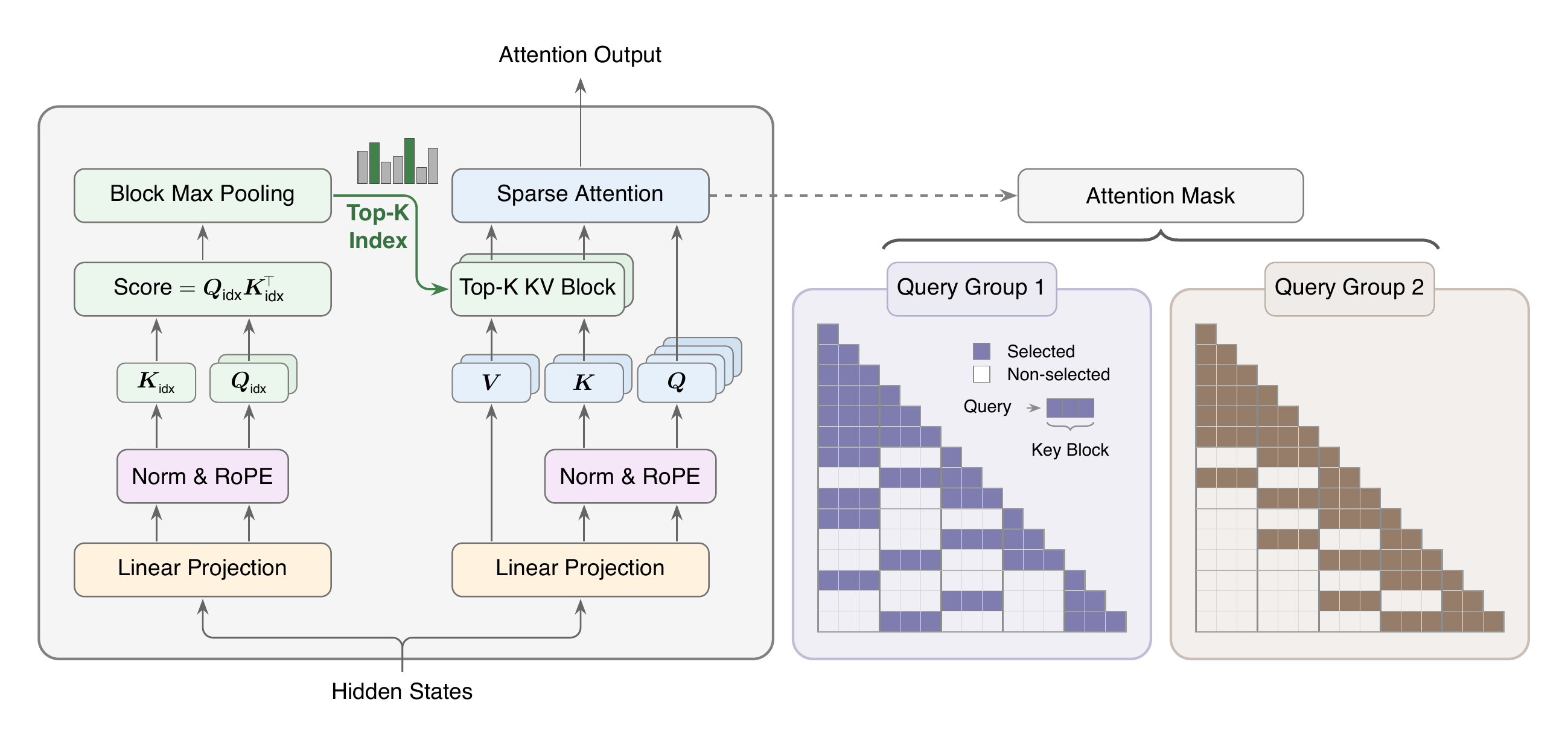
MiniMax Sparse Attention
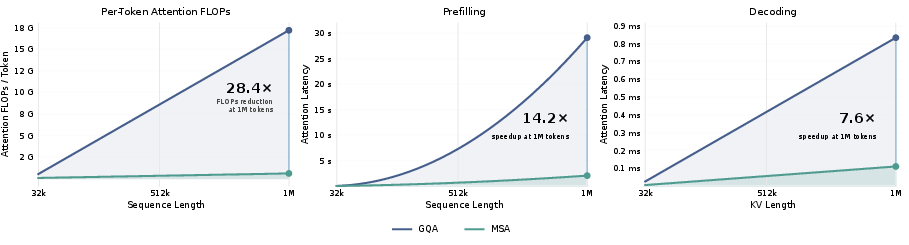
Abstract: Ultra-long-context capability is becoming indispensable for frontier LLMs: agentic workflows, repository-scale code reasoning, and persistent memory all require the model to jointly attend over hundreds of thousands to millions of tokens, yet the quadratic cost of softmax attention makes this untenable at deployment scale. We introduce MiniMax Sparse Attention (MSA), a blockwise sparse attention built upon Grouped Query Attention (GQA). A lightweight Index Branch scores key-value blocks and independently selects a Top-k subset for each GQA group, enabling group-specific sparse retrieval while maintaining efficient block-level execution; the Main Branch then performs exact block-sparse attention over only the selected blocks. Designed around a principle of simplicity and scalability, MSA is deliberately streamlined, making it straightforward to deploy efficiently across a broad range of GPUs. To translate sparsity into practical speedups, we co-design MSA with a GPU execution path that uses exp-free Top-k selection and KV-outer sparse attention to improve tensor-core utilization under block-granular access. On a 109B-parameter model with native multimodal training, MSA performs on par with GQA while reducing per-token attention compute by 28.4x at 1M context. Paired with our co-designed kernel, MSA achieves 14.2x prefill and 7.6x decoding wall-clock speedups on H800. Our inference kernel is available at: https://github.com/MiniMax-AI/MSA. A production-grade natively multimodal model powered by MSA has been publicly released at: https://huggingface.co/MiniMaxAI/MiniMax-M3.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces a way to make LLMs handle super long inputs much faster and cheaper, without losing accuracy. The method is called MiniMax Sparse Attention (MSA). It helps the model focus only on the most important parts of a very long text, codebase, or video timeline, instead of paying equal attention to everything.
Think of it like reading a giant textbook: instead of rereading every single page each time you answer a question, you first pick a few likely chapters and then read those carefully. That saves a lot of time.
What questions are the researchers asking?
They aim to answer simple but important questions:
- How can a model pay attention to millions of tokens (pieces of text, code, or video frames) without becoming too slow or expensive?
- Can we skip unimportant parts and still keep the model’s quality?
- Can this be done in a way that runs efficiently on real GPUs used in production?
How does their method work?
To explain the method, let’s use a “library” analogy.
The problem with regular attention
Standard attention looks at every past token when deciding the next token. If you double the length of the input, the work roughly quadruples. That’s too slow for million-token contexts.
The idea of sparse attention: pick a few shelves, not the whole library
MSA divides the long sequence into blocks (like shelves of books). Instead of scanning every shelf, the model picks only a small number of shelves that seem most relevant, then reads only the books on those shelves. This reduces the work from “everything” to “just the top shelves.”
Two-branch design: a picker and a reader
MSA splits attention into two parts:
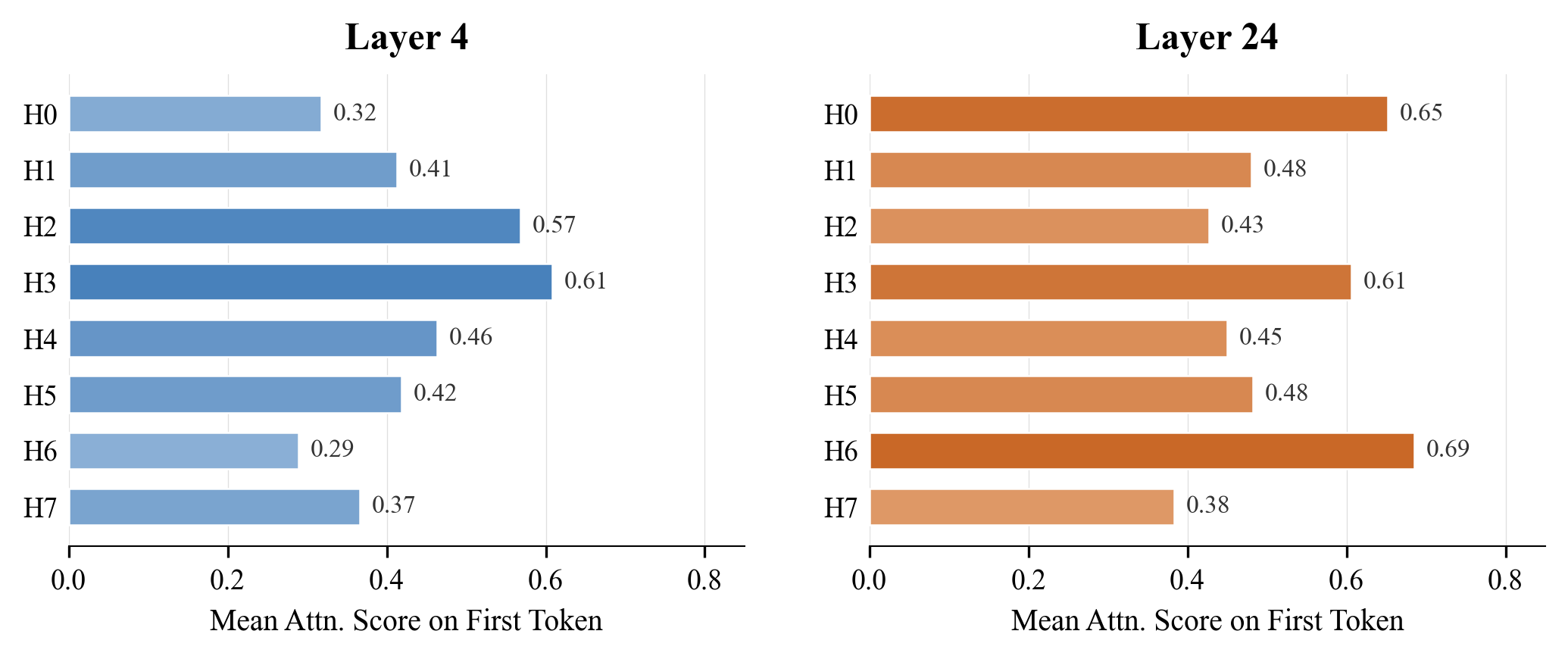
- Index Branch (the picker): A tiny “librarian” module scores shelves and chooses the top k shelves that are likely helpful for each group of attention heads. It always includes the “local” shelf (the most recent block) to stay safe and stable.
- Main Branch (the reader): The main attention then reads only from the chosen shelves and computes the final attention exactly on those.
This design is built on top of Grouped Query Attention (GQA), which already groups multiple attention heads to share the same keys/values. MSA lets each group pick its own shelves, which keeps things accurate while staying efficient.
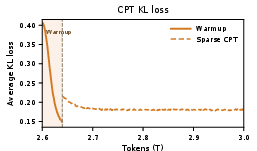
Training the picker so it chooses well
The picker needs to learn what shelves matter. The paper uses a teacher-student trick:
- The Main Branch acts like a teacher that knows where it would put attention.
- The Index Branch (the student) learns to match the teacher’s pattern using a KL alignment loss (think: “make your picks agree with the teacher’s choices”).
- During the first short phase (warmup), both branches use full attention so the student can learn from good examples. After that, the model switches to sparse mode but keeps training the student to stay aligned.
- They also “detach” gradients correctly so only the picker’s small parameters get updated by this extra loss, avoiding training instability.
Making it fast on GPUs
Speed doesn’t come just from the idea—it also needs careful engineering:
- Exp-free Top-k: They select the top shelves by comparing raw scores directly, skipping unnecessary softmax math. This makes selection quicker.
- KV-outer processing: They process “shelves” first and gather the queries that asked for those shelves. That packs work into big, efficient GPU matrix operations, using special fast math units.
- Load balancing and two-phase combine: They split work so hot shelves (popular ones) don’t become bottlenecks and combine partial results efficiently later.
All this turns theoretical savings into real speed-ups on actual hardware.
What did they find?
In tests on a very large 109-billion-parameter model trained on text and multimodal data (images and video), MSA:
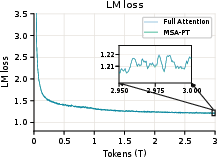
- Kept accuracy similar to the standard method across many benchmarks (reasoning, math, code, images, video, and long-context tasks).
- Greatly cut the amount of attention computation per token at 1 million tokens: about 28.4× less math in the attention part.
- Delivered big real speed-ups on NVIDIA H800 GPUs:
- About 14.2× faster “prefill” (reading the long prompt),
- About 7.6× faster “decoding” (generating the answer).
- Worked in two modes:
- Train-from-scratch with sparsity (MSA-PT), which sometimes did best on math, vision, video, and long-context tasks.
- Convert an existing dense model to sparse (MSA-CPT), which kept very similar performance to the original and is practical if you already have a trained model.
- Used a tiny attention budget per position (for example, picking 16 shelves of size 128 tokens each = 2,048 tokens), yet still handled long contexts effectively.
They released the optimized inference kernel and a production multimodal model using MSA so others can try it.
Why does it matter and what could come next?
Long contexts are crucial for real-world use: reading whole code repositories, following long instructions, remembering past chats, understanding videos over time, and more. MSA shows you can:
- Keep model quality,
- Cut costs and latency,
- And scale to million-token contexts more practically.
This makes big models more usable and affordable in production, and it’s good for energy use too.
Next steps could include:
- Even better retrieval of the most relevant blocks for ultra-long inputs,
- Adjusting how many shelves are picked at inference time for extra accuracy,
- Using the same idea in reinforcement learning and agent workflows, where long context costs dominate.
In short, MSA is a simple, scalable way to make long-context AI fast and practical—without sacrificing what makes these models powerful.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single consolidated list of unresolved issues that are missing, uncertain, or left unexplored in the paper, phrased to guide concrete future work.
- Lack of theoretical guarantees: no bounds on approximation error vs. dense softmax attention (e.g., on attention mass lost, output error, or loss increase) as a function of , , and indexer quality.
- Sensitivity to hyperparameters: no systematic study of how , block size , /, and trade off quality, recall, memory, and latency across tasks and sequence lengths.
- Fixed, uniform budgets: absence of adaptive or token-/layer-dependent and at inference/training time to dynamically allocate attention budget where needed.
- Block-level granularity only: no exploration of post-selection token-level refinement within selected blocks to reduce irrelevant tokens and improve precision.
- Per-GQA-group sharing design: impact of group-shared selection vs. per-head selection on diversity and expressivity is not analyzed; criteria for when group-level sharing is optimal are missing.
- Indexer architecture limits: only a single dot-product index head per group and one shared key head with max-pooling to blocks is considered; richer scoring (multi-layer indexers, attention over blocks, learned block embeddings, additive biases, or multi-head indexers) is not evaluated.
- KL alignment scope: after warmup, the KL loss is computed over currently selected tokens/blocks only, which risks self-reinforcing errors; alternative supervision (e.g., exploration, entropy regularization, consistency regularization, or partial dense teacher signals) is not tested.
- Warmup cost and schedule: 40B-token warmup is substantial; minimal warmup requirements, zero-warmup conversion feasibility, and robustness under smaller budgets are not studied.
- Always-included local block: cost-benefit vs. alternatives (e.g., learned local windows, dynamic neighborhood size, or priors that decrease with distance) is not ablated.
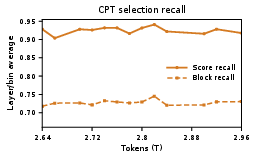
- Long-context retrieval gaps: residual deficits on some HELMET/RULER subsets are acknowledged but not dissected; no targeted ablations of failure modes where relevant information is spread across > blocks.
- Memory overhead not quantified: two-phase KV-outer forward uses O_buf and LSE_buf; memory footprint, peak HBM usage, and batch-size impacts at 1M+ contexts (and scaling with ) are not reported.
- Decode path details: kernel design focuses on prefill; decoding-specific kernels, KV-cache management/eviction policies, and interaction with cache pruning methods (e.g., SnapKV/H2O) are not detailed or benchmarked.
- Hardware portability: performance is only shown on H800; portability and speedups on A100/H100, consumer GPUs, AMD GPUs, and TPUs, and the reliance on hardware features (e.g., TMA) are not evaluated.
- Numerical precision/robustness: implications of exp-free TopK with fp8/bf16/fp16 (ties, scale sensitivity, quantization error), and accuracy/speed tradeoffs across dtypes are not characterized.
- Distributed training/inference: interaction of MSA gather/scatter and two-phase buffers with tensor/pipeline/expert parallelism (communication hotspots, all-to-all contention, scheduling under skewed block popularity) is not analyzed.
- Applicability beyond GQA: generalization to MQA or full MHA backbones, encoder–decoder architectures, and cross-attention layers (e.g., for multimodal fusion) is not empirically validated.
- Multimodal selection behavior: how the indexer treats vision/video tokens, cross-modal dependencies, and spatial/temporal locality vs. sparsity tradeoffs are not probed (e.g., does per-block selection degrade fine-grained visual reasoning?).
- Training efficiency: end-to-end training wall-clock gains and cost breakdown (index compute, TopK, sparse attention) vs. dense baseline are not reported; only inference speedups are quantified.
- Parameter/memory overhead of indexer: the added parameter count, activation memory, and optimizer-state footprint for index projections are not quantified.
- Comparison to contemporaneous sparse methods: no head-to-head evaluations vs. NSA, MoBA, DSA, or InfLLM-V2 under controlled models/compute to establish Pareto dominance or tradeoffs.
- Quality–latency Pareto curves: missing explicit curves of benchmark quality vs. (and ) to support practitioners in choosing budgets.
- Hierarchical/coarse-to-fine indexing: the indexer cost still scales as ; hierarchical block pyramids, segment summaries, or sub-sampling for TopK preselection to reduce indexer FLOPs are not explored.
- Streaming/online settings: efficient incremental updates to block scores and selections for streaming inputs (beyond prefill/standard decode) are not described.
- Failure analysis: no qualitative/quantitative analysis of missed-retrieval cases, correlation between recall metrics and downstream errors, or domain- and modality-specific error patterns.
- Layer-wise heterogeneity: uniform / across layers is assumed; potential benefits of deeper layers using larger budgets or different granularity are not investigated.
- Positional encoding interactions: only RoPE (dim 64) is used; compatibility with alternative position encodings/scalings and their impact on indexer behavior is not studied.
- Downstream agentic metrics: agent benchmarks are reported as perplexity only; end-to-end task success (e.g., SWE-bench solve rates, tool-use pipelines) under long contexts is not measured.
- Safety/robustness: effects on factuality, hallucination, calibration, and adversarial robustness with sparse selection are not evaluated.
- Reproducibility of training kernels: inference kernel is open-sourced, but availability, portability, and maintenance of training-time kernels and fused KL paths are not clarified.
Practical Applications
Summary
MiniMax Sparse Attention (MSA) is a GQA-based block-sparse attention mechanism and kernel stack that enables ultra-long-context LLMs to run efficiently by selecting only a small number of KV blocks per query (e.g., k=16 blocks of size 128, ~2,048 tokens), while preserving quality. It delivers substantial real-world efficiency gains (e.g., ~14.2× prefill and ~7.6× decode speedups at 1M tokens on H800) and supports both training-from-scratch and near-lossless conversion from dense GQA checkpoints via a simple KL-aligned indexer warmup. A production multimodal model (MiniMax-M3) and an inference kernel are publicly available.
Below are actionable applications, organized by deployment readiness and mapped to sectors, tools, and dependencies.
Immediate Applications
The following can be deployed or prototyped now with the released kernel and model, or via conversion of existing GQA models.
- AI inference acceleration for long-context workloads
- Sectors: software/AI infrastructure, cloud platforms, enterprise IT
- What: Replace dense GQA layers with MSA in long-context LLMs to cut latency and GPU cost for million-token prefill/decoding.
- Tools/products/workflows:
- Integrate MSA kernels into serving stacks (vLLM, TGI, Triton/TensorRT-LLM, Ray Serve).
- Offer “long-context tier” endpoints with 10×–15× faster prefill for RAG/agents.
- Use the public model MiniMax-M3 to validate throughput, or convert GQA checkpoints via MSA-CPT warmup.
- Assumptions/dependencies:
- Greatest gains at very long contexts; speedups measured on H800-class GPUs; benefits may vary by GPU and sequence length.
- Model backbone should use GQA; MSA-CPT warmup (tens of billions tokens) preserves quality when converting dense checkpoints.
- Kernel integration and ops support (bf16/fp8) required; tune k and block size to quality/latency needs.
- Repository- and corpus-scale RAG and analytics
- Sectors: legal, finance, healthcare, research, public sector
- What: Process very long documents or many stitched documents (e-discovery, regulation analysis, patient longitudinal records, audit trails) without aggressive chunking.
- Tools/products/workflows:
- LlamaIndex/LangChain pipelines configured with ≥128K–1M context powered by MSA.
- Document understanding copilots that maintain larger working windows during analysis.
- Assumptions/dependencies:
- Long-context-capable model weights (e.g., MiniMax-M3 or converted checkpoints) and sufficient HBM.
- Domain fine-tuning for specialized jargon; compliance/governance for sensitive data (HIPAA/GDPR).
- Repository-scale code assistants and static analysis
- Sectors: software engineering, DevOps, security
- What: Code review, refactoring, and dependency impact analysis across monorepos using million-token windows.
- Tools/products/workflows:
- IDE extensions (VS Code, JetBrains) with MSA-backed backends; CI bots for repo-wide change analysis.
- Assumptions/dependencies:
- Code-tuned LLMs with GQA backbones; benefits increase with repository size and analysis depth.
- Multimodal long-duration video/image understanding
- Sectors: media analytics, sports analytics, retail, safety/compliance
- What: Video QA and report generation over long temporal spans (minutes to hours) at lower cost/latency.
- Tools/products/workflows:
- Video QA pipelines using the natively multimodal MiniMax-M3, batched inference with MSA kernels.
- Assumptions/dependencies:
- Multimodal pretraining is required; GPU memory planning must account for long contexts and visual tokens.
- Long-horizon agentic workflows with persistent working memory
- Sectors: customer support, sales operations, knowledge management, IT automation
- What: Agents that keep large working contexts (tools outputs, logs, plans) over many interleaved steps without constant retrieval.
- Tools/products/workflows:
- Agent frameworks (AutoGen, LangGraph) configured to maintain large context windows rather than repeatedly re-querying stores.
- Assumptions/dependencies:
- Long-context budgets still finite (e.g., ~2,048 selected tokens per query); careful prompt/tooling design to ensure critical information is selected.
- Cost and energy savings for model providers and enterprises
- Sectors: cloud/edge providers, AI platforms, FinOps/sustainability
- What: Reduce GPU-hours per request and energy consumption for long-context inference and training.
- Tools/products/workflows:
- Offer discounted SKUs for long-context workloads; track $/M-token and kgCO2e/M-token KPIs.
- Assumptions/dependencies:
- Savings depend on realized wall-clock speedups; operational telemetry and autoscaling policies should be updated to reflect new throughput.
- Faster pretraining/continued-pretraining with sparse attention
- Sectors: academia, open-source labs, model vendors
- What: Train or convert large GQA models to sparse attention to extend context affordably.
- Tools/products/workflows:
- Use MSA-PT (from scratch) or MSA-CPT (convert dense GQA checkpoints) with KL-aligned indexer warmup and forced local block.
- Assumptions/dependencies:
- Training pipelines must implement KL loss, gradient detach, and warmup; verify quality with long-context benchmarks (RULER/HELMET).
- Systems research and teaching in efficient attention
- Sectors: academia, systems/compilers research
- What: Use the released kernels to study block-sparse attention, Top‑k selection, KV‑outer iteration, and fused KL plumbing.
- Tools/products/workflows:
- Curriculum modules and lab assignments comparing Q‑outer vs KV‑outer kernels; Triton/CUDA kernel prototyping.
- Assumptions/dependencies:
- Access to modern GPUs with tensor cores; reproducible benchmarking harness.
Long-Term Applications
These require further research, scaling, or ecosystem support (e.g., broader hardware coverage, training budgets, or productization).
- Standardization of block-sparse attention in mainstream LLM stacks and hardware
- Sectors: semiconductor, cloud, AI frameworks
- What: Native MSA-like primitives in PyTorch/JAX, TensorRT-LLM, and accelerator ISAs; compiler-level auto-scheduling for sparse attention.
- Potential tools/products:
- Vendor-optimized Top‑k and KV‑outer kernels; automatic sparse scheduling in compilers; standardized APIs for block-sparse attention.
- Dependencies:
- Cross-vendor performance parity; IR/graph support for dynamic sparsity; benchmarking standards.
- Extreme long-context agents with persistent and personal memory
- Sectors: productivity, CRM, ITSM, creative tools
- What: Agents that maintain months of interaction history and artifacts in-context, reducing reliance on external retrieval and improving coherence.
- Potential tools/products:
- “Memory-native” agent platforms with dynamic k scaling at inference and background memory compaction.
- Dependencies:
- Further research on indexers (richer scoring, adaptive budgets), guardrails for privacy/forgetting, and storage orchestration.
- Fully in-context knowledge management without heavy RAG stacks
- Sectors: enterprise knowledge bases, legal, finance, consulting
- What: Keep large portions of a corpus in-context for end-to-end reasoning and drafting, simplifying pipelines.
- Potential tools/products:
- Context-first KM systems that move from retrieval to selection-only attention; hybrid with light RAG fallback.
- Dependencies:
- Memory/cost tradeoffs, quality at scale, and governance for sensitive content.
- Long-horizon multimodal robotics and teleoperation
- Sectors: robotics, autonomous systems, manufacturing
- What: Controllers/planners that keep long visual and state histories in-context for better planning/explanations.
- Potential tools/products:
- Long-context policy models with block-sparse attention for temporal grounding and failure analysis.
- Dependencies:
- Real-time constraints, safety certification, on-robot compute or efficient streaming to edge GPUs.
- On-device/edge long-context assistants
- Sectors: mobile/PC OEMs, embedded, healthcare devices
- What: Local assistants handling larger contexts (private documents, logs) on constrained GPUs/NPUs using sparse attention.
- Potential tools/products:
- Edge LLM runtimes with MSA-like kernels, dynamic k, and mixed-precision/fp8.
- Dependencies:
- Hardware support for sparse patterns and tensor cores; memory limits; model distillation to smaller GQA backbones.
- Improved learned indexers and training objectives
- Sectors: model R&D, academia
- What: Higher-recall selection with minimal compute via better ranking heads, auxiliary losses, or RLHF/RLAIF tuned to retrieval quality.
- Potential tools/products:
- Plug-in indexer modules with optional cross-head context, adaptive windowing, or task-aware k scheduling.
- Dependencies:
- Careful stability/efficiency balance; training data with long-context supervision; evaluation suites beyond RULER/HELMET.
- Sector-specific longitudinal analytics
- Healthcare: decade-long EHR timeline understanding and cohort analysis for care pathways; assumptions include domain fine-tuning, strict PHI controls, and auditability.
- Finance: multi-year 10‑K/10‑Q and call transcript synthesis for research/compliance; assumes robust grounding and human-in-the-loop.
- Education: portfolio- and course-long assessment/feedback; depends on LMS integrations and bias/fairness evaluation.
- Policy and sustainability frameworks for efficient long-context AI
- Sectors: government, standards bodies, ESG
- What: Guidelines and benchmarks that recognize block-sparse attention as best practice for long-context deployments, informing procurement and carbon reporting.
- Potential tools/products:
- Public efficiency scorecards (tokens/joule), green AI certifications for long-context services.
- Dependencies:
- Transparent, reproducible benchmarks across hardware; alignment with privacy and safety regulations.
Notes on feasibility across applications:
- Architectural fit: MSA assumes a GQA backbone; conversion (MSA-CPT) is near-lossless with warmup and KL alignment, but MHA/MQA-only models may require additional adaptation.
- Quality vs. budget: The selection budget (~2,048 tokens per query in the paper) is small relative to million-token contexts; some tasks may require larger k at inference, trading speed for recall.
- Hardware variability: Reported gains use H800; performance on A100/H100/L40S and future NPUs/accelerators may differ until kernels are re-tuned.
- Multimodal readiness: Long-context gains apply to multimodal only if the model is natively trained for vision/video and tokenization is efficient.
- Licensing/commercial use: Validate licenses for the released kernels and MiniMax-M3 before production use.
Glossary
- agentic workflows: Multi-step, autonomous task sequences where a model plans, reasons, and acts over long horizons. "LLMs are rapidly shifting from short, single-turn interactions to long-horizon agentic workflows"
- arithmetic intensity: The ratio of computation to data movement; higher values typically improve GPU efficiency. "we choose KV-outer iteration with Q gather to maximize arithmetic intensity."
- bfloat16: A 16-bit floating-point format with an 8-bit exponent that balances range and precision for deep learning. "(bfloat16-sized traffic)"
- bitonic sort: A parallel sorting network often used in GPU kernels; here referenced as a baseline for top-k selection complexity. "scale as (bitonic sort)"
- blockwise sparse attention: An attention pattern that restricts computation to selected blocks of tokens rather than all tokens. "a blockwise sparse attention built upon Grouped Query Attention (GQA)."
- causal Softmax Attention: Attention that only attends to past or current positions to maintain autoregressive causality. "causal Softmax Attention computes"
- co-design: Jointly designing algorithms and hardware/software execution paths to achieve practical speedups. "we co-design MSA with a GPU execution path"
- cooperative thread array (CTA): A CUDA scheduling unit (thread block) that executes cooperatively on an SM; used as the work granularity in kernels. "A direct one-CTA-per-tile mapping is dominated by sink rows"
- decoding: The inference phase where tokens are generated step-by-step, often latency-sensitive. "MSA achieves prefill and decoding wall-clock speedups on H800."
- FLOPs: Floating point operations; a measure of computational cost used to compare attention mechanisms. "the causal attention FLOPs of GQA and MSA are"
- GQA (Grouped Query Attention): An attention variant that shares key–value heads across multiple query heads to reduce cost. "built upon Grouped Query Attention (GQA)."
- GQA group: The set of query heads that share one key–value head in GQA. "independently selects a Top- subset for each GQA group"
- GQA ratio: The ratio of query heads to key–value heads (G = Hq/Hkv) indicating how many query heads share a KV head. "GQA ratio"
- HBM (High Bandwidth Memory): High-throughput memory used by GPUs to store and exchange intermediate tensors efficiently. "HBM buffers "
- Index Branch: The lightweight selector submodule that scores blocks and chooses which key–value blocks to attend. "A lightweight Index Branch scores key–value blocks"
- indexer warmup: A training phase that initializes the indexer by running dense attention before switching to sparse selection. "The solid segment denotes indexer warmup"
- KL loss: Kullback–Leibler divergence used here to align the indexer’s selection distribution with the main attention’s distribution. "a KL loss aligns the index distribution"
- KV-outer iteration: A loop ordering for sparse attention that iterates over key–value blocks first and gathers queries to increase compute intensity. "we organize sparse attention in a KV-outer order"
- logsumexp (LSE): A numerically stable transform for summing exponentials in log space, used for softmax normalization bookkeeping. "we further fuse the auxiliary LSE computation required by the sparse KL loss into the forward pass"
- min-heap: A priority queue structure where the smallest element is at the root; used for efficient per-thread top-k maintenance. "maintains a -element min-heap in shared memory."
- Mixture of Experts (MoE): An architecture with many specialized expert sub-networks, of which only a subset is activated per token. "a 109B-parameter Mixture of Experts (MoE) model"
- persistent grid: A GPU kernel launch pattern where CTAs persist and dynamically fetch work to balance load. "The kernel runs as a persistent grid"
- prefill: The attention pass over the prompt/context before token generation; often the dominant cost at long contexts. "MSA achieves prefill and decoding wall-clock speedups on H800."
- Programmatic Dependent Launch: A CUDA feature to reduce overhead by launching kernels programmatically with dependencies. "The two kernels use Programmatic Dependent Launch to hide the inter-kernel launch latency."
- radix selection: A selection algorithm using radix-based bucketing; referenced as a baseline for top-k performance. "(radix selection)"
- reverse sparse index: A data structure mapping selected key–value blocks back to the queries that selected them, enabling KV-outer processing. "a reverse sparse index from the TopK selection identifies the relevant query positions."
- RoPE (Rotary Positional Embedding): A positional encoding scheme that rotates query/key vectors to encode relative positions. "RoPE dimension 64."
- split-K: A technique that splits work across multiple partial reductions (K-dimension) and later combines them, used here for block-sparse softmax. "normalized split-K weights"
- stop-gradient: A training operation that blocks gradient flow through certain tensors to isolate learning signals. "we apply stop-gradient to the Index Branch input"
- tensor-core MMA: Matrix multiply–accumulate operations executed on GPU tensor cores for high-throughput matrix math. "concatenate them to fill tensor-core MMAs"
- TMA copies: Specialized GPU memory transfer mechanisms (Tensor Memory Accelerator) used to move tiles efficiently into shared memory. "These queries are loaded into shared memory via TMA copies"
- Top-k selection: Selecting the k highest-scoring items (e.g., blocks) to limit attention computation. "uses exp-free Top- selection"
- wall-clock speedups: Real, end-to-end runtime improvements measured during execution. "MSA achieves prefill and decoding wall-clock speedups on H800."
- warp: The basic SIMD execution unit on NVIDIA GPUs consisting of 32 threads that execute in lockstep. "Each of the warp's 32 lanes"
Collections
Sign up for free to add this paper to one or more collections.

