- The paper introduces a hybrid architecture that integrates dynamic knowledge graphs with memory-augmented retrieval to lower perplexity and enhance long-context modeling.
- It fuses graph-enhanced entity embeddings with semantic and contextual memory banks, achieving 2–2.5x lower memory usage and improved retrieval precision.
- Empirical results on datasets like WikiText-103 and PG-19 validate its scalable linear memory growth and superior in-context learning performance.
Knowledge Graph Enhanced Memory-Augmented Retrieval for Long Context Modeling
Motivation and Context
Long-context language modeling introduces critical requirements not only for scaling context windows but also for maintaining entity states and their relationships over thousands of tokens. Semantic similarity-based retrieval approaches systematically neglect the structural reasoning necessary to track entities and causal chains in domains such as technical support, scientific literature, or narrative fiction. Attention window extension methods (e.g., LongLLaMA, YARN, LongLoRA) suffer from “lost-in-the-middle” effects, losing relevant information regardless of its actual importance. Memory-augmented retrieval architectures (e.g., MemLong, ERMAR) mitigate quadratic memory scaling but retrieve only on semantic similarity, overlooking explicit entity state and relationship modeling.
KGERMAR System Architecture
KGERMAR introduces a hybrid retrieval and memory architecture designed to dynamically construct context-specific knowledge graphs from input text during inference, integrating explicit entity relationship information alongside surface-level semantic similarity. The framework consists of four principal modules: contextual knowledge graph construction, graph-enhanced embedding generation, a multi-component memory architecture, and a hybrid multi-modal retrieval mechanism.
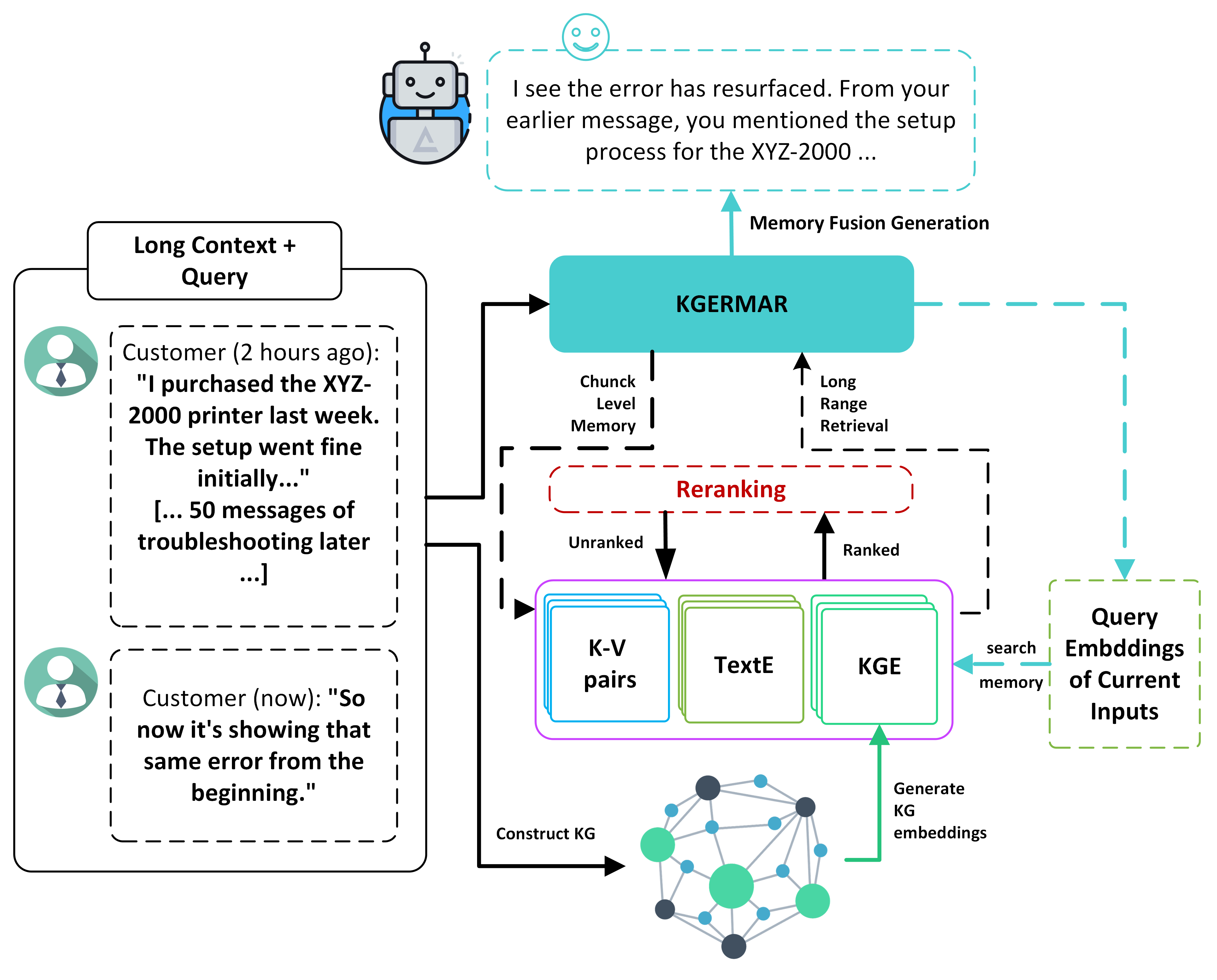
Figure 1: KGERMAR system overview, highlighting dynamic knowledge graph extraction and multi-component memory for retrieval.
The contextual knowledge graph is constructed in real time via transformer-based NER (BERT-large, CoNLL-2003) and relation extraction (BERT-base, TACRED), followed by entity consolidation and relation scoring. This graph encodes extracted entities, their types, and pairwise relationships (HasProperty, CausedBy, PartOf, etc.), filtered with stringent confidence thresholds.
Graph-enhanced entity embeddings are produced via R-GCN, propagating structural information over the graph, then fused with local textual entity embeddings from LLMs (OpenLLaMA-3B) by cross-modal attention. The final entity representation merges relational structure and local semantics, enabling retrieval beyond lexical overlap.
KGERMAR’s memory comprises three specialized banks: contextual (token-level), semantic (BGE-M3 chunk embeddings), and structural (graph-enhanced entity embeddings). Retrieval combines dot-product or cosine similarity signals across all banks via learned fusion weights, with results injected into the LLM through retrieval causal attention across late transformer layers.
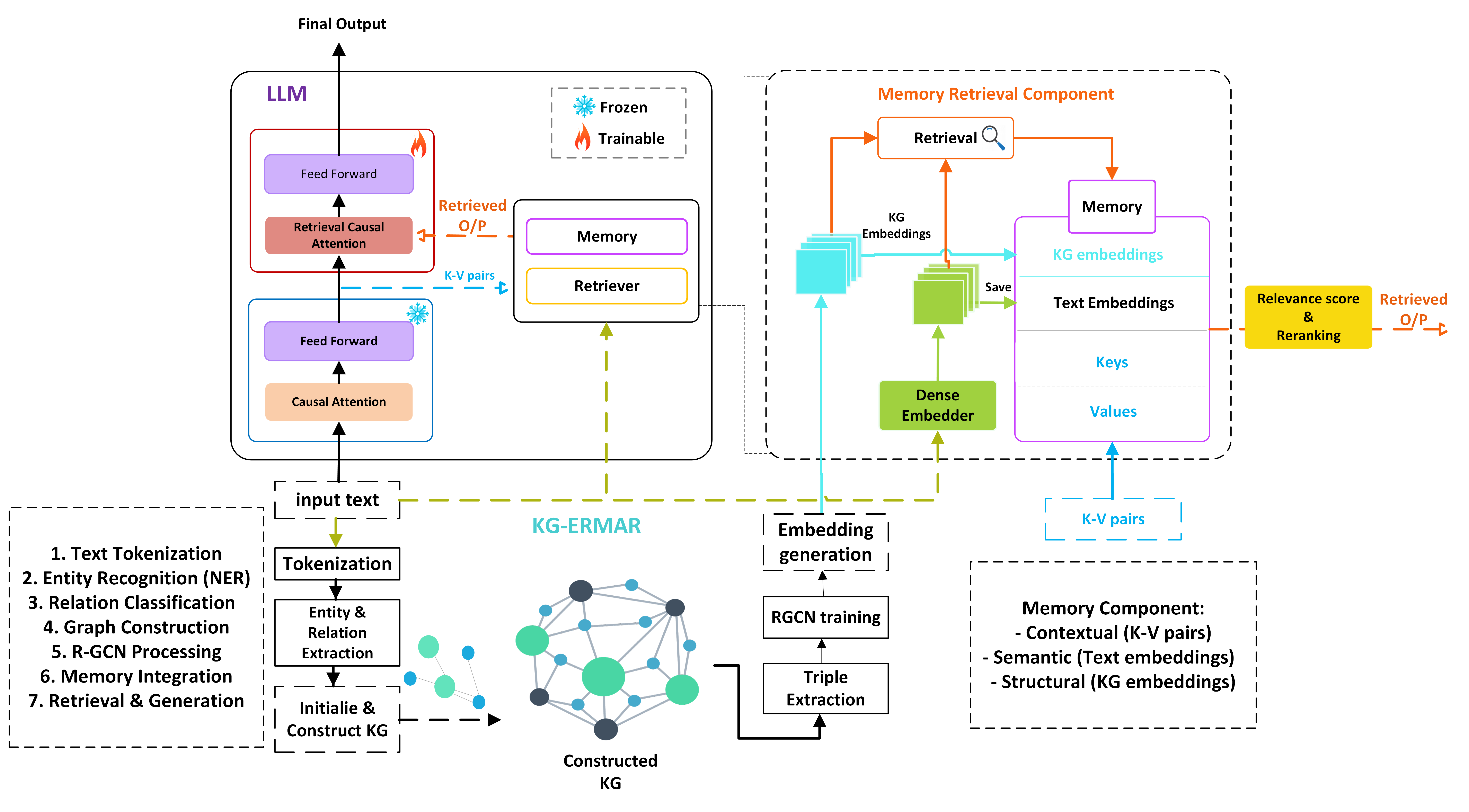
Figure 2: The four key architectural components: knowledge graph construction, graph-enhanced embeddings, multi-modal memory, and retrieval.
Empirical Evaluation and Numerical Results
KGERMAR was benchmarked on SlimPajama (long-context training), WikiText-103 (encyclopedic), PG-19 (book-length narrative), and Proof-pile (scientific/math). Fine-tuning was performed via LoRA on OpenLLaMA-3B. The evaluation metrics included perplexity (on final 2048 tokens), in-context learning accuracy (across five NLU tasks), memory efficiency (peak/reserved GPU memory, memory per token), and computational speed (per-token latency, throughput).
Perplexity: KGERMAR achieves up to 8.5% lower perplexity versus memory-augmented baselines (ERMAR, MemLong) across context lengths from 1K to 32K tokens (WikiText-103: 7.74/7.25/7.20/7.14 vs ERMAR’s 8.42/7.61/7.62/7.80).
Memory Efficiency: KGERMAR exhibits 2–2.5x lower memory per token and peak GPU usage compared to baselines, particularly salient at extended sequences (32K tokens: 14.51 GB peak vs ERMAR’s 22.87 GB).
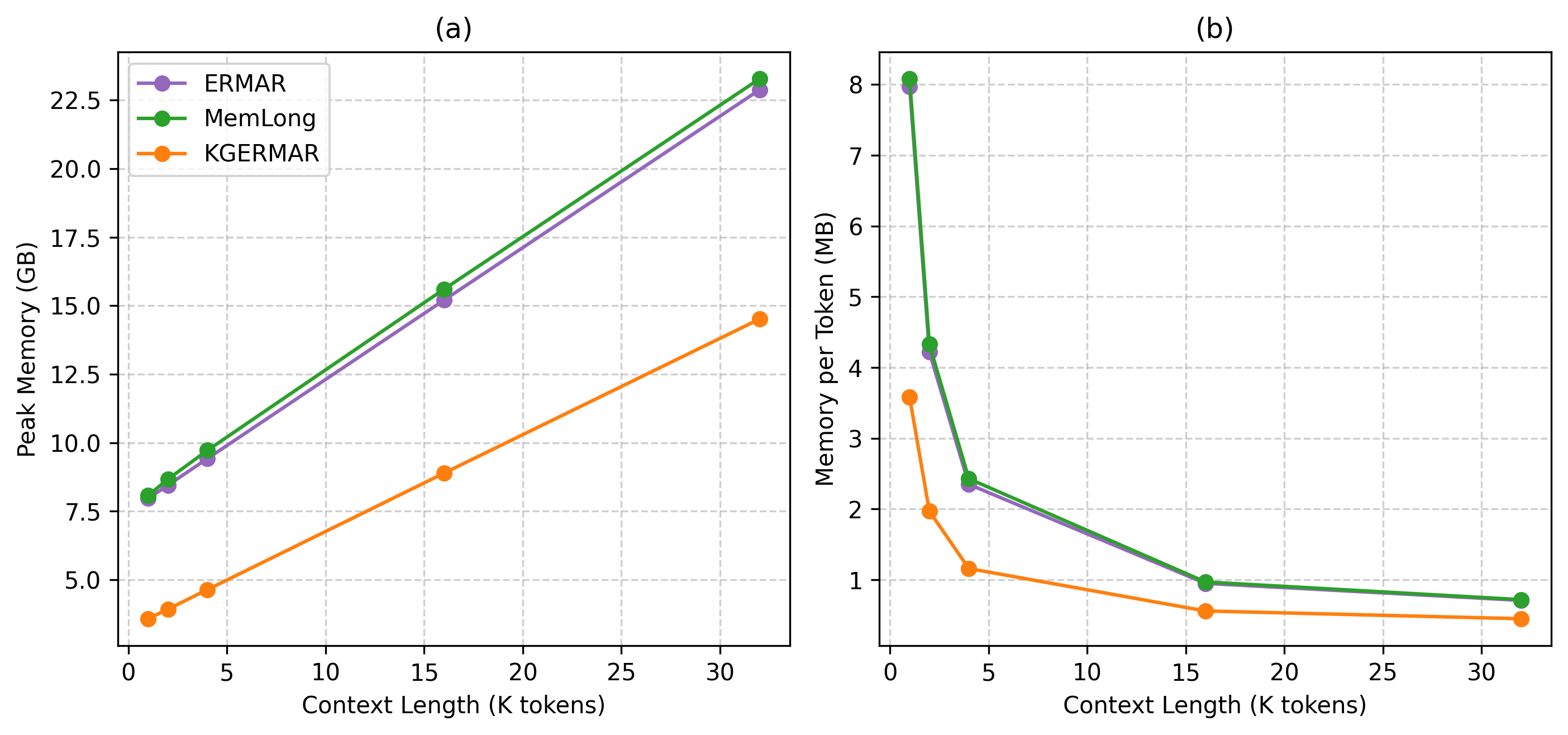
Figure 3: KGERMAR maintains 2–2.5x lower peak memory and memory-per-token than ERMAR and MemLong across all context lengths.
Scaling Behavior: KGERMAR maintains near-linear latency and memory scaling across context lengths (R²=0.98), with throughput >1K tokens/sec and consistent modeling quality. ERMAR and MemLong demonstrate higher throughput at short sequences but suffer less predictable scaling and higher variance.
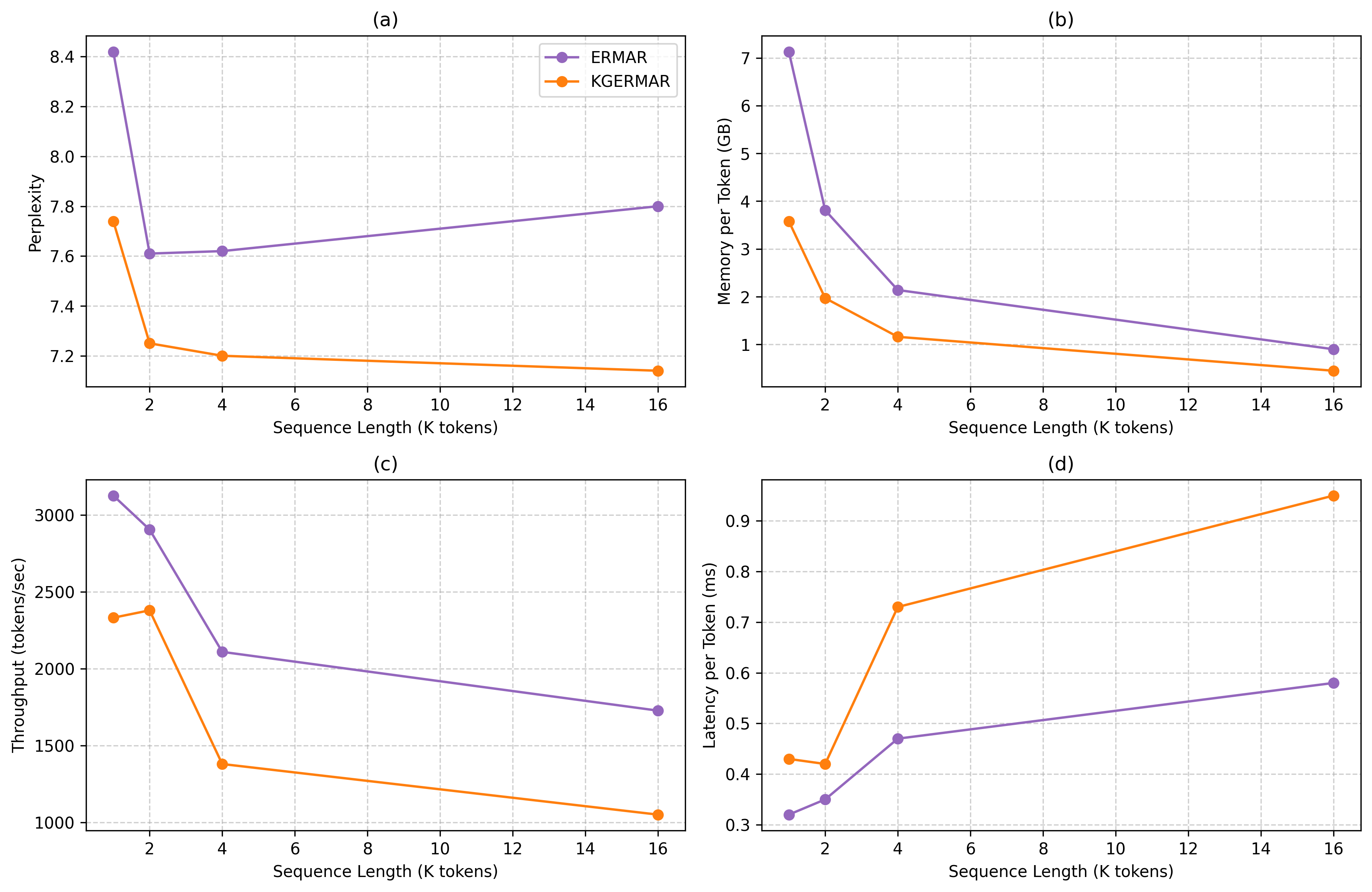
Figure 4: Perplexity, memory, throughput, and latency scaling for KGERMAR and ERMAR over increasing context lengths. KGERMAR is more memory-efficient and maintains better perplexity.
Speed Analysis: KGERMAR incurs higher per-token latency owing to real-time graph construction (0.43–0.91 ms/token), with amortized overhead at longer contexts and stable throughput. Absolute latency is traded off for improved perplexity and memory robustness.
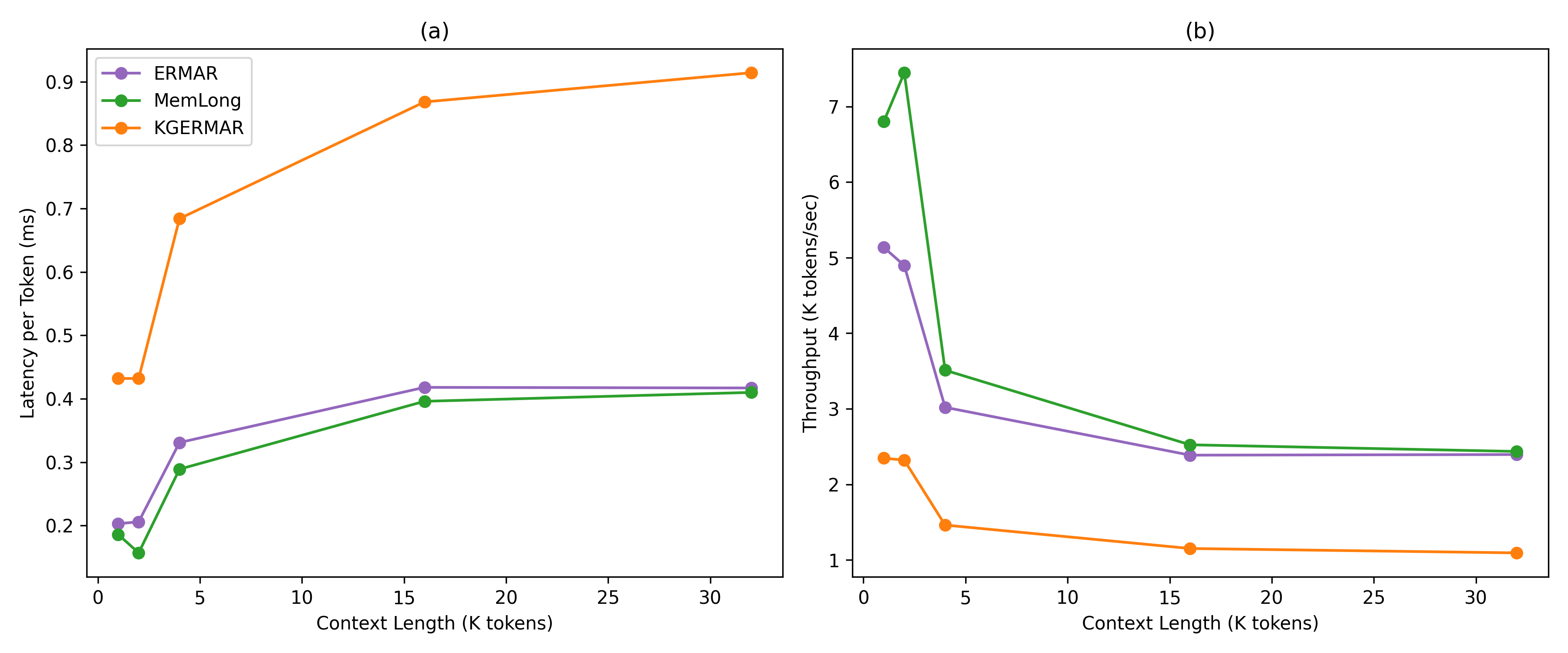
Figure 5: Detailed latency and throughput: KGERMAR’s consistent processing times are more predictable than baselines despite higher absolute latency.
Extended Scaling: KGERMAR achieves linear memory growth, stable throughput, and consistent perplexity across PG-19 and WikiText-103, validating practical predictability for deployment.
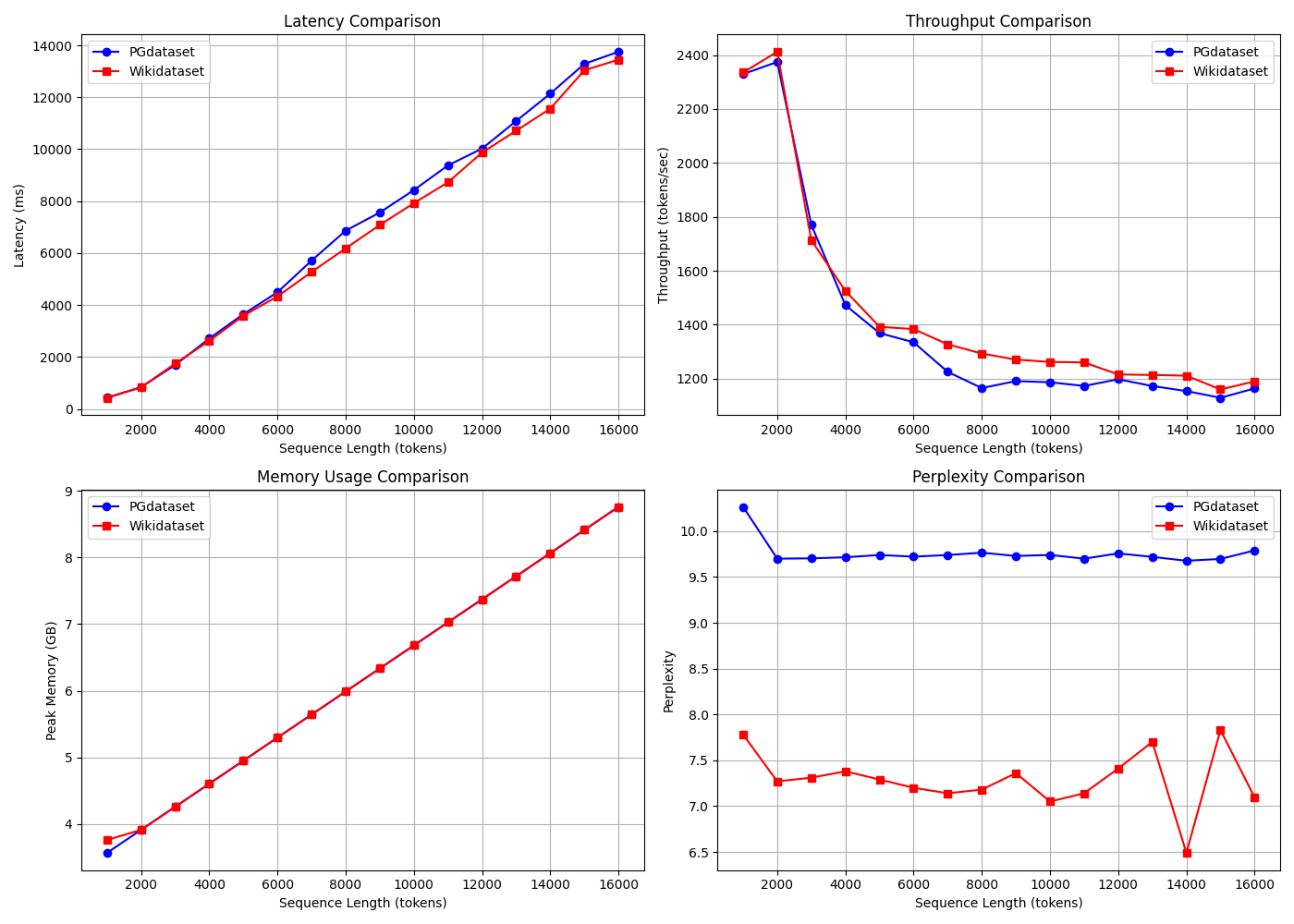
Figure 6: KGERMAR scaling analysis across PG-19 and WikiText-103 highlights linear latency/memory trends and stable perplexity.
In-Context Learning (ICL): KGERMAR outperforms both ERMAR and MemLong across five NLU tasks (SST-2, MR, Subj, SST-5, MPQA). Gains are most pronounced in opinion/subjectivity tasks, reflecting superiority in entity-driven relationship tracking.
Ablation Example: Compared to MemLong, KGERMAR generates structurally complete responses by leveraging explicit entity relationships in the retrieved context.
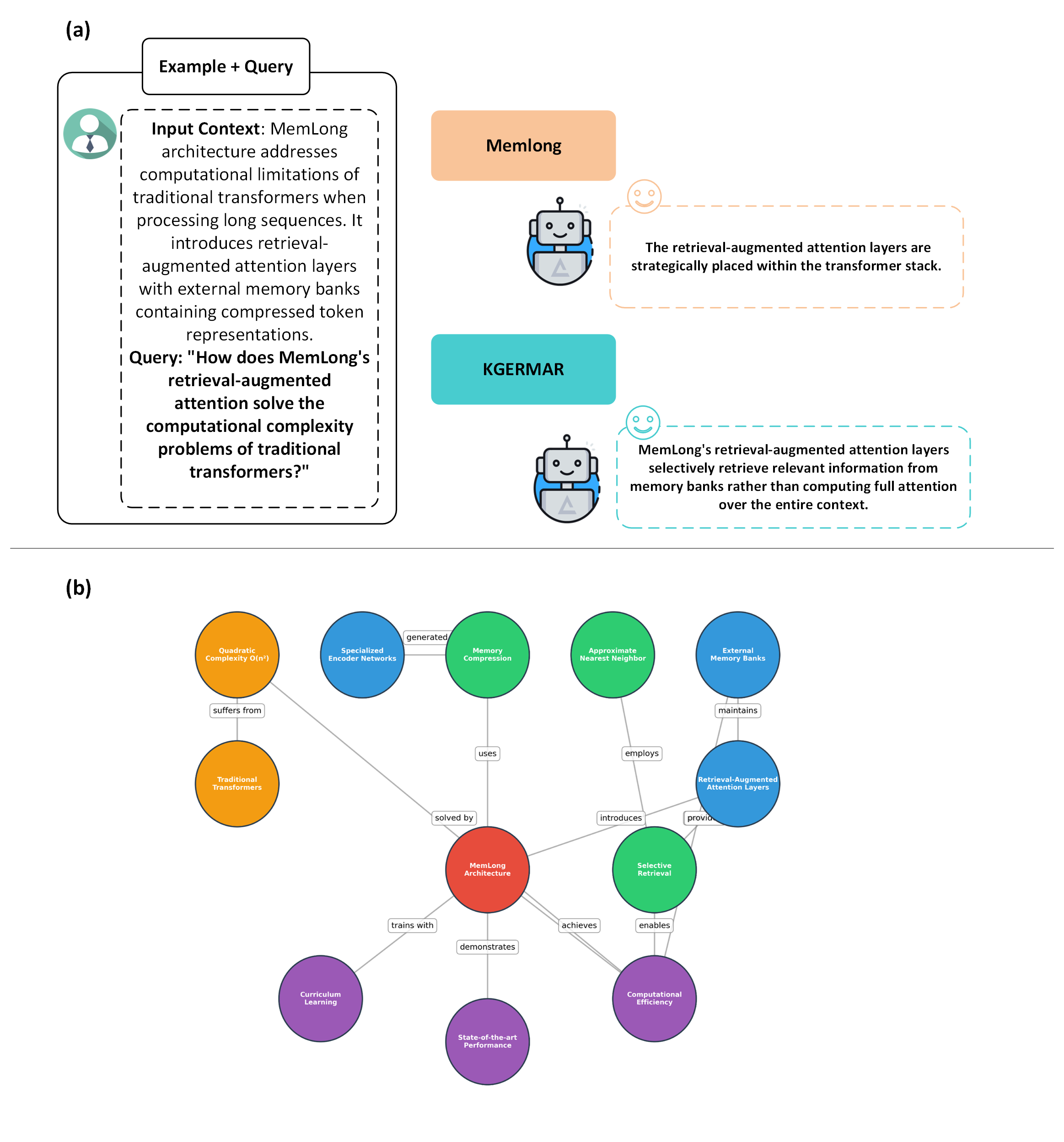
Figure 7: (a) KGERMAR achieves improved answer completeness; (b) knowledge graph-generation enables structured retrieval.
Practical and Theoretical Implications
KGERMAR demonstrates that dynamically constructing document-specific knowledge graphs and explicitly modeling entity relationships obviate the reliance on static knowledge bases and mitigate retrieval precision loss in long-context applications. The hybrid memory architecture enables scalable modeling, memory efficiency, and richer retrieval signal spaces than purely semantic systems. Practically, KGERMAR facilitates long-context deployment on commodity hardware without quadratic resource scaling, offering predictable computational requirements and improved retrieval quality.
Theoretically, KGERMAR shows that integrating relational structure with language modeling circumvents lost-in-the-middle phenomena and enables causal reasoning and entity state tracking at inference. This positions memory-augmented retrieval architectures as competitive alternatives to extended-attention models when scaling context and reduces over-reliance on large, static external knowledge graphs.
Future Directions
Enhancements may include reducing real-time graph construction latency via offline pre-computation, expanding domain-adaptive NER/relation models for specialized terminology, refining cross-paragraph relation extraction, and supporting multilingual settings. KGERMAR’s architectural innovations suggest future work in agentic systems, domain-adaptive retrieval, and explicit structural reasoning for long-context tasks with evolving entity graphs.
Conclusion
KGERMAR provides a principled, scalable framework for memory-augmented retrieval in long-context language modeling, integrating dynamic knowledge graph construction and graph-enhanced entity representations. Empirical results on perplexity, memory efficiency, and in-context learning demonstrate clear advantages over strong baselines. KGERMAR advances memory-augmented modeling by enabling real-time, document-adaptive structural reasoning. The approach’s architectural efficiency, retrieval precision, and generalization across diverse domains underscore its utility for future AI systems requiring robust long-context processing (2606.14047).