- The paper introduces a geometric, capability-based routing mechanism that selects the most cost-effective model for each LLM query.
- It demonstrates significant improvements by achieving up to 76.98% accuracy while reducing cost by up to 1.39× compared to single-model baselines.
- The method leverages calibrated ModernBERT and multi-dimensional difficulty assessments to efficiently route queries in heterogeneous model pools.
Brick: Spatial Capability Routing for the Mixture-of-Models (MoM) Paradigm
Introduction and Motivation
"Brick: Spatial Capability Routing for the Mixture-of-Models (MoM) Paradigm" (2606.13241) systematically investigates whole-model routing in LLM deployments, formalizing the Mixture-of-Models (MoM) paradigm. The paradigm distinguishes itself from token-level Mixture-of-Experts (MoE) by routing at the level of discrete models, leveraging heterogeneous pools with distinct price and capability profiles. The central deployment problem is empirical: given per-query, per-model correctness and costs, can a router dispatch queries to the cheapest model that will correctly answer them, achieving cost-optimality without sacrificing accuracy? The engineering challenge is multi-dimensional: models possess non-uniform strengths across tasks, and cost/latency vary by an order of magnitude. Superficial domain- or length-based routing is shown to be inadequate due to intra-domain heterogeneity, leading to Brick's geometric capability-based routing approach.
Mixture-of-Models Paradigm and Pool Construction
The MoM paradigm pools models at inference time using an external router, dispatching one model per query. The paper operates on a three-model pool: qwen3.5-9b, deepseek-v4-flash, and kimi2.6, selected for their complementary price-quality profiles. Cost objects are explicitly separated into a dimensionless scalar cm for routing-math and a realized per-call USD cost $a_m^{\$},lockedatcalibration.Thepoolexhibitspronouncedcostdisparities(upto44\timesspread),andthethree−modeloracledemonstratessignificantperformanceheadroom(83.25\%accuracyvs75.02\%forthestrongestsinglemodel),motivatingMoMroutingasacost−effectivemechanismforcapturingthisgap.</p><h2class=′paper−heading′id=′dataset−and−evaluation−protocol′>DatasetandEvaluationProtocol</h2><p>BrickisevaluatedonBrick2DatasetA—astratified,license−clean,multidimensionalbenchmarkof5,504queriesspanningsixcapabilitydimensions:coding,creativesynthesis,instructionfollowing,mathreasoning,planning/agentic,andworldknowledge.Qualityisvalidatedviadeterministicschema,LLMcalibration,andmanualaudit.Gradingprotocolsarediverse,employingbothdeterministicand<ahref="https://www.emergentmind.com/topics/llm−judges−a669791b−05c7−4fa3−8c4c−60b7bafe2ad2"title=""rel="nofollow"data−turbo="false"class="assistant−link"x−datax−tooltip.raw="">LLMjudges</a>.Responseaccuracyisdefinedstrictlyastherateatwhichthedispatchedmodelsolvesthequeryperprotocolgrader.</p><h2class=′paper−heading′id=′comparative−analysis−of−routing−baselines′>ComparativeAnalysisofRoutingBaselines</h2><p>Externalroutingbaselinesincludedomain/length−based,<ahref="https://www.emergentmind.com/topics/routellm"title=""rel="nofollow"data−turbo="false"class="assistant−link"x−datax−tooltip.raw="">RouteLLM</a>pairwise−preference,<ahref="https://www.emergentmind.com/topics/frugalgpt"title=""rel="nofollow"data−turbo="false"class="assistant−link"x−datax−tooltip.raw="">FrugalGPT</a>cascades,andCascadeRoutingutility−basedapproaches.Single−steprouters(RouteLLM)degeneratetoalways−Kimiinthispool,offeringnoaccuracy/costgain.Cascaderoutersescalatesequentiallybycost,incurringconsiderablecumulativeoverheadinagentic<ahref="https://www.emergentmind.com/topics/regimes"title=""rel="nofollow"data−turbo="false"class="assistant−link"x−datax−tooltip.raw="">regimes</a>(1.47\times$ cost for 10-step agent trajectories). Notably, Brick's pure single-step routing scales favorably for agentic applications, avoiding the compounding cost/latency of cascades.</p>
<p>Cost vs performance is visualized across baselines, with Brick's max profile ($76.98\%at0.022083USD)dominatingalways−Kimibothinaccuracyandcost(28\%cheaper).Mid−bandBrickprofilesexploitdeepseek−v4−flash’ssweetspots(particularlyinworldknowledge),yieldingaccuracy/costtrade−offsunattainablebycascadebaselines.<imgsrc="https://emergentmind−storage−cdn−c7atfsgud9cecchk.z01.azurefd.net/paper−images/2606−13241/costpareto.png"alt="Figure1"title=""class="markdown−image"loading="lazy"><pclass="figure−caption">Figure1:CostvsresponseaccuracyonDataset A.BrickprofilestraceaParetofrontabovecascadeandsingle−modelbaselines;thedashedlinemarkstheoracleceiling.</p></p><h2class=′paper−heading′id=′brick−architecture−and−routing−formalism′>BrickArchitectureandRoutingFormalism</h2><p>Brickprocessesqueriesthroughacalibratedpipeline:textnormalization,keywordpriorinjection,capabilityvectorestimationvia<ahref="https://www.emergentmind.com/topics/modernbert"title=""rel="nofollow"data−turbo="false"class="assistant−link"x−datax−tooltip.raw="">ModernBERT</a>,complexity/difficultyclassification,modelscoring,and<ahref="https://www.emergentmind.com/topics/deterministic−selection"title=""rel="nofollow"data−turbo="false"class="assistant−link"x−datax−tooltip.raw="">deterministicselection</a>.Thegeometricroutingruleoperatesinasix−dimensionalcapabilityspace,withbothqueriesandmodelsasvectors.Theroutingmathcomputesper−capabilityrequirementsandmodelcapacitiesinlogitspace,derivingasymmetricresidualsforunder−andover−capacity.Theroutingobjectivea_m^{\$0 aggregates capability distance and dollar-scaled penalty, controlled by four scalars $a_m^{\$1 modulated by a user preference knob $a_m^{\$2.
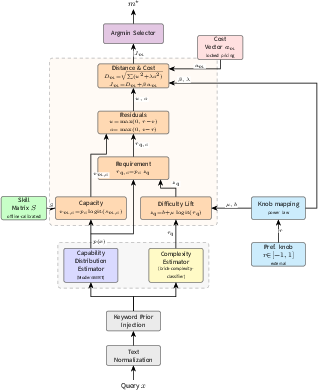
Figure 2: Brick architecture. Parallel capability and complexity estimators feed a cost-penalized geometric routing block; scalars are modulated by user preference.
A worked example computes detailed routing math and illustrates Brick’s deterministic behavior. Two complementary views (capability heatmap and 3D projection) trace routing decisions in capability space.
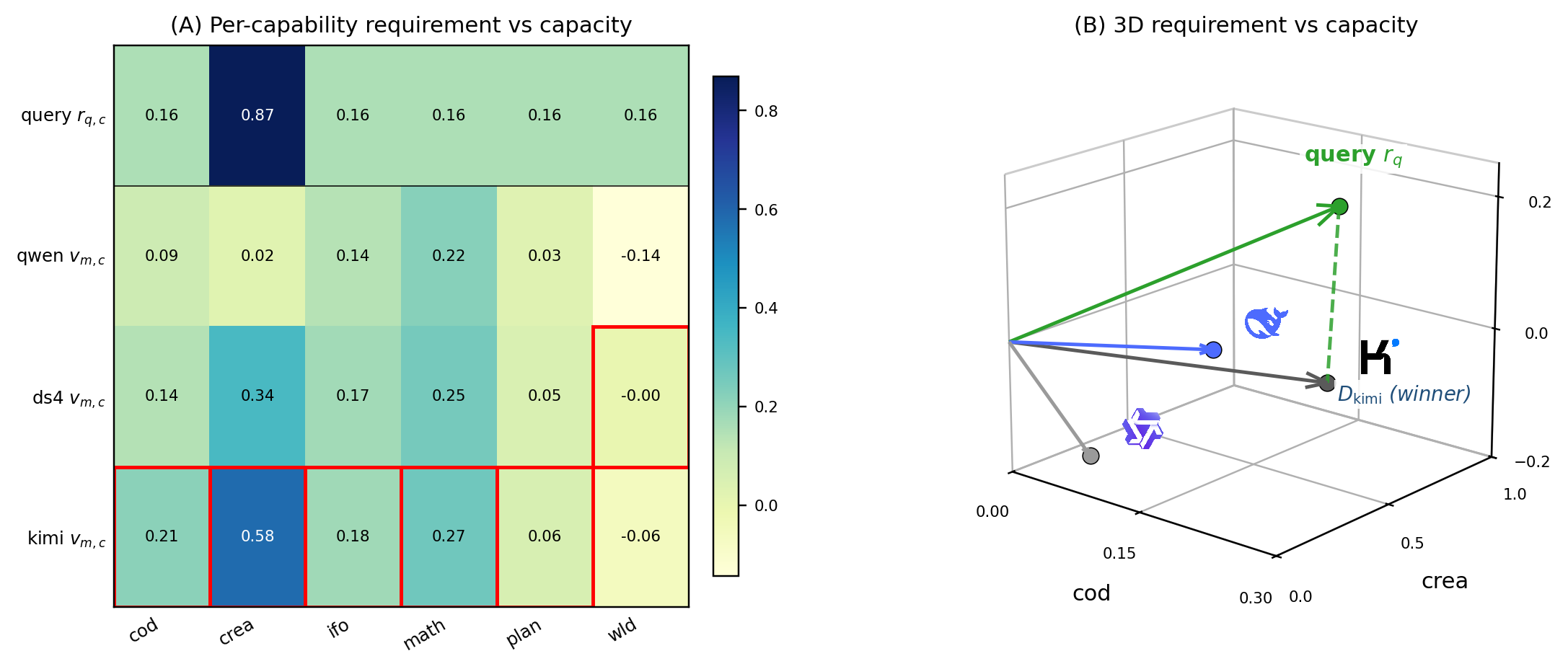
Figure 3: Two views of the routing decision for a worked-example query show heatmap alignment (A) and geometric projection (B) of requirements and model capacities.
ModernBERT is fine-tuned for high-confidence capability classification (macro-Pearson $a_m^{\$3). The complexity head is domain-agnostic, blending label and confidence for continuous difficulty estimations, with anchors mapping to difficulty levels. The user knob $a_m^{\$4 exposes a continuous trade-off between cost and quality, with independently calibrated power-law multipliers.
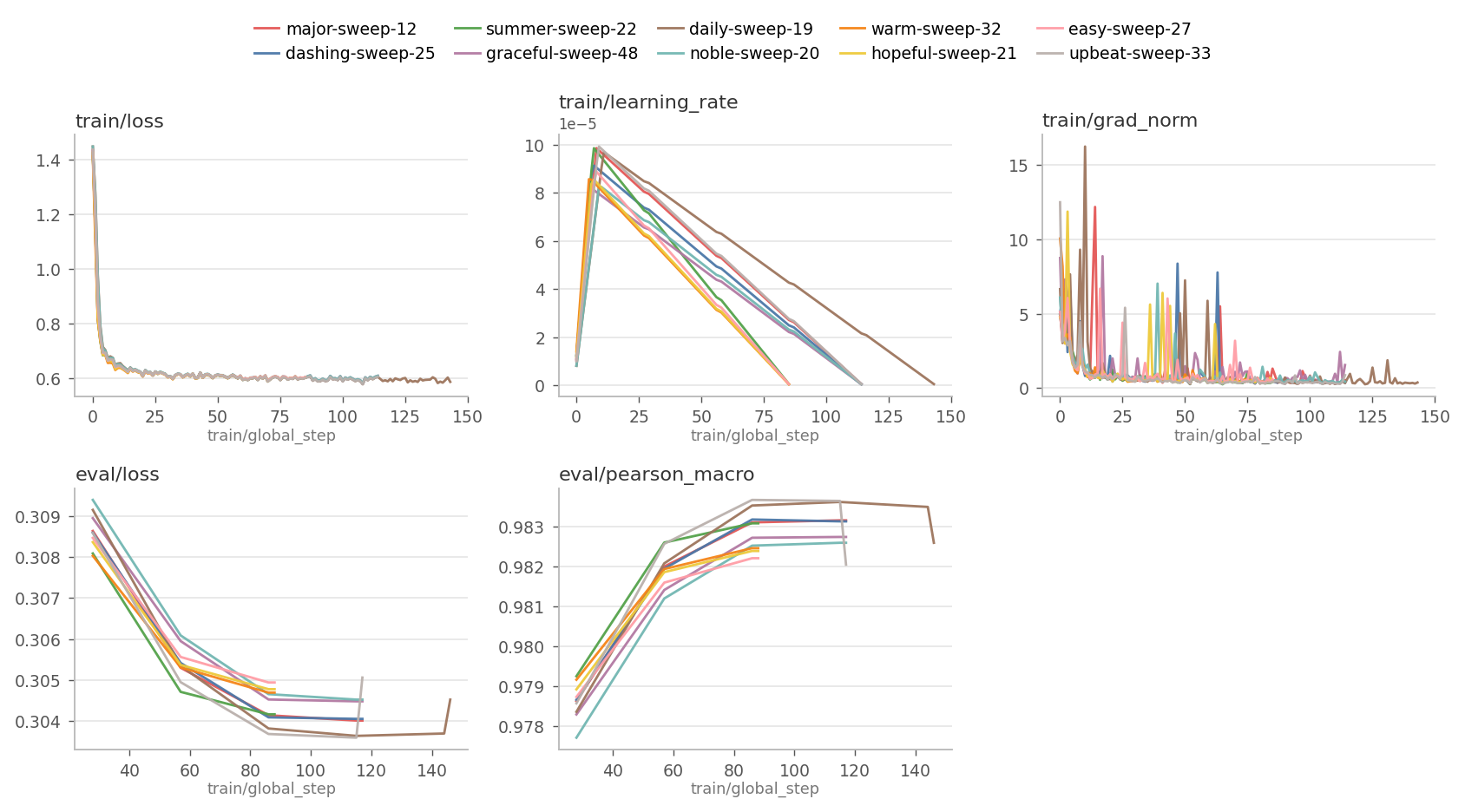
Figure 4: Top-10 ModernBERT training runs visualized by loss, learning rate, gradient norm, and macro-Pearson; the best configuration is selected for deployment.
Results: Response Accuracy, Cost, and Latency
Brick's max-quality profile achieves $a_m^{\$5 selected-answer accuracy and $a_m^{\$6 route-exact accuracy, exceeding always-Kimi by $a_m^{\$7 pp at $a_m^{\$8 lower cost. Neutral and low profiles offer substantial cost savings ($a_m^{\$9 and ,lockedatcalibration.Thepoolexhibitspronouncedcostdisparities(upto440 cheaper, respectively) for only marginal decreases in accuracy. Across the cost-performance landscape, Brick profiles dominate classical routers, exploiting complementary error sets and refusal patterns.
Latency measurements distinguish router decision overhead from end-to-end perceived latency. Brick matches or beats always-Kimi in median latency due to routing to faster models on non-frontier queries.
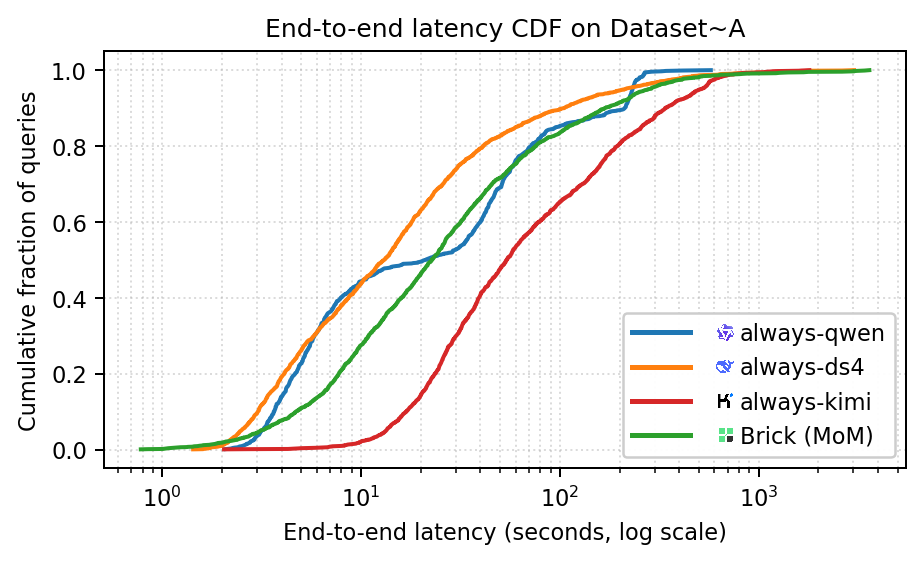
Figure 5: End-to-end latency CDF. Brick (MoM) at max profile achieves higher response accuracy than always-ds4 and always-kimi at lower latency.
Implications, Limitations, and Open Directions
The empirical findings validate several claims:
- MoM routing outperforms the best single baseline and cascade routers across cost and accuracy.
- Pure routing scales linearly for agentic applications, avoiding the compounding penalties of cascade approaches.
- Complementary error sets and per-capability refusal patterns are exploited via calibrated skill vectors.
- The residual oracle gap (,lockedatcalibration.Thepoolexhibitspronouncedcostdisparities(upto441 pp) is the direction for future improvements, requiring enhanced estimator stacks and skill matrix calibration over sparse pools.
Practical deployment is tractable: Brick’s knob exposes direct operator control over quality-vs-cost. The approach generalizes to multimodal routing and mixed open-weight/commercial API pools, with modality detection as a natural extension point.
Theoretical implications center around formalizing model selection as a geometric optimization in capability-cost space. Speculative directions include Bayesian skill estimation, domain-conditioned complexity, and entropy-based thermodynamic formalisms for query routing.
Conclusion
Brick formally advances whole-model routing in heterogeneous LLM pools via capability-space geometry and cost-penalized selection, offering a practical and theoretically sound bridge for cost-aware deployment of both open-weight and closed-weight models. The routing paradigm is validated by robust empirical performance, interpretable architecture, and scalable design for agentic and multimodal applications.

