- The paper demonstrates that crowd behavior predominantly determines which parts of a document are highlighted, overshadowing individual contributions in initial salience.
- The paper employs co-readership identity controls to disentangle document structure, crowd influence, and personal residuals for precise within-document prediction.
- The paper shows that a modest history captures stable thematic preference, revealing a strong individual signature in selection tasks despite minimal personal salience.
Summary of "Personal Salience: Highlighting Is Social, but Individuality Lives in Selection"
Decomposition of Highlighting: Social vs. Individual Salience
This paper defines a methodological framework for analyzing the origin and structure of textual highlighting traces in social annotation platforms, with emphasis on how much individuality can be recovered from such traces. The authors develop precise controls by leveraging co-readership identity controls, thus separating generic salience (document-level structure and semantic centrality), crowd salience (aggregation of marks from other readers), and personal salience (individual residuals). Two principal tasks are investigated: within-document salience prediction (which sentences are selected as highlights) and selectivity prediction (which already-highlighted spans belong to a particular reader).
Strong empirical evidence is produced that within-document highlighting is predominantly social. The crowd (other readers’ highlights) is the strongest predictor of what any given reader marks, outperforming both document structure and sophisticated personalization models trained on user history. Even a frontier LLM “twin” trained with leakage-free user history underperforms the crowd baseline, highlighting the information-privileged nature of aggregated human labels.
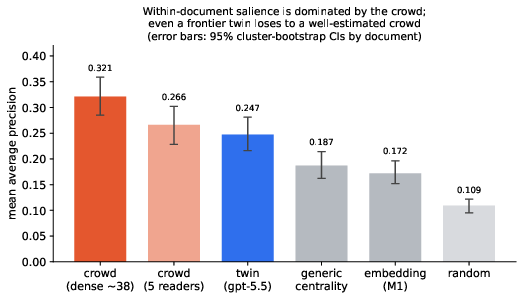
Figure 1: Within-document salience is overwhelmingly predicted by aggregated crowd behavior; the “twin” LLM and personal embedding models are decisively outperformed.
Crucially, the personal signal in within-document salience is quantitatively negligible—the own-vs-other identity gap is only +0.017 AP for the embedding-based scorer, and not statistically significant with the LLM-based twin. Hence, individuality in highlight selection is almost entirely subsumed by shared salience.
Selection Reveals Individuality: Asymmetry of Recoverable Signal
In sharp contrast, the selectivity task (discriminating which salient spans are a specific reader’s) surfaces a strong individual signature. When candidates are restricted to already-marked passages, a user’s own history is a robust predictor. The own-vs-other identity gap in selection is +0.14, nearly an order of magnitude stronger than in salience.
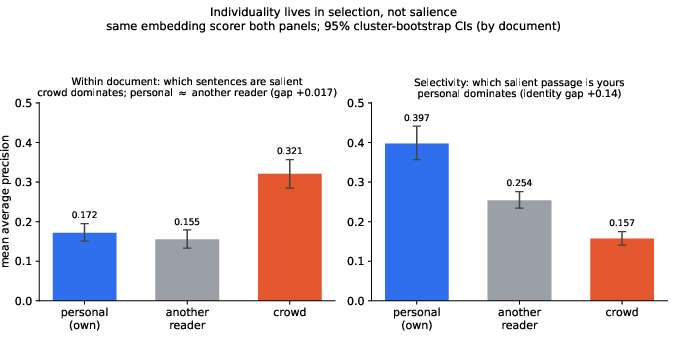
Figure 2: Individual signal in highlighting emerges strongly in selection tasks; the personal model decisively outperforms both crowd and peer models.
Crowd popularity is anti-predictive in selectivity: the most-marked spans are universally shared and not diagnostic of a single individual’s preferences, scoring below the base rate. The distinction is clear—salience is governed by crowd dynamics, but selection is informative of personalized thematic preference.
Topic Decomposition and Stable Thematic Preference
The paper decomposes selectivity signal into thematic vs. non-thematic components by substituting the comparison peer with topically-nearest co-readers. As topic similarity increases, the selectivity gap shrinks eightfold, indicating that stable thematic preference dominates the individual signal. Even against a near-topic-twin, a residual (+0.026 AP) survives, which the authors caution may reflect either finer-grained topic nuances or non-thematic “style”; current embedding models may not precisely disentangle these.
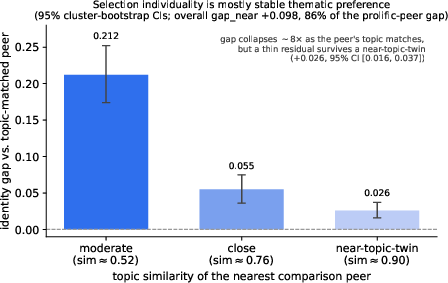
Figure 3: Selectivity signal is largely explained by stable thematic preference; a thin residual survives even when peer similarity is maximized.
This decomposition demonstrates that most recoverable individuality from highlight history is stable topic preference, although a thin semantic residual may persist.
Scaling Laws: History Requirements for Individual Signal
The authors establish a scaling law for selectivity prediction based on the number of prior highlights (K) used to build personal profiles. Selectivity AP increases with more history and plateaus after approximately $60$ highlights; additional history yields negligible gains. This indicates that a modest history suffices for capturing individual selectivity, while crowd prediction accuracy is data-hungry and continues to improve with more readers.
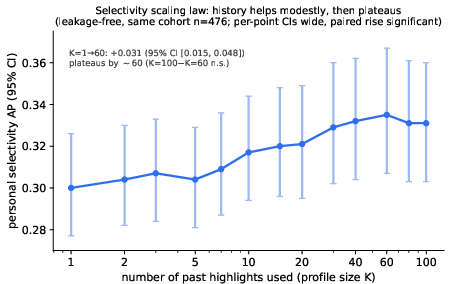
Figure 4: Selectivity AP rises with increasing history and plateaus quickly, supporting that a modest number of highlights captures personal preference.
Population-Level Trends in Crowd Consensus
An exploratory analysis reveals that crowd consensus in highlighting decreases as document popularity increases; as more readers annotate a document, inter-reader agreement on highlights declines. Although statistical significance is limited, the trend is consistent with annotation-disagreement literature and suggests increasing heterogeneity in large audiences.
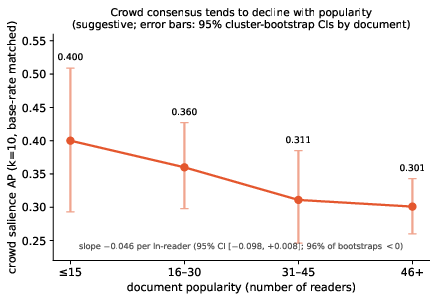
Figure 5: Crowd consensus diminishes with document popularity, indicating greater variance in highlight selection among larger reader pools.
Implications and Future Directions
The paper’s findings carry methodological and theoretical implications for personalization, digital twins, and social annotation:
- Digital Twin Limitations: Personalization from behavioral highlight traces is primarily effective at predicting selection among salient content, not identifying salience itself.
- Personalization Benchmarks: The results challenge benchmarks assuming strong recoverable individual salience and underscore the necessity of using proper identity controls and leakage-free profiles.
- Crowd Dynamics: The dominance of crowd salience supports the robustness of wisdom-of-crowds phenomena in shared annotation, while weakening as document diversity increases.
- Future Work: Refinement of semantic embeddings, modeling of finer-grained style or cross-topic transfer, and analysis of niche or private content are potential research avenues. Improved deduplication and richer profile aggregation (e.g., retrieval, recency effects) could further clarify individual signal extraction.
Conclusion
The study demonstrates that highlighting behavior in social annotation systems is predominantly social, with crowd consensus serving as the primary determinant of what passages are salient. The individual signature, while genuinely present, is significantly stronger in selection tasks—choosing among commonly-highlighted options—than in initial salience. Stable thematic preference accounts for most of this signal, with minimal evidence for non-thematic style. Personalization in digital annotation should therefore focus on leveraging selection dynamics, using careful leakage-free controls and appropriately-constructed crowds, to accurately model individual interests.

