- The paper introduces an agentic proving policy that leverages retrieval-enhanced, feedback-conditioned multi-round iterative proof repair to significantly improve Lean theorem proving performance.
- It constructs a trajectory-level Lean corpus (OProofs) and employs continuous post-training to integrate new verified proofs with repair signals.
- Empirical evaluations across multiple benchmarks demonstrate that combining retrieval and detailed compiler feedback leads to notable improvements in Pass@32 metrics.
Introduction
OProver introduces an integrated agentic formal theorem proving framework for Lean 4 that fundamentally reconfigures both data construction and training procedures. The system unifies retrieval, compiler feedback, and iterative proof repair, aiming to mitigate the train-inference divergence afflicting prior approaches, where retrieval and environment feedback are mostly deployed as inference-time heuristics rather than incorporated into the prover's policy during training. The central contribution is the agentic proving policy trained end-to-end to execute bounded multi-round refinement, leveraging retrieved compiler-verified proofs and Lean diagnostics at each iteration. This approach constructs OProofs, a large-scale trajectory-level Lean corpus, and couples model performance with evolving data quality through iterative post-training and corpus recirculation.
Unified Agentic Proving Framework
OProver formalizes agentic proving as a multi-round loop wherein the policy π conditions on the target statement s, retrieval memory Rt (top-k relevant compiler-verified proofs), previous proof attempt pt−1, and Lean feedback ft−1. At each round, the policy generates a revised proof attempt, which is verified by Lean. The process terminates upon successful verification or exhaustion of the round budget. Critically, the interaction state is kept compact, conditioning only on the most recent attempt and feedback, facilitating targeted repair and preventing excessive prompt growth. Retrieval memory is indexed from OProofs and expanded continuously during post-training.
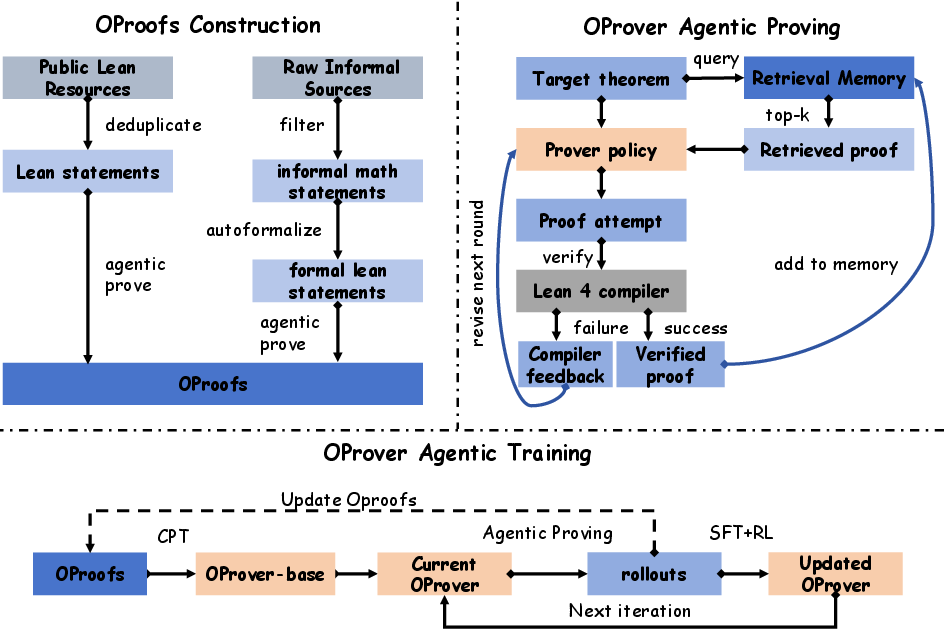
Figure 1: Structural overview of OProver, illustrating OProofs Construction, agentic proving with retrieval/feedback, and agentic training with CPT, SFT, RL, and data recirculation.
Compiler feedback is provided in raw textual form rather than categorical abstraction, ensuring fine-grained failure diagnostics are utilized directly for proof revision. Retrieval augmentation exposes reusable lemma and tactic structures from related contexts without rigid template constraints, increasing proof flexibility. This synergy between feedback and retrieval is integral to OProver's robustness across diverse theorem types.
OProofs: Corpus Construction and Characteristics
OProofs delivers a trajectory-level Lean corpus, superseding traditional datasets restricted to final verified proofs. The corpus comprises 1.77M unique Lean statements, 6.86M compiler-verified proofs, 1.07M agentic proving trajectories, and over 280K round-level repair supervised instances. Data is sourced from public Lean resources, large-scale proof synthesis (including autoformalization and compiler verification), and ongoing agentic proving traces. Each trajectory records retrieved context, failed attempts, feedback, and subsequent repairs, supporting both supervised and RL objectives. Domain and difficulty annotation is performed via LLM classification, establishing coverage in Algebra, Analysis, Number Theory, Geometry, and supporting domains; difficulty tiers span Elementary to GraduatePlus.
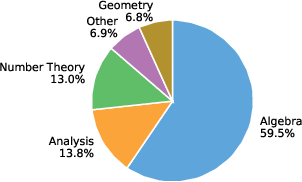
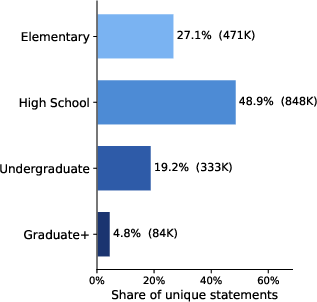
Figure 2: Corpus overview summarizing unique statements, proofs, trajectory repair instances, domain distribution, and difficulty levels.
Crucially, OProofs is not static. As OProver advances, newly verified proofs and repair traces are continuously assimilated, building data recirculation into the iterative post-training pipeline. This co-evolution paradigm is essential for sustaining improvements in both retrieval context and supervision signal.
Training Pipeline: Continued Pretraining and Iterative Post-Training
OProver is initialized via continued pretraining (CPT) on a 65B-token mixture emphasizing Lean formal data (from OProofs), code corpora, mathematical reasoning datasets, and chain-of-thought expansions, resulting in a domain-adapted OProver-Base. Iterative post-training alternates agentic proving rollouts, supervised fine-tuning (SFT) on repair trajectories, and RL via Group Sequence Policy Optimization (GSPO) with group-relative normalization. Newly verified proofs enhance OProofs and the retrieval memory, with harder unresolved cases feeding RL signal.
Supervised fine-tuning leverages explicit round-level repair supervision, strictly matching training and deployment interfaces. Reinforcement learning optimizes group-wise advantages, pooling rounds from multiple rollouts on each theorem, permitting cross-comparative credit assignment. The training interface and reward formulation are tuned for maximal compatibility with agentic interaction.
Empirical Evaluation and Results
OProver is evaluated on five Lean 4 theorem-proving benchmarks: MiniF2F, MathOlympiadBench, ProofNet, ProverBench, PutnamBench. Comparisons include state-of-the-art open-weight reasoning models (DeepSeek-V3.2, Kimi-K2.5) and open-weight formal provers (Goedel-Prover-V2, LongCat-Flash-Prover).
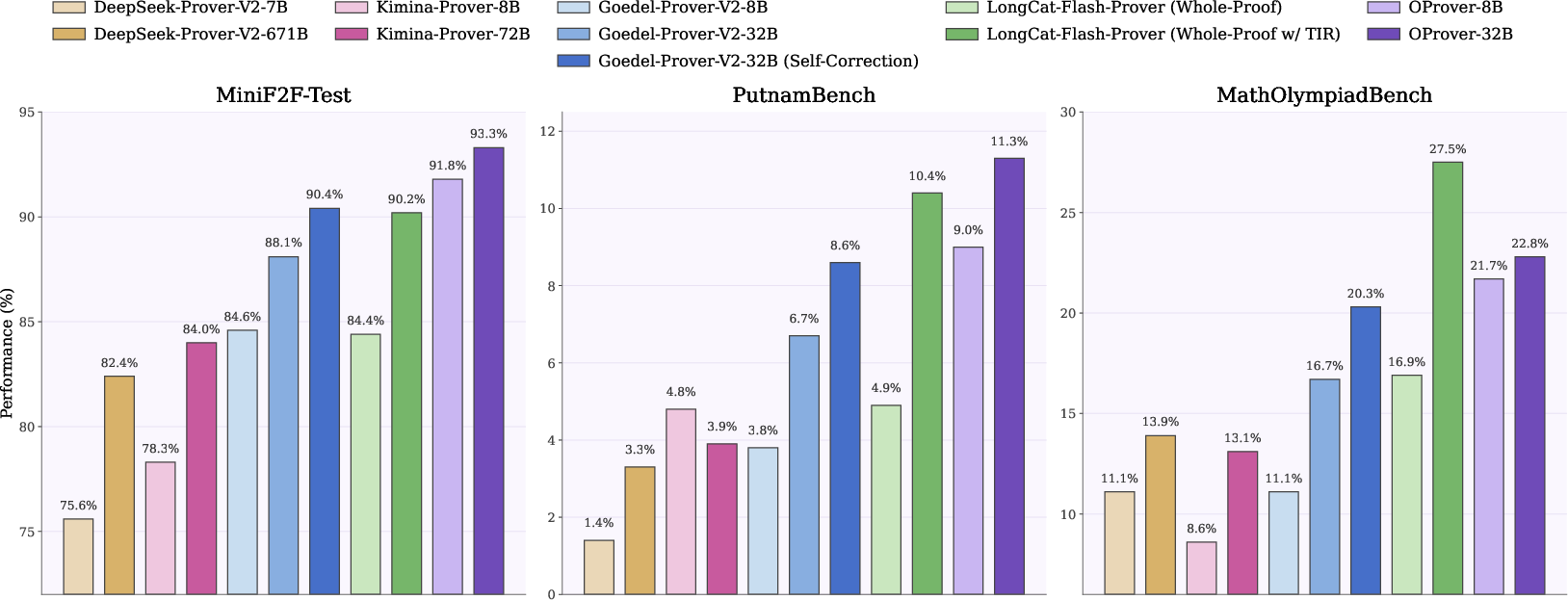
Figure 3: Pass@32 performance comparisons on MiniF2F-Test, PutnamBench, and MathOlympiadBench, with OProver achieving consistent state-of-the-art or near state-of-the-art results.
OProver-32B attains the highest Pass@32 in MiniF2F (93.3%), ProverBench (58.2%), and PutnamBench (11.3%), and ranks second in MathOlympiadBench (22.8%) and ProofNet (33.2%), outperforming models with significantly greater parameter counts (e.g., LongCat-Flash-Prover, DeepSeek-Prover-V2). The performance edge is not model scale-driven; instead, it arises from integrated retrieval, feedback-conditioned multi-round repair, and process-level post-training. Even OProver-8B surpasses Goedel-Prover-V2-32B, demonstrating scalability of the method.
OProver's capacity to benefit from increased test-time compute is confirmed by consistent improvements in BestPass at fixed budget B, with diminishing marginal returns as budget grows, and clear benchmark-dependent allocation optima between refinement depth and sampling width.
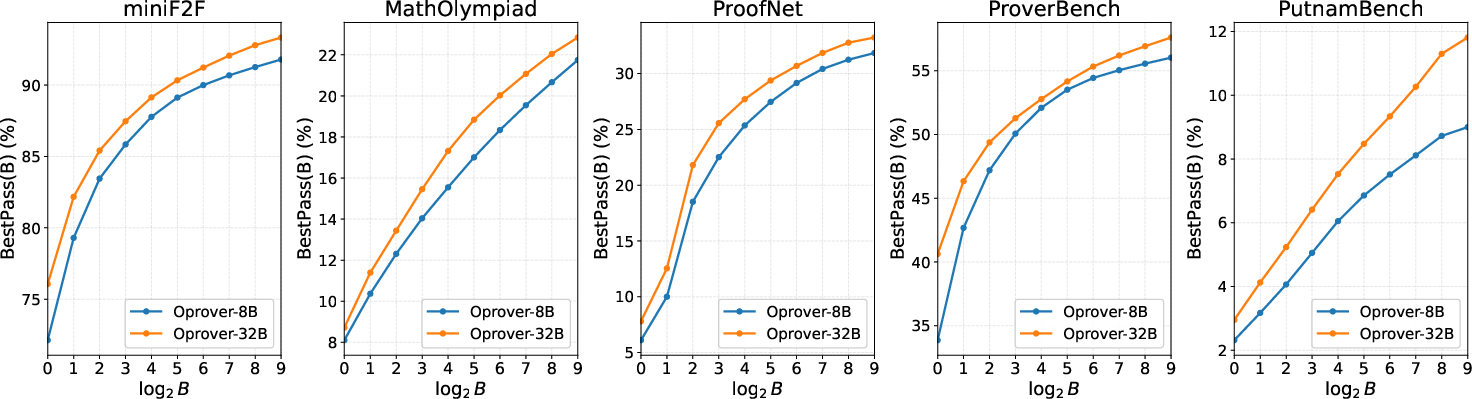
Figure 4: OProver test-time performance scaling under fixed compute budget B, showing monotonic gains with increased resources and diminishing returns at higher B.
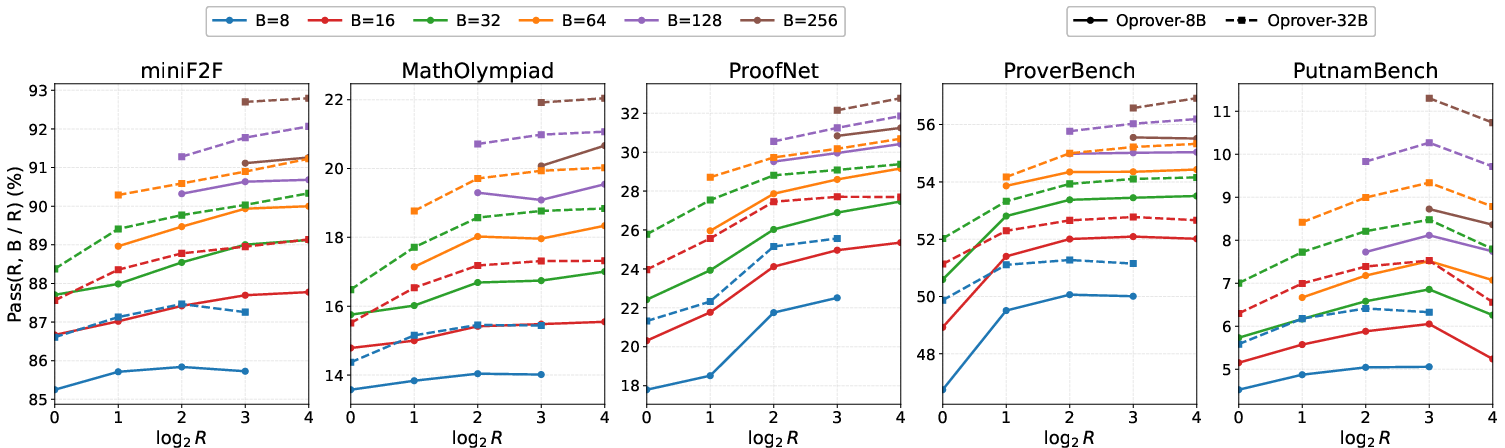
Figure 5: Performance tradeoff between refinement depth R and sampling width under fixed total budget, illustrating benchmark-specific allocation optima.
Iterative post-training yields monotonic improvements per iteration, confirming that continued infusion of newly verified proofs and agentic repair traces directly augments proving capability.
Component Ablation: Feedback and Retrieval
Ablation studies evidence the dominant role of multi-turn compiler feedback in driving performance, with retrieval providing additional gains. Removing feedback consistently degrades Pass@32 by 5--8 points across benchmarks and model sizes; further removing retrieval yields incremental drops (~1--2 points). The combined results confirm that OProver's improvement arises from the synergy of retrieval-augmented grounding and feedback-conditioned iterative repair, not single-round sampling.
Implications and Future Directions
OProver substantiates the theoretical pragmatic benefits of agentic proving, trajectory-level process supervision, and co-evolutionary training. The framework demonstrates scalability on formal mathematics benchmarks and establishes retrieval and feedback conditioning as essential for robust proof search and repair. On the theoretical side, OProofs serves as an archetype for process-level formal corpora, bridging the gap between static proof artifacts and dynamic interactive supervision.
Practically, OProver's unified policy, with recirculating agentic training loops, presents a scalable approach for enhancing formal theorem proving in Lean and other proof assistants. The methodology invites further study into abstraction-aware retrieval, multi-agent collaboration in agentic proving, and full-cycle formal-mathematical data synthesis pipelines. As iterated refinement and feedback integration matures, future AI systems may better approximate expert-level mathematical reasoning with verifier-grounded reliability.
Conclusion
OProver delivers a comprehensive agentic formal theorem proving framework for Lean 4, unifying retrieval, feedback, and iterative repair within training and inference. By constructing the OProofs corpus with trajectory-level supervision and enabling co-evolution between data and policy, OProver advances formal reasoning performance and scales test-time efficiency robustly. Empirical results validate the framework across diverse benchmarks, and ablation studies reinforce the criticality of agentic refinement and retrieval grounding. The architecture and corpus establish a foundation for further advances in proof-oriented AI, formal verification, and automated mathematical reasoning.

