracy, reflection accuracy, overconfidence rate, underconfidence rate, and Chow score."
- Commit rate: The probability with which the agent commits to (i.e., affirms) its own answer, used to analyze calibration behavior. "the + checkpoint's commit rate $\bbP({=}1)$ rapidly saturates near $1.0$"
- Credit-assignment mismatch: A training pathology where the reward signal attributes credit/blame in a way that misguides learning (e.g., penalizing honest error flags). "and trace it to a credit-assignment mismatch problem (\cref{sec:methods:problem})."
- DAPO-style improvements: Practical enhancements to GRPO training including asymmetric clipping, token-mean normalization, and removing the KL term. "augments the original GRPO objective \citep{shao2024deepseekmath} with DAPO-style improvements \citep{yu2025dapo}---asymmetric clipping, token-mean normalization, and the removal of the KL divergence term."
- Dynamic schedule: A time-varying coefficient strategy (here for the calibration bonus) to emphasize calibration early and task accuracy later. "(ii) a dynamic schedule on the calibration coefficient, which enables the model to simultaneously improve reflection calibration and task performance."
- Entropy collapse: A failure mode in RL where the policy becomes overly deterministic too quickly, reducing exploration. "apply the asymmetric \clip(\rho, 1- , 1+) to encourage exploration and prevent entropy collapse"
- Environment feedback: Concrete information returned by the environment after actions (e.g., execution results, error messages, tool outputs). "LLM agents acting in an environment receive environment feedback, e.g., execution results, error messages, or tool outputs, after each action"
- Greedy decoding: A decoding strategy that selects the highest-probability token at each step without sampling. "the main results are reported with greedy decoding"
- GRPO (Group Relative Policy Optimization): An RL method that normalizes rewards within a group of rollouts per prompt and optimizes a clipped objective. "Group Relative Policy Optimization (GRPO; \citealt{shao2024deepseekmath, guo2025deepseek}) generates rollouts"
- Importance ratio: The likelihood ratio between the current and behavior policies for a token/action, used in off-policy policy-gradient corrections. "where $\rho_{k,t} = (a_{k,t}\mid h_{k,t}) / \pi_{\theta_{\old}(a_{k,t} \mid h_{k,t})$ is the importance ratio"
- Instruction-tuned (model): A model fine-tuned to follow natural-language instructions, often with supervised data. "We experiment with three instruction-tuned models across two scales: Qwen2.5-Coder-3B/7B-Instruct and Llama-3.2-3B-Instruct"
- KL divergence term: A regularizer that penalizes divergence from a reference policy to stabilize RL fine-tuning. "and (iii) drop the KL divergence term to avoid over-constraining the policy and allow learning to be driven more directly by verifiable rewards"
- Outcome-only RL: Reinforcement learning that optimizes solely for final-task outcomes, ignoring calibration/alignment between self-assessment and outcomes. "We analyze why outcome-only RL leads to uncalibrated models"
- Overconfidence: A miscalibration where the model asserts correctness more often than warranted by actual accuracy. "Beyond the well-documented overconfidence of LLMs"
- Post-feedback reflection: The agent’s self-assessment of answer correctness after observing environment feedback. "Post-feedback reflection quality is therefore a direct measure of how well the agent comprehends what it has done"
- Pseudo-rewards: Surrogate reward signals (here, the agent’s own reflections) used to continue training without ground-truth outcomes. "self-improvement that uses reflections as pseudo-rewards without outcome supervision"
- Reflection gap: The discrepancy between actual outcomes and the agent’s post-feedback self-assessments. "a persistent reflection gap: LLM agents tend to mis-assess their own outputs after observing concrete environment feedback"
- Rollout: A sampled trajectory of actions (and feedback) generated by the policy for a given prompt during RL training. "generates rollouts for each prompt "
- Selective prediction: A paradigm where the model selectively commits to predictions it deems reliable, improving accuracy on the committed set. "more effective test-time selective prediction by committing only to rollouts flagged as correct"
- Test-time scaling: Improving performance by sampling multiple rollouts at inference and selecting among them (e.g., via reflection). "In test-time scaling with rollouts per question, the agent can act as its own verifier"
- Token-mean normalization: Normalizing loss/advantages by the total number of tokens to reduce length bias in training. "asymmetric clipping, token-mean normalization, and the removal of the KL divergence term"
- Underconfidence: A miscalibration where the model flags correct answers as wrong more often than warranted. "LLM agents exhibit significant underconfidence---flagging correct answers as wrong"
- Verifier (agent as its own verifier): Using the agent’s calibrated reflection to judge its own outputs instead of relying on an external judge. "turns the agent into its own verifier grounded in environment feedback"
- Within-group normalization: Normalizing rewards/advantages within the set of rollouts sampled for the same prompt to stabilize policy updates. "within-group normalization on near-constant rewards produces near-zero advantages"
- World model: The agent’s internal representation/understanding of how its actions affect the environment. "i.e., the quality of its implicit world model"
Collections
Sign up for free to add this paper to one or more collections.