- The paper presents a novel technique that injects retrieval rewards at each generation step to guide token-level query optimization.
- It employs a dual reward strategy through beam search and policy updates, significantly enhancing retrieval accuracy and efficiency.
- Experimental results demonstrate improved nDCG scores and reduced latency, affirming robust performance across in-domain, out-of-domain, and multilingual settings.
STORM: Stepwise Token Optimization with Reward-Guided Beam Search
Contemporary information retrieval (IR) increasingly utilizes dense and learned-sparse neural retrievers that necessitate expensive indexing and maintenance. Lexical retrievers like BM25, though efficient for deployment and updates, often encounter severe vocabulary mismatch, limiting retrieval performance. Recent attempts to bridge this gap leverage LLM-based query expansion or rewriting, but these methods are typically agnostic of the retriever's feedback during generation. Reinforcement learning-based approaches provide retrieval rewards to the sequence as a whole, yet suffer from credit assignment inefficiencies due to delayed and aggregate supervision.
STORM (Stepwise Token Optimization with Reward-Guided Beam Search) addresses these inefficiencies by injecting retrieval feedback into the generation process at every token, converting the global retrieval reward into a token-level signal that guides exploration and optimization.
Methodology and Novelty
STORM reconceptualizes the training of query rewriting models for lexical retrieval by merging reward-guided beam search with cooperative training. At each generation step, partial expansions are submitted to the retriever (BM25 in this case), and their relevance is instantly scored. Only candidates predicted to be effective are retained and expanded further, pruning low-reward branches early and focusing both exploration and exploitation on useful vocabulary.
This approach not only enables efficient discovery of discriminative terms but also leverages the retrieval reward twice: once as a token-level guide in decoding and a second time as a reweighting function during policy updates within the Generative Cooperative Networks (GCN) paradigm. The policy is updated using importance-weighted off-policy learning, mixing reward-guided beams and stochastic samples to stabilize training and promote diversity.
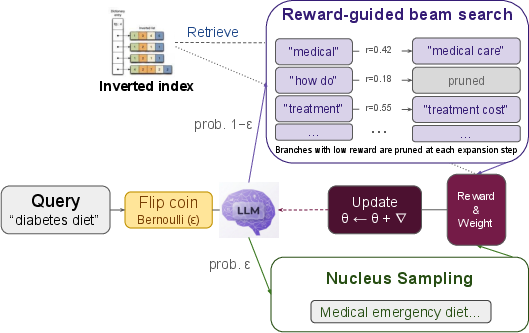
Figure 1: The STORM training loop; queries are routed either to reward-guided beam search, which integrates stepwise retriever feedback and pruning, or to classical nucleus sampling, followed by scoring and policy updating.
Experimental Evaluation
STORM was instantiated atop LLMs of varying sizes (Qwen3-0.6B, 1.7B, 4B, and 8B) and compared against standard lexical baselines (BM25, RM3, SPLADE-v2), prompt-based LLM query rewriters (HyDE, MuGI, W2P, QUESTER), and dense retrievers (mDPR, mContriever, mColBERT) on an array of benchmarks:
- In-domain: TREC DL'19/20, MS-MARCO dev
- Out-of-domain: 12 BEIR datasets
- Multilingual: MIRACL (18 languages, zero-shot transfer)
Across nearly all settings, STORM achieved the best or near-best nDCG@10 scores relative to model size, often with substantial margins. For instance, STORM-8B obtains nDCG@10 = 67.3 on TREC DL'20 and averages out-of-domain nDCG@10 = 47.5, outperforming all size-matched LLM rewriters and lexical baselines. At 0.6B parameters, STORM already yields clear improvements over BM25, RM3, and HyDE, indicating sample efficiency and robustness at smaller scales.
Zero-shot transfer experiments on MIRACL revealed that STORM, trained solely on English, outperformed dedicated multilingual dense retrievers on average (nDCG@10 up to 48.4, compared to 44.1 for mColBERT), with especially large gains on morphologically rich languages (French, German, Chinese).
Latency evaluations revealed that STORM's output is both compact and highly effective, achieving retrieval times competitive with vanilla BM25 (<15ms per query at 8B scale), in stark contrast to other LLM-based rewriters whose verbose outputs substantially inflate retrieval latency (W2P: >34s, MuGI: >16s per query).
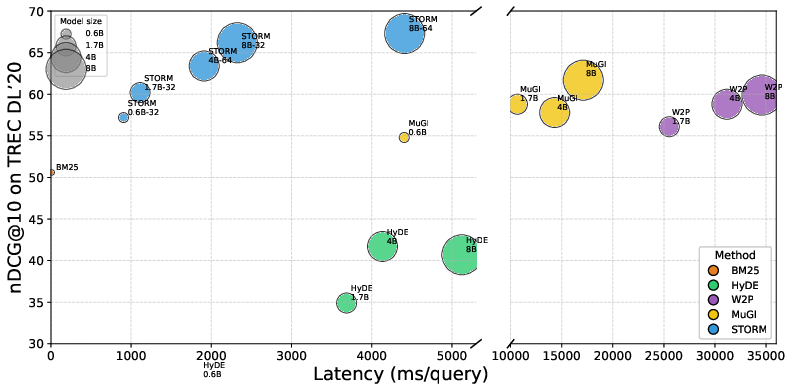
Figure 2: Latency–effectiveness landscape on TREC DL'20. STORM resides in the upper-left, simultaneously maximizing effectiveness (nDCG@10) and minimizing query latency compared to LLM rewriters.
Analysis and Ablations
A thorough ablation study demonstrated the impact of multiple design choices:
- Reward-guided beam search was essential for effective exploration and early convergence, outperforming standard sampling and greedy decoding.
- Mixture weights and temporal parameters modulated exploration-exploitation trade-offs.
- The length budget for generation required tuning by dataset but was less critical for small models; for large models and multilingual generalization, expanded output length further improved effectiveness.
- Both LoRA and full fine-tuning were effective; the former offered competitive performance with lower resource cost.
Qualitative analyses show that, compared with generative baselines that emit long pseudo-passage expansions, STORM produces concise and discriminatively targeted keyword sets, directly aligned with the retriever's needs. This not only improves ranking but reduces computational cost at retrieval.
Theoretical and Practical Implications
STORM's approach has several far-reaching implications:
- Lexical query rewriting can serve as a tractable, retriever-aligned, and scalable substitute for dense neural retrieval in many practical scenarios, especially where dense indexing is infeasible or costly.
- By converting global, non-differentiable retrieval metrics to local token-level learning signals, the methodology provides a blueprint for aligning generative models with arbitrary black-box objectives.
- The demonstrated zero-shot multilingual transfer suggests that reward-aligned query policies learn content-based discriminative term selection that generalizes cross-lingually, conditional on a multilingual backbone.
- The efficiency gains (in both generation and retrieval) argue for the practicality of reward-guided approaches in interactive or latency-sensitive IR/RAG pipelines.
Future Directions
Several extensions and open questions follow naturally:
- Adaptive generation length: dynamically controlling expansion size based on query or corpus characteristics may further increase efficiency without loss of effectiveness.
- Integration with learned sparse retrievers: extending reward definitions beyond lexical BM25, possibly leveraging learned sparse models as the reward oracle, could address in-domain performance gaps relative to SPLADE.
- Alternative retrieval objectives: exploring finer-grained feedback (e.g., passage-level or contextual relevance) or incorporating semantic constraints could broaden applicability in RAG and conversational IR.
Conclusion
STORM introduces a principled, scalable, and retriever-aware approach to query rewriting by transmitting retrieval signals down to the token level via reward-guided beam search. Empirical evidence confirms that this approach yields models that outperform contemporary lexical, generative, and dense retrieval baselines of similar scale, with particular strengths in efficiency, robustness, and multilinguality (2606.10621). STORM's framework paves the way for systematically aligning LLM-based generation with non-differentiable downstream metrics, advancing both theoretical insights and practical deployments in retrieval and RAG systems.