SCAIL-2: Unifying Controlled Character Animation with End-to-end In-Context Conditioning
Abstract: Controlled character animation requires transferring motion from a driving sequence to a reference character. Prior works heavily rely on intermediate representations, including pose skeletons to represent motion or masked background to represent environment, which inevitably leads to information loss. To address this, we present SCAIL-2, an framework that bypasses those intermediates and achieves \textbf{end-to-end} character animation. By directly concatenating driving videos to the sequence, the model can obtain all the required visual information from the input video. To address lack of end-to-end data, we unify sub-tasks of character animation with decoupled conditions and then curate a pipeline to synthesize MotionPair-60K, an end-to-end motion transfer dataset containing heterogeneous tasks of character animation. To archive the unification, we utilize in-context mask conditioning and mode-specific RoPE as soft guidance beyond textual instructions and raw visual information. To address synthetic discrepancy in detailed regions, we propose Bias-Aware DPO to construct preference items to mitigate the errors. Extensive experiments demonstrate that our method substantially outperforms existing state-of-the-art approaches in various character animation tasks. A large subset of synthetic data as well as model weights will be released at our project page: https://teal024.github.io/SCAIL-2/.




Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces SCAIL-2, a new AI system that can “animate” characters in videos. Imagine you have:
- a short video of someone dancing (the “driver”), and
- a still image (or a frame) of a different character you want to move the same way (the “target”).
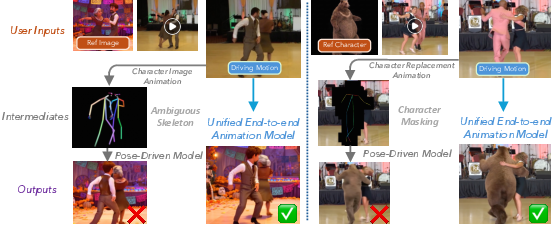
SCAIL-2 learns to copy the movement from the driver video and apply it to the target character, even when there are several characters, tricky interactions, or a different background. The key idea: instead of using simplified stick‑figure poses or cut‑out masks (which throw away detail), the model learns directly from full videos end‑to‑end.
What questions does it try to answer?
In simple terms, the paper asks:
- Can we animate characters by directly looking at full videos, without turning them into stick figures first?
- Can one model handle several related jobs at once, like:
- keeping the original background and just moving the target character (Animation Mode), or
- replacing the whole character into the driver’s scene (Replacement Mode)?
- How do we make this work well for multiple characters that interact, different body shapes, and even non‑human characters?
- Can we fix common “tiny detail” mistakes (like finger movements) that older methods often get wrong?
How did the researchers do it?
To keep things approachable, here are the main pieces and how they work, with everyday analogies.
The end‑to‑end idea (no stick figures)
Most older methods first turn the movement into a simple pose skeleton (like a stick figure), then animate from that. This throws away helpful details (like hand shape or who is in front during a hug). SCAIL‑2 skips that step. It looks at the full driver video alongside the target character picture and learns to transfer motion directly—like a skilled choreographer watching one dancer and teaching another without redrawing the moves.
Under the hood, it uses a video diffusion model (think of it like starting with TV static and gradually “denoising” it until a clean video appears), guided by the driver video and the reference character.
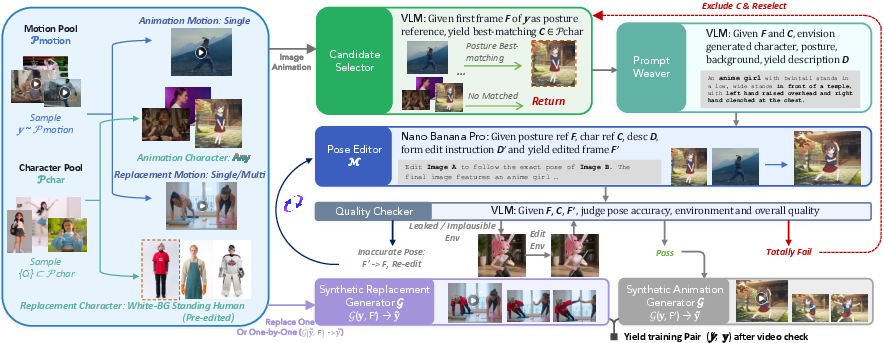
Creating training data when pairs don’t exist
Training needs many pairs of videos showing the same movement performed by different characters or settings. Those pairs are rare, so the team built them.
They use a “synthetic loop”:
- Take a real driver video (the movement you want).
- Use existing animation tools to generate a matching “fake” video of a different character doing the same move.
- Curate and refine the results with an automated assistant (it picks good character candidates, writes prompts, checks quality, and edits).
- Collect lots of these pairs into a dataset called MotionPair‑60K.
A clever twist called “reverse driving” helps avoid copying the fake video’s mistakes:
- Treat the fake video as the input (to tell the model the motion).
- Treat the original real video as the target the model should reconstruct. This way the model learns movement from the synthetic video but learns visual accuracy from the real one.
One model, many tasks: small hints that guide big behavior
SCAIL‑2 unifies different tasks with two lightweight signals added to the visual context:
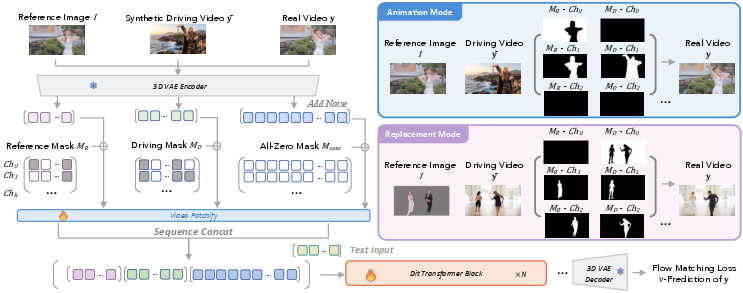
- In‑context mask conditioning:
- An environment switch (like a light switch) tells the model whether to keep the original background (Animation Mode) or to use the driver video’s background (Replacement Mode).
- “Binding slots” are like colored wristbands for each character. Characters with the same color are linked, so the model knows whose motion goes to whom. This prevents mix‑ups when characters cross or interact.
- Mode‑specific RoPE (positional hints):
- Think of “RoPE” as a way the model knows the “where and when” of video pieces.
- The model uses slightly different positional offsets for Animation vs. Replacement Mode, so it doesn’t confuse “regenerate the first frame” with “keep the driver’s first frame background.”
Together, these hints help the model read the full visual input while still staying focused on the right task.
Fixing tiny detail bias with preferences (Bias‑Aware DPO)
Some training videos (especially those made from poses) lose fine details like exact finger bends. To fix this, the authors build “preference pairs”:
- A “better” clip and a “slightly worse” clip that share the same overall move but differ in fine details (the worse one has an extra round of pose extraction, which often blurs finger accuracy).
- The model is trained to prefer the better one using a method called DPO (Direct Preference Optimization). In plain terms: it practices choosing the clip with more accurate tiny details.
What did they find?
Here are the main results in everyday language:
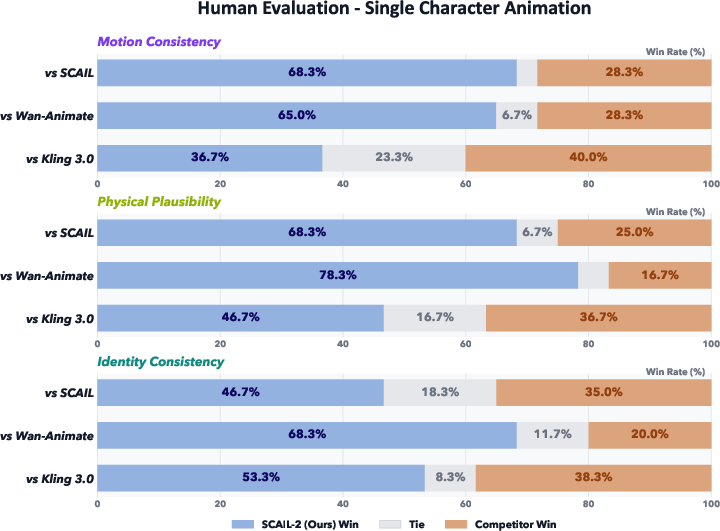
- It beats other leading open‑source methods on several tests, especially when:
- characters interact closely,
- body shapes are very different, or
- there are multiple characters.
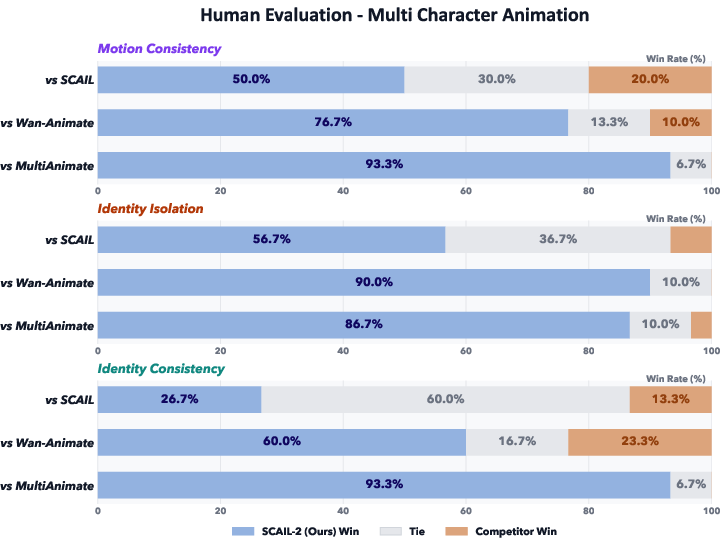
- It keeps character identities separate better (less “identity bleeding” when characters cross paths).
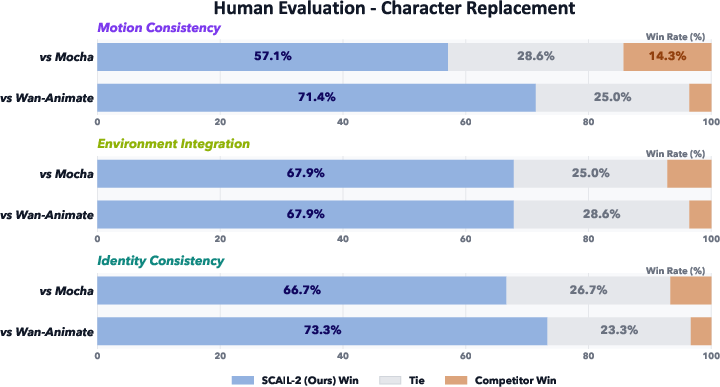
- Replacement Mode (putting the character into the driver’s scene) works more naturally than methods that “inpaint” holes in the background.
- Fine details improve—especially hands—after the Bias‑Aware DPO step.
- It generalizes well, even to cases the model didn’t see during training (zero‑shot), and can handle non‑human movers where pose‑skeletons fail.
- Video quality remains high across benchmarks.
Why it matters: skipping the stick‑figure step preserves subtle cues like occlusions, finger shapes, and object interactions (catching a ball, holding an instrument), which makes animations look more natural and believable.
What could this change or enable?
- Film, TV, and online creators could swap or animate characters more easily without perfect motion‑capture suits or manual editing.
- Multi‑character scenes with complex interactions (fights, dances, sports) become more achievable because the model reads full visual context.
- Game and virtual production teams can bring diverse characters (different bodies, clothes, even animals) into the same motion smoothly.
- The “unified” design means new features (like better hand or face movement) can be added without building a separate model for each task.
Limits and what’s next
- It still depends on lots of high‑quality paired data. The team made synthetic pairs, but the final quality is limited by the tools used to make them.
- Very fine details (like lip‑sync or subtle facial expressions) are still challenging.
- Future work could use better generators, smarter data curation, and targeted preference training for faces and speech to push realism further.
In short, SCAIL‑2 shows that learning animation end‑to‑end from full videos, plus a few well‑designed hints and a clever training pipeline, can produce more natural, flexible, and reliable character animation across many situations.
Knowledge Gaps
Unresolved Gaps, Limitations, and Open Questions
Below is a concise, actionable list of what remains missing, uncertain, or unexplored in the paper, intended to guide future research:
- Data realism and bias
- Quantify and reduce domain gap between synthetic MotionPair-60K and real paired data; measure how generator-specific artifacts (from SCAIL, MoCha, Wan-Animate) propagate into the end-to-end model despite reverse driving.
- Establish a standardized, publicly released, real-world paired benchmark (not only synthetic) for end-to-end character animation to validate generalization and avoid overfitting to synthetic priors.
- Analyze demographic and content biases introduced by the Candidate Selector/Prompt Weaver/VLM filter; report distributions (skin tone, body shape, age, clothing, lighting) and their effect on performance.
- In-context mask dependency and robustness
- Evaluate failure modes when SAM3 segmentation or rule-based character matching is inaccurate (low light, motion blur, occlusions, animals, costumes) and develop segmentation-agnostic or self-correcting inference strategies.
- Investigate user-side practicality: how are masks/binding slots provided at inference without expert tools, and what is the impact of imperfect user masks on motion binding and identity isolation?
- Binding slots scalability and adaptability
- Study scalability beyond K=6 binding slots; develop mechanisms for a dynamic or learned number of participants, and quantify performance when many characters interact or swap places for long durations.
- Explore learning binding without explicit masks (self-supervised identity-motion association) and compare to mask-conditioned training under heavy occlusion and identity similarity.
- Environment weaving control
- Replace the binary environment switch with continuous or disentangled controls (e.g., blend camera motion from E_y with lighting from E_I; partial background adoption).
- Devise metrics to quantify environment consistency (e.g., lighting/color spill/occlusion handling) and hand–object/foot–ground contact plausibility under environment transfer.
- 3D consistency and geometry awareness
- Measure and improve 3D consistency under large camera motions, depth ambiguities, and view changes; compare end-to-end conditioning with explicit depth/mesh priors or multi-view constraints.
- Investigate integrating learned or estimated scene geometry (monocular depth, NVS priors) to stabilize interactions and reduce identity/motion drift across perspective changes.
- Fine-grained motion and contact modeling
- Extend Bias-Aware DPO beyond hands to feet–ground contacts (slippage), facial micro-expressions, eye gaze, hair/clothes secondary motion, and object manipulations; create region-specific preference datasets and objective weighting.
- Validate whether DPO preferences derived solely from synthetic error chains align with human preferences on real footage; consider human-in-the-loop preference curation and multi-criteria (motion accuracy vs. identity fidelity vs. contact realism).
- Evaluation methodology gaps
- Introduce objective motion-following metrics for end-to-end settings (e.g., keypoint/mesh tracking on target vs. driving, contact consistency scores) to complement GSB and Video-Bench.
- Provide quantitative ablations for each proposed module (in-context mask, mode-specific RoPE, reverse driving) with statistical significance, not only qualitative examples.
- Benchmark on non-human species and non-standard morphologies with explicit metrics (pose-following fidelity, identity leakage) to substantiate claims of broader applicability.
- Mode-specific RoPE generality
- Examine whether Mode-Specific Shifted RoPE effects generalize to other backbones/positional schemes; provide theory or diagnostics on why temporal vs. spatial shifts disambiguate modes and when this breaks.
- Assess sensitivity to the chosen offsets (ΔW, ΔHref) and provide auto-tuning or learned positional strategies.
- Long video stability and memory
- Systematically test long-horizon generation (multi-minute) for temporal drift, identity stability, and background coherence; compare history token strategies beyond “replace first two latents.”
- Explore memory-efficient recurrent/streaming mechanisms or keyframe-based conditioning to improve runtime and stability.
- User controllability and UX
- Formalize and evaluate richer controls (text-only instructions, region-level prompts, motion mixing, partial temporal transfer); define interfaces that do not rely on expert mask or segmentation tools.
- Add uncertainty estimation or confidence maps when motion binding/environment weaving is ambiguous, enabling fallback strategies or user corrections.
- Cross-modal and task extensions
- Extend to audio-driven constraints (lip-sync, music-driven motion), detailed facial animation, and speech–gesture alignment; create paired data/metrics and assess interference with body motion fidelity.
- Explore compositional tasks quantitatively (e.g., simultaneous multi-character animation + replacement + object retargeting) with dedicated metrics and datasets.
- Physical plausibility and safety
- Incorporate physics constraints (e.g., no foot sliding, torque limits, collision avoidance) or learned physical priors; introduce objective tests for physical plausibility and contact realism.
- Develop guardrails for identity misuse (consent, watermarking, provenance) and content safety; quantify the effectiveness of watermarking/traceability under end-to-end conditioning.
- Generalization to animals and non-rigid characters
- Build and evaluate an animal-focused benchmark (varied species, gaits, occlusions) and study segmentation/motion binding for tails/wings and topology changes; compare to skeleton-free alternatives.
- Investigate domain adaptation or specialized modules for non-human anatomy where pose estimators and SAM3 struggle.
- Computational efficiency and accessibility
- Profile training/inference cost and latency; explore distillation, low-rank adaptation, or sparsity to make the approach feasible beyond 64×H100 settings.
- Provide guidelines for resolution scaling, VAE bitrate settings, and trade-offs between quality, speed, and memory.
- Reverse driving assumptions
- Analyze whether reverse driving introduces subtle leakage or teaches the model to rely on target-specific artifacts; design controls/diagnostics to detect unintended supervision paths.
- Compare reverse driving to alternative curriculum (e.g., cycle consistency, teacher–student with noisy forward pairs) and quantify differences in motion fidelity and identity leakage.
- Data release and reproducibility
- Clarify the subset and licensing of MotionPair-60K to enable reproducible research; specify exact sources and filters to facilitate community baselines.
- Release code for the agentic synthetic loop (Candidate Selector, Prompt Weaver, Quality Checker) and report failure rates/edge cases.
- Comparative breadth
- Provide broader comparisons against closed-source models (e.g., Kling 3.0) under controlled protocols (same prompts, seeds, and visibility of inputs) and report statistical significance.
- Evaluate zero-shot generalization to out-of-domain scenes (underwater, extreme lighting, crowds, sports broadcast footage) and to high resolutions beyond training defaults.
- Theoretical understanding
- Develop analyses of why and when in-context end-to-end conditioning surpasses explicit pose representations, especially under occlusion and interaction; formalize failure boundaries and hybrid conditions that are provably beneficial.
- Study identifiability of motion–identity disentanglement under the proposed conditioning and masking, and propose diagnostics for identity leakage.
Practical Applications
Overview
SCAIL-2 introduces an end-to-end character animation framework that directly conditions a video diffusion model on driving videos and reference characters, unifying multiple tasks (single/multi-character animation and character replacement) through:
- In-context mask conditioning (environment switch and character binding slots),
- Mode-specific shifted RoPE for task disambiguation,
- A reverse-driving synthetic pipeline (MotionPair-60K) to create training pairs at scale,
- Bias-Aware DPO post-training to fix fine-grained motion errors (e.g., hands/fingers).
Below are practical, real-world applications grounded in these findings and design choices. Each item includes sectors, potential tools/products/workflows, and key assumptions/dependencies.
Immediate Applications
These can be deployed with current capabilities (offline or near-real-time) using the released weights/dataset subset and standard GPU infrastructure.
- Studio-grade digital doubles and character replacement for post-production — sectors: film/TV/VFX, advertising
- What: Replace or animate a performer’s appearance while preserving complex motion and human–object interactions without manual rotoscoping or unreliable skeletons.
- Tools/products/workflows: Nuke/Blender/Unreal plugins using SCAIL-2 inference; pipeline nodes to feed reference frames, driving clips, and binding masks (auto-generated via SAM3); environment switch toggles replacement vs. animation mode.
- Assumptions/dependencies: GPU inference (high-memory for 14B backbone), rights/consent for likeness use, shot complexity (crowd/occlusion) may need careful binding-slot authoring; hand/facial micro-motions improved by Bias-Aware DPO but not perfect.
- Previsualization and stunt/choreography previz — sectors: film, TV, game cinematics
- What: Rapid previz by swapping in stand-in actors, props, or creature references to test blocking and multi-character interactions.
- Tools/products/workflows: Storyboarding apps integrate SCAIL-2 batch renders; binding slots to lock motion-to-character mapping; mode-specific RoPE presets for animation vs. replacement sequences.
- Assumptions/dependencies: Offline iteration; segmentation quality (SAM3) for masks; motion ambiguity reduced by end-to-end driving but edge cases remain.
- Personalized ad creatives and brand mascots — sectors: marketing, social media
- What: Produce variant ads by swapping brand mascots or spokespersons into the same motion/environment with consistent HOI (e.g., holding products, instruments).
- Tools/products/workflows: Cloud API for batch creative generation; environment switch to preserve or change backgrounds; QC loop akin to the paper’s agentic quality checker.
- Assumptions/dependencies: Brand safety guidelines, content approval pipelines; compute costs for scale; legal clearance of likenesses.
- Creator tools for social video and VTubing (asynchronous) — sectors: creator economy, entertainment
- What: Animate custom avatars from recorded motions for shorts, music videos, or streams (offline/asynchronous rather than low-latency live).
- Tools/products/workflows: Desktop app or OBS plugin (offline render), reference bank per avatar, per-clip binding-slot presets; batch background replacement for style consistency.
- Assumptions/dependencies: Latency acceptable for non-live pipelines; GPU access (consumer GPUs feasible at reduced resolution); moderation tools advisable.
- Game modding and cinematic pipelines — sectors: gaming, e-sports content
- What: Swap player avatars/NPCs into cinematic sequences or recap content without re-rigging; multi-character scenes benefit from binding slots to avoid identity leakage.
- Tools/products/workflows: Unreal/Unity bridge; ingest replay footage as driving video; batch export to in-engine cutscenes or promotional clips.
- Assumptions/dependencies: Offline processing; licensing for game assets; animation-to-engine format conversions may need wrapper scripts.
- E-commerce/fashion video generation — sectors: retail, fashion tech
- What: Cross-body-shape animation to showcase clothing on diverse models by transferring motion from exemplar videos to new reference identities; background control to match brand aesthetics.
- Tools/products/workflows: Merchant dashboard plugin; environment switch for studio vs. lifestyle backgrounds; catalog avatar library.
- Assumptions/dependencies: Clothing physics not explicitly modeled; product fit realism depends on identity disentanglement quality and garment drape assumptions.
- Sports, fitness, and coaching media — sectors: sports media, fitness tech
- What: Create branded highlight reels or training clips by replacing the subject with team mascots or instructor avatars while retaining precise motion/object control (e.g., ball handling).
- Tools/products/workflows: Broadcast post pipeline node; batch processing tools; binding-slot presets for players vs. referees vs. crowd.
- Assumptions/dependencies: Timing constraints for broadcast; accurate HOI generally strong but extreme fast-motion may need QC; rights/league approvals.
- Academic R&D on end-to-end conditioning and diffusion alignment — sectors: academia, ML research
- What: Use MotionPair-60K subsets, in-context mask conditioning, and Bias-Aware DPO recipes to study multi-task conditioning, preference optimization for diffusion, and multi-entity binding.
- Tools/products/workflows: Training scripts with reverse-driving; ablation of mask channels, RoPE shifts, and DPO objectives; benchmark on Studio-Bench/X-Dance.
- Assumptions/dependencies: Compute resources (multi-GPU) for training variants; dataset license/availability.
- Automated rotoscoping/compositing acceleration — sectors: post-production, software
- What: Reduce manual roto by using the model’s environment weaving and character binding to regenerate foreground/background composites.
- Tools/products/workflows: After Effects/Premiere extension; export mattes from in-context masks; compare against inpainting baselines for artifact reduction.
- Assumptions/dependencies: Mask extraction (SAM3) quality; manual tweaks for edge lighting/reflections.
- Data synthesis for motion research — sectors: academia, simulation
- What: Generate consistent cross-identity motion pairs for evaluating pose-free tracking, HOI reasoning, and model-based mocap alternatives.
- Tools/products/workflows: Adopt reverse-driving synthetic loop; integrate quality checkers (VLMs) to filter outputs; programmatic binding-slot generation.
- Assumptions/dependencies: Reliance on pre-existing generators (pose-driven) when expanding datasets; curation effort to manage bias.
Long-Term Applications
These require further research, scaling, or system integration (e.g., real-time optimizations, improved face/hand detail, broader safety tooling).
- Real-time live character replacement for broadcast and events — sectors: live TV, sports, concerts
- What: Low-latency character swap or avatar overlays during live productions, preserving HOI.
- Tools/products/workflows: Model distillation/pruning; on-prem GPU accelerators; tight integration with camera-tracking and live keying systems.
- Assumptions/dependencies: Significant latency and compute optimization; robust segmentation without precomputation; safety/consent pipelines.
- Interactive AR/VR telepresence with multi-user avatars — sectors: XR, teleconferencing
- What: Real-time or near-real-time multi-character animation in shared spaces, with correct motion–identity binding and environment control.
- Tools/products/workflows: XR SDK plugins; online binding-slot editing; mixed-reality environment weaving; device-edge inference strategies.
- Assumptions/dependencies: Hardware constraints on headsets; improved hand/face fidelity and lip-sync integration; streaming bandwidth.
- Universal markerless motion capture alternative — sectors: gaming, animation, sports analytics
- What: Replace skeleton-driven mocap with end-to-end video-driven capture, especially where pose estimators fail (occlusions, non-humans).
- Tools/products/workflows: Export motion descriptors or mesh sequences inferred by the model; 3D reconstruction post-process; pipeline with mesh-guided variants.
- Assumptions/dependencies: Additional research for 3D-consistent outputs and retargeting; physics plausibility and calibration.
- High-fidelity facial performance and lip-sync animation — sectors: film, VTubing, education
- What: Extend Bias-Aware DPO to face/mouth/eye micro-expressions for dialog-driven performance.
- Tools/products/workflows: Face-centric preference datasets; audio-conditioned control streams; dedicated face binding slots.
- Assumptions/dependencies: New preference data with reliable positives; temporal coherence for speech; avoidance of identity leakage.
- Animal/creature and multi-species character animation — sectors: documentaries, games, education
- What: Leverage non-human generalization to animate animals or fantasy creatures from exemplar motions.
- Tools/products/workflows: Creature reference libraries; HOI with props; custom binding-slot conventions for appendages.
- Assumptions/dependencies: Broader training data and QA for tail/wing/claw dynamics; physics-informed priors beneficial.
- Unified multi-character choreographing editor — sectors: content creation software
- What: A timeline tool that authors binding-slot assignments, environment switches, and mode-specific RoPE presets for complex scenes.
- Tools/products/workflows: NLE/DAW-like interface; constraint solving for motion binding; preview renders.
- Assumptions/dependencies: UX research; standardization of mask/binding formats; collaboration features.
- Safety and provenance by design — sectors: policy, platforms, media compliance
- What: Integrate content credentials (watermarks, C2PA), consent metadata, and detection tools; use SCAIL-2 to stress-test detection.
- Tools/products/workflows: Provenance embedding at render; platform-side detectors tuned on MotionPair-like data; governance dashboards.
- Assumptions/dependencies: Standards convergence; legal frameworks for likeness and synthetic media labeling; stakeholder alignment.
- Energy-efficient, on-device deployment — sectors: mobile, creator tools
- What: Model compression/distillation for laptops/phones enabling creator-side rendering.
- Tools/products/workflows: Quantization, LoRA adapters, frame interpolation to reduce compute; caching of reference embeddings.
- Assumptions/dependencies: Quality–latency trade-offs; device thermal limits; incremental decoding research.
- Generalized multi-agent imitation learning with binding slots — sectors: robotics, autonomous systems (research)
- What: Re-purpose binding-slot conditioning to disentangle multi-agent motions from video for policy learning.
- Tools/products/workflows: Pipeline translating learned motion bindings into agent trajectories; sim-to-real adapters.
- Assumptions/dependencies: Bridging 2D video to 3D control; safety/physics constraints; domain transfer challenges.
- Privacy-preserving telehealth and education media — sectors: healthcare, education
- What: Replace identities in sensitive videos (patients, students) while keeping movements for analysis or instruction.
- Tools/products/workflows: Identity anonymization presets using replacement mode; clinician/educator avatar libraries.
- Assumptions/dependencies: Clinical validation for accuracy; institutional policies; secure compute/storage.
Cross-Cutting Assumptions and Dependencies
- Compute and scale: The 14B backbone was trained on 64× H100; practical deployment may require smaller distilled variants or cloud inference. Resolution/length trade-offs affect quality and cost.
- Data and licensing: MotionPair-60K is synthetic; subset and model weights will be released. Real-world use needs rights/consent for reference identities and driving footage.
- Segmentation/mask quality: In-context masks rely on SAM3; failure cases (crowds, occlusions) may require manual clean-up or improved segmentation.
- Quality caveats: Bias-Aware DPO improves hands but extreme fine-grained motions (subtle fingerings, lip-sync) still need further work. Physics consistency (cloth, collisions) is not modeled.
- Safety and governance: Potential for misuse (deepfakes) necessitates provenance, consent management, watermarking, and moderation workflows.
- Tooling integration: Robust adoption benefits from plugins for NLEs/VFX suites (After Effects, Nuke), DCCs (Blender, Maya), and game engines (Unreal/Unity), plus APIs for automation.
These applications leverage SCAIL-2’s core strengths—end-to-end conditioning, task unification, and robust multi-character binding—to reduce manual labor, improve motion/environment fidelity, and broaden the applicability of character animation across creative and technical domains.
Glossary
- Agentic editing loop: an automated, iterative pipeline that uses planning, checking, and editing components to synthesize better conditioning images; "we propose an agentic editing loop to generate plausible reference images directly from random human-centric datasets."
- Animation Mode: the sub-task where a character is animated within its original background; "hereafter we denote Animation Mode to be this specific task."
- Background inpainting: an image/video editing approach that fills in or regenerates background regions, often used to integrate a posed character into a scene; "achieve this by background-inpainting pose-driven animation."
- Bias-Aware DPO: a post-training scheme based on preference optimization that targets systematic errors (e.g., hand/finger motions) introduced by synthetic data; "we propose Bias-Aware DPO to construct preference items to mitigate the errors."
- Binding map: a mapping that specifies which driving character’s motion is routed to which target character; "We unify the sub-tasks of character image animation by a binding map $\pi: \mathcal{C}_{\boldsymbol{y} \!\to\! \mathcal{C}_{\boldsymbol{I}$"
- Binding slots: mask channels that explicitly bind motion sources to target characters to prevent identity mixing; "we further introduce channels as the binding slots."
- Candidate Selector: a component in the synthetic loop that picks the most suitable reference character/image; "The generation loop combines a Candidate Selector, a Prompt Weaver, a Quality Checker and a strong multi-reference image generation model"
- Channel concat: concatenating conditioning information as additional channels into the model’s latent or feature space; "rather than injected into the denoising embedding via channel concat"
- Denoising model: the network trained to remove noise from diffused latents conditioned on inputs; "A denoising model is trained to recover the added noise"
- Direct Preference Optimization (DPO): a training method that optimizes a model to prefer certain outputs over others based on pairwise preferences; "we can adopt DPO-based methods~\cite{Wallace_2024_diffusion_dpo} to optimize the preference."
- End-to-end driving paradigm: conditioning the generator directly on driving videos instead of intermediate representations, preserving full visual context; "SCAIL-2 adopts end-to-end driving paradigm to bypass unreliable animation intermediates."
- Environment affordance: the environmental cues and constraints that shape how a character interacts with the surroundings; "Character replacement, typically defined as animation with environment affordance"
- Environment switch: a mask channel indicating whether the environment should come from the reference or the driving video; "we add $1$ additional channel as environment switch"
- Exocentric human skeletons: third-person skeletal representations of motion that can be ambiguous for interactions; "but still rely on exocentric human skeletons"
- Fixed spatial offset: a deliberate positional shift applied to driving tokens to keep them spatially separate from video tokens; "carries a fixed spatial offset along the axis"
- FSDP-2: a specific distributed training strategy (Fully Sharded Data Parallel v2) used to scale large models efficiently; "using FSDP-2~\cite{zhao2023pytorch}."
- Forward diffusion process: the noising process that progressively corrupts data in diffusion models; "A forward diffusion process then progressively corrupts by adding Gaussian noise over timesteps:"
- GSB (Good/Same/Bad): a human evaluation protocol categorizing results as better, on par, or worse than references; "we adopt GSB(Good/Same/Bad) subjective evaluations"
- HOI (Human-Object Interaction): interactions between humans and manipulated objects that models must preserve; "human-object-interaction (HOI) generalization."
- I2V backbone: an image-to-video generative backbone used to synthesize video from conditioning inputs; "The I2V backbone~\cite{wan} receives the input of $[\boldsymbol{z}_{\text{ref};\, \boldsymbol{z}_{t};\, \boldsymbol{z}_{\text{driv}]$"
- In-Context Driving design: a conditioning scheme that concatenates context tokens (reference/driving) directly with the target sequence; "Our model adopts the In-Context Driving design~\cite{scail},"
- In-Context Mask Conditioning: supplying additional mask channels (environment switch and binding slots) as soft guidance alongside visual context; "We propose In-Context Mask Conditioning to simultaneously model the difference between sub-tasks and enhance the original raw visual inputs"
- Latent video diffusion model: a diffusion model operating in a compressed latent space (via VAE) for video generation; "a latent video diffusion model~\cite{wan} first encodes it into a latent representation"
- LPIPS (Learned Perceptual Image Patch Similarity): a perceptual similarity metric used to evaluate visual quality; "low level metrics like SSIM~\cite{ssim}, PSNR~\cite{psnr}, LPIPS~\cite{lpips}, FVD~\cite{fvd} can be calculated"
- Mode-Specific Shifted RoPE: a RoPE configuration that shifts positional encodings differently for animation vs. replacement modes to reduce conflicts; "we adopt Mode-Specific Shifted RoPE."
- Motion Binding: an objective for correctly extracting motions from the driving video and routing them to the intended target characters; " Motion Binding --- extract motions from the driving video"
- MotionPair-60K: a curated dataset of synthetic motion-transfer video pairs used to train end-to-end conditioning; "synthesize MotionPair-60K, an end-to-end motion transfer dataset"
- Pose-driven methods: approaches that rely on extracted pose sequences (e.g., skeletons) as motion conditions for generation; "Pose-driven methods first extract an explicit pose sequence $c_{\text{pose} = \mathcal{P}(\boldsymbol{y})$ via an off-the-shelf estimator"
- Pose-guider: a module or pathway that injects pose information into diffusion models; "via channel concat~\cite{wananimate} or pose-guider~\cite{unianimate-dit}."
- Preference tuple: the structured pair of preferred and less-preferred outputs (with shared conditioning) used for preference optimization; "forming a preference tuple:"
- Renderer-trained: models trained on data produced by a graphics engine/renderer rather than real footage; "We adopt renderer-trained single-character replacement model~\cite{mocha}"
- Reverse Driving: a training strategy where synthesized videos are used as driving inputs and real videos as supervision targets to avoid generator biases; "Reverse Driving. We use data in a reverse manner:"
- RoPE (Rotary Positional Embeddings): a positional encoding technique applying rotations in embedding space to encode positions; "3D RoPE coordinates assigned to $\boldsymbol{z}_{\text{ref}$"
- SAM3: a segmentation model used to extract masks for in-context conditioning; "The extraction is performed by a robust segment model SAM3~\cite{sam3} with rule-based matching."
- SAM3D-Body: a 3D human mesh/segmentation tool used as a pose/shape condition for evaluation; "adopting human mesh from SAM3D-Body~\cite{sam3db}"
- SFT (Supervised Fine-Tuning): a training approach where a model is refined on labeled examples without preference comparisons; "SFT can strengthen hand learning by adding an explicit hand loss"
- Studio-Bench: a benchmark for evaluating character animation, including complex motions and interactions; "We evaluate the animation performance of our methods using Studio-Bench~\cite{scail}"
- Universal Transfer: an objective to disentangle pose from identity so motions transfer without leaking appearance; " Universal Transfer --- disentangle pose from identity so that motion extracted from any driving character transfers to any target in a physically plausible manner without identity leakage."
- VAE encoder: the encoder of a variational autoencoder used to map videos into latent space for diffusion; "via a pretrained VAE encoder ."
- VDMs (Video Diffusion Models): diffusion-based generative models specialized for video synthesis; "video diffusion models (VDMs)~\cite{svd, cogvideox, wan}."
- Video-Bench: an automatic evaluator/benchmark suite for video quality; "We also employ Video-Bench~\cite{videobench} as the automatic evaluator"
- VLM (Vision-LLM): a model jointly processing vision and language, used here for data quality checking; "when applying VLM~\cite{gemini} to check the synthetic data."
- Zero-shot: evaluating or applying a model on tasks or settings not seen during training; "the multi-character animation results are zero-shot"
Collections
Sign up for free to add this paper to one or more collections.