- The paper introduces an innovative training pipeline using Augmented Lean Formalisation (ALF) that reduces compute and parameter requirements while boosting performance.
- It employs a curriculum-stratified Lean corpus, multi-stage data augmentation, and hybrid autoregressive and diffusion decoding to enhance robustness and transferability.
- Empirical results on MiniF2F-Test and PutnamBench demonstrate that even a 4B-parameter model can outperform larger systems, making formal theorem proving more accessible.
Overview
Pythagoras-Prover introduces a family of compute-efficient, open-source neural theorem provers for Lean~4 that robustly outperform prior state-of-the-art models at a fraction of the parameter count and inference budget. The paper presents an effective training pipeline underpinned by a meticulously-curated Lean corpus, stratified difficulty curriculum, a structured mutation- and distillation-based data augmentation framework (Augmented Lean Formalisation, ALF), and a hybrid model suite spanning autoregressive and diffusion-based decoding. Empirically, Pythagoras-Prover-4B surpasses DeepSeek-Prover-V2-671B on MiniF2F-Test (82.4%→86.1%) while being 167× smaller, and Pythagoras-Prover-32B achieves top leaderboard results on MiniF2F and PutnamBench. The introduction of MiniF2F-ALF—a systematically mutated, contamination-sensitive benchmark—reveals the limits of robustness and transfer for contemporary Lean provers.
Architecture and Training Pipeline
The Pythagoras-Prover suite consists of autoregressive models at 4B and 32B parameters and, notably, a 4B-parameter diffusion-based model. All variants are trained using a pipeline designed to decouple scalable data curation from the computational bottleneck of Lean verification, and to maximize robustness and transfer.
Lean-Verified Core Corpus
An initial Lean-verified seed corpus is assembled, stratified by difficulty (easy, medium, hard). Easy/medium data is synthesized via autoformalisation of natural language mathematical problems (using Goedel-Autoformaliser-v2), explicit error-driven rubric-guided simplification, and multi-source data selection. The hard tier is drawn from curated competition-level sources (Big-Math Olympiads, AIME, AMC, etc.), ensuring coverage over non-routine formal argumentation.
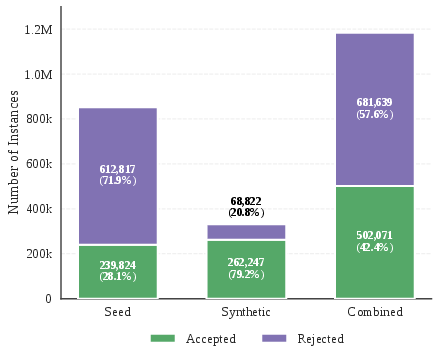
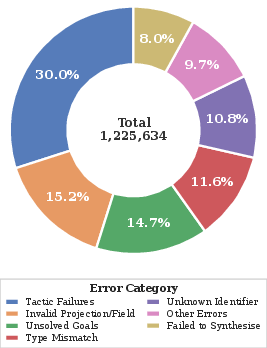
Figure 1: Instances accepted/rejected in Lean verification per data source and tier, showing efficacy of multi-stage filtering and synthetic augmentation.
To expand the verified corpus without linearly scaling formal verification cost, ALF produces, per instance, five variants across: simplification, generalization, lemma proposal, proof-step decomposition, and reformulation. Variants are proof-populated via self-distillation (using post-RL Pythagoras-Prover generations), passing only a lightweight consistency check instead of expensive Lean validation. Empirically, 87.8% of random sampled ALF instances pass Lean verification, demonstrating high-fidelity augmentation.
Curriculum SFT, Dynamic Filtering, and RL
Model training follows a curriculum SFT schedule by difficulty, initializes with parameter-efficient LoRA, and deploys a dynamic reasoning-proof filter to fit within an 8k-token context. Reinforcement learning (GRPO) is employed on held-out competition problems; however, SFT already extracts dominant proof-search capabilities, resulting in marginal RL gains (quantified in ablation).
Diffusion Theorem Prover
Pythagoras-Prover-Diffusion employs block-wise masked discrete diffusion and a tactic-level masking process, enabling non-sequential denoising steps. This model is the first demonstration of viable, scalable, and efficient diffusion-based formal proof generation for Lean.
Experimental Results
MiniF2F and PutnamBench
On MiniF2F-Test, Pythagoras-Prover-4B (86.1\% at pass@32) outperforms DeepSeek-Prover-V2-671B by $3.7$ points using 167× fewer parameters. Pythagoras-Prover-32B (93.0\% at pass@2048) achieves the best open-weight result, exceeding Goedel-Prover-V2-32B at a quarter of the inference budget and without reliance on self-correction or test-time RL.
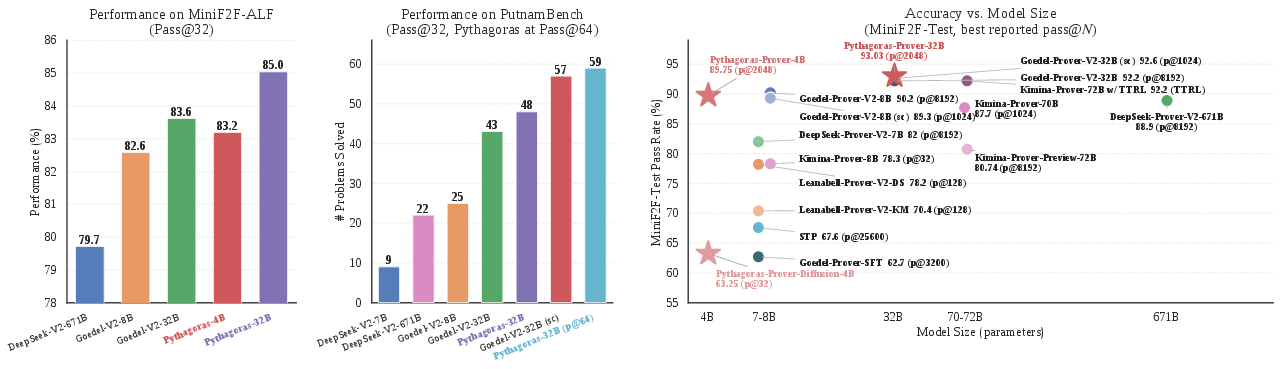
Figure 2: Prover performance across MiniF2F-ALF and PutnamBench under limited inference budgets, highlighting Pythagoras-Prover’s advantages at all model and compute regimes.
On PutnamBench, Pythagoras-Prover exhibits robust scaling with inference budget: at pass@2048 it solves 93/672 problems, outperforming all open-source systems including those with heavy reliance on self-correction loops.
Robustness: The MiniF2F-ALF Benchmark
MiniF2F-ALF evaluates transfer to ALF-mutation-induced distribution shifts. Across provers, accuracy universally decreases, but Pythagoras-Prover degrades less than other state-of-the-art models. At 32B, it remains on top (85.0% pass@32); at 4B, accuracy (83.2%) rivals the much larger Goedel-Prover-V2-32B.
Scaling and Efficiency Analysis
Ablation studies and scaling curves show Pythagoras-Prover saturates pass rates at smaller budgets with steeper efficiency, internalising proof search behaviours that allow fewer samples and more reliable reasoning. Effective token complexity analysis demonstrates restart sampling to be substantially more compute-efficient than history-accreting self-correction methods, especially as sequence length grows.
Diffusion Versus Autoregressive Decoding
Pythagoras-Prover-Diffusion achieves 63.3\% on MiniF2F-Test at pass@32, lagging behind its autoregressive counterpart (86.1\%) but generating 2.6× more tokens per GPU-second, positioning it as optimal under strict latency or wall-clock constraints.
Theoretical Insights, Implications, and Future Directions
Pythagoras-Prover demonstrates that rigorous Lean theorem proving can be decoupled from sheer scale, provided that high-quality, curriculum-stratified, and mutation-augmented data curation is in place. The use of ALF allows efficient expansion into otherwise data-starved corners of the formal mathematics regime, enhancing generalisability and robustness to controlled benchmark perturbations. The results indicate that current benchmarks are close to saturation and that diagnostic power is now best gained through contamination-sensitive mutation-based suites (e.g., MiniF2F-ALF).
From a practical standpoint, Pythagoras-Prover makes formal theorem proving accessible to researchers without frontier-scale compute, as world-leading results can be achieved with models as small as 4B parameters. The computational and methodological paradigm shift towards data-centric and curriculum-driven pipelines, as opposed to pure scale, will likely underpin the next generation of open-source formal theorem provers.
On the theoretical side, the diffusion-based prover opens a new axis of research into decoding regimes that prioritise random-access, parallel, and iterative refinement during proof search. Once long-context stability in diffusion models is resolved, such approaches may further erode the dependence on strictly sequential, autoregressive inductive biases currently dominant in formal reasoning models.
Conclusion
Pythagoras-Prover establishes new state-of-the-art results for open-weight Lean provers at radically reduced compute and parameter budgets. The integration of ALF for large-scale statement mutation, self-distillation, and curriculum-mandated training yields provers that are robust, efficient, and transferable—a paradigm expected to catalyze both further advancements in formal reasoning systems and more inclusive access to advanced mathematical automation tools. Future work in diffusion, richer data mutation, and adversarial benchmark construction will push formal theorem proving beyond traditional capacity and robustness limits.