Improving Robotic Generalist Policies via Flow Reversal Steering
Abstract: Generalist policies can learn a wide range of skills from diverse robot datasets. In order to solve or improve on challenging news tasks, we need a way to infer and invoke the appropriate actions from the policy's rich behavioral prior, especially when directly commanding the policy fails. We focus on flow matching generalists and propose Flow Reversal Steering (FRS): a method that takes suboptimal but ``reasonable'' actions, finds their latent noises by passing them through the flow policy in reverse, and maps them to nearby generalist action modes. We evaluate FRS across many simulated and real-world manipulation settings. First, FRS can turn coarse semantic guidance from humans or vision-LLMs (VLMs) into corresponding good robot actions, improving zero-shot control. These gains can be distilled with behavioral cloning by training an auxiliary policy to output noises that the generalist maps to good actions -- showing up to 95% absolute task success rate boosts in under a minute of training. Finally, FRS enables policy improvement by bootstrapping reinforcement learning with semantic knowledge, improving on several tasks that standard RL fails to improve on.






Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper is about helping robots use what they already know to do new tasks better and faster. The authors introduce a method called Flow Reversal Steering (FRS), which takes rough guidance (like “move toward the sponge”) and turns it into precise, safe robot actions using a powerful “generalist” robot policy. They also show how to learn from these guided actions quickly, so the robot improves over time.
What are the main questions?
- When a robot has learned many skills from big datasets, how can we get it to use the right skill for a brand-new task?
- Can simple hints from a person or a vision-LLM (VLM) steer the robot toward the right behavior?
- Can we turn those steered actions into quick learning, so the robot gets better with very little training?
- Can this help robots improve even when normal reinforcement learning struggles?
How did they do it? Methods explained with everyday ideas
The robot’s “generalist brain”
Think of a “generalist policy” as a big robot brain that learned lots of everyday skills from many examples: picking up objects, placing items, wiping surfaces, and more. It can usually follow instructions, but new tasks can still be tricky.
Noise and flow matching (in simple terms)
Inside this robot brain is a process called “flow matching.” Imagine the robot has a secret code (called “noise”) that it turns into an action. With flow matching, this code always maps to the same action, like a fixed recipe: the ingredients (noise) deterministically become a meal (action).
- “Noise” is just the hidden code the robot uses to produce actions.
- “Denoising” is the process of turning that code back into a clean, usable action.
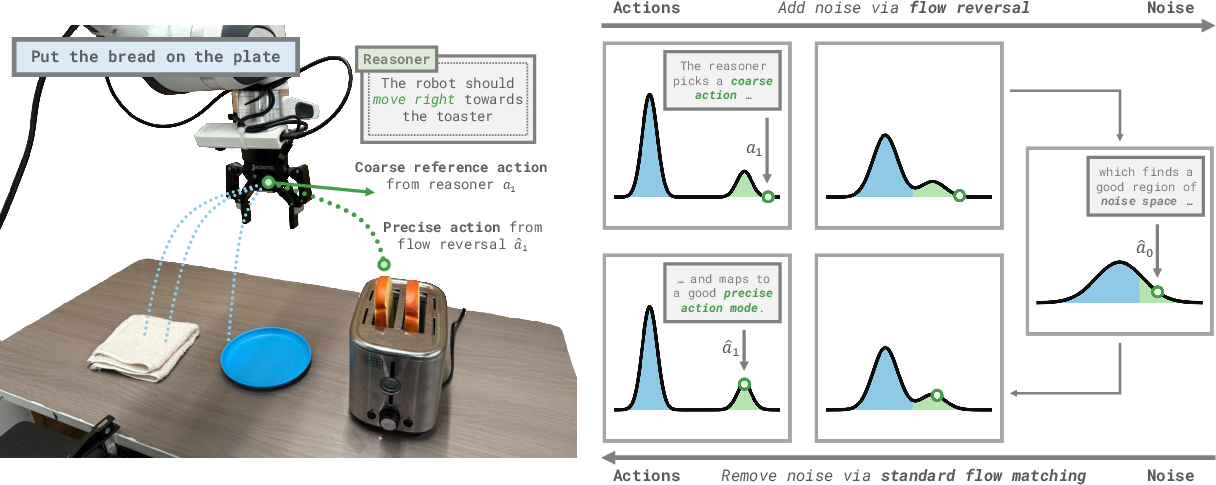
Flow Reversal Steering (FRS): turning rough ideas into good actions
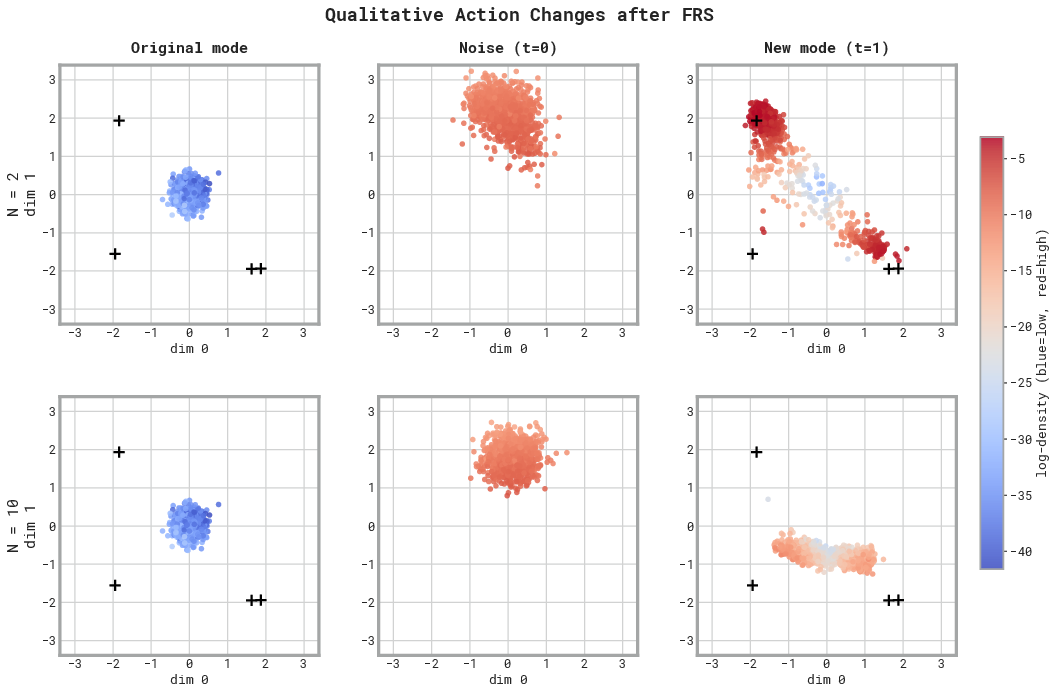
FRS works backward from a rough action to find the hidden code the robot would use, then plays it forward to get a polished, safe action the robot is comfortable executing.
Here’s the idea:
- You give a coarse action, like “move the gripper forward.”
- FRS runs the robot’s flow model in reverse to find the noise (the hidden code) that would produce something like that action.
- The robot then “denoises” that code to get a refined action that fits what it learned during training. It’s similar but smarter: it tends to be more precise and “in-distribution,” meaning it’s the kind of action the robot has seen before and knows how to do safely.
This lets simple, high-level guidance from a person or a VLM steer the robot toward the right behavior, while the robot handles the tricky details.
Learning from FRS: two quick ways to improve
Once FRS helps the robot do better actions, those actions can teach a small helper policy to keep doing well without needing the human or VLM every time.
- Behavioral Cloning (BC): Think “imitation learning.” The helper policy copies the good examples.
- Reinforcement Learning (RL): Think “trial and error with points.” The helper policy tries actions and gets rewarded for good results.
The paper proposes two efficient learning methods:
- Diffusion Steering via Behavioral Cloning (DSBC)
- Train a small helper policy to predict the right noise (hidden code) from observations.
- The big generalist robot brain then turns that noise into a good action.
- This trains in under a minute on just about 10 trajectories and works surprisingly well.
- DSRL + FRS (bootstrapping RL)
- Use a few successful FRS-guided rollouts as a starting point for RL.
- Add a small “imitation” term to keep the helper policy near those good behaviors.
- This speeds up learning and helps on tasks where normal RL makes very slow progress.
What did they find, and why is it important?
Here are the main takeaways from simulations and real-world tests:
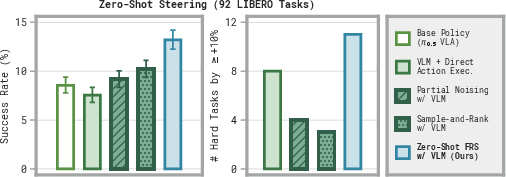
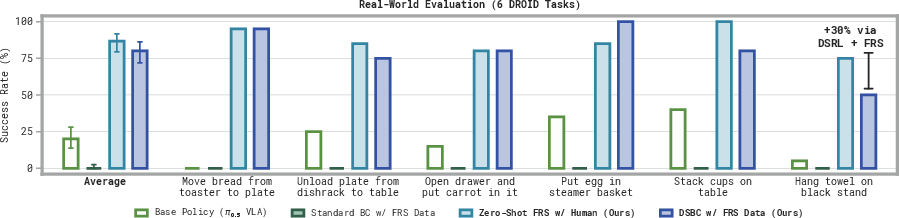
- Zero-shot improvement: Without any training, using FRS to refine VLM guidance helped robots succeed more often on many challenging tasks. It especially helped when the base policy almost never succeeded.
- DSBC learns fast: Training the small helper policy to output the right noise from FRS-guided rollouts boosted performance quickly. In some cases, the paper reports up to about 95% absolute success rate improvements after under a minute of training on ~10 trajectories.
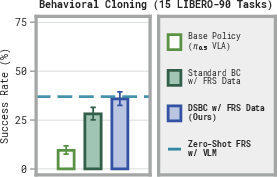
- Better than standard BC: DSBC beat regular BC (which tries to mimic robot actions directly), because DSBC leans on the generalist’s strong action prior. When the helper policy makes a mistake, the big robot brain still turns the noise into a “reasonable” action, helping recover.
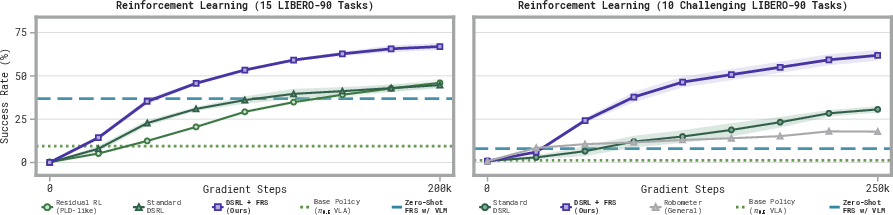
- RL learns faster and further: DSRL + FRS learned more efficiently and reached higher success rates than standard generalist RL methods. Even with just one successful FRS trajectory to start, it made meaningful progress where the base policy barely succeeded.
- Real-world gains with little data: On six real tasks, DSBC trained with only 10 human-steered FRS rollouts raised success by around 60% absolute on average. Regular BC failed in that low-data setting. In a towel-hanging task, performance rose from 5% (base) to 50% (DSBC) and then to 80% after a short RL phase.
These results matter because they show a practical way to use high-level guidance (from humans or VLMs) to get robots to do precise, safe actions, and then quickly learn from them.
What is the impact?
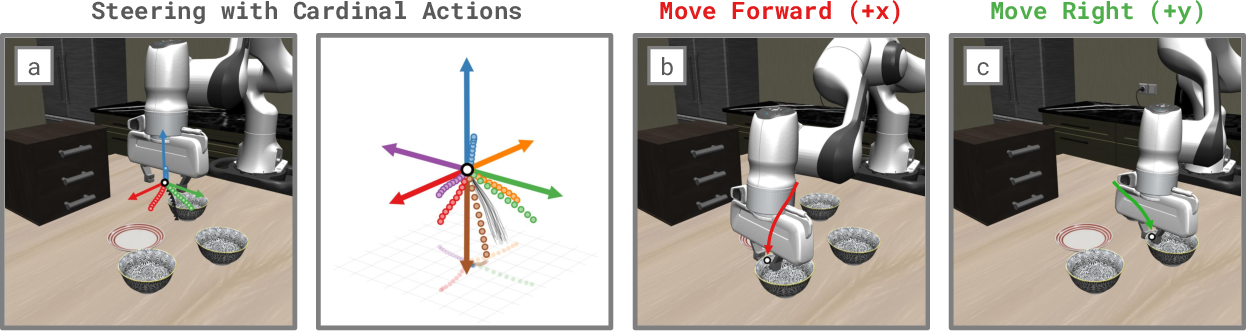
- Easier human guidance: People can give very simple hints (like “move right” or “go toward the sponge”), and FRS turns them into good robot actions. No need for tedious teleoperation all the time.
- Smarter use of VLMs: VLMs are great at understanding goals but not at low-level control. FRS bridges that gap by letting the robot convert rough VLM suggestions into fine-grained, reliable actions.
- Fast, low-compute learning: DSBC and DSRL + FRS let robots improve in minutes with small models and few examples, making adaptation more practical in real settings.
- Better generalist robots: This approach helps generalist policies tap into their “reasonable behavior” prior, making them more capable on new tasks without heavy retraining.
In short, Flow Reversal Steering is a simple, powerful way to steer and improve generalist robot policies using high-level knowledge, leading to faster learning and better performance in both simulation and the real world.
Knowledge Gaps
Below is a concise, actionable list of the knowledge gaps, limitations, and open questions left unresolved by the paper. These items are intended to guide future research.
- Lack of theoretical guarantees for flow reversal: No analysis of conditions under which reversing the learned velocity field yields a unique, stable noise mapping, nor bounds on reconstruction error or stability as a function of step size, Lipschitzness of vθ, or model approximation errors.
- Sensitivity to numerical integration choices: The method uses first-order Euler with a fixed number of steps (e.g., 10), but there is no study of how the step size h, number of steps, or higher-order ODE solvers affect steering quality, stability, and latency.
- Quantitative characterization of reconstruction bias: The core claim is that reverse-then-forward integration produces “similar but not identical,” more “in-distribution” actions, but there is no metric-based analysis (e.g., deviation from reference, likelihood under the policy, action smoothness) to quantify this bias or its task impact.
- Applicability beyond deterministic flow policies: The approach assumes deterministic flow matching; it is not evaluated on (and may not straightforwardly extend to) stochastic diffusion samplers (e.g., DDPM) or world-action models that do not admit a clean deterministic inverse mapping.
- Generality across control modalities and embodiments: Experiments focus on Cartesian action chunks for a single-arm manipulator; it remains unclear how FRS performs for torque control, high-DoF hands, bimanual/mobile manipulation, or legged systems.
- Scalability to longer-horizon, multi-stage tasks: Steering is applied at the action level using directional cues; it is unknown how FRS performs in tasks needing long-term planning, precise path geometry, or hierarchical subgoal sequencing.
- Dependence on base VLA competency: FRS leverages the generalist’s prior; performance degrades if the base model lacks relevant skills. The failure modes and fallback strategies when the prior is misaligned or insufficient are not studied.
- Robustness to poor or misleading coarse guidance: The paper assumes “reasonable” coarse actions; it does not analyze how FRS behaves when the guidance is ambiguous, incorrect, or adversarial, nor how to detect or correct such cases online.
- Safety and constraint handling in real-world settings: There is no mechanism for incorporating safety constraints (e.g., collision avoidance, joint limits, forbidden zones) into the reverse/forward mapping or the steering process.
- Real-time performance and latency: While DSBC training is fast, the per-step runtime and latency of online flow reversal and denoising under varying horizons, action rates, and hardware profiles are not reported or profiled.
- Sensitivity to VLM prompting and perception errors: The method relies on VLMs to supply directional cues; ablations on prompt design, visual noise/occlusions, and VLM failure modes (e.g., misidentification, hallucinations) are missing.
- Selection bias in task subsets: Several evaluations focus on tasks where zero-shot FRS achieves nontrivial success; it is unclear how representative these are and how results transfer to broader, more randomized or harder distributions.
- Limited evaluation diversity and randomization: LIBERO’s low randomization and the small real-world set make it difficult to assess generalization, robustness to scene variation, and resilience to covariate shift at deployment.
- Minimal ablations on FRS hyperparameters: There is no systematic study on the number of reverse/forward steps, action-chunk duration, steering frequency, or the mix between steered and base actions.
- Ambiguity of mapping to “nearby” action modes: The method assumes that reversing a coarse action maps to a “nearby” desirable mode; it does not investigate cases with multiple plausible modes, nor how to select among them.
- Combining FRS with other steering signals: The paper focuses on directional cues; it leaves unexplored the use of richer references (e.g., object keypoints, end-effector poses, partial trajectories, grasp poses) or multi-modal guidance fusion.
- Offline DSBC limitations and error accumulation: Offline DSBC uses flow-reversed noises from demonstrations without verifying the reconstructed actions; there is no analysis of how reconstruction error, suboptimal demos, or temporal misalignment affect learned noise policies.
- Recovery and compounding error under DSBC: While DSBC appears robust in some OOD states, there is no systematic evaluation of failure recovery, error compounding across long horizons, or when the VLA prior fails to “catch” large deviations.
- RL bootstrapping requirements and failure cases: DSRL + FRS assumes at least some successful steered rollouts; the method does not address how to proceed when zero successes can be obtained, nor how many successes are needed by task difficulty.
- Interaction with reward design and VLM-based rewards: Comparisons to VLM reward models are limited; it remains open how best to combine FRS with dense/shaped rewards, preference feedback, or learned value functions.
- Measuring “in-distributionness” explicitly: The claim that FRS yields in-distribution actions is not validated with density estimators, likelihood proxies, or uncertainty measures; a concrete metric could guide when to steer vs. defer to the base policy.
- Effects of visual and actuation noise: The robustness of FRS to camera noise, calibration drift, latency, and actuator backlash is not assessed, especially for precise tasks.
- Alternative inverse mappings and learning the inverse: The paper does not investigate learned inverses, adjoint-based methods, or amortized inverse models that might reduce numerical error and latency versus numerical integration.
- Interaction between FRS and exploration: Steering toward “reasonable” modes may reduce exploration needed for RL in some tasks; there is no analysis of when FRS biases hinder discovery of novel strategies.
- Bias amplification from priors: If the generalist prior encodes spurious correlations or unsafe habits, FRS may reinforce them; there is no mechanism for detecting or mitigating such biases during steering or learning.
- Multi-step/trajectory-level steering: FRS operates step-wise; open questions remain on planning with FRS over sequences (e.g., trajectory optimization in noise space) and aligning with hierarchical planners.
- Transfer across datasets and base models: Results are reported for specific VLAs (OpenPi π0.5) and datasets (LIBERO, DROID); it is unknown how FRS performs with other backbones (e.g., GR00T, WAMs), training regimes, or visual encoders.
- Formalizing when to steer vs. defer: The paper mentions deferring to the base policy for precise grasps but lacks a policy for deciding when to steer, when to sample, and when to rely on the base policy, or how to learn such arbitration.
- Evaluation of sample-and-rank with stronger scorers: The baseline uses cosine similarity to VLM directional cues; more powerful scorers (e.g., learned action-value models or physics-informed metrics) are not explored for comparison.
- Impact of action representation: The approach hinges on directional “chunks”; the effect of different action parameterizations (delta poses, residuals, velocities, impedance parameters) on FRS efficacy is not analyzed.
- Multi-object and cluttered scenes: The capacity of FRS to resolve clutter, avoid pushing non-target objects, or coordinate multi-object interactions is not systematically evaluated.
- Safety-critical deployment: No discussion of integrating FRS with formal safety monitors, verification, or risk-sensitive objectives for deployment in human-occupied environments.
Practical Applications
Practical Applications of Flow Reversal Steering (FRS) for Robotic Generalist Policies
Below are actionable applications of the paper’s findings, organized by deployment horizon. Each item lists concrete use cases, likely sectors, enabling tools/workflows, and key assumptions/dependencies that influence feasibility.
Immediate Applications
The following can be deployed with today’s flow-matching generalist policies and standard robotics stacks.
- Human-in-the-loop semantic steering for manipulation
- Use cases: Quickly guide a generalist robot through novel tasks using only coarse directional inputs (e.g., “move toward sponge,” “lift up,” “move right”), rather than full teleoperation.
- Sectors: Warehousing (ad hoc picking/placing of new SKUs), light manufacturing (line changeovers, kitting), service robotics (hospitality, janitorial), healthcare/assisted living (fetch-and-carry, light cleaning), research labs (bench organization).
- Tools/workflows: Minimal-effort operator console (joystick or UI buttons for Cartesian directions); FRS module that maps coarse actions to in-distribution fine actions; fall-back to base VLA for precise grasps; ROS node or SDK wrappers for reverse integration and denoising.
- Assumptions/dependencies: Availability of a flow-matching generalist policy with relevant “reasonable” behaviors; visual observations of sufficient fidelity; task-relevant affordances present in the VLA’s prior; real-time safe control stack; basic operator training.
- VLM-guided zero-shot task execution in new scenes
- Use cases: Autonomously execute high-level instructions (e.g., “wipe the spill with a sponge,” “place bowl on rack”) by letting a VLM suggest a coarse directional action at each step and using FRS to make it executable.
- Sectors: Home/service robots (cleaning, tidying), hospitality (table clearing), retail backroom (stock placement).
- Tools/workflows: Prompted VLM for semantic direction selection; FRS reverse/forward pass per step; simple “defer to base policy” rule for precise substeps; logging and guardrails for safety.
- Assumptions/dependencies: VLM can reliably infer correct high-level directions; latency budget permits per-step VLM+FRS inference; base VLA encodes relevant manipulation modes; prompt engineering and scene context are well-configured.
- Rapid, on-site adaptation via Diffusion Steering via Behavioral Cloning (DSBC)
- Use cases: Train a small “noise policy” in under a minute from ~10 successful FRS rollouts to adapt the robot to new variations (new objects, placements, lighting), then deploy without retraining the full VLA.
- Sectors: Manufacturing (quick retooling), warehousing (new SKU introduction), field service (site-specific quirks), labs (new apparatus).
- Tools/workflows: Collect a handful of successful FRS-guided episodes; run DSBC to fit a compact noise policy; deploy noise policy + generalist decoder in place of repeated human/VLM steering; optional periodic refresh.
- Assumptions/dependencies: Few-shot success is achievable via FRS; compute for lightweight training (~1 GB GPU memory); stable robot calibration; the generalist’s prior remains valid.
- Bootstrapped reinforcement learning (RL) using FRS (DSRL + FRS)
- Use cases: Improve performance on harder tasks that the base policy cannot solve by seeding RL with one or a few successful FRS episodes and using a BC auxiliary term to bias exploration.
- Sectors: Assembly with tight constraints, dexterous placements (e.g., towel hanging), complex packing, specialized lab workflows.
- Tools/workflows: Prefill replay buffer with successful FRS rollouts (even a single success can help); add DSBC-style auxiliary loss to the actor; SAC or similar off-policy RL with noise actions; overnight improvement loops.
- Assumptions/dependencies: Reward function or success detector is available (rule-based or VLM reward if reliable); data logging and safety checks during exploration; VLA can decode steerable action modes.
- Offline DSBC from existing demonstrations (no noises recorded)
- Use cases: Train a noise policy from legacy teleop datasets by applying flow reversal to each action offline, enabling reuse of existing demonstrations without retraining the generalist.
- Sectors: Any domain with existing robot demo corpora (manufacturing, service robotics, R&D labs); internal data platforms (fleet logs).
- Tools/workflows: Batch reverse integration on all recorded actions to extract approximate noises; noise-policy BC training; deploy as a small “adapter” that steers the generalist.
- Assumptions/dependencies: Demonstrations are of sufficient quality; reverse integration error is acceptable (reconstructions need not be perfect, but close); licensing/consent for reprocessing datasets.
- Safer, in-distribution exploration and shared autonomy
- Use cases: Reduce unsafe or erratic actions during exploration or recovery by biasing outputs toward “reasonable” behaviors encoded in the generalist; maintain human oversight with low-effort inputs.
- Sectors: Human-populated environments (hospitals, hospitality, retail), mobile manipulators in public spaces, education.
- Tools/workflows: FRS-based action shaping; safety monitors (geofencing, force limits); configurable thresholds for when to defer to the base policy; logs for safety audits.
- Assumptions/dependencies: The generalist prior avoids unsafe modes in the deployment context; conservative safety layers remain in place; appropriate HRI policies.
- Developer tooling and diagnostics for generalists
- Use cases: Inspect and debug behavior modes by mapping actions to noises and back; regression testing (compare mode selection across versions); light-weight adapters for different tasks/sites without touching the full model.
- Sectors: Robotics software vendors, integrators, academic labs.
- Tools/workflows: SDK exposing reverse/forward passes; evaluation harnesses; visualization of noise-space clusters; ROS/gRPC services to integrate with planning stacks.
- Assumptions/dependencies: Access to the flow VLA’s velocity field; stable integration step sizes and numerics; reproducible inference pipelines.
Long-Term Applications
These require further research, scaling, standardization, or productization.
- Unified semantic-to-control stacks (fully automated VLM-to-FRS pipelines)
- Use cases: End-to-end systems where high-level goals and environment descriptions from VLMs consistently yield correct low-level actions via FRS with minimal prompting or human intervention.
- Sectors: Household assistants, hospitality, small-business automation, elder care.
- Tools/workflows: Stronger VLMs for spatial/physical reasoning; adaptive prompting; automatic detection of when to steer vs. defer; continual learning with DSBC/RL.
- Assumptions/dependencies: More reliable VLM perception and physical common sense; robust latency and on-device compute; advanced uncertainty estimation.
- Cross-robot, fleet-level adaptation via shared noise policies
- Use cases: Train a noise policy once (via DSBC/RL with FRS) and deploy across a fleet of robots with varying hardware by relying on the common generalist decoder, reducing per-robot retraining.
- Sectors: Warehousing, retail chains, multi-site manufacturing, facility management.
- Tools/workflows: Standardized noise-space APIs; calibration-aware adapters; fleet telemetry to refine shared noise policies.
- Assumptions/dependencies: Consistent generalist backbones across devices; robust domain adaptation layers; strong MLOps for multi-robot deployment.
- Hierarchical integration with task-and-motion planning (TAMP) and symbolic planners
- Use cases: Planners propose sequences of subgoals and coarse controls; FRS grounds them into fine-grained actions with in-distribution priors, improving plan success rates.
- Sectors: Complex assembly, lab automation, inspection/maintenance.
- Tools/workflows: Planner-to-steering interfaces (directional chunks, subgoal state specs); learned affordance models; feedback loops to revise symbolic plans based on FRS outcomes.
- Assumptions/dependencies: Reliable subgoal detection; consistent scene grounding; verified transitions.
- Real-time, high-rate control through accelerated reverse integration
- Use cases: Applications needing >50–100 Hz control loops (e.g., dynamic manipulation, drones) where reverse/forward passes must be hardware-accelerated.
- Sectors: Advanced manufacturing, aerial manipulation, high-throughput logistics.
- Tools/workflows: Neural ODE solvers optimized on accelerators; approximate integration schemes with bounded error; co-designed hardware.
- Assumptions/dependencies: Stable numerical methods for fast bidirectional flow; latency budgets met on embedded compute.
- Safety certification leveraging in-distribution biases
- Use cases: Formalize and certify that FRS-steered policies remain within demonstrably “reasonable” behavior sets, easing deployment in regulated environments.
- Sectors: Healthcare, public-facing service robots, critical infrastructure.
- Tools/workflows: Behavioral envelopes inferred from datasets; monitors that validate noise/action mode membership; audit trails of reverse/forward mappings.
- Assumptions/dependencies: Standards bodies and regulators accept data-driven behavioral constraints; robust guarantees around failure modes.
- Extending FRS beyond manipulation to broader embodied control
- Use cases: Combine with navigation (mobile manipulation), dexterous hands, legged locomotion; potentially transfer to other generative controllers (e.g., diffusion-based driving, animation).
- Sectors: Logistics (mobile pick-and-place), field robotics, entertainment/animation.
- Tools/workflows: Multi-modal generalists (vision-language-proprioception); hierarchical noise policies (navigation vs. manipulation); expanded datasets.
- Assumptions/dependencies: Generalists with broad, high-quality priors across modalities; safe integration of motion generation with physical dynamics.
- Dataset design and coverage analytics in noise space
- Use cases: Use flow reversal to identify underrepresented action modes, curate data to fill gaps, and target data collection to improve generalization.
- Sectors: Foundation model training pipelines, academic consortia, OEMs building domain-specific generalists.
- Tools/workflows: Noise-space clustering and rarity metrics; automatic recommendations for new demonstrations; active data collection loops.
- Assumptions/dependencies: Scalable, reliable inversion across large corpora; consistent mapping between noise modes and semantic behaviors.
- Consumer-grade assistants with household personalization
- Use cases: Home robots that learn owner-specific routines via a few minutes of FRS-guided episodes and DSBC, with periodic improvement via RL.
- Sectors: Consumer robotics.
- Tools/workflows: Simple voice-to-direction UX; privacy-preserving on-device training; safe home deployment policies.
- Assumptions/dependencies: Affordable on-device compute; robust perception in varied home conditions; reliable fallback behaviors.
- Standardization of “noise-space adapters” across foundation models
- Use cases: Interoperable, swappable adapters that steer different generalists via a common API, enabling an ecosystem of third-party task modules.
- Sectors: Robotics platforms, ISVs, integrators.
- Tools/workflows: Open interfaces for reverse/forward mapping; benchmarks and compliance suites; MLOps for versioning adapters.
- Assumptions/dependencies: Industry/community convergence on flow/diffusion conventions; licensing and IP agreements for model access.
Notes across applications
- The paper demonstrates: (a) zero-shot boosts on challenging tasks using VLM/human semantic guidance; (b) DSBC can distill improvements with small models trained in under a minute on ~10 rollouts, improving success by up to ~95% absolute in reported cases; (c) RL can be bootstrapped/improved even when the base VLA has near-zero success by seeding with a single FRS success.
- Key dependencies: A capable flow-matching generalist policy, reliable perception, steerable affordances in the model’s prior, integration step-size/stability for reverse/forward passes, and appropriate safety layers.
- Limitations to plan for: If the generalist lacks relevant behaviors, FRS cannot invent them; VLMs may give erroneous directions; integration error at low step counts; latency budgets; rewards must be available for RL; distribution shift between demos and deployment.
Glossary
- Action chunk: A temporally extended low-level control segment that servos the robot along a specified direction. "rough steering action chunk"
- Affordances: The action possibilities offered by objects and the environment that bias which behaviors are reasonable in a scene. "albeit biased by the affordances in the scene"
- Behavioral cloning (BC): Supervised imitation learning that trains a policy to match expert action distributions from demonstrations. "fine-tunes it with behavioral cloning (BC) to match the action distribution of experts."
- Classifier-free guidance: A diffusion/flow steering technique that mixes conditional and unconditional predictions to bias sampling toward desired behaviors. "behavior attenuation with classifier-free guidance"
- DDIM sampling: A deterministic sampling procedure for diffusion models that enables consistent denoising without randomness. "diffusion policies with deterministic DDIM sampling too"
- Diffusion policy: A policy that generates actions by iteratively denoising Gaussian noise through a learned process. "diffusion or flow matching"
- Diffusion Steering via Behavioral Cloning (DSBC): Training a noise-action policy via supervised learning on noises recovered by flow reversal, which the generalist maps to good actions. "Diffusion Steering via Behavioral Cloning (DSBC)."
- Diffusion Steering via Reinforcement Learning (DSRL): Learning a policy over latent noises with RL so that the generalist denoises them into high-quality actions. "Diffusion Steering via Reinforcement Learning (DSRL~\citep{wagenmaker2025dsrl}) learns an auxiliary latent noise action policy"
- Euler integration: A first-order numerical method for integrating differential equations forward or backward in time. "via Euler integration"
- Flow matching: Learning a deterministic velocity field that maps noise to data by solving an ODE, enabling structured denoising. "flow matching deterministically maps noise to outputs"
- Flow reversal: Integrating the learned flow field backward from an action to recover the corresponding noise that would denoise to it. "flow reversal is distinct from the forward diffusion process"
- Flow Reversal Steering (FRS): Steering method that reverses the flow to map coarse actions to noise and denoises them into fine-grained, in-distribution actions. "We thus propose Flow Reversal Steering (FRS): a novel approach that maps coarse reference actions to their noises by passing them through flow policies in reverse."
- Forward diffusion process: The training-time process that progressively adds noise to data, typically via linear interpolation with Gaussian noise. "forward diffusion process, which linearly interpolates data with Gaussian noise"
- Generalist policy: A single multi-task policy trained on diverse data that captures a prior over reasonable behaviors across tasks. "Generalist policies can learn a wide range of skills from diverse robot datasets."
- Latent action decoder: Using a large policy (e.g., a VLA) to decode latent inputs (such as noise) into executable robot actions. "latent action decoder"
- Latent noise action policy: An auxiliary policy that outputs noise vectors conditioned on observations to steer a flow/diffusion policy. "latent noise action policy"
- Markov decision process (MDP): A formal framework for sequential decision making; here instantiated over noise actions for RL. "“noise action” Markov decision process"
- Ordinary differential equation (ODE): A continuous-time equation defining the dynamics of the flow’s velocity field used for denoising. "satisfies an ordinary differential equation"
- Partial noising: A steering technique that interpolates a reference action with noise before denoising to bias sampling. "partial noising, where reference actions are interpolated with Gaussian noise before being denoised"
- Residual RL: RL that learns a residual correction on top of a base policy to refine its behavior. "via residual RL"
- Sample-and-rank: A steering strategy that samples multiple candidate actions, scores them, and executes the highest-ranked one. "sample-and-rank"
- Soft Actor-Critic (SAC): An off-policy RL algorithm that optimizes a stochastic policy with an entropy regularizer for efficient exploration. "underlying RL algorithm (SAC)"
- Velocity field: The vector field learned in flow matching that specifies the denoising direction at each time and state. "fit a velocity field"
- Vision-Language-Action models (VLAs): Policies that integrate visual and linguistic inputs to produce robot actions. "vision-language-action policies (VLAs"
- Vision-LLMs (VLMs): Large models that jointly process images and text, used here as high-level semantic reasoners. "vision-LLMs (VLMs)"
- Zero-shot: Performing a task without any task-specific training or fine-tuning. "improving zero-shot control"
Collections
Sign up for free to add this paper to one or more collections.

