Beyond representational alignment with brain-guided language models for robust reasoning
Abstract: The correspondence between LLMs and the neural mechanisms underlying human higher-order cognition remains insufficiently characterized. Given that language and reasoning in the human brain appear dissociable, an open question is whether LLMs align with neural signals from reasoning-related regions and whether such signals can improve them. Here, focusing on deductive reasoning, we show that LLM internal representations are not only partially aligned with task-fMRI activity but can also be directly enhanced by these signals. Using a neural-predictivity metric, we find that LLMs explain a substantial fraction of the explainable variance in reasoning-related regions at the aggregate level, whereas predictivity within specific reasoning types is lower, indicating both alignment and divergence. Building on this, we propose a brain-guided framework: we steer model representations along directions induced by the joint structure of model and brain representations, applying intervention at inference and fine-tuning during training. We demonstrate that task-evoked brain signals can directly enhance LLM reasoning, yielding gains orthogonal to language-only supervision across 10 LLMs (1.5B-72B), with transfer across reasoning types and up to 13\% absolute accuracy gain. Our results advance LLM-brain correspondences from correlation to guidance, establishing a brain-signal-driven pathway toward more robust and cognitively aligned AI.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Beyond representational alignment with brain-guided LLMs for robust reasoning — Explained simply
1) What is this paper about?
This paper asks a big question: can we use real human brain signals to help AI think more reliably? The authors study how LLMs handle logical puzzles and whether guiding them with brain activity from people solving the same puzzles can make the models better at reasoning.
2) What questions were the researchers asking?
They focused on three simple, important questions:
- Do today’s LLMs internally “think” in ways that resemble how the human brain works during logical reasoning?
- If there is some similarity, can brain activity actually guide and improve a model’s reasoning, not just match it?
- Will this brain-guided help make models more robust—so they do better on new or slightly changed logic problems, not just the ones they’ve seen?
3) How did they do the study?
To answer these questions, they brought together three things: brain scans, LLMs, and carefully designed logic problems.
Here’s the setup, explained in everyday terms:
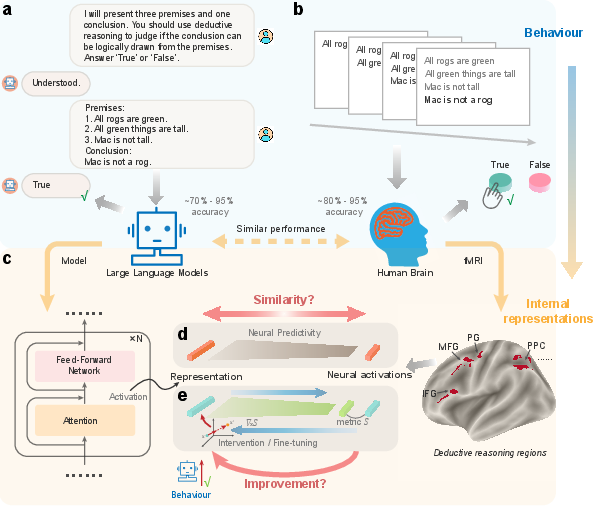
- The brain data: They used fMRI, a brain scanning method that measures changes in blood flow linked to brain activity. Think of it as a slow-motion “heat map” showing which brain areas light up when people think. In the study, people solved deductive logic problems (like “All A are B…” or “If A is taller than B, and B is taller than C, then…”), while their brain activity was recorded.
- The LLMs: They tested 10 modern LLMs, from small to very large ones. Each model got the same logic problems as the people did and had to answer True/False.
- Comparing brain and model “thoughts”: The team looked inside the models’ hidden layers—the internal steps models use to go from input to answer. Then they used a simple math tool (like a translator) to see how well those hidden model patterns could predict the brain activity patterns. This measure is called neural predictivity—think of it as a score for “how much the model’s internal signals line up with the brain’s signals.”
- Brain-guided steering:
- NARI (Neural Activation guided Representation Intervention): At answer time, they gently nudged the model’s internal signals in the direction suggested by the brain data—like giving a steering correction to a car that’s drifting off the road.
- NARF (Neural Activation guided Representation Fine-tuning): They trained the model’s internal steps to more closely follow the brain-guided directions—like coaching a player in practice so they move better during the game.
To make this clearer, here are the key steps they took:
- They mapped model signals to brain signals using a simple linear “translator.”
- They computed a direction to push the model’s internal state toward brain-like patterns for reasoning.
- They applied this either briefly at test time (NARI) or baked it into the model through training (NARF).
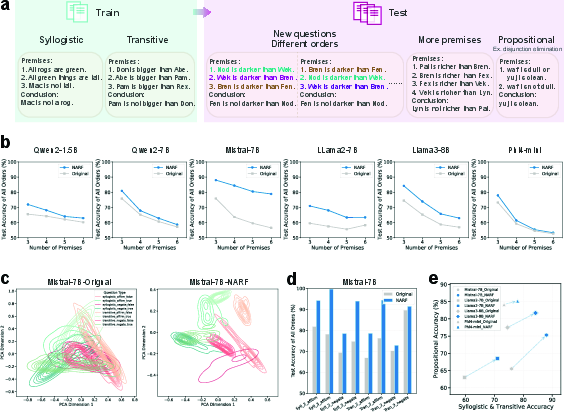
- They tested not only on the original problems, but also on new versions with shuffled premise order, more steps, and even a different kind of logic (propositional reasoning, like “If P then Q”).
4) What did they find, and why does it matter?
The main findings are both scientific (about brains and models) and practical (about making AI better):
- Partial alignment between models and human reasoning in the brain:
- The models’ hidden signals matched a large portion of the brain activity in regions known for logical thinking (not just language areas). In simple terms: LLMs don’t only “speak”—they also show some signs of logic-like processing inside.
- However, the match was not perfect, and it was weaker when looking at specific types of reasoning one by one. So there’s overlap, but also clear differences.
- Brain signals can directly improve model reasoning:
- NARI (steering at answer time) could flip wrong model answers to right ones by gently nudging internal signals in brain-guided directions. This worked across different models and even transferred to new, unseen problems.
- NARF (training with brain guidance) made models more robust. After training, they handled:
- Shuffled order of premises
- Problems with more steps
- A different type of logic (propositional reasoning)
- The gains were meaningful—up to about 13 percentage points better accuracy in some cases.
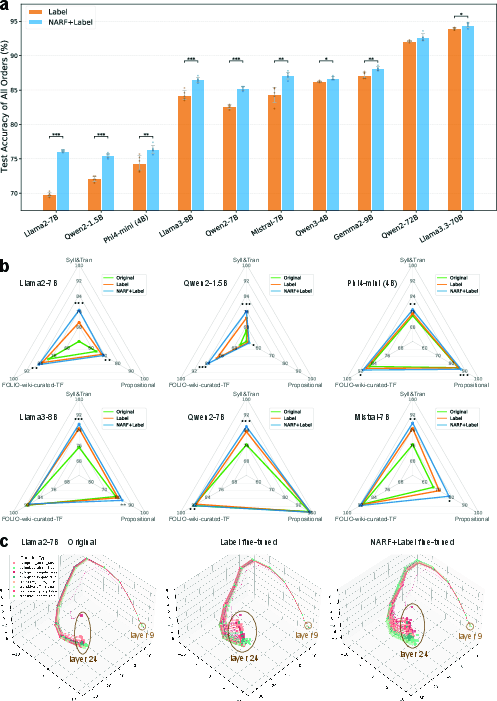
- Brain guidance adds something new beyond language-only training:
- When they combined ordinary “learn-from-text” training with brain-guided training, performance improved more than with text-only training.
- Brain-guided training seemed to shape the model’s internal “thinking path,” not just the final answer, which helped it generalize better to new situations.
- It’s not a one-off: They also showed similar benefits using a different brain dataset about relational reasoning, suggesting the approach is flexible.
Why this matters: It moves the field from just noticing that models and brains sometimes look similar (correlation) to actually using brain signals to make models think better (guidance). That’s a big step toward AI that reasons more like people do and works more reliably on new kinds of problems.
5) What’s the bigger picture?
This research suggests a new way to train thinking machines: don’t only teach them through words and answers; also guide their inner process using patterns from the human brain. If expanded, this idea could help:
- Build AI that’s better at robust reasoning, not just memorizing patterns.
- Create training methods that combine “what to answer” (language labels) with “how to think” (brain-guided internal signals).
- Explore other mental skills with clear brain networks—like social reasoning (theory of mind)—and see if brain-guided training helps there too.
A note on limits and future steps:
- fMRI is slow and gives a broad view of brain activity; faster brain measurements (like EEG or MEG) might allow even finer guidance of step-by-step reasoning.
- The study tested mid-sized to large models on carefully designed logic tasks; many more brain datasets and tasks could make the approach even stronger.
In short: The paper shows that human brain activity can be used not just to study AI, but to actively teach AI better reasoning. It’s a promising path toward smarter, more human-aligned systems.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, concrete list of what remains missing, uncertain, or unexplored in the study, framed to guide actionable future research.
- Limited neural modality and temporal resolution: fMRI’s slow hemodynamics prevented analysis of fast, step-by-step reasoning dynamics (e.g., chain-of-thought). Test NARI/NARF with high-temporal-resolution signals (MEG/EEG/ECoG) and align interventions to token-level or step-level trajectories.
- Small and narrow fMRI dataset: Only 10 usable subjects and 70 deductive problems (syllogistic/transitive), which constrains encoder training (∼56 training trials per split). Collect larger, richer reasoning datasets with more trials per type and subjects to improve mapping stability and ceiling estimates.
- Task scope is basic and structured: Experiments focus on relatively simple, pseudoword deductive tasks; generality to richer, open-ended reasoning (e.g., math proofs, program synthesis, scientific inference, analogical/spatial reasoning, multi-step planning) is untested.
- Representation-level mapping is linear: The brain-to-model encoder uses ridge regression; it is unknown whether non-linear mappings (e.g., kernels, deep encoders) yield better predictivity and stronger guidance.
- Token and layer selection is restricted: The study focuses on last-token hidden states and mid-layer/attention-module representations. It remains open how multi-token aggregation, earlier or later layers, or specific heads/neurons contribute to predictivity and guidance.
- Within-type alignment is modest: Ceiling-normalized predictivity within reasoning types is ∼27%, indicating sizable divergence. Identify which representational features are misaligned and how to target them for larger within-type gains.
- Region-of-interest (ROI) constraints: Analyses use pre-defined ROIs (reasoning, MD, language). Whole-brain, searchlight, or data-driven parcellations could reveal overlooked regions or more precise subregions driving alignment/gains.
- Subject variability is underexplored: Intervention success varies across subjects; mechanisms of model–subject coupling are unclear. Develop subject-agnostic templates, quantify how individual brain differences affect directions, and assess whether personalized vs. pooled guidance works best.
- Robustness of control baselines: “Random signals” and “random directions” are used, but stronger controls (e.g., stimulus-shuffled fMRI, phase-randomized time courses, cross-subject misalignment) are needed to rule out residual confounds.
- Generalization beyond pseudowords: While pseudowords reduce semantic confounds, applicability to naturalistic semantics (real words, pragmatic contexts) and ecologically valid tasks remains unknown.
- HCP modality mismatch: The HCP relational task uses images for humans and text descriptions for models; modality translation may change cognitive processes. Validate with neural data collected from matched text-based relational tasks.
- Scalability to frontier LLMs: NARI sometimes fails when few errors remain (near-ceiling models). How to learn intervention directions when errors are scarce (e.g., via synthetic counterfactuals, self-contrastive signals, or uncertainty-targeted sampling)?
- Stability and safety of interventions: Representation steering can be unstable; systematic analysis of perturbation ranges, convergence, unintended side effects on unrelated capabilities, and long-horizon generation stability is missing.
- Negative transfer and catastrophic side effects: NARF improves target reasoning but effects on other tasks/capabilities (language understanding, safety, calibration) are not measured. Conduct broad regressions and task batteries to detect trade-offs.
- Process supervision interplay: The synergy between neural-guided objectives and advanced process supervision (e.g., verifiers, tool use, synthetic chains) is not quantified. Establish how neural guidance complements or replaces process signals at scale.
- Mechanistic interpretability: Which neurons/heads/circuits are causally responsible for brain-guided gains is unknown. Perform causal ablations, probing, and sparse-feature analyses to identify mechanism-level changes induced by NARI/NARF.
- Cross-linguistic and cross-cultural generality: All experiments use English pseudowords. Test whether brain–model alignment and gains persist across languages and cultural backgrounds, and whether language-specific reasoning demands alter mappings.
- Mapping intercept and similarity choices: The paper notes better directions when excluding the encoder’s intercept in gradients but does not fully explain why. Systematically evaluate similarity functions, normalization schemes, and treatment of mean-shifts.
- Multi-region integration strategies: Signals from reasoning vs. MD vs. language areas show different effects, but optimal fusion (e.g., learned region weights, task-conditional routing) is unexplored.
- Causal role of brain regions: Region specificity is suggestive but not causal. Test whether perturbing model features aligned to specific ROIs (or using targeted neural signals) selectively modulates distinct reasoning subskills.
- Data efficiency and compute costs: The paper does not quantify the sample efficiency of NARF vs. label-only fine-tuning or the compute overhead of brain-guided training. Benchmark data/compute trade-offs and identify low-cost protocols.
- Privacy and ethics of brain-guided AI: Using human neural data raises privacy and consent issues; frameworks for anonymization, federated training, and ethical deployment are not addressed.
- Broader out-of-distribution testing: Beyond premise permutations/more premises, evaluate robustness to adversarially constructed logic, linguistic perturbations (syntax, negation, quantifiers), and domain shifts (e.g., scientific/logical curricula).
- Chain-of-thought models at scale: NARI was tried on one small “thinking” model. Whether brain-guided steering can shape token-by-token reasoning in large CoT models (and improve faithfulness/consistency) remains open.
- Longitudinal and reproducibility concerns: Results rely on a single preprocessing pipeline and split strategies. Assess robustness across preprocessing choices, alternative noise ceiling estimations, and multiple lab datasets.
- Benchmarking against other steering methods: Compare brain-guided steering to representation engineering alternatives (e.g., sparse autoencoders, linear steering vectors from behavior, activation patching) on the same tasks and metrics.
- Toward practical deployment: fMRI-based guidance is impractical at scale. Develop surrogate neural targets (e.g., learned “neural priors,” synthetic neural generators) that capture core structure without requiring new fMRI collection.
Practical Applications
Immediate Applications
Below are actionable use cases that can be deployed now or piloted with currently available resources and open-source tools. Each item notes sectors, potential tools/workflows, and key dependencies.
- Brain-guided reasoning boosters for open-source LLMs — software/AI, enterprise AI
- Use case: Integrate NARI (inference-time steering) and NARF (representation-level fine-tuning) into mid-size open LLMs (1.5B–70B) to reduce simple logic errors and improve out-of-distribution generalization on rule-based tasks (e.g., policy compliance checks, contract logic consistency, internal QA on rule-driven agents).
- Tools/workflows:
- “LogicGuard” plug-in that applies precomputed, subject-aggregated steering directions to middle-layer attention representations during inference on logic-heavy prompts.
- “Cognitive-Alignment Regularizer” that co-optimizes cross-entropy with NARF’s neural-similarity objective during fine-tuning.
- Dependencies/assumptions: Requires access to intermediate activations and weights (open models); generalized steering directions derived from public fMRI (no user neurodata at deployment); validated primarily on pseudoword-based deductive tasks and FOLIO—careful evaluation needed before use in high-stakes domains.
- Cognitive alignment metric for model selection — software/AI, academia, policy
- Use case: Add “NeuroScore for Reasoning” (ceiling-normalized neural predictivity in reasoning ROIs) to model evaluation dashboards to select among checkpoints/fine-tunes for agents that require robust logic.
- Tools/workflows: Batch compute ridge-encoding predictivity using open fMRI datasets; report by region (reasoning vs. language vs. MD network) and layer.
- Dependencies/assumptions: Public task-fMRI datasets suffice for initial scoring; assumes alignment correlates with generalization; compute and data governance for neurodata handling.
- Benchmarking suites that probe reasoning beyond language-only supervision — academia, software/AI
- Use case: Release “NeuroBench-Reasoning” combining: (i) neural predictivity tests, (ii) logic generalization under premise permutations and increased premises, (iii) cross-type transfer (e.g., to propositional logic, FOLIO).
- Tools/workflows: Provide code to learn W matrices per layer, generate steering vectors, and run ablations (Random Signals, Random Directions).
- Dependencies/assumptions: Works best with mid-layer attention features; replicates shown across multiple LLM families.
- Safer reasoning for rule-based agents — finance, legal, compliance, operations
- Use case: Apply NARF+label fine-tuning to internal assistants performing policy application, entitlement checks, or rules-based triage, reducing false logical inferences without changing base agent workflows.
- Tools/workflows: Fine-tune with NARF on synthetic syllogistic/transitive datasets and internal rule corpora; add inference-time checks with light NARI nudges when uncertainty is detected.
- Dependencies/assumptions: Internal evaluation must confirm gains on domain-specific rules; improvements are orthogonal to language-only training but require careful calibration and monitoring.
- Improved logic tutoring and formative assessment — education, edtech, daily life
- Use case: Deploy brain-guided fine-tuned tutors that better identify valid/invalid conclusions in logic exercises, including novel combinations and reordered premises, supporting students’ learning of reasoning patterns.
- Tools/workflows: NARF+label fine-tunes on pseudoword logic problems; add item-generation pipelines that vary premise order and count to assess transferable reasoning.
- Dependencies/assumptions: Gains demonstrated on structured deductive logic; must validate on real curriculum content and languages; avoid over-claiming human-likeness.
- Research pipelines for cognitive neuroscience — academia (cog neuro, NeuroAI)
- Use case: Use LLMs as computational models of deductive reasoning networks to test hypotheses (e.g., middle-layer alignment, reasoning-type selectivity), and to design new tasks minimizing semantic confounds.
- Tools/workflows: Encoding models from LLM layers to fMRI voxels; cross-type predictivity analysis; PCA visualizations of correct/incorrect subspaces pre/post steering.
- Dependencies/assumptions: Task-evoked fMRI datasets; reproducibility across subjects; ethical use and sharing of neural data.
- Model debugging and process-analysis tools — software/AI
- Use case: Inspect and compare “reasoning trajectories” across layers before/after NARF to diagnose where misreasoning emerges; use PCA/cluster separation of correct vs. incorrect internal states.
- Tools/workflows: Lightweight probes of attention outputs at 1/4–3/4 depth; visualization modules integrated with training logs.
- Dependencies/assumptions: Access to activations; careful interpretation to avoid spurious post-hoc narratives.
- Low-risk domain pilots for rule consistency — public sector, policy ops
- Use case: Pilot brain-guided models for non-critical rule consistency checking (e.g., administrative logic consistency, FAQ policy mapping) to study productivity impacts.
- Tools/workflows: NARF fine-tune on synthetic deductive tasks; add local policy templates for domain adaptation; deploy behind human-in-the-loop review.
- Dependencies/assumptions: No clinical/legal final-use decisions without oversight; clear governance for evaluation and rollback.
Long-Term Applications
These opportunities require further research, larger or different neural datasets, real-time signals, scaling studies, or regulatory maturation.
- Real-time neuro-steered reasoning with fast neural signals — healthcare, BCI, software/AI
- Use case: Replace/augment fMRI with MEG/EEG to derive temporally precise, step-level guidance for chain-of-thought reasoning and interactive assistants; explore closed-loop steering during multi-step reasoning.
- Tools/products: “NeuroCoT” modules that align stepwise representations to fast neural markers; closed-loop agent controllers.
- Dependencies/assumptions: High-SNR MEG/EEG datasets with aligned reasoning tasks; robust mappings at step resolution; privacy and clinical-grade data pipelines.
- Personalized cognitive alignment — healthcare, education, accessibility
- Use case: Subject-specific steering vectors to adapt LLMs to individuals’ reasoning patterns, potentially assisting users with cognitive impairments or tailoring logic instruction.
- Tools/products: “Personal NeuroProfile” generated from brief neuro-assessment sessions; adaptive tutoring or assistive communication tools.
- Dependencies/assumptions: Feasible, ethical collection of personal neural data; demonstrable benefit vs. aggregated directions; strong privacy safeguards; regulatory oversight for medical uses.
- Neuro-aligned verification for safety-critical AI — healthcare, aviation, autonomous systems, robotics
- Use case: Combine formal methods, unit tests, and neuro-alignment constraints to ensure planning/reasoning modules maintain logic consistency under distribution shift.
- Tools/products: “Neuro-Process Supervision” that enforces representation-level constraints during safety cases.
- Dependencies/assumptions: Evidence that neuro-guidance improves worst-case reliability; standards integration; large-scale validation on realistic tasks beyond pseudowords.
- Domain-general cognitive training signals for AI — software/AI, robotics, planning
- Use case: Expand beyond deductive logic to other cognitive faculties with identifiable networks (e.g., relational reasoning, theory of mind) to build multi-capability, neuro-guided agents.
- Tools/products: Multi-task NARF libraries spanning reasoning types; sector-specific curricula (planning, scheduling, mathematical proof hints).
- Dependencies/assumptions: Availability of task-evoked neural datasets for each faculty; robust transfer to naturalistic tasks; scalable training cost-benefit.
- Clinical and research tools for cognitive assessment — healthcare, academia
- Use case: Use model–brain representational alignment as a digital biomarker for reasoning function, aiding assessment of developmental trajectories or disorders; simulate effects of lesions or network dysfunction on LLM behavior.
- Tools/products: “NeuroAlign Score” dashboards for clinics/research; model-based perturbation studies linked to patient imaging.
- Dependencies/assumptions: Clinically validated correlations between alignment metrics and outcomes; rigorous trials; HIPAA/GDPR-compliant data handling.
- Standards and certification for neuro-aligned AI — policy, regulation, industry consortia
- Use case: Define certification pathways that include cognitive-alignment metrics and neuro-guided training evidence for AI used in regulated contexts.
- Tools/products: Reference datasets; procedures for ceiling-normalized predictivity; auditing toolkits.
- Dependencies/assumptions: Community consensus on metrics; public–private partnerships to curate datasets; ethical frameworks for neurodata.
- Advanced planning and control in robotics and operations — robotics, energy, logistics
- Use case: Apply neuro-guided reasoning to symbolic planning, constraint satisfaction, and schedule optimization under perturbations (e.g., grid operations, warehouse tasking).
- Tools/products: Planning modules trained with NARF on relational reasoning tasks; inference-time steering to avoid brittle logical failures.
- Dependencies/assumptions: Demonstrations on complex, real-world constraints; integration with continuous control; safety assurance.
- Privacy-preserving neuro-guidance at scale — software/AI, privacy tech
- Use case: Federated or synthetic-neurodata approaches to derive steering signals without exposing raw neural data; subject-agnostic generalized directions trained across institutions.
- Tools/products: Secure multiparty learning of W matrices and steering vectors; synthetic generative models of neural activation for reasoning tasks.
- Dependencies/assumptions: Methods to validate that synthetic/federated signals retain utility and privacy; institutional coordination.
- Neuro-guided curriculum learning and data efficiency — software/AI
- Use case: Use neural predictivity gaps to select training samples or generate data that maximally improves under-aligned layers/regions, reducing data/compute for reasoning improvements.
- Tools/products: “NeuroCurriculum” selector that targets model weaknesses indicated by brain-alignment diagnostics.
- Dependencies/assumptions: Reliable layer/region-level diagnostics generalize across tasks; evidence for improved sample efficiency.
Cross-cutting assumptions and dependencies (impacting feasibility)
- Access to task-evoked neural datasets: Current results rely on fMRI with slow hemodynamics and pseudoword logic tasks; broader, more naturalistic signals (MEG/EEG, multi-language, multi-domain) are needed for step-level guidance and generalization.
- Model access: NARI/NARF require intermediate activations and parameter updates; feasible for open-source models, not for closed APIs unless providers expose hooks.
- Generalization limits: Demonstrated gains center on structured deductive reasoning and selected benchmarks; careful transfer testing is required for domains with rich semantics or complex planning.
- Ethics, privacy, and governance: Any use of human neural data requires strict consent, anonymization, and compliance with regional regulations; deployment must avoid individual-level neurodata unless explicitly consented.
- Compute and engineering: Mapping and steering are lightweight at inference once precomputed, but training workflows add complexity; monitoring and rollback are needed to manage steering stability across inputs.
Glossary
- Attention module: The self-attention sublayer in a transformer that models dependencies among tokens by computing attention-weighted combinations of representations. "which processes inputs through successive layers comprising an attention module followed by a \ac{ffn} module"
- Autoregressive transformer: A transformer that predicts tokens sequentially (each token conditioned on all previous ones), commonly used for language modeling. "the calculation of each layer of autoregressive transformers is:"
- Basal Ganglia (BG): A group of subcortical nuclei involved in action selection, learning, and cognitive control; analyzed here as part of deductive reasoning regions. "left \ac{bg}"
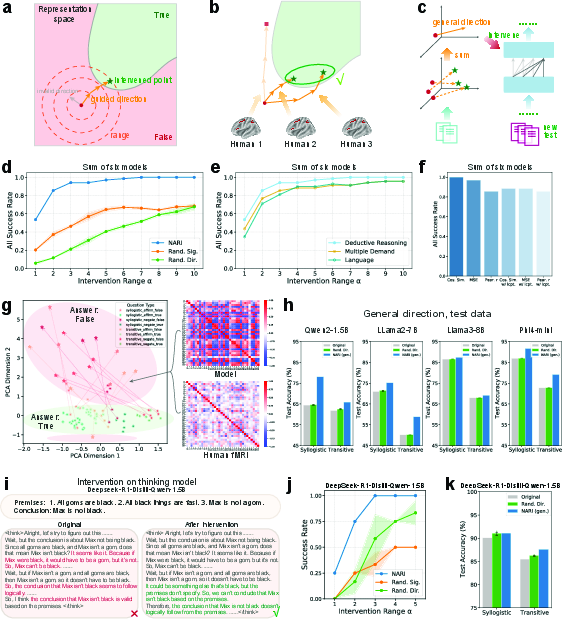
- Chain-of-Thought (CoT): A prompting or model approach that elicits intermediate reasoning steps in natural language before the final answer. "our demonstration on chain-of-thought models reveals promising directions for future work on more complex cognitive processes with slow thinking."
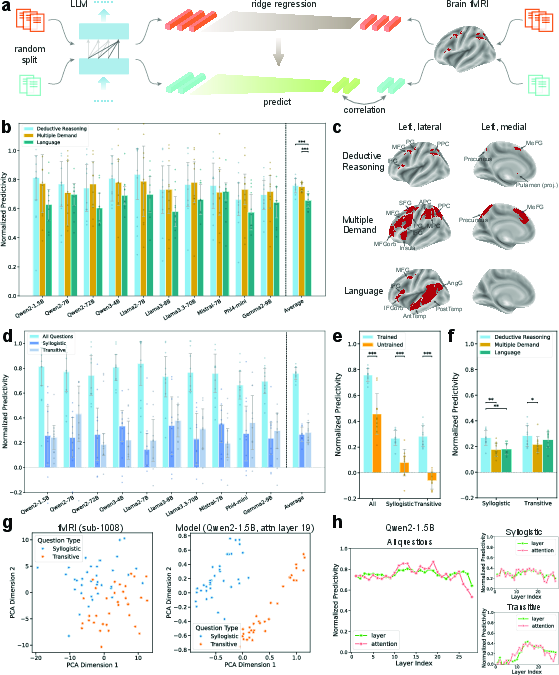
- Ceiling-normalized predictivity: A brain-model alignment metric normalized by an estimated upper-bound “ceiling” set by human–human predictivity, facilitating comparability. "Analyzing reasoning types separately, ceiling-normalized predictivity drops to 27\% for each type"
- Cross-entropy (CE): A loss function measuring the difference between predicted and true probability distributions, often used to train classifiers. "While standard language supervision optimizes final output tokens (e.g, cross-entropy on
True''/False'')" - Explainable variance: The portion of variance in neural data that can in principle be accounted for given measurement noise; used here to quantify model–brain correspondence. "we find that LLMs explain a substantial fraction of the explainable variance in reasoning-related regions"
- Feed-Forward Network (FFN): The position-wise nonlinearity sublayer in each transformer block that transforms token representations after attention. "comprising an attention module followed by a \ac{ffn} module"
- FOLIO dataset: A benchmark of first-order logical inference problems expressed in natural language, used to assess reasoning generalization. "including generated propositional problems and the FOLIO dataset~\cite{han2024folio}"
- Functional localization: Identifying subject-specific brain regions engaged by particular cognitive functions using task contrasts. "We imitate participant-specific functional localization~\cite{fedorenko2010new} to specify locations for each human subject."
- Functional magnetic resonance imaging (fMRI): A neuroimaging technique that infers neural activity via blood-oxygen-level dependent signals; used here to obtain task-evoked brain responses during reasoning. "we show that LLM internal representations are not only partially aligned with task-\ac{fmri} activity but can also be directly enhanced by these signals."
- GLMSingle: A toolbox that fits single-trial general linear models to fMRI data to improve response estimates. "We use MATLAB, SPM12, and GLMSingle~\cite{prince2022improving} to preprocess \ac{fmri} data"
- Human Connectome Project (HCP): A large-scale neuroimaging initiative; here, its Relational Processing Task provides an external neural dataset for validation. "HCP Relational Processing Task from the Human Connectome Project~\cite{van2013wu}"
- Inferior frontal gyrus (IFG): A frontal cortical region implicated in language and cognitive control; included among reasoning-related ROIs. "left \ac{ifg}"
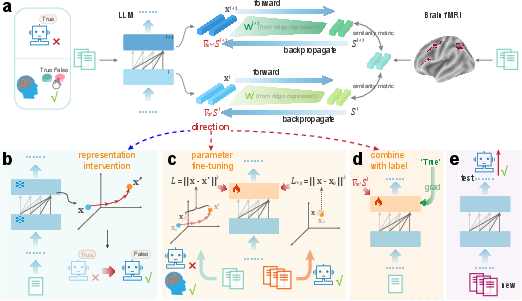
- Intercept term: The bias term in a linear model capturing mean shifts between source and target spaces; excluding it when computing gradients can improve representational steering. "Excluding the intercept term when computing gradients, which introduces a systematic shift in the direction, improves direction quality"
- Mean absolute deviation (MAD): A robust dispersion metric (median of absolute deviations from the median) used for error bars. "and then compute the median and \ac{mad} (as error bars) across participants."
- Medial frontal gyrus (MeFG): A medial frontal region associated with higher-order cognition; part of the deductive reasoning ROIs. "left \ac{mefg}"
- Middle frontal gyrus (MFG): A dorsolateral frontal region implicated in executive functions; included as a reasoning-related ROI. "bilateral \ac{mfg}"
- Multiple-demand (MD) network: A set of frontoparietal regions engaged across diverse cognitively demanding tasks; used as a comparison network. "\ac{md} regions support demanding cognitive tasks, including logical reasoning"
- Neural activation guided representation fine-tuning (NARF): Training that adjusts model parameters to align intermediate representations with brain-guided targets for improved reasoning. "We introduce two complementary methods---\ac{nari} and \ac{narf}---that directly incorporate task-\ac{fmri} signals from reasoning tasks into the model's latent representations."
- Neural activation guided representation intervention (NARI): An inference-time method that nudges internal representations along directions derived from model–brain similarity gradients to correct errors. "We apply \ac{nari} to the attention-module outputs in middle transformer layers (1/4-3/4 depth) at inference"
- Neural predictivity: The degree to which model representations can predict brain activity patterns, typically measured via encoding models and correlations. "We quantify model-brain correspondence using neural predictivity"
- Pearson correlation: A linear correlation coefficient used here to compare predicted and observed voxel responses. "The predictions are compared against the corresponding brain representations with a Pearson correlation."
- Posterior parietal cortex (PPC): A parietal region involved in spatial cognition and reasoning; included among reasoning ROIs. "bilateral \ac{ppc}"
- Precentral gyrus (PG): A frontal region (primary motor cortex area) included in the meta-analytic reasoning ROIs for completeness of coverage. "bilateral \ac{pg}"
- Principal component analysis (PCA): A dimensionality reduction technique used to visualize separation of reasoning types and answer spaces. "Visualization through \ac{pca} reveals that both \ac{LLM} and \ac{fmri} representations partially separate syllogistic from transitive problems"
- Pseudoword: A pronounceable, non-lexical string used to minimize semantic confounds in reasoning stimuli. "The dataset leverages pseudowords that minimize semantic and lexical confounds, providing a cleaner basis for comparing neural representations of reasoning with LLMs."
- Region of Interest (ROI): A predefined brain region analyzed for task-related activity or model predictivity. "Predictivity is assessed in reasoning ROIs~\cite{prado2011brain}"
- Ridge regression: A linear regression with L2 regularization used to map model representations to voxel responses. "we then fit cross-validated ridge regression models to predict voxel-wise \ac{fmri} responses from these representations"
- Representational alignment: The correspondence between internal model representations and brain activity patterns. "Beyond representational alignment with brain-guided LLMs for robust reasoning"
- Representation intervention: The process of directly modifying internal activations to steer model behavior during inference. "We first validate our approach through representation intervention experiments."
- SPM12: A software package for fMRI data preprocessing and analysis. "We use MATLAB, SPM12, and GLMSingle~\cite{prince2022improving} to preprocess \ac{fmri} data"
- Syllogistic reasoning: Deductive reasoning involving categorical premises about set inclusion leading to a conclusion. "syllogistic and transitive reasoning"
- Transitive reasoning: Deductive reasoning based on ordered relations (e.g., A > B, B > C implies A > C). "syllogistic and transitive reasoning"
- Voxel: A volumetric pixel representing a small 3D unit of brain imaging data; the basic unit for fMRI analysis. "voxel-wise \ac{fmri} responses"
Collections
Sign up for free to add this paper to one or more collections.

